







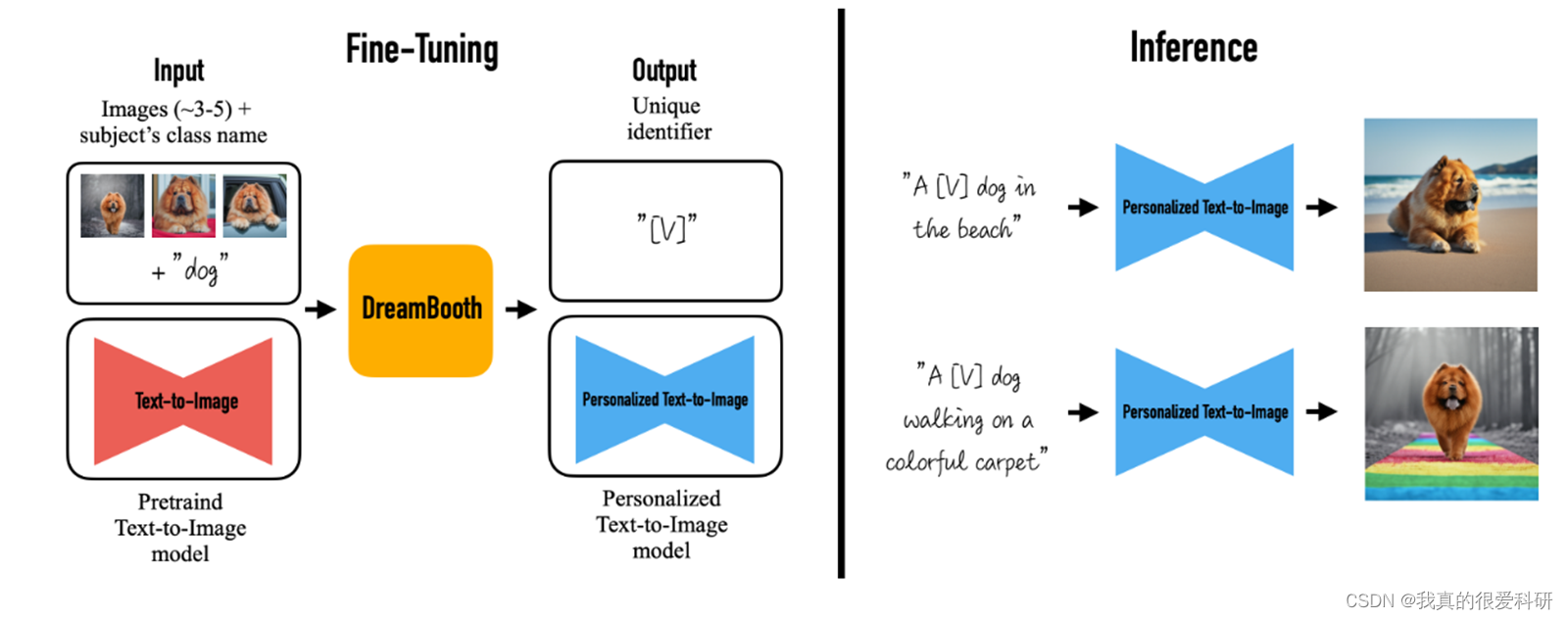
 本文介绍了一种新的方法DreamBooth,通过微调预训练的文本到图像模型,实现个性化主题生成。该模型结合了语义先验和自生类特定的先验损失,能在不同场景中生成与特定主题一致的图像,提升图像质量和一致性。
本文介绍了一种新的方法DreamBooth,通过微调预训练的文本到图像模型,实现个性化主题生成。该模型结合了语义先验和自生类特定的先验损失,能在不同场景中生成与特定主题一致的图像,提升图像质量和一致性。
本文是发表CVPR2023上的一篇论文
论文链接:[2208.12242] DreamBooth:微调文本到图像扩散模型,用于主题驱动的生成 (arxiv.org)
官网论文链接:DreamBooth

论文主要的创新点在于提出了一种新的方法DreamBooth以实现“个性化”的文本到图像的扩散模型。大致的想法如下:给定一个主题的几张图像作为输入,微调一个预训练的文本到图像模型,使它学会将唯一标识符与该特定主题绑定。一旦主体被嵌入到模型的输出域中,唯一标识符就可以用于合成在不同场景中情境化的主体的新颖的照片级真实感图像。通过利用嵌入在模型中的语义先验与一个新的自生类特定的先验保存损失,以实现合成的主题在不同的场景,姿势,视图和照明条件下都能够生成关于特定主题的图像。
Intorduction
当前扩散模型在图像生成方面大放异彩,能够生成许多高质量的图片,但有时候我们希望生成特定对象的一些图片,也就是所谓的特定主题的图像生成。
目前最新的文本到图像模型已经在这方面取得了重要进展,通过学习大量图像和标题对之间的语义关联,实现了高质量和多样化的图像合成。 然而,这些模型缺乏在特定主题的外观建模能力,并且不能以一致的方式在不同上下文中合成相同主题的图像。为了解决这个问题,作者提出了一种名为DreamBooth的新方法,即个性化的文本到图像扩散模型。该方法通过扩展模型的语言视觉词典,将新单词与用户指定的特定主题相关联。通过这种方式,模型可以使用这些新单词生成与主题相关的图像,并保持其关键特征。论文中详细介绍了此方法,包括使用罕见的令牌标识符表示特定主题,并微调预训练的文本到图像框架。除此之外,作者还提出了一个自生成的、特定于类别的先验保留损失,以避免语言漂移并保持生成的实例的多样性。
最后,作者强调了他们方法的应用潜力,包括重新语境化主题、修改主题属性以及原创艺术品的生成。他们通过构建一个新的数据集来评估这个新任务,并表示他们是第一个解决这一主题驱动生成问题的技术。目标是使用户能够从几个捕获的图像中合成不同主题的图片,并在不同的背景下保持其独特特征。
Related work
Text-to-Image Editing and Synthesis.
文本到图像编辑和合成领域近年来取得了重大进展,其中使用了基于生成对抗网络 (GAN) 和图像-文本表示 (如CLIP) 的方法,实现了逼真的图像操作。这些方法在结构化场景(如人脸编辑)中表现出色,并且能够在不同主题的数据集上进行操作。一些研究通过在更多样化的数据上训练模型来提高生成结果的多样性。 最近的研究还利用了扩散模型,这些模型在多样化的数据集上实现了最先进的生成质量,通常超过了传统的GAN方法。这些方法大多只允许对整个图像进行全局编辑,但也有一些研究提出了基于文本的局部化编辑技术,而无需使用掩码,取得了令人印象深刻的结果。 尽管大多数编辑方法可以修改图像的全局属性或对特定图像进行局部编辑,但目前还没有一种方法能够在不同的上下文中生成给定主题的新颖再现。此外,还存在一些文本到图像合成的研究,其中最近的大型文本到图像模型展示了前所未有的语义生成能力。 然而,这些模型仍然缺乏对生成图像的细粒度控制,并且仅依赖于文本提示进行生成。具体而言,跨生成图像并保持对象身份的一致性仍然具有挑战性,有时甚至是不可能的。这是该领域仍然需要解决的一个问题。
Controllable Generative Models.
在控制生成模型方面,有多种方法可以用于主题驱动的图像合成。一些方法已经被证明是可行的途径。其中一种方法是基于扩散的技术,允许使用参考图像或文本来引导图像的变化。另外,一些方法使用用户提供的掩码来限制修改的区域,以克服主题修改的问题。倒置技术可以在修改上下文的同时保留主体的特征。快速提示技术能够在没有输入掩码的情况下进行局部和全局编辑。
Method
Text-to-Image Diffusion Models
这部分主要是介绍的扩散模型的一些概念,主要提到论文中所需要用到一个预训练的扩散模型,具体有关扩散模型的概念在此就不多叙述了。
Personalization of Text-to-Image Models
为实现个性化的文本生成图像模型,首先我们的第一个任务就是要将特定主题的实例植入到模型的输出域中,这样我们就可以在模型中查询主题的各种新颖的图像。我们希望能够通过较少的图片来对模型进行微调,但是在微调的过程中应该避免模型产生过拟合和模式崩溃以及无法充分捕获目标分布等问题。
为了将一个新的(唯一标识符,主题)对植入到扩散模型的字典中,论文采用了一种简化方法,将主题的所有输入图像标记为“[identifier] [class noun]”。其中,[identifier]是与主题相关的唯一标识符,[class noun]是主题的大致类别描述(如猫、狗、手表等)。这些类别描述符可以由用户提供或通过分类器获得。我们可以在句子中使用类别描述符,以便将类别的先验知识与我们唯一的主题相关联。但作者发现,使用错误的类别描述符或没有类别描述符会增加训练时间和语言漂移,并降低性能。 基本上,我们试图利用模型对特定类别的先验知识,并将其与主题的唯一标识符嵌入在一起,以便在不同的上下文中生成主题的新姿势和表达。这样一来,我们可以借助视觉先验知识生成具有不同姿势和表达的主题图像。
那我们应该如何选择[identifier] ?我们需要选择一种标识符,它在语言模型和扩散模型中没有明显的含义。同时,我们也不希望模型将这些标识符与现有的英语单词联系起来。因为如果模型认为这些标识符实际上是某种特定含义的单词,可能会导致性能下降。 为了避免这种情况,论文采用了一种方法。我们通过在词汇表中寻找罕见的标记,然后将这些标记转换为文字。这样,我们可以最小化标识符与强先验知识的关联。我们得到一个由字符组成的序列。这个序列的长度可以是不固定的,我们发现长度为1到3的字符序列效果较好。
具体来说,论文使用一个稀有令牌查找方法,在词汇表中找到罕见的标记。然后,将字符序列转换成文字,得到了一个定义了唯一标识符的序列。对于Imagen这个例子,发现在T5-XXL令牌化器中,使用最多包含3个Unicode字符(不包括空格)的标记进行均匀随机采样,并且选择的范围是从5000到10000。 通过这种方式,能够减少标识符的先验知识,使其更适合用于生成具有不同姿势和表达的主题图像。
Class-specific Prior Preservation Loss
这部分主要就是讲解论文提出的这个特定类别的先验损失
作者发现,模型在使用少量图像进行微调时,模型可能会过度拟合这些图像,从而忘记了如何生成与这些图像相似但不完全相同的图像。这种现象被称为"过拟合",它会导致模型在生成图像时偏离先验信息,从而产生语言漂移。
提出这个损失函数的原因是为了解决在生成图像时出现的语言漂移问题,从而提高生成图像的质量和准确性。通过使用先验信息来指导生成图像的过程,可以使生成的图像更加多样化和一致化,从而提高生成图像的质量和准确性。
这个损失的本质实际上就是在训练之前先用模型生成一系列的这个类别的图像,然后我们在训练过程中,利用这些生成的图像来监督整个模型的训练,以防止出现语言漂移的问题。
然后我们来看DreamBooth方法的训练过程。
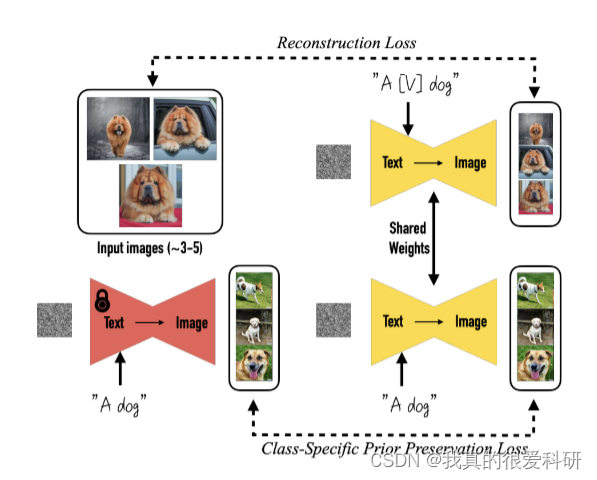
上边的部分就是输入特定主题的3-5张图像进行训练,以图中为例,此时的输入词就是 “A [V] dog”,当然在训练的过程中,会有一个Reconstruction Loss,用于约束生成和原始图像接近的图片。
然后下半部分主要就是论文所提出的这个特定类别的先验损失(Class-specific Prior Preservation Loss)。还是以图为例,在训练之前,先用模型生成一系列“A dog”的图像,这些图像中会有各种各样的狗,也会产生于各种各样的环境。将这些图像用于在训练过程中约束整个模型, 从而防止产生语言漂移问题。也就是说当训练开始之后,虽然参数更新了,但是输入 a dog,模型需要依然能够生成各种各样的狗和环境,仍然具有多样性,而不是说只会生成特定的狗。也就表示模型在训练过程中对 dog 这个单词的认识并没有发生改变,也就是说模型没有发生语言漂移,只有在输入含有特定标识符的文本(即 "A [V] dog")才能产生特定主题的图像。
Experiments
Dataset and Evaluation
Dataset:
数据集包含 30 个物体,其中既有静止不动的物体,也有活着的动物,每个物体有 25 种不同的prompts,从而组合起来就形成了 750 种不同的图片文本对。为了评估模型的好坏,需要对每个图像文本对生成 4 个图片,这样总共就生成了 3000 个不同的图片。
Evaluation Metrics:
"subject fidelity" 指的是生成的图像与原始图像之间的相似度,也就是生成图像的质量。
"prompt fidelity"指的是生成的图像与文本提示之间的相似度,也就是生成图像是否符合文本提示的要求。
这两个指标都是用来衡量DreamBooth生成图像的质量和准确性的。通过提高这两个指标,DreamBooth可以生成更高质量、更准确的图像。
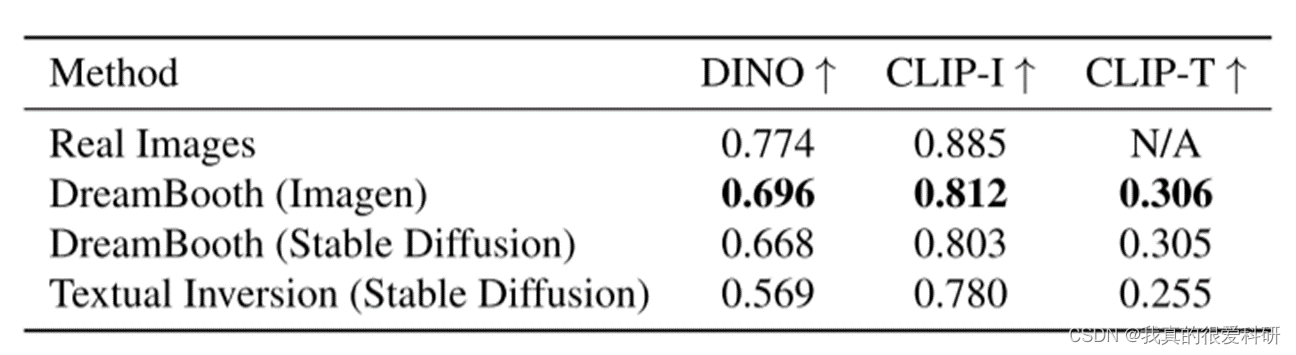
CLIP-I指的是生成的图像与真实图像之间的相似度,通过计算它们之间的平均成对余弦相似度来衡量。这个指标主要关注保留主体细节,确保生成的图像能够准确地反映真实图像的内容。
DINO是我们提出的度量标准,它计算生成的图像和真实图像的ViTS/16 DINO嵌入之间的平均成对余弦相似性。与CLIP-I不同的是,DINO的目标是鼓励模型区分不同主题或图像的独特特征,而不是仅仅关注相似的文本描述。
CLIP-T衡量的是生成图像与文本提示之间的相似度,通过计算它们之间的平均余弦相似度来评估。这个指标主要用于衡量模型在理解文本提示并生成相应图像方面的能力。
在不同的扩散模型实现后的比较:
在同一扩散模型上将论文所提出的DreamBooth方法与Textual Inversion 方法进行比较:

生成效果展示:



















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











