






 本文介绍了如何使用TransUNet模型进行医学图像处理,包括数据集的2D切片预处理、代码实现以及训练和测试过程。作者提供了GitHub链接和示例代码,以帮助读者理解和实践。
本文介绍了如何使用TransUNet模型进行医学图像处理,包括数据集的2D切片预处理、代码实现以及训练和测试过程。作者提供了GitHub链接和示例代码,以帮助读者理解和实践。
TransUNet
论文链接:https://arxiv.org/abs/2102.04306
GitHub链接:https://github.com/Beckschen/TransUNet
本文完整代码:https://download.csdn.net/download/qq_45806961/89222079(其中少了2Ddata文件夹,就是预处理第一阶段,生成的二维图像保存位置,可以自行创建即可)
一、处理数据集
提前准备好数据集,如下图所示:
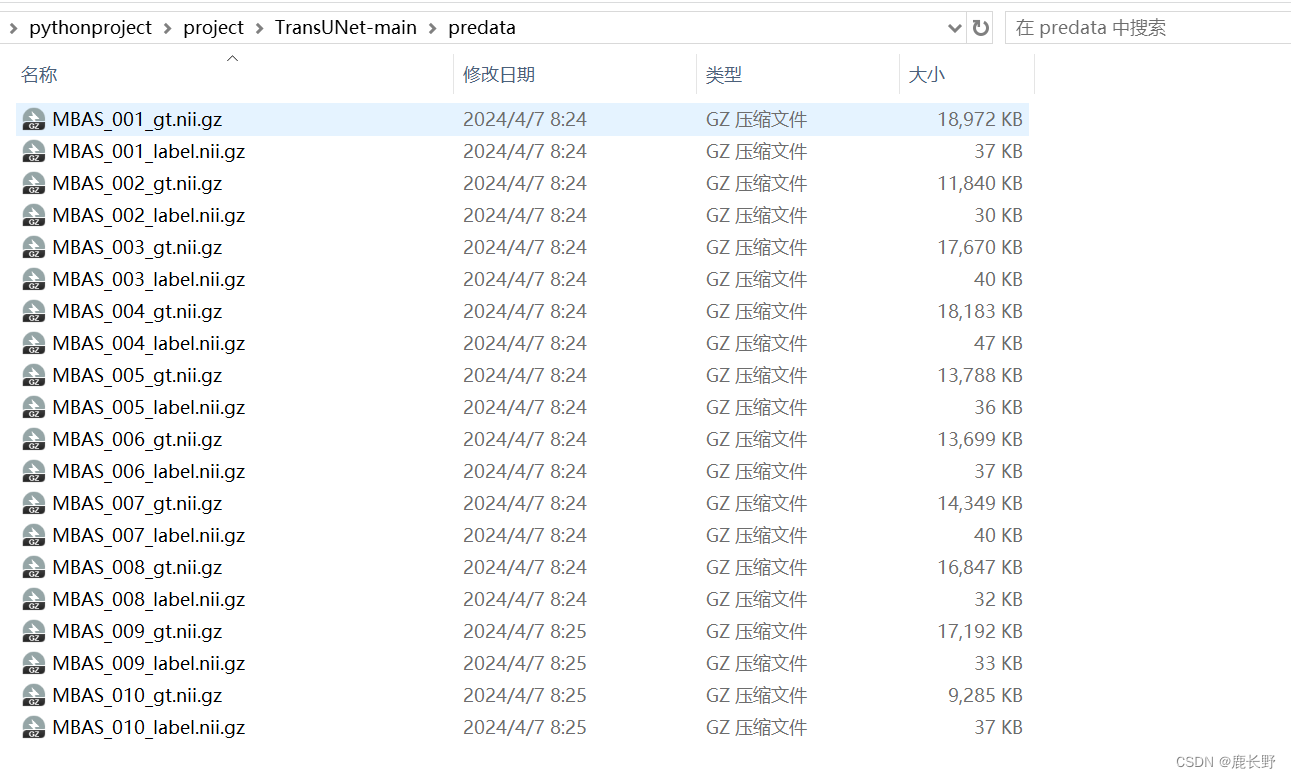
将数据转化为2D图像(根据自己的数据集进行更改下面的读取等操作,比较简单,并且添加了备注)
'''
coding:utf-8
@Software:PyCharm
@Time:2024/4/17 21:35
@Author:鹿长野
'''
# 如果更换数据集,就需要更改这里,根据数据集的相关名称进行更改
# 对nii格式的文件进行切片处理
import numpy as np
import nibabel as nib
import h5py
import os
from PIL import Image
data_path = "./predata"
def process_file(file_path):
# 获取图像和标签
img = nib.load(file_path) # ./predata/MBAS_001_gt.nii.gz ---> ./predata/MBAS_001_label.nii.gz
label_path = file_path.replace('_gt.nii.gz', '_label.nii.gz') # 找到标签的文件路径
# print(label_path)
label = nib.load(label_path)
# print(label)
img_data = img.get_fdata() # 获取像素数据
label_data = label.get_fdata()
# print(label_data)
img_clipped = np.clip(img_data, -125, 275)
img_normalised = (img_clipped-(-125))/(275-(-125)) # 图像做归一化,标签并没有
# img_clipped = img_data
# img_normalised = img_clipped
for i in range(img_clipped.shape[2]):
formatted_i ="{:04d}".format(i+1) # 将i+1四位数,不够的补零,我自己的理解,例如i是9,就是0010,所以加上1还是10,只是在前面补了两个零
img_slice = img_normalised[:,:,i]
label_slice = label_data[:,:,i]
image = Image.fromarray(img_slice.astype(np.uint8)) # 将图像转化为PIL图像对象
image = image.convert('L') # 转化为灰度图像
label = Image.fromarray(label_slice.astype(np.uint8))
label = label.convert('L')
case_name = os.path.splitext(os.path.split(file_path)[1])[0] # (从file_path开始入手)获取路径中的文件名,不包含扩展名 ----> MBAS_001_gt
# print(case_name) # 打印 MBAS_001_gt.nii
case_name = case_name.replace("_gt.nii","")
# print(case_name) # 打印 MBAS_001
case_number = "{:03d}".format(int(formatted_i))
image.save(f"./2Ddata/{case_name}_{case_number}.png")
label.save(f"./2Ddata/{case_name}_{case_number}_label.png")
for root,dirs,files in os.walk(data_path):
for file in files:
if file.endswith("gt.nii.gz"): # 只读取图像,不读取标签文件
file_path = os.path.join(root,file)
process_file(file_path)
处理后的数据如下所示:(image+label放在了一起)
 然后将image+label对应的两张图像叠加在一起,为了贴合作者的数据集而做的处理,代码如下:
然后将image+label对应的两张图像叠加在一起,为了贴合作者的数据集而做的处理,代码如下:
'''
coding:utf-8
@Software:PyCharm
@Time:2024/4/18 10:12
@Author:鹿长野
'''
# 把img图像和对应的mask图像合并为一个npz文件
# 如果更换数据集,就需要更改这里,根据数据集的相关名称进行更改
import glob
import cv2
import numpy as np
from tqdm import tqdm
def npz():
path = './2Ddata/*.png' # 图像路径
path2 = './data/train_npz/' # 项目中存放训练所用的npz文件路径
for i,img_path in tqdm(enumerate(glob.glob(path))):
# print("i:",i)
# print("img_path:",img_path) # 打印 ./2Ddata/MBAS_001_001.png
if img_path.endswith('_label.png'): # 没有读取标签图片,提前给跳过
continue
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
label_path = img_path.replace('.png', '_label.png') # 读取标签图片
# print(label_path)
label = cv2.imread(label_path,flags=0) # flags 默认读取灰度图像
filename = img_path.split('/')[-1].split('.')[0] # img_path = ./2Ddata\MBAS_001_001.png,所以需要再次处理
# print(filename) # 2Ddata\MBAS_001_001,所以不得不根据实际问题进行结合
filename = filename.replace('2Ddata\\', '') # 两个\\才代表一个\
# print(filename)
np.savez(path2+filename+'.npz',image=image,label=label)
npz()
处理后的数据如下图所示:
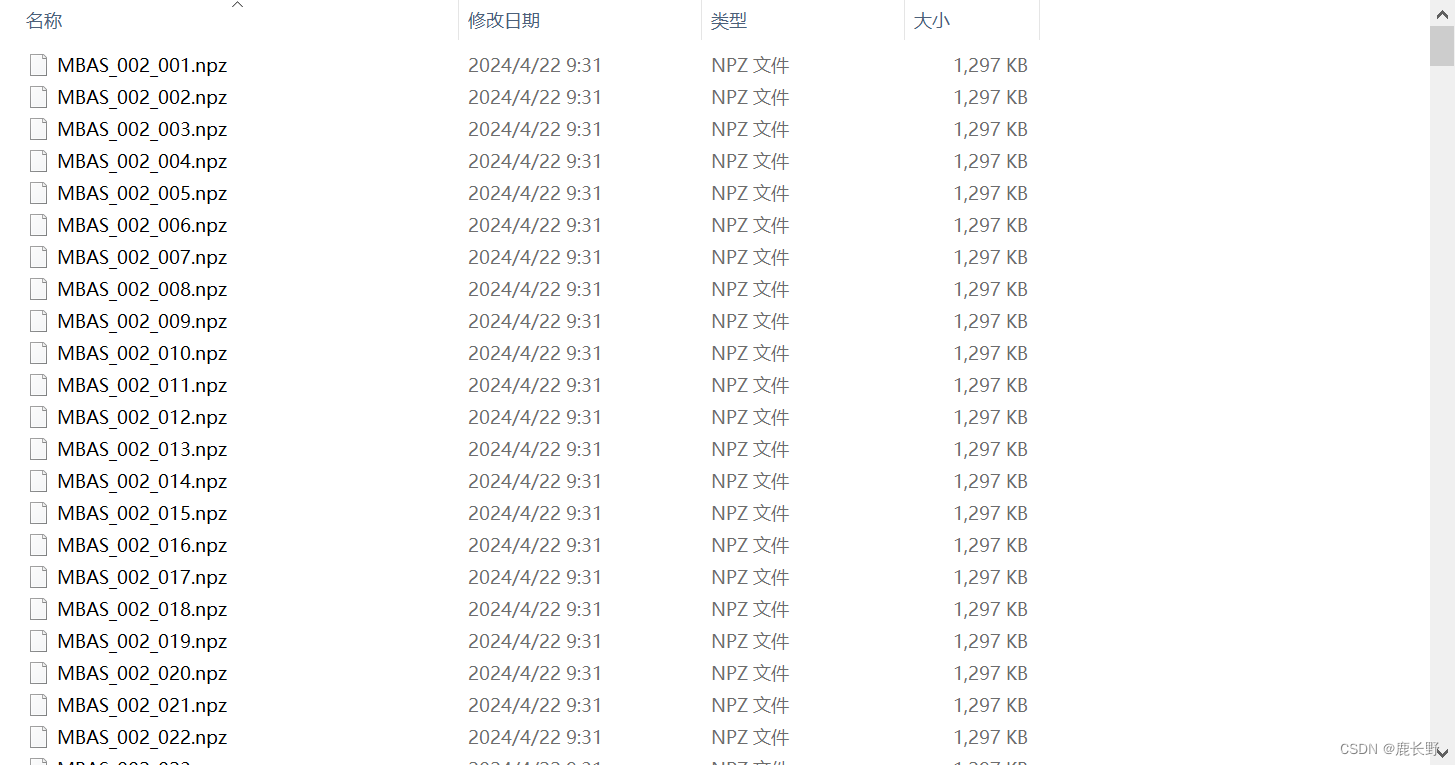
上述代码将数据分成了训练集和测试集,如下图,根据地址自行更改:
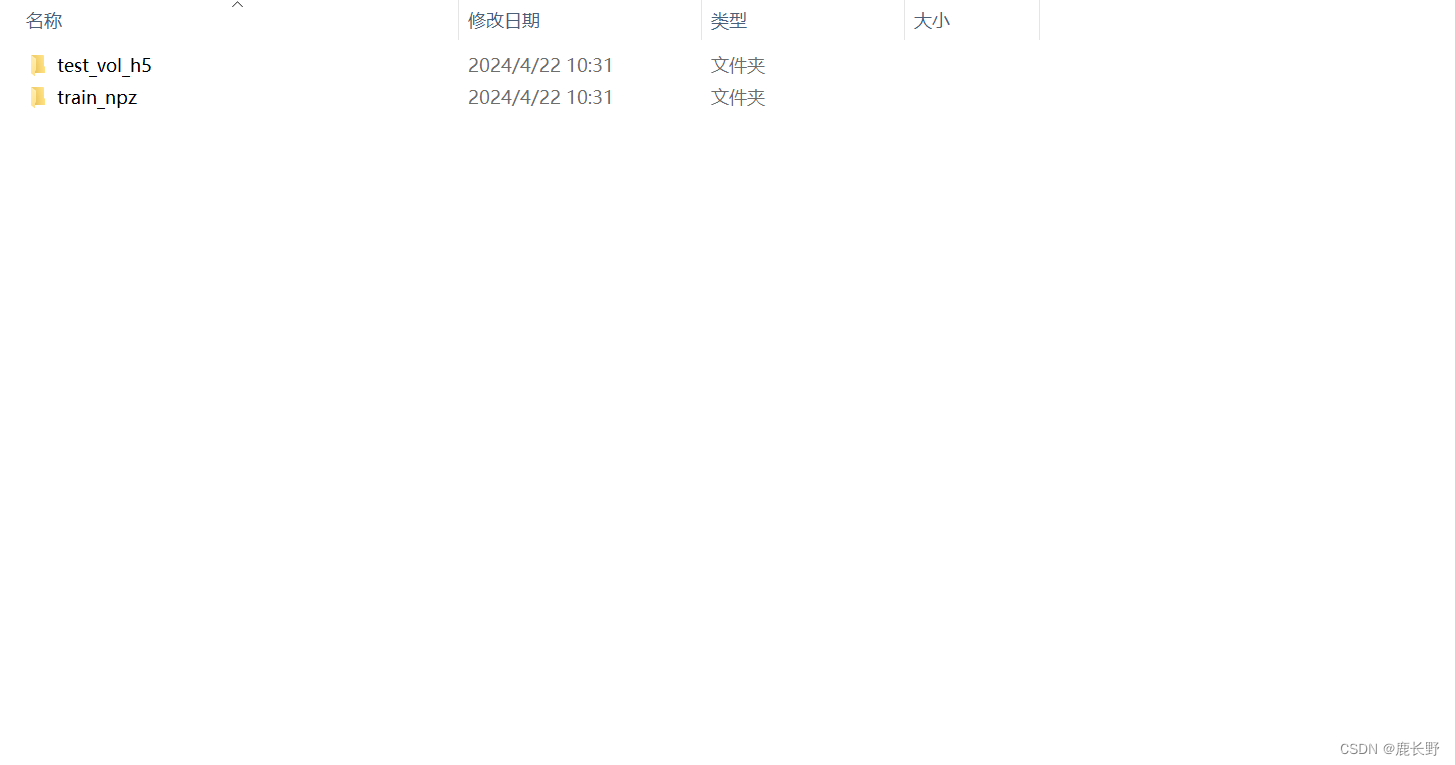
同时也会生成TXT文件,代码中注明了文件保存位置,自行修改即可,
自此,数据集处理好啦
二、开始训练


下载预训练模型,存放地址如下,可以自行去网站下载
运行train.py
三、开始测试

需要修改的部分和训练过程中一样,训练后的结果会保存在test_save_dir中
测试结果

如有任何问题留言!

















 4330
4330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









