







朴素贝叶斯
一、朴素贝叶斯理论
1. 简介
朴素贝叶斯算法是有监督的学习算法,解决的是分类问题,如客户是否流失、是否值得投资、信用等级评定等多分类问题。该算法的优点在于简单易懂、学习效率高、在某些领域的分类问题中能够与决策树、神经网络相媲美。但由于该算法以自变量之间的独立(条件特征独立)性和连续变量的正态性假设为前提,就会导致算法精度在某种程度上受影响。
2. 贝叶斯决策理论
朴素贝叶斯是贝叶斯决策理论的一部分,所以在讲述朴素贝叶斯之前有必要快速了解一下贝叶斯决策理论。
假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示:

我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
- 如果p1(x,y) > p2(x,y),那么类别为1
- 如果p1(x,y) < p2(x,y),那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。 接下来,就是学习如何计算p1和p2概率。
3. 条件概率
P(A|B)指在事件B发生的情况下,事件A发生的概率。

由文氏图可以看出,
P
(
A
∣
B
)
=
P
(
A
⋂
B
)
P
(
B
)
P(A|B)=\frac{P(A\bigcap B)}{P(B)}
P(A∣B)=P(B)P(A⋂B)所以,
P
(
A
⋂
B
)
=
P
(
A
∣
B
)
P
(
B
)
P(A\bigcap B)=P(A|B)P(B)
P(A⋂B)=P(A∣B)P(B)同理可得,
P
(
A
⋂
B
)
=
P
(
B
∣
A
)
P
(
A
)
P(A\bigcap B)=P(B|A)P(A)
P(A⋂B)=P(B∣A)P(A)所以,
P
(
A
∣
B
)
P
(
B
)
=
P
(
B
∣
A
)
P
(
A
)
P(A|B)P(B)=P(B|A)P(A)
P(A∣B)P(B)=P(B∣A)P(A)由此可得,
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
)
P(A|B)=\frac{P(B|A)P(A)}{P(B)}
P(A∣B)=P(B)P(B∣A)P(A)这就是条件概率的计算公式。
4. 全概率
其含义是如果A和A’构成样本空间的一个划分,那么事件B的概率,就等于A和A’的概率分别乘以B对这两个事件的条件概率之和,即
P
(
B
)
=
P
(
B
∣
A
)
P
(
A
)
+
P
(
B
∣
A
′
)
P
(
A
′
)
P(B)=P(B|A)P(A)+P(B|A')P(A')
P(B)=P(B∣A)P(A)+P(B∣A′)P(A′)
则条件概率公式也可以写成:
P
(
A
∣
B
)
=
P
(
B
∣
A
)
P
(
A
)
P
(
B
∣
A
)
P
(
A
)
+
P
(
B
∣
A
′
)
P
(
A
′
)
P(A|B)=\frac{P(B|A)P(A)}{P(B|A)P(A)+P(B|A')P(A')}
P(A∣B)=P(B∣A)P(A)+P(B∣A′)P(A′)P(B∣A)P(A)
5. 贝叶斯推断
对条件概率变形可得:
P
(
A
∣
B
)
=
P
(
A
)
P
(
B
∣
A
)
P
(
B
)
P(A|B)=P(A)\frac{P(B|A)}{P(B)}
P(A∣B)=P(A)P(B)P(B∣A)
我们把P(A)称为"先验概率",代表还没有训练模型之前,根据历史数据/经验估算A拥有的初始概率。它反映了A的概率分布,该分布独立于样本。
P(A|B)称为"后验概率",即给定数据样本B时A成立的概率,反映了在看到数据样本 B后A成立的置信度。
大部分机器学习模型尝试得到后验概率。
P(B|A)/P(B)称为"可能性函数",这是一个调整因子,使得预估概率更接近真实概率。
现在思考一个问题:我们只需要比较P(A1|B)和P(A2|B)的大小,分母相同,我们就只需要比较分子即可,所以为了减少计算量,全概率公式在实际编程中可以不使用。
6. 朴素贝叶斯分类器
- 朴素贝叶斯分类器采用了“属性条件独立性假设”,即每个属性独立地对分类结果发生影响。
- 为方便公式标记,不妨记P(C=c|X=x)为P(c|x),基于属性条件独立性假设,贝叶斯公式可重写为 P ( c ∣ x ) = P ( c ) P ( x ∣ c ) P ( x ) = P ( c ) P ( x ) ∏ i = 1 d P ( x i ∣ c ) P(c|x)=\frac{P(c)P(x|c)}{P(x)}=\frac{P(c)}{P(x)}\prod_{i=1}^{d}P(x_{i}|c) P(c∣x)=P(x)P(c)P(x∣c)=P(x)P(c)i=1∏dP(xi∣c)
其中d为属性数目,
x
i
x_{i}
xi为 x 在第i个属性上的取值。
对于所有类别来说P(x)都相同,所以只需要计算比较分子即可。
7. 拉普拉斯平滑
零概率问题: 在计算事件的概率时,如果某个事件在观察样本库(训练集)中没有出现过,会导致该事件的概率结果是0。这是不合理的,不能因为一个事件没有观察到,就被认为该事件一定不可能发生(即该事件的概率为0)。
拉普拉斯平滑是为了解决零概率的问题。
法国数学家拉普拉斯最早提出用加1的方法,估计没有出现过的现象的概率。拉普拉斯平滑,又叫加一平滑,它对分子划分的计数加1,分母加类别数。
理论假设:假定训练样本很大时,每个分量x的计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题
二、实战
1. 朴素贝叶斯之文档分类
背景:以在线社区留言为例。为了不影响社区的发展,我们要屏蔽侮辱性的言论,所以要构建一个快速过滤器,如果某条留言使用了负面或者侮辱性的语言,那么就将该留言标志为内容不当。过滤这类内容是一个很常见的需求。对此问题建立两个类型:侮辱类和非侮辱类,使用1和0分别表示。
1.1 准备数据:从文本中构建词向量
我们把文本看成单词向量或者词条向量,也就是说将句子转换为向量。考虑出现所有文档中的单词,再决定将哪些单词纳入词汇表或者说所要的词汇集合,然后必须要将每一篇文档转换为词汇表上的向量。简单起见,我们先假设已经将本文切分完毕,存放到列表中,并对词汇向量进行分类标注。编写代码如下:
首先是函数loadDataSet(),为的是创建实验样本。
"""
函数说明:创建实验样本
Parameters:
无
Returns:
postingList - 实验样本切分的词条
classVec - 类别标签向量
"""
def loadDataSet():
#切分词条,词条是字符的任意组合
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #类别标签向量,1代表侮辱性文字,0代表正常言论
return postingList,classVec
从运行结果可以看出,我们已经使postingList存放词条列表,classVec存放每个词条的所属类别,1代表侮辱类 ,0代表非侮辱类。

接着是函数createVocabList(),为的是创建一个包含在所有文档中出现的不重复词条的列表,也就是词汇表。
"""
函数说明:创建一个包含在所有文档中出现的不重复词条的列表,也就是词汇表
Parameters:
dataSet - 整理的样本数据集
Returns:
vocabSet - 返回不重复的词条列表,也就是词汇表
"""
def createVocabList(dataSet):
#创建一个空集
vocabSet = set([])
for document in dataSet:
#两个集合的并集,|用于求两个集合的并集,所以对象得都是集合,故用到set函数
vocabSet = vocabSet | set(document)
#set函数得到的是字典,需要返回不重复的词条列表
return list(vocabSet)
接着是函数setOfWords2Vec(),为的是根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0。
"""
函数说明:根据vocabList词汇表,将inputSet向量化,向量的每个元素为1或0
Parameters:
vocabList - createVocabList返回的词汇表
inputSet - 切分的词条列表
Returns:
returnVec - 文档向量,词集模型
"""
def setOfWords2Vec(vocabList,inputSet):
#创建一个和词汇表等长的向量,所含元素都为0
returnVec = [0]*len(vocabList)
for word in inputSet: #遍历每个词条
if word in vocabList: #如果存在于词汇表中,则置1
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec
测试运行这两个函数。
if __name__ == '__main__':
#测试loadDataSet()函数
postingList,classVec = loadDataSet()
print('postingList:\n',postingList)
#测试createVocabList()函数
myVocabList = createVocabList(postingList)
print('myVocabList:\n',myVocabList)
#测试setOfWords2Vec()函数
print('testResult:\n',setOfWords2Vec(myVocabList,postingList[0]))
从运行结果可以看出,postingList是原始的词条列表,myVocabList是词汇表。myVocabList是所有单词出现的集合,没有重复的元素。而词汇表的作用就是用来将词条向量化的,一个单词在词汇表中出现过一次,那么就在相应位置记作1,如果没有出现就在相应位置记作0。

1.2 训练算法:从词向量计算概率
朴素贝叶斯分类器训练函数
"""
函数说明:朴素贝叶斯分类器训练函数
Parameters:
trainMatrix - 训练文档矩阵,即setOfWords2Vec返回的returnVec构成的矩阵
trainCategory - 训练类别标签向量,即loadDataSet返回的classVec
Returns:
p0Vect - 非侮辱类的条件概率数组
p1Vect - 侮辱类的条件概率数组
pAbusive - 文档属于侮辱类的概率
"""
def trainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix) #计算训练的文档数目
numWords = len(trainMatrix[0]) #计算每篇文档的词条数
pAbusive = sum(trainCategory)/float(numTrainDocs) #文档属于侮辱类的概率
p0Num = zeros(numWords); p1Num = zeros(numWords) #创建numpy.zeros数组,词条出现数初始化为0
p0Denom = 0.0; p1Denom = 0.0 #分母初始化为0
for i in range(numTrainDocs):
if trainCategory[i] == 1: #统计属于侮辱类的条件概率所需的数据,即P(w0|1),P(w1|1),P(w2|1)···
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else: #统计属于非侮辱类的条件概率所需的数据,即P(w0|0),P(w1|0),P(w2|0)···
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = p1Num/p1Denom
p0Vect = p0Num/p0Denom
return p0Vect,p1Vect,pAbusive #返回属于非侮辱类的条件概率数组,属于侮辱类的条件概率数组,文档属于侮辱类的概率
if __name__ == '__main__':
# #测试loadDataSet()函数
# postingList,classVec = loadDataSet()
# print('postingList:\n',postingList)
# # 测试createVocabList()函数
# myVocabList = createVocabList(postingList)
# print('myVocabList:\n',myVocabList)
# # 测试setOfWords2Vec()函数
# print('testResult:\n',setOfWords2Vec(myVocabList,postingList[0]))
postingList, classVec = loadDataSet()
myVocabList = createVocabList(postingList)
print('myVocabList:\n', myVocabList)
trainMat = []
for postinDoc in postingList:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V, p1V, pAb = trainNB0(trainMat, classVec)
print('p0V:\n', p0V)
print('p1V:\n', p1V)
print('classVec:\n', classVec)
print('pAb:\n', pAb)
运行结果如下,p0V存放的是每个单词属于类别0,也就是非侮辱类词汇的概率。比如p0V的stupid这个单词属于非侮辱类的概率为0。同理,p1V的stupid这个单词属于侮辱类的概率为0.15789474,也就是约等于15.79%的概率。显而易见,这个单词属于侮辱类。pAb是所有侮辱类的样本占所有样本的概率,从classVec中可以看出,一用有3个侮辱类,3个非侮辱类。所以侮辱类的概率是0.5。因此p0V存放的就是P(I|非侮辱类) = 0.04166667、P(problems|非侮辱类) = 0.04166667,.一直到P(so|非侮辱类) = 0.04166667,即各个单词属于非侮辱类的条件概率。同理,p1V存放的就是各个单词属于侮辱类的条件概率。pAb就是先验概率。

1.3 测试算法:根据现实情况修改分类器
朴素贝叶斯分类函数
训练好分类器,我们可以开始使用分类器来进行分类。
"""
函数说明:朴素贝叶斯分类器分类函数
Parameters:
vec2Classify - 待分类的词条数组
p0Vec - 侮辱类的条件概率数组
p1Vec -非侮辱类的条件概率数组
pClass1 - 文档属于侮辱类的概率
Returns:
0 - 属于非侮辱类
1 - 属于侮辱类
"""
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = reduce(lambda x,y:x*y, vec2Classify * p1Vec) * pClass1 #对应元素相乘
p0 = reduce(lambda x,y:x*y, vec2Classify * p0Vec) * (1.0 - pClass1)
print('p0:',p0)
print('p1:',p1)
if p1 > p0:
return 1
else:
return 0
"""
函数说明:测试朴素贝叶斯分类器
Parameters:
无
Returns:
无
"""
def testingNB():
listOPosts,listClasses = loadDataSet() #创建实验样本
myVocabList = createVocabList(listOPosts) #创建词汇表
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) #将实验样本向量化
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses)) #训练朴素贝叶斯分类器
testEntry = ['love', 'my', 'dalmation'] #测试样本1
thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) #测试样本向量化
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'属于侮辱类') #执行分类并打印分类结果
else:
print(testEntry,'属于非侮辱类') #执行分类并打印分类结果
testEntry = ['stupid', 'garbage'] #测试样本2
thisDoc = array(setOfWords2Vec(myVocabList, testEntry)) #测试样本向量化
if classifyNB(thisDoc,p0V,p1V,pAb):
print(testEntry,'属于侮辱类') #执行分类并打印分类结果
else:
print(testEntry,'属于非侮辱类') #执行分类并打印分类结果
if __name__ == '__main__':
testingNB()
运行结果如下,p0,p1都为0,显然该算法无法进行比较。
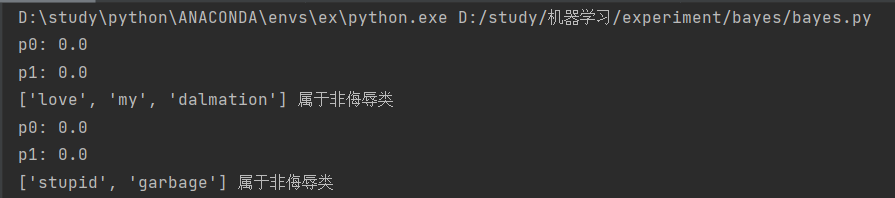
首先有两个问题
问题1 利用贝叶斯分类器对文档进行分类时,要计算多个概率的乘积以获得文档属于某个类别的概率,即计算p(w0|1)p(w1|1)p(w2|1)。如果其中有一个概率值为0,那么最后的成绩也为0。这就是零概率问题,不能因为样本没有,就认为不可能发生。 为了降低这种影响,可以将所有词的出现数初始化为1,并将分母初始化为2。这种做法就叫做拉普拉斯平滑,又被称为加1平滑,是比较常用的平滑方法,它就是为了解决0概率问题。(前面也有介绍,见目录一、7.)
问题2 下溢出,这是由于太多很小的数相乘造成的。学过数学的人都知道,两个小数相乘,越乘越小,这样就造成了下溢出。在程序中,在相应小数位置进行四舍五入,计算结果可能就变成0了。为了解决这个问题,对乘积结果取自然对数,在代数中有ln(a*b) = ln(a) + ln(b)。通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。下图给出函数f(x)和ln(f(x))的曲线。

发现它们在相同区域内同时增加或者减少,并且在相同点上取到极值。它们的取值虽然不同,但不影响最终结果。
因此针对这两个问题,我们可以对trainNB0(trainMatrix, trainCategory)函数进行更改,修改如下:
针对问题1
p0Num = np.ones(numWords); p1Num = np.ones(numWords) #创建numpy.ones数组,词条出现数初始化为1,拉普拉斯平滑
p0Denom = 2.0; p1Denom = 2.0 #分母初始化为2,拉普拉斯平滑
针对问题2
p1Vect = log(p1Num/p1Denom) #取对数,防止下溢出
p0Vect = log(p0Num/p0Denom)
从运行结果可以看出,已经不存在零概率问题。

测试函数的修改
p1 = sum(vec2Classify * p1Vec) + log(pClass1) # 对应元素相乘。logA * B = logA + logB,所以这里加上log(pClass1)
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
从运行结果可以看出,前面出现的问题已经解决。

2. 朴素贝叶斯之过滤垃圾邮件
首先我们来看一下分类步骤:
- 收集数据:提供文本文件。
- 准备数据:将文本文件解析成词条向量。
- 分析数据:检查词条确保解析的正确性。
- 训练算法:使用我们之前建立的trainNB0()函数。
- 测试算法:使用classifyNB(),并构建一个新的测试函数来计算文档集的错误率。
- 使用算法:构建一个完整的程序对一组文档进行分类,将错分的文档输出到屏幕上。
2.1. 收集数据
Github上下载:email数据集,其中ham为非垃圾邮件,spam为垃圾邮件。
2.2. 准备数据:切分文本
对于一个文本字符串,我们可以使用split函数以非字母、非数字作为符号进行切分。代码如下:
"""
函数说明:接收一个大字符串并将其解析为字符串列表
Parameters:
无
Returns:
无
"""
def textParse(bigString): #将字符串转换为字符列表
listOfTokens = re.split(r'[\W*]', bigString) #将特殊符号作为切分标志进行字符串切分,即非字母、非数字
return [tok.lower() for tok in listOfTokens if len(tok) > 2] #除了单个字母,例如大写的I,其它单词变成小写
if __name__ == '__main__':
docList = []; classList = []
for i in range(1, 26): #遍历25个txt文件
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) #读取每个垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
classList.append(1) #标记垃圾邮件,1表示垃圾文件
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read()) #读取每个非垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
classList.append(0) #标记非垃圾邮件,1表示垃圾文件
vocabList = createVocabList(docList) #创建词汇表,不重复
print(vocabList)
运行结束得到一个词汇表:

根据词汇表,我们就可以将每个文本向量化。我们将数据集分为训练集和测试集,使用留存交叉验证的方式测试朴素贝叶斯分类器的准确性。代码如下:
#文件解析及完整的垃圾邮件测试函数
"""
函数说明:接收一个大字符串并将其解析为字符串列表
Parameters:
无
Returns:
无
"""
def textParse(bigString): #将字符串转换为字符列表
listOfTokens = re.split(r'[\W*]', bigString) #将特殊符号作为切分标志进行字符串切分,即非字母、非数字
return [tok.lower() for tok in listOfTokens if len(tok) > 2] #除了单个字母,例如大写的I,其它单词变成小写
"""
函数说明:测试朴素贝叶斯分类器
Parameters:
无
Returns:
无
Author:
Jack Cui
Blog:
http://blog.csdn.net/c406495762
Modify:
2017-08-14
"""
def spamTest():
docList = []; classList = []; fullText = []
for i in range(1, 26): #遍历25个txt文件
wordList = textParse(open('email/spam/%d.txt' % i, 'r').read()) #读取每个垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(1) #标记垃圾邮件,1表示垃圾文件
wordList = textParse(open('email/ham/%d.txt' % i, 'r').read()) #读取每个非垃圾邮件,并字符串转换成字符串列表
docList.append(wordList)
fullText.append(wordList)
classList.append(0) #标记非垃圾邮件,1表示垃圾文件
vocabList = createVocabList(docList) #创建词汇表,不重复
trainingSet = list(range(50)); testSet = [] #创建存储训练集的索引值的列表和测试集的索引值的列表
for i in range(10): #从50个邮件中,随机挑选出40个作为训练集,10个做测试集
randIndex = int(random.uniform(0, len(trainingSet))) #随机选取索索引值
testSet.append(trainingSet[randIndex]) #添加测试集的索引值
del(trainingSet[randIndex]) #在训练集列表中删除添加到测试集的索引值
trainMat = []; trainClasses = [] #创建训练集矩阵和训练集类别标签系向量
for docIndex in trainingSet: #遍历训练集
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex])) #将生成的词集模型添加到训练矩阵中
trainClasses.append(classList[docIndex]) #将类别添加到训练集类别标签系向量中
p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) #训练朴素贝叶斯模型
errorCount = 0 #错误分类计数
for docIndex in testSet: #遍历测试集
wordVector = setOfWords2Vec(vocabList, docList[docIndex]) #测试集的词集模型
if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: #如果分类错误
errorCount += 1 #错误计数加1
print("分类错误的测试集:",docList[docIndex])
print('错误率:%.2f%%' % (float(errorCount) / len(testSet) * 100))
if __name__ == '__main__':
spamTest()
函数spamTest()会输出在10封随机选择的电子邮件上的分类错误概率。既然这些电子邮件是随机选择的,所以每次的输出结果可能有些差别。如果发现错误的话,函数会输出错误的文档的此表,这样就可以了解到底是哪篇文档发生了错误。如果想要更好地估计错误率,那么就应该将上述过程重复多次,比如说10次,然后求平均值。相比之下,将垃圾邮件误判为正常邮件要比将正常邮件归为垃圾邮件好。运行结果如下:




三、总结
1.朴素贝叶斯推断的优点:
- 生成式模型,通过计算概率来进行分类,可以用来处理多分类问题。
- 对小规模的数据表现很好,适合多分类任务,适合增量式训练,算法也比较简单。
- 对缺失数据不太敏感,算法也比较简单,常用于文本分类
朴素贝叶斯推断的缺点:
- 对输入数据的表达形式很敏感。
- 由于朴素贝叶斯的“朴素”特点,所以会带来一些准确率上的损失。朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。
- 需要计算先验概率,分类决策存在错误率。
- 需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
2.email中的txt文件编码形式得相同,否则无法解析,代码会无法运行。
3.课本中的代码:
listOfTokens = re.split(r'\W*', bigString)
该代码需要做修改否则输出为空集,把*改成+。
4.拉普拉斯平滑对于改善朴素贝叶斯的分类效果有很大的作用。















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









