







编译:将源代码翻译成目标代码的过程
完整编译过程:

整个编译过程可以分为编译前端和编译后端。编译前端包含词法分析、语法分析和语义分析,通常与目标平台无关,仅负责分析源代码。编译后端通常与目标平台有关,涉及中间代码的生成、优化及目标代码生成。
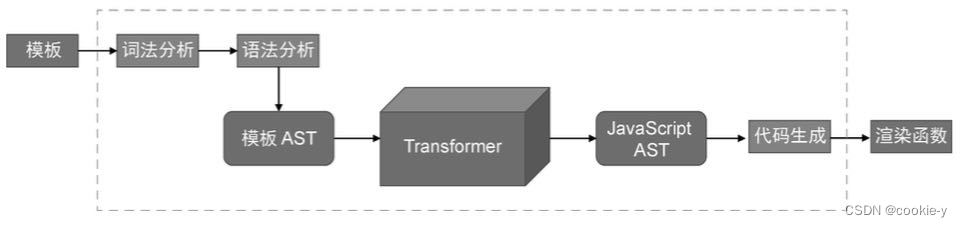
Vue编译流程
对Vue的模板编译器来说,源代码就是组件的模板,标代码就是渲染函数
AST是 abstract snytax tree 的首字母缩写,即抽象语法树,是一个具有层级结构的对象。
模板AST就是用来描述模板的抽象语法树,具有与模板同构的嵌套结构。
- 不同类型的节点通过
type属性区分 - 子节点存储在
children数组中 - 标签节点的属性节点和指令节点存储在
props数组中 - 不同类型的节点会使用不同的对象属性进行描述
const ast = {
// 逻辑根节点
type: 'Root',
children: [
// div标签节点
{
type: 'Element',
tag: 'div',
children: [
// h1标签节点
{
type: 'Element',
tag: 'h1',
props: [
// v-if指令节点
{
type: 'Directive',
name: 'if'
exp: {
// 表达式节点
type: 'Expression',
content: 'ok'
}
}
]
}
]
}
]
}
对具体步骤进行封装
- parse():完成对模板的词法分析和语法分析,得到模板AST
- transform():完成对模板的语义分析,实现模板AST到JavaScript AST的转换工作
- generate():根据JavaScript AST生成渲染函数

// 目标代码生成过程
const templateAST = parse(template)
const jsAST = transform(templateAST)
const code = generate(jsAST)
parse()
将模板字符串解析为模板AST的解析器。
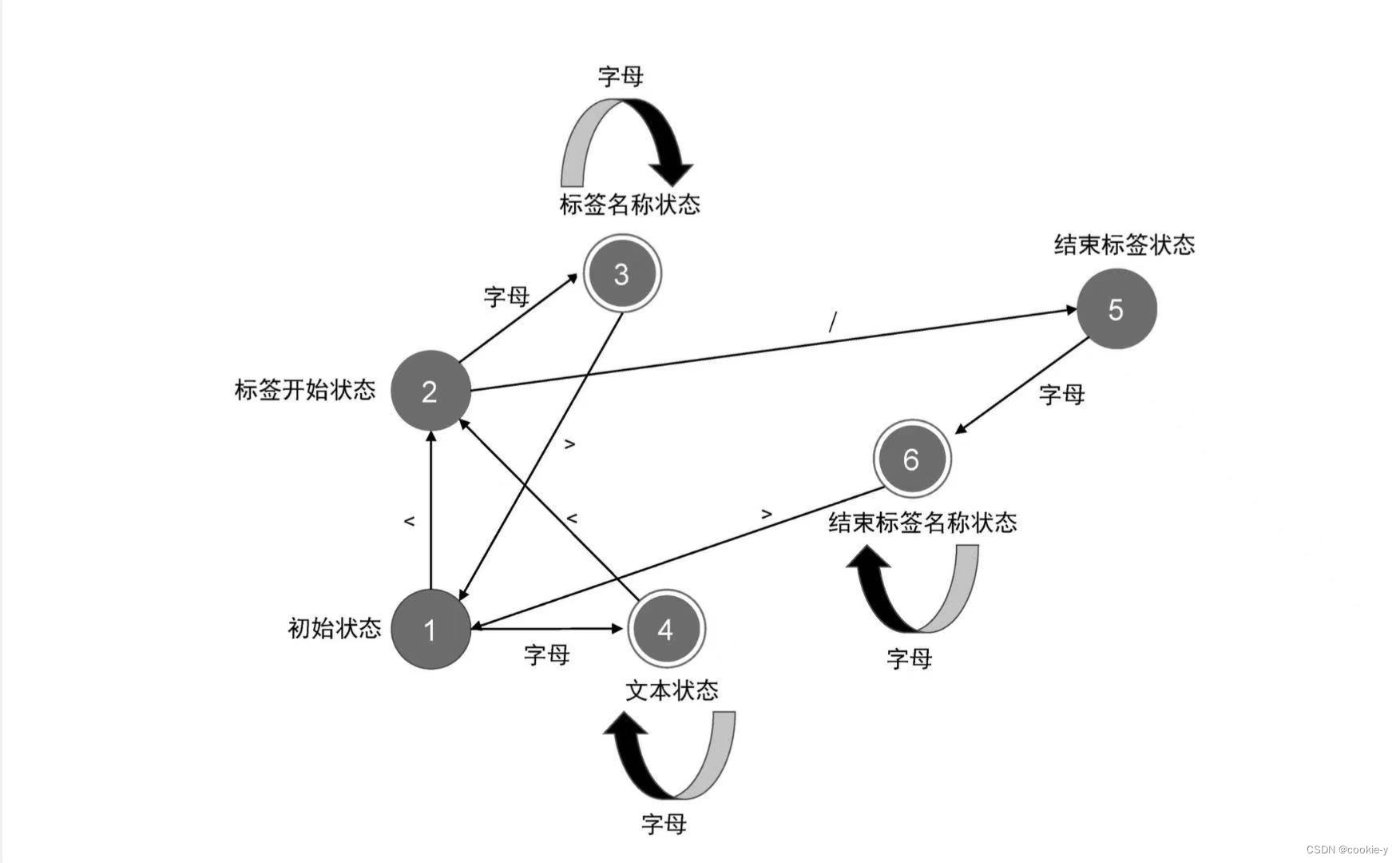
解析器的入参是字符串模板,解析器会逐个读取字符串模板中的字符,根据一定的规则通过有限状态自动机进行切割。
有限状态指有限个状态,自动机指随着字符的输入,解析器会自动在不同状态间迁移。
有限状态自动机可以帮助我们完成对模板的标记化
文本模式指的是解析器在工作时所进入的一些特殊状态,在不同的特殊状态下,解析器对文本的解析行为会有所不同。解析器行为规范
| 模式 | 能否解析标签 | 是否支持HTML实体 |
|---|---|---|
| DATA | 能 | 是 |
| RCDATA | 否 | 是 |
| RAWTEXT | 否 | 否 |
| CDATA | 否 | 否 |
const parse = (str) => {
// 定义上下文对象
const context = {
// source是模板内容,用于在解析过程中进行消费
source: str,
// 解析器当前处于的文本模式,初始模式为DATA
mode: TextModes.DATA,
// 消费指定数量的字符
advanceBy(num) {
context.source = context.source.slice(num);
},
// 消费空白字符
advanceSpaces() {
// 匹配空白字符
const match = /^[\t\r\n\f ]+/.exec(context.source);
if (match) {
// 消费空白字符
context.advanceBy(match[0].length);
}
},
};
// 调用parseChildren函数开始解析, 它返回解析后得到的子节点
const nodes = parseChildren(context, []);
return {
type: "Root",
children: nodes,
};
};
解析子元素
function parseChildren(context, ancestors) {
// 定义nodes数组存储子节点, 是最终的返回值
let nodes = [];
// 从上下文对象中取得当前状态,包括模式mode和模板内容source
const {
mode, source } = context;
// 开启while循环,只要满足条件就会一直对字符串进行解析
while (!isEnd(context, ancestors)) {
let node;
// 只有DATA模式和RCDATA模式才支持插值节点的解析
if (mode === TextModes.DATA || mode === TextModes.RCDATA) {
// 只有DATA模式才支持标签节点的解析
if (mode === TextModes.DATA && source[0] === "<") {
if (source[1] === "!") {
if (source.startsWith("<!--")) {
// 注释
node = parseComment(context);
} else if (source.startsWith("<![CDATA[")) {
// CDATA
node = parseCDATA(context, ancestors);
}
} else if (source[1] === "/") {
// 结束标签
// 状态机缺少与之对应的开始标签
console.log("无效的结束标签");
continue;
} else if (/[a-z]/i.test(source[1])) {
// 标签
node = parseElement(context, ancestors);
}
} else if (source.startsWith("{
{")) {
// 解析插值
node = parseInterpolation(context);
}
}
// node不存在,说明处于其他模式,此时一切内容都作为文本处理
if (!node) {
// 解析文本节点
node = parseText(context);
}
nodes.push(node);
}
return nodes;
}
解析器遇到开始标签时,将该标签压入父级节点栈,并开启新的状态机;遇到结束标签且父级节点栈中存在于该标签同名的开始标签节点时,停止当前正在运行的状态机
function isEnd(context, ancestors) {
// 当模版内容解析完毕后,停止
if (!context.source) return true;
// 与父级节点栈内所有节点作比较
for (let i = ancestors.length - 1; i >= 0; --i) {
// 如果遇到结束标签,只要父级节点栈中存在与该标签同名的开始标签节点,就停止
if (context.source.startWith(`</${
ancestors[i].tag}`)) {
return true 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1116
1116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









