






Zoom In and Out: A Mixed-scale Triplet Network for Camouflaged Object Detection
Abstract
作者受到人类在观察模糊图像会放大和缩小行为的启发,设计了一种混合尺度的三重网络ZoomNet。
ZoomNet采用Zoom策略,通过设计尺度集成单元和分层混合尺度单元学习判别混合尺度语义,挖掘候选对象与背景环境之间的不可察觉的线索。
此外,考虑到不可区分纹理的不确定性和模糊性,ZoomNet构建了一个简单而有效的正则化约束,即不确定性感知损失,促进模型在候选区域准确地产生更高置信度的预测。

Structure
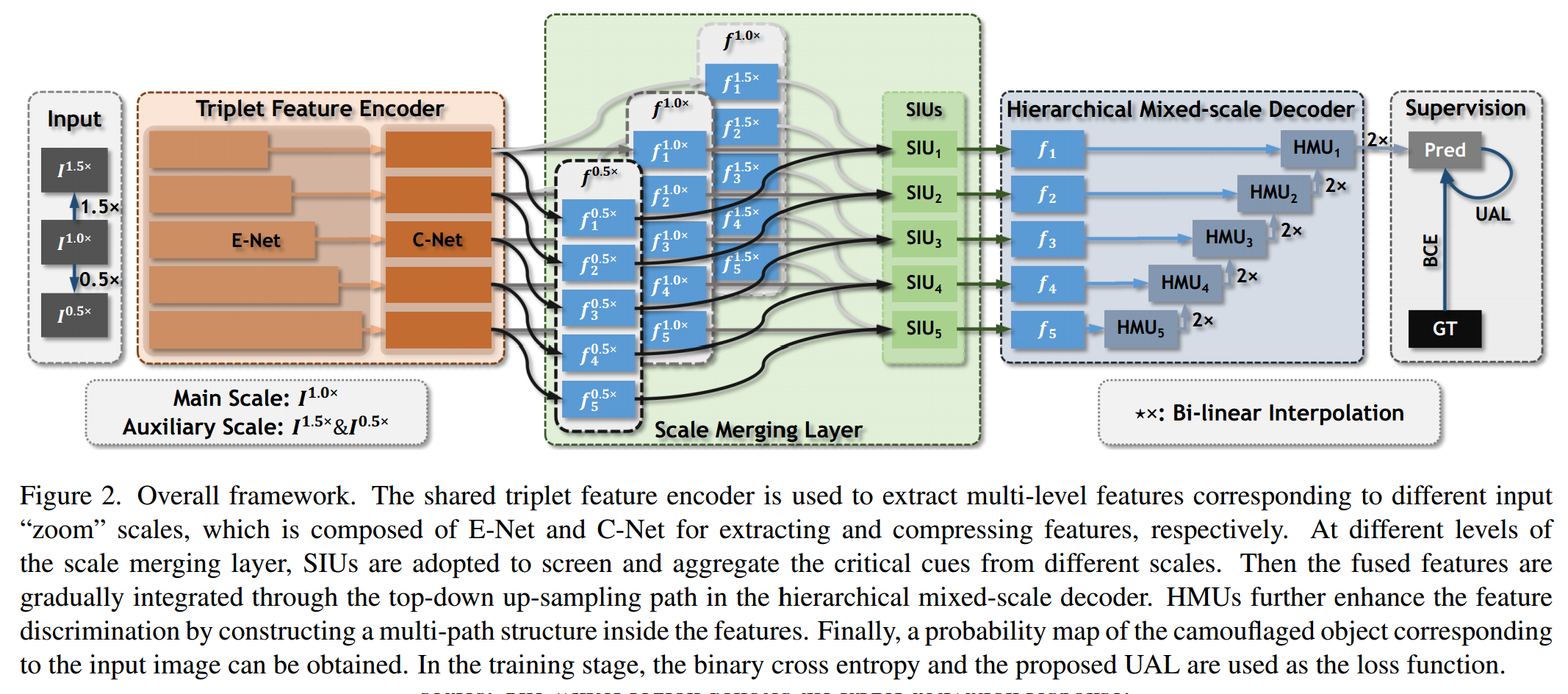
ZoomNet使用共享的triplet特征编码器提取不同尺度的特征。然后使用尺度融合单元SML在attention-aware filtering机制下,融合这些特征。接着ZoomNet使用分层混合尺度单元HMUs以自上而下的方式逐步融合多尺度特征表示。除此之外,ZoomNet也使用了一种不确定损失(UAL)去协助BCE损失。
Scale Merging Layer
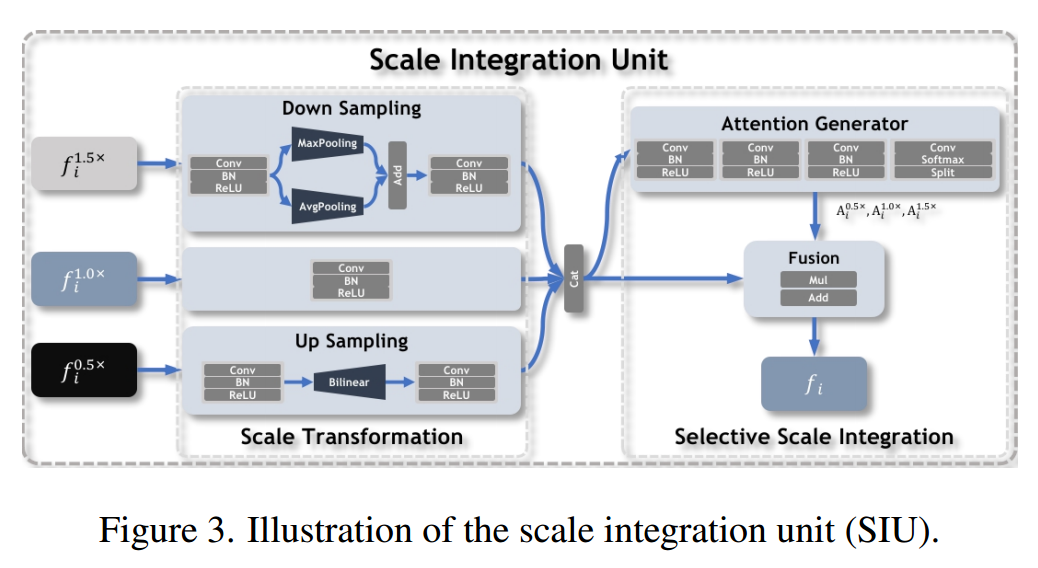
如公式所示,该层的主要工作是将0.5尺度下的特征进行双线性差值操作,将1.5尺度下的特征进行混合池化操作。然后,对这三组特征进行连接。最后经过一系列的Conv-BN-ReLU层和一个softmax层激活后获得每个特征的注意力图。最终的融合是将不同尺度的特征进行加权相加。
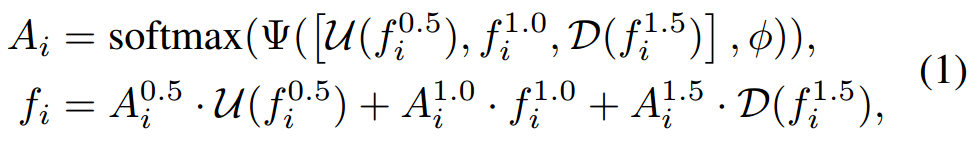
Hierarchical Mixed-scale Decoder
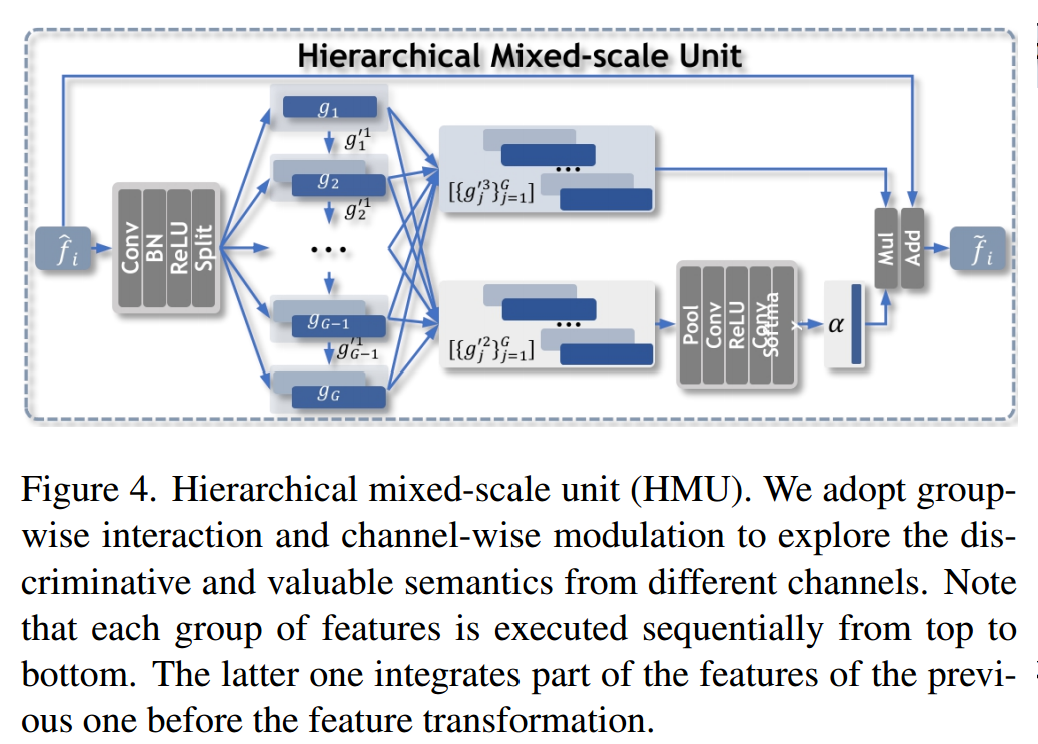
分层混合尺度解码器主要用来融合不同channels的特征。分层混合尺度解码器会融合尺度融合层的特征和上一个分层混合尺度解码器的特征。

Group-wise Iteration
ZoomNet使用1×1的卷积去扩展特征图的通道数。然后将这些特征分成G个group,将gi分成三个gi’,将后两个gi’用来channel-wise modulation,第一个gi’与gi+1进行连接,实现信息交换。
Channel-wise Modulation
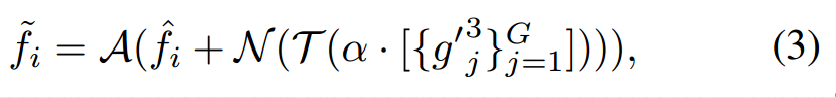
ZoomNet会连接g’2接着会转换成特征调制向量α,α会对g’3连接成的特征进行加权,然后经过一个卷积层,再与fi连接,最后经过一个激活层。
Loss Functions
伪装物体检测只使用BCEL时,会在预测的时候,产生严重的模糊性和不确定性,降低COD的可靠性。ZoomNet为了迫使模型增加决策的置信度,增加了对模糊预测的惩罚,设计了一个强约束的不确定感知损失作为BCEL的辅助函数。

不确定感知损失LUAL = 1 - | 2pi,j - 1 |2,模型的总损失函数可以表示为:
L = LBCEL + λ×LUAL
Summary
ZoomNet的主要思想是融合不同尺度的特征来让模型学习到图片中的关键线索,思想很像是特征金字塔。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











