







文章目录
Source-Free Domain Adaptive Fundus Image Segmentation with Class-Balanced Mean Teacher
摘要
本文研究了无源域自适应眼底图像分割,旨在使用未标记图像将预训练的眼底分割模型调整到目标域。这是一项具有挑战性的任务,因为仅使用未标记的数据调整模型的风险很高。大多数现有方法主要通过设计技术来从模型的预测中仔细生成伪标签,并使用伪标签来训练模型。虽然这些方法经常获得积极的适应效果,但存在两个主要问题。首先,它们往往相当不稳定 - 突然出现不正确的伪标签可能会对模型造成灾难性的影响。其次,他们没有考虑眼底图像的严重类别不平衡,其中前景区域通常非常小。
本文旨在通过提出类别平衡平均教师(CBMT)模型来解决这两个问题。CBMT通过提出一种弱强增强平均教师学习方案来解决不稳定问题,其中只有教师模型从弱增强图像生成伪标签,以训练以强增强图像作为输入的学生模型。教师被更新为即时训练学生的EMA,这可能会很嘈杂。这样可以防止教师模型突然受到不正确的伪标签的影响。针对类不平衡问题,CBMT提出了一种新颖的损耗校准方法,根据全局统计来突出前景类。实验表明,CBMT很好地解决了这两个问题,并且在多个基准上优于现有方法。
代码地址
方法
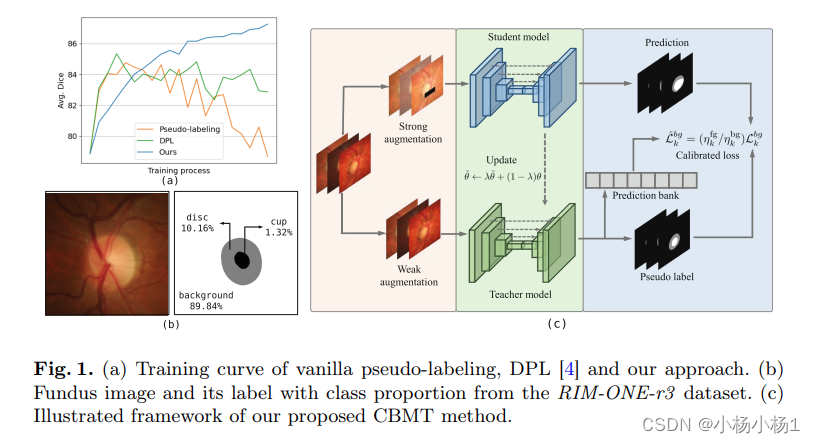
图C为本文的主要方法,从图中可以看出,前面两部分为标准的mean Teacher结构,就不要过多叙述了,主要看他的损失函数以及,Prediction bank
Global Knowledge Guided Loss Calibration
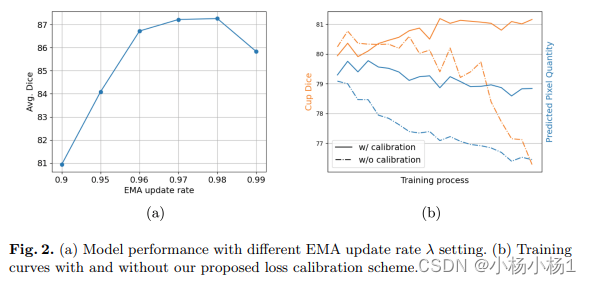
对于基础图像,前景对象通常非常小,并且大多数像素将作为背景。如果用交叉熵损失更新学生模型,背景类将主导损失,从而稀释了前景类的监督信号。所提出的全局知识引导损耗校准技术旨在解决这一问题。
解决前景和背景不平衡的幼稚方法是计算每个图像中分别属于这两个类别的像素数,并根据这些数字设计一个损失加权函数。这种策略可能适用于标准的监督学习任务,其中标签是可靠的。但是对于伪标签,基于单个图像进行统计分析的风险太大。为了解决这个问题,分析了整个数据集中的类不平衡,并利用这些全局知识来校准每个单独图像的损失。
具体来说,我们存储所有图像的像素预测,并将前景和背景的平均损失保持为:
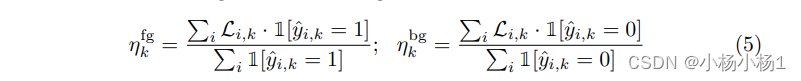
再通过得到的损失加权给背景损失函数
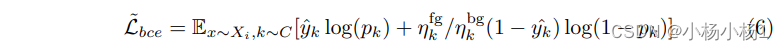
注意,他的Prediction bank大概率是指存储了所有图像的像素预测,这是我的理解
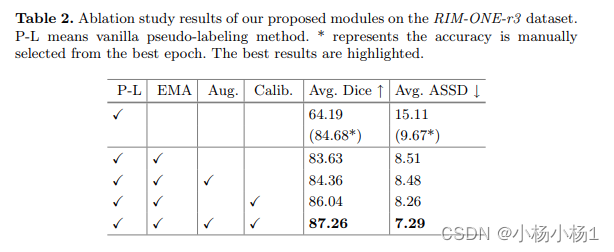
实验结果

















 6034
6034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











