







本文是发表于SIGGRAPH(Special Interest Group on Computer Graphics and Interactive Techniques)上的一篇文字,被收录于ACMTrans.Graph。
论文地址:参与和激励 (yuval-alaluf.github.io)

一、Intorduction
这部分主要就是说,最新的基于文本的图像生成研究已经取得了前所未有的进展,能够生成多样化和创造性的图像。然而,一些研究表明,生成的图像并不总是忠实地反映目标提示的语义含义。特别是出现了“灾难性的忽视”和不正确的“属性绑定”问题。为了解决这些语义问题,研究者提出了“生成语义护理”(GSN)的概念,并引入了一种名为Attend-and-Excite的GSN形式。该方法利用了预先训练的扩散模型的强大交叉注意力图,通过要求每个主题标记在图像中的某个部分占主导地位来解决问题。该方法不需要额外的训练或微调,通过动态应用在推理时间内来提升图像生成的质量。该方法能够减轻灾难性忽视问题并隐含地鼓励属性和主题之间的正确绑定。实证结果表明,Attend-and-Excite在生成语义上忠实的图像方面具有优势,并强调了减轻灾难性忽视问题的重要性。
二、Related work
早期的研究主要探索了在生成对抗网络(GAN)框架下的文本引导图像合成方法。最近,大规模自回归模型和扩散模型取得了令人印象深刻的结果。然而,仍然存在生成与输入提示对齐的挑战。为了增强对文本的依赖,一些研究采用了无分类器指南的方法,允许外推文本驱动的梯度来更好地指导生成。然而,实现预期结果通常需要大量的工程设计。为了提供更多对合成过程的控制,一些研究引入了分割图或空间条件。在图像编辑的背景下,一些方法使用用户提供的掩码来指定应该更改的区域。还有一些相关工作将特定概念引入到预训练的文本到图像模型中,例如通过学习将一组图像映射到嵌入空间中的“单词”。最近研究还探索了仅通过使用输入文本提示为用户提供更多控制的方法。有两个最新的研究探讨了文本到图像模型的语义问题,并提出了解决方法,但这些方法在实际应用中存在一些限制。与之相比,论文提出的Attend-and-Excite技术通过优化潜伏表示来实现图像合成,并能够生成与扩散模型产生的图像有显着差异的图像。同时,基于文本的图像合成还存在其他语义问题,如对象关系和组合,解决这些问题可能需要额外的模型。
三、Preliminaries
这部分主要讲了基于Latent Diffusion的Stable Diffusion的基本原理,主要就是在Stable Diffusion中,通过交叉注意进行文本调节。稳定扩散中的文本引导使用交叉注意机制执行。去噪UNet网络由自注意层和交叉注意层组成。
四、Attend-and-Excite

上图是Attend-and-Excite方法的整体原理图,根据我自己的理解,第一行就是整个扩散模型在图像生成的去噪过程。
第二行显示了文本的交叉注意力图。在扩散模型中,交叉关注图被用来通过专注于文本提示中提到的特定元素来引导图像生成过程。它在图像合成过程中应用,以确保生成的图像准确反映输入文本提示的内容,这里主要是提取主题标记所对应的注意力图以做处理。
第三行主要讲述的就是对主题标记的注意力图的处理以及论文中所提出的一个新的自定义损失函数的计算。首先会将注意图做一个高斯平滑处理(高斯平滑是一种用于减少图像或信号中的噪音和细节的技术。它通过对每个像素周围的像素值进行加权平均来工作,平均值由高斯函数加权。在“Attend-and-Excite”中,高斯平滑被应用于注意力地图,以确保注意力值平滑分布,并防止注意力分布的突然变化,这可能导致不稳定的优化行为。这有助于为图像生成过程创建更稳定和可靠的引导。)然后分别计算每个主题标记的损失,这里的公式含义是:( Ls ) 代表特定主题标记的损失,( A{s,t} ) 代表时间步 ( t ) 处标记 ( s ) 的注意力值。最终的损失Loss是所有Ls中最大的那个。
损失函数试图加强每个时间步中被忽视的主题标记的激活,鼓励在某个时间步加强一个被忽视的主题标记。比如图中最后计算L2和L5,最后的损失选择两个中的最大值,从而对最不被关注的主题增加关注,损失计算出来后,利用梯度下降法来更新潜在张量Zt。
五、experiments
由于目前还没有开放的数据集来分析基于文本的图像生成中的语义问题,我们构建了一个新的基准来评估所有方法。为了分析灾难性忽视的存在,我们构建了包含两个主题的提示。此外,为了测试正确的属性绑定,提示应该包含与主题标记匹配的各种属性。具体来说,我们考虑三种类型的文本提示:(i)“a [animalA] and a [animalB]",(ii)“a [animal] and a [color][object]",(iii)“a [colorA][objectA] and a [colorB ][objectB]"。
由于颜色设置是随机的,所以可以概括为三类:动物-动物和对象-对象对以及动物-对象。
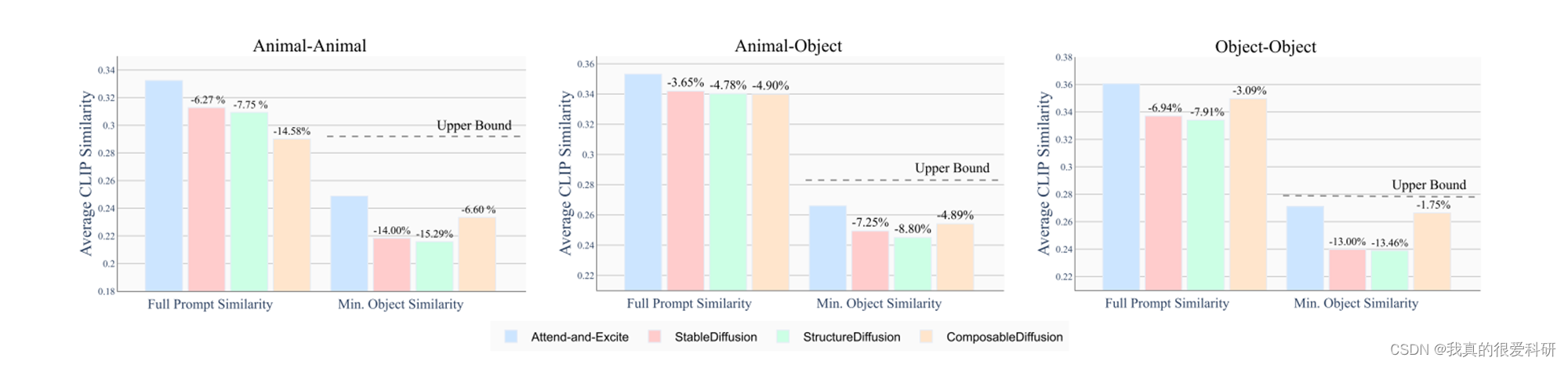
论文所用指标为Average CLIP Similarity,也就是文本提示和每种方法生成的图像之间的CLIP图像-文本相似度的平均值,按不同类别划分。完整提示相似度表示考虑全文提示时的图像-文本相似度,而最小对象相似度表示最被忽略的主题的平均CLIP相似度。(图中其他方法的百分比是相对于Attend-and-Excite所得分数的比较)。

论文还用了一个预训练的BLIP图像字幕模型来生成与输入提示对应的图像字幕。然后,我们计算输入提示和字幕之间的平均CLIP相似度。CLIP模型具有强大的语义先验,因此被选择用于计算文本之间的相似性。在计算文本-文本相似度时,研究者观察到Attend-and-Excite方法在各个子集中超过了其他方法至少4.7%的性能。这表明该方法能够有效捕捉到原始提示中的主题和属性。
实验证明,论文所提出的Attend-and-Excite方法相对于其他方法有着更好的性能。

















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











