







文章目录
- 一、 提升质量
- 1、UC-gs:交叉视图不确定性的航拍街道重建(Drone-assisted Road Gaussian Splatting with Cross-view Uncertainty)
- 2、Spann3R:空间记忆提升三维重建(3D Reconstruction with Spatial Memory)
- 3、DoubleTake:几何引导深度估计 Geometry Guided Depth Estimation(ECCV 2024)
- 4、Robust 3D GS:矫正相机参数偏差
- 5、Efficient Relighting with Triple Gaussian Splatting(精度luo)
- 6、StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal(精度luo)
- 7、Infinigen: Infinite Photorealistic Worlds Using Procedural Generation
- 8、Self-Evolving Depth-Supervised 3D Gaussian Splatting from Rendered Stereo Pairs
- 9、CSS: Overcoming Pose and Scene Challenges in Crowd-Sourced 3D Gaussian Splatting(鲁棒性)
- 10、GS-Net: Generalizable Plug-and-Play 3D Gaussian Splatting Module(质量)
- 11、GStex:独立解耦Texturemap,提升纹理表示
- 12、Spectral-GS: Taming 3D Gaussian Splatting with Spectral Entropy(对抗伪影)
- 13 CityGaussianV2: 先验的大场景 Geometrically Accurate Reconstruction
- 二、提升几何(与mesh、SDF联合优化方法)
- 1 MeshGS:自适应Mesh-对齐的GaussianSplatting高质量渲染
- 2.0-水平集上联合抽取Splats与SDF场
- 三、 稀疏重建、生成式
- 1、Splatt3R:两张图像的零样本高斯(Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs)(稀疏重建 )
- 2、GenWarp: 语义保留的单张图像生成3D(GenWarp: Single Image to Novel Views with Semantic-Preserving Generative Warping)(稀疏重建 )
- 3、ReconX: 用视频扩散模型从稀疏视图重建任意场景(Reconstruct Any Scene from Sparse Views with Video Diffusion Model)(生成式 )
- 4、LM-Gaussian:大模型先验的稀疏重建
- 5、Wonderworld:拓展图片边界,生成3D场景
- 6、SplatFields: Neural Gaussian Splats for Sparse 3D and 4D Reconstruction(稀疏)
- 7、Dense Point Clouds Matter(稠密化)
- 8、3DTopia-XL:扩散模型辅助生成
- 9.3DGS-Enhancer: 通过视图一致2D Diffusion,提升无界3D Gaussian Splatting (NlPs2024 Spotlight)
- 10.L3DG:Latent 3D Gaussian Diffusion
- 四、 大场景
- 1、航空图像的大场景高斯重建(3D Gaussian Splatting for Large-scale 3D Surface Reconstruction from Aerial Images)(大场景 )
- 2、大场景的分层表示(A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets)
- 3、3D Gaussian Splatting for Large-scale 3D Surface Reconstruction from Aerial Images(大场景)
- 6、GaRField++
- 四、 加速与剪枝
- 1、实时高斯:通过光度SLAM加速3DGS(Towards Real-Time Gaussian Splatting: Accelerating 3DGS through Photometric SLAM)(加速 )
- 2、PRoGS: 渐进高斯渲染(PRoGS: Progressive Rendering of Gaussian Splats )(压缩 )
- 3、3DGS-LM: Faster Gaussian-SplattingOptimization with Levenberg-Marquardt
- 6、EdgeGaussians
- 五、动态
- 1、Dynamic Gaussian Marbles for Novel View Synthesis of Casual Monocular Videos(动态场景、分割等)
- 2、FlashSplat: 2D to 3D Gaussian Splatting Segmentation Solved Optimally(分割)
- 3、GS for Immersive Human-centric Volumetric Videos(人体)
- 4.MonST3R:运动中的几何估计
- 5.VR-Splatting
- 6.video-3D workflow
- 7.PhotoReg :GS点云3D配准
- 8.6DGS:GS + 体渲染
- 总结
一、 提升质量
1、UC-gs:交叉视图不确定性的航拍街道重建(Drone-assisted Road Gaussian Splatting with Cross-view Uncertainty)
来源:1清华大学人工智能产业研究院2安阳理工大学 3清华大学4北京理工大学
项目:https://sainingzhang.github.io/project/uc-gs/

解决问题:无人机的高海拔限制了它捕捉细粒度的道路细节的能力。全局鸟瞰图和局部街景在尺度和粒度上的不匹配使得MatrixCity [15]不适合无人机辅助的道路场景合成。空中和地面图像表现出较大的视图差异,很难直接训练3D-GS。
自动驾驶仿真场景:无人机视角的数据为地面车辆数据提供一个互补的视角,增强场景重建和渲染的完整性。 本文设计了一种不确定性感知训练方法,允许航空图像辅助合成地面图像学习效果较差的区域,而不是像以前的工作那样在3D-GS训练中对所有像素进行平均加权。通过排除空中透视中不相关的部分,如建筑的upper floor,它们与街景的关系较小,我们成功地减轻了街景上视角的移动和旋转的模糊性,提高了NVS的保真度 。
为了量化评估指标,提供合成数据集 :AirSim [29]控制无人机和车辆进行精确的轨迹生成,拟摄像机的视角,生成真实场景。通过 Unreal Engine 渲染相应的图像数据。地面视图利用车辆轨迹来生成前向图像。如图2,在1.5m和1.8m高度的地方采集前视图地面图像,在20m高度采集鸟瞰图图像,从前视图向下的60°角(基于测试)。1.6米和1.9米高度的附加试验数据评估透视影响。每个场景包括315张地面图像和351张航空图像的训练集,以及36张地面图像的测试集。

综合结果表明:(1)联合训练空中和地面图像有助于提高3D-GS在测试视图移动和旋转时的表示能力,但在held-out(保留)的道路视图测试中表现不佳。(2) 我们的方法减少了联合训练的弱点,并在数据集上进行的测试和涉及视图移动和旋转的场景上定量地优于其他基线。(3) 从质量上讲,我们的方法在道路场景细节的渲染方面有了很大的改进。

整体管道。首先采用基于ensemble的渲染不确定性,量化3D高斯在地面图像上的学习结果。接下来,将地面不确定性投影到空中,以构建交叉视图不确定性。随后,我们将交叉视图不确定性引入到3D高斯训练中,作为损失函数中航空图像每个像素的权重,以及3D-GS对地面图像的原始渲染损失。
细节
训练时,对空中和地面图像中的所有像素进行平均加权,会使空中图像具有与道路图像相同的合成优先级。与道路场景不重叠的区域和对道路场景合成贡献不大的区域不仅不能提高道路重建的有效性,也影响三维高斯收敛。
具体地说,训练一个由地面图像生成的运动结构(SfM)初始化的M个高斯溅射(GS)集合。通过将集合解释为均匀加权混合模型,成员的预测通过平均进行组合,预测不确定性表示为单个成员预测的方差。
一组GS中,场景中像素p的期望颜色,以及不确定性(即单个像素预测的方差)分别为:

通过渲染M个单独的RGB图像,并直接在像素空间中计算均值和方差,可以非常容易地计算 µ R G B µ_{RGB} µRGB 和 σ R G B 2 σ^2_{RGB} σRGB2 。两者都是RGB颜色通道上的3个矢量。通过以下方式将颜色通道的方差合并为一个不确定性值:

1.交叉视图不确定性投影。为了将不确定性图从地面视图投影到空中视图,我们测试了几种方法。基于神经场的方法,如NeRF和3D-GS,容易过拟合,因此用地面不确定性图训练的神经场无法在空中呈现高质量的不确定性。此外, 最近出现的端到端密集立体模型DUSt3R[39]将SoTA设置在许多3D任务上,可以用作空中和地面图像之间的2D-2D像素匹配器 。通过这种方式,通过地面和空中图像之间的匹配,将地面的不确定性图投影到空中,并通过多次匹配像素处的不确定性进行平均,构建出合理的交叉视图的不确定性图。可视化如图5所示。

2.不确定性敏感的训练。 U k ( x ) U_k(x) Uk(x)是第k幅航拍图像的像素x的不确定性值将其归一化到(0,1):

最后用uncertainty map来加权损失( λ S S I M λ_{SSIM} λSSIM = 0.2 λ v o l λ_{vol} λvol = 0.001):


L v o l L_{vol} Lvol是[Scaffold-gs]中使用的体积正则化,使得高斯球小,且重叠少。
结果
实验采用两个真实的城市场景:纽约市(NYC)和旧金山(SF),收集自Kyrylo Sibiriakov 和 Tav Shande。总结:不仅提高了从地面角度对GS的表示,而且 improves the quality of road scenes synthesis during the view shifting and rotation。

2、Spann3R:空间记忆提升三维重建(3D Reconstruction with Spatial Memory)
来源:Department of Computer Science, University College London
主页:https://hengyiwang.github.io/projects/spanner
代码:https://github.com/HengyiWang/spann3r

Spann3R,一种从有序或无序的图像,到密集的三维重建。建立在DUSt3R范式上的Spann3R使用了一个基于transformer的架构,在不事先了解场景或摄像机参数的情况下,直接从图像中回归点图。DUSt3R可以预测在其局部坐标系中表达的每个图像对点图,而Spann3R可以预测在全局坐标系中表达的每个图像点图,从而消除了基于优化的全局对齐的需要。Spann3R的关键思想是管理一个外部空间记忆,学习跟踪所有以前相关的3D信息。然后,Spann3R查询这个空间内存,以预测全局坐标系中下一个坐标系的三维结构。利用DUSt3R的预训练权重,并对数据集子集进行进一步微调,Spann3R在各种未知数据集上显示出具有竞争力的性能和泛化能力,可以实时处理有序的图像集合

图1.概述。给定一组有序或无序的图像集合,而不知道相机参数的先验知识,所提出的Spann3R可以通过直接回归在一个公共坐标系中的每个图像的点图来增量地重建三维几何图形。Spann3R在推理过程中不需要任何基于优化的对齐,即每个图像的三维重建可以通过简单的基于transformer的正向传递来解决,从而实现实时在线重建。通过对一些自捕获的图像进行重建,以说明Spann3R的泛化能力。

图2.动机。DUSt3R [81]直接在一个局部坐标系中回归每个图像对的点图。相比之下,Spann3R通过一个存储所有先前预测的空间记忆来预测一个公共坐标系中的全局点图。因此,我们的方法可以实现在线增量重建,而不需要建立一个密集的成对图和一个最终的基于优化的对齐。

图3。Spann3R的概述。我们的模型包含一个ViT [25]编码器和两个相互交织的解码器,如DUSt3R [81]。这里的目标解码器用于从图像中获取查询特征进行内存查询,而参考解码器用于使用几何特征和我们的记忆特征基于内存读出进行预测。一个轻量级的内存编码器被用来将先前预测的点图和几何特征一起编码到我们的内存键和值特征中。破折号表示在下一个时间步中的操作
细节
给定一个图像序列{ I t I_t It} t = 1 N ^N_{t=1} t=1N,训练一个网络 F F F,将每个 I t I_t It映射到其对应的点图 X t X_t Xt,并用初始帧的坐标系表示。为实现这一点,引入了一个空间内存,它编码之前的预测,以推理下一帧。
编码。向前传递中,模型以一帧 I t I_t It和前一个查询 f t − 1 Q f_{t−1}^Q ft−1Q作为输入。ViT用于将帧编码为视觉特征,查询特征 f t − 1 Q f_{t−1}^Q ft−1Q用于检索内存库中的特征,输出融合特征 f t − 1 G f_{t−1}^G ft−1G(fK和fV是内存key和value特征):

解码。融合特征 f t − 1 G f_{t−1}^G ft−1G和视觉特征 f t I f_t^I ftI被输入两个交织在一起的解码器,通过交叉注意共同处理它们。这可以使模型能够解释两个特征之间的空间关系;Target Decoder解码的特征ftH‘输入MLP,生成下一步的查询特征:

由Reference Decoder解码的特征 f t − 1 H f_{t−1}^H ft−1H被输入一个MLP头,以生成点图和置信度(同时也从 f t H ’ f_{t}^H’ ftH’生成一个点图和信心,仅供监督):

memory编码。Reference Decoder的特征和预测点图用于对存储器key和value特征进行编码:

由于memory key和value特征同时具有来自几何特征和视觉特征的信息,因此它可以实现基于外观和距离的memory readout
讨论。 与DUSt3R [81]相比,我们的架构有一个更轻量级的内存编码器和两个MLP头,用于编码查询、内存密钥和内存值特性。对于解码器,DUSt3R [81]包含两个解码器——一个参考解码器重建标准坐标系中的第一个解码器,和一个目标解码器重建第一个图像的第二个解码器。相反,我们在DUSt3R [81]中重新使用了这两个解码器。目标解码器主要用于产生查询存储器的特征,而参考解码器从存储器中提取融合的特征进行重构。在初始化方面,我们直接使用了两个视觉特征。
空间记忆。 图4显示了空间内存的概述,包括密集的工作内存、稀疏的长期内存和从内存中提取特征的内存查询机制。

空间存储器存储所有键的 f K ∈ R B s × ( T ⋅ P ) × C f^K∈R^{Bs×(T·P)×C} fK∈RBs×(T⋅P)×C和key的 f V ∈ R B s × ( T ⋅ P ) × C f^V∈R^{Bs×(T·P)×C} fV∈RBs×(T⋅P)×C特征。为了计算融合特征 f t − 1 G f^G_{t−1} ft−1G,使用查询特征 f t − 1 Q f^Q_{t −1} ft−1Q∈ R B s × P × C R^{Bs×P×C} RBs×P×C进行交叉注意力,实现内存读取:

注意图 A A A包含了当前查询中的每个token相对于内存key中的所有token的一个密集的注意权重(见图8)。我们在训练过程中应用了0.15的注意退出,以鼓励模型从记忆值的一个子集中推理几何形状。

效果。

3、DoubleTake:几何引导深度估计 Geometry Guided Depth Estimation(ECCV 2024)
来源:1Niantic 2University College London
代码:https://github.com/nianticlabs/doubletake
摘要:从一系列带pose的RGB图像中估计深度是一项基本的计算机视觉任务,在增强现实、路径规划等领域有应用。先前的工作通常利用多视图立体框架中的先前帧,依赖于在局部邻域中匹配纹理。相比之下,我们的模型通过向我们的网络提供最新的3D几何数据作为额外输入来利用历史预测。这种自生成的几何提示可以对关键帧未覆盖的场景区域的信息进行编码,与之前帧的单个预测深度图相比,它更加正则化。我们引入了一种Hint MLP,它将代价体特征与先验几何的提示相结合,从当前相机位置渲染为深度图,并对先验几何的置信度进行度量。我们证明,我们的方法可以以交互速度运行,在离线、增量和重访评估场景中实现了最先进的深度估计和3D场景重建。

我们的主要贡献是将廉价的元数据注入到特征卷中。然后,在输入到2D成本体积编码器-解码器之前,每个体积单元与MLP并行缩减为特征图。我们还使用了一个图像编码器,专门用于在成本体积编码器-解码器中在整个帧中传播和校正成本体积的深度估计时,强制执行强图像先验。该公式灵活,允许三种不同的操作模式:1)增量在线深度和重建,每帧76.6ms;2)离线高质量离线深度和重建的,每场景13.8s;3)在长时间缺席后重访位置时,以每帧62.8ms的速度重访深度估计。

几何注入。通过匹配的MLP,我们的功能量减少到成本量。然后,我们的Hint MLP将多视图立体成本量与先前预测的几何体的估计相结合。对于成本体积中的每个位置,Hint MLP将以下内容作为输入:(i)视觉匹配得分,(ii)几何提示,由渲染的深度提示与该成本体积位置处的深度平面之间的绝对差形成,以及(iii)该像素处提示的置信度估计。
4、Robust 3D GS:矫正相机参数偏差
标题:Robust 3D Gaussian Splatting for Novel View Synthesis in Presence of Distractors
代码:https://github.com/paulungermann/Robust3DGaussians
项目主页:https://paulungermann.github.io/Robust3DGaussians/
Robust 3D GS 解决了 3DGS 的常见误差源,包括模糊、不完美的相机姿态和颜色不一致,目的是提高对手机捕获重建等实际应用的鲁棒性。我们的主要贡献包括将运动模糊建模为相机姿态上的高斯分布,使我们能够以统一的方式解决相机姿态细化和运动模糊校正问题。此外,我们提出了散焦模糊补偿机制,并解决了由环境光、阴影或与相机相关的因素(如变化的白平衡设置)引起的颜色不一致问题。该方案与3DGS配方无缝融合,同时保持其在训练效率和渲染速度方面的优势。我们在相关基准数据集(包括Scannet++和Deblur NeRF)上进行了实验验证,获得了最先进的结果,从而在相关基线上实现了持续的改进。


5、Efficient Relighting with Triple Gaussian Splatting(精度luo)
https://gsrelight.github.io/
Efficient Relighting with Triple Gaussian Splatting
基于空间和角度高斯的表示和三重溅射过程,用于从多视点照明输入图像进行实时、高质量的新型照明和视图合成,朗伯光照模型加上角度高斯的混合作为每个空间高斯的有效反射函数。单个商用 GPU 上实现了 40-70 分钟的训练时间和 90 fps 的渲染速度,这个速度提升比之前方法大不少。


6、StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal(精度luo)
https://stable-x.github.io/StableNormal/
StableNormal: Reducing Diffusion Variance for Stable and Sharp Normal
@克服地心引力 基于大模型扩散先验,减少推理方差,从而产生“稳定”和“清晰”的法线估计,即使在具有挑战性的成像条件下,例如极端照明、运动/散焦模糊和低质量/压缩图像。好的normal是平面估计和meshing的最基础。


7、Infinigen: Infinite Photorealistic Worlds Using Procedural Generation
https://github.com/princeton-vl/infinigen
Infinigen: Infinite Photorealistic Worlds Using Procedural Generation
室内场景生成任务的infinigen开源了

8、Self-Evolving Depth-Supervised 3D Gaussian Splatting from Rendered Stereo Pairs
https://arxiv.org/pdf/2409.07456
《Self-Evolving Depth-Supervised 3D Gaussian Splatting from Rendered Stereo Pairs》
自监督方法,在一个粗糙GS模型上,通过投影双目视图 + 深度估计 + 精细优化的简单方法,无额外信息实现模型精度提升,考虑到精细建模



9、CSS: Overcoming Pose and Scene Challenges in Crowd-Sourced 3D Gaussian Splatting(鲁棒性)
https://arxiv.org/pdf/2409.08562
《CSS: Overcoming Pose and Scene Challenges in Crowd-Sourced 3D Gaussian Splatting》
面向众包采集的图像进行无姿态场景重建的问题。解决相机姿势缺失、视点有限和光照不一致的问题。
CSS 通过强大的几何先验(视角观测置信度)和先进的照明建模来解决这些问题,从而在复杂的现实条件下实现高质量的新颖视图合成。@殺生丸 浪潮项目能用到,GS in the wild的改进。


10、GS-Net: Generalizable Plug-and-Play 3D Gaussian Splatting Module(质量)
https://arxiv.org/abs/2409.11307
GS-Net,一种可通用的、即插即用的 3DGS 模块,可以从稀疏的 SfM 点云中推理生成致密高斯椭球,从而增强几何结构表示。GS-Net是第一个具有跨场景泛化能力的即插即用3DGS模块。

11、GStex:独立解耦Texturemap,提升纹理表示
项目主页:https://lessvrong.com/cs/gstex/
标题:GStex: Per-Primitive Texturing of 2D Gaussian Splatting for Decoupled Appearance and Geometry Modeling
类似Mesh,给每个Splat赋予独立解耦的Texturemap,提供更加精准的纹理表示能力,同时可以提升编辑时的精细度。比较有想法的一个工作,@克服地心引力 兴刚可以关注一下


12、Spectral-GS: Taming 3D Gaussian Splatting with Spectral Entropy(对抗伪影)
https://arxiv.org/abs/2409.12771
Spectral-GS: Taming 3D Gaussian Splatting with Spectral Entropy
研究目标与Mip-GS相同,为解决3DGS对高频信息、如needle伪影的拟合和采样问题,提出基于谱分析、信息熵估计的3D形状感知分割和2D视图一致滤波策略,提升高频细节与抗伪影、anti-aliasing能力。



13 CityGaussianV2: 先验的大场景 Geometrically Accurate Reconstruction
https://dekuliutesla.github.io/CityGaussianV2/
CityGaussianV2: Efficient and Geometrically Accurate Reconstruction for Large-Scale Scenes

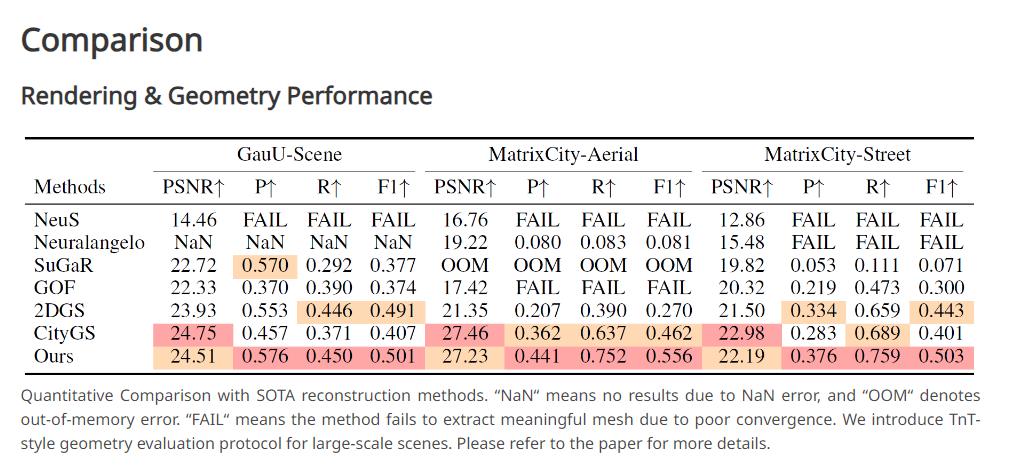
结合DepthAnything深度估计模型、2DGS等方法升级Citygaussian,在几何重建方面提升较大,已开源
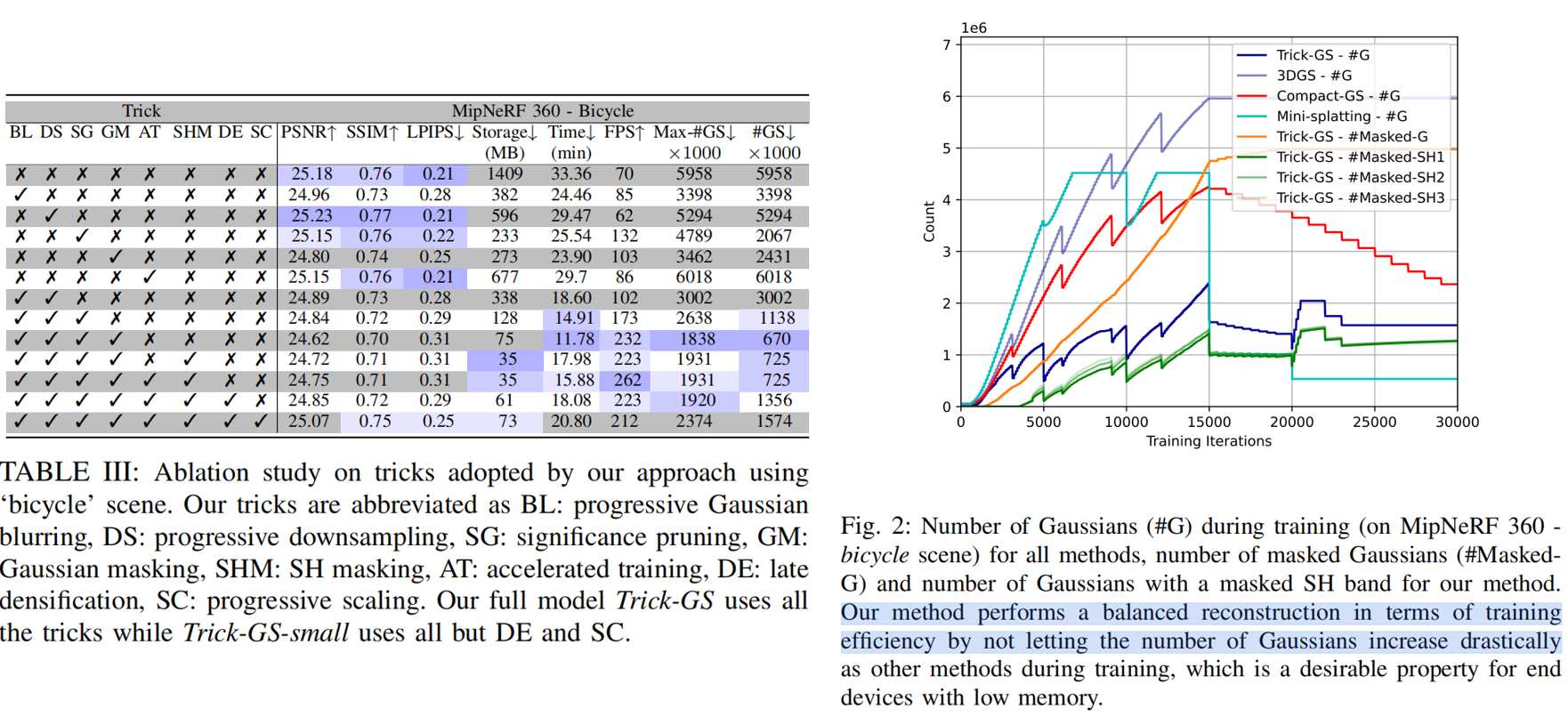
14.Trick-GS
摘要。为了向设备友好型GS迈出一步,我们对高效生成GS管道的各种方法进行了原则性的分析。这些方法包括高斯剪枝[6]、渐进式训练[8]、[9]、模糊[8]和球谐函数的mask[10]。经过仔细的探索,我们提出了Trick-GS,这是一种通过系统地结合这些方法而创建的GS方法。Trick-GS在多个基准数据集上具有与普通GS和其他紧凑GS方法相当的精度,与其他方法相比,拥有2×的训练速度,40×更小的磁盘尺寸和2×的渲染速度。此外,Trick-GS是灵活的,人们可以调整设计,以确定管道的不同方面的优先级,如收敛和渲染速度、准确性和磁盘大小。
1.根据体积裁剪(Pruning with Volume Masking)
较小scale的高斯往往对整体质量的影响很小,需要学习mask和去除这种高斯。简而言之,学习N个高斯的N个二进制掩码, M ∈ M∈ M∈{0,1} N ^N N,应用于不透明度 α ∈ α∈ α∈[0,1] N ^N N,和非负的scale属性, s ∈ R + N × 3 s∈R^{N×3}_+ s∈R+N×3。然后对学习到的mask进行阈值处理,生成hard mask M:

其中,ϵ为掩蔽阈值,sg为停止梯度算子,1(·)和σ(·)分别为指示函数和s型函数。训练中,高斯在稠密化阶段使用这些mask进行裁剪,并在稠密化阶段后的每 k m k_m km次迭代中进行裁剪。
2.根据重要性裁剪(Pruning with Significance of Gaussians)
找到并删除对总体影响很小的高斯,高斯的影响是通过考虑它被光线击中的频率来决定的。更具体地说,所谓的重要性得分计算为 1 ( G ( X j ) , r i ) 1(G(X_j),r_i) 1(G(Xj),ri),其中 1 ( ⋅ ) 1(·) 1(⋅)是指标函数, r i r_i ri是训练集中每条射线i,Xj是高斯j命中ri的次数。然后这个分数与高斯的体积和不透明度在等式4。
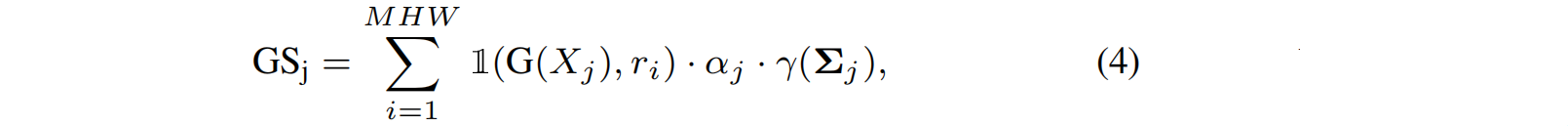
其中 j j j为高斯索引, i i i为像素, γ ( Σ j ) γ(Σ_j) γ(Σj)为高斯体积,M、H和W表示视图数量、图像宽高。然后,通过标准化所有排序高斯函数中高斯体积的前90%,以避免过度的浮动高斯分布。这个显著性得分用于在训练期间修剪预设的高斯函数的百分位数。由于这是一个昂贵的操作,我们在训练中使用这种修剪 k s g k_{sg} ksg次,考虑到上一轮中删除的百分比因数。
3.球形谐波(SH)mask
SHs被用来表示高斯的视图相关颜色,然而,并不是所有的高斯 have the same levels of varying colors depending on the scene(大致意思是不是所有高斯都是degree 3级这么高阶)。采用[End-to-end rate-distortion optimized 3d gaussian representation]策略,根据训练过程中学习到的mask 对SH band进行裁剪,并在训练完成后去除不必要的band。具体来说,每个高斯人在每个SH波段学习一个掩模。SH掩模的计算方法为等式如果对应的SH波段l的第i个高斯值值为零,则它的硬掩模Msh l i值为零,否则为不变。
mask计算与最终颜色渲染为:
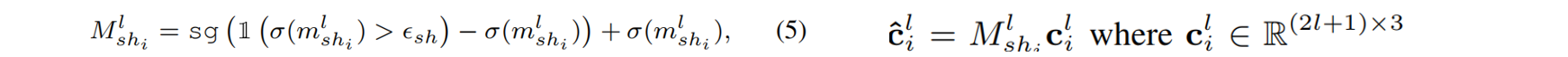
4.渐进式训练
高斯分布的渐进训练是指从较粗糙、较不详细的图像表示开始,逐渐将表示变回原始图像。该方法已被证明是一种正则化方案[8][9],用于高斯分布的稠密化和裁剪,因为从SfM点云中对高斯分布的初始化可以是次最优的。三种策略:
by blurring 。高斯模糊用于改变图像中的细节level。核大小在每 k b k_b kb次迭代时根据衰减因子逐步降低。该策略有助于从高斯分布的次优初始化中去除浮动伪影,并作为一种正则化来收敛到一个更好的局部最小值。它也显著地影响了训练时间,因为一个较粗的场景表示需要更少的高斯数来表示场景
by resolution 从较小的图像开始,在训练期间逐步提高图像分辨率,以帮助学习更广泛的全局信息[8][9]。这种方法特别帮助学习前景对象后面像素的更细粒度细节。

r
e
s
(
i
)
res(i)
res(i)为第i次训练迭代时的图像分辨率,
r
e
s
s
res_s
ress为起始图像分辨率,
r
e
s
e
res_e
rese为全训练图像分辨率,
τ
r
e
s
τ_{res}
τres为阈值迭代。
by scales of Gaussians. 另一种策略是,在栅格化阶段,通过控制低通滤波器,在训练的早期阶段关注低频细节。如果每个三维高斯按照下式投影,一些高斯可能会小于单个像素,从而导致artifacts。协方差 Σ i ′ Σ'_i Σi′替换为 Σ i ′ + s I Σ'_i+sI Σi′+sI(在对角线元素中添加一个小值,s = 0.3,I是一个单位阵)。
优化过程中逐步改变每个高斯在的s,以确保每个高斯在在屏幕空间中覆盖的最小面积。在优化的开始阶段使用较大的s可以使高斯分布从更宽的区域接收梯度,因此可以有效地学习场景的粗结构。值s保证投影高斯面积大于9πs,证明请参考[28],s定义为s = HW/9πN,其中N、H和W分别表示高斯数、图像高度和宽度。随着高斯数的增加,该策略的下界为默认值为s = 0.3。我们从SfM初始化的20%的3D点开始优化,它具有最小的误差,以帮助更有效的训练。
5.3DGS的加速训练
在栅格化过程中,从第0波段分离出较高的SH波段(separating higher SH bands from the
0
t
h
0^{th}
0th band),从而降低了较高的SH波段的更新次数。SH波段(45个dims)覆盖了这些更新的很大一部分,其中它们仅用于表示与视图相关的颜色变化。[23]修改光栅化器,从散射中分离出SH band(modifies the rasterizer to split
SH bands from the diffused color)。SH波段每16次迭代更新一次,其中散射颜色在每一步更新一次。为了加快训练速度,我们进一步用优化的CUDA内核修改了SSIM损失计算[23]。SSIM按标准配置为11×11高斯核卷积,其中优化版本是用两个较小的一维高斯核替换较大的二维核得到的。SSIM指标是用卷积输出的 a fused kernel计算的。对更高的SH波段应用较少的更新次数和优化SSIM损失计算对精度的影响可以忽略不计,而有助于加速训练时间。
损失定义为(只有 Gaussian 和 SH masking是可学习的):
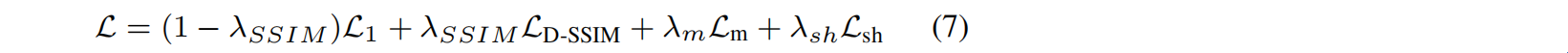
实验
实验设置。15个场景来自有界和无界的室内/室外场景;9个来自MipNeRF360,2个(卡车和火车)来自Tanks&Temples和2个(德约翰逊和游戏室)来自Deep Blending数据集。每个数据集中的每8张图像用于测试。模型经过30K次迭代的训练,并使用PSNR、SSIM和LPIPS 进行评估。
应用了一个简单的后处理,在训练后使用半张量存储所有16位精度的高斯参数,因为我们发现精度下降是不显著的。所有实验在NVIDIA RTX 3090上。
我们将图像降采样8×,并通过对数衰减逐渐增加到原来的分辨率,直到19500年迭代。类似地,我们对从9×9和σ = 2.4开始的训练图像应用高斯模糊,每 k b = 100 k_b =100 kb=100次迭代逐渐减少,直到19500次迭代。
ABE split 和渐进尺度策略用于10K迭代。之后,标准稠密化在每100次迭代中启用,直到迭代至15K。每100次迭代中的20K到20.5K的之间进行稠密化,以帮助模型恢复the loss that is from pruning of false-positive Gaussians。学习率分别为0.5和0.05,用于学习高斯掩模和SH掩模。选择损失权值和掩模阈值 λ m = λ s h = ϵ m = 0.05 λ_m = λ_{sh} =ϵ_m=0.05 λm=λsh=ϵm=0.05和 ϵ s h = 0.1 ϵ_{sh}=0.1 ϵsh=0.1。使用高斯掩模在每个致密化步骤和致密化停止后的每500次迭代中进行高斯化修剪
基于重要性评分的高斯剪枝应用6次,直到迭代22K,第一次剪枝率设置为60%,下一次迭代使用剪枝衰减因子为0.7
模型Trick-GS-small压缩了23×模型大小,训练时间和FPS分别提高了1.7×和2×。然而,这导致了准确性的轻微损失;模型Trick-GS使用后期的稠密化和渐进的基于尺度训练,不牺牲准确性
与Trick-GS-small相比,Trick-GS将PSNR平均提高了0.2 dB,存储空间减少了50%,训练时间减少了15%。


二、提升几何(与mesh、SDF联合优化方法)
1 MeshGS:自适应Mesh-对齐的GaussianSplatting高质量渲染
论文:https://arxiv.org/pdf/2410.08941
标题:MeshGS: Adaptive Mesh-Aligned Gaussian Splatting for High-Quality Rendering
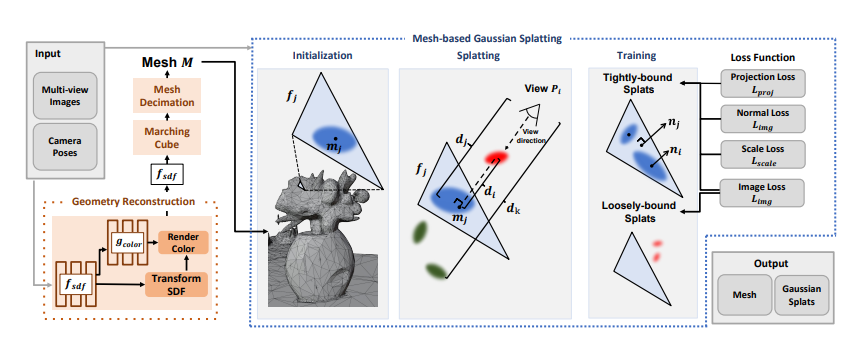
联合使用Mesh与GS实现高质量渲染,根据SDF等距离推理信息区分紧凑与松散的Splats,并自适应的绑定Mesh面片与Splats,同时在渲染时合理的选取用Mesh还是Splats进行3D场景不同区域的显示(低频用Mesh、高频用Splats)
2.0-水平集上联合抽取Splats与SDF场
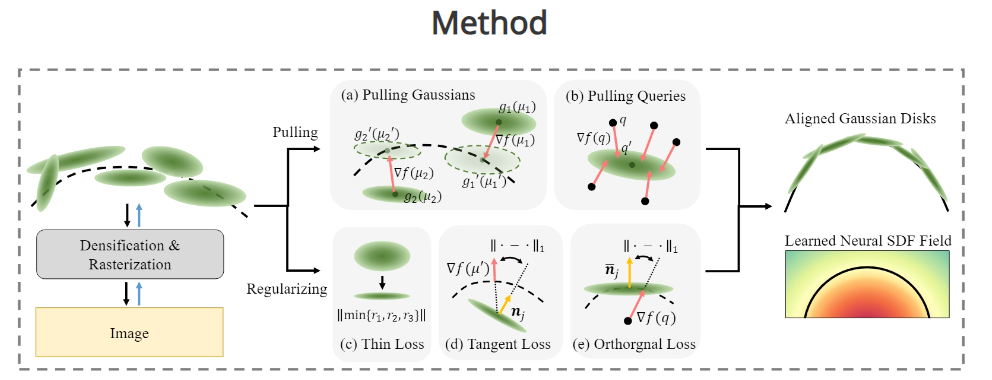
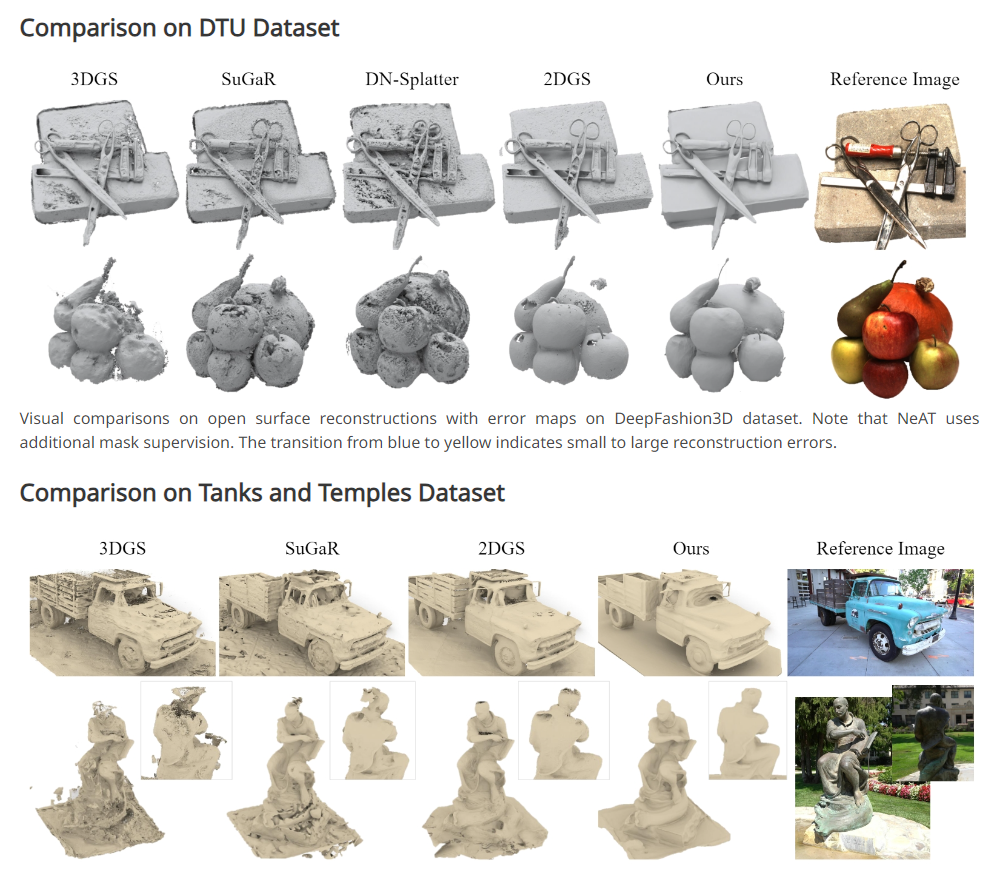
https://wen-yuan-zhang.github.io/GS-Pull/
Neural Signed Distance Function Inference through Splatting 3D Gaussians Pulled on Zero-Level Set
在0-水平集上联合抽取Splats与SDF场,在GS建模的基础上改善表面重建的效果
3.FeatureGS
FeatureGS,它将一个基于特征值导出的三维形状特征的附加几何损失项合并到3DGS的优化过程中。目的是提高局部三维邻域的几何精度,提高平面表面结构熵的性质。我们提出了基于高斯分布的“平面性planarity”,以及高斯邻域的“平面度planarity”、“全方差omnivariance”和“特征熵eigenentropy”的几何损失项的四种可选公式。我们对DTU基准数据集的15个场景进行了定量和定性的评估,重点关注以下关键方面:几何精度和伪影减少,由倒角距离测量,和内存效率,由高斯的总数评估。此外,渲染质量是由峰值信噪比监测的。FeatureGS在几何精度方面提高了30%,减少了90%的高斯数,并抑制了浮动伪影,同时保持了可比的光度渲染质量。高斯函数的“平面性”几何损失提供了最高的几何精度,而高斯邻域的“全方差”最多地减少了漂浮物的人为因素和高斯函数的数量。这使得FeatureGS成为一种几何精确、伪影减少和记忆有效的三维场景重建的强方法,从而能够直接使用高斯中心进行几何表示。
3.2 Geometric Loss
基于特征值推导出的三维形状特征,我们引入了四种不同的新型附加几何损失项,以增强三维高斯分布本身和邻域高斯分布中心的特定性质(见图2)。对于 第一种方法,目标是压平(flatten)高斯 ,以实现高斯中心的高几何精度。这是通过将几何损失项中每个高斯值本身的特征值(scale)(图3a)的三维形状特征“平面性”来实现的; 对于第二种方法,使用协方差矩阵(每个高斯中心的k(kNN)最近邻(图3b)的三维形状特征 ,加入一个基于邻域的几何损失项。为了增强与Manhattan-Word-Assumption一致的人造物体局部三维结构的具体表征,我们加强了平面表面的优势和结构熵(predominance of planar surfaces, structural entropy)。这是通过高斯邻域三维形状特征“平面性”、“全方差”和“特征熵”来完成的,即planarity,omnivariance以及eigenentropy。

3.2.1 Covariance Matrix
高斯。3DGS是一种场景的显式三维表示,每个点的特征是缩放、旋转和颜色,包括不透明度。缩放分量可以类似于协方差矩阵的三个特征值 s 1 ≥ s 2 ≥ s 3 ≥ 0 s_1 ≥ s_2 ≥ s_3 ≥ 0 s1≥s2≥s3≥0,旋转分量可以解释为协方差矩阵的特征向量 ( ε 1 、 ε 2 、 ε 3 ) (ε_1、ε_2、ε_3) (ε1、ε2、ε3)。通过使用高斯协方差矩阵的归一化特征值(尺度)(图3a),我们计算了三维形状特征。
高斯邻域。三维空间中高斯的中心点 p 0 p_0 p0,它的k近邻{ p 1 , p 2 , . . . , p k p_1,p_2,...,p_k p1,p2,...,pk}。该邻域的质心,以及邻域(图3b)的协方差矩阵计算为:

3.2.2 Eigenvalue Normalization 特征值归一化

然后将归一化的特征值
s
1
′
s
2
′
s
3
′
s'_1s'_2s'_3
s1′s2′s3′和
λ
1
′
λ
2
′
λ
3
′
λ'_1λ'_2λ'_3
λ1′λ2′λ3′按降序排列
3.2.3 Gaussians Geometric Loss
平面性度量了高斯分布与平面结构相似的程度;平面性高斯损失,偏向于高平面性:


3.2.4 Gaussians Neighborhoods Geometric Loss
为了增强人造物体的三维点云所表现出的结构特性,我们使用每个点的k-近邻合并了一个基于邻居的几何损失。通过几何邻域损失,实现了局部邻域中具有减少的结构熵的平面表面的表征。
Neighborhood Planarity。 与保持单个高斯的平面性类似,我们希望根据Manhattan-Word-Assumption和其他(几乎)平面表面来增强人造物的性质,并抑制高斯在邻域内的球面扩散。因此,除了高斯分布的平面性外,我们还利用邻域的平面性,以及对应的neighborhood planarity loss:

Neighborhood Omnivariance。 全方差表示邻域的体积,并表示点是否分散在局部各个方向上,是点云分类的一个高度相关的特征。最小化邻域全方差损失,能减少点的局部分散:

Neighborhood Eigenentropy。 特征熵通过基于归一化特征值测量局部三维邻域内的熵来量化邻域点局部结构的有序/无序性,是一个很好的三维特征来表征平面点云结构。特征熵和邻域特征熵损失定义如下,最小化邻域特征熵损失有利于最小化无序性,从而降低三维点的熵

3.3 光度-几何损失

三、 稀疏重建、生成式
1、Splatt3R:两张图像的零样本高斯(Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs)(稀疏重建 )
来源:1 Active Vision Lab, 2 Visual Geometry Group --University of Oxford
代码:https://splatt3r.active.vision/

Splatt3R,这是一种无姿态的前馈方法,用于野外3D重建和从立体对合成新的视图。给定未校准的自然图像,Splatt3R可以预测3D高斯splats,而不需要任何相机参数或深度信息。为了通用性,简单地在一个大规模的预训练“foundation”3D MASt3R模型中添加一个高斯解码器,将其扩展到处理3D结构和外观。具体来说,与仅重建3D点云的原始MASt3R不同,我们预测了为每个点构建高斯基元所需的额外高斯属性。因此,与其他新颖的视图合成方法不同,Splatt3R首先通过优化3D点云的几何损失来训练,然后是新视图的综合目标。通过这样做,我们避免了在从立体视图训练3D高斯时出现的局部最小值。我们还提出了一种新的损失mask策略,这对于外推视角至关重要。实验在ScanNet++数据集上训练Splatt3R,并对未校准的野生图像进行了出色的泛化。Splatt3R可以以512 x 512分辨率以4FPS重建场景,并且可以实时渲染生成的splat。

我们使用视觉变换器编码器同时对每个图像进行编码,然后将它们传递给Transformer解码器,该解码器在每个图像之间执行交叉注意。通常,MASt3R有两个预测头,一个用于预测像素对齐的3D点和置信度,另一个用于特征匹配。我们引入了第三个头来预测每个点的协方差(由旋转四元数和尺度参数化)、球谐函数、不透明度和平均偏移。这使我们能够为每个像素构建一个完整的高斯基元,然后我们可以对其进行渲染以进行新颖的视图合成。在训练过程中,我们只训练高斯预测头,依赖于预训练MASt3R模型来做其他参数。
为了优化我们的高斯参数预测,我们监督预测场景的新视图渲染。在训练过程中,每个样本由两个输入的“上下文”图像组成,我们使用它们来重建场景,以及一些带pose的“目标”图像,用于计算渲染损失。这些目标图像中的一些可能包含场景的区域,这些区域由于被遮挡或位于其平截头体之外而对两个上下文视图不可见。为了解决这个问题,我们只监督渲染中包含与上下文图像中的像素之一直接对应的像素的区域。这使我们能够从不一定是两个输入图像之间的插值的视角来监督我们的渲染。
细节
提出背景: 大多数现有的可推广的3D-GS方法的一个显著局限性是,它们只监督输入立体视图[7,10]之间的新视点,而不是学习推断到更远的视点。这些外推观点的挑战是,他们经常看到的点被输入相机视图模糊,或者完全在他们的截锥体之外。因此,监督这些点的新视图呈现损失是适得其反的,并可能对模型的性能造成破坏。通过只监督位于两个上下文图像之间的视图的新视图渲染丢失,现有的工作避免了试图重建场景中许多看不见的部分。然而,这意味着该模型没有经过训练来准确地为超出立体基线的视图生成新的视图渲染
为了解决这个问题,我们采用了一种基于 frustum culling(截锥体裁剪)和covisibility testing的损失mask策略,使用训练中已知的地面真实姿态和深度图进行计算。我们只将均方误差和LPIPS损失应用于渲染中可以可行地重建的部分,从而防止了从场景中不可见的部分更新到我们的模型。
MASt3R训练。给定真实pointmap X 1 X^1 X1和 X 2 X^2 X2,对于每个视图v∈{1,2}中的每个有效像素i,训练目标 L p t s L_{pts} Lpts定义为:


Pixel Splat[7]和MVSplat [10]都使用前馈的、交叉注意的网络架构来提取输入视图之间的信息。其次,MASt3R预测每个图像的像素对齐的3D点(和置信度),而可推广的3D-GS模型预测每个图像的像素对齐的三维高斯分布。
给定一组未校准的图像 I I I,MASt3R使用ViT对其编码,再传递给解码器,在每个图像之间执行交叉注意。MASt3R有两个预测头,一个预测每个像素的一个3D点(x)和置信度©,另一个用于特征匹配(这里没用到); 本文引入了第三个“高斯头”,预测了每个点的协方差(由旋转四元数 q ∈ R 4 q∈R^4 q∈R4和尺度 s ∈ R 3 s∈R^3 s∈R3参数化)、球面谐波( S ∈ R 3 × d S∈R^{3×d} S∈R3×d)和透明度(α∈R),并预测了每个点的偏移量( ∆ ∈ R 3 ∆∈R^3 ∆∈R3),将高斯原语的均值参数化为µ=x+∆: 为每个像素构造一个完整的高斯原语,再对其渲染合成新视图。 只训练高斯预测头(DPT架构[45]),其他参数依赖于预训练MASt3R模型。
为了帮助学习高频颜色,我们试图预测每个像素的颜色和我们应用于该像素对应的高斯原语的颜色之间的残差。训练中每个样本由两张“上下文”图像,用于重建场景,以及一些带pose的“目标”图像,用于计算渲染损失。
未见区域的loss mask。“目标”图像可能包含场景的一些区域,由于被遮挡,两个上下文视图不可见,或完全在上下文视图之外。监督未见的像素的渲染损失,会适得其反,并对模型的性能造成潜在的破坏。现有的可推广的前馈辐射场预测方法试图通过只合成输入立体视图[7,10,16]之间的新视图来避免这个问题,从而减少了需要重建的不可见点的数量。相反,我们试图训练我们的视角到更远的地方,而不是两个输入图像之间的插值。
计算每个“目标”图像中,哪个像素在至少一个上下文图像中是可见的。反投影其中的每个点,到每个上下文图像上,检查渲染的深度是否与地面真实深度密切匹配。例子如图3。最终的mask重建损失为:


效果


预处理计算了训练集中每个场景的图像重叠mask:第二图像中至少ϕ%的像素在第一图像中具有直接对应,并且目标图像至少ψ%的像素出现在至少一个上下文图像中。
训练分割中的每个场景中随机抽取2张输入图像和3张目标图像。使用我们在ϕ= ψ = 0.3中设置的ϕ和ψ参数来选择视图。我们使用λMSE = 1.0和λLP IP S = 0.25,以分辨率为512×512对模型进行2000个周期(≈50万次迭代)的训练。我们使用在1.0×10−5的学习速率下的Adam优化器进行优化,权重衰减为0.05,梯度剪辑值为0.5

2、GenWarp: 语义保留的单张图像生成3D(GenWarp: Single Image to Novel Views with Semantic-Preserving Generative Warping)(稀疏重建 )
代码:https://genwarp-nvs.github.io/
来源:1Sony AI 2Sony Group Corporation 3Korea University
针对Scene的Sparsefusion(VLDM)来了,单视图通过生成式模型生成Few View,通过Splatter3R / Instantsplat等稀疏GS方法实现场景建模

最近将大规模文本到图像(T2I)模型与单目深度估计(MDE)相结合的研究在处理野生图像方面显示出了希望。在这些方法中,输入视图被几何扭曲为具有估计深度图的新视图,然后扭曲的图像被T2I模型修复。然而,当将输入视图扭曲为新的视点时,它们会与嘈杂的深度图和语义细节的丢失作斗争。在这篇论文中,我们提出了一种新的单目新视图合成方法,这是一种语义保持的生成扭曲框架,通过用自注意力增强交叉视图注意力,使T2I生成模型能够学习在哪里扭曲和在哪里生成。我们的方法通过在源视图图像上调节生成模型并结合几何扭曲信号来解决现有方法的局限性。定性和定量评估表明,我们的模型在域内和域外场景中都优于现有方法。
常见场景生成方法:
1.《Pixelsynth: Generating a 3d-consistent experience from a single image》. IEEE/CVF 2021.
2.《Simple and effective synthesis of indoor 3d scenes》.AAAI 2023.
3.《Geometry-free view synthesis: Transformers and no 3d priors》. IEEE/CVF 2021.
4.《Long-term photometric consistent novel view synthesis with diffusion models》. 2023 IEEE/CVF / ICCV 2023.
5.《Luciddreamer: Domain-free generation of 3d gaussian splatting scenes》arXiv 2023.
3、ReconX: 用视频扩散模型从稀疏视图重建任意场景(Reconstruct Any Scene from Sparse Views with Video Diffusion Model)(生成式 )
主页:https://liuff19.github.io/ReconX/
代码:soon
来源:Tsinghua University, 2HKUST

它将模糊的重建挑战重新定义为时间生成任务。关键的见解是释放大型预训练视频扩散模型的强生成先验,用于稀疏视图重建。然而,在预训练模型直接生成的视频帧中,3D视图的一致性很难被准确地保持。为了解决这个问题,在输入视图有限的情况下,提出的ReconX:首先构建一个全局点云,并将其编码到上下文空间中作为3D结构条件。在条件的指导下,视频扩散模型然后合成既保留细节又表现出高度3D一致性的视频帧,确保场景从各个角度的连贯性。最后,我们通过置信度感知的3D高斯散点优化方案从生成的视频中恢复3D场景。对各种真实世界数据集的广泛实验表明,我们的ReconX在质量和可推广性方面优于最先进的方法。
4、LM-Gaussian:大模型先验的稀疏重建
LM-Gaussian: Boost Sparse-view 3D Gaussian Splatting with Large Model Priors

三维高斯喷溅对稀疏视角的高质量三维重建, 主要有三个障碍。1)初始化失败: 3DGS严重依赖于预先计算出的相机姿态和点云来初始化高斯球体。然而,传统的结构运动(SfM)技术,由于输入图像之间的重叠不足,[60]无法成功处理稀疏视图设置,因此对3DGS初始化产生不准确的相机姿态和不可靠的点云。2)对输入图像的过拟合:由于缺乏足够的图像提供约束,3DGS往往对稀疏输入图像进行过拟合,从而产生具有严重伪影的新合成视图。3)缺乏细节:由于有限的多视图约束和几何线索,3DGS总是无法恢复捕获的3D场景和未观测区域的细节,这显著降低了最终的重建质量。
本文三个目标:
1)鲁棒初始化;DUSt3R是一个综合的立体模型,以成对的图像作为输入,直接生成相应的三维点云。通过全局优化过程,从输入图像中获得摄像机姿态,并建立全局配准点云。然而,由于DUSt3R对前景区域的固有偏差,全局点云经常在背景区域出现伪影和飞蚊。为了缓解这个问题,我们引入了一个背景感知深度引导的初始化模块。最初,我们使用深度先验来细化由DUSt3R产生的点云,特别是在场景的背景区域。此外,我们采用迭代滤波操作,通过进行几何一致性检查和基于置信度的评估来消除不可靠的三维点。
2)防止过拟合;稀疏视图使用photo-metric 损失会使3DGS对输入图像进行过拟合。本文引入了多个几何约束来规范3DGS的优化:首先加入了一个多尺度的深度正则化项,以鼓励3DGS同时捕获深度先验的局部和全局几何结构。其次,引入了一个余弦约束的正态正则化项,以确保3DGS的几何变化与正态先验对齐。最后,使用加权的虚拟视图正则化项来增强3DGS对看不见的视图方向的弹性
3)细节保留:使用迭代高斯细化模块,基于扩散先验的修复模型,来恢复3DGS渲染的图像的高频细节。增强后的图像作为伪标签来优化3DGS(迭代地细化,将图像扩散先验逐步注入到3DGS中增强细节。具体来说,高斯修复模型是建立在加入Lora层的ControlNet中,利用稀疏输入图像对Lora层进行微调,使修复模型可以在特定的场景中很好地工作)。
细节:
1.鲁棒的初始化
共分为4个过程:a.相机位姿恢复。采用DUSt3R的方法,最小化点云投影损失 L p c L_{pc} Lpc。对所有图像对{ I k , I l I_k,I_l Ik,Il},以及 P k P_k Pk和 P l P_l Pl 代表第 k k k 个和第 l l l 个摄像机坐标系中的point map。为了评价第k坐标系三维点与第l坐标系三维点的一致性。投影损失包含变换矩阵 T k , l T_{k,l} Tk,l、一个比例因子 σ k , l σ_{k,l} σk,l和 P k P_k Pk。置信度map η k η _k ηk和 η l η_l ηl是权重。

b.深度引导优化。使用基于扩散模型的单目深度模型 Marigold,合并点云投影损失、多尺度深度损失和深度平滑性损失,将DUSt3R输出与深度引导进行合并。

L
o
p
t
L_{opt}
Lopt为总优化损失,平滑性损失
L
s
m
o
o
t
h
L_{smooth}
Lsmooth通过惩罚深度梯度的变化,促进深度图的平滑性,并通过图像梯度进行加权。
c.点云清理:为了消除floater和伪影,采用两种:geometry-based cleaning,

2.多模态正则化高斯重构(防止过拟合)
由三部分组成:a.Photo-metric (光度)损失:

b.多尺度深度正则化。使用单目深度估计模型Marigold,从稀疏图像预测深度图{
D
^
k
\hat{D}_k
D^k}
k
=
0
K
−
1
_{k=0}^{K−1}
k=0K−1,并使用PCC相关系数(Pearson Correlation Coefficient)衡量深度图之间相似性(量化两个数据集的线性相关性)。为了增强对局部结构的捕获,将深度图像划分为小块,每次迭代随机选择F个非重叠斑块来评估深度相关损失(后者为单目估计模型预测的深度图的第
f
f
f块):

c.余弦约束的法线正则化:深度提供了场景内的距离信息,但法线对于塑造曲面和确保平滑性也是必不可少,利用余弦相似度来量化从normal prior预测的normal map和使用高斯渲染的normal map之间的方差。先验来自[Repurposing diffusion-based image generators for monocular depth estimation, CVPR 2024]

d.虚拟视图正则化. 随机采样
K
v
K_v
Kv个虚拟视图,将点云投影到其二维平面上。采用加权混合算法将三维点渲染为RGB图像{
I
k
p
r
I^{pr}_k
Ikpr}
k
=
0
K
v
−
1
_{k=0}^{Kv-1}
k=0Kv−1,指导高斯优化。具体的,像素
i
i
i 的颜色由U个最近的投影3D点决定。如图5,根据半径π内与像素
i
i
i的接近程度来选择的,π被定义为像素宽度的三分之一。这些点按距离{
d
u
d_u
du}
u
=
0
U
−
1
_{u=0}^{U−1}
u=0U−1排列,并分配权重。靠近虚拟视点的三维点有更高的权重(背景为白色)。虚拟视图损失为:


多模态联合优化:

3.迭代高斯细化
a.迭代高斯优化。使用高斯核从虚拟视点生成 K v K_v Kv个图像,并利用高斯修复模型对这些图像进行均匀增强,得到修复后的图像{ I k r e p a i r e I^{repaire}_k Ikrepaire} k = 0 K v − 1 ^{Kv−1}_{k=0} k=0Kv−1。为了保持场景的一致性和减少潜在的冲突,去噪强度较低,每个修复过程中逐步向高斯渲染的图像重新引入有限的细节:

b.高斯修复模型。使用高斯修复模型,将模糊的高斯渲染图像增强为清晰、真实,同时保留风格和内容。

4.场景增强
扩散先验+GS建模一篇新,对稀疏视图中加入背景感知深度引导初始化模块、多模态正则化高斯重建模块、迭代高斯细化模块(大模型先验)提升稀疏重建的效果
5、Wonderworld:拓展图片边界,生成3D场景
项目:https://kovenyu.com/wonderworld/
论文:https://arxiv.org/pdf/2406.09394
《wonderworld Interactive 3D Scene Generation from a Single Image》
交互式3D 世界生成,根据用户的移动和内容请求以交互方式在10秒内生成 3D 场景



6、SplatFields: Neural Gaussian Splats for Sparse 3D and 4D Reconstruction(稀疏)
https://markomih.github.io/SplatFields/
SplatFields: Neural Gaussian Splats for Sparse 3D and 4D Reconstruction
splat
特征缺乏空间自相关性是导致 3DGS 技术在稀疏重建设置中性能不佳的因素之一。 通过结合Triplane与GS,提出了一种优化策略,将 splat 特征建模为相应隐式神经场的输出来有效地正则化它们。在静态和动态场景上都取得了较好的效果。


7、Dense Point Clouds Matter(稠密化)
https://arxiv.org/pdf/2409.08613
《Dense Point Clouds Matter: Dust-GS for Scene Reconstruction from Sparse Viewpoints》
基于Dust3R和单目深度估计,做稠密化init GS的又一篇文章,主要目标在稀疏视角下效果更好


8、3DTopia-XL:扩散模型辅助生成
项目:https://3dtopia.github.io/3DTopia-XL/
代码:https://github.com/3DTopia/3DTopia-XL
标题:3DTopia-XL: Scaling High-quality 3D Asset Generation via Primitive Diffusion
基于DiT与一种新式基元3D表示(PrimeX)的高质量 3D 资产生成方法,5秒生成PBR资产。该方法提出的PrimX 3D表示显式的将目标的3D形状和纹理、材质编码为一个紧致的N*D维张量,每个基元与其对应的形状曲面锚定,通过DiT生成。


9.3DGS-Enhancer: 通过视图一致2D Diffusion,提升无界3D Gaussian Splatting (NlPs2024 Spotlight)
3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors (NlPs2024 Spotlight)

链接:https://xiliu8006.github.io/3DGS-Enhancer-project/
标题:3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors (NIPS 2024 Spotlight)
通过视频生成扩散先验改进低质量3DGS建模的效果
10.L3DG:Latent 3D Gaussian Diffusion
https://arxiv.org/pdf/2410.13530
L3DG: Latent 3D Gaussian Diffusion
LDM的3DGS版本

四、 大场景
1、航空图像的大场景高斯重建(3D Gaussian Splatting for Large-scale 3D Surface Reconstruction from Aerial Images)(大场景 )
https://arxiv.org/pdf/2409.00381
大场景航拍GS建模,除了分块之外,引入了ray-tracing GS方法实现深度、法向量估计,结合多视角一致性约束,实现了与MVS方法接近的Meshing质量的同时、SOTA的GS渲染效果
2、大场景的分层表示(A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets)
https://github.com/renaissanceee/hierarchical-3d-gaussians

3D GS 训练和渲染所需的资源,限制了场景大小。本文引入了一个3D高斯层次结构,为非常大的场景保留了视觉质量,同时提供了一种高效的Level-of-Detail(LOD)解决方案,通过有效的level选择和level之间的平滑过渡,高效地渲染远处的内容。此外还引入了一种分而治之的方法,允许我们在独立的块中训练非常大的场景。我们将块合并到一个层次结构中,可以对其进行优化,以进一步提高合并到中间节点的高斯图像的视觉质量。非常大的捕获通常对场景的覆盖率很低,对原始的3D高斯飞溅训练方法提出了许多挑战;我们调整和规范培训,以解决这些问题。我们提出了一个完整的解决方案,可以实时渲染非常大的场景,并且由于我们的LOD方法,可以适应可用资源。我们使用简单且经济实惠的设备展示了多达数万张图像的捕获场景的结果,覆盖了长达数公里的轨迹,持续时间长达一小时。

细节1:LOD的实现策略(核心)
-
1.使用固定数量的,少量3DGS去优化整个场景,生成最初的高斯球
-
2.基于树结构,自底向上构建
-
3.每个节点代表一个3DGS基元,其中叶子结点是3DGS最初产生的高斯球,内部节点是融合后的3D高斯球
-
4.内部节点的要求:
a. 保持与叶节点相同的快速栅格化流程
b. 尽可能的描述子节点的外观 -
5.内部节点融合( μ μ μ、 ∑ ∑ ∑、 α α α、 S H SH SH):
a. 均值 μ μ μ和协方差 ∑ ∑ ∑,最小化加权3D KL散度(合并后的节点和其子节点之间)

其中 w i w_i wi是归一化后的权重,归一化前的原始权重 w i ′ w_i' wi′与每个子节点对其创建的父节点的贡献成正比。
b. 计算原始权重
w
i
′
w_i'
wi′(即每个高斯球的贡献)
i. 考虑一个独立的高斯球
g
i
g_i
gi,它对一个像素位置(x,y)的贡献(contribution)为:

g
i
g_i
gi对整张图像的贡献为:

细节2:cut选择和level转换
(一)cut选择
- 定义:给定某一视图V 时,选择树结构中的哪些节点进行渲染,这些被选择的节点的集合成为一个cut。
请注意,一个cut内的节点不一定都在同一个level,也就是树的同一层。 - 选择策略:给定一个视图V,选择那些保持渲染质量的同时,渲染速度最快的那些节点。
- 具体选择过程:
a. 定义节点n的粒度ε(n):一个节点n的粒度,是它在给定视图V上投影后在屏幕上的大小;
b. 取出一个节点中包含的所有叶子结点,将它们按照自身bbox的最长轴进行投影,计算投影后的尺寸大小是否小于给定的目标粒度 τ ε τ_ε τε;(如 1 pixel)
c. 如果节点n的粒度小于目标粒度,即 ε ( n ) ε(n) ε(n)< τ ε τ_ε τε ,但其父节点的粒度大于目标粒度,那么当前节点n就被选择在cut中,如图绿色轨迹所示。

(二)level转换(线性插值)
作用:实现层次间(父节点到子节点)的平滑过度。先生成两个与紫色具有相同属性的高斯球(α除外),然后分别插值到他们各自的属性。

(三)压缩
为了避免内存开销过大,以及,避免父节点尺寸仅仅比子节点稍微大一点点,这会导致这些节点很难被优化到。为了解决这个问题,作者对生成的树结构进行稀疏化。
- 将叶节点做标记,防止被删除;
- 在所有训练图像中,以目标粒度为3像素,寻找所有cut的集合成为cut1;
- 在集合cut1中找到最底层的节点,产生cut2,cut2中的节点就代表在所选粒度下,细节最丰富的节点;
- 删除叶节点和cut2节点之间的所有节点;
- 将目标粒度*2,重复上述过程,直到目标粒度达到一半像素。
3、3D Gaussian Splatting for Large-scale 3D Surface Reconstruction from Aerial Images(大场景)
https://arxiv.org/pdf/2409.00381
3D Gaussian Splatting for Large-scale 3D Surface Reconstruction from Aerial Images
大场景航拍GS建模,除了分块之外,引入了ray-tracing GS方法实现深度、法向量估计,结合多视角一致性约束,实现了与MVS方法接近的Meshing质量的同时、SOTA的GS渲染效果


6、GaRField++
https://arxiv.org/abs/2409.12774
GaRField++: Reinforced Gaussian Radiance Fields for Large-Scale 3D Scene Reconstruction
Garfield++,面向大场景航拍建模,对标citygaussian,三点改进:光线-高斯相交策略和新颖的高斯密度控制以提高学习效率,基于ConvKAN网络的外观解耦模块解决光照条件不均匀的问题在大型场景中,以及颜色损失、深度失真损失和法线一致性损失的细化最终损失,没有做分割


四、 加速与剪枝
1、实时高斯:通过光度SLAM加速3DGS(Towards Real-Time Gaussian Splatting: Accelerating 3DGS through Photometric SLAM)(加速 )
来源:滑铁卢大学
论文:https://arxiv.org/pdf/2408.03825
摘要。与传统的VSLAM相比,当前的3DGS集成降低了跟踪性能和运行速度。为了解决这些问题,我们建议将3DGS与单目光度SLAM系统直接稀疏测距相结合(integrating 3DGS with Direct Sparse Odometry, a monocular photometric SLAM system)。我们已经进行了初步实验,表明直接使用稀疏的里程计Odometry 点云输出,而不是标准的运动结构方法,可以显著缩短实现高质量渲染所需的训练时间。减少3DGS训练时间可以开发在移动硬件上实时运行的3DGS集成SLAM系统。
传统的VSLAM方法使用场景表示,如点云和占用网格,并不能完全捕捉场景。相比之下,3D高斯溅射(3DGS)[1]可以生成具有增强细节和真实性的场景。3DGS对VSLAM的首次应用,如SplaTAM [2],成功地使用实时单眼视频输入生成了3DGS场景。然而,与ORBSLAM3 [3]等传统VSLAM系统相比,它们的跟踪精度更低,运行速度更慢。这些挑战可能源于他们的跟踪方法的不同。传统的VSLAM通过跟踪连续图像上的特征点来计算姿态。相比之下,3DGS通过扩展3DGS优化到包括姿态,将3DGS纳入VSLAM
DUSt3R并不是产生高密度点云的唯一方法。我们的主要贡献是证明了单目光度或基于像素的VSLAM系统,如直接稀疏测量(Direct Sparse Odometry:DSO,类似于LOFTER,不使用特征点来做投影匹配)[7],可以产生高密度点云,加速3DGS训练。基于像素的SLAM系统跟踪高梯度像素而不是特征点,由于有更多的跟踪候选对象,因此会导致更密集的点云。我们进一步修改了DSO,以跟踪更多未用于姿态优化的像素,将点云密度增加到与DUSt3R相当的水平。我们做的实验表明,将修改后的DSO点云和姿态输入到3DGS中,而不是使用Colmap,可以显著提高训练时间,特别是在训练过程的早期。定性地说,3DGS的高质量渲染在一分钟内完成,如图1所示。此外,DSO以实时速度运行,这比典型的结构从运动系统更快。这一贡献对于使用3DGS的VSLAM系统尤其有利,其中速度是最重要的。

DSO和所做的修改的简化描述。DSO的工作原理是在连续的帧i和帧j中跟踪一组像素。它优化姿态p,使用下面的光度损失方程的每个像素:

其中I为像素强度,a和b是光度变量,s是曝光。这个函数在考虑照明变化时,找到最匹配帧
i
i
i 和帧
j
j
j 之间的像素变化.
通过跟踪高梯度像素,DSO可以为其地图创建密集的点云;然而,点选择是为跟踪性能而优化的,而不是最大化点密度。我们发现,在更密集的点云上,3DGS训练比通常为DSO的最佳跟踪设置生成的更快。为了在不影响跟踪的情况下提高3DGS的性能,我们修改了DSO,以包含不用于姿态跟踪的额外的点。
对DSO的像素选择器进行修改,在缺乏跟踪像素的区域寻找均匀分布的额外像素。因为这些额外的像素很难跟踪位置,所以它们只优化了位置,而不会影响整体的姿态跟踪。此外,图像中的一些区域缺乏梯度,使得跟踪成为不可能。为了确保3DGS的这些无梯度区域中存在点,我们实现了一个系统,在这些区域中放置一些点,并将它们的位置设置为附近跟踪点的平均值。
Replica上实验效果:

2、PRoGS: 渐进高斯渲染(PRoGS: Progressive Rendering of Gaussian Splats )(压缩 )
https://arxiv.org/pdf/2409.01761

渐进式渲染一篇工作,类似压缩感知,可以在只加载10% splat的情况下达到80%质量的渲染效果,也可以结合splat压缩使用

3、3DGS-LM: Faster Gaussian-SplattingOptimization with Levenberg-Marquardt


优化器层面的改进,使用SLAM中常用的LM优化器替换ADAM,结合一种中间梯度缓存数据结构,在同等建模质量下获得30%提速,且可即插即用,与任意3DGS方法联合
6、EdgeGaussians
https://arxiv.org/abs/2409.12886
EdgeGaussians – 3D Edge Mapping via Gaussian Splatting
研究在3DGS中引入边特征,和我们讨论的研究目的是一样的,提出一种基于图像学习3D线段、边缘点云、GS表示的方法,提供基于边缘的几何先验



五、动态
1、Dynamic Gaussian Marbles for Novel View Synthesis of Casual Monocular Videos(动态场景、分割等)
https://geometry.stanford.edu/projects/dynamic-gaussian-marbles.github.io/
《Dynamic Gaussian Marbles for Novel View Synthesis of Casual Monocular Videos》
单相机视频输入,通过提出GS Marble基本结构,结合分治的稠密跟踪方法,实现动态GS场景建模
2、FlashSplat: 2D to 3D Gaussian Splatting Segmentation Solved Optimally(分割)
https://arxiv.org/pdf/2409.08270
FlashSplat: 2D to 3D Gaussian Splatting Segmentation Solved Optimally
通过线性规划解决3DGS分割问题,在线优化速度提升至30s,已开源,可做工程参考

3、GS for Immersive Human-centric Volumetric Videos(人体)
https://nowheretrix.github.io/DualGS/
《Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos》
上科大团队,双重GS用于实时体素视频应用,这个效果比今年3DV时候看起来更好了


4.MonST3R:运动中的几何估计
https://monst3r-project.github.io/
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion


Must3R的4D版本,单目视频估计动态点云与内外参,效果、速度看着都很不错,
动态版本、以及建筑行业的动态过程管理等方面。应该也是目前速度最快的4D Recon方案之一。
5.VR-Splatting
https://lfranke.github.io/vr_splatting/
VR-Splatting: Foveated Radiance Field Rendering via 3D Gaussian Splatting and Neural Points


VR-Splatting 将神经点渲染和3DGS的优势结合到 VR 混合注视点辐射场渲染系统中。方法在注视点区域提供了高保真度,并满足 90 Hz VR 帧速率要求。
6.video-3D workflow
https://huggingface.co/spaces/Stable-X/StableRecon
基于Dust3R和Span3R的video-3D workflow
7.PhotoReg :GS点云3D配准
PhotoReg: Photometrically Registering 3D
https://github.com/ziweny11/PhotoRegCodes
PhotoReg takes two input 3D Gaussian Splatting models and
aligns them into a merged Gaussian Splatting model. Transformation and Scale information between two inputs is obtained through
3D visual foundation models and further refined photometrically.

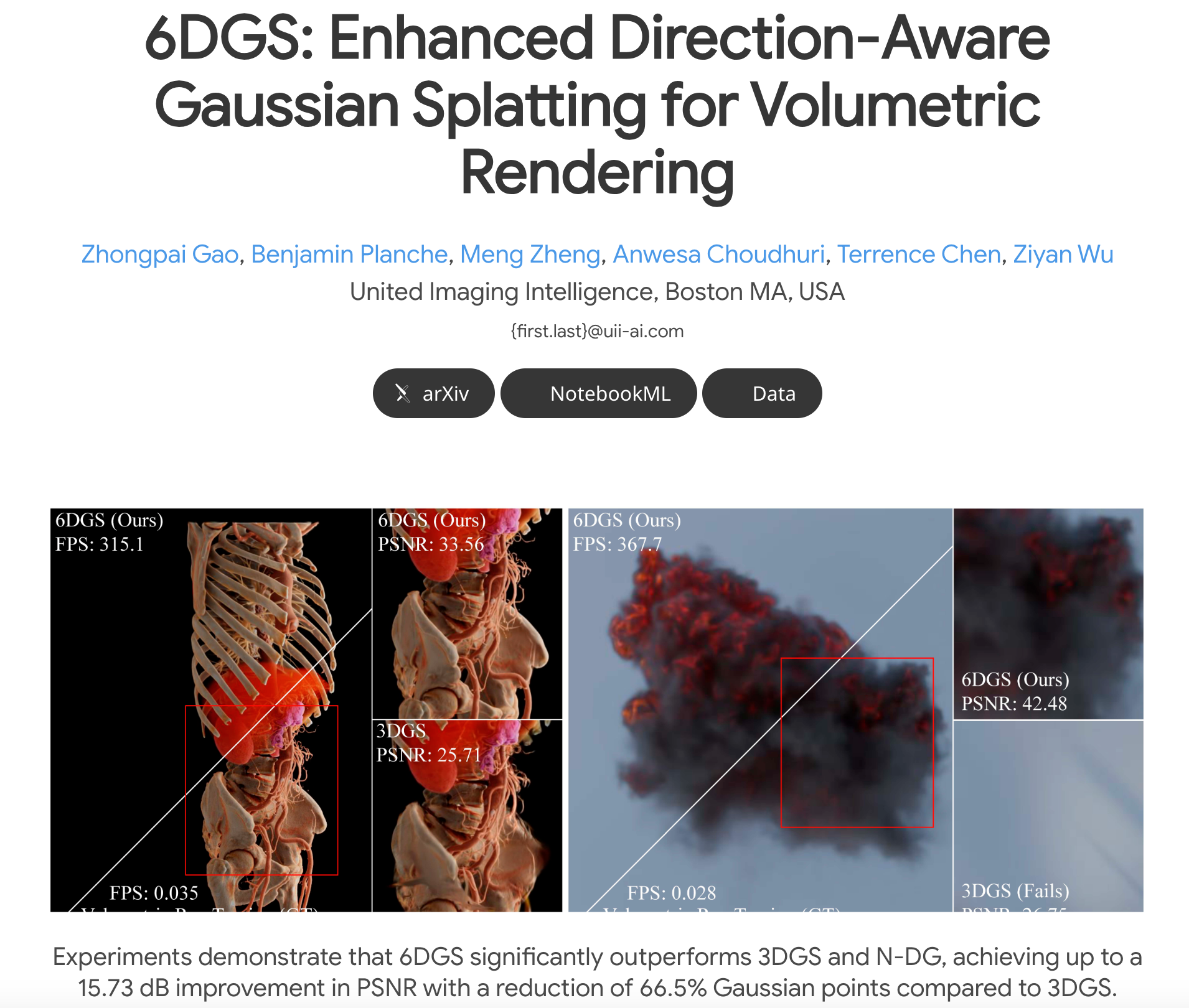
8.6DGS:GS + 体渲染
6DGS:Enhanced Direction-AwareGaussian Splatting for VolumetricRendering
https://arxiv.org/pdf/2410.04974
d
\sqrt{d}
d
1
8
\frac {1}{8}
81
x
ˉ
\bar{x}
xˉ
x
^
\hat{x}
x^
x
~
\tilde{x}
x~
ϵ
\epsilon
ϵ
ϕ
\phi
ϕ
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

















 704
704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









