









Attend-and-Excite: Attention-Based Semantic Guidance for Text-to-Image Diffusion Models
- 给定一个预训练的文本到图像的扩散模型(例如,Stable Diffusion [Rombach等人,2022年]),我们的方法“Attend-and-Excite”指导生成模型在图像合成过程中修改交叉注意力值,以生成更能忠实描绘输入文本提示的图像
- 仅使用Stable Diffusion(上排)在生成多个对象(例如,一匹马和一只狗)时存在困难。然而,通过融入“Attend-and-Excite”(下排)来加强主体标记(以蓝色标记),我们能够获得与输入文本提示在语义上更忠实的图像。

- 我们引入了生成性语义护理(Generative Semantic Nursing,GSN)的概念,我们试图在推理过程中实时干预生成过程,以提高生成图像的忠实度。通过使用基于注意力的GSN表述,我们将其命名为Attend-and-Excite,指导模型细化交叉注意力单元,以关注文本提示中的所有主体标记,并加强或激发它们的激活,从而鼓励模型生成文本提示中描述的所有主体
Introduction
-
我们观察到在基于文本生成的图片中,有两个严重的语义错误
- “灾难性忽视”,即没有生成提示中的一个或多个主体
- “属性绑定错误”,即模型将属性绑定到错误的主体上或完全未进行绑定
-
在GSN过程中,我们在去噪过程的每个时间步上稍微调整潜在代码,以便鼓励潜在代码更好地考虑从输入文本提示传递的语义信息。
-
我们提出了一种名为“Attend-and-Excite”的GSN(生成性语义护理)形式,该方法利用了预训练扩散模型的强大交叉注意力图。这些注意力图为每个图像块上的文本标记定义了一个概率分布,从而决定了块中的主导标记
- 尽管每个块可以自由地关注所有文本标记,但没有机制确保所有标记都被图像中的某个块关注。在主题标记未被关注的情况下,相应的主题将不会在输出图像中表现出来。
- 每个patch定义一个文本标记的概率分别,从而确定patch中的主导标记
-
因此,直观上,为了使一个主体出现在生成的图像中,模型应该至少将一个图像块分配给该主体的标记
- Attend-and-Excite通过要求每个主体标记在图像的某个块中占据主导地位来体现这一直觉
- 我们仔细地在每个去噪时间步上引导潜在代码,并鼓励模型关注所有主体标记并加强——或激发——它们的激活
- 重要的是,我们的方法在推理时实时应用,不需要额外的训练或微调
- 相反,我们选择保留预训练生成模型和文本编码器已经学习到的强大语义
-
虽然Attend-and-Excite只明确解决了灾难性忽视的问题,但我们的解决方案间接地鼓励了属性和其主体之间的正确绑定。
- 这可以归因于灾难性忽视和属性绑定这两个问题之间的联系。
- 通过预训练的文本编码器获得的文本嵌入,将每个主体及其对应属性之间的信息联系起来
Related work
- Feng等人[2022]提出了StructureDiffusion,它使用一致性树或场景图将提示拆分为多个名词短语。为每个名词短语计算一个注意力图,并且交叉注意力单元的输出是所有注意力操作的平均值。
- 我们发现,StructureDiffusion得到的结果往往与Stable Diffusion产生的结果相似,未能实现有意义的修改来修正语义错误(见第5节)。
Preliminaries
-
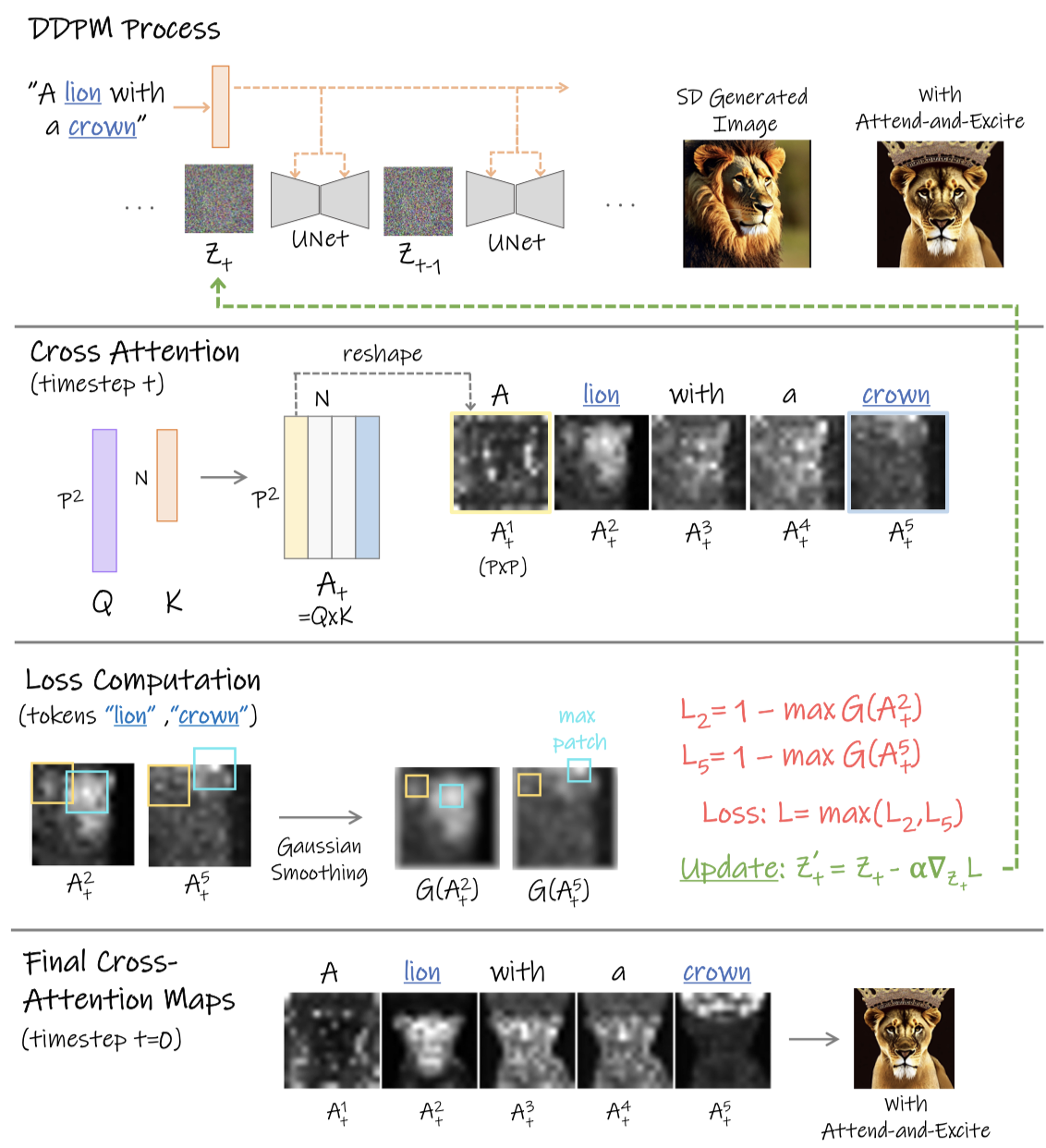
图3. Attend-and-Excite概述。给定一个提示(例如“一头戴着皇冠的狮子”),我们提取主题标记(狮子,皇冠)及其对应的At_2,At_5个注意力图。我们在每个注意力图上应用高斯核以获取平滑的注意力图,这些图会考虑相邻的块。我们的优化方法会增强在时刻𝑡下被忽略最多的标记的最大激活值,并相应地更新潜在代码𝑧𝑡。在𝑡=0时的最终交叉注意力图显示在最后一行。
- 增强在时刻t下被忽略最多的标记的最大激活值是什么意思?
-
设𝑃为中间特征图的空间维度(即,𝑃 ∈ {64, 32, 16, 8}),𝑁为提示中的文本标记数量
-
通过在中间特征(𝑄)和文本嵌入(𝐾)的线性投影上计算得到一个注意力图,如图3的第二行所示
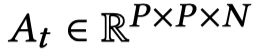
-
𝐴 𝑡定义了每个空间块(𝑖, 𝑗)在文本标记上的分布,t应该是指去噪步骤第t步
- 具体来说,𝐴 𝑡 [𝑖, 𝑗 ,𝑛]表示对于中间特征图的第(𝑖, 𝑗)个空间块,赋予标记𝑛的概率,也就是这个ij块是第k(k属于n)文本词的概率
- 直观地看,这个概率表示从标记𝑛到块(𝑖, 𝑗)传递的信息量。请注意,每个𝑃 × 𝑃单元格的最大值为1,因为概率不能超过1
-
我们操作的是16 × 16的注意力单元,因为它们已被证明包含最多的语义信息
- 这句话的意思应该是动了P为16的注意力图
Attend-and-excite
- 我们方法的核心是生成性语义护理(generative semantic nursing)的思想,即在每个时刻𝑡逐步将带噪声的潜在代码转移到更具语义忠实性的生成上
- 我们定义了一个损失目标,试图最大化每个主题标记的注意力值
- 然后,我们根据计算出的损失的梯度来更新时刻𝑡的带噪声的潜在代码
- 这鼓励下一个时刻的潜在代码在其表示中更好地融入所有主题标记。这种操作在推理过程中实时进行(即,不需要额外的训练)
- 这里的主题标记是所有文本标记嘛,算不算A,with这种单词?
- 应该不算

- 提取交叉注意力图。给定输入提示P,我们考虑P中存在的所有主题标记(例如名词)的集合S = {𝑠 1 , …,𝑠 𝑘 }。我们的目标是为每个标记𝑠 ∈ S提取一个空间注意力图,以指示𝑠对每个图像块的影响。
- 所以之前的问题,主题词是P里面所有的“名词”
- 给定当前时刻的带噪声潜在代码𝑧 𝑡,我们使用𝑧 𝑡和P对预训练的UNet网络执行前向传递(算法1中的步骤1), 然后,我们考虑在平均所有16 × 16注意力层和头之后获得的交叉注意力图。得到的聚合图𝐴 𝑡包含𝑁个空间注意力图,每个P中的标记一个,即𝐴_𝑡 ∈ R^16×16×𝑁。
- 这里的还是考虑N个文本词,也就是所有词
- 到目前为止还是代码中的第一行
- 预训练的CLIP文本编码器在P前添加一个特殊的标记⟨𝑠𝑜𝑡⟩,指示文本的开头。我们注意到,Stable Diffusion学习在𝐴 𝑡中定义的标记分布中始终给⟨𝑠𝑜𝑡⟩标记分配一个高注意力值。由于我们感兴趣的是增强实际的提示标记,我们通过忽略⟨𝑠𝑜𝑡⟩的注意力并对剩余标记执行Softmax操作来重新加权注意力值(算法1中的步骤2)
- Softmax操作后,结果矩阵𝐴 𝑡的(𝑖, 𝑗)-th项表示每个文本标记在相应图像块中存在的概率。然后,我们为每个主题标记𝑠提取16 × 16的归一化注意力图(步骤4)
- 这一步是从之前的每一个ij块中总结出一个主题标记s,p✖️p大小的归一化图
- 因为之前是p✖️p中的每一个点对应N个主题词,这里的操作应该是从p✖️p✖️N中总结出一个这个主题词s所对应的p✖️p大小的注意力图,这里还是不太理解,可能理解的是错的,这里真实是什么样的呢?
- 获取平滑的注意力图。
- 请注意,上面计算的注意力值𝐴 𝑠 𝑡可能无法完全反映结果图像中是否生成了某个对象。
- 具体来说,具有高注意力值的一个单独块可能仅源于从标记𝑠传递的部分信息。这可能发生在模型没有生成完整的主题,而是生成了与主题某些部分相似的块时
- 为了避免这样的对抗性解决方案,我们在算法1的步骤5中对𝐴 𝑠 𝑡应用高斯滤波器。这样做之后,最大激活块的注意力值将依赖于其相邻块,因为在此操作之后,每个块都是原始图中其相邻块的线性组合
- 对于集合𝑆中的每个主题标记,我们的优化鼓励至少存在一个具有高激活值的𝐴𝑡_s的补丁(patch),因此,我们定义了量化这种期望行为的损失函数如(2)所示

- 通过上图操作,首先利用1-max(At_s)找到这里面最大的那个对应与s主题的值,然后1-减去以后变成小的,再利用上图左边的那个公式找到Ls里最大的,也就是在At_s中被忽略最高的主题词
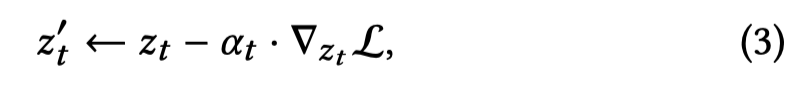
- 通过上图操作,首先利用1-max(At_s)找到这里面最大的那个对应与s主题的值,然后1-减去以后变成小的,再利用上图左边的那个公式找到Ls里最大的,也就是在At_s中被忽略最高的主题词
- 然后通过上面公式,用这个被忽略最高的L将Zt偏移,其中𝛼𝑡是一个标量,定义了梯度更新的步长
- 上面的更新过程只针对一时间步的子集进行,t=T,T-1,,,t_end,比如T为50,只在50-25之间执行上述过程,这是基于观察得出的结论,即在最后的时间步中,生成图像中对象的空间位置不会发生改变。
- 下图就过程说的就是这个事情,Tt是一个阈值

- 下图就过程说的就是这个事情,Tt是一个阈值
Results
- 评估设置。由于目前没有公开可用的数据集来分析基于文本的图像生成中的语义问题,我们构建了一个新的基准来评估所有方法
- 评估设置。由于目前没有公开可用的数据集来分析基于文本的图像生成中的语义问题,我们构建了一个新的基准来评估所有方法
- (i) “一个[动物A]和一个[动物B]”,(ii) “一个[动物]和一个[颜色][物体]”,以及(iii) “一个[颜色A][物体A]和一个[颜色B][物体B]”。
Limitations
- 虽然我们解决了两个核心语义问题,但实现语义准确生成的道路仍然漫长,还存在其他需要解决的挑战,如复杂的对象组合(例如,“骑在…上”,“在…前面”,“在…下面”)
Conclusions
- 一旦扩散过程走错方向,它能否被纠正?在这项工作中,我们引入了生成性语义护理(GSN)的概念,它指的是在预训练的文本到图像扩散模型的去噪过程中对潜在变量进行精细操作。然后,我们提出了Attend-and-Excite,这是GSN的一种特定形式,它鼓励文本中的所有主题标记都被某个图像块所关注。我们证明,通过应用这种直观的优化,我们能够即时缓解两个核心的语义问题,从而在生成器走错方向后对其进行纠正
Appendix
Ablation study
-
接下来,我们验证了在第25个去噪步骤(即所有去噪步骤的一半后)停止潜在修改的决定。这是基于观察得出的,即在早期的去噪步骤中,每个主体的空间位置就已经确定[Hertz et al. 2022; Voynov et al. 2022]。因此,在去噪过程的后期应用我们的潜在更新对最终图像的空间布局影响可能微乎其微。此外,我们发现,在25次迭代后应用潜在更新会导致最终图像中出现不希望的伪影。图12展示了这一点,我们比较了我们的Attend-and-Excite技术,其中我们要么在所有时间步上修改潜在(上),要么仅在前25个时间步上修改(下)。可以看出,早期停止修改会导致图像更加清晰,质量更高。
-
本方法是修改了原生成模型的注意力机制了吗?
- 应该是


















 116
116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









