




标题:《FastGS: Training 3D Gaussian Splatting in 100 Seconds》
项目:https://fastgs.github.io.
来源:南开大学
一、摘要
现有主流的三维高斯溅射(3DGS)加速方法在训练过程中难以有效控制高斯分布数量,导致计算资源浪费。本文的FastGS框架是简洁且通用的加速方案,通过多视图一致性机制全面评估各高斯基元的重要性,高效平衡训练效率与渲染质量:设计了基于多视图一致性的密度增强与剪枝策略,摒弃了传统预算分配机制。在Mip-NeRF 360、Tanks & Temples和Deep Blending数据集上的大规模实验表明:FastGS在训练速度上显著超越现有最佳(SOTA)方法,Mip-NeRF 360数据集上较DashGaussian实现3.32倍加速,Deep Blending数据集上较基础3DGS实现15.45倍加速,同时保持与DashGaussian相当的渲染质量。实验验证FastGS具有强大的通用性,涵盖动态场景重建、表面重建、稀疏视图重建、大规模重建及同步定位建图等任务,训练加速比达2-7倍。
二、Overview
FastGS框架如图3:使用SfM点云初始化3DGS,并在多视图图像上训练。通过提出的多视图一致性致密化和剪枝策略来控制3DGS的增减。如图3b和图3c所示,Taming-3DGS[25]和Speedy-Splat[12]也分别从多视图中估计高斯分数用于致密化和剪枝。但两者都依赖与高斯分布相关的分数来控制高斯数量,而非考虑每个高斯对多视图渲染质量的贡献。这种对多视图信息的次优利用导致Taming-3DGS[25]出现冗余问题,而Speedy-Splat[12]则导致渲染质量下降。相比之下,如图3a所示,我们的方法根据多视图重建质量而非高斯属性来评估每个高斯的重要性。此外,我们的方法在致密化和剪枝过程中都利用了多视图一致性,这将在第3节和第4节详细阐述。为进一步提升光栅化效率,第5节介绍了我们使用的紧凑框(CB)技术。
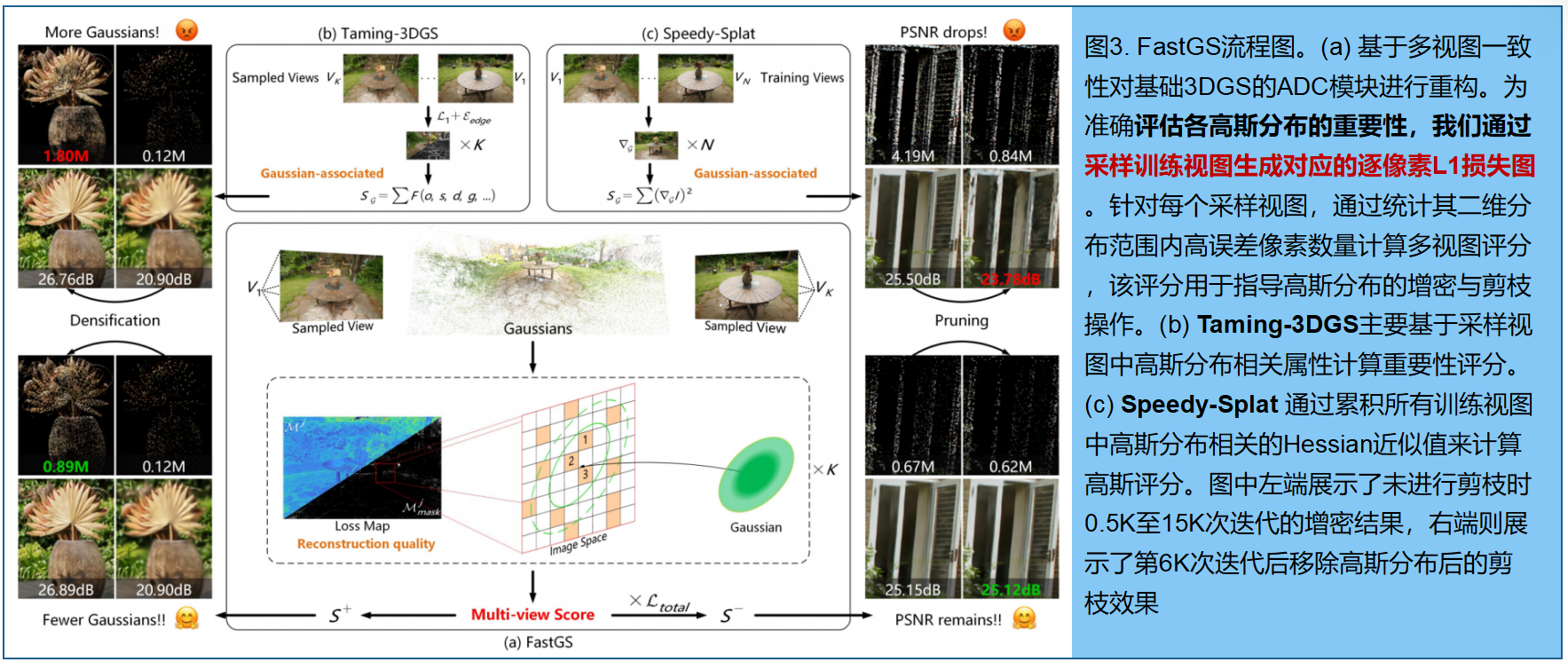
三、多视图一致性稠密化
传统的3DGS仅基于图像空间中的梯度幅值对高斯基元进行密度增强,这会产生大量冗余高斯。其他稠密化方法[4,8,44]同样会生成数百万个高斯基元,导致效率低下。我们认为这种冗余现象源于这些方法未能严格判断多视角中是否需要对某个高斯进行密度增强。如图3b所示,Taming-3DGS在密度增强过程中考虑了多视角一致性,主要根据高斯相关属性(如不透明度、缩放比例、深度和梯度)而非其对渲染质量的实际贡献来计算评分,这使得难以严格保证高斯基元的多视角一致性。如图3b左侧所示,这也导致了冗余问题。此外,其评分计算过程复杂且效率较低。为解决这些问题,我们提出了一种基于多视角一致性的新型简单密度增强策略VCD。如图3a所示,该方法通过采样视角计算每个高斯分布2D足迹中高误差像素的平均数量,其中高误差像素仅通过真实值与渲染结果之间的逐像素L1损失来判定。如图3a左侧所示,VCD在使用更少高斯分布的情况下实现了可比的渲染质量,从而大幅避免了冗余问题。接下来我们将详细阐述VCD的具体实现方法:
给定K个相机视角 V = V= V={ v j v^j vj} j = 1 k _{j=1}^k j=1k(从训练视图中随机抽取),以及对应的真值图像 G = G= G={ g j g^j gj} j = 1 k _{j=1}^k j=1k和渲染图像 R = R= R={ r j r^j rj} j = 1 k _{j=1}^k j=1k。针对每个视角 v j v^j vj,计算渲染颜色 r u , v j , c r_{u,v}^{j,c} ru,vj,c 与真值颜色 g u , v j , c g_{u,v}^{j,c} gu,vj,c在像素 ( u , v ) (u,v) (u,v)处的误差:
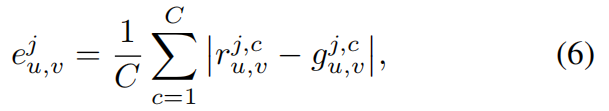
其中 c c c 表示颜色通道。根据逐像素误差构建损失映射 M j ∈ R W × H M^j∈R^{W×H} Mj∈RW×H:
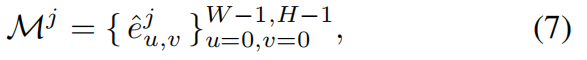
其中每个
e
^
u
,
v
j
\hat{e}^j_{u,v}
e^u,vj值均通过min–max normalization 获得:
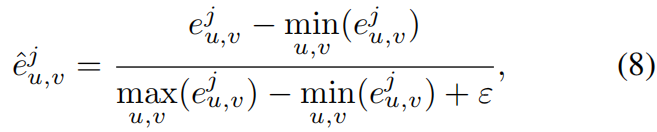
随后对
M
j
M^j
Mj应用阈值
τ
τ
τ ,识别出重建误差较大的像素
p
h
p_h
ph,并生成mask:
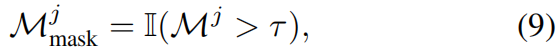
其中像素P的
M
m
a
s
k
j
(
u
,
v
)
=
1
M^j_{mask}(u,v)=1
Mmaskj(u,v)=1表示重建质量较差的区域。
接下来,要找到与这些高误差像素相关的高斯基元。对于每个3D高斯基元Gi,将其投影到2D图像空间,以获得其2D足迹 Ωi 。然后,我们使用指示函数 判断像素是否存在高误差,为每个高斯基元计算重要性评分 s i + s^+_i si+,通过统计所有采样视图中二维足迹内高误差像素的数量进行累积,最终对累积值取平均值:
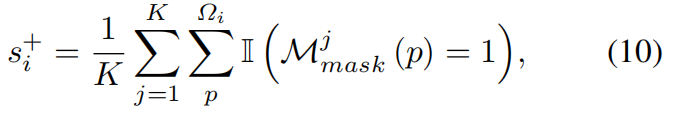
当 s i + s^+_i si+值较高时(超过预设阈值 τ + τ^+ τ+),表明该高斯持续存在于多个视图的高误差区域,因此可作为候选进行密集化处理。值得注意的是,我们可以通过渲染过程的前向传播直接高效地确定二维足迹内的高误差像素数量
四、多视图一致性剪枝
传统的3DGS方法[17]虽然能剔除不透明度过低或尺度过大的高斯,但难以有效处理冗余问题。近期提出的剪枝策略[1,7,8]同样存在缺陷,不仅无法消除冗余,反而可能显著降低渲染质量。这些方法均未基于多视图一致性来判定高斯基元的冗余性。如图3c所示,**Speedy-Splat[12]通过累加所有训练视图中与高斯相关的海森矩阵近似值来计算剪枝分数,而非捕捉每个高斯对多视图渲染质量的真实贡献。**这种间接依赖多视图一致性的方法导致渲染质量下降,如图3c右侧所示。为彻底消除冗余高斯分布,我们提出了一种基于多视图一致性的新型剪枝策略 VCP 。如图3a所示,该方法与VCD类似,通过评估每个高斯分布对多视图重建质量的影响来计算分数。如图3a右侧所示, VCP 在保持渲染质量的同时有效剔除了大量冗余高斯基元:
具体而言,针对每个视图 v j ∈ V v^j∈V vj∈V,我们计算渲染图像 r j r^j rj与对应真实图像 g j g^j gj之间的光度损失:
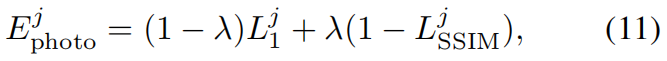
由于光度损失能可靠地反映重建保真度,我们将其与等式(10)结合,以推导出每个高斯基元 G i G_i Gi的剪枝分数:
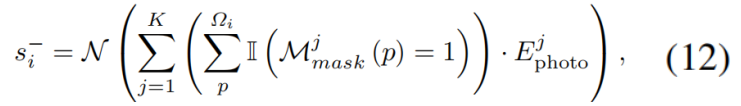
其中
N
(
⋅
)
N(·)
N(⋅)表示最小-最大归一化函数。
s
i
−
s^−_i
si−可视为高斯基元
G
i
G_i
Gi对整体渲染质量影响的量化指标,当其超过预设阈值
τ
−
τ^−
τ−时,即表明其对多视角渲染质量的贡献度较低,将被剪枝。
五、Compact Box
在光栅化预处理阶段,标准3DGS算法采用 3-sigma 规则生成二维椭圆,但这种方法会产生大量高斯-tiles对,导致计算冗余并降低渲染效率。Speedy-Splat算法通过精确tiles交集部分解决了这一问题,但我们发现某些2DGS对特定tile像素的影响仍然微乎其微。为进一步减少冗余配对,我们提出Compact Box 算法,通过计算高斯中心的马氏距离,剔除贡献度最低的高斯-tiles对,从而在保持渲染质量的同时提升效率。
实验
数据集。与标准3DGS 相同,我们在三个真实世界数据集上进行实验:Mip-NeRF 360 、Deep-Blending 和 Tanks & Temples。对于其他具有挑战性的任务,我们在D-NeRF、NeRF-DS 和 Neu3D 数据集上评估动态场景重建。Tanks & Temples、 LLFF、BungeeNeRF 和 Replica 分别用于表面重建、稀疏视图重建、大规模重建和SLAM。
评估指标。为评估性能表现,我们采用 PSNR 、 SSIM 和 LPIPS 等常用指标来衡量新视图渲染质量。同时,通过总训练时间(分钟)、最终高斯点数量及渲染速度(帧率)等指标,评估模型的训练效率与紧凑性
具体实现。所有方法均采用Adam优化器[20]进行3万次迭代训练。在实验中,我们统一设置 K = 10 K=10 K=10和 λ = 0.2 λ=0.2 λ=0.2。基础配置下,每500次迭代执行一次数据密集化处理,直至第15,000次迭代。为确保实验公平性,所有测试均使用 NVIDIA RTX 4090显卡完成,对比方法均采用官方代码实现。FastGS的默认配置为3DGSaccel[17,25],包含我们提出的VCD、 VCP 和CB三种加速方案。为实现极致训练加速,我们的方法在渲染质量上并非最优。为此推出FastGS Big版本,该版本通过将数据密集化处理频率提升至每100次迭代一次,同时保持最高渲染质量和最快训练速度。
如表1,FastGS在保持渲染质量相当的情况下实现了最快训练速度。平均场景训练耗时100秒,最快案例仅需77秒。Speedy-Splat[12]在剪枝过程中未能充分考虑多视图一致性,导致渲染质量显著下降。Taming3DGS[25]采用弱多视图一致性约束,造成高斯点过度增长且训练速度放缓。当前 SOTA 算法DashGaussian[4]虽能实现高渲染质量,但缺乏有效的冗余高斯点剪枝策略,其场景优化仍保留数百万高斯点,制约了训练速度。相比之下,我们的改进方案FastGS-Big在渲染质量上比DashGaussian[4]提升超过0.2分贝,训练时间缩短43.7%以上,高斯点数量减少超过一半。
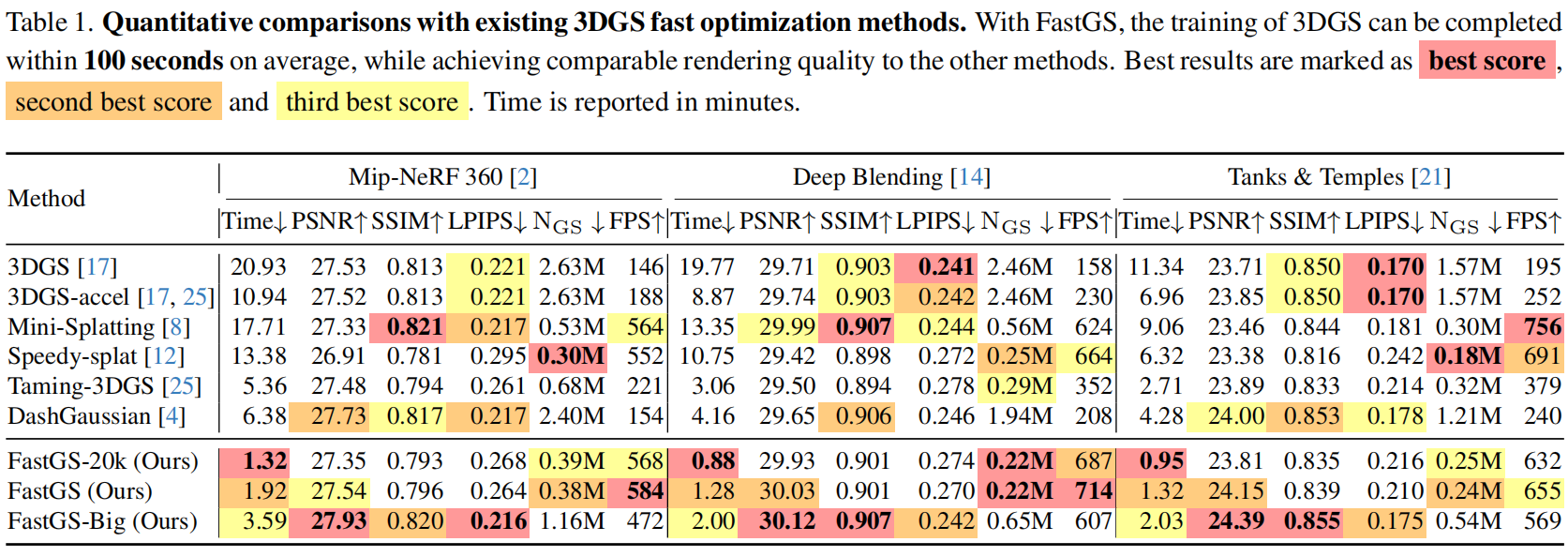
图4展示了表1的结果,其改进版本FastGS-Big在多视图一致性约束下,能更精准地重建场景,几何结构的还原度也更高。

FastGS的通用性
基准模型。Deformable-3DGS、 PGSR、DropGaussian、OctreeGS和photo-SLAM ,分别被选作动态场景重建、表面重建、稀疏视图重建、大规模重建和光图SLAM的骨干方案。
增强主干网络。由于框架设计简洁,该方法可轻松适配其他3DGS主干网络,支持不同优化器、表示基元或附加滤波器。如表2所示,我们的方法在保持渲染质量不变的前提下,训练速度提升2-14倍,高斯数量平均减少77.46%。这充分体现了该方法的普适性,我们认为这源于多视图一致性是3D重建任务的核心要素。
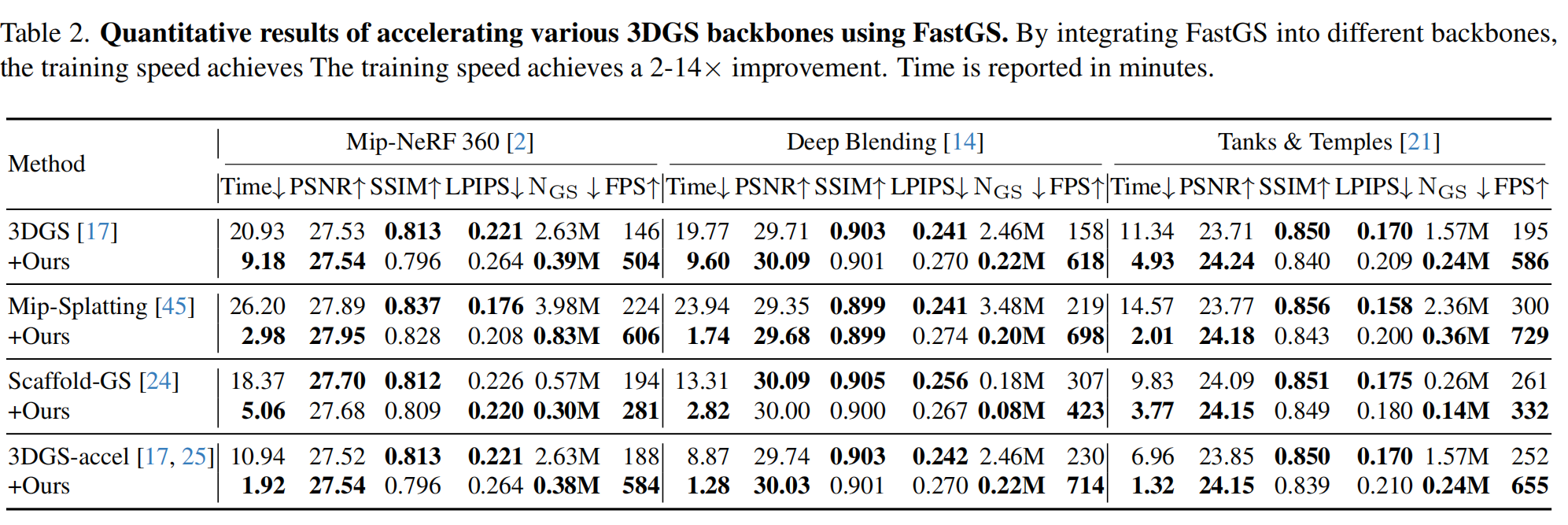
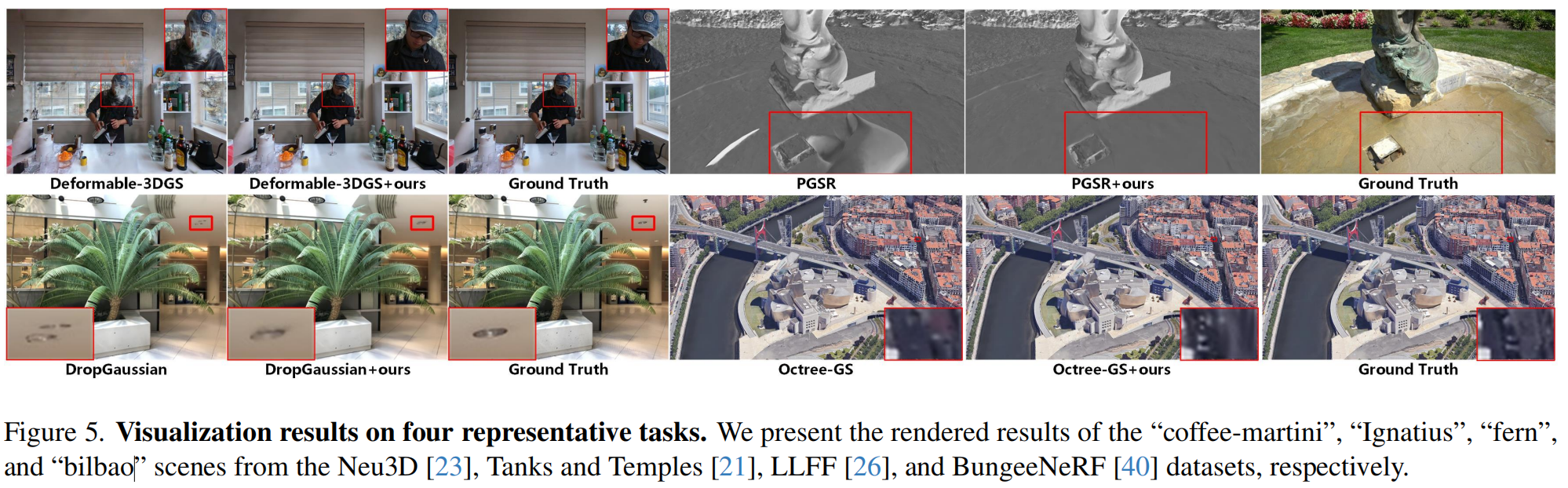
在多项任务的优化中,我们进一步测试了多种 SOTA 方法与本框架的结合应用。如表3和表4。方法在保持渲染质量的同时,使所有基准方法的训练速度提升了2-7倍。图5展示了部分实验结果,这种显著提升充分证明了我们方法的普适性。我们认为这种优势源于多视角一致性特征,该特性是各类重建任务的基础支撑。更多实验数据详见补充材料,相关代码也将开源共享。

代码片(多视图一致性分数计算)
full_metric_counts = None
full_metric_score = None
for view in range(len(camlist)):
my_viewpoint_cam = camlist[view]
render_image = render_fastgs(my_viewpoint_cam, gaussians, pipe, bg, args.mult)["render"]
photometric_loss = compute_photometric_loss(my_viewpoint_cam, render_image)
gt_image = my_viewpoint_cam.original_image.cuda()
get_flag = True
l1_loss_norm = get_loss(render_image, gt_image)
metric_map = (l1_loss_norm > args.loss_thresh).int()
render_pkg = render_fastgs(my_viewpoint_cam, gaussians, pipe, bg, args.mult, get_flag = get_flag, metric_map = metric_map)
accum_loss_counts = render_pkg["accum_metric_counts"]
if DENSIFY:
if full_metric_counts is None:
full_metric_counts = accum_loss_counts.clone()
else:
full_metric_counts += accum_loss_counts
if full_metric_score is None:
full_metric_score = photometric_loss * accum_loss_counts.clone()
else:
full_metric_score += photometric_loss * accum_loss_counts
pruning_score = (full_metric_score - torch.min(full_metric_score)) / (torch.max(full_metric_score) - torch.min(full_metric_score))
if DENSIFY:
importance_score = torch.div(full_metric_counts, len(camlist), rounding_mode='floor')
else:
importance_score = None
return importance_score, pruning_score
#pic_center =60%x80%
d
\sqrt{d}
d
1
8
\frac {1}{8}
81
x
ˉ
\bar{x}
xˉ
D
^
\hat{D}
D^
I
~
\tilde{I}
I~
ϵ
\epsilon
ϵ
ϕ
\phi
ϕ
∏
\prod
∏
a
b
c
\sqrt{abc}
abc
∑
a
b
c
\sum{abc}
∑abc
/ $$
E
\mathcal{E}
E

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









