







项目主页:https://shihmengli.github.io/extranerf-website/
来源:华盛顿大学,康奈尔大学,谷歌研究,加州大学伯克利分校
标题:ExtraNeRF: Visibility-Aware View Extrapolation of
Neural Radiance Fields with Diffusion Models

文章目录
摘要
ExtraNeRF,利用NeRF建模特定于场景的、细粒度的细节,同时利用扩散模型来推理超出观察的数据。一个关键的因素是跟踪可见性,以确定场景的哪些部分没有被观察到,并专注于与扩散模型一致地重建这些区域。我们的主要贡献包括一个基于可见性感知扩散模型的inpainting模块,它微调输入图像,初始化一个NeRF,以及中等质量的(通常模糊)inpaint区域;然后第二个扩散模型训练输入图像,以持续增强,特别是锐化前面的inpaint 图像。文章展示了高质量的结果,推断出少量(通常是6个或更少)的输入视图,有效地outpainting NeRF,并在原始视角内inpaint newly disoccluded的区域。
1.引言
NeRF的基本形式的一个限制是:它的插值比 extrapolating(外延)好得多,并且需要密集的插值。
核心策略是使用神经辐射场(NeRF [29])来捕获特定场景的、细粒度的细节,并利用二维扩散模型来扩展场景超出观测数据的范围。这种直接融合最初导致nerf渲染的图像看起来模糊和细节不足。这主要是由于当从不同的角度应用于3D场景时,2D扩散先验之间的不和谐,特别是在场景级视图外延中,复杂的细节(如叶子和分支)显著减少。
pipeline为多阶段的过程(见图2),其中包括:
(1)可见性模块 ,用于识别所有观察数据中的可见3D内容;
(2)利用可见性感知的 inpainting模块,为每个场景定制想象并添加可信的3D内容用于extrapolatw,并确保观察数据的内容保持不变;
(3)使用 扩散模型,丰富新增内容的视图一致细节。
2.相关工作
2.1 视图合成
给定一组带pose图像,视图合成的目标是从新颖的视角[8,21,52]模拟一个场景的样子。这个问题传统上被表述为基于图像的渲染任务[12,73],通过基于深度映射[7]在视图中混合像素颜色或使用代理几何[19]合成图像,可以获得令人印象深刻的结果。近年来,在深度神经网络[26,37,38,57,72]的帮助下,研究结果得到了进一步的提高。与精心策划的场景表示[15,45,56,62],研究人员已经能够合成新的视图,甚至从一个图像[Pixelsynth,Consistent view synthesis
with pose-guided diffusion models]等。与这些最近的努力类似,我们的工作试图推断出超出可见的内容,并预测在所有图像中被遮挡的内容。然而,我们不是依赖深度网来学习几何关系,并以纯粹的数据驱动的方式生成虚假内容,而是将3D归纳偏差(例如,可见性)烘焙到管道中,以建立生成过程。这使我们能够生成高质量、真实和连贯的场景内容。
2.2 NeRF神经辐射场
现有的基于NeRF的模型往往不受约束,导致以下限制:首先,它们需要对场景的密集观察;其次,当外延而不是插值时,它们的性能会显著下降。为了缓解这些问题,研究人员提出了通过数据分割统计数据[16,33,63]或几何约束[54]来正则化底层场景表示。虽然这些方法大大减少了所需的输入图像的数量,但它们仍然假设输入视图有一个广泛的场景覆盖范围。因此,该任务仍然属于视图插值设置之下。在本文中,我们关注的是一个常见但又具有极具挑战性的实时捕获设置,其中我们只能访问一些具有小基线的图像。我们表明,通过仔细集成生成模型与NeRF,可以有效地扩大NeRF的操作范围,并产生高质量的效果图。
2.3 扩散模型
扩散模型[13,40,48,49]由于其能力和可伸缩性而引起了整个视觉界的广泛关注。他们在大量的2D任务上表现出了显著的性能,如图像inpaint[28,42],去模糊[20,61],并实现了高质量、多样化的图像生成[40,43]。通过结合神经渲染[29], 学习到的扩散先验可以进一步提升到3D,以实现文本到3D[24,35,51,59]或单/多图像3D生成[25,27,36,44,46,47,53]等应用。与这些工作类似,我们也利用扩散模型来合成新的视图,并将生成结果融合回3D。然而,我们研究的不是以对象为中心的内容,而是研究如何建模场景的3D内容。此外,我们明确地跟踪跨视图的可见性,这使我们能够生成现实和一致的3D重建。与我们的工作同时,Sargent等人[Zeronvs]也试图外延3D场景。虽然他们的重点主要是生成超出可见图像边界的内容,但我们的方法同时预测了未被遮挡的区域和未被观察到的区域。
3.准备工作
3.1 NeRF。
神经辐射场 NeRF 是一种隐式的场景表示法。它的核心是一个连续的函数 f θ f_θ fθ: R 3 × R 2 → R + × R 3 R ^3×R^2 →R^+×R^3 R3×R2→R+×R3,由一个神经网络参数化,将3D点 x ∈ R 3 x∈R^3 x∈R3和一个视图方向 d ∈ R 2 d∈R^2 d∈R2映射到一个体积密度 σ ∈ R + σ∈R^+ σ∈R+和一个RGB辐射 c ∈ R 3 c∈R^3 c∈R3。对于每个像素,我们从相机中心到像素中心方向投射一个光线 r ( s ) = o + s d r(s)=o+sd r(s)=o+sd,并沿射线采样一组三维点,查询它们的亮度和密度。然后通过体渲染获得像素的颜色:
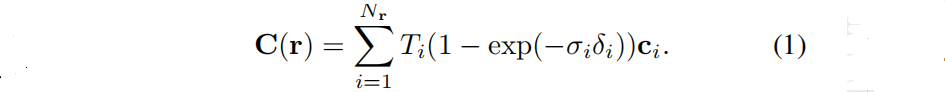
δ i = s i + 1 − s i δ_i = s_{i+1}−s_i δi=s
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









