






目录
场景/物体三维重建过程:首先用colmap估计图像位姿,而后以图像和位姿作为出入,用NeRF或Gaussian Splatting进行三维重建
一、NeRFStudio安装
简介:Nerfstudio,一个用于NeRF开发的模块化PyTorch框架。框架中用于实现基于NeRF的方法的组件即插即用,使得研究人员和相关从业者可以轻松地将NeRF集成到自己的项目中。框架的模块化设计支持实时可视化工具,导入用户真实世界捕获的数据集外(in-the-wild)数据,以及导出为视频,点云和网格表示的工具。近期,还导入了InstantNGP、3D Gaussian Splatting等最新重建算法。

1.安装(ubuntu系统)
下载项目代码到本地:
git clone https://github.com/nerfstudio-project/nerfstudio.git
可以去github直接下载zip文件,也可以按照以上命令git。网络不好可以去gitee(码云)加速。
cd nerfstudio
pip install --upgrade pip setuptools
pip install -e .
2.安装(windows系统)
2.1.安装vs2019 + cuda 11.6;
2.2.通过conda创建虚拟环境nerfstudio,依次执行如下命令:
conda create --name nerfstudio -y python=3.8
conda activate nerfstudio
python -m pip install --upgrade pip
3.3.安装依赖:
(1).pytorch 1.13.1, 执行如下命令:
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 -f https://download.pytorch.org/whl/torch_stable.html
(2).tinycudann, 执行如下命令:
pip install ninja git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
3.4.安装nerfstudio,依次执行如下命令:
git clone git@github.com:nerfstudio-project/nerfstudio.git
cd nerfstudio
pip install --upgrade pip setuptools
pip install -e .
5.安装ffmpeg, 执行如下命令:
conda install -c conda-forge ffmpeg
6.安装colmap, 执行如下命令:
conda install -c conda-forge colmap
conda install -c conda-forge mpir
7.安装hloc,依次执行如下命令: 可选,windwos上不支持pycolmap
cd ..
git clone --recursive https://github.com/cvg/Hierarchical-Localization/
cd Hierarchical-Localization/
pip install pycolmap # windows不支持
python -m pip install -e .
二、安装tinycudann
pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
这句命令不成功的,请切换gcc与g++版本,方法见最后
三、Colmap安装与使用
colmap是用来对一系列图像进行位姿匹配,从而生成场景的三维模型(点云)。也就是你对一个场景拍摄了很多照片,colmap可以估计出每张照片的相机位置(pose,是NeRF的输入),并利用SFM算法生成三维模型。使用NeRF和Gaussian Splatting进行三维重建必备的工具。
1. 安装依赖
sudo apt-get install \
git \
cmake \
ninja-build \
build-essential \
libboost-program-options-dev \
libboost-filesystem-dev \
libboost-graph-dev \
libboost-system-dev \
libeigen3-dev \
libflann-dev \
libfreeimage-dev \
libmetis-dev \
libgoogle-glog-dev \
libgtest-dev \
libsqlite3-dev \
libglew-dev \
qtbase5-dev \
libqt5opengl5-dev \
libcgal-dev \
libceres-dev
2. 安装colmap
git clone https://github.com/colmap/colmap.git
cd colmap
mkdir build
cd build
sudo cmake .. \
-D CMAKE_CUDA_COMPILER="/usr/local/cuda-11.3/bin/nvcc" ../CMakeLists.txt \
-D CMAKE_CUDA_ARCHITECTURES='89'
cd ..
sudo make -j24
sudo make install
注意:
更改以上命令中cuda路径,以及最后的显卡算力(75代表Turing架构,如RTX 20系列;80代表Ampere架构,如RTX 30系列;89为RTX4080 显卡等)
3.使用colmap
3.1 可视化界面使用
使用命令打开colmap
colmap gui
打开界面如下:
 1.创建 project_cat 文件夹,把图片放 project_cat/images 下
1.创建 project_cat 文件夹,把图片放 project_cat/images 下
2.执行 Automatic reconstruction 重建,如下:‘


需要等待比较久的时间,最开始比较占用CPU,大概执行的是特征点计算和匹配一类的,后面会占用比较大的GPU使用率,GPU内存占用大概2G.
到下面的界面后表明完成。

同时介绍了可视化sparse, dense, mesh 模型结果的方法。最终效果如下:

一些参数说明:
Rotate model: Left-click and drag.
Shift model: Right-click or -click (-click) and drag.
Zoom model: Scroll.
Change point size: -scroll (-scroll).
Change camera size: -scroll. (红色的表示相机拍摄位置的符号)
Adjust clipping plane: -scroll. (距离观察视点一定距离的点会被 clipped)
Select point: Double-left-click point (change point size if too small). The green lines visualize the projections into the images that see the point. The opening window shows the projected locations of the point in all images.
3.2 Nerfstudio命令行调用Colmap
除以上可视化界面直接计算图片的pose以外,还可以用Nerfstudio调用colmap:
ns-process-data images --sfm-tool hloc --feature-type superpoint --matcher-type superglue --data '/path/to/IMG' --output-dir '/path/to/IMG'
其优点是利用superpoint 和 superglue深度特征,替代原始的sift提取特征
3.3 colmap结果不准时的修复
1.在终端 colmap gui命令打开可视化界面,先新建项目,将sparse/0中的database.db和图片路径输入,再import项目,输入sparse/0文件夹,就能显示以下界面
2.在可视化界面中,import model之前不准的结果路径(sparse/0文件夹)
3.在可视化界面中,双击选中不准的图片,直接删除(中间这几个相机挤在一起,明显有问题)
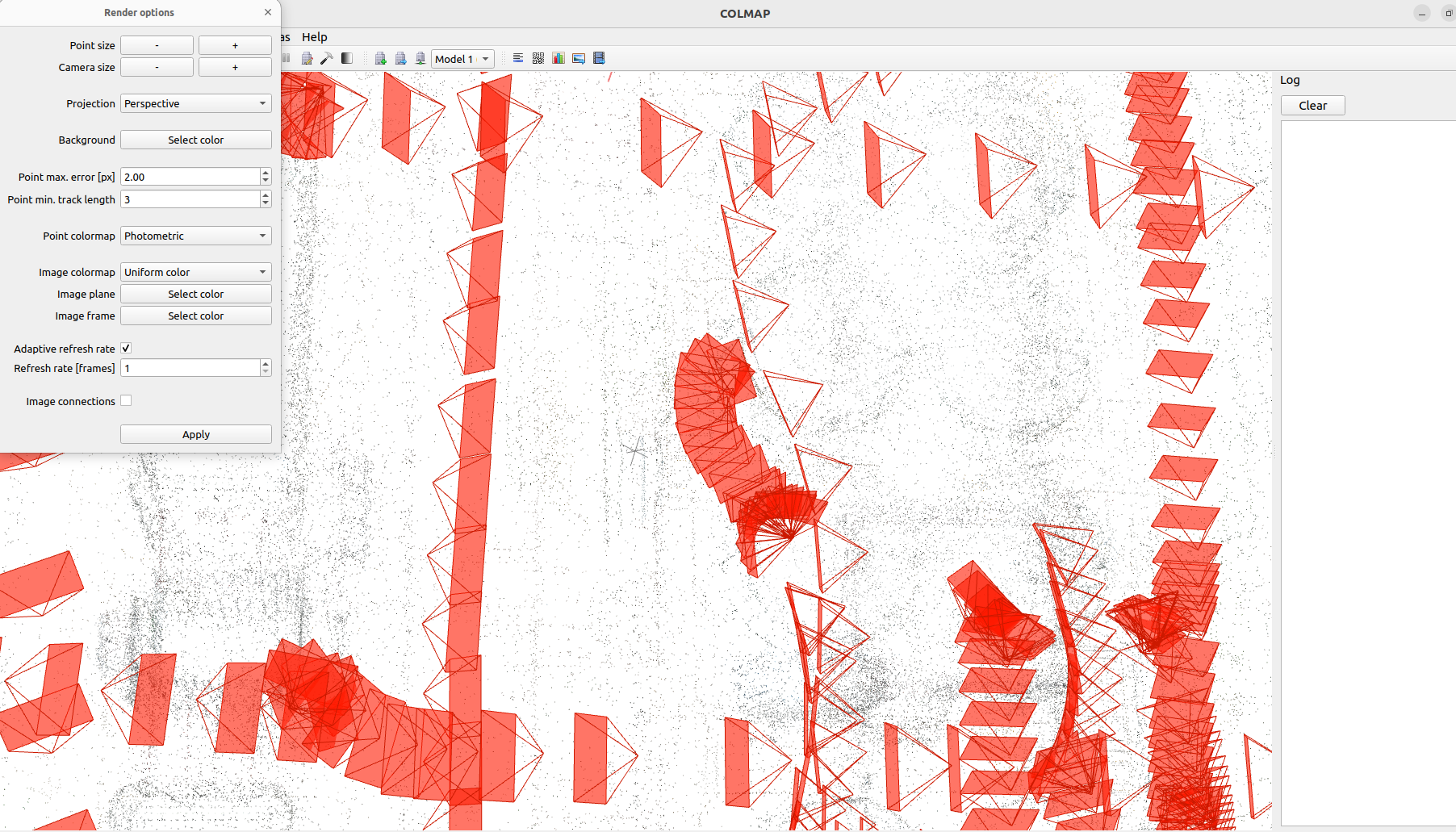 删除完以后,export model,直接放在一个新文件夹里
删除完以后,export model,直接放在一个新文件夹里
4.更新clmap计算出的点云:
colmap point_triangulator
--database_path /home/data/garden/colmap/sparse/0/database.db
--image_path /home/data/garden/images
--input_path /home/data/garden/colmap/sparse/0
--output_path /home/data/garden/colmap/sparse/1 # 新生成的点云保存路径,可以提前创建好,替代原来的sparse/0
5.重新增量式把删除的图片计算进来(可选):
colmap mapper --database_path /home/xzz/instruct-gs2gs/data/liangcang2-2copy/distorted/sparse/0/database.db
--image_path /home/data/garden/images
--input_path /home/data/garden/colmap/sparse/0
--output_path /home/data/garden/colmap/sparse/0+ # 新生成的0+路径,可以替代原始的sparse/0
--Mapper.fix_existing_images 1
可以检查一下0+的相机位置对不对,还是不对的话就舍弃0+
3.4 colmap 校正地面
# 1.windows命令:
E:\COLMAP-3.9.1-windows-cuda\COLMAP.bat model_orientation_alignerhel --help
# 2.ubuntu命令:
colmap model_orientation_aligner --help
# (大概需要 --image_path arg --input_path sparse/0 --output path arg 三个输入参数 )
四、使用NeRFStudio进行三维重建
4.1.通过colmap生成数据集,也可从网上,如https://data.nerf.studio/nerfstudio/ 下载lego 乐高玩具测试集,并拷贝到nerfstudio的data/nerfstudio目录下,data/nerfstudio需自己创建;
4.2.采用colmap生成数据集时,需执行如下命令生成transforms.json:
ns-process-data images --data data/nerfstudio/lego/train --output-dir data/nerfstudio/lego --camera-type perspective --matching-method exhaustive --sfm-tool colmap --crop-factor 0.0 0.0 0.0 0.0
4.3.训练命令如下:迭代产生的checkpoint存储在outputs/lego/nerfacto目录下
ns-train nerfacto --data data/nerfstudio/lego --vis viewer --max-num-iterations 50000
参数为数据路路径,迭代次数等。还可添加其他参数,用命令ns-render --help查看官方文档
训练进度如下图所示:

训练结束后,会显示本地浏览地址。打开web实时预览: https://viewer.nerf.studio/versions/23-04-10-0/?websocket_url=ws://localhost:7007 ,如下图所示:
 加载预训练模型,继续训练命令为:
加载预训练模型,继续训练命令为:
ns-train nerfacto --data data/nerfstudio/person --load-dir outputs/person/nerfacto/2023-08-23_152364/nerfstudio_models
加载预训练模型进行可视化查看:
ns-viewer --load-config outputs/person/nerfacto/2023-04-23_152364/config.yml
训练结果可以导出为 (1).渲染视频; (2).点云;(3).mesh.
支持的自定义数据集类型:https://docs.nerf.studio/en/latest/quickstart/custom_dataset.html
ns-process-data各参数说明:https://docs.nerf.studio/en/latest/reference/cli/ns_process_data.html
官方提供的数据集:https://drive.google.com/drive/folders/19TV6kdVGcmg3cGZ1bNIUnBBMD-iQjRbG
colmap结果转nerfstudio输入:
一般nerfstudio结果需要有sparse_pc.ply与transforms.json,如何将colmap的结果转成这种格式?只需以下命令:
ns-process-data images --data liangcang2-2copy/images --output-dir lc2 --skip-colmap --colmap-model-path colmap/sparse/0
查看训练好的模型:
ns-viewer --load-config outputs/lc2/splatfacto/2024-09-25_174814/config.yml
四*、gsplat使用
python .\examples\simple_trainer.py _3dgs --enable_viewer --use_bilateral_grid --data_dir "E:\BaiduNetdiskDownload\uav\$_" --result_dir "E:\BaiduNetdiskDownload\uav\$_" --steps-scaler 1.5
五、3D GaussianSplatting安装与使用
5.1 安装
首先,克隆代码到本地(–recursive是为了添加SIBR的可视化库,用于显示结果)
git clone https://github.com/graphdeco-inria/gaussian-splatting --recursive
然后,cd目录到gaussian-splatting 下,按照yml创建环境:
cd gaussian-splatting
SET DISTUTILS_USE_SDK=1 # 只有 Windows 需要
conda env create --file environment.yml
conda activate gaussian_splatting
安装整体比较简单,基本一键式安装
5.2 使用
首先,自带的库可以把视频,处理成图片。例如:
ffmpeg -i -qscale:v1-qmin1-vffps C:Users\data\crane.mov -qscale:v 1 -qmin 1-vf fps= %04d.jpg
然后,是用colmap处理图像,获得每张图像的pose:
python convert.py -s data/crane
由于我已经用colmap处理好了图像,因此需要修改以上代码。首先,需要创建 ‘ distorted’文件夹,并将 ‘colmap’中的‘spase’ 文件夹复制进去;然后复制 ‘images’文件夹,并重命名为‘input’。然后执行修改后的命令:
python convert.py -s 'data/crane' --skip_matching
得到的数据集格式如下:

最后,开始训练:
python train.py -s 'data/crane' --data_device cpu --iterations 30000
以上参数可选gpu或cpu,一般训练30k就能收敛。想细节更好,建议往100k训练。500张图,4080gup,30k大概需要半小时内(但是colmap需要一小时)。以下是训练截图:
 最上面一行output那,显示了保存路径。
最上面一行output那,显示了保存路径。
结果可视化:
./SIBR_viewers/install/bin/SIBR_gaussianViewer_app -m ./output/ee33ed94-3
以上命令,需要将路径改为自己的。可视化效果如下:

可以通过键盘的‘wsad’进行移动,‘ikjl’键来切换视角。只要照片拍的好,效果就好。具体数据采集问题,可以咨询博主。
常用命令汇总:
# 拷贝环境
sudo mount machine3:/nfs/gs_env ~/anaconda3/envs/gs
# 矫正
python convert.py -s 'data/indoor3' --skip_matching (必须有input文件夹,以及包含sparse的distorted文件夹)
colmap image_undistorter --image_path --input_path(put "0" into folder) --output_path
# train
python train.py -s 'data/center' --data_device cpu -r 1 --iterations 100000 --densify_until 60000 --densification_interval 250 --cache-path 'path'
# 实时渲染
./SIBR_viewers/install/bin/SIBR_gaussianViewer_app -m ./output/f80f5f1f-3
python render.py -m ./output/4e756cf2-4 --skip_train
# 遇到错误
OSError: [Errno 24] Too many open files: 在终端执行 ulimit -n 4096
# 无法识别数据中的子文件夹(比如images下面还有1、2、3等子图像文件夹)
scene/dataset_readers.py中的 line 96,将如下第一行修改为第二行:
# image_path = os.path.join(images_folder, os.path.basename(extr.name))
image_path = os.path.join(images_folder, extr.name)
# 地面校准
colmap model_orientation_aligner --help
# sparse/0在nerfstudio环境下转为transform.json
ns-process-data images --data data/liangcang4k/images --output_dir data/liangcang4k/ns --skip_colmap --skip_image_processing --colmap_model_path colmap/sparse/0
五* CUDA安装(附C++编译器说明)
提示:安装cuda前,首先要确保gcc与g++编译器的版本,与cuda版本相匹配。不确定的先看第5节
1、查看已安装的CUDA版本
所有已安装的CUDA版本默认保存在/usr/local路径下,cd到该路径下通过ls命令查看:

2、查看当前使用的CUDA版本
在/usr/local路径下通过 stat cuda 命令查看当前使用的CUDA版本:
3、安装新的CUDA版本——CUDA11.3为例
3.1、下载对应版本的CUDA安装包: 链接(选择下载runfile文件)
3.2、在下载文件的目录下,通过命令进行安装:
sudo sh cuda_10.0.130_410.48_linux.run
## 安装时去掉对显卡驱动的安装,如下图中去掉第一行

3.3、修改环境变量
系统环境中修改cuda版本。执行以下命令,打开环境路径,在最后添加并保存:
gedit ~/.bashrc
## 默认为以上软连接的路径
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda
## 也可以指定具体路径
export PATH=/usr/local/cuda-11.3/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH
保存环境变量:
source ~/.bashrc
4、CUDA版本的切换
4.1、删除原版本的cuda软连接
sudo rm -rf /usr/local/cuda
4.2、建立新的指向cuda-10.0的软连接
sudo ln -s /usr/local/cuda-10.0 /usr/local/cuda
5.切换gcc与g++版本
cuda支持的最高版gcc与g++如下表,大部分人都需要降级gcc:

安装对应版本gcc与g++(这里以cuda11.3对应的9.5为例):
sudo apt-get install gcc-9
sudo apt-get install g++-9
随后,进入/usr/bin目录下删除旧版本gcc/g++文件(这里只是删除了软连接):
cd /usr/bin
sudo rm gcc g++
最后,将gcc/g++和新安装的gcc-9/g+±9关联起来:
sudo ln -s gcc-9 gcc
sudo ln -s g++-9 g++
查看最新版本:
gcc -V
其他切换版本方法:gcc版,默认使用优先级最高的版本。设置gcc 10优先级为100,设置gcc 9优先级为70。那么默认使用gcc10。
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-10 100 --slave /usr/bin/g++ g++ /usr/bin/g++-10 --slave /usr/bin/gcov gcov /usr/bin/gcov-10
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-9 70 --slave /usr/bin/g++ g++ /usr/bin/g++-9 --slave /usr/bin/gcov gcov /usr/bin/gcov-9
随后,使用以下命令来选择版本(默认选择第1行的,序号为0)
sudo update-alternatives --config gcc
- 批量修改文件名(先cd到对应路径):
for i in KaTeX parse error: Expected group after '_' at position 21: …0 300); do mv *_̲{i}.png ${i}.png 2>/dev/null; done
1.colmap对齐校正:
colmap model_orientation_aligner --image_path arg --input_path arg --output_path arg 三个输入参数 )
2.裁减colmap:
python split_colmap/split_colmap_v2.py --input 0 --output 00 --xmin -6.6 --xmax -2.04 --zmin -13.3 --zmax 8.7 --threshold .5
3.裁减ply:
python clip_model.py --in-path heyangblock2/point_cloud/iteration_60000/point_cloud.ply --out-path heyangblock2/clipped.ply --xmin -2.04 --xmax 1.74
4.合并所有clipped.ply
python merge_models.py --in-paths */clipped.ply --out-path heyang.ply
python trainer/gstrainer/train.py --data.path '/home/xzz/Pixel-GS/data/xytdoor' --save.path /tmp/unused --auto-exp.enable
input3路径下的图片转fl3.txt
# import os
# def write_filenames_to_txt(folder_path, output_txt_path):
# # 获取文件夹中所有文件(不包含子文件夹里的文件)
# filenames = [f for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))]
# # 写入到txt文件中
# with open(output_txt_path, 'w', encoding='utf-8') as f:
# for name in sorted(filenames):
# f.write(f"{name}\n")
# print(f"已将 {len(filenames)} 个文件名写入 {output_txt_path}")
# # 示例路径(请替换为你自己的)
# folder_path = r'/home/xzz/视频/xytgarden/input3'
# output_txt_path = r'/home/xzz/视频/xytgarden/fl3.txt'
# write_filenames_to_txt(folder_path, output_txt_path)
colmap mapper \
--database_path /home/xzz/视频/xytgarden/514/new.db \
--image_path /home/xzz/视频/xytgarden/input3 \
--image_list /home/xzz/视频/xytgarden/fl3.txt \
--output_path /home/xzz/视频/xytgarden/sparse/3
colmap model_merger \
--input_path1 /home/xzz/视频/xytgarden/sparse/0/0 \
--input_path2 /home/xzz/视频/xytgarden/sparse/1/0 \
--output_path /home/xzz/视频/xytgarden/01


















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









