







注意,本文章仅适用于远程连接服务器进行调试的情况
- 引入软链接
在服务器控制台,你的项目的上一级目录,输入如下命令:
ln -s /home/username/miniconda3/envs/virtualenv_name/lib/python3.6/site-packages/torch/distributed/ yourproject
之后,进入你项目的目录,输入ls,你将在项目文件夹下看见一个蓝色的distributed文件夹,说明软链接成功

通过PyCharm的deployment功能,将远程yourproject/distributed文件夹下载到本地
-
修改PyCharm设置
点击edit configurations -
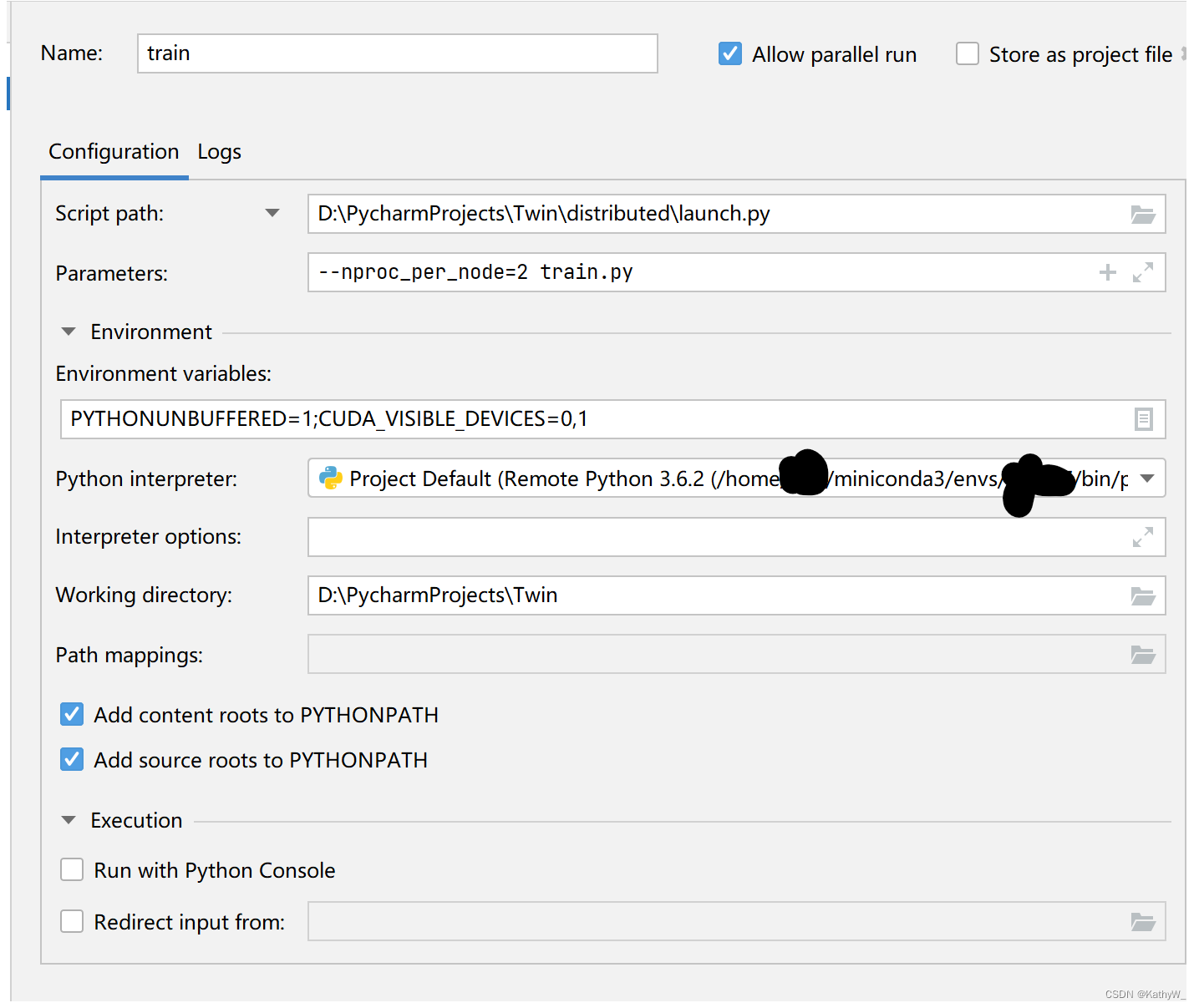
在script设置里面输入你本地项目文件夹的launch.py路径,
因为这里只能选择本地文件,所以我们之前把distributed文件夹下载到本地就起作用了,直接选择即可
因为软链接成功了,所以使用本地的launch相当于远程的launch -
修改parameters,只需要删除原来的运行脚本中的python -m torch.distributed.launch,其他不变
-
修改环境变量,加入CUDA_VISIBLE_DEVICES=0,1
-
其他不变,点击确定,点击run->debug train.py完成调试
界面如图所示















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











