







提示:
信息检索:索引压缩-词项的统计特性(Heaps定律、Zipf定律)
回顾


Heaps定律
一种对词项数目M进行估计的方法是采用Heaps定律: M=kT^b。

对RCV1文档集来说,虚线log10M = 0.49log10T + 1.64
是基于最小二乘法的最佳拟合,则M= 101.64 * T0.49,
所以k =101.64≈44, b=0.49对RCV1是一个很好的经验拟合.
对于前1,000,020个词条,Heaps定律会估计得到大约38,323个词项;而实际数目是38365,和估计值非常接近.

Heaps定律提供了对文档集中词汇量的估计
我们还想了解词项在文档中的分布情况,在自然语言中,只有很少一些非常高频的词项,而其它绝大部分都是很生僻的词项
Zipf定律
排名第i多的词项的文档集频率与1/i成正比
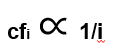
cfi是文档集频率:词项t在文档集中出现的次数
Zipf定律推论
如果最高频的词项(the)出现了cfn次
那么第二高频的词项(of)出现了cf1/2次
第三高频的词项(and)出现了cf1/3次
等价的: cfi= K/i中K是归一化因子,所以
log cfi= log K- log I
log cfi和log i之间存在着线性关系

















 1790
1790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











