






一、mysql数据库汉字首字母获取查询
1.汉字提取首字母
get_first_pinyin_char: 此函数是将一个中文字符串的第一个汉字转成拼音字母 (例如:“李”->l),包括特殊字符处理,可以进行动态添加
CREATE DEFINER=`root`@`%` FUNCTION `get_first_pinyin_char`(PARAM VARCHAR(255)) RETURNS varchar(2) CHARSET utf8mb4
BEGIN
DECLARE V_RETURN VARCHAR(255);
DECLARE V_FIRST_CHAR VARCHAR(2);
SET V_FIRST_CHAR = UPPER(LEFT(PARAM,1));
SET V_RETURN = V_FIRST_CHAR;
IF LENGTH( V_FIRST_CHAR) <> CHARACTER_LENGTH( V_FIRST_CHAR ) THEN
SET V_RETURN = ELT(INTERVAL(CONV(HEX(LEFT(CONVERT(PARAM USING gbk),1)),16,10),
0xB0A1,0xB0C5,0xB2C1,0xB4EE,0xB6EA,0xB7A2,0xB8C1,0xB9FE,0xBBF7,
0xBFA6,0xC0AC,0xC2E8,0xC4C3,0xC5B6,0xC5BE,0xC6DA,0xC8BB,
0xC8F6,0xCBFA,0xCDDA,0xCEF4,0xD1B9,0xD4D1),
'A','B','C','D','E','F','G','H','J','K','L','M','N','O','P','Q','R','S','T','W','X','Y','Z');
END IF;
RETURN V_RETURN;
END
2.汉字字段全拼首字母查询
pinyin :此函数是将一个中文字符串对应拼音母的每个相连 (例如:“李佳航”->ljh(或者说"张伟"-zw))
CREATE DEFINER=`root`@`%` FUNCTION `pinyin`(P_NAME VARCHAR(255)) RETURNS varchar(255) CHARSET utf8mb4
BEGIN
DECLARE V_COMPARE VARCHAR(255);
DECLARE V_RETURN VARCHAR(255);
DECLARE I INT;
SET I = 1;
SET V_RETURN = '';
while I < LENGTH(P_NAME) do
SET V_COMPARE = SUBSTR(P_NAME, I, 1);
IF (V_COMPARE != '') THEN
#SET V_RETURN = CONCAT(V_RETURN, ',', V_COMPARE);
SET V_RETURN = CONCAT(V_RETURN, get_first_pinyin_char(V_COMPARE));
#SET V_RETURN = fristPinyin(V_COMPARE);
END IF;
SET I = I + 1;
end while;
IF (ISNULL(V_RETURN) or V_RETURN = '') THEN
SET V_RETURN = P_NAME;
END IF;
RETURN V_RETURN;
END
最终使用效果如下:
where pinyin ( ‘字段’) LIKE concat( ‘%’, #{dto.firstChar},‘%’ ),便可以查询对应的数据。
二、通过ES插件elasticsearch-analysis-pinyin进行汉字首拼查询
-
使用场景介绍
搜索功能支持:拼音检索,中文检索,拼音中文混合检索
例如:输入:l德h
【期望结果】:刘德华 和刘德华4
【不期望结果】:刘得华 、刘的华 -
下载pinyin 插件
github地址
注意:下载的版本要与自己的ES版本一致
目前v7.13.1 已经支持拼音中文混合检索 可以直接安装插件直接使用
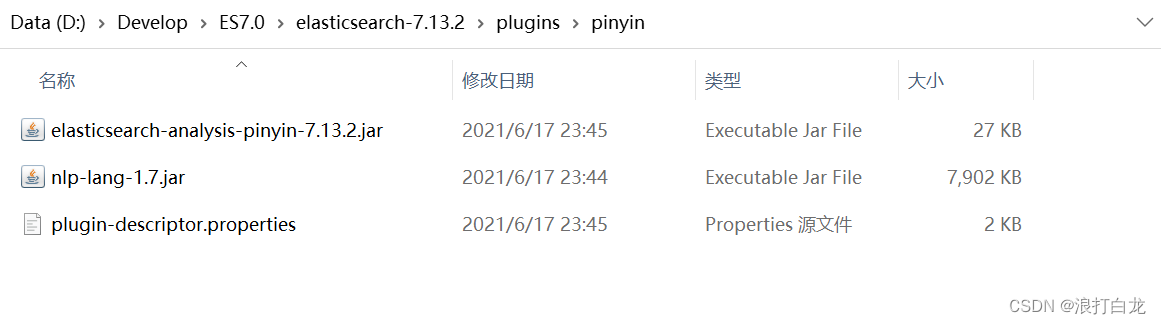
安装完成后,重启ES。
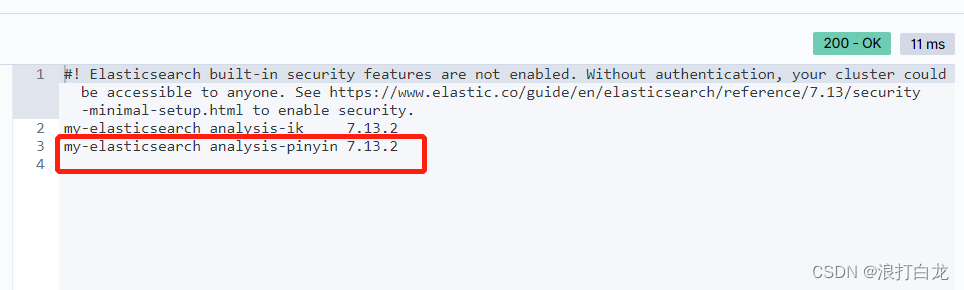
验证插件是否安装成功: GET /_cat/plugins?pretty 成功截图:
-
创建index并使用kibana进行测试
1)创建索引
PUT /name_index
{
"settings": {
"analysis": {
"analyzer": {
"pinyin_chinese_analyzer": {
"tokenizer": "pinyin_tokenizer"
},
"pinyin_analyzer": {
"tokenizer": "pinyin_chinese_tokenizer"
}
},
"tokenizer": {
"pinyin_chinese_tokenizer": {
"type": "pinyin",
"keep_first_letter": false,
"keep_separate_first_letter": false,
"keep_full_pinyin":false,
"keep_original":false,
"limit_first_letter_length":50,
"keep_separate_chinese": true,
"lowercase":true
},
"pinyin_tokenizer": {
"type": "pinyin",
"keep_first_letter": false,
"keep_separate_first_letter": true,
"keep_full_pinyin":true,
"keep_original":false,
"limit_first_letter_length":50,
"keep_separate_chinese": true,
"lowercase":true
}
}
}
}
}
2)查询索引
GET /_cat/indices
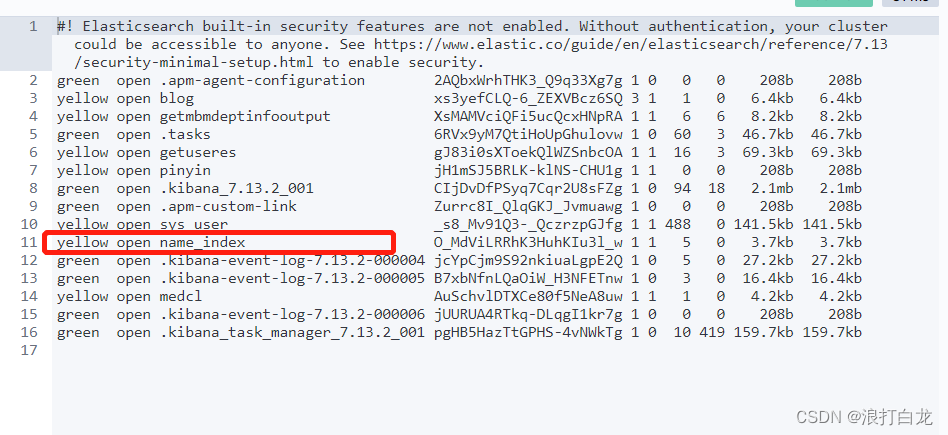
3)Mapping设置
POST /name_index/_mapping
{
"properties": {
"name": {
"type": "text",
"analyzer": "pinyin_chinese_analyzer",
"search_analyzer": "pinyin_analyzer"
}
}
}
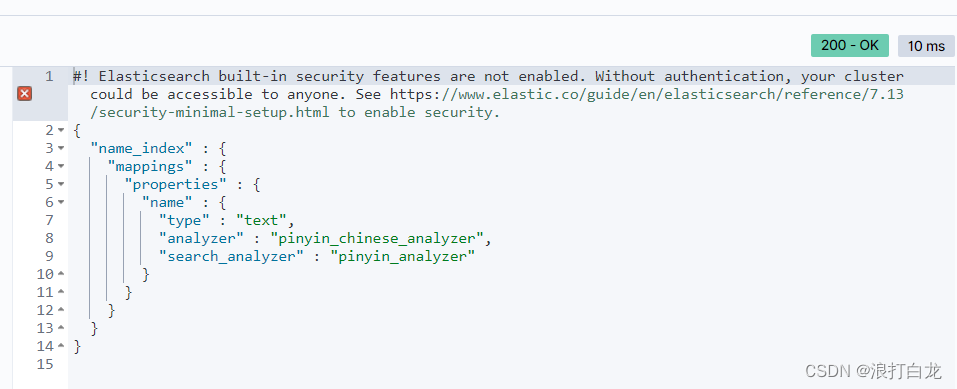
4)查询Mapping设置是否生效
GET /my_index/_mapping?pretty
5)测试索引下定义的分词器
GET /name_index/_analyze
{
"text": ["刘德华"],
"analyzer": "pinyin_chinese_analyzer"
}
GET /name_index/_analyze
{
"text": ["刘德h"],
"analyzer": "pinyin_analyzer"
}
6)创建数据
###################创建数据########################
POST /name_index/_doc/1
{"name":"刘德华"}
PUT /name_index/_doc/2
{"name":"刘de华"}
PUT /name_index/_doc/3
{"name":"刘得华"}
PUT /name_index/_doc/4
{"name":"刘德华4"}
PUT /name_index/_doc/5
{"name":"刘2德3华"}
7)查询所有数据
GET /name_index/_search
{
"query": {
"match_all": {}
}
}
8)拼音中文混合检索
GET /name_index/_search
{
"query": {
"match_phrase": {
"name": "ldh"
}
}
}
三、通过java程序实现ES首字母查询数据
1.controller层
/**
* es查询用户名称
*/
@ApiOperation("es查询用户名称")
@GetMapping("/nameList")
public AjaxResult nameList(@RequestParam(name = "name") String paramStr) {
List<Object> list = new ArrayList<>();
PageResult<List<JSONObject>> nameResult = esUtileService.multiSearch("name_index", paramStr, 1, 10);
JSONArray jsonArray = JSONArray.parseArray(nameResult.getList().toString());
jsonArray.forEach(item -> {
list.add(JSONObject.toJavaObject((JSON) item, Object.class));
});
return AjaxResult.success(list);
}
2.Serivice层
@Slf4j
@Component
public class EsUtileService {
@Autowired
RestHighLevelClient restHighLevelClient;
public PageResult<List<JSONObject>> multiSearch(String index, String keywords, Integer pageNo, Integer pageSize) {
SearchResponse searchResponse = getSearchList(index, keywords, pageNo, pageSize);
SearchHits searchHits = searchResponse.getHits();
List<JSONObject> resultList = new ArrayList<>();
for (SearchHit hit : searchHits) {
//原始查询结果数据
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
JSONObject jsonObject = JSONObject.parseObject(JSONObject.toJSONString(sourceAsMap));
resultList.add(jsonObject);
}
long total = searchHits.getTotalHits().value;
PageResult<List<JSONObject>> pageResult = new PageResult<>();
pageResult.setPageNum(pageNo);
pageResult.setPageSize(pageSize);
pageResult.setTotal(total);
pageResult.setList(resultList);
pageResult.setTotalPage(total == 0 ? 0 : (int) (total % pageSize == 0 ? total / pageSize : (total / pageSize) + 1));
return pageResult;
}
public SearchResponse getSearchList(String index, String words, int pageNo, int pageSize) {
// 这个sourcebuilder就类似于查询语句中最外层的部分。包括查询分页的起始,
// 查询语句的核心,查询结果的排序,查询结果截取部分返回等一系列配置
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//分页处理
buildPageLimit(sourceBuilder, pageNo, pageSize);
//超时设置
sourceBuilder.timeout(TimeValue.timeValueSeconds(60));
//执行查询
sourceBuilder.query(chineseAndPinYinSearch(words));
//指定索引库和类型
SearchRequest searchRequest = new SearchRequest(index);
// 索引不存在时不报错
searchRequest.indicesOptions(IndicesOptions.lenientExpandOpen());
searchRequest.source(sourceBuilder);
try {
return restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
public void buildPageLimit(SearchSourceBuilder sourceBuilder, Integer pageNum, Integer pageSize) {
if (sourceBuilder != null && !StringUtils.isEmpty(pageNum) && !StringUtils.isEmpty(pageSize)) {
sourceBuilder.from(pageSize * (pageNum - 1));
sourceBuilder.size(pageSize);
}
}
//中文、拼音混合搜索
private QueryBuilder chineseAndPinYinSearch(String words) {
//使用dis_max直接取多个query中,分数最高的那一个query的分数即可
DisMaxQueryBuilder disMaxQueryBuilder = QueryBuilders.disMaxQuery();
/**
* 纯中文搜索,不做拼音转换,采用edge_ngram分词(优先级最高)
* 权重* 5
*/
QueryBuilder normSearchBuilder = QueryBuilders.matchQuery("name", words).boost(5f);
/**
* 拼音简写搜索
* 1、分析key,转换为简写 case: 南京东路==>njdl,南京dl==>njdl,njdl==>njdl
* 2、搜索匹配,必须完整匹配简写词干
* 3、如果有中文前缀,则排序优先
* 权重*1
*/
String firstChar = ChineseToPinYinUtil.getAllFirstLetter(words);
TermQueryBuilder pingYinSampleQueryBuilder = QueryBuilders.termQuery("name", firstChar);
/**
* 拼音简写包含匹配,如 njdl可以查出 "城市公牛 南京东路店",虽然非南京东路开头
* 权重*0.8
*/
QueryBuilder pingYinSampleContainQueryBuilder = null;
if (firstChar.length() > 1) {
pingYinSampleContainQueryBuilder = QueryBuilders.wildcardQuery("name", "*" + firstChar + "*").boost(0.8f);
}
/**
* 拼音全拼搜索
* 1、分析key,获取拼音词干 case : 南京东路==>[nan,jing,dong,lu],南京donglu==>[nan,jing,dong,lu]
* 2、搜索查询,必须匹配所有拼音词,如南京东路,则nan,jing,dong,lu四个词干必须完全匹配
* 3、如果有中文前缀,则排序优先
* 权重*1
*/
QueryBuilder pingYinFullQueryBuilder = null;
if (words.length() > 1) {
pingYinFullQueryBuilder = QueryBuilders.matchPhraseQuery("name", words).analyzer("pinyin_analyzer");
}
disMaxQueryBuilder.add(normSearchBuilder)
.add(pingYinSampleQueryBuilder);
//以下两个对性能有一定的影响,故作此判定,单个字符不执行此类搜索
if (pingYinFullQueryBuilder != null) {
disMaxQueryBuilder.add(pingYinFullQueryBuilder);
}
if (pingYinSampleContainQueryBuilder != null) {
disMaxQueryBuilder.add(pingYinSampleContainQueryBuilder);
}
return pingYinFullQueryBuilder;
}
工具类ChineseToPinYinUtil
public class ChineseToPinYinUtil {
private final static int[] LI_SEC_POS_VALUE = {1601, 1637, 1833, 2078, 2274,
2302, 2433, 2594, 2787, 3106, 3212, 3472, 3635, 3722, 3730, 3858,
4027, 4086, 4390, 4558, 4684, 4925, 5249, 5590};
private final static String[] LC_FIRST_LETTER = {"a", "b", "c", "d", "e",
"f", "g", "h", "j", "k", "l", "m", "n", "o", "p", "q", "r", "s",
"t", "w", "x", "y", "z"};
/**
* 取得给定汉字串的首字母串,即声母串
*
* @param str 给定汉字串
* @return 声母串
*/
public static String getAllFirstLetter(String str) {
if (str == null || str.trim().length() == 0) {
return "";
}
String returnStr = "";
for (int i = 0; i < str.length(); i++) {
returnStr = returnStr + getFirstLetter(str.substring(i, i + 1));
}
return returnStr;
}
/**
* 取得给定汉字的首字母,即声母
*
* @param chinese 给定的汉字
* @return 给定汉字的声母
*/
public static String getFirstLetter(String chinese) {
if (chinese == null || chinese.trim().length() == 0) {
return "";
}
chinese = conversionStr(chinese, "GB2312", "ISO8859-1");
// 判断是不是汉字
if (chinese.length() > 1)
{
// 汉字区码
int liSectorCode = (int) chinese.charAt(0);
// 汉字位码
int liPositionCode = (int) chinese.charAt(1);
liSectorCode = liSectorCode - 160;
liPositionCode = liPositionCode - 160;
// 汉字区位码
int liSecPosCode = liSectorCode * 100 + liPositionCode;
if (liSecPosCode > 1600 && liSecPosCode < 5590) {
for (int i = 0; i < 23; i++) {
if (liSecPosCode >= LI_SEC_POS_VALUE[i]
&& liSecPosCode < LI_SEC_POS_VALUE[i + 1]) {
chinese = LC_FIRST_LETTER[i];
break;
}
}
} else // 非汉字字符,如图形符号或ASCII码
{
chinese = conversionStr(chinese, "ISO8859-1", "GB2312");
chinese = chinese.substring(0, 1);
}
}
return chinese;
}
/**
* 字符串编码转换
*
* @param str 要转换编码的字符串
* @param charsetName 原来的编码
* @param toCharsetName 转换后的编码
* @return 经过编码转换后的字符串
*/
private static String conversionStr(String str, String charsetName, String toCharsetName) {
try {
str = new String(str.getBytes(charsetName), toCharsetName);
} catch (UnsupportedEncodingException ex) {
System.out.println("字符串编码转换异常:" + ex.getMessage());
}
return str;
}
}
写在最后:码字不易,望三连给上。抱拳!抱拳!抱拳!
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









