







导读
本文将粗略解读18-DSP-Chen-Sparse Bayesian learning for off-grid DOA estimation with nested arrays,博主才学疏浅,如有错误,多多海涵。希望能找到志同道合的伙伴一起研究SBL,大家有什么问题可以留言交流。
信号模型
假设阵列接收信号为,那么接受信号的协方差矩阵为:
简单说明一下上式的推导过程。假设,
,那么观测信号协方差阵表示为:
又因为有,所以将
进行向量化可以得到:
其中,代表khtari-rao积,
是源功率向量。
为了方便后续表示,令,
。其中,
代表克罗内克积。
真实情况的协方差阵只能用有限快拍数去近似:
所以,真实的向量化之后的协方差矩阵用表示:
其中,代表采样得到的协方差和真实协方差之间的误差。由中心极限定理,该误差的概率密度服从正态分布[1]:
其中,。和OGSBL一样,也考虑离格误差,并用一阶泰勒展开近似。因此有
。
那么整体信号模型表示为:
贝叶斯二层先验
那么接收信号假设服从复高斯分布:
信源服从功率的复高斯分布:
其中,,
。那么超参数
服从独立的伽马分布:
其中,是一个很小的正数(例如,0.01)。
隐变量高斯分布证明
下面整理一下矩阵的维度:,然后开始证明
的后验服从一个复高斯分布。
已知和
与
无关,那么有
。
相对于
独立,有
那么上述公式分子部分表示为:
要最大化后验概率的对数似然函数
实际上就是分子求导,求一阶零点,得到极大值,再将零点带入分母部分。令上式指数括号中的部分为
:
式子当中,
,
,
,
,
和
都是与
无关的量。
因此,我们对求导,取零点得:
。
和
是实对称阵。然后我们将零点带回
得:
令,再根据Woodbury矩阵引理,有:
因此信号的后验概率分母部分可以表示为:
其中,常数。那么可以看出随机变量:
那么的后验概率表示为:
因此的后验服从复高斯分布:
其中,。
超参数更新
接下来用第二类估计函数估计超参数,第二类估计函数定义为:
已知,那么有:
根据行列式转换定理:,我们令
,则上式转换成:
因此,。又有
,
。因此,原来的对数似然函数等价于:
这里将视作无关项,再根据行列式求导公式:
对其求导得一元二次方程:。取零点可得:
因此,功率迭代公式得到证明。
一阶泰勒展开离格
离格部分别的博主已经有证明过了(DOA估计 基于稀疏贝叶斯的离格DOA估计),这里不在赘述。
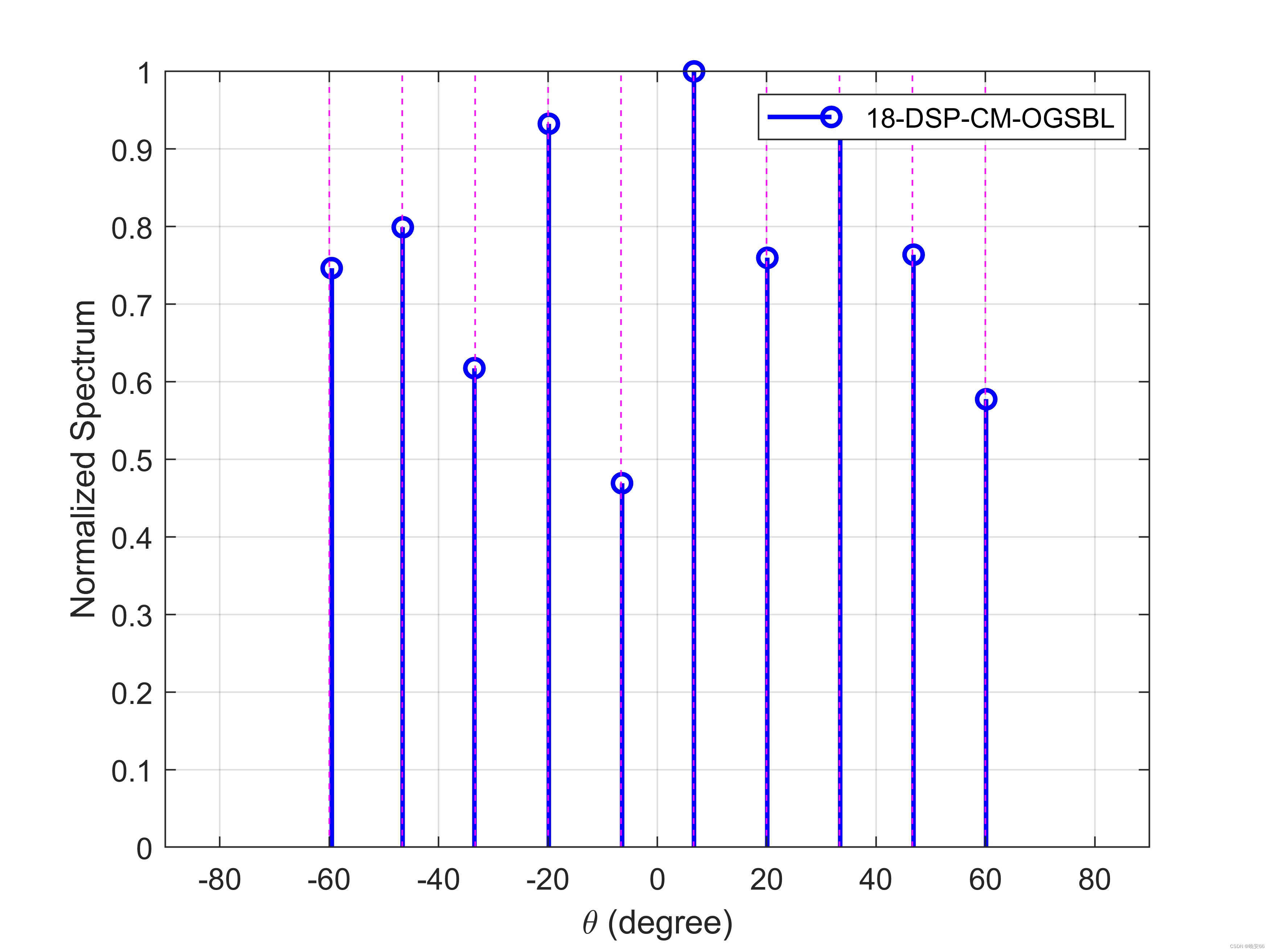
仿真实验
| 角度 | -60,60之间均匀分布10个源 |
| 信噪比 | 0dB |
| 扰噪比 | 无 |
| 快拍数 | 200 |
| 网格步长 | 1° |
| 阵元数 | (3,4)二阶扩展差分互质阵 |
function [Pm, search_range, iter]=Bayesian_DSP2018(X, nSnapshot, search_step, MicP, etc, d, maxiter, tol)
search_range=[-90:search_step:90]; % 搜索区域
Rxx=X*X'/nSnapshot; % 协方差矩阵
Y=Rxx(:); % 矢量化
[nMic2,T]=size(Y);
nMic=sqrt(nMic2);
nGrid=length(search_range);% 网格点数
In=eye(nMic);
In=In(:); % 单位阵矢量化
pos_all=round(log(kron(exp(-MicP),exp(MicP))));% 虚拟阵元
% ans1 = unique(pos_all); % 自由度DOF = 虚拟阵元数量(包含正、负位置的阵元)
W=kron(Rxx.',Rxx)/nSnapshot;
W_sq=sqrtm(inv(W));
Y=W_sq*Y;
% ans1 = sqrt(nSnapshot)*In;
%% Initialization
beta0=1;
delta=ones(nGrid+1,1);
a_search=search_range*pi/180; % 角度转弧度
A=exp(-1i*pi*pos_all'*sin(a_search)); % 虚拟阵元阵列流型
B=-1i*pi*pos_all'*cos(a_search).*A;
% a_search=search_area*pi/180; % 角度转弧度
% A=exp(-1i*pi*pos_all'*sind(search_area)); % 虚拟阵元阵列流型
% B=-1i*pi*pos_all'*cosd(search_area).*A;
A_w=W_sq*A;
B_w=W_sq*B;
I_w= W_sq* In;
Phi=[A_w, I_w]; %公式13
% V_temp= 1/beta0*eye(nMic2) + Phi *diag(delta) * Phi';
% Sigma = diag(delta) -diag(delta) * Phi' * (V_temp\Phi) * diag(delta); % 公式19
% mu = beta0*Sigma * Phi' * Y; % 公式18
converged = false;
iter = 0;
while (~converged) || iter<=100
iter = iter + 1;
delta_last = delta;
%% Calculate mu and Sigma
V_temp= 1/beta0*eye(nMic2) + Phi *diag(delta) * Phi';
Sigma = diag(delta) -diag(delta) * Phi' * (V_temp\Phi) * diag(delta);
mu = beta0*(Sigma * (Phi' * Y));
%% Update delta
temp=sum( mu.*conj(mu), 2) + T*real(diag(Sigma));
delta= ( -T+ sqrt( T^2 + 4*d* real(temp) ) ) / ( 2*d );
%% Stopping criteria
erro=norm(delta - delta_last)/norm(delta_last);% 收敛条件
if erro < tol || iter >= maxiter
converged = true;
end
%% Grid refinement
[~, idx] = sort(delta(1:end-1), 'descend');
idx = idx(1:etc);
BHB = B_w' * B_w;
P = real(conj(BHB(idx,idx)) .* (mu(idx,:) * mu(idx,:)' + Sigma(idx,idx)));
v = real(diag(conj(mu(idx))) * B_w(:,idx)' * (Y - A_w * mu(1:end-1)-mu(end)*I_w))...
- real(diag(B_w(:,idx)' * A_w * Sigma(1:end-1,idx)) + diag(Sigma(idx,nGrid+1))*B_w(:,idx).'*conj(I_w));
eigP=svd(P);
if eigP(end)/eigP(1)>1e-5
temp1 = P \ v;
else
temp1=v./diag(P);
end
temp2=temp1'*180/pi;
if iter<100
ind_small=find(abs(temp2)<search_step/100);
temp2(ind_small)=sign(temp2(ind_small))*search_step/100;
end
ind_large=find(abs(temp2)>search_step);
temp2(ind_large)=sign(temp2(ind_large))*search_step/100;
angle_cand=search_range(idx) + temp2;
search_range(idx)=angle_cand;
% for iii=1:etc
% if angle_cand(iii)>= search_mid_left(idx(iii)) && (angle_cand(iii) <= search_mid_right(idx(iii)))
% search_area(idx(iii))=angle_cand(iii);
% end
% end
A_ect=exp(-1i*pi*pos_all'*sin(search_range(idx)*pi/180));
B_ect=-1i*pi*pos_all'*cos(search_range(idx)*pi/180).*A_ect;
A_w(:,idx) =W_sq*A_ect;
B_w(:,idx) =W_sq*B_ect;
Phi(:,idx)= A_w(:,idx);
end
Pm=delta(1:end-1);
end
% [search_area,sort_s]=sort(search_area);
% Pm=Pm(sort_s);
% insert=(search_area(1:end-1)+search_area(2:end))/2;
% search_area_2=zeros(length(search_area)*2-1,1);
% search_area_2(1:2:end)=search_area;
% search_area_2(2:2:end)=insert;
% Pm_2=zeros(length(Pm)*2-1,1);
% Pm_2(1:2:end)=Pm;
% search_area=search_area_2;
% Pm=Pm_2;
参考文献
[1] 1998-DSP-Covariance matching estimation techniques for array signal processing applications
[2] 2018-DSP-Sparse Bayesian learning for off-grid DOA estimation with nested arrays
[3] 2012-TSP-Compressed Sensing of Complex Sinusoids: An Approach Based on Dictionary Refinement
[4] 2016-SP-An efficient off-grid DOA estimation approach for nested array signal processing by using sparse Bayesian learning strategies

















 3546
3546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











