







《The Forward-Forward Algorithm: Some Preliminary Investigations》
摘要
目的:介绍一种新的神经网络学习过程,并证明它在一些小问题上工作得足够好,值得进一步研究。
方法:
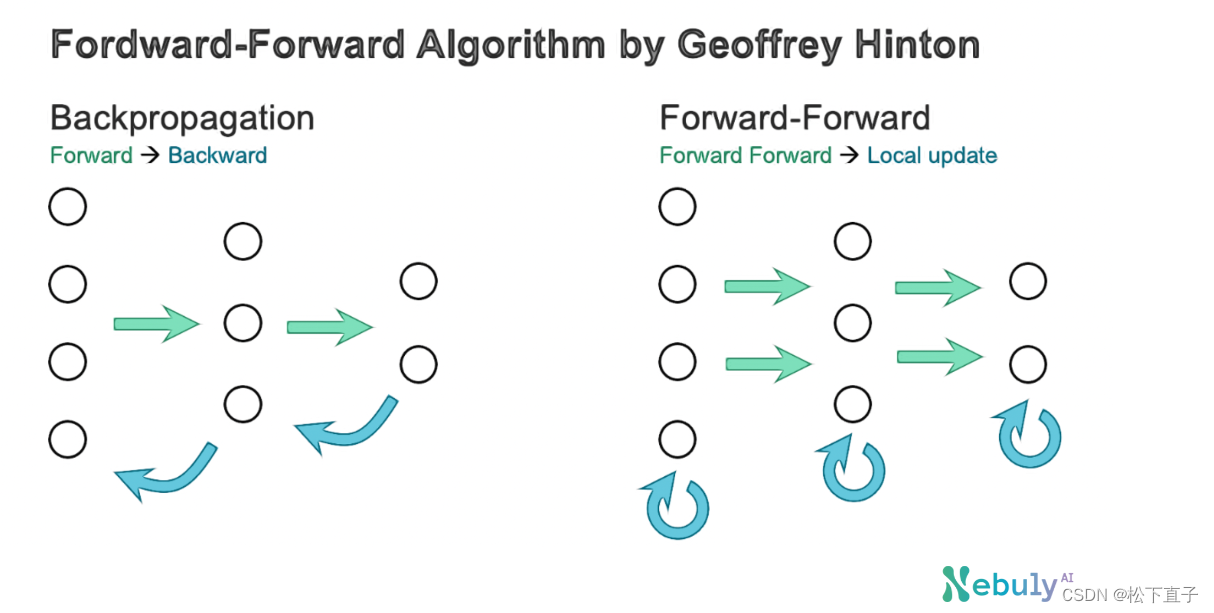
- forward - forward算法将反向传播的前向和后向传递替换为两个前向传递
- 一个是正数据(即真实数据),另一个是由网络本身生成的负数据。
- 每一层都有自己的目标函数,即正面数据有高优度,负面数据有低优度。
- 一个层中活动平方和可以用作优度,但还有许多其他可能性,包括减去活动平方和
- 如果正传递和负传递可以及时分离,负传递可以离线完成
- 这将使正传递中的学习简单得多,并且允许视频在网络中流水线传输,而无需存储活动或停止传播导数。
反向传播存在的问题
- 没有令人信服的证据表明,皮层明确地传播误差导数或存储神经活动,以用于后续的向后传递
- 通过时间反向传播作为一种学习序列的方式尤其不可信
- 为了在不频繁暂停的情况下处理感觉输入流,大脑需要通过不同的感觉处理阶段来处理感觉数据
- 后面阶段的表示可以提供自上而下的信息,这些信息在后面的时间步骤中影响前面阶段的表示,但是感知系统需要实时执行推理和学习,而不能停止执行反向传播。
- 需要完全了解正向传递中执行的计算,以便计算正确的导数
- 如果我们在正向通道中插入一个黑盒,就不可能再进行反向传播,对于前向-前向算法,黑匣子根本不会改变学习过程,因为不需要通过它进行反向传播
- 在没有一个完美的正向传递模型的情况下,总是可以求助于多种形式的强化学习中的一种。其思想是对权重或神经活动进行随机扰动,并将这些扰动与收益函数的结果变化联系起来。
- 但是强化学习过程受到高方差的影响:当许多其他变量同时被扰动时,很难看到扰动一个变量的效果。为了平均掉所有其他扰动引起的噪声,学习率需要与被扰动的变量数量成反比,这意味着强化学习的规模很糟糕,无法与反向传播竞争包含数百万或数十亿个参数的大型网络。
本文方法:
- 包含未知非线性的神经网络不需要求助于强化学习。
- 前向-前向算法(FF)在速度上与反向传播相当,它的优点是可以在前向计算的精确细节未知时使用。
- 另一个优点是,可以在学习的同时通过神经网络传输顺序数据,而无需存储神经活动或停止传播误差导数。
- forward-forward算法比反向传播算法稍慢,在本文研究的几个小问题上也不能很好地推广,因此它不太可能在功率不是问题的应用中取代反向传播算法。
- 在非常大的数据集上训练的非常大的模型的能力的令人兴奋的探索将继续使用反向传播。
- 前向-前向算法优于反向传播的两个方面是作为一种皮层学习模型,以及作为一种利用非常低功耗的模拟硬件而不求助于强化学习的方法
Forward-Forward算法
- Forward-Forward算法是一种贪婪的多层学习过程,灵感来自玻尔兹曼机和噪声对比估计
- 其思想是将反向传播的正向传递和反向传递替换为两个正向传递,这两个正向传递以完全相同的方式相互作用,但基于不同的数据和相反的目标。
- 正传递对真实数据进行操作,并调整权重以增加每个隐藏层的优度。
- 负传递对“负数据”进行操作,并调整权重以减少每个隐藏层的优度。
- 本文探讨了两种不同的优度度量——神经活动平方和和和活动平方和,但还有许多其他度量是可能的。
假设一层的优度函数只是该层中校正的线性神经元活动的平方和,学习的目的是使优度远高于真实数据的某个阈值,而远低于负数据的某个阈值
输入向量为正数(即实数)的概率是通过应用逻辑函数给出的,σ为sigmoid,阈值θ
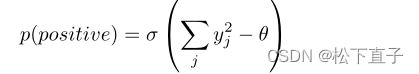
其中yj为隐藏单元j在层归一化前的活动。负面数据可以由神经网络使用自顶向下的连接来预测,也可以由外部提供
和之前反向传播将误差从最后一层往前传不同:它不需要从最后一层将误差传递过来更新每一层的权值,而是每一层自己使用正负样本的计算来调整权值。
一个hidden unit的yj对于正样本来说总是高的,对于负样本总是低的,这样通过看平方之后的数值就能直接判断好坏样本了,为了让后边的隐藏层能不被这个信息影响学习,在第一个隐藏层后悔做一个归一化,消除掉数值大小的信息
使用简单的分层优度函数学习多层表示
- 可以通过使隐藏单元的活动平方和对于正数据为高,对于负数据为低来学习单个隐藏层。
- 但是如果第一个隐藏层的活动被用作第二个隐藏层的输入,那么仅仅通过第一个隐藏层的活动向量的长度来区分正数据和负数据是微不足道的。为了防止这种情况,FF将隐藏向量的长度归一化,然后将其作为下一层的输入
- 这删除了第一个隐藏层中用于确定优度的所有信息,并迫使下一个隐藏层使用第一个隐藏层中神经元相对活动中的信息。
- 这些相关的活动不受层规范化的影响。
- 换句话说,第一个隐藏层中的活动向量有长度和方向。
- 长度用于定义该层的优度,只有方向被传递到下一层。
未来工作
对Forward-Forward算法的研究才刚刚开始,还有许多悬而未决的问题:
- FF能否生成一个图像或视频的生成模型,足以创建无监督学习所需的负数据?
- 最好的优度函数是什么?本文在大多数实验中使用活动平方和,但对积极数据最小化活动平方和,对消极数据最大化活动平方和似乎更好一些。最近,只要最小化正数据上的未平方和(最大化负数据上的未平方和)就能很好地工作22。
- 最好的激活函数是什么?到目前为止,只有relu被探索过。在FF的背景下,还有许多其他的可能性,它们的行为没有被探索。使激活为t分布下密度的负对数是一种有趣的可能性。
- 对于空间数据,FF能否从图像不同区域的大量局部优度函数中受益?如果这种方法可行,学习速度应该会快得多。
- 对于顺序数据,是否可以使用快速权重来模拟简化的变压器?
- FF是否可以从拥有一组试图最大化其平方活动的特征检测器和一组试图最小化其平方活动的约束违反检测器中受益?
















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











