







文章目录
摘要
项目地址:https://ziweny11.github.io/photoreg.
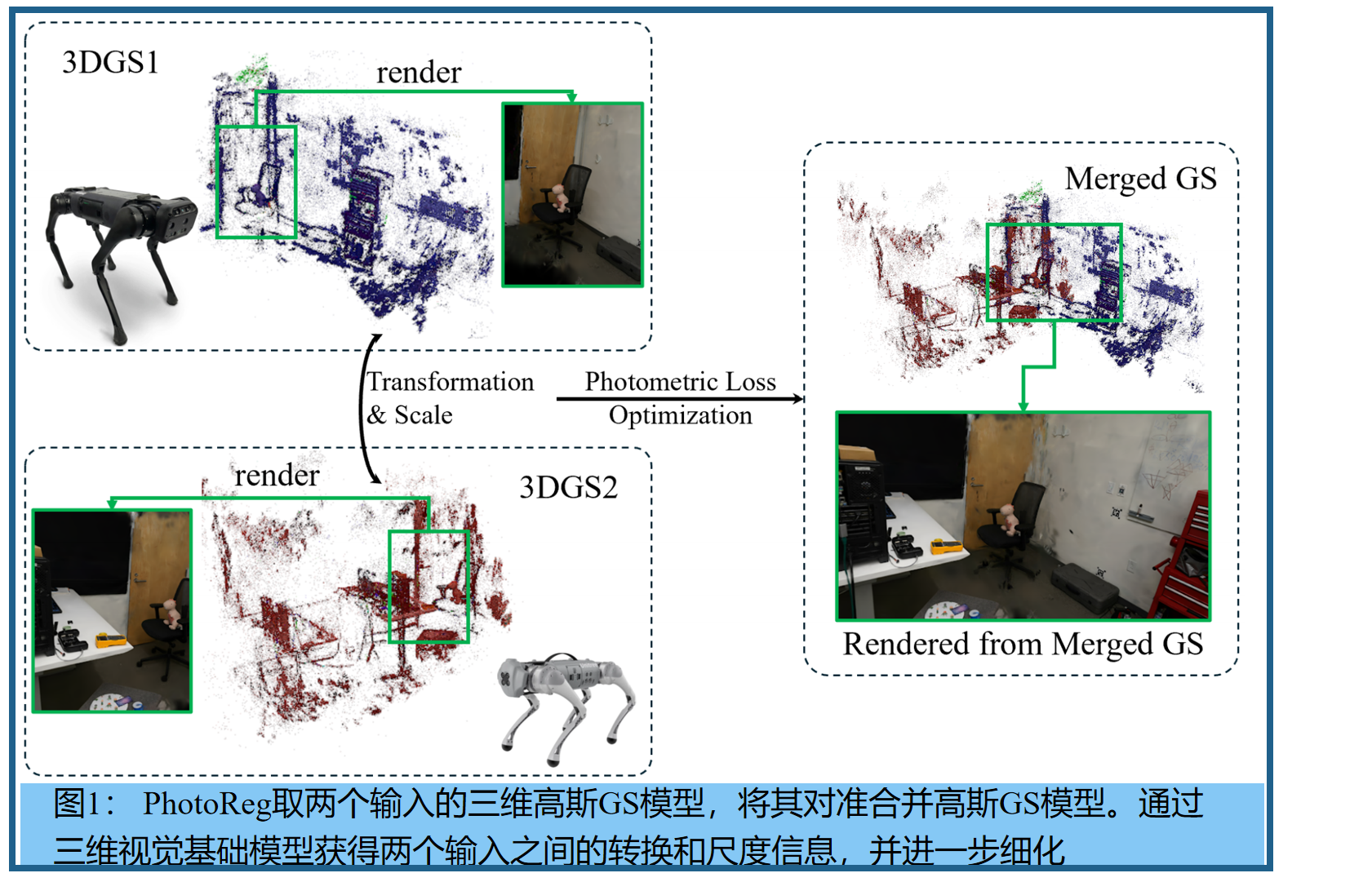
构建准确的环境表示法对于智能机器人在部署过程中做出决策至关重要。最近引入的三维高斯溅射(3DGS)可以实时渲染,它描述了多达数百万个原始的椭球体。3DGS已经迅速崛起。然而,一个尚未解决的关键问题仍然存在:如何将多个3DGS融合成一个单一的相干模型?这项工作的一个关键见解是利用逼真重建之间的二元性(duality),从三维结构渲染真实的二维图像,和三维基础模型,从图像对预测三维结构。为此,我们开发了PhotoReg,一个框架来注册多个逼真的3DGS模型与3D基础模型。由于3DGS模型通常是由单眼相机图像构建的,因此它们具有任意的尺度。为了解决这个问题,PhotoReg通过考虑这些模型中的深度估计,积极地加强不同3DGS模型之间的尺度一致性。然后,利用细粒度的光度损耗迭代地细化对齐,以产生高质量的融合3DGS模型。
一、前言
本文将允许一组机器人,以分散的方式探索和绘制大的未知空间。经典的配准(registration)方法,如 iterative closest point(ICP) 及其变体,主要关注于通过最小化对应点之间的距离来对齐点云。然而,3DGS中固有的连续和复杂的几何表示与传统配准方法管理的离散点集有显著的不同,这需要像PhotoReg等创新方法来有效对齐。
PhotoReg利用在互联网规模的数据集上训练的三维基础模型,从二维图像对中获得初始的三维结构( 3DGS模型的初始对齐,特别是在模型之间的重叠最小的情况下 )。由于单个的3DGS模型可能不是相同的尺度,PhotoReg通过考虑每个模型中的置信度感知深度估计来积极地对齐其尺度。随后,PhotoReg优化了细粒度光度损失,以测量模型中渲染图像的质量,以确保3DGS之间的紧密对齐。我们对经典基准数据集和定制收集的数据提供了PhotoReg的广泛的经验评估。这包括一个由在一个公共区域内工作的两只四足动物收集的自定义数据集。
二、准备工作
1.3D Registration(三维配准)
三维配准:在机器人感知中,配准是指寻找两个三维结构之间的转换。随着时间的推移,登记两点云已经得到了广泛的研究。ICP [22]基于最近点假设,寻找对应点对并估计它们之间的刚体变换。诸如color ICP [23]、Point to plane ICP [24]和鲁棒ICP [25]等变量在准确性和效率方面改进了该方法。我们已经探索了注册两个nerf的方法。NeRF2NeRF [26]提出通过手动选择关键点来对齐两个NeRF。DReg-NeRF [27]通过使用深度学习自动化NeRF模型的对齐,进一步推进了三维配准。人们尝试探索3DGS配准: LoopSplat [28] 通过registering 3D Gaussian splats,引入了一种新的loop closure technique。然而,LoopSplat依赖于RGB-D图像来进行深度传感器的读数,这限制了它在深度传感器不可用或不可靠时的适用性。PhotoReg可以在没有深度传感器的情况下注册3DGS。
2.视觉基础模型
在互联网规模的数据[29]上训练的视觉基础模型,充当即插即用的模块,以促进一系列下游任务。例如,DINOv2 [33]是在互联网规模的未标记数据上进行训练的,使用自我监督技术,允许它在不需要显式注释的情况下发展对视觉内容的深刻理解。DUSt3R [34]设计用来从RGB图像中生成三维点图,实现姿态估计,并已应用于下游机器人机械手感知[35]、[36]。PhotoReg利用基础模型的突发功能来执行稳健的对齐。
DUSt3R:在DUSt3R的核心是一个大型vision transformer[37]。输入2张 RGB图像宽度W和高度H, I 1 , I 2 ∈ R W × H × 3 I_1,I_2∈R^{W×H×3} I1,I2∈RW×H×3和输出2相应的3D点图 X 1 , 1 X 2 , 1 ∈ R W × H × 3 X_{1,1}X_{2,1}∈R^{W×H×3} X1,1X2,1∈RW×H×3与相关置信图 C 1 , C 2 ∈ R W × H C_1,C_2∈R^{W×H} C1,C2∈RW×H和深度图 D 1 , D 2 ∈ R W × H D_1,D_2∈R^{W×H} D1,D2∈RW×H,进一步恢复各种几何量,如相对相机姿态和完全一致的3D重建。在我们提出的PhotoReg框架中,我们将利用上述输出。这个工作流程如图2所示。由于DUSt3R完全是由数据驱动的,所以它不需要在我们的图像中识别手工特征来找到对应关系。因此,它能够准确地找到相对的相机姿态,即使在输入的图像对之间的视觉重叠是最小的。我们的PhotoReg框架利用了这一特性,使GS模型的重叠对齐。

DINOv2 [33]: DINOv2是一个视觉基础模型,它使用了一个transformer,在广泛的图像数据集上以一种自监督的方式进行训练。它以单个图像作为输入,并输出一个相应的向量嵌入。这些嵌入对于spatial transformation是invariant的,语义上相似的对象在这个嵌入空间中很接近。
我们使用DINOv2在每个3DGS模型中搜索潜在的相邻区域。这些相邻的区域表现出重叠的视觉特征,如在两幅图像中都可识别的共同元素。DINOv2有助于检测这些重叠的特征,并指导选择输入图像到上面讨论的DUSt3R模型中。DINOv2的工作流程概述如图3所示。
三、主要方法
问题设置。具体来说,给定输入3DGS模型 G 1 G_1 G1和 G 2 G_2 G2,我们提出的方法旨在发现一个变换函数T,该函数在 G 1 G_1 G1的坐标系内,将 G 2 G_2 G2对齐到 G 1 G_1 G1。由于3DGS是任意规模的,T需要处理 G 1 G_1 G1和 G 2 G_2 G2,这可能会有很大的不同的scale。
3DGS模型 G G G由一组三维高斯分布组成,其中每个高斯分布由其三维位置 µ µ µ定义;协方差矩阵 Σ Σ Σ,描述高斯分布在三维空间中的分布和方向;不透明度 α α α;球谐(SH)系数 c c c,包含颜色信息:
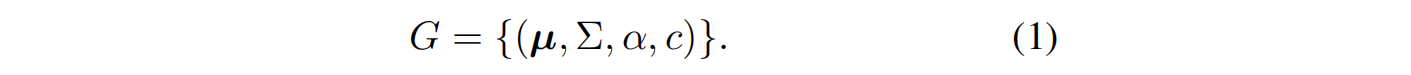
转换:3DGS模型的转换涉及到对每个高斯分布的每个属性应用缩放、旋转和平移。设 T A B T^B_A TAB
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









