







 文章介绍了一种新的图像生成技术DiffusioninStyle,通过利用Stable-diffusion的潜在张量特性,通过计算目标风格图像的统计信息来创建适应特定风格的噪声分布,从而生成具有精确风格的图像。方法相比传统微调减少了训练需求。实验结果显示在风格匹配和图像质量上优于现有方法。
文章介绍了一种新的图像生成技术DiffusioninStyle,通过利用Stable-diffusion的潜在张量特性,通过计算目标风格图像的统计信息来创建适应特定风格的噪声分布,从而生成具有精确风格的图像。方法相比传统微调减少了训练需求。实验结果显示在风格匹配和图像质量上优于现有方法。
本文是发表于ICCV 2023上的一篇文章,主要是实现了风格化的扩散模型
论文主页Diffusion in Style (ivrl.github.io)
CVF论文地址ICCV 2023 Open Access Repository (thecvf.com)
一、Intorduction
使用大规模的文本生成图像模型来实现具有特定类别的图像是一个很有吸引力的想法。然而,在生成的图像上实施连贯的风格并不简单。在输入文本提示中描述样式通常不足以获得所需样式的图像。所以我们一般的做法是对模型进行微调,但是现存的一些方法总会产生一些比如结果可能远非美观,与所需风格不精确匹配等问题。
通过实现发现,在Stable-diffusion中,初始潜在张量影响生成的图像的风格和布局。使用相同的初始潜张量和不同的文本提示生成的图像通常会导致具有共享属性的图像,例如相似的颜色,亮度和对象定位。因此,我们假设,标准高斯分布,从初始潜在张量采样,防止生成所需风格的图像。
所以论文由此提出了风格扩散(Diffusion in Style),用于实现自定义风格的图像生成。Diffusion in Style背后的关键思想是使用风格相关的初始潜在张量开始去噪过程。我们通过简单地估计一小组目标风格图像的潜在编码的元素方式的平均值和标准差,获得初始潜在张量的风格特定的分布。在第二步中,这给我们留下了一个简单的微调,它需要比以前的方法少几个数量级的图像和/或训练迭代。此外,风格扩散的图像生成效果也是相对不错。
二、Related Work
2.1. Latent space statistics for style representation
这里实际上就是说图像的风格可以被看做是特征分布的,在论文所提的方法中,使用潜在张量每个位置的平均值和方差作为先验风格,然后让稳定扩散在目标样式图像上进行微调,从而生成有着相应风格的图像。
2.2. Controlling the style of Stable Diffusion
这部分首先介绍了现存的一些控制Stable Diffusion 生成图像样式的方法,这里就不叙述,然后讲述了论文所提的方法:从相同的初始潜张量使用稳定扩散生成的图像通常具有相同的属性,例如相似的颜色和对象定位。由于通过对参考图像的噪声版本而不是随机初始潜张量进行去噪,可以保持参考图像的某些属性。这只需要使用最低的时间步长。所以论文在稳定扩散中,从其中采样初始潜在张量的标准噪声分布会阻止生成所需风格的图像,并且应该适应特定于风格的噪声分布。
2.3. Modifying the forward diffusion process
这部分主要是说,将标准噪声分布N(0d,Id×d)更改为特定于样式的噪声分布N(style,
style),通过不改变前向扩散的类型,而只改变噪声分布的位置μ和协方差μ,避免了从头开始重新训练稳定扩散,并将其微调为仅1000次迭代和一小组图像的特定样式分布。
3. Diffusion in Style
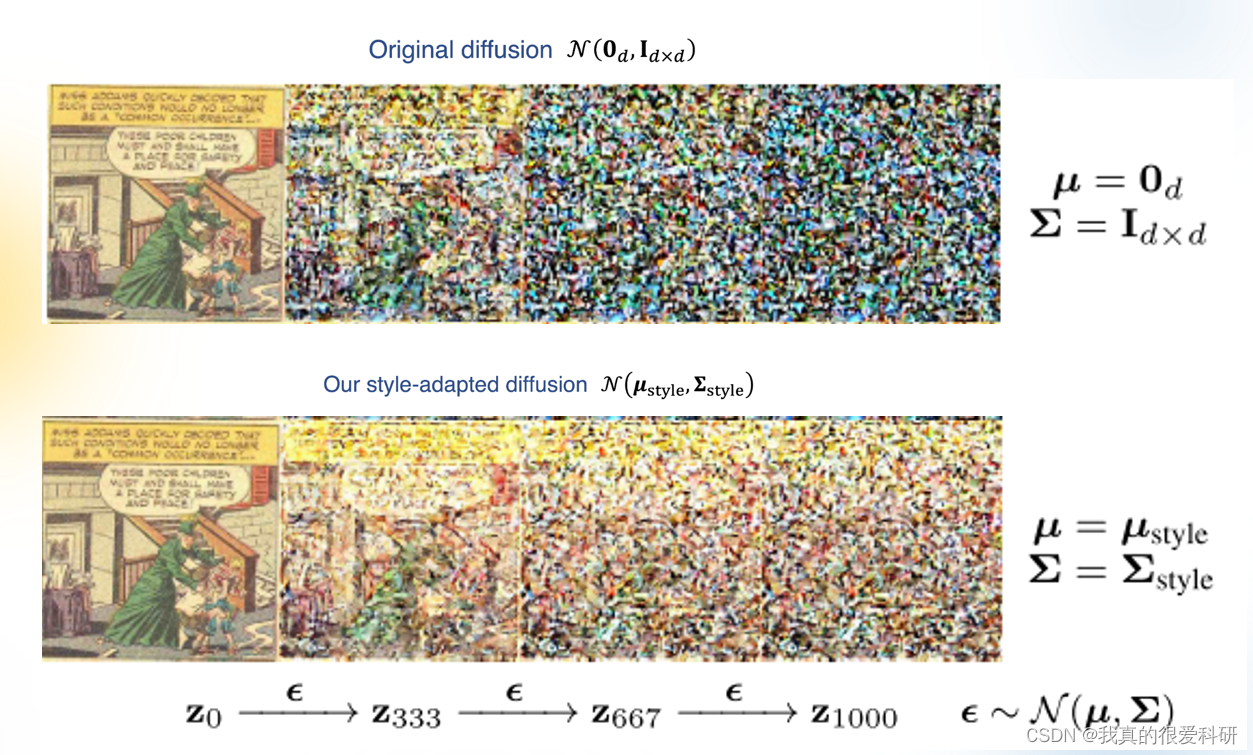
Stable Diffusion在扩散过程中,主要预测噪声分布是指标准正态分布N(0,1),而Diffusion in Style的关键思想实际上就是将标准正态分布N(0,1)用一个适应于特定风格的噪声分布N(style,
style)。
如何实现Diffusion in Style呢?主要是通过两个步骤,首先是通过输入的一组目标图像计算出适应风格的噪声分布,然后将适应风格的噪声分布应用到扩散模型的UNet网络中,从而实现生成相应风格的图像。
在“Diffusion in Style”中,为了计算新的适应风格的噪声分布,我们从目标风格图像集合中提取出潜在张量,并计算每个元素的均值和方差。这些均值和方差用于计算新的适应风格的噪声分布。新的噪声分布是一个多元高斯分布,其中每个元素的噪声都是从一个均值为μ,方差为σ^2的正态分布中独立采样得到的。在原始的Stable Diffusion中,均值μ等于0,方差矩阵Σ等于单位矩阵I。在适应风格的噪声分布中,均值μ和方差矩阵Σ是从目标风格图像集合中计算得到的。其中,均值μ是目标风格图像集合中每个元素的均值,方差σ^2是目标风格图像集合中每个元素的方差。
style和
style是用于计算适应风格的噪声分布的两个参数。具体来说,
style是一个均值向量,
style是一个协方差矩阵。
对于style,我们首先从目标风格图像集合中提取出一小部分图像的潜在张量,然后计算它们在每个位置上的均值。对于
style,我们使用与
style相同的方法来计算每个位置上的标准差。最后,我们将每个位置上的方差开方,得到每个位置上的标准差。这样,我们就得到了一个与输入图像大小相同的标准差张量,它被用作适应风格的噪声分布的协方差矩阵的对角线元素。
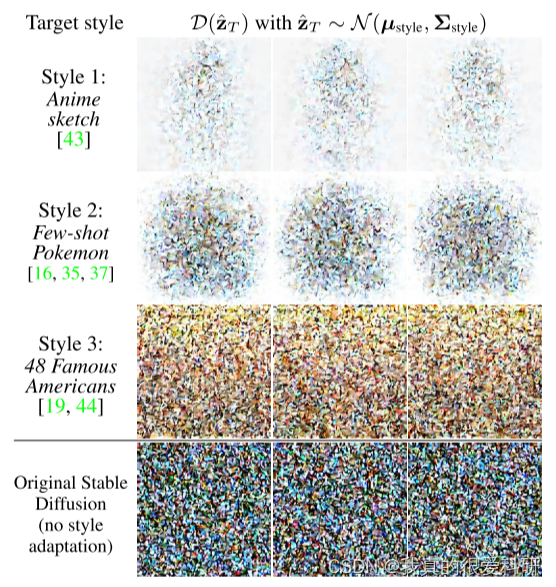
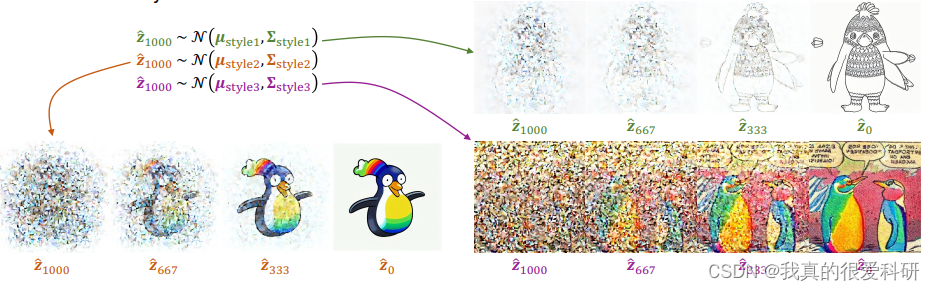
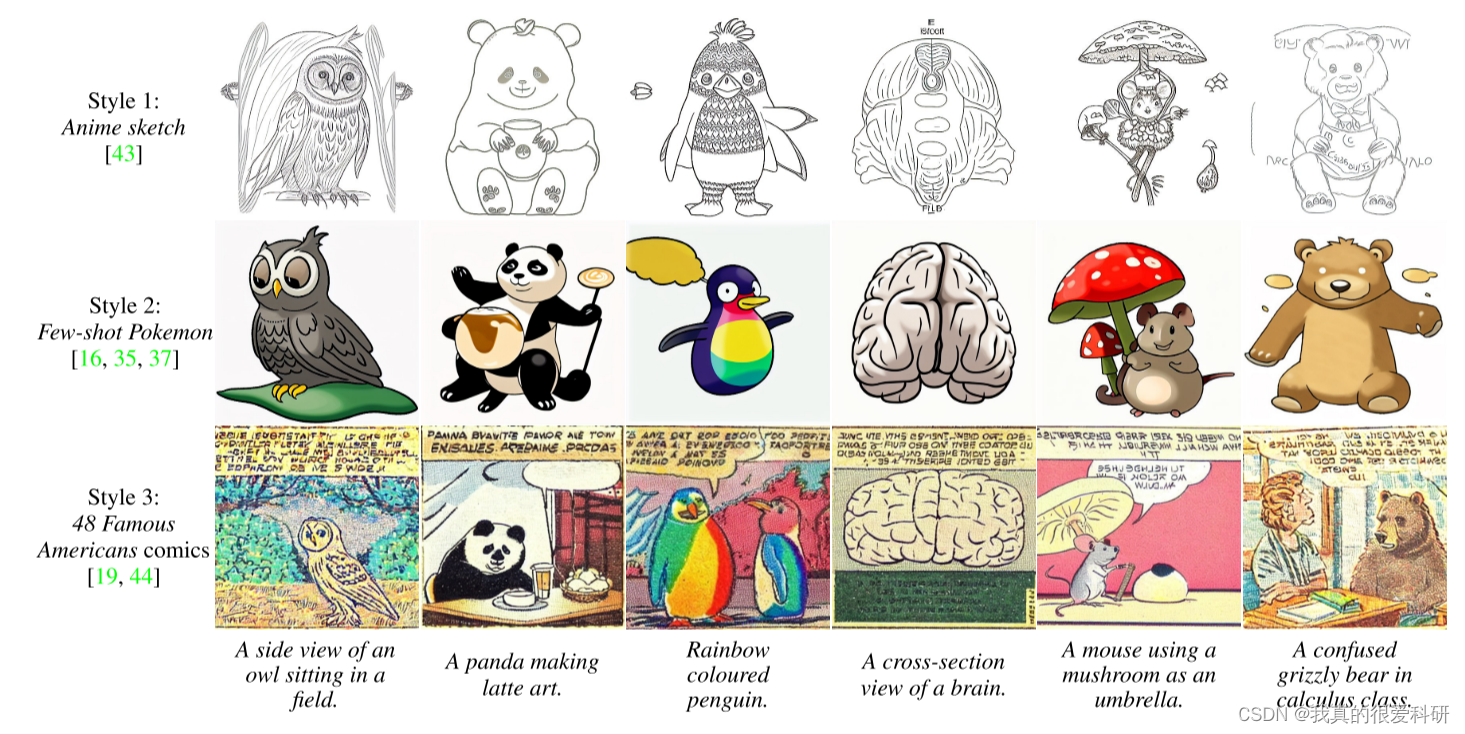
4.Experiments and results
这部分主要是展示了生成图像的结果,以及与现有的一些方法所生成的图像做的比较。
5.Quantitative evaluation
在对生成图像作质量评估时,主要采用了Clip和FID两个指标。
CLIP分数用于衡量生成图像与给定文本提示之间的相关性,而标准FID分数用于衡量生成图像与原始图像的差异程度。通过比较这两个指标,可以评估不同方法在样式匹配和图像质量方面的表现。
在评估FID值时,论文中确实使用了来自目标风格的图像与生成图像进行比较。这样做是为了衡量生成图像与真实图像之间的差距。通过将生成图像与目标风格图像进行对比,可以评估生成图像的质量和风格匹配程度,从而得出FID值。
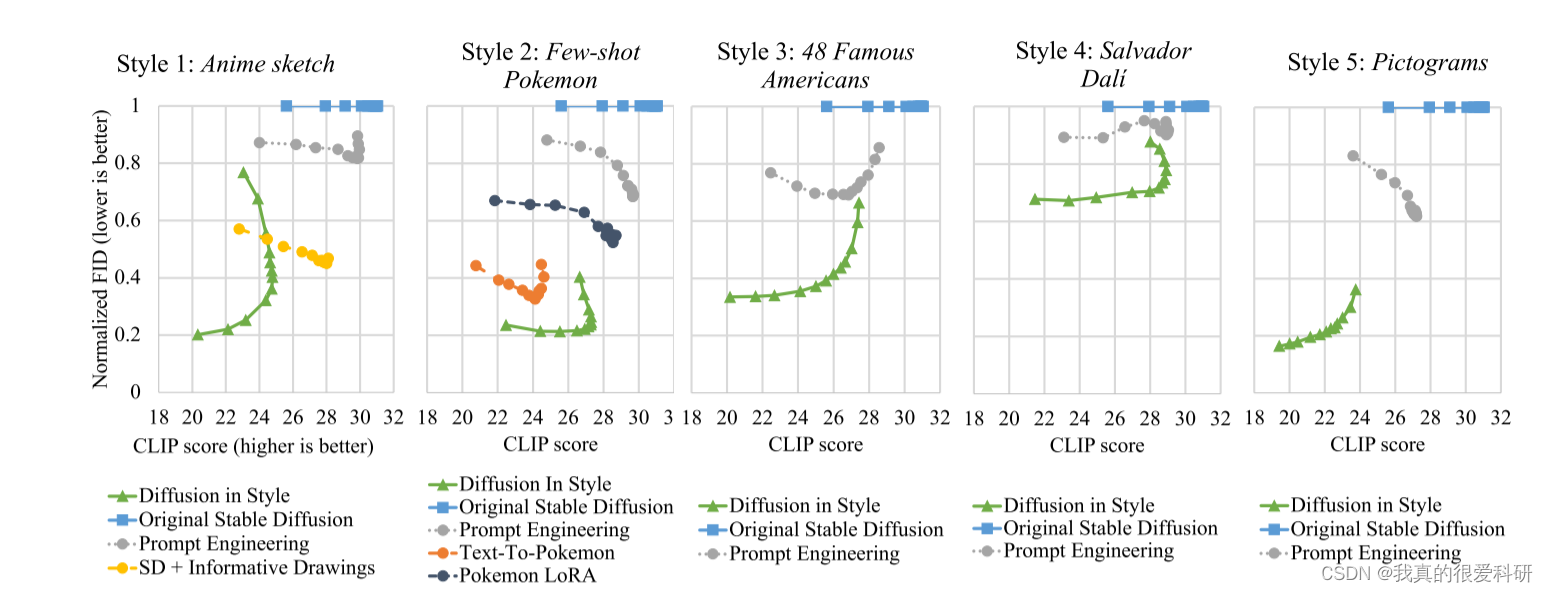
上图中,FID和CLIP分数的曲线沿着一系列的指导权重。使用一系列指导权重({1.0,1.5,2.0,3.0,4.0,5.0,6.0,7.0,8.0,10.0,15.0,20.0})进行评估,从而得出每个模型的曲线。对于图中的每个点,已经用相应的模型和引导权重生成了800个图像。这800个图像对应于DrawBench [27]中200个提示中的每个提示的4个图像。所有800个图像都是用不同的初始潜张量生成的,但是在不同的评估点上使用相同的初始潜张量。每条曲线的最左边的点总是对应于1.0的引导权重。风格扩散的总体趋势,a形,证实了在4.2节中观察到的风格和内容之间的权衡。增加引导权重通常以降低风格匹配为代价来改善如由CLIP分数测量的快速对齐,如由归一化FID分数测量的。附录E中提供的用户研究与此处提供的CLIP/FID评分一致。
在图中,每个点代表了不同模型在指定条件下的性能表现。这些点的横坐标表示CLIP分数,纵坐标表示标准FID分数。这些指标用于评估生成图像与给定文本提示之间的相关性和生成图像与原始图像的差异程度。
5. Conclusion
这篇文章主要提出一个新方法:风格适应稳定扩散。通过对一组目标风格的图像计算得到适应风格的噪声分布,然后对UNet进行微调以实现生成对应目标风格的图像。这和我之前度读过的一篇发表于CVPR 2023上的一篇同样是微调Diffusion的方法DreamBooth有一些相似,具体有关DreamBooth的内容可以参考【论文笔记】DreamBooth,当然论文中也提到了DreamBooth这个方法,说DreamBooth并没有实习风格的特定,而只是针对于特定的对象实现的,以及DreamBooth的缺点,就是一些特殊的对象,在使用DreamBooth调整特定风格的模型需要数千个目标风格图像和多达40万次迭代。但总体而言都是实现了生成图像的个性化。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











