






文章目录
前言
最近面试问到了很多关于项目中关于模型和算子量化的操作和原理,为了巩固一下深度学习基础,整理顺便自学。
提示:以下是本篇文章正文内容,下面案例可供参考
一、模型是什么?算子是什么?
1.概念
在机器学习和深度学习中,模型一般指从数据中学习并做出预测的完整系统或架构,算子通常指的是在图像处理或其他领域中,用于执行特定操作(如边缘检测、滤波等)的数学公式或算法。
2.区别
在实际应用中,算子可以作为构建模型的基础组件,例如在CNN中,卷积层的卷积操作可以看作是一种算子,而整个网络结构则是一个模型。
二、模型量化
2.1.按量化精度分类
模型量化是指将神经网络中的浮点数(如32位的FP32)转换为低位宽的表示形式,如16位的半精度浮点数(FP16)或8位的整数(INT8)。这样做可以显著减少模型的内存占用,提高推理速度,同时在适当的量化策略下,对模型的精度影响较小。
2.1.1量化为INT8的示例代码:
代码如下(示例):
import torch
import torchvision.models as models
import torch.quantization
import torchvision.transforms as transforms
import torchvision.datasets as datasets
# 定义一个简单的模型
class SimpleModel(torch.nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1)
self.relu = torch.nn.ReLU()
self.conv2 = torch.nn.Conv2d(16, 32, 3, padding=1)
self.pool = torch.nn.MaxPool2d(2, 2)
self.fc = torch.nn.Linear(32 * 16 * 16, 10)
def forward(self, x):
x = self.pool(self.relu(self.conv1(x)))
x = self.pool(self.relu(self.conv2(x)))
x = x.view(-1, 32 * 16 * 16)
x = self.fc(x)
return x
# 实例化模型并准备数据
model = SimpleModel()
model.eval()
# 准备量化配置
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
print(model.qconfig)
# 指定量化准备和量化过程
torch.quantization.prepare(model, inplace=True)
torch.quantization.convert(model, inplace=True)
# 保存量化后的模型
torch.save(model.state_dict(), 'quantized_model_int8.pth')
# 加载模型并进行推理
model.load_state_dict(torch.load('quantized_model_int8.pth'))
model.eval()
# 假设输入数据
input_data = torch.rand(1, 3, 224, 224)
# 使用INT8进行推理(需要额外的校准步骤)
# 这里只是一个示例,实际应用中需要使用校准数据集
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model, inplace=True)
torch.quantization.calibrate(model, calib_dataloader, inplace=True)
torch.quantization.convert(model, inplace=True)
# 校准模型(需要提供校准数据集)
# torch.quantization.calibrate(model, calib_dataloader, inplace=True)
torch.quantization.convert(model, inplace=True)
# 保存量化后的模型
torch.save(model.state_dict(), 'quantized_model_int8.pth')
# 加载量化后的模型
model.load_state_dict(torch.load('quantized_model_int8.pth'))
model.eval()
# 假设输入数据
input_data = torch.rand(1, 3, 224, 224)
# 使用INT8进行推理
with torch.no_grad():
output = model(input_data)
print(output)
在第一个示例中,我们首先定义了一个简单的卷积神经网络模型,使用PyTorch的量化API来将模型量化为INT8。
我们使用了get_default_qconfig来获取默认的量化配置,这个配置指定了量化的算法和位宽。接着,我们调用prepare函数来准备模型进行量化,然后使用convert函数将模型转换为量化版本。这个过程包括准备模型进行量化、校准(需要校准数据集)和转换模型。
在进行INT8量化时,通常需要一个校准步骤,这是因为INT8量化需要确定合适的比例因子和零点。校准通常使用一小部分数据(称为校准数据集)来估计这些参数。
在这个示例中,我们没有提供校准数据集,因此INT8量化部分被注释掉了。在实际应用中,校准步骤是必要的,因为它可以帮助确定量化参数,从而减少量化带来的精度损失。
2.1.2.使用FP16进行推理的示例代码:
代码如下(示例):
import torch
import torchvision.models as models
# 加载预训练模型
model = models.resnet18(pretrained=True)
model.eval()
# 将模型转换为半精度浮点数(FP16)
model = model.half()
# 假设输入数据
input_data = torch.rand(1, 3, 224, 224).half()
# 使用FP16进行推理
with torch.no_grad():
output = model(input_data)
print(output)
在第二个示例中,我们将模型和输入数据转换为半精度浮点数(FP16),这可以减少模型大小和提高推理速度。这种方法不需要对模型进行校准,因为它不涉及将权重转换为整数表示。
2.1.3.使用INT8和FP16进行推理的优势和潜在的挑战:
在使用FP16和INT8量化技术时,每种方法都有其特定的优势和潜在的挑战。
FP16量化的优势:
- 速度提升:FP16量化可以减少内存带宽需求和计算量,从而加快模型的推理速度。
- 内存占用减少:FP16模型占用的内存空间大约是FP32的一半,这在资源受限的设备上尤为重要。
- 能效比提升:FP16计算在GPU等硬件上通常具有更高的能效比,即单位功耗下的计算性能更高。
FP16量化的挑战:
- 精度损失:虽然FP16可以显著提升性能,但也可能带来一定的精度损失。
- 数值稳定性:在某些极端情况下,FP16可能会导致数值不稳定。
- 硬件兼容性:不是所有的GPU都支持FP16计算,需要确保硬件支持FP16并安装了相应的驱动和CUDA版本。
INT8量化的优势:
- 性能提升:INT8量化通过减少模型大小和计算复杂度,显著提升模型的推理性能。
- 内存占用减少:INT8量化可以进一步减少模型的存储需求,相比于FP16,INT8可以减少更多的内存占用。
- 功耗降低:INT8量化后的模型需要的计算资源更少,从而降低了能耗。
INT8量化的挑战:
- 精度损失:INT8量化可能会比FP16量化带来更大的精度损失,因为量化过程是近似的。
- 校准过程:INT8量化需要一个校准过程来确定合适的量化参数,这可能增加额外的计算负担。
- 硬件支持:虽然许多现代硬件支持INT8量化,但具体的支持程度和优化可能因平台而异。
在选择FP16还是INT8量化时,需要根据模型的复杂度、输入数据的大小、GPU型号以及对精度和速度的具体要求来决定。对于大型模型和复杂任务,FP16和INT8量化都可以带来显著的性能提升,但如果模型需要在资源受限的设备上运行,INT8量化可能是更合适的选择。在实际应用中,可能还需要进行充分的测试和调整,以确保量化后的模型满足精度和性能的要求。
当然还有其他的量化精度比如INT4,FP8等,不过INT8和FP16是目前比较常用的量化精度。
2.2按量化后是否需要调参分类
2.2.1 QAT(Quantization Aware Training)
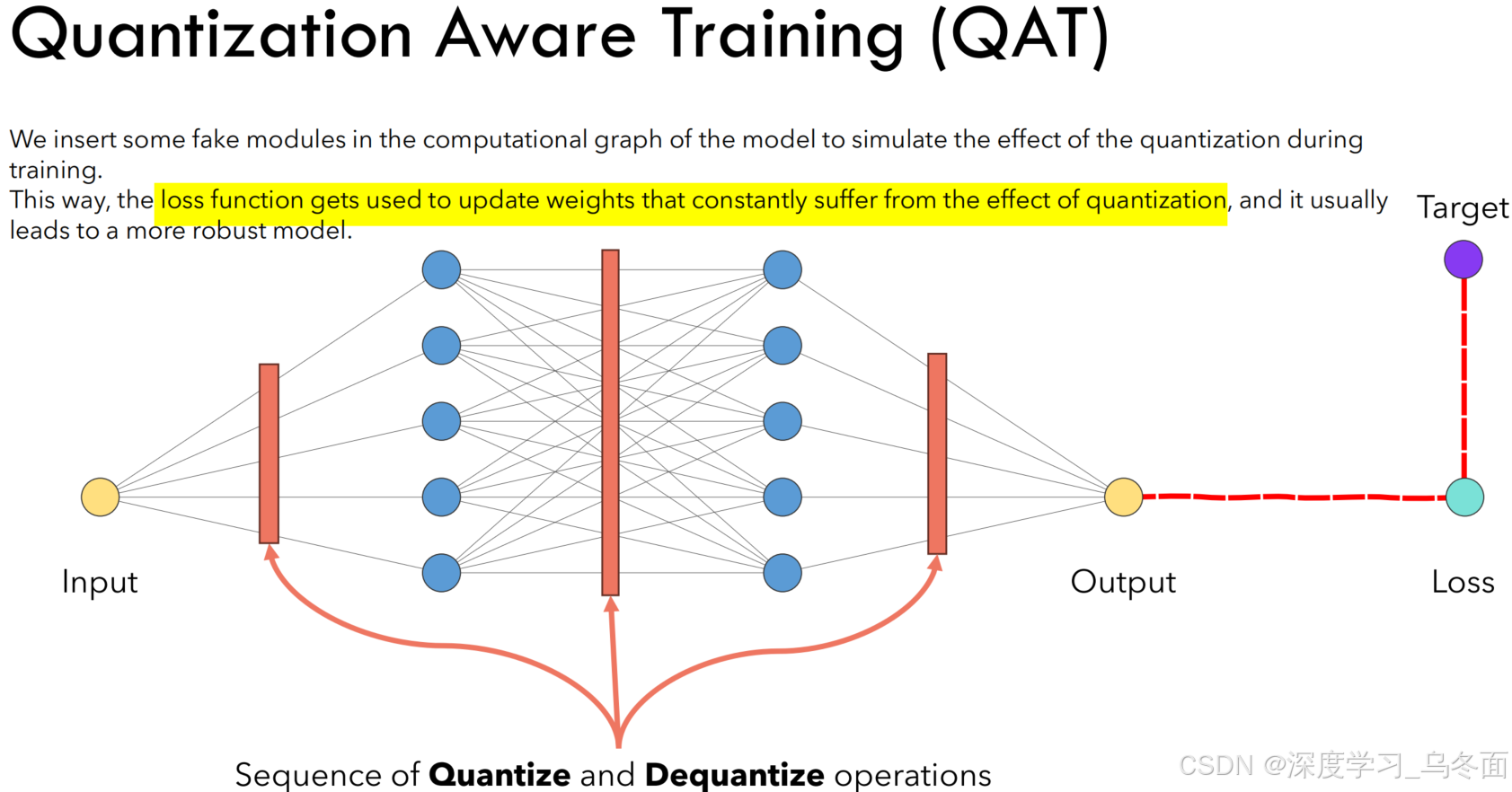
QAT是一种在模型训练过程中模拟量化操作的技术。它通过在模型的前向和后向传播中插入伪量化节点,让模型在训练时就适应量化带来的信息损失。QAT的关键步骤包括模拟量化、梯度近似和优化参数。这种方法可以显著减少量化对模型精度的负面影响,但会增加模型训练的时间和计算资源消耗。QAT适用于对模型精度要求较高的场景,尤其是当PTQ无法满足精度要求时 。
2.2.2 PTQ(Post Training Quantization)
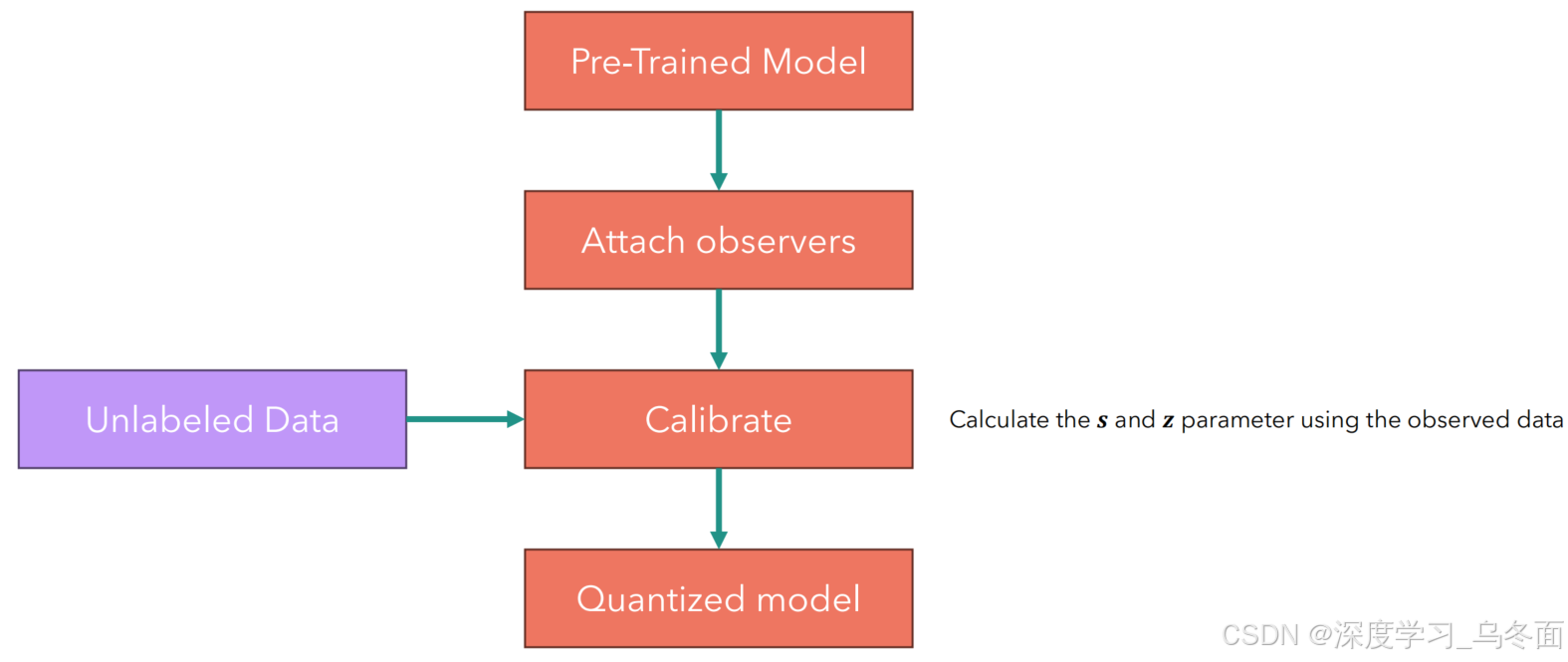
是在模型训练完成后进行的量化技术。它通过使用校准数据集来确定量化参数,然后将训练好的模型转换为定点计算的网络。PTQ的优势在于操作简单快速,无需额外训练,适合快速部署到资源受限的设备上。PTQ可能会导致模型精度的下降,因为它没有像QAT那样在训练过程中适应量化误差 。
2.3.按量化是否对称类
2.3.1 对称量化
- 特点:对称量化要求量化后的值中零点必须对应于原始值中的零,这意味着量化操作的零点固定不变。对称量化通常使用两个参数(量化的最小值和最大值)来定义量化的范围,而这个范围是以零为中心对称的。
- 优势:对称量化操作简单,易于实现,对于正负值分布均匀的数据集效果较好。
- 挑战:对于参数矩阵不是很对称的数据集,对称量化无法像非对称量化那样精确地表示数据范围,可能导致量化误差增加。
在实际应用中,对称量化和非对称量化都有各自的使用案例。
对称量化的案例通常出现在那些数据分布相对均匀,且大部分数据集中在零附近的情境中。例如,在音频处理或图像处理中,当需要对信号或像素值进行量化时,如果这些值大多数情况下都是接近零的,那么对称量化就可以有效地减少表示范围,同时保持数据的分布特性。对称量化的一个简单例子是在图像处理中对灰度图像进行量化,其中像素值在0到255之间均匀分布,使用对称量化可以有效地将这些值映射到量化后的表示中。
2.3.2 非对称量化
- 特点:非对称量化不要求量化后的值中零点对应于原始值中的零。这意味着量化操作可以有一个任意的零点,这个零点被映射到量化范围内的某个整数值上。非对称量化使用三个参数(量化最小值、量化最大值和零点)来定义从原始数值到量化数值的映射关系。
- 优势:非对称量化可以更精确地表示数据范围,尤其适用于数据分布不均匀的情况,如大部分值为正或负。
- 挑战:执行量化和反量化操作可能需要更多的计算,因为涉及到额外的零点参数。
非对称量化则适用于数据分布不均匀或偏态的情况。例如,在金融数据分析中,某些特征的值可能在正负之间有显著的差异,或者数据集中包含一些极端值。在这种情况下,非对称量化可以更灵活地处理数据的这种偏态分布,通过调整零点的位置来更好地捕捉数据的特征。非对称量化的一个例子是在量化投资策略中,对股票价格变动的百分比进行量化,其中价格变动可能包括正负值,且分布不均。
在选择量化策略时,需要考虑数据的分布特性以及模型对精度的要求。对称量化由于其简单性,在许多情况下是首选,但如果数据分布不均匀,非对称量化可能会提供更好的精度。在实际应用中,可能需要通过实验来确定哪种量化策略更适合特定的模型和数据集。
三、模型量化具体步骤
-
范围确定:
- 在训练集或验证集上运行模型,收集每层参数和激活值的统计信息。
- 确定每层的最大值和最小值,这些值将用于后续的量化过程。
-
缩放和偏移计算:
- 根据确定的范围计算缩放因子(scale factor),这通常涉及到将浮点数范围映射到整数表示的范围。
- 计算偏移量(zero point),确保量化后的零点对应于原始值中的零(对称量化)或映射到合适的整数值(非对称量化)。
-
参数量化:
- 使用计算得到的缩放因子和偏移量,将浮点参数转换为整数形式。
- 对于权重和激活值,应用量化公式将浮点数映射到整数。
-
推理调整:
- 在模型推理(即模型部署)过程中,根据量化方法调整计算。
- 对于动态量化,激活值在运行时被量化和反量化。
- 对于静态量化,激活值在推理前被量化,并在操作之间传递量化值。
-
校准(可选):
- 对于某些量化方法,如静态量化,可能需要一个校准步骤来确定量化参数。
- 校准通常涉及在一个小的验证数据集上运行模型,并收集激活值的分布信息。
-
模型转换:
- 将模型转换为量化版本,这可能涉及到替换模型中的某些层或操作,以支持量化计算。
-
测试和验证:
- 在量化后,对模型进行测试和验证,确保量化模型的性能满足要求。
- 如果需要,对量化模型进行微调,以补偿量化带来的精度损失。
-
部署:
- 将量化后的模型部署到目标硬件平台上,进行实际应用。
总结
量化过程中,需要考虑模型的精度、速度和硬件兼容性。不同的量化策略和精度(如INT8、FP16、INT4等)可能会对模型的性能和兼容性产生不同的影响。因此,量化策略的选择应基于具体的应用需求和目标硬件的特性。

















 1426
1426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









