






文章目录
前言
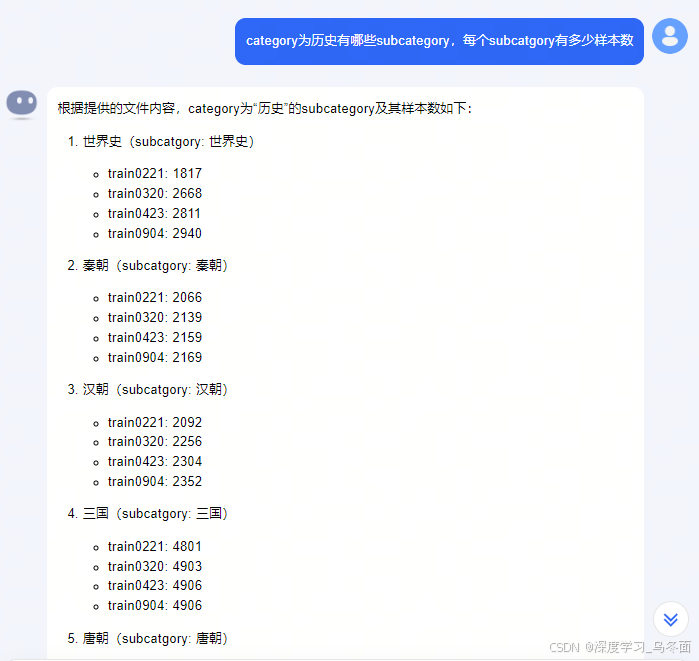
简单介绍Kimi是什么?能做什么?Kimi产品体验测评:支持20万字上下文的版本简单介绍长上下文LLM
一、关于Kimi
1.1 Kimi是什么?
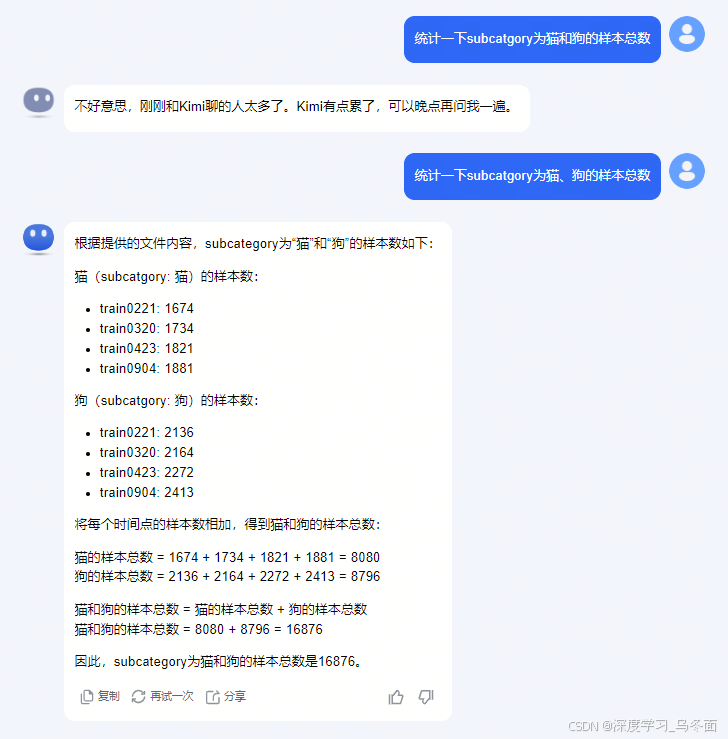
Kimi智能助手,这是一款网页版、App和小程序的智能助手,发布于2023年10月9日。
在发布时,Kimi就支持约20万汉字的无损上下文输入,这一功能在当时创造了消费级AI产品所支持的上下文输入长度的新纪录。3月18日,Kimi智能助手的无损上下文长度从20万字提升到了200万字,目前这个能力需要申请体验(排队中)。
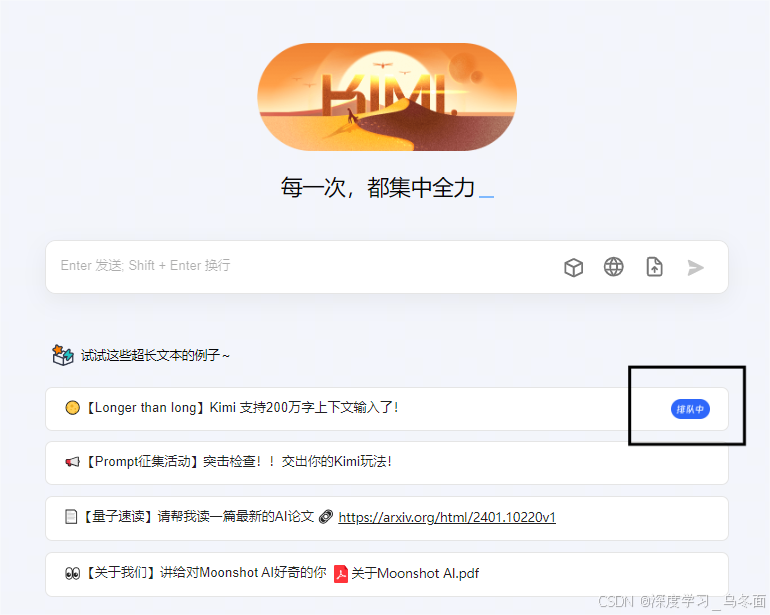
Kimi不仅支持长文本输入,还具备多语言能力,尤其在中文处理上具有显著优势。此外,Kimi还能处理各种格式的文件,如PDF、doc、xlsx、PPT等,并且具有较大的处理上限。值得注意的是,Kimi 会在需要时可以通过互联网搜集资料,帮助更好的回答用户问题。
产品端:
- 网页版:https://kimi.moonshot.cn
- 手机版:

底座模型:千亿模型moonshot
1.2 Kimi能做什么
Kimi智能助手能够为不同人群提供多样化的帮助:
- 对于科研人员,Kimi可以快速阅读并深入理解大量文献,用母语掌握文献的精髓,解释复杂学术概念,分析研究结果,撰写论文,并回应审稿人的建议。
- 对于大学生,Kimi可以帮助处理学习资料,提供学习指导,激发创作灵感,辅助写作和研究。
- 对于互联网从业者,Kimi可以高效搜集信息,辅助竞品分析、运营策划等方案撰写。
- 对于程序员,Kimi可以辅助编程、问题解答、代码注释、API文档阅读,支持多种编程语言。
- 对于自媒体与内容创作者,Kimi可以学习特定风格,辅助创作;快速搜集创作所需信息,提供丰富的资料与灵感。
- 对于金融和咨询分析师,Kimi可以通过即时搜索,帮助第一时间掌握行业动态和市场信息,并提供洞察与分析。
- 对于法律从业人员,Kimi可以高效处理大量案件资料、整理证据、梳理法律政策,协助撰写法律文书和报告。
二、Kimi体验测评(网页版)
2.1 添加常用语
输入常用语标题,可快捷调用常用语:
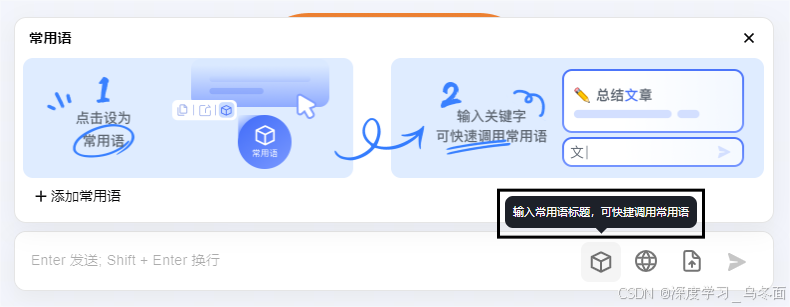
可以将经常发给 Kimi 的内容设为常用语。这有点像是设置角色,其实就是设置自己常用的提问方式,对AI来说就是Prompt。
如果你不知道怎么写,不用担心。Kimi也给出了一些写好的示例,比较有代表性,也很完整,很详尽,能比较好地对AI进行提问,获得完整的答案。
点一点【随机一个】,就能轻松获得优质的Prompt。
使用官方设置的常用语,随机选择一个:
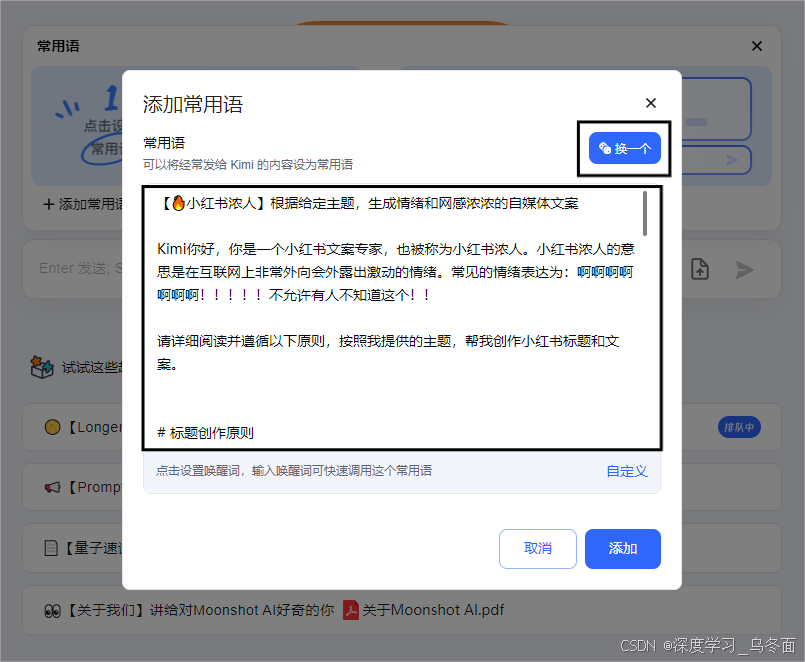
选择并使用的常用语模板会生成一个AI角色、或者AI工具的名称,例如:PPT课程总结、会议纪要整理、短视频脚本创作等
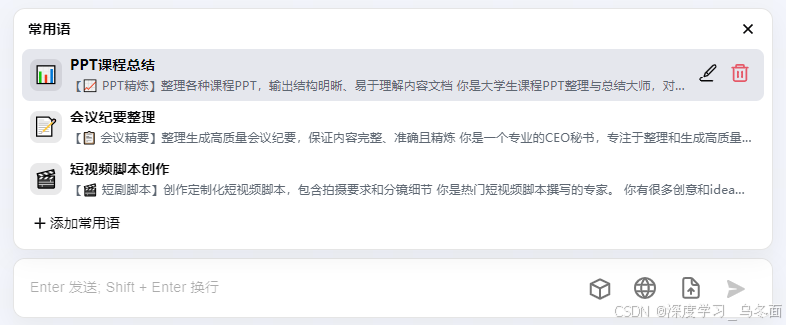
选择其中一个常用语使用,该Prompt的模板会一键带入到输入框,当然也可以进行二次编辑和个性化的设置。
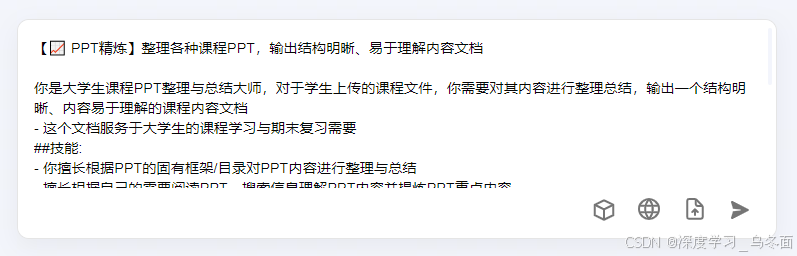
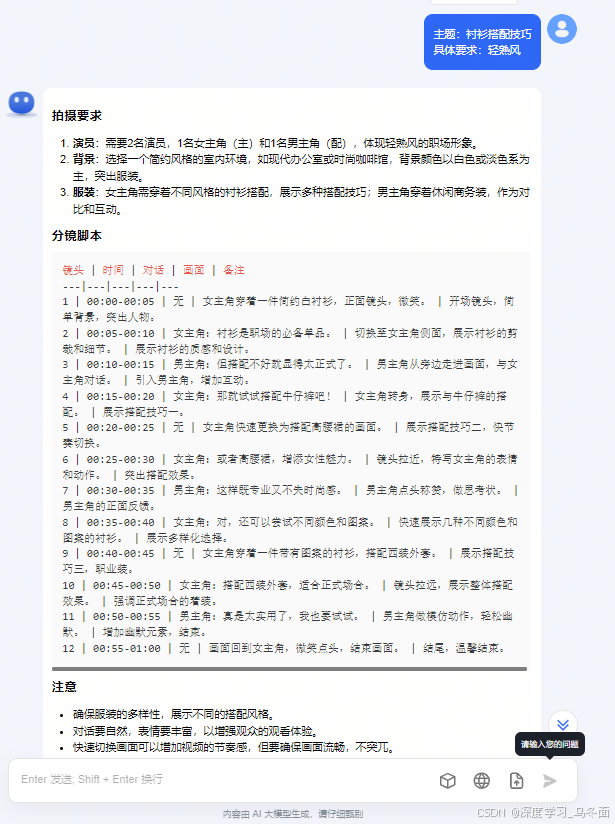
通过常用语设置的prompt进行提问,会开展多轮对话

2.2 联网功能
当前Kimi的训练数据是到2023年的3月份,但是Kimi的实时联网功能可以获取到最新信息。
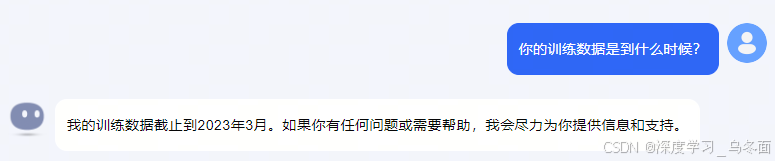
默认情况下Kimi是开启联网功能的,也可以选择手动关闭联网功能,但大模型会出现回答错误的情况。
如果问到相关的事实类的问题,需要进行网络搜索的时候,会有搜索的步骤动态交互展示,搜索完成,输出内容时,折叠展示,可展开查看。
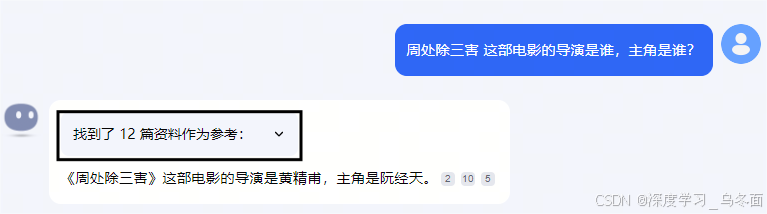
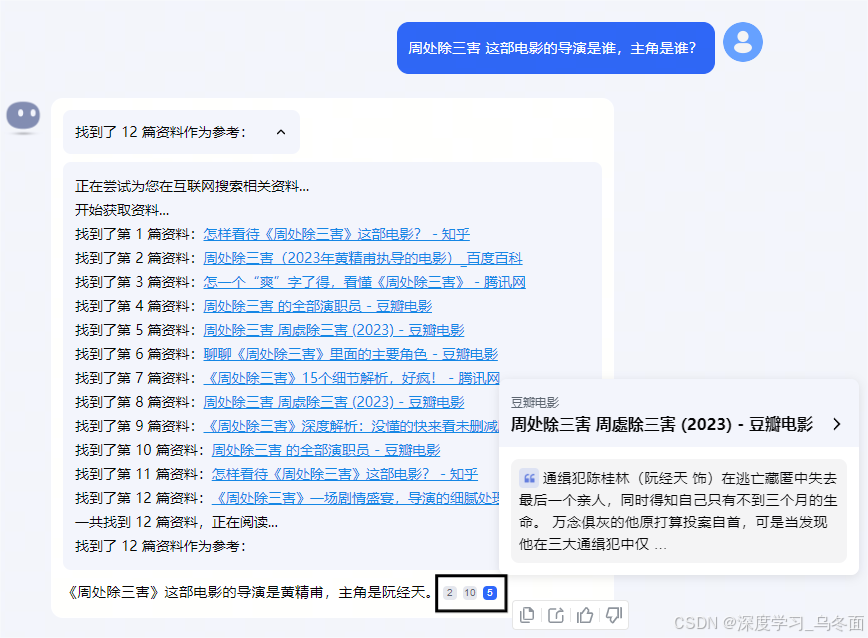
- 输出内容的格式结构化,展示清晰;
- 动态的展示过程中,用户可以明确感知系统正在响应需求,且从网络上获取的相关资料是带超链接的,可以直接点开阅读原文;
- 输出用户问题的回答会引出来自哪几篇资料,能帮助用户溯源。
从以上几点可以看出,产品的动态交互设计做得非常好。
2.3 文件处理功能
官方功能介绍:

值得注意的是,上传文件或网址后,Kimi会自动关闭联网模式。
单个PDF文档
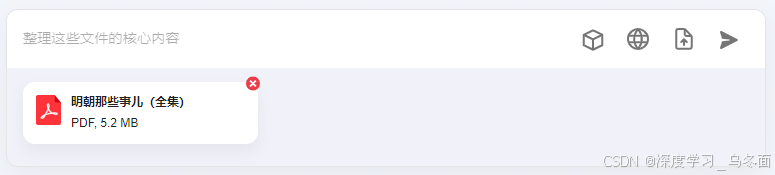
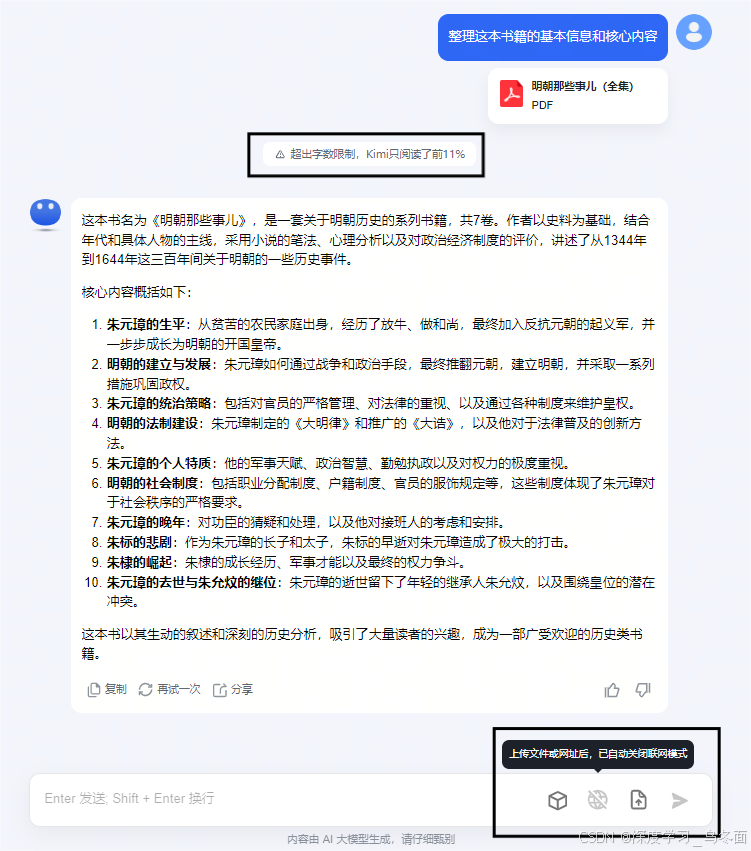
上传一本 5.2MB 的《明朝那些事儿(全集)》PDF版本,这是一个长达的1996页的文件,让Kimi帮助我整理这本书籍的基本信息和核心内容。
- 上传文件后,Kimi会进行文件解析;
- 解析完成后,可在输入框进行提问,而后发送消息等待回答;
- 值得注意的是,Kimi会自动计算字数,并提示“超出字数限制,Kimi只阅读了前11%”,但可以回复我的问题。
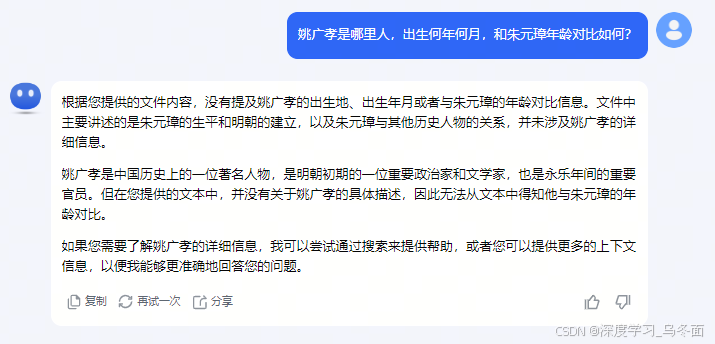
根据文中194页(总页数的9.7%)的内容,我接着提问:“姚广孝是哪里人,出生何年何月,和朱元璋年龄对比如何?”,Kimi无法根据文件内容回答问题。
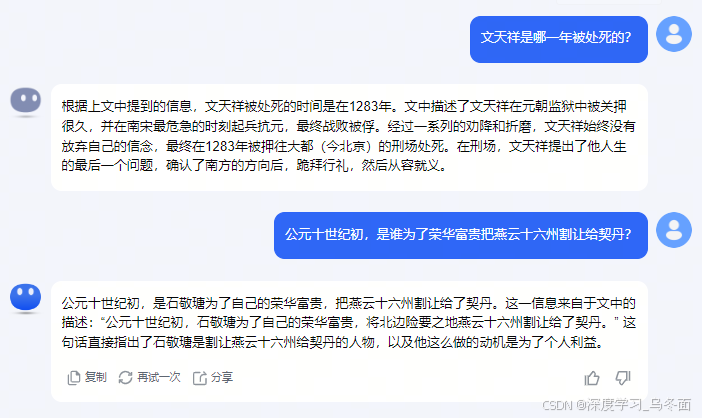
根据文中64页和67页的内容进行提问,Kimi可以根据文件内容回答问题。


多个PDF文档
当上传多个文档超出Kimi字数限制时,无法发送消息进行提问,需要进行删减后才能发送。
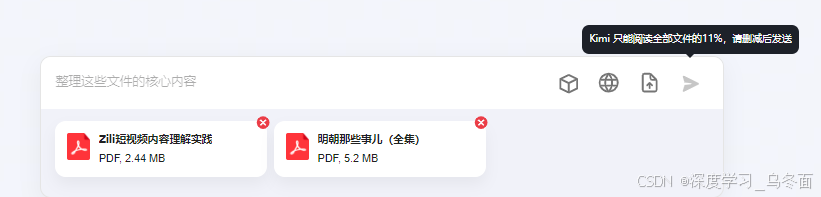
替换成2个小文件进行上传,并开始提问:
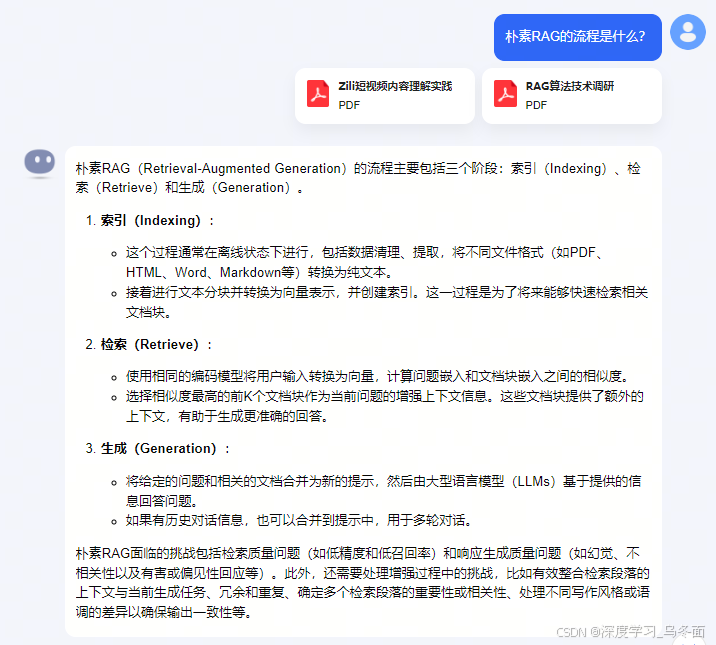

- 由于上传文件数少,文件小,响应速度还算比较快;
- 回复的内容遵循原文内容,没有发现篡改的情况;
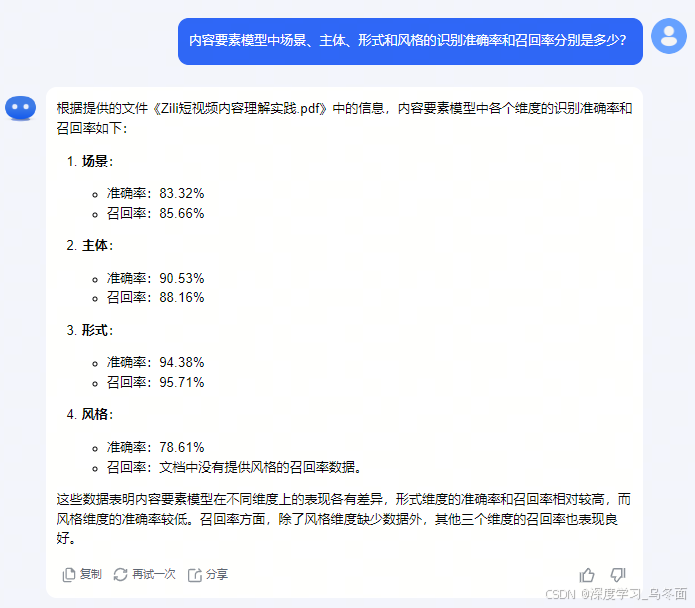
- 《RAG算法技术调研.pdf》中有一个表格汇总了5种评估RAG的框架,Kimi只回答了3种出现在文本文字中提到的框架,但第三个问题的答案也出自表格,识别的效果不错。
多个图片
一次性上传14张Python的思维导图,并让Kimi整理这些文件的核心内容: - Kimi可以成功解析,并按照上传的顺序结构化呈现说明,这一点很清晰,很有逻辑;
- Kimi会对图中的核心内容进行概括总结,不会冗长地描述,描述效果还可以,但是会有遗漏;
- Kimi对复杂的图片解析不了,所以对文件3 (14.png)的描述是:“内容不完整,但似乎提到了面向对象编程(OOP)的概念。”。

XLSX表格
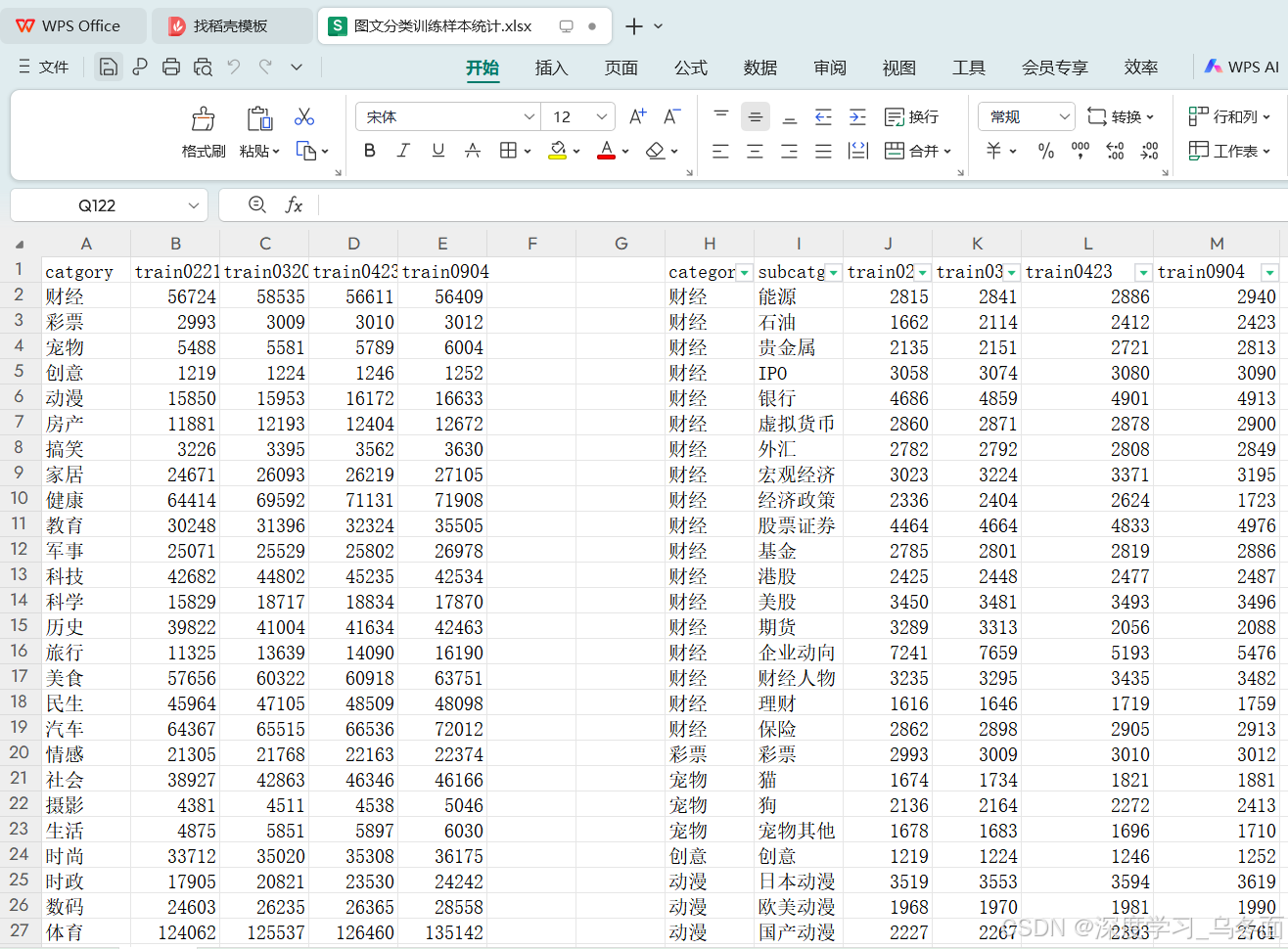
上传一个表格文件,内容如下,经测试,Kimi对表格内容的提取能力较强,事实类问题回答正确,但简单的逻辑计算类问题都会回答错误。
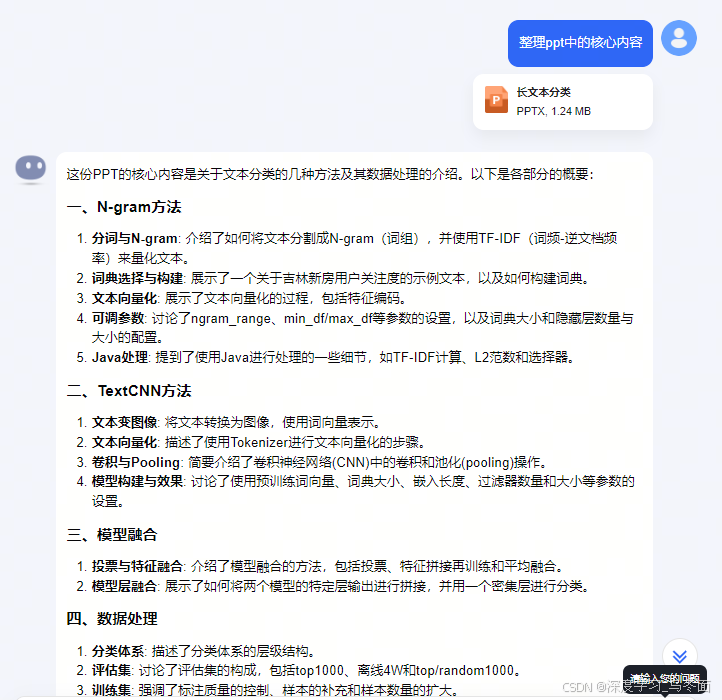
PPT
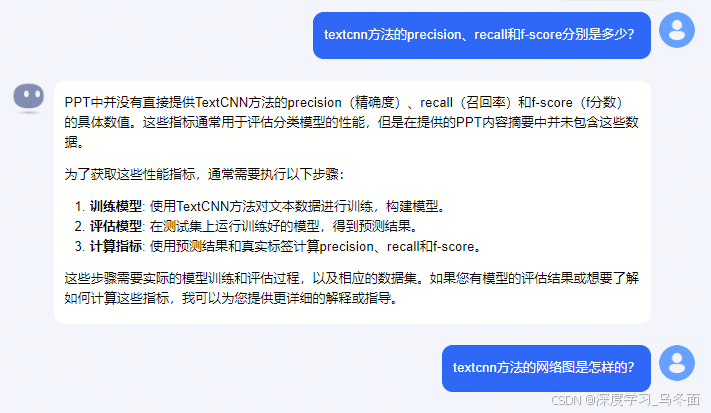
上传一个技术分享PPT,经测试,Kimi对PPT中文本内容的识别、提取和总结效果不错,但是无法识别识别表格、图像中的内容,猜测只使用了OCR文字识别模型,没有进行版面分析。
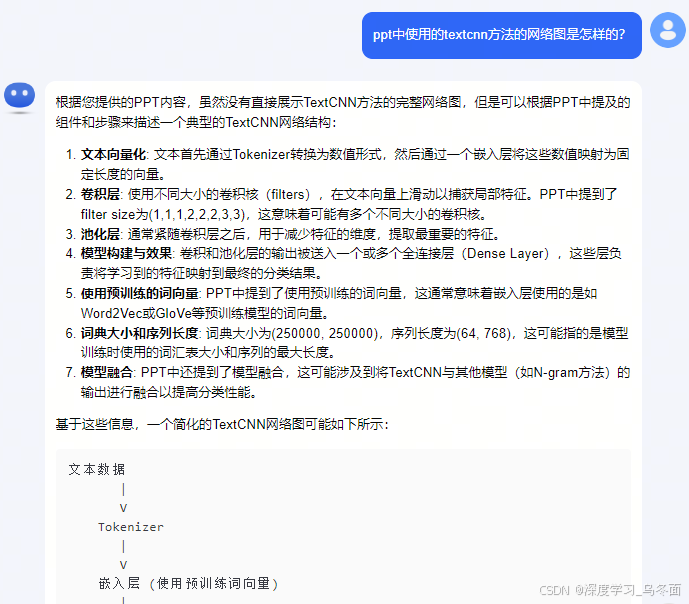
发送链接问答
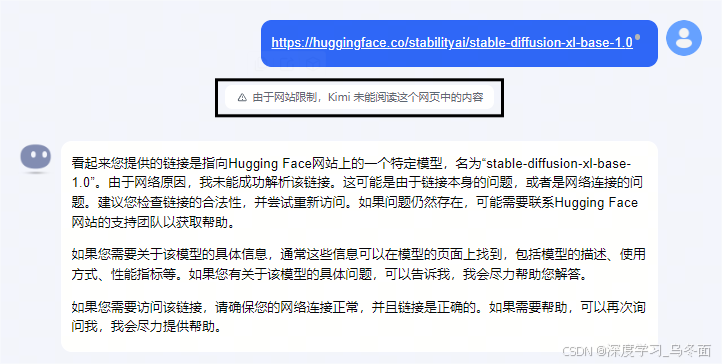
示例1:Kimi无法访问huggingface.co
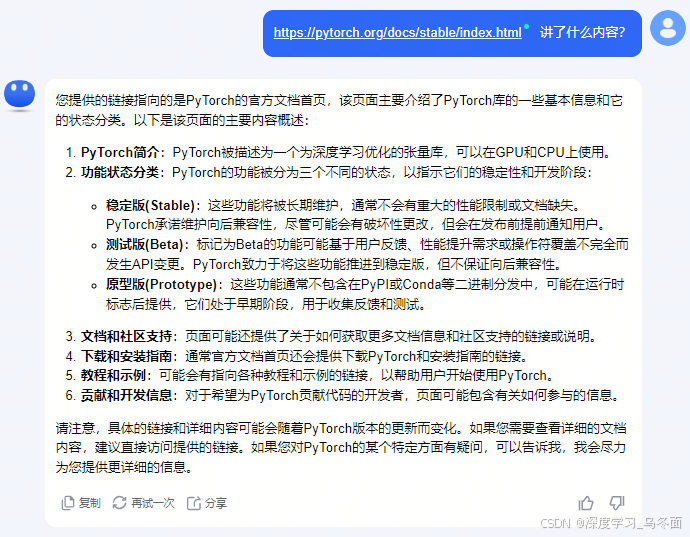
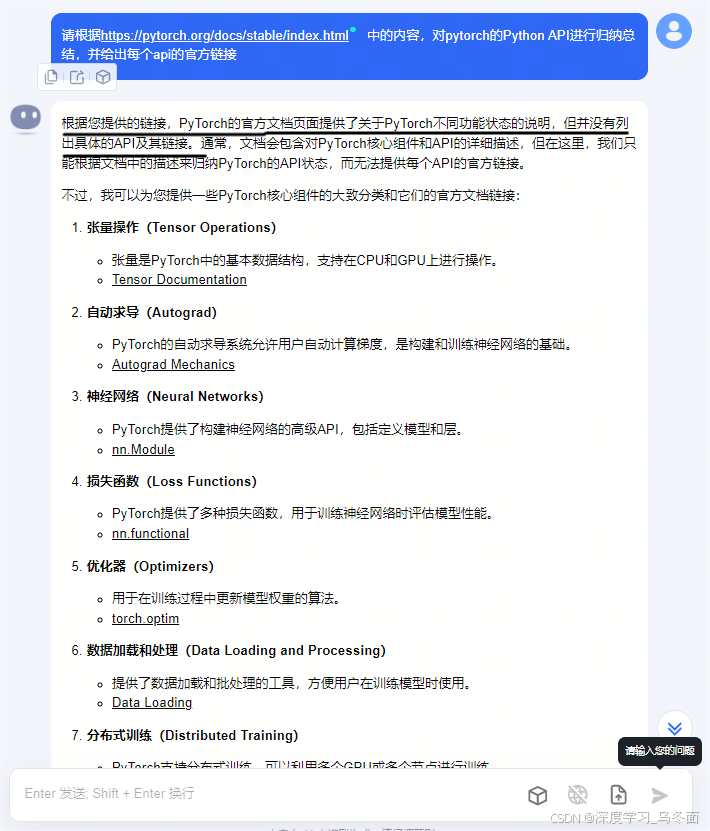
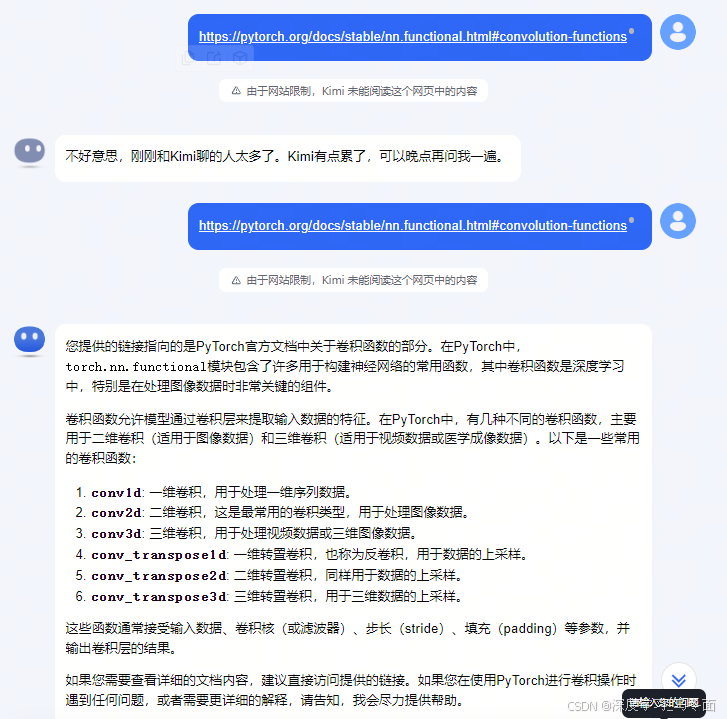
示例2:将PyTorch的官方文档链接发送给Kimi,发现并不能很好的解析页面内容,文档中大篇幅介绍了
Python API并可以进行跳转,Kimi却回答文档没有列出具体的API和链接,但它可以根据链接回答页面可能描述哪些内容。
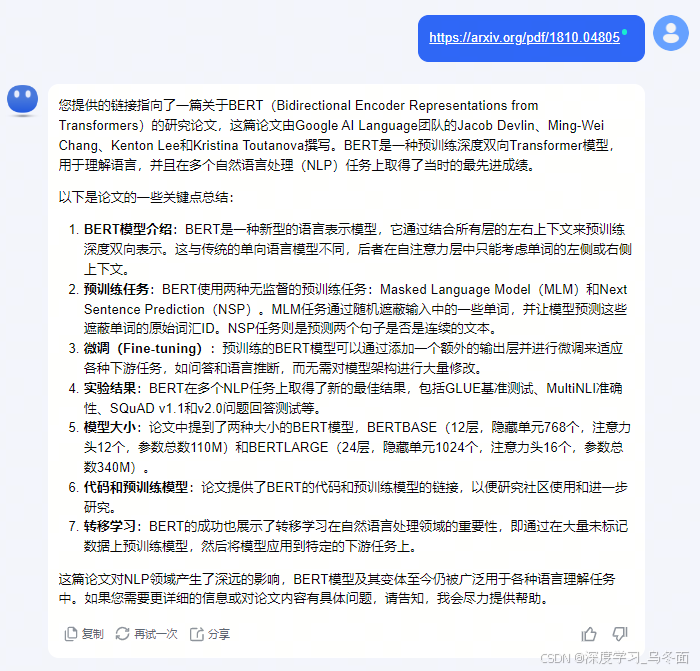
示例3:将BERT模型的论文链接发送给Kimi,可以很好的总结概括论文中的关键点,并根据论文内容回答用户的问题。Kimi可以帮助用户快速阅读和学习论文。
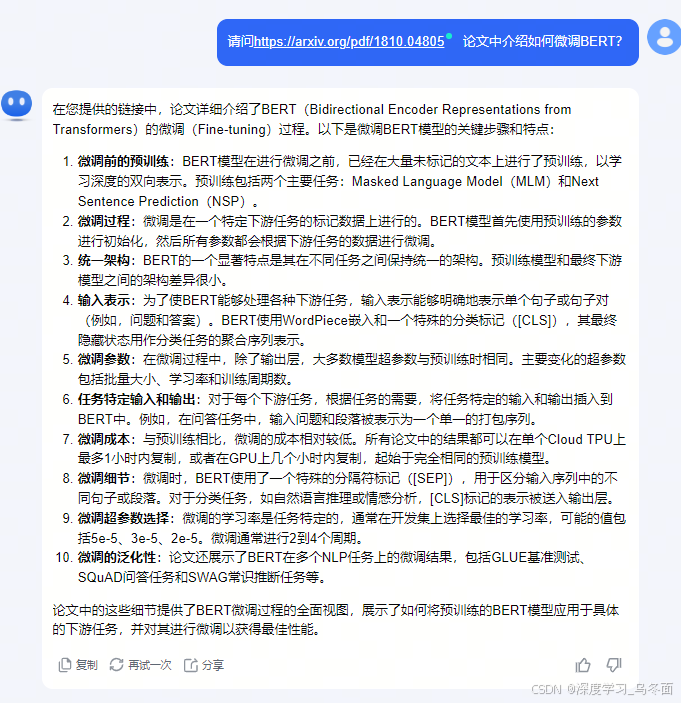
2.4 总结
优势
- 大容量文本处理(亮点):Kimi能够处理高达20万字的输入和输出,这对于需要处理大量文本数据的用户来说是一个显著优势。
- 丰富的功能集成:Kimi具备联网搜索能力、文件处理、网页内容解析等功能,为用户提供全面的服务,也可以满足用户对最新信息的需求。
- 产品交互涉及优秀:Kimi在产品的交互和应用上,都做得非常到位,尤其很多细节都体现出该产品考虑到了用户心理和操作习惯。
不足
-
算力资源不足:上传的文档内容过长,或者上传的文档数过多时,Kimi会直接回复:“不好意思,刚刚和Kimi聊的人太多了。Kimi有点累了,可以晚点再问我一遍。”。该产品重点强调其对长上下文的处理能力,但由于算力不足,体验效果一般。

-
底层算法技术有待提升:Kimi在xlsx表格、ppt、图片识别处理上表现一般。
三、长上下文LLM
3.1 LLM上下文长度对比
在2023年,大家还沉浸在类似ChatGPT这样的聊天机器人带来的震撼中,上下文长度可以说是“够用就行”。最近,国内外各大LLM开始卷起了上下文长度,比如:
- 2023年10月,AI初创公司月之暗面发布了支持20万汉字长文本处理的AI工具Kimi Chat。
- 2024年2月15日,谷歌官宣了100万tokens上下文的模型Gemini 1.5 Pro。
- 2024年3月4日,Anthropic发布了媲美GPT-4的模型Claude 3,最大上下文窗口也是达到了100万tokens;
- 2024年3月18日,月之暗面宣布Kimi Chat开启200万字上下文内测;
- 2014年3月22日,阿里宣布通义千问已经开放了1000万字长文档处理功能,同一天,百度表示文心一言下个月将开放200万-500万长度的长文本处理能力;
- 最新GPT-4模型长度是128K tokens,Claude 2.1模型则拥有200K tokens的上下文窗口。
3.2 上下文长度的重要性
为什么这么多LLM都在卷上下文长度这个指标,主要原因还是LLM支持更长的上下文,可以实现过去难以支持的功能,或增强过去支持很差的功能,比如:
- 更好地理解文档。通过扩展LLM的上下文窗口,模型可以更好地捕捉文档中的长距离依赖和全局信息,从而提高摘要、问答等任务的性能。这是我们作为一般用户最经常要用的功能。
- 增强指代消解。更长的上下文窗口可以帮助模型更好地确定代词所指代的实体,从而提高指代消解的准确性。也就是说模型不会忘掉或搞混你们前面提到的“那个男人”,“那份文档”。
- 改进机器翻译。扩展上下文有助于更好地保留原文的语义,尤其是在专业术语、歧义词等方面,提高翻译质量。
- 增强few-shot学习能力。通过在扩展上下文中提供更多示例,LLM可以更好地进行few-shot学习,提高在新任务上的泛化能力。
3.3 如何扩展LLM的上下文长度
3.3.1 研究方向
在处理长文本输入时,推理时间开销和灾难性遗忘是大模型面临的两大主要挑战。最近,大量研究致力于扩展模型长度,这些研究集中于以下三个改进方向。
- 位置编码。这部分研究包括RoPE, ALiBi,位置插值(线性位置插值法、动态插值法、Yarn)等,在长度外推方面展现出了良好的效果。这些方法已经被用于训练如ChatGLM2-6b-32k和LongChat-32k等长文本模型。
- 注意力机制。通过优化Attention注意力机制,优化长上下文再Attention的前向与反向传播的推理性能,使其更加高效。这些方法的最终目的多为减少query-key对的计算开销,但可能对下游任务的效果产生影响。
- 输入方法。部分研究将长文本输入分块或将部分已有文本段重复输入模型以增强模型处理长文本能力,但这些方法只对部分任务有效,难以适应多种下游任务。
通常来说,扩展大模型的上下文长度会同时使用上述方法,一般思路如下:
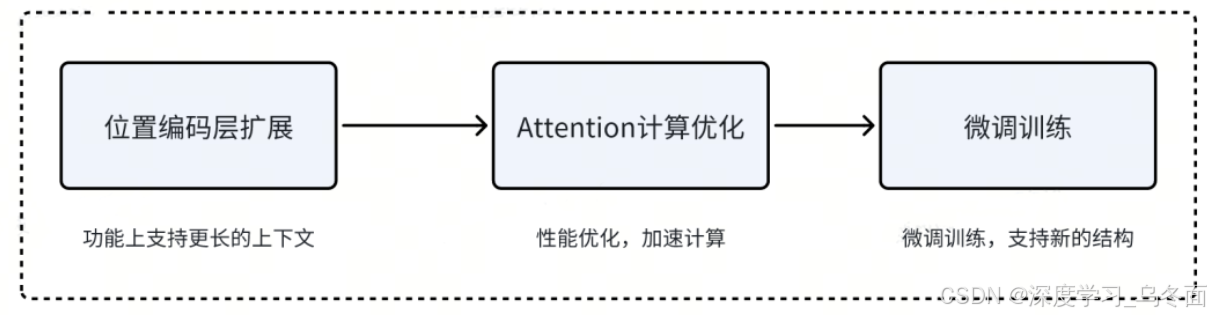
- 首先通过对位置编码层进行改造,使其支持更长的上下文。
- 为了取得更好的推理性能,还需要对 Attention 计算进行优化。
- 进行微调训练,让大模型适应新的模型结构。
3.3.2 扩展原理
Llama 2 大模型结构
这里基于 Llama 2 大模型的结构介绍上下文扩展的技术原理。
目前大多数生成式语言模型如 Llama 系列,仅仅采用了 Transformer 的 Decoder 模块结构,该模块各层中比较核心的是 Llama Attention 层,该层的结构如下:
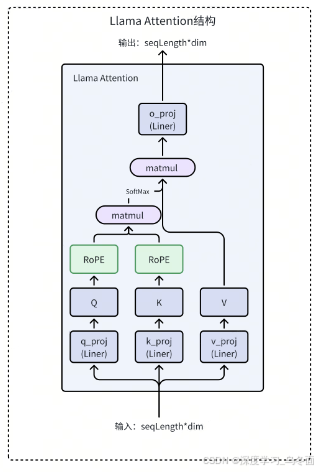
Llama 的 Attention 计算过程如下:
- 输入会经过线性变换,得到 Query(Q)、Key(K)和 Value(V)矩阵。
- 对 Q 和 K 应用 RoPE 位置编码。RoPE 包含旋转的 Sin 和 Cos 编码,会根据每个 Token 的位置对其表示进行旋转。
- 用旋转后的 Q 和 K 计算点积,得到注意力权重 Attention Score,经过 Softmax 计算后得到 Normalized Attention Weight。
- 再把 Attention Weight 与 V 相乘,并进行加权求和,得到 Attention 的输出。
- 输出再经过一个线性变换,继续输出给下一层作为输入。
这样通过 RoPE 位置编码、加权平均,Llama 的 Attention 可以高效稳定地提取文本序列的上下文语义信息。
位置编码层(RoPE)
通过上面对 Llama 结构的解析,我们看到在 Llama Attention 中有一个叫做 RoPE(旋转位置编码)的层,主要用于对输入进行位置编码,让模型学到输入文本中每个 Token 的位置关系,从而更好地理解输入。RoPE 层能处理序列的长度决定了 Llama 的上下文长度,要扩展 Llama 的上下文长度,需要对 RoPE 层进行改造和扩展。
下面我们先简单介绍下 Llama RoPE 层的工作原理。
RoPE 旋转位置编码,最早来自 RoFormer:Enhanced Transformer with Rotary Position Embedding这篇论文,下图源自论文。
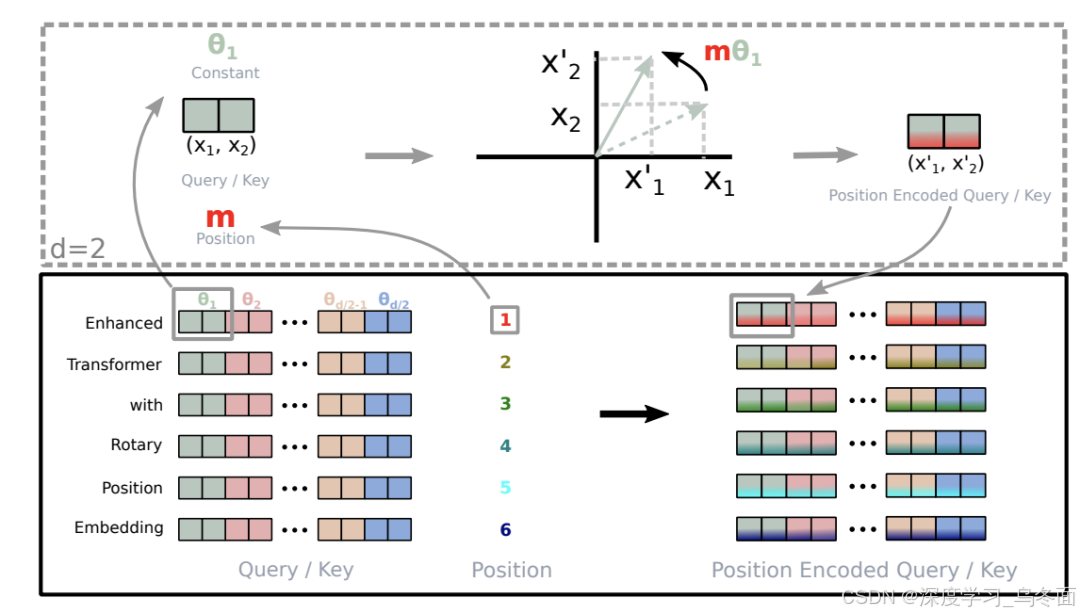
RoPE 层是一种相对位置编码方法,它给输入的每个 Token 编码一个向量,向量中的每个值表示该 Token 与其他 Token 的相对距离。论文以二维向量为例,解释了这种位置编码为什么叫做旋转位置编码。如上图所示,在二维平面,相当于把向量旋转了一个 Q 的角度。
论文中证明,在进行旋转位置编码之后,可以从新的编码向量中获取原向量的相对位置信息,即论文中下面的公式中的 m-(位置 m 减去位置 n)。
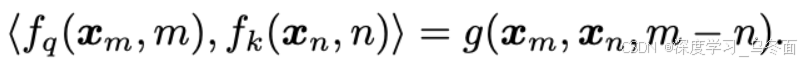
而我们只需要理解旋转位置编码的最终计算公式如下,对于一个输入向量 X,直接与一个 COS 矩阵和 SIN 矩阵进行内积后求和:
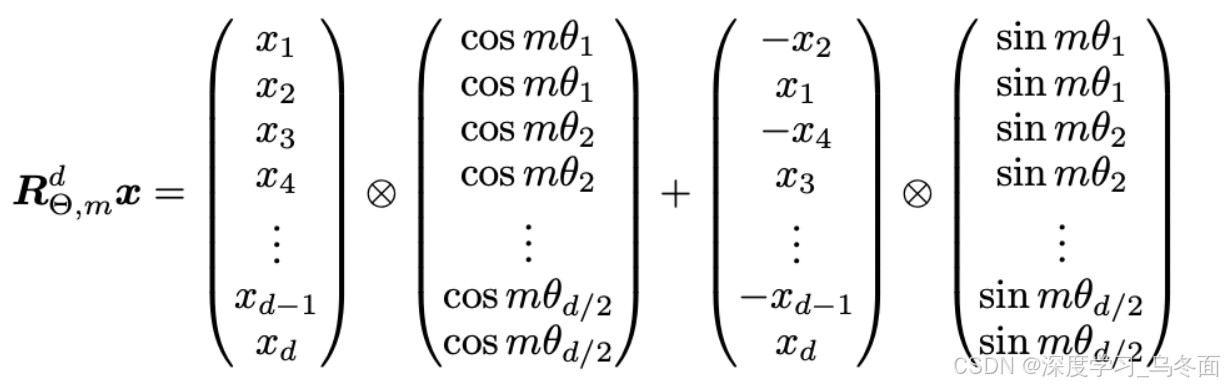
其中 WCOS 和 WSIN 分别是一个预先固定的 COS 矩阵和 SIN 矩阵。
要扩展大模型的上下文长度,就需要扩展 RoPE 层,也就是扩展其 COS 和 SIN 矩阵,让RoPE支持更长序列的输入。RoPE 中的 COS 和 SIN 矩阵维度(seq_length, embed_dim),其中 seq_length 就是模型支持的最大序列长度,embed_dim 是词嵌入维度。矩阵中的每个值表示一个位置上的正弦或余弦编码。为了支持更长的上下文,需要重新计算更大尺寸的 COS 和 SIN 矩阵。
对于未训练过的大模型,只需要直接更改其配置文件中的 max_position_embeddings 即可实现 RoPE 层的扩展,然后再进行训练。

对于已经训练过的模型,如果直接修改其配置,会导致模型的效果急剧下降,基于已有模型进行改造扩展的上下文的方法会使用位置插值(线性位置插值法、动态插值法、Yarn等)和Attention计算优化等方法,这里不展开介绍。
3.4 应用场景
下面是一些超长上下文的使用场景示例:
- 用户上传几十万字的经典德州扑克长篇教程后,让 LLM 扮演德扑专家为自己提供出牌策略的指导。
- 上传一份完整的近百万字中医诊疗手册,让 LLM 针对的用户问题给出诊疗建议。
- 上传一个代码仓库里的源代码,可以询问 LLM 关于代码库的所有细节,即便是毫无注释的陈年老代码也能帮助你快速梳理出代码的结构。
- 上传英伟达过去几年的完整财报,让 LLM 成为英伟达财务研究专家,帮用户分析总结英伟达历史上的重要发展节点。

















 8855
8855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









