







第一章 绪论
1.1研究背景和意义
随着科学技术的高速发展,技术知识的创新,硬件设备的更新迭代,使得机器视觉以及人工智能不再只是停留在纸面上,许多传统行业也逐渐寻求从人工密集型向人工智能转型的途径。如何用机器来替代简单重复的工作程序已经成为了目前工业的发展趋势,本文基于深度学习和图像识别技术,以自主导航机器人为载体,设计并实现了一套适用于移动平台多仪表定位及识别读数的算法,用于工业复杂背景下的智能仪表识别读数。
仪表作为测量、监视以及数据采集的重要工具,被广泛应用于油田、油井、电站等工业场所,仪表能有如此广泛的运用得益于它诸多不可替代的优点:结构简单、成本低、耐使用、抗干扰性强等;也正因为仪表的广泛运用,让读取表盘数据,记载录入数据成为一项庞大而繁琐的工作。仪表分为指针式仪表和数字式仪表,指针式仪表一般不具备数据传输接口,因而无法实现测量数据的自动采集与传输,大多采用人工的方式进行数据录入,这种模式效率低、读数慢、时效性差。数字式仪表虽然大多带有数据传输的接口,可受到工业强电、强磁场环境的干扰,数据传输不稳定甚至可能出现数据断流的情况。因此寻找一种替代人工读数的方法也就成为行业里的一种需求,在所有的研究方法中,最可行、最有效的方式就是通过视觉图像技术来完成对仪表拍摄图像的识别读数。
依据指针式仪表的特征和几何特点,应用投影变换,EAST文本检测网络,轮廓筛选,霍夫变换,直线检测及拟合等方法实现对仪表的坐标矫正、表盘及表盘中心定位、指针定位及拟合。结合对刻度线的统计分析计算出仪表的最小刻度角。结合对指针的相对偏转角求解完成指针式仪表的读数。算法的适用性较强,在复杂背景下的定位效果优异。针对数字式仪表,运用颜色空间转换,图像形态学操作,像素投影法,自适应高度截取、穿线法等方法实现对数字式仪表的数字提取、分割、识别以及小数点的定位和提取,完成对数字式仪表的识别读数,算法适用性较好,并在多个测试目标上得到有效验。
1.2研究现状:
最早在国外开展指针式仪表读数识别的是Sablatnig R团队,该团队通过对原始被测仪表内的形状,相对位置和大小定义一套先验参数,来实现限定场景下特定仪表的识别。Sambarta Dasgupta等人对数字图像中圆形的研究提出了创新性的观点,算法基于群体智能技术,即细菌觅食优化(BFO),用BFO算法演化了一组编码的候选圆,以便它们可以提取图像边缘图上的实际圆,该方法与Hough圆形检测相比具有较高的鲁棒性。Behaine Carlos引入主动形状模型(ASM)方法进行指针识别,以增加其鲁棒性。Chen Xi等人利用形态学分割从背景中提取表盘,然后利用改进霍夫变换来对指针进行定位。
和国外相比,国内开展仪表识别的进展稍晚一些,国内研究较早的有哈尔滨工业大学的张凤翔,采用高分辨率工业摄像机,借助浮动阈值法对图像进行预处理,通过对刻度线检测校正得到精确的圆心位置,实现指针式仪表的识别。谢吉航基于霍夫圆检测、MSER(Maximally Stable Extremal Regions)实现对仪表及表盘文本的获取,将边缘检测和形态学算法结合,进而再对仪表识别读数。孙浩晏针对霍夫算法参数难选择和获取的极坐标参数不能直观反映直线信息以及最小二乘算法受噪声影响较大等问题,使用RANSAC方法对最小二乘直线拟合算法进行了改进,改进后的算法具有很强的鲁棒性和容错能力,能够获得可信度较高的指针直线山。陈彬通过对仪表指针中心点检测,并将检测结果用于投影实现对指针的定位,极大的提升了算法的运算速度。由于应用场合的多变,逐渐有人意识到仪表的定位仅仅通过传统的图像处理方式难以得到,加之机器学习逐渐步入到大众的眼里,杨传旺受Adaboost训练器在人脸识别上的运用启发,将Adaboost应用到仪表识别中,实现复杂背景下仪表的定位。刘葵则将深度学习与仪表检测结合,使用Faster-RCNN网络实现在相似物的干扰下对表盘较好的提取。
对于数字式仪表识别,与之相关联的主要技术是字符分割与识别,数显式仪表的字符识别是OCR(光学字符识别)的重要组成部分,OCR技术在数显仪表上的运用是比较广的,周曼等人用EAST全卷积神经网络进行文字检测,再结合CNN-LSTM-CTC进行文字识别,完成工业现场数显式仪表的自动识别。郭爽采用穿线法结合模板匹配实现数字式仪表自动识别。唐轶俊等人基于BP神经网络来实现数显仪表数字字符识别系统的搭建。范建斌基于支持向量机的方式对仪表数字显示值识别展开研究,采用一对一及一对多的方法结合有效解决了数字的识别问题。马冲基于多卷积特征编码的Multi--Conv-SSD深度学习技术结合关键点检测技术实现对电子示数的自动识别。由以上仪表识别研究现状可知,针对仪表的检测与识别,国内外已开展很多相关的研究工作,但由于指针式仪表与数字式仪表识别原理截然不同,导致二者的识别方案无法兼容,算法也难以适用,使得在仪表识别前首先对仪表类型进行分类成为了一种需求。随着理论技术和硬件设备的发展和完善,机器视觉技术的用途越加广泛,从传统图像处理到机器学习,再到深度学习,这些技术的发展在仪表识别上都具备很好的应用前景,由以上仪表识别研究现状可知,针对仪表的检测与识别,国内外已开展很多相关的研究工作,但由于指针式仪表与数字式仪表识别原理截然不同,导致二者的识别方案无法兼容,算法也难以适用,使得在仪表识别前首先对仪表类型进行分类成为了一种需求。随着理论技术和硬件设备的发展和完善,机器视觉技术的用途越加广泛,从传统图像处理到机器学习,再到深度学习,这些技术的发展在仪表识别上都具备很好的应用前景,在本文中也会结合各项技术的优点来制定仪表识别的方案,就仪表识别这一内容展开深入的研究。
1.3课题研究的主要内容
本文以自主巡航机器人拍摄的仪表图像和固定点位摄像头拍摄的仪表图像为研究对象,摄像头固定在机器人平台上处于运动状态,而识别的仪表包括指针式及数字式两类仪表,基于以上背景,仪表检测与识别工作包括以下几个部分:仪表的定位及分类研究、仪表角度校正配准研究、仪表识别读数研究,包括指针式仪表识别和数字式仪表识别两类。指针式仪表识别包括图像增强、仪表分度值求解、指针拟合、数字刻度定位及读数误差校正。数字式仪表识别包括数字提取、分割和识别。
第二章 需求分析
2.1图像分析需求
仪表类型:1.指针仪表,需要分析出两个指针对应的数字; 2.单指针仪表,需要分析出指针对应的数字; 3.数字仪表,需要分析出每个仪表的数字。图像识别服务运行于中心平台,积成电子平台提供web服务提供图像文件并接收线路通道图像识别结果。
请求格式:{"taskid": "20220623220601", "pictures": [{"picid": "001","picname": "001.jpg","url": "http://192.168.1.1/001.jpg"}]}
响应格式:{"taskid": "20220623220601","result": [{"meter_type":"pointer","reading":19.02}{"meter_type":"pointer""reading":19.02}……]}
2.2 可行性分析
数据可行性:
训练数据集采用了工厂车间的真是仪表图片,图片由云台摄像头在若干固定点位拍摄,部分室外仪表图片由站内机器人拍摄。
技术可行性:
YOLOv5的检测速度可以达到工业应用要求;在预处理阶段处理得当的情况下,八段码识别可以有效检测出小数点位置。霍夫变换有在指针检测方面应用的潜力。
硬件可行性:
硬件上符合实验要求,模型已经在机器上训练完毕,机器完全可以承担当前工作量的数据训练,可以保证在预算内完成训练。
2.3 项目设计制约因素
本项目才用的算法均为已经证实且广泛应用于工业场景的技术,代码执行对算力的要求在机器的算力范围内,不会导致机器过热而造成直接或间接的生命财产损失。本项目功能包括且仅限于对工业仪表的检测和读数,不含任何可能违反相关法律法规的功能,且视频或图像数据由使用的第三方提供,与本人无关。本项目中的一些内容以及呈现效果均是为了仪表检测而创作,尊重一切地方文化和习俗,无不良信息传播或不良行为引导。队编写或采用开源代码,不存在侵犯他人知识产权的行为,若用户在使用过程中发现疑似侵权行为请联系作者,将第一时间确认并删除相关内容。代码在windows10下使用pycharm编写,且可以在ubuntu系统下正常使用,理论在任何linux或windows系统下均可正常运行,不会由于地方风俗差异而导致使用过程中存在差别。用户在使用过程中请注意机器的使用情况,避免过负荷使用电脑以免硬件电磁污染及高温导致的电路材料对健康的影响。
第三章 基于yolov5、霍夫变换、穿线法的多类仪表识别方法
3.1 baseline方法
3.1.1 yolov5方法
YOLO将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。从网络设计上,YOLO与rcnn、fast rcnn及faster rcnn的区别如下:YOLO训练和检测均是在一个单独网络中进行。YOLO没有显示地求取region proposal的过程。而rcnn/fast rcnn 采用分离的模块(独立于网络之外的selective search方法)求取候选框(可能会包含物体的矩形区域),训练过程因此也是分成多个模块进行。Faster rcnn使用RPN(region proposal network)卷积网络替代rcnn/fast rcnn的selective search模块,将RPN集成到fast rcnn检测网络中,得到一个统一的检测网络。尽管RPN与fast rcnn共享卷积层,但是在模型训练过程中,需要反复训练RPN网络和fast rcnn网络(注意这两个网络核心卷积层是参数共享的)。YOLO将物体检测作为一个回归问题进行求解,输入图像经过一次inference,便能得到图像中所有物体的位置和其所属类别及相应的置信概率。而rcnn/fast rcnn/faster rcnn将检测结果分为两部分求解:物体类别,物体位置即bounding box。YOLO检测网络包括24个卷积层和2个全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果。YOLO网络借鉴了GoogLeNet分类网络结构。看GoogLeNet。不同的是,YOLO未使用inception module,而是使用1x1卷积层+3x3卷积层简单替代。
YOLO论文中,作者还给出一个更轻快的检测网络fast YOLO,它只有9个卷积层和2个全连接层。使用titan x GPU,fast YOLO可以达到155fps的检测速度,但是mAP值也从YOLO的63.4%降到了52.7%,但却仍然远高于以往的实时物体检测方法的mAP值。YOLO将输入图像分成SxS个格子,每个格子负责检测落入该格子的物体。若某个物体的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这个物体。
Bounding box信息包含5个数据值,分别是x,y,w,h,和confidence。其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。w,h是bounding box的宽度和高度。注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到[0,1]区间内并且被归一化到[0,1]。confidence反映当前bounding box是否包含物体以及物体位置的准确性。
因此,YOLO网络最终的全连接层的输出维度是 S*S*(B*5 + C)。YOLO使用均方和误差作为loss函数来优化模型参数,即网络输出的S*S*(B*5 + C)维向量与真实图像的对应S*S*(B*5 + C)维向量的均方和误差。如下式所示。其中,coordError、iouError和classError分别代表预测数据与标定数据之间的坐标误差、IOU误差和分类误差。
YOLO模型训练分为两步:
1)预训练。使用ImageNet
1000类数据训练YOLO网络的前20个卷积层+1个average池化层+1个全连接层。训练图像分辨率resize到224x224。
2)用步骤1)得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,然后用VOC 20类标注数据进行YOLO模型训练。为提高图像精度,在训练检测模型时,将输入图像分辨率resize到448x448。
综上,YOLO具有如下优点:
1. YOLO将物体检测作为回归问题进行求解,整个检测网络pipeline简单。在titan x GPU上,在保证检测准确率的前提下,可以达到45fps的检测速度。
2. YOLO在训练和推理过程中关注整张图像的整体信息,而基于region proposal的物体检测方法(如rcnn/fast rcnn),在检测过程中,只关注候选框内的局部图像信息。因此,对于后者,若当图像背景中的部分数据被包含在候选框中送入检测网络进行检测时,容易被误检测成物体。测试证明,YOLO对于背景图像的误检率低于fast rcnn误检率的一半。
3.通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。
但相比RCNN系列物体检测方法,YOLO具有以下缺点:
1.识别物体位置精准性差。
2.召回率低。
3.1.2 霍夫变换方法
经过定位及角度校正后的仪表即可进行识别读数,本文从人工读数的角度出发,采用以指针为桥梁,借助EAST文本定位网络对仪表进行读数的方法,摆脱了已有视觉识别方案受限于指针起点及仪表量程的缺陷,首先对目标图像进行增强处理,便于后续的轮廓及刻度提取,然后对仪表中心定位,借助圆心特征求出仪表的最小刻度角,采用直线检测和直线拟合对指针进行提取定位,采用文本定位网络模型结合轮廓筛选算法对表盘文本进行定位,找到距离指针最接近的两个刻度数字并进行识别,通过对文本的中心特征提取计算得到相邻刻度间的夹角值,结合刻度识别结果求得分度值信息,最终由指针位置和分度值确定最终的仪表读数。
经过ACE增强处理后刻度特征已经能被提取得到,结合圆心坐标及仪表轮廓特征,即可对仪表的刻度特征进行计算,得到最小夹角信息。主要流程包括刻度特征提取、刻度筛选、连接圆心及刻度轮廓中心、刻度特征信息排序、计算相邻连线夹角,刻度夹角计算等。首先对图像进行二值化处理,通过轮廓提取算法可以实现对表盘刻度特征的提取,将所有轮廓的最小矩形边界的四个坐标点保存在向量组中,所有轮廓特征内,可称为形状特征筛选;二是对轮廓中心与圆心的距离筛选,刻度中心到圆心的距离与表盘半径存在一定的关系,可称为距离特征筛选。中包含了部分非刻度信息(如数字轮廓),为了排除这些非刻度特征的干扰,采用如下两种轮廓筛选算法:一是通过轮廓区域面积,区域周长,长宽比筛选得到符合要求的大部分轮廓,刻度本身的面积周长以及长宽比都在固定区间。
指针的定位实质是基于直线的检测,直线检测常见的方法有霍夫直线检测,LSD直线检测,霍夫直线检测是基于概率统计的方式实现的,需要设置合理的阈值。本文采用的方法是LSD直线检测算法,相比与霍夫直线检测算法,LSD算法的检测准确性更高,且不受限于其他参数。LSD算法通过对图像进行高斯模糊采样减弱锯齿效应,再对像素点进行梯度计算,梯度大小可定义为: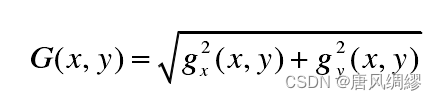 。然后对梯度进行伪排序,将梯度分为1024个桶,将梯度放入相应的桶中,属于同一梯度的点越多,是直线的概率也就越大,然后经过区域生长算法,将梯度小于P的设为USED,梯度大于P的设为NOT USED,遍历排序表内的像素m,若m的梯度标记为NOT USED,搜索其周围同样属于NOT USED的且方向在设定阈值内的像素,将其标记改为USED,重复上述过程得到一个生长区域Region,再对这个区域进行矩形构造,矩形的中心点可由以下关系式确定:
。然后对梯度进行伪排序,将梯度分为1024个桶,将梯度放入相应的桶中,属于同一梯度的点越多,是直线的概率也就越大,然后经过区域生长算法,将梯度小于P的设为USED,梯度大于P的设为NOT USED,遍历排序表内的像素m,若m的梯度标记为NOT USED,搜索其周围同样属于NOT USED的且方向在设定阈值内的像素,将其标记改为USED,重复上述过程得到一个生长区域Region,再对这个区域进行矩形构造,矩形的中心点可由以下关系式确定: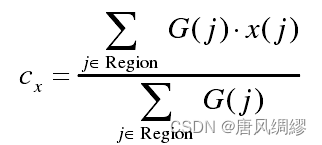
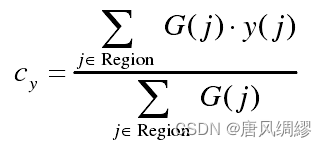
矩形的长宽由最小包围框确定,同时矩形内梯度要保证一致,最终得到矩形的中线即可认为是检测到的直线。下图为采用LSD检测算法来对指针实现检测的结果,其中红色线段就是LSD算法检测结果,可以看到算法对直线段的检测灵敏度较高,其中大部分并非指针所在位置的直线段,因此需要对检测结果进行分析处理。从检测结果可知指针上的直线特征要比其他区域的直线特征更加明显,图b依据长度特征对检测结果进行一次筛选,在一次筛选结果基础上对所有直线依据中点位置信息进行二次筛选,在筛选后的所有直线中,大部分直线的斜率与指针的中线斜率一致,依据斜率一致性特征找到所有斜率相近的直线段,收集这些线段的端点,最后将这些端点进行直线拟合,拟合后的直线必过圆心,图中灰色的点代表的是筛选得到的直线的端点,蓝色细线是由这些点以及圆心一起拟合得到的指针中心线,可以看到最终拟合得到的指针与指针实际的位置是基本吻合的。

3.1.3 穿线法检测数字
像素投影分割数字是通过对每行每列的图像像素进行扫描,统计所有不是黑色(背景色)的像素之和,最终依据每行每列的求和结果可以绘制出一幅数字像素分布直方图,是投影得到的像素分布直方图,依据投影结果找到所有数字的四个坐标值即可提取出所有数字。
经过定位算法后虽然已经较精确的锁定数字区域了,可受背景色的干扰,无法提取到每个数字的边界,仍旧无法对数字进行识别,所以首要工作是将数字轮廓全部提取出来,最直接的方式就是通过对像素值进行阈值分割提取,实验发现直接对图像的RGB三通道进行阈值筛选始终无法得到效果较好的数字轮廓图,这是因为RGB颜色空间利用三个颜色分量的线性组合来表示颜色,任何颜色都与这三个分量有关,由于三个颜色分量相关性较大,导致连续变换颜色时并不直观,自然环境下获取的图像容易受自然光照、遮挡和阴影等情况的影响,即对亮度比较敏感。而RGB颜色空间的三个分量都与亮度密切相关,即只要亮度改变,三个分量都会随之相应地改变,所以在进行像素提取时,RGB颜色空间下很难达到预期效果,本文将RGB转化为HSV颜色空间,再进行像素轮廓的提取,HSV比RGB更接近人们对彩色的感知经验,非常直观地表达颜色的色调、鲜艳程度和明暗程度,方便进行颜色的对比,所以HSV颜色空间下,比RGB更容易跟踪某种颜色的物体,常用于分割指定颜色的物体。
数显式仪表的数字与手写数字有较大的差别,无法直接用OCR进行识别,否则个别字体的误检率极高。在训练手写数字识别网络的数据集中也并不包含有标准的数码管格式的样本,所以得到的模型对本节的数字识别是不具备通用性的,那么解决办法除了再训练一个专用的网络模型,就只有从其他图像特征出发来达到识别目的。数码管的显示原理是通过控制每一段灯的亮灭来达到不同的数字显示效果的,在程序里每一个数字对应着一个八位二进制的编码,代表七段数码管以及小数点的亮灭情况,可依据该特征采用穿线法来对数显式仪表中的数字进行识别,原理为假设有三条穿过数码管的直线,三条线与七段数码管一共有七处相交的线段,通过对这七处相交的线段进行像素分析,像素之和大于阈值则置1,否则置0,数字1通过长宽比单独确定。
3.2 多类仪表检测识别方法
方法的输入数据为含有仪表图像帧的视频。代码尝试从外部接收到视频流信息,没有接受到则重复尝试直至超出某一限定次数报错。若正常读取到视频流,则初始化视频读取类字典,从配置文件中获取所需配置信息。然后初始化任务模型,初始化任务检测器,视频流检测器每个任务一个。视频流检测器将视频按照每秒两帧的频率截取图片放入图片队列,检测器先从图像队列中获取数据,获取不到再从视频流队列获取数据。然后启动图像检测任务或视频流检测任务。检测器确认图像为正常检测图像且大小不为0后将图像(ndarray格式)传入预测模型。预测模型先用训练好的模型执行目标检测,返回目标的类型和坐标根据类型,将图片按照坐标进行裁剪、按类型进行标记,根据目标类型的不同程序会进入不同的预测模块,若目标类型为数字仪表,则进入数字仪表读数预测模型,对图形按照颜色阈值划分为二值图像,然后对二值图像做腐蚀膨胀,将每个电子字体分割,用穿针法检测七段码从而确定字体笔画,对于图像中目标的可能存在的倾斜角度,在此阶段需要在判断笔画时加入多种if条件,然后进行小数点的识别,具体实现方法为斜体数字的小数点识别,在数字区域内进行boundRect识别,将识别结果返回检测器;若目标类型为指针仪表,则进入指针仪表读数预测模型,在原有图像分割的基础上,需要进一步分割图形(以减少接下来霍夫直线检测阶段的噪声直线的干扰),然后进行霍夫直线检测,将霍夫检测结果放入list,若list为空,则说明检测失败或结果为空,返回NULL,否则检测出的唯一一条,或第一条直线即为指针位置所在直线,对该直线的参数(theta,rho)进行变换,得到直角坐标系上的坐标,将识别结果返回检测器。检测器按照配置文件中的要求将返回的结果放入字典中。检测器若接受到结果且结果不为空,则创建字典、写字典。将字段上传服务器对应存储路径。数字检测方面:由于目标图像在拍摄时存在倾斜,直接使用穿线法正确率极低,起初通过水平检测旋转图像进行位置修正,但适应性差不满足工业应用场景,于是采用新的方法:基于检测结果对笔画判断结果进行修改。效果相对较好。指针检测使用baseline方法可以检测出待检测指针所在直线,但有过多噪声直线干扰,无法正常进行角度判断。尝试调整霍夫检测精度以及判断直线的阈值,但效果不佳:若降低精度则指针所在直线可能无法被检测到,提高直线阈值会导致结果混乱原因不明。之后观察霍夫检测结果,发现有多条直线是在同一位置的重复检测,又尝试对霍夫检测结果进行剔除若两条直线的rho、theta之间满足一定关系,则认定为同一条直线,修改代码后再次运行,重复划线问题有效解决,减少了霍夫检测直线数量,之后设法筛选出目标直线,无果。对结果进行分析,发现干扰直线主要是由于仪表板干扰,于是尝试在原有分割结果的基础上对图像再次分割,找出其中的有意义部分,再次进行霍夫检测,基本符合预期。
3.3 实验分析
数据集为工厂中的真是仪表图片,由多个摄像头在若干固定点位拍摄的视频中截取得到。此外还有部分室外仪表,自主导航机器人拍摄得到。为提升图像目标检测的准确率,在训练过程中还采用了网上找到的1200张数字仪表图像。训练过程先用labelImg对所有图像进行标注,然后再预训练模型yolov5s的基础上继续训练,使用模型结果预测目标位置,分析预测结果从而逆向对模型结果进行微调。官方说明预测速度为CPU每张平均预测时间为0.23秒,使用GPU则平均时间降至0.16秒。实际应用中预测时间与官方说明相差不大,而在整体使用流程中,时间开销主要体现在读视频流和数据前后端传递过程中。相比于改进前的yolo方法,对单张图像的预测,每次完成预测都会结束进程,再次预测需要重新加载模型速度极慢,而如果要预测多张图片,就必须要将待预测的所有图片都放在某一文件夹中,无法在实时预测过程中添加新数据。模型改进后,实现了此功能,且删除了yolo自带的部分默认运行但与本项目无关的代码,预测速度明显提升且有更高的实用价值。
第四章 多类仪表检测系统的设计与实现
4.1技术方案
4.1.1 总体设计思路
程序尝试从外部接收到视频流信息,没有接受到则重复尝试直至超出某一限定次数报错。若正常读取到视频流,则初始化视频读取类字典,从配置文件中获取所需配置信息。然后初始化任务模型,初始化任务检测器,视频流检测器每个任务一个。视频流检测器将视频按照每秒两帧的频率截取图片放入图片队列,检测器先从图像队列中获取数据,获取不到再从视频流队列获取数据。然后启动图像检测任务或视频流检测任务。检测器确认图像为正常检测图像且大小不为0后将图像(ndarray格式)传入预测模型。预测模型先用训练好的模型执行目标检测,返回目标的类型和坐标根据类型,将图片按照坐标进行裁剪、按类型进行标记,根据目标类型的不同程序会进入不同的预测模块,若目标类型为数字仪表,则进入数字仪表读数预测模型,对图形按照颜色阈值划分为二值图像,然后对二值图像做腐蚀膨胀,将每个电子字体分割,用穿针法检测七段码从而确定字体笔画,对于图像中目标的可能存在的倾斜角度,在此阶段需要在判断笔画时加入多种if条件,然后进行小数点的识别,具体实现方法为斜体数字的小数点识别,在数字区域内进行boundRect识别,将识别结果返回检测器;若目标类型为指针仪表,则进入指针仪表读数预测模型,在原有图像分割的基础上,需要进一步分割图形(以减少接下来霍夫直线检测阶段的噪声直线的干扰),然后进行霍夫直线检测,将霍夫检测结果放入list,若list为空,则说明检测失败或结果为空,返回NULL,否则检测出的唯一一条,或第一条直线即为指针位置所在直线,对该直线的参数(theta,rho)进行变换,得到直角坐标系上的坐标,将识别结果返回检测器。检测器按照配置文件中的要求将返回的结果放入字典中。检测器若接受到结果且结果不为空,则创建字典、写字典。将字段上传服务器对应存储路径。
4.1.2 系统整体功能模块
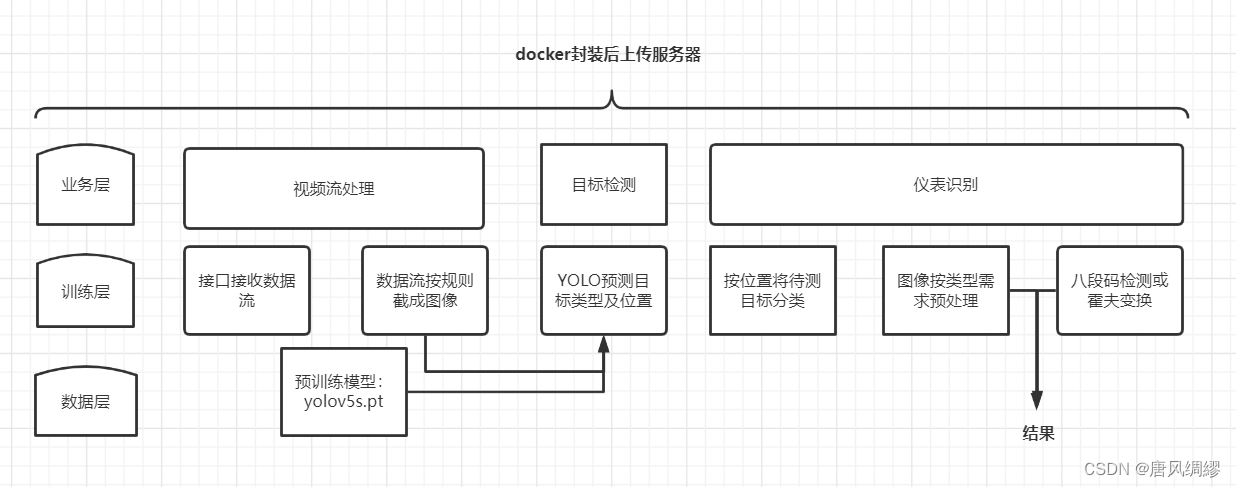
4.2 模块1 视频流读取
尝试从外部接收到视频流信息,没有接受到则重复尝试直至超出某一限定次数报错。若正常读取到视频流,则初始化视频读取类字典,从配置文件中获取所需配置信息。然后初始化任务模型,初始化任务检测器,视频流检测器每个任务一个。尝试从外部接收到视频流信息,没有接受到则重复尝试直至超出某一限定次数报错。若正常读取到视频流,则初始化视频读取类字典,从配置文件中获取所需配置信息。然后初始化任务模型,初始化任务检测器,视频流检测器每个任务一个。
4.3 模块2 检测器
视频流检测器将视频按照每秒两帧的频率截取图片放入图片队列,检测器先从图像队列中获取数据,获取不到再从视频流队列获取数据。然后启动图像检测任务或视频流检测任务。检测器确认图像为正常检测图像且大小不为0后将图像(ndarray格式)传入预测模型。当接收器收到预测模块的结果时,检测器按照配置文件中的要求将返回的结果放入字典中。检测器若接受到结果且结果不为空,则创建字典、写字典。将字段上传服务器对应存储路径。
4.4 模块3 预测模块
预测模型先用训练好的模型执行目标检测,返回目标的类型和坐标根据类型,将图片按照坐标进行裁剪、按类型进行标记,根据目标类型的不同程序会进入不同的预测模块,若目标类型为数字仪表,则进入数字仪表读数预测模型,对图形按照颜色阈值划分为二值图像,然后对二值图像做腐蚀膨胀,将每个电子字体分割,用穿针法检测七段码从而确定字体笔画,对于图像中目标的可能存在的倾斜角度,在此阶段需要在判断笔画时加入多种if条件,然后进行小数点的识别,具体实现方法为斜体数字的小数点识别,在数字区域内进行boundRect识别,将识别结果返回检测器;若目标类型为指针仪表,则进入指针仪表读数预测模型,在原有图像分割的基础上,需要进一步分割图形(以减少接下来霍夫直线检测阶段的噪声直线的干扰),然后进行霍夫直线检测,将霍夫检测结果放入list,若list为空,则说明检测失败或结果为空,返回NULL,否则检测出的唯一一条,或第一条直线即为指针位置所在直线,对该直线的参数(theta,rho)进行变换,得到直角坐标系上的坐标,将识别结果返回检测器。
第五章 系统测试
5.1 在windows系统下的测试
在windows系统下进行本地测试你(使用软件:pycharm)可正常启动服务,使用postman让服务get图片,设置接口http://127.0.0.1:5002/api/v0.1/download/pointer2.jpg程序返回127.0.0.1 [04/Jul/2022 11:15:26] "GET /api/v0.1/download/pointer2.jpg HTTP/1.1" 200
[2022-07-04 11:15:26] - [werkzeug] - [INFO] - 127.0.0.1 [04/Jul/2022 11:15:26] "GET /api/v0.1/download/pointer2.jpg HTTP/1.1" 200 127.0.0.1 [04/Jul/2022 11:15:26] "GET /api/v0.1/download/pointer2.jpg HTTP/1.1" 200 证明程序可以正常接受外部图像。将图像接口设为api/v0.1/picture,post http://127.0.0.1:5010/api/v0.1/picture,post内容为{
"taskid": "20220623220601",
"pictures": [
{
"picid": "001",
"picname": "001.jpg",
"url": "http://127.0.0.1:5010/api/v0.1/download/pointer2.jpg"
}
]
}
后端执行预测,返回{
"result": [
{
"results": [
{
"reading": 0,
"type": "pointer"
},
{
"reading": 64.0,
"type": "pointer"
},
{
"reading": 40.0,
"type": "pointer"
},
{
"reading": 37.0,
"type": "pointer"
}
],
"taskid": "20220623220601"
}
],
"taskid": "20220623220601"
}
证明程序正常运行,分析结果说明图像中共含四个仪表,均为指针类型仪表,读数分别为:0,64,40,37。
5.2 linux系统上运行
本测试采用xshell远程访问Ubuntu系统,测试过程与结果与5.1一致。
5.3 在web服务平台运行
首先在linux系统上对程序用docker封装,镜像上传至目标linux系统后创建容器,设置端口后台运行,效果由甲方测试检验。
第六章 总结与展望
6.1工作总结
本文基于自主巡航机器人平台对指针式仪表及数字式仪表两大类别仪表的自动检测与识别方法展开了研究,该套方法可以在移动平台下对拍摄到的图片中的目标物进行多目标定位及分类,然后通过图像配准校正仪表的角度和位置,对于指针式仪表,通过对指针及刻度轮廓进行提取、表盘刻度数字文本定位,结合人眼对指针式仪表进行读数的方式及逻辑,制定了一套适用性广,精确性高的读数算法;针对数字式仪表,通过目标定位,颜色空间转换、数字提取以及数字分割,结合数字识别及小数点分离算法,完成了对数显式仪表的读数识别。
5.2 下一步的工作计划
本文针对自主巡航机器人拍摄的仪表图像进行识别读数研究,考虑到拍摄到的目标物所处背景及角度随时在发生变化,对图像目标检测,图像配准展开了相应的研究;通过目标检测得到拍摄物的坐标及类别,结合为不同种类仪表制定的识别算法,使得算法的适用性大大增强。提出的基于最小刻度角的指针式仪表读数校正及自适应高度截断定位小数点方法为相关领域提供了可参考的解决方案。不过由于时间有限在本课题的研究中,还存在一些值得改善的研究点,主要如下:
1.采用基于特征点实现仪表配准的方法是存在缺陷的,需要有一张标准的图片作为参考图,这是采用传统方式进行图像配准都会存在一个缺陷,可以考虑引入深度学习进行特征提取,以监督的方式训练出每张图片进行图像变换所需的变换矩阵参数,从而摆脱依赖标准图片进行特征匹配的限制。
2.文本检测网络定位表盘上的数字时效果不是很好,这主要是由于采用的数据集不是专用数据集,导致呈现出的效果大打折扣,后期可以考虑针对表盘数字定位制作专用的数据集用于网络的训练,在标注时只需要标注数字,其他文字不要标注,可以大大提高模型的精确率。
3.指针式仪表及数字式仪表识别算法中都涉及到了数字的识别,两者数字虽然存在较大的特征差异,可是通过目标识别神经网络模型有机会将两部分的数字识别合并为一个模块,能大大简化整体的算法流程。
















 944
944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









