







 本文介绍了稀疏贝叶斯学习在方向估计问题中的应用,特别是在处理离格信号时的算法。文章详细阐述了基于离格空域模型的迭代算法,利用拉普拉斯先验和信号的联合稀疏性进行推断。通过贝叶斯估计和噪声模型建立,提出了信号模型和噪声模型的联合概率密度函数,并通过EM法更新超参数。最后,文章提供了算法的仿真结果,验证了方法的有效性。
本文介绍了稀疏贝叶斯学习在方向估计问题中的应用,特别是在处理离格信号时的算法。文章详细阐述了基于离格空域模型的迭代算法,利用拉普拉斯先验和信号的联合稀疏性进行推断。通过贝叶斯估计和噪声模型建立,提出了信号模型和噪声模型的联合概率密度函数,并通过EM法更新超参数。最后,文章提供了算法的仿真结果,验证了方法的有效性。
前言
稀疏贝叶斯学习是贝叶斯统计优化算法中十分重要的一类,它是在贝叶斯理论的基础上发展而来的。这篇文章的工作由杨在教授等人在2013年1月于TSP上发布,从贝叶斯的角度出发,是一个基于离格空域模型的迭代算法,利用所有快拍处的信号都具有拉普拉斯先验及不同快拍之间的联合稀疏性进行推断。本篇文章主要是对这篇TSP其中一些部分进行补充推导,由于第一次接触稀疏贝叶斯,因此内容可能有些繁琐及错误。
P.S.这玩意自带的latex编辑器时不时抽风因此有些公式可能有些诡异的大。
离格估计模型
网格划分:
定义角度域模型先验网格划分如下所示:
网格在均匀划分,显然,网格模型格点数
、阵元数
与信源数
应服从:
对于待估计的入射波角度,其导向矢量在角度域上可作如下一阶泰勒展开进行近似:
其中,
为离第
个信号入射角度最近的网格点的角度及其位置,
为该网格点对应的名义导向矢量的导数。假设阵列排布方向的垂直方向对应的角度为0°,则该阵列导向矢量中的第m个元素可表示为:
则该元素对求导可表示为:
因此对于该先验网格集合中的角度对应的名义导向矢量集合的一阶泰勒展开近似即为:
其中为该网格的名义阵列流形状,
为该网格的名义阵列流形导数,
为对应网格点上的误差权重系数。
因此原来通用的信号模型
即可被重新表述为
其中,
,
。又因为需要对该模型进行贝叶斯估计,所以首先假定
为联合稀疏的。
稀疏贝叶斯估计
关于稀疏贝叶斯学习的推导与详细步骤可参考以下链接:
Derivation of Sparse Bayesian Learning
噪声模型
在圆信号的前提下,复高斯分布,且满足
,
,显然有
,
,则可得
,
。因此该复随机过程
服从的分布为:
,
为其均值,
为其协方差阵,不难可从高斯过程推出复高斯过程概率密度函数为,或参考复高斯分布:
因此噪声模型的联合概率密度函数可表示为:
其中为噪声精度,
为快拍数。
由于假定为联合稀疏,则其方差均可视为0,因此阵列接收信号
的联合概率密度函数为:
由于不知道噪声精度,因此对噪声精度进行了一个分布作为超先验(离散样本假设服从高斯分布,其共轭分布便是
分布):
稀疏信号模型
同样的,由于信号与干扰同样是假定稀疏先验的,因此同样以两阶段分层先验对输入信号及其功率精度进行建模,有:
其中,
,
。
联合概率密度函数
后验概率分布推断
在给定先验分布后,后验分布即可根据贝叶斯准则推得:
然而
实际上很难获得,因此需要先对稀疏信号的后验分布进行入手。
首先对基于后验分布进行分解,根据贝叶斯公式,有:
根据上式,首先对进行入手。根据贝叶斯公式与全概率公式,有:
分子部分已经给出,可得:
考察分母部分,由分子得,原式可变为如下所示:
利用高斯函数的性质,即
对指数括号内的函数对求一阶导,并将对应的
带入即可消去关于得到积分后的概率密度函数。
令:
对的一阶导求零点,可得:
则可进一步转化为:
根据复高斯分布结构即得分母部分服从的复高斯分布为
进一步利用Woodbury矩阵引理对协方差阵部分进行化简,即得:
至此后验概率等式右边分子与分母服从的复高斯分布的均值与方差均已经得到,代入后验概率的贝叶斯公式中,即得:
考虑指数内部分,令其为,则有:
则与
即为后验概率服从的复高斯分布的均值与协方差,为:
即式15、16。
如作者在文中一样,令:
将代入
即可得到其另外一种形式,有:
超参数更新估计
此时需要对、
与
进行变量更新,通常有两种方法进行更新,其一是通过第二类最大似然函数,其二是通过EM法。作者在文献中是通过EM法,最大化后验概率情况下联合概率密度的对数期望,对
及
进行更新。
EM法更新超参数
算法模型的整体因子图如下所示:
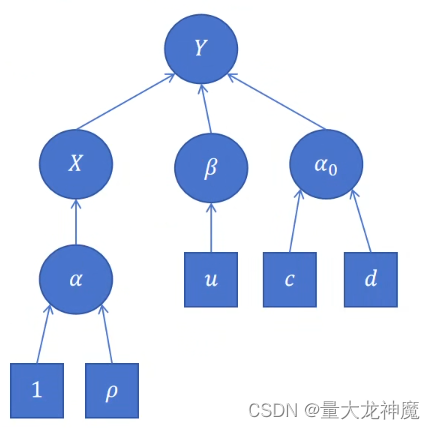
首先简单介绍一下EM法:EM算法是一种迭代优化策略,由于它的计算方法中每一次迭代都分两步,其中一个为期望步(E步),另一个为极大步(M步),所以算法被称为EM算法(Expectation-Maximization Algorithm)。EM的总体步骤可简单概括为以下几步:
- 输入:观测数据
,联合分布
,条件分布
,其中
为隐变量,最大迭代次数J。(注意,设该简单模型中的待估计参数为
)
- 随机初始化模型参数
的初始值
。
- E-step:计算联合分布的条件概率期望:
- M-step:极大化联合分布的条件概率期望:
在最大化后验概率的求解过程中,因为后验概率求解式:
中的右半部分的同样难以求得,但其与联合概率密度成正比,因为:
在这个等价过程中需要注意的是,虽然前文已经提到难以获得,但是其与各隐变量及超参数是独立关系,因此上式是成立的,同时在下一节中最大化第二类最大似然函数等价最大化各超参数的这一目标是成立的。因此最大化后验概率密度就等价于最大化将
视为隐变量的联合概率密度,其对数似然函数形式为:
通过最大似然估计法即可得到:
其中:
接下来处理的重点便转到了上,对于该项,根据Mackay的Bayesian Interpolation,有:
证明如下:
证毕
第二类最大似然函数法更新超参数
按照Tipping文中的思路,对数化边缘概率密度,得:
首先引入行列式转换定理:
因此原行列式项可进一步转化为:
对第二项使用Woodbury矩阵引理,则有:
则原式为:
这部分需要费点心思的是的求导,有以下等式成立:
因此有:
该部分若直接求解,即得
对于误差权重系数,需要最大化
,该问题等价于最大化
,将该概率密度函数带入,即得:
即最小化,对该式展开,即有:
对上式行二、三其中各项展开求均值,可得:
该式共分为两部分。首先引入矩阵的迹与Hadamard积之间的转换
结合矩阵的迹的循环性,以及复向量二范数的平方的展开:
对于第一部分,有:
对于第二部分,有:
则有
其中表示Hadamard积,
为不含
的量,即与
完全无关。
且由此可发现,与
均为半正定矩阵。
则
为凸,取其偏导数为0点即为其最小点,有:
当且仅当可逆。
如果在更新的过程中迭代出了超出其定义范围外的值,或者矩阵出现不可逆的情况时,作者采用对
中的元素逐个迭代的方法进行求解。
首先令:
表示为与相关的形式即为:
其中为与
![]() 无关的项,上式可视为一二次函数,求其导数零点即可得到:
无关的项,上式可视为一二次函数,求其导数零点即可得到:
将超出范围的重映射至
的分布内,即可得到:
在算法具体流程中作者还通过奇异值分解将信号进行PCA降维,一定程度上减小了计算量。
网格权重计算
通过对网格的权重计算,即可根据不同方向来向的信号形成一个等价空域功率谱。
其中为接收信号奇异值分解后信号对应的右特征向量集。
算法总体流程
| 1、输入:接收信号、信源数、阵列结构、网格分辨率、 |
| 2、初始化 |
| 3、更新 |
| 4、更新 |
| 若 |
| 对得到的网格空域谱进行谱峰搜索即为所得角度。 |
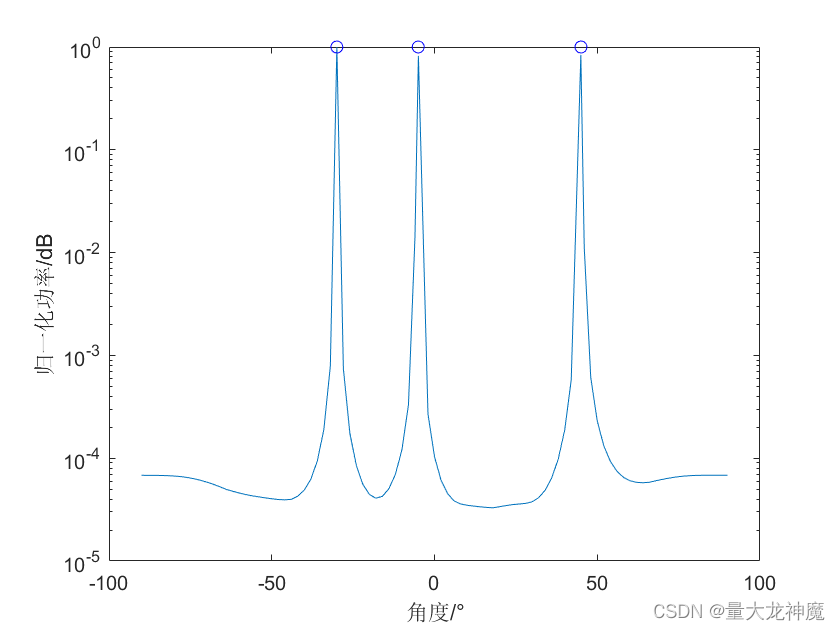
仿真
部分仿真条件如下所示:
| 角度 | -30°、-5°、45° |
| 信噪比 | 20dB |
| 扰噪比 | 20dB |
| 快拍数 | 100 |
| 先验网格分辨率 | 2° |
| 阵元数 | 10 |
代码如下所示:
clc;
clear;
%% 初始化及设定参数
array_num = 10;%%阵元数
snapshot_num = 100;%%快拍数
source_aoa = [-30,-5,45];%%信源到达角
c = 340;%%波速
f = 1000;%%频率
lambda = c/f;%%波长
d = 0.5*lambda;
source_num = length(source_aoa);%%信源数
sig_nr = [20,20,20];%%信噪比、扰噪比
reso_num = 91;%%网格数
%% 导向矢量
X = zeros(source_num,snapshot_num);
A = exp(-1i*(0:array_num-1)'*2*pi*(d/lambda)*sind(source_aoa));%%阵列响应矩阵
for ik = 1:length(sig_nr)
X(ik,:) = sqrt(10^(sig_nr(ik)/10))*(randn(1,snapshot_num)+randn(1,snapshot_num)*1i)/sqrt(2);
end
n = (randn(array_num,snapshot_num)+randn(array_num,snapshot_num)*1i)/sqrt(2);
Y = A*X+n;
% [~,~,D_svd] = svd(Y,'econ');
% Y = Y*D_svd(:,1:source_num);%%信号降维
%% OGSBI算法输入量整理
params.Y = Y;
params.reso_num = reso_num;
params.maxiter = 2000;%%最大迭代次数
params.tolerance = 1e-4;%%误差容忍度
params.sigma2 = mean(var(Y))/100;%%噪声方差估计值
res = OGSBI(params);
xp_rec = res.reso_grid;
x_rec = res.mu;
% x_rec = res.mu * D_svd(:,1:size(res.mu,2))';
xpower_rec = mean(abs(x_rec).^2,2) + real(diag(res.Sigma)) * source_num / snapshot_num;
xpower_rec = abs(xpower_rec)/max(xpower_rec);
[xp_rec,x_index] = sort(xp_rec,'ascend');
xpower_rec = xpower_rec(x_index);
figure();
plot(xp_rec,10*log(xpower_rec));xlabel("角度/°");ylabel("归一化功率/dB");
hold on;
semilogy(source_aoa,max(xpower_rec),'bo');
hold off;
function res = OGSBI(params)
%% 函数参数初始化
Y = params.Y;
reso_num = params.reso_num;
reso_grid = linspace(-90,90,reso_num)';
reso = 180/(reso_num-1);
[array_num, snapshot_num] = size(Y);
r = reso*pi/180;
maxiter = params.maxiter;
tol = params.tolerance;
index_b = randperm(length(reso_grid),array_num)';%%该变量主要记录alpha中最大的几个元素的位置,以后续对这几个位置进行一阶泰勒展开
converged = false;%%判断收敛的Boolen
iter = 0;
A = exp(-1i*(0:array_num-1)'*pi*sind(reso_grid'));
B = -1i*pi*(0:array_num-1)'*cosd(reso_grid').*A;
alpha = mean(abs(A'*Y), 2);
beta = zeros(reso_num,1);
c_sigma0_init = 1e-4;
d_sigma0_init = 1e-4;
c_gamma_init = 1;
d_gamma_init = 1e-4;
alpha_0 = 0.01;
alpha_0_seq = zeros(maxiter,1);%%噪声精度变化迭代
Phi = A;
while ~converged
iter = iter+1;
Phi(:,index_b) = exp(-1i*(0:array_num-1)'*pi*sind(reso_grid(index_b)'));%%根据上一轮迭代得到的网格点位置,对这几个点进行进一步迭代。
B(:,index_b) = -1i*pi*(0:array_num-1)'*cosd(reso_grid(index_b)').*A(:,index_b);
alpha_last = alpha;%%上一次迭代出的alpha的结果
%% 更新X的后验概率密度函数的均值与方差
C = 1/alpha_0*eye(array_num)+Phi*diag(alpha)*Phi';
Cinv = inv(C);%%(16)的woodbury反演形式中的逆矩阵的括号内部分
Sigma = diag(alpha)-diag(alpha)*Phi'*Cinv*Phi*diag(alpha);%%(16)的woodbury矩阵反演公式形式
mu = alpha_0*Sigma*Phi'*Y;%%(15)
%% 更新alpha
musq = mean(abs(mu).^2,2);
alpha = musq+real(diag(Sigma));
for ik = 1:reso_num
alpha(ik) = (-snapshot_num+sqrt(snapshot_num^2+4*d_gamma_init*(mu(ik,:)*mu(ik,:)'+snapshot_num*Sigma(ik,ik))))/(2*d_gamma_init);
end
%% 更新alpha_0
alpha_0 = (snapshot_num*array_num+c_sigma0_init-1)/(norm(Y-Phi*mu,'fro')^2+snapshot_num*trace(Phi*Sigma*Phi')+d_sigma0_init);%%(18),范数部分详见18至19之间部分
alpha_0_seq(iter) = alpha_0;
%% 判断是否停止迭代
if norm(alpha-alpha_last)/norm(alpha_last) < tol || iter >= maxiter
converged = true;
end%%收敛或迭代次数达到上限时进入该循环
%% 更新beta
[beta,index_b] = off_grid_operation(Y,alpha,array_num,mu,Sigma,Phi,B,beta,r);
reso_grid(index_b) = reso_grid(index_b)+beta(index_b)*180/pi;
end
res.mu = mu;
res.Sigma = Sigma;
res.beta = beta;
res.alpha = alpha;
res.iter = iter;
res.sigma2 = 1/alpha_0;
res.sigma2seq = 1./alpha_0_seq(1:iter);
res.reso_grid = reso_grid';
end
function [beta,index_b] = off_grid_operation(Y,gamma,iter_size,mu,Sigma,Phi,B,beta,r)
reso_num = size(B,2);
snapshot_num = size(Y,2);
[~, index_b] = sort(gamma, 'descend');
index_b = index_b(1:iter_size);%%选定位置进行一阶泰勒展开
temp = beta;
beta = zeros(reso_num,1);
beta(index_b) = temp(index_b);
BHB = B'*B;
P = real(conj(BHB(index_b,index_b)).*(mu(index_b,:)*mu(index_b,:)'+snapshot_num*Sigma(index_b,index_b)));%%(20)
v = zeros(length(index_b), 1);%%(21)
for t = 1:snapshot_num
v = v+real(conj(mu(index_b,t)).*(B(:,index_b)'*(Y(:,t)-Phi*mu(:,t))));
end
v = v-snapshot_num*real(diag(B(:,index_b)'*Phi*Sigma(:,index_b)));
eigP = svd(P);
eigP = sort(eigP,'descend');
if eigP(end)/eigP(1) > 1e-5 || any(diag(P) == 0)
for n = 1:iter_size
temp_beta = beta(index_b);
temp_beta(n) = 0;
beta(index_b(n)) = (v(n)-P(n,:)*temp_beta)/P(n,n);%%(26.1)
if abs(beta(index_b(n))) > r/2%%(26.2)
beta(index_b(n)) = r/2*sign(beta(index_b(n)));
end
if P(n,n) == 0
beta(index_b(n)) = 0;
end
end
else
beta = zeros(reso_num,1);
beta(index_b) = P\v;
end
end
仿真结果如下所示:
角度估计:
部分参考文献:


















 1482
1482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









