







引言
本论文来自leveldb源码中bloom.cc下布隆过滤器实现的代码注释中推荐的论文。论证了一种布隆过滤器的优化方式,带有详细的证明。是不可多得的好文章。其中的许多公式会对布隆过滤器相关的文章有所帮助。所以博主将原文和其中的海量公式转化为了可编辑的markdown和Latex,方便大家引用。如有转载,望注明论文出处和本文出处,谢谢!
论文原文出处:论文原文
本文作者:csdn账号,个人空间 - AcWing
受平台字数限制,只好将论文分成多段,望理解
上接 布隆过滤器优化算法double—hashing论文原文(二)
7. Multiple Queries
In the previous sections, we analyzed the behavior of P r ( F ( z ) ) \mathbf{Pr}(\mathcal{F}(z)) Pr(F(z)) for some fixed Z and moderately sized TI .Unfortunately, this quantity is not directly of interest in most applications. Instead, one is usually concerned with certain characteristics of the distribution of the number of, say, z 1 , … , z ℓ ∈ U − S z_{1},\ldots,z_{\ell}\in U-S z1,…,zℓ∈U−S for which F ( z ) \mathcal{F}(z) F(z) occurs. In other words, rather than being interested in the probability that a particular false positive occurs, we are concerned with, for example, the fraction of distinct queries on elements of U − S U-S U−S posed to the filter for which it returns false positives. Since { F ( z ) : z ∈ U − S } \{\mathcal{F}(z):z\in U-S\} {F(z):z∈U−S} are not independent, the behavior of P r ( F ) \mathbf{Pr}(\mathcal{F}) Pr(F) alone does not directly imply results of this form. This section is devoted to overcoming this difficulty Now, it is easy to see that in the schemes that we analyze here, once the hash locations for every
x ∈ S x\in S x∈S have been determined,the events { F ( z ) : z ∈ U − S } \{\mathcal{F}(z):z\in U-S\} {F(z):z∈U−S} are independent and occur with equal probability. More formally, letting 1 ( ⋅ ) 1(\cdot) 1(⋅) denote the indicator function, { 1 ( F ( z ) ) : z ∈ U − S } \{\mathbf{1}(\mathcal{F}(z)):z\in U-S\} {1(F(z)):z∈U−S} are conditionally independent and identically distributed given { H ( x ) : x ∈ S } \{H(x):x\in S\} {H(x):x∈S} . Thus, conditioned on { H ( x ) : x ∈ S } \{H(x):x\in S\} {H(x):x∈S} , an enormous number of classical convergence results (e.g. the law of large numbers and the central limit theorem) can be applied to { 1 ( F ( z ) ) : z ∈ U − S } \{1(\mathcal{F}(z)):z\in U-S\} {1(F(z)):z∈U−S} These observations motivate a general technique for deriving the sort of convergence results
for { 1 ( F ( z ) ) : z ∈ U − S } \{\mathbf{1}(\mathcal{F}(z)):z\in U-S\} {1(F(z)):z∈U−S} that one might desire in practice. First, we show that with high probability over the set of hash locations used by elements of S (that is, { H ( x ) : x ∈ S } \{H(x):\:x\in S\} {H(x):x∈S} ),the random variables { 1 ( F ( z ) ) : z ∈ U − S } \{\mathbf{1}(\mathcal{F}(z)):z\in U-S\} {1(F(z)):z∈U−S} are essentially independent Bernoulli trials with success probability lim n → ∞ \operatorname*{lim}_{n\to\infty} limn→∞Pr ( F ) (\mathcal{F}) (F) . From a technical standpoint, this result is the most important in this section. Next,we show how to use that result to prove counterparts to the classical convergence theorems mentioned above that hold in our setting Proceeding formally, we begin with a critical definition.
Definition 7.1. Consider any scheme where
{
H
(
u
)
:
u
∈
U
}
\{H(u):u\in U\}
{H(u):u∈U} are independent and identically distributed. Write
S
=
{
x
1
,
…
,
x
n
}
S=\{x_{1},\ldots,x_{n}\}
S={x1,…,xn} .The false positive rate is defined to be the random variable
R
=
P
r
(
F
∣
H
(
x
1
)
,
…
,
H
(
x
n
)
)
.
R=\mathbf{Pr}(\mathcal{F}\mid H(x_1),\ldots,H(x_n)).
R=Pr(F∣H(x1),…,H(xn)).
The false positive rate gets its name from the fact that, conditioned on R R R , the random variables { 1 ( F ( z ) ) : z ∈ U − S } \{\mathbf{1}(\mathcal{F}(z)):z\in U-S\} {1(F(z)):z∈U−S} are independent Bernoulli trials with common success probability. R R R .Thus, the fraction of a large number of queries on elements of U − S U-S U−S posed to the filter for which it returns false positives is very likely to be close to R R R .In this sense, R R R ,while a random variable, acts like a rate for { 1 ( F ( z ) ) \{ \mathbf{1} ( \mathcal{F} ( z) ) {1(F(z)) : z ∈ U − S } z\in U- S\} z∈U−S} It is important to note that in much of literature concerning standard Bloom filters,the false
positive rate is not defined as above.Instead the term is often used as a synonym for the false positive probability.Indeed, for a standard Bloom filter, the distinction between the two concepts as we have defined them is unimportant in practice, since, as mentioned in Section 2, one can easily show that R . R. R. is very close to Pr ( F ) \Pr(\mathcal{F}) Pr(F) with extremely high probability (see, for example, [11]). It turns out that this result generalizes very naturally to the framework presented in this paper, and so the practical difference between the two concepts is largely unimportant even in our very general setting.However,the proof is more complicated than in the case of a standard Bloom filter, and so we will be very careful to use the terms as we have defined them.
Theorem 7.1.Consider a scheme where the conditions of Lemma 4.1 hold.Furthermore,assume that there is some function y y y and independent identically distributed random variables. { V u : u ∈ U } \{V_{u}:u\in U\} {Vu:u∈U} ,such that V u V_{u} Vu is uniform over Supp ( V u ) \operatorname{Supp}(V_{u}) Supp(Vu) ,,and for u ∈ U u\in U u∈U ,we have H ( u ) = g ( V u ) H(u)=g(V_{u}) H(u)=g(Vu) Define
p = d e f ( 1 − e − λ / k ) k Δ = d e f max i ∈ H P r ( i ∈ H ( u ) ) − λ n k ( = o ( 1 / n ) ) ξ = d e f n k Δ ( 2 λ + k Δ ) ( = o ( 1 ) ) \begin{aligned}&p\stackrel{def}{=}\left(1-\mathrm{e}^{-\lambda/k}\right)^{k}\\&\Delta\stackrel{def}{=}\max_{i\in H}\mathbf{Pr}(i\in H(u))-\frac{\lambda}{nk}\quad(=o(1/n))\\&\xi\stackrel{def}{=}nk\Delta(2\lambda+k\Delta)\quad(=o(1))\end{aligned} p=def(1−e−λ/k)kΔ=defi∈HmaxPr(i∈H(u))−nkλ(=o(1/n))ξ=defnkΔ(2λ+kΔ)(=o(1))
Then for any ϵ = ϵ ( n ) > 0 \epsilon=\epsilon(n)>0 ϵ=ϵ(n)>0 with ϵ = ω ( ∣ P r ( F ) − p ∣ ) \epsilon=\omega(|\mathbf{Pr}(\mathcal{F})-p|) ϵ=ω(∣Pr(F)−p∣) ,for n sufficiently large so that ϵ > ∣ Pr ( F ) − p ∣ \epsilon>|\Pr(\mathcal{F})-p| ϵ>∣Pr(F)−p∣
P r ( ∣ R − p ∣ > ϵ ) ≤ 2 exp [ − 2 n ( ϵ − ∣ P r ( F ) − p ∣ ) 2 λ 2 + ξ ] . \mathbf{Pr}(|R-p|>\epsilon)\leq2\exp\left[\frac{-2n(\epsilon-|\mathbf{Pr}(\mathcal{F})-p|)^{2}}{\lambda^{2}+\xi}\right]. Pr(∣R−p∣>ϵ)≤2exp[λ2+ξ−2n(ϵ−∣Pr(F)−p∣)2].
Furthermore, for any function. h ( n ) h( n) h(n) = o ( min ( 1 / ∣ P r ( F ) o( \operatorname* { min} ( 1/ | \mathbf{Pr}( \mathcal{F} ) o(min(1/∣Pr(F) − p ∣ , n ) ) - p| , \sqrt {n}) ) −p∣,n)) ,we have that ( R − p ) h ( n ) (R-p)h(n) (R−p)h(n) converges to 0 in probability as T l → x Tl\rightarrow\mathbf{x} Tl→x
Remark. Since ∣ P r ( F ) − p ∣ = o ( 1 ) \left|\mathbf{Pr}(\mathcal{F})-p\right|=o(1) ∣Pr(F)−p∣=o(1) by Lemma 4.1, we may take h ( n ) = 1 h(n)=1 h(n)=1 in Theorem 7.1 to conclude that R R R converges to P P P in probability as T l → ∞ Tl\to\infty Tl→∞
Remark.From the proofs of Theorems 5.1 and 5.2,it is easy to see that for both the partition and (extended) double hashing schemes, Δ = 0 \Delta=0 Δ=0 SO ξ = 0 \xi=0 ξ=0 forboth schemes as well
Remark. We have added a new condition on the distribution of H ( u ) H(u) H(u) , but it trivially holds in all of the schemes that we discuss in this paper (since, for independent fully random hash func tions h 1 h_{1} h1 and h 2 h_{2} h2 , the random variables { ( h 1 ( u ) , h 2 ( u ) ) : \{ ( h_{1}( u) , h_{2}( u) ) : {(h1(u),h2(u)): u ∈ U } u\in U\} u∈U} are independent and identically distributed, and ( h 1 ( u ) , h 2 ( u ) ) (h_{1}(u),h_{2}(u)) (h1(u),h2(u)) is uniformly distributed over its support).
Proof. The proof is essentially a standard application of Azuma’s inequality to an appropriately defined Doob martingale. Specifically, we employ the technique discussed in [12, Section 12.5] For convenience, write S = { x 1 , … , x n } S=\{x_{1},\ldots,x_{n}\} S={x1,…,xn} .For h 1 , … , h n ∈ h_{1},\ldots,h_{n}\in h1,…,hn∈Supp ( H ( u ) ) (H(u)) (H(u)) ,define
f ( h 1 , … , h n ) = d e f P r ( F ∣ H ( x 1 ) = h 1 , … , H ( x n ) = h n ) , f(h_1,\ldots,h_n)\stackrel{\mathrm{def}}{=}\mathbf{Pr}(\mathcal{F}\mid H(x_1)=h_1,\ldots,H(x_n)=h_n), f(h1,…,hn)=defPr(F∣H(x1)=h1,…,H(xn)=hn),
and note that R = f ( H ( x 1 ) , … , H ( x n ) ) R=f(H(x_{1}),\ldots,H(x_{n})) R=f(H(x1),…,H(xn)) .Now consider some C C C such that for any h 1 , … , h j h_{1},\ldots,h_{j} h1,…,hj , h j ′ h_{j}^{\prime} hj′ h j + 1 , … , h n ∈ h_{j+1},\ldots,h_{n}\in hj+1,…,hn∈Supp ( H ( u ) ) (H(u)) (H(u))
∣ f ( h 1 , … , h n ) − f ( h 1 , … , h j − 1 , h j ′ , h j + 1 , … , h n ) ∣ ≤ c . |f(h_1,\dots,h_n)-f(h_1,\dots,h_{j-1},h_j',h_{j+1},\dots,h_n)|\leq c. ∣f(h1,…,hn)−f(h1,…,hj−1,hj′,hj+1,…,hn)∣≤c.
Since the H ( x i ) H(x_{i}) H(xi) 's are independent, we may apply the result of [12, Section 12.5] to obtain
P r ( ∣ R − E [ R ] ∣ ≥ δ ) ≤ 2 e − 2 δ 2 / n c 2 , \mathbf{Pr}(|R-\mathbf{E}[R]|\geq\delta)\leq2\mathrm{e}^{-2\delta^{2}/nc^{2}}, Pr(∣R−E[R]∣≥δ)≤2e−2δ2/nc2,
for any δ > 0 \delta>0 δ>0
To find a small choice for t t t wewrite
∣ f ( h 1 , … , h n ) − f ( h 1 , … , h j − 1 , h j ′ , h j + 1 , … , h n ) ∣ = ∣ Pr ( F ∣ H ( x 1 ) = h 1 , … , H ( x n ) = h n ) − Pr ( F ∣ H ( x 1 ) = h 1 , … , H ( x j − 1 ) = h j − 1 , H ( x j ) = h j ′ , H ( x j + 1 ) = h j + 1 , … H ( x n ) = ∣ ∣ { v ∈ S u p p ( V u ) : g ( v ) ⊆ ⋃ i = 1 n h i } ∣ − ∣ { v ∈ S u p p ( V u ) : g ( v ) ⊆ ⋃ i = 1 n { h j ′ i = j h i i ≠ j } ∣ ∣ S u p p ( V u ) ∣ ≤ max v ′ ∈ S u p p ( V u ) ∣ { v ∈ S u p p ( V u ) : ∣ g ( v ) ∩ g ( v ′ ) ∣ ≥ 1 } ∣ ∣ S u p p ( V u ) ∣ = max M ′ ∈ S u p p ( H ( u ) ) P r ( ∣ H ( u ) ∩ M ′ ∣ ≥ 1 ) , \left.\begin{aligned}&\left|f(h_{1},\ldots,h_{n})-f(h_{1},\ldots,h_{j-1},h_{j}^{\prime},h_{j+1},\ldots,h_{n})\right|\\&=\left|\Pr(\mathcal{F}\mid H(x_{1})=h_{1},\ldots,H(x_{n})=h_{n})\right.\\&-\Pr(\mathcal{F}\mid H(x_{1})=h_{1},\ldots,H(x_{j-1})=h_{j-1},H(x_{j})=h_{j}^{\prime},H(x_{j+1})=h_{j+1},\ldots H(x_{n})\\&=\frac{\left|\left|\{v\in\mathrm{Supp}(V_u):g(v)\subseteq\bigcup_{i=1}^nh_i\}\right|-\left|\left\{v\in\mathrm{Supp}(V_u):g(v)\subseteq\bigcup_{i=1}^n\left\{\begin{array}{c}h_j^{\prime}&i=j\\h_i&i\neq j\end{array}\right.\right.\right\}\right|}{\left|\mathrm{Supp}(V_u)\right|}\\&\leq\frac{\max_{v^{\prime}\in\mathrm{Supp}(V_u)}\mid\{v\in\mathrm{Supp}(V_u):|g(v)\cap g(v^{\prime})|\geq1\}\mid}{\left|\mathrm{Supp}(V_u)\right|}\\&=\max_{M^{\prime}\in\mathrm{Supp}(H(u))}\mathbf{Pr}(|H(u)\cap M^{\prime}|\geq1),\end{aligned}\right. f(h1,…,hn)−f(h1,…,hj−1,hj′,hj+1,…,hn) =∣Pr(F∣H(x1)=h1,…,H(xn)=hn)−Pr(F∣H(x1)=h1,…,H(xj−1)=hj−1,H(xj)=hj′,H(xj+1)=hj+1,…H(xn)=∣Supp(Vu)∣ ∣{v∈Supp(Vu):g(v)⊆⋃i=1nhi}∣− {v∈Supp(Vu):g(v)⊆⋃i=1n{hj′hii=ji=j} ≤∣Supp(Vu)∣maxv′∈Supp(Vu)∣{v∈Supp(Vu):∣g(v)∩g(v′)∣≥1}∣=M′∈Supp(H(u))maxPr(∣H(u)∩M′∣≥1),
where the first step is just the definition of f f f ,the second step follows from the definitions of V u V_{u} Vu and y y y ,the third step holds since changing one of the h i h_{i} hi 's to some M ′ ∈ Supp ( H ( u ) ) M^{\prime}\in\operatorname{Supp}(H(u)) M′∈Supp(H(u)) cannot change
∣ { v ∈ Supp ( V u ) : g ( v ) ⊆ ⋃ i = 1 n h i } ∣ \left|\left\{v\in\operatorname{Supp}(V_u)\::\:g(v)\subseteq\bigcup\limits_{i=1}^nh_i\right\}\right| {v∈Supp(Vu):g(v)⊆i=1⋃nhi}
bv more than
∣ { v ∈ S u p p ( V u ) : ∣ g ( v ) ∩ M ′ ∣ ≥ 1 } ∣ , \left|\left\{v\in\mathrm{Supp}(V_u)\::\:|g(v)\cap M'|\geq1\right\}\right|, ∣{v∈Supp(Vu):∣g(v)∩M′∣≥1}∣,
and the fourth step follows from the definitions of V u V_{u} Vu and y y y
Now consider any fixed M ′ ∈ Supp ( H ( u ) ) M^{\prime}\in\operatorname{Supp}(H(u)) M′∈Supp(H(u)) , and let y 1 , … , y ∣ M ′ ∣ y_{1},\ldots,y_{|M^{\prime}|} y1,…,y∣M′∣ be the distinct elements of M ′ M^{\prime} M′ .Recall that ∥ M ′ ∥ = k \|M^{\prime}\|=k ∥M′∥=k ,SO ∣ M ′ ∣ ≤ k |M^{\prime}|\leq k ∣M′∣≤k .Applying a union bound,we have that
P r ( ∣ H ( u ) ∩ M ′ ∣ ≥ 1 ) = P r ( ⋃ i = 1 ∣ M ′ ∣ y i ∈ H ( u ) ) ≤ ∑ i = 1 ∣ M ′ ∣ P r ( y i ∈ H ( u ) ) ≤ ∑ i = 1 ∣ M ′ ∣ λ k n + Δ ≤ λ n + k Δ . \begin{aligned}\mathbf{Pr}(|H(u)\cap M'|\geq1)&=\mathbf{Pr}\left(\bigcup_{i=1}^{|M^{\prime}|}y_{i}\in H(u)\right)\\&\leq\sum_{i=1}^{|M^{\prime}|}\mathbf{Pr}(y_{i}\in H(u))\\&\leq\sum_{i=1}^{|M^{\prime}|}\frac{\lambda}{kn}+\Delta\\&\leq\frac{\lambda}{n}+k\Delta.\end{aligned} Pr(∣H(u)∩M′∣≥1)=Pr i=1⋃∣M′∣yi∈H(u) ≤i=1∑∣M′∣Pr(yi∈H(u))≤i=1∑∣M′∣knλ+Δ≤nλ+kΔ.
Therefore, we may set c = λ n + k Δ c=\frac{\lambda}{n}+k\Delta c=nλ+kΔ to obtain
P r ( ∣ R − E [ R ] ∣ > δ ) ≤ 2 exp [ − 2 n δ 2 λ 2 + ξ ] , \mathbf{Pr}(|R-\mathbf{E}[R]|>\delta)\leq2\exp\left[\frac{-2n\delta^2}{\lambda^2+\xi}\right], Pr(∣R−E[R]∣>δ)≤2exp[λ2+ξ−2nδ2],
for any δ > 0 \delta>0 δ>0 .Since E [ R ] = \mathbf{E}[R]= E[R]=Pr ( F ) (\mathcal{F}) (F) , we write (for sufficiently large T l . Tl. Tl. so that ϵ > ∣ P r ( F ) − p ∣ ) \epsilon>|\mathbf{Pr}(\mathcal{F})-p|) ϵ>∣Pr(F)−p∣)
P r ( ∣ R − p ∣ > ϵ ) ≤ P r ( ∣ R − P r ( F ) ∣ > ϵ − ∣ P r ( F ) − p ∣ ) ≤ 2 exp [ − 2 n ( ϵ − ∣ P r ( F ) − p ∣ ) 2 λ 2 + ξ ] . \begin{aligned}\mathbf{Pr}(|R-p|>\epsilon)&\leq\mathbf{Pr}(|R-\mathbf{Pr}(\mathcal{F})|>\epsilon-|\mathbf{Pr}(\mathcal{F})-p|)\\&\leq2\exp\left[\frac{-2n(\epsilon-|\mathbf{Pr}(\mathcal{F})-p|)^2}{\lambda^2+\xi}\right].\end{aligned} Pr(∣R−p∣>ϵ)≤Pr(∣R−Pr(F)∣>ϵ−∣Pr(F)−p∣)≤2exp[λ2+ξ−2n(ϵ−∣Pr(F)−p∣)2].
To complete the proof, we see that for any constant δ > 0 \delta>0 δ>0
P r ( ∣ R − p ∣ h ( n ) > δ ) = P r ( ∣ R − p ∣ > δ / h ( n ) ) → 0 a s n → ∞ , \mathbf{Pr}(|R-p|h(n)>\delta)=\mathbf{Pr}(|R-p|>\delta/h(n))\to0\quad\mathrm{as}\:n\to\infty, Pr(∣R−p∣h(n)>δ)=Pr(∣R−p∣>δ/h(n))→0asn→∞,
where the second step follows from the fact that ∣ P r ( F ) − p ∣ = o ( 1 / h ( n ) ) |\mathbf{Pr}(\mathcal{F})-p|=o(1/h(n)) ∣Pr(F)−p∣=o(1/h(n)) so for sufficiently large 77. ,
P r ( ∣ R − p ∣ > δ / h ( n ) ) ≤ 2 exp [ − 2 n ( δ / h ( n ) − ∣ P r ( F ) − p ∣ ) 2 λ 2 + ξ ] ≤ 2 exp [ − δ 2 λ 2 + ξ ⋅ n h ( n ) 2 ] → 0 a s n → ∞ , \begin{aligned}\mathbf{Pr}(|R-p|>\delta/h(n))&\leq2\exp\left[\frac{-2n(\delta/h(n)-|\mathbf{Pr}(\mathcal{F})-p|)^{2}}{\lambda^{2}+\xi}\right]\\&\leq2\exp\left[-\frac{\delta^{2}}{\lambda^{2}+\xi}\cdot\frac{n}{h(n)^{2}}\right]\\&\to0\quad\mathrm{as}\:n\to\infty,\end{aligned} Pr(∣R−p∣>δ/h(n))≤2exp[λ2+ξ−2n(δ/h(n)−∣Pr(F)−p∣)2]≤2exp[−λ2+ξδ2⋅h(n)2n]→0asn→∞,
and the last step follows from the fact that h ( n ) = o ( n ) h(n)=o({\sqrt{n}}) h(n)=o(n)
Since, conditioned on R . R. R. ,the events { F ( z ) : z ∈ U − S } \{{\mathcal{F}}(z):z\in U-S\} {F(z):z∈U−S} are independent and each occur witl probability R . R. R. ,Theorem 7.1 suggests that { 1 ( F ( z ) ) : z ∈ U − S } \{\mathbf{1}(\mathcal{F}(z)):z\in U-S\} {1(F(z)):z∈U−S} are essentially independent Bernoulli trials with success probability μ̸ \not{\mu} μ .The next result is a formalization of this idea.
Lemma 7.1.Consider a scheme where the conditions of Theorem 7.1 hold.Let F n 0 ( z ) \mathcal{F}_{n_0}(z) Fn0(z) denote F ( z ) \mathcal{F}(z) F(z) in the case when the schemeis used with η l = η 0 \eta_{l}=\eta_{0} ηl=η0 .Similarly, let R n 0 R_{n_0} Rn0 denote R R R in the case where T l = Y l 0 {\boldsymbol{T}\boldsymbol{l}}={\boldsymbol{Y}\boldsymbol{l}}_{0} Tl=Yl0 .Let { X n } \{X_{n}\} {Xn} be a sequence of real-valued random variables, where each. X n X_{n} Xn can be erpressed as some function of { 1 ( F n ( z ) ) : \{ \mathbf{1} ( \mathcal{F} _{n}( z) ) : {1(Fn(z)): z ∈ U − S } z\in U- S\} z∈U−S} ,and let Y Y Y be any probability distribution on 1 R 1\mathbb{R} 1R .Then for every x ∈ R x\in\mathbb{R} x∈R and ϵ = ϵ ( n ) > 0 \epsilon=\epsilon(n)>0 ϵ=ϵ(n)>0 with ϵ = ω ( ∣ P r ( F ) − p ∣ ) \epsilon=\omega(|\mathbf{Pr}(\mathcal{F})-p|) ϵ=ω(∣Pr(F)−p∣) ,for sufficiently large T I TI TI so that ϵ > ∣ Pr ( F ) − p ∣ \epsilon>\left|\Pr(\mathcal{F})-p\right| ϵ>∣Pr(F)−p∣
∣ Pr ( X n ≤ x ) − Pr ( Y ≤ x ) ∣ ≤ ∣ Pr ( X n ≤ x ∣ ∣ R n − p ∣ ≤ ϵ ) − Pr ( Y ≤ x ) ∣ + 2 exp [ − 2 n ( ϵ − ∣ P r ( F ) − p ∣ ) 2 λ 2 + ξ ] . \begin{aligned}|\Pr(X_{n}\leq x)-\Pr(Y\leq x)|\leq|\Pr(X_{n}\leq x\mid|R_{n}-p|\leq\epsilon)-\Pr(Y\leq x)|\\&+2\exp\left[\frac{-2n(\epsilon-|\mathbf{Pr}(\mathcal{F})-p|)^{2}}{\lambda^{2}+\xi}\right].\end{aligned} ∣Pr(Xn≤x)−Pr(Y≤x)∣≤∣Pr(Xn≤x∣∣Rn−p∣≤ϵ)−Pr(Y≤x)∣+2exp[λ2+ξ−2n(ϵ−∣Pr(F)−p∣)2].
Proof. The proof is a straightforward application of Theorem 7.1.Fix any x ∈ x\in x∈ 18 ,and choose some E E E satisfying the conditions of the lemma. Ther.
n ≤ x ) = P r ( X n ≤ x , ∣ R n − p ∣ > ϵ ) + P r ( X n ≤ x , ∣ R n − p ∣ ≤ ϵ ) = P r ( X n ≤ x ∣ ∣ R n − p ∣ ≤ ϵ ) + P r ( ∣ R n − p ∣ > ϵ ) [ P r ( X n ≤ x ∣ ∣ R n − p ∣ > ϵ ) − P r ( X n ≤ x ∣ ∣ R n − p ∣ ≤ ϵ ] \begin{aligned}{}_{n}\leq x)&=\mathbf{Pr}(X_{n}\leq x,|R_{n}-p|>\epsilon)+\mathbf{Pr}(X_{n}\leq x,|R_{n}-p|\leq\epsilon)\\&=\mathbf{Pr}(X_{n}\leq x\mid|R_{n}-p|\leq\epsilon)\\&+\mathbf{Pr}(|R_{n}-p|>\epsilon)\left[\mathbf{Pr}(X_{n}\leq x\mid|R_{n}-p|>\epsilon)-\mathbf{Pr}(X_{n}\leq x\mid|R_{n}-p|\leq\epsilon\right]\end{aligned} n≤x)=Pr(Xn≤x,∣Rn−p∣>ϵ)+Pr(Xn≤x,∣Rn−p∣≤ϵ)=Pr(Xn≤x∣∣Rn−p∣≤ϵ)+Pr(∣Rn−p∣>ϵ)[Pr(Xn≤x∣∣Rn−p∣>ϵ)−Pr(Xn≤x∣∣Rn−p∣≤ϵ]
implying that
∣ Pr ( X n ≤ x ) − Pr ( X n ≤ x ∣ ∣ R n − p ∣ ≤ ϵ ) ∣ ≤ Pr ( ∣ R n − p ∣ > ϵ ) . |\Pr(X_n\leq x)-\Pr(X_n\leq x\mid|R_n-p|\leq\epsilon)|\leq\Pr(|R_n-p|>\epsilon). ∣Pr(Xn≤x)−Pr(Xn≤x∣∣Rn−p∣≤ϵ)∣≤Pr(∣Rn−p∣>ϵ).
Therefore,
( X n ≤ x ) − P r ( Y ≤ x ) ∣ P r ( X n ≤ x ) − P r ( X n ≤ x ∣ ∣ R n − p ∣ ≤ ϵ ) ∣ + ∣ P r ( X n ≤ x ∣ ∣ R n − p ∣ ≤ ϵ ) − P r ( Y n ≤ x ) P r ( ∣ R n − p ∣ > ϵ ) + ∣ P r ( X n ≤ x ∣ ∣ R n − p ∣ ≤ ϵ ) − P r ( Y n ≤ x ) ∣ , \begin{aligned}&(X_{n}\leq x)-\mathbf{Pr}(Y\leq x)|\\&\mathbf{Pr}(X_{n}\leq x)-\mathbf{Pr}(X_{n}\leq x\mid|R_{n}-p|\leq\epsilon)|+|\mathbf{Pr}(X_{n}\leq x\mid|R_{n}-p|\leq\epsilon)-\mathbf{Pr}(Y_{n}\leq x)\\&\mathbf{Pr}(|R_{n}-p|>\epsilon)+|\mathbf{Pr}(X_{n}\leq x\mid|R_{n}-p|\leq\epsilon)-\mathbf{Pr}(Y_{n}\leq x)|,\end{aligned} (Xn≤x)−Pr(Y≤x)∣Pr(Xn≤x)−Pr(Xn≤x∣∣Rn−p∣≤ϵ)∣+∣Pr(Xn≤x∣∣Rn−p∣≤ϵ)−Pr(Yn≤x)Pr(∣Rn−p∣>ϵ)+∣Pr(Xn≤x∣∣Rn−p∣≤ϵ)−Pr(Yn≤x)∣,
so for sufficiently large T l . Tl. Tl. so that ϵ > ∣ P r ( F ) − p ∣ \epsilon>\left|\mathbf{Pr}(\mathcal{F})-p\right| ϵ>∣Pr(F)−p∣
∣ Pr ( X n ≤ x ) − Pr ( Y ≤ x ) ∣ ≤ ∣ Pr ( X n ≤ x ∣ ∣ R n − p ∣ ≤ ϵ ) − Pr ( Y ≤ x ) ∣ + 2 exp [ − 2 n ( ϵ − ∣ P r ( F ) − p ∣ ) 2 λ 2 + ξ ] , \begin{aligned}|\Pr(X_{n}\leq x)-\Pr(Y\leq x)|\leq|\Pr(X_{n}\leq x\mid|R_{n}-p|\leq\epsilon)-\Pr(Y\leq x)|\\&+2\exp\left[\frac{-2n(\epsilon-|\mathbf{Pr}(\mathcal{F})-p|)^{2}}{\lambda^{2}+\xi}\right],\end{aligned} ∣Pr(Xn≤x)−Pr(Y≤x)∣≤∣Pr(Xn≤x∣∣Rn−p∣≤ϵ)−Pr(Y≤x)∣+2exp[λ2+ξ−2n(ϵ−∣Pr(F)−p∣)2],
by Theorem 7.1.
Toillustrate the power of Theorem7.1andLemma 7.1,we use them to prove versions of the strong law oflarge numbers.the weak law of large numbers.Hoeffding’s inequality,and the central limit theorem.
Theorem 7.2.Consider a scheme that satisfies the conditions of Theorem 7.1.Let Z ⊆ U − S Z\subseteq U-S Z⊆U−S be countably infinite,and write Z = { z 1 , z 2 , … } Z=\{z_{1},z_{2},\ldots\} Z={z1,z2,…} .Then for any ϵ > 0 \epsilon>0 ϵ>0 ,for n sufficiently large so that ϵ > ∣ P r ( F ) − p ∣ \epsilon>\left|\mathbf{Pr}(\mathcal{F})-p\right| ϵ>∣Pr(F)−p∣ ,we have.
Pr ( lim ℓ → ∞ 1 ℓ ∑ i = 1 ℓ 1 ( F n ( z i ) ) = R n ) = 1. \Pr\left(\lim\limits_{\ell\to\infty}\dfrac{1}{\ell}\sum\limits_{i=1}^{\ell}\mathbf{1}(\mathcal{F}_{n}(z_{i}))=R_{n}\right)=1. Pr(ℓ→∞limℓ1i=1∑ℓ1(Fn(zi))=Rn)=1.
2.For any ϵ > 0 \epsilon>0 ϵ>0 ,for TI sufficiently large so that ϵ > ∣ Pr ( F ) − p ∣ \epsilon>\left|\Pr(\mathcal{F})-p\right| ϵ>∣Pr(F)−p∣
P r ( ∣ lim ℓ → ∞ 1 ℓ ∑ i = 1 ℓ 1 ( F n ( z i ) ) − p ∣ > ϵ ) ≤ 2 exp [ − 2 n ( ϵ − ∣ P r ( F ) − p ∣ ) 2 λ 2 + ξ ] . \mathbf{Pr}\left(\left|\lim\limits_{\ell\to\infty}\dfrac{1}{\ell}\sum\limits_{i=1}^\ell\mathbf{1}(\mathcal{F}_n(z_i))-p\right|>\epsilon\right)\leq2\exp\left[\dfrac{-2n(\epsilon-|\mathbf{Pr}(\mathcal{F})-p|)^2}{\lambda^2+\xi}\right]. Pr( ℓ→∞limℓ1i=1∑ℓ1(Fn(zi))−p >ϵ)≤2exp[λ2+ξ−2n(ϵ−∣Pr(F)−p∣)2].
In particular, lim ℓ → ∞ 1 ℓ ∑ i = 1 ℓ 1 ( F n ( z i ) ) \operatorname*{lim}_{\ell\rightarrow\infty}\frac1\ell\sum_{i=1}^\ell\mathbf{1}(\mathcal{F}_n(z_i)) limℓ→∞ℓ1∑i=1ℓ1(Fn(zi)) converges to P P P in probability as 7 l → 0 7l\rightarrow0 7l→0
3.For any function Q ( n ) Q(n) Q(n) , ϵ > 0 \epsilon>0 ϵ>0 ,andn sufficiently large so that ϵ / 2 > ∣ P r ( F ) − p ∣ \epsilon/2>\left|\mathbf{Pr}(\mathcal{F})-p\right| ϵ/2>∣Pr(F)−p∣
Pr
r
(
∣
1
Q
(
n
)
∑
i
=
1
Q
(
n
)
1
(
F
n
(
z
i
)
)
−
p
∣
>
ϵ
)
≤
2
e
−
Q
(
n
)
ϵ
2
/
2
+
2
exp
[
−
2
n
(
ϵ
/
2
−
∣
P
r
(
F
)
−
p
∣
)
2
λ
2
+
ξ
]
.
\mathbf{r}\left(\left|{\frac{1}{Q(n)}}\sum_{i=1}^{Q(n)}\mathbf{1}(\mathcal{F}_{n}(z_{i}))-p\right|>\epsilon\right)\leq2\mathrm{e}^{-Q(n)\epsilon^{2}/2}+2\exp\left[{\frac{-2n(\epsilon/2-|\mathbf{Pr}(\mathcal{F})-p|)^{2}}{\lambda^{2}+\xi}}\right].
r
Q(n)1i=1∑Q(n)1(Fn(zi))−p
>ϵ
≤2e−Q(n)ϵ2/2+2exp[λ2+ξ−2n(ϵ/2−∣Pr(F)−p∣)2].
4.For any function Q ( n ) Q(n) Q(n) with lim n → ∞ Q ( n ) = ∞ \operatorname*{lim}_{n\to\infty}Q(n)=\infty limn→∞Q(n)=∞ and Q ( n ) = o ( min ( 1 / ∣ P r ( F ) − p ∣ 2 , n ) ) Q(n)=o(\operatorname*{min}(1/|\mathbf{Pr}(\mathcal{F})-p|^{2},n)) Q(n)=o(min(1/∣Pr(F)−p∣2,n))
∑ i = 1 Q ( n ) 1 ( F n ( z i ) ) − p Q ( n ) p ( 1 − p ) → \sum_{i=1}^{Q(n)}\frac{\mathbf{1}(\mathcal{F}_{n}(z_{i}))-p}{\sqrt{Q(n)p(1-p)}}\to ∑i=1Q(n)Q(n)p(1−p)1(Fn(zi))−p→N(0,1) in itituin s 7 l → 0 7l\rightarrow0 7l→0
Remark. By Theorems 6.2 and 6.3, ∣ P r ( F ) − p ∣ = Θ ( 1 / n ) |\mathbf{Pr}(\mathcal{F})-p|=\Theta(1/n) ∣Pr(F)−p∣=Θ(1/n) for both the partition and double hashing schemes introduced in Section 5. Thus, for each of the schemes, the condition Q ( n ) = Q(n)= Q(n)= o ( min ( 1 / ∣ P r ( F ) − p ∣ 2 , n ) ) o(\operatorname*{min}(1/|\mathbf{Pr}(\mathcal{F})-p|^{2},n)) o(min(1/∣Pr(F)−p∣2,n)) in the fourth part of Theorem 7.2 becomes Q ( n ) = o ( n ) Q(n)=o(n) Q(n)=o(n)
Proof. Since, given R n R_{n} Rn , the random variables { 1 ( F n ( z ) ) : z ∈ Z } \{\mathbf{1}(\mathcal{F}_{n}(z)):z\in Z\} {1(Fn(z)):z∈Z} are conditionally independent Bernoulli trials with common success probability R n R_{n} Rn ,a direct application of the strong law of large numbers yields the first item. For the second item.we note that the first item implies that
lim ℓ → ∞ 1 ℓ ∑ i = 1 ℓ 1 ( F n ( z i ) ) ∼ R n . \lim\limits_{\ell\to\infty}\frac{1}{\ell}\sum\limits_{i=1}^{\ell}\mathbf{1}(\mathcal{F}_{n}(z_{i}))\sim R_{n}. ℓ→∞limℓ1i=1∑ℓ1(Fn(zi))∼Rn.
A direct application of Theorem 7.1 then gives the result.
The remaining two items are slightly more difficult.However, they can be dealt with using straightforward applications of Lemma 7.1. For the third item,define
X n = d e f ∣ 1 Q ( n ) ∑ i = 1 Q ( n ) 1 ( F n ( z i ) ) − p ∣ . X_n\stackrel{\mathrm{def}}{=}\left|\frac{1}{Q(n)}\sum_{i=1}^{Q(n)}\mathbf{1}(\mathcal{F}_n(z_i))-p\right|. Xn=def Q(n)1i=1∑Q(n)1(Fn(zi))−p .
and Y = d e t 0 Y\overset{\mathrm{det}}{\operatorname*{=}}0 Y=det0 .Let =e/2to obtain
P r ( X n > ϵ ∣ ∣ R n − p ∣ ≤ δ ) = P r ( ∣ ∑ i = 1 Q ( n ) 1 ( F n ( z i ) ) − Q ( n ) p ∣ > Q ( n ) ϵ ∣ ∣ R n − p ∣ ≤ δ ) ≤ P r ( ∣ ∑ i = 1 Q ( n ) 1 ( F n ( z i ) ) − Q ( n ) R n ∣ > Q ( n ) ( ϵ − ∣ R n − p ∣ ) ∣ ∣ R n − p ∣ ≤ δ ) ≤ P r ( ∣ ∑ i = 1 Q ( n ) 1 ( F n ( z i ) ) − Q ( n ) R n ∣ > Q ( n ) ϵ 2 ∣ ∣ R n − p ∣ ≤ δ ) ≤ 2 e − Q ( n ) t 2 / 2 , \begin{aligned}&\mathbf{Pr}(X_{n}>\epsilon\mid|R_{n}-p|\leq\delta)\\&=\mathbf{Pr}\left(\left|\sum_{i=1}^{Q(n)}\mathbf{1}(\mathcal{F}_{n}(z_{i}))-Q(n)p\right|>Q(n)\epsilon\:\bigg|\:|R_{n}-p|\leq\delta\right)\\&\leq\mathbf{Pr}\left(\left|\sum_{i=1}^{Q(n)}\mathbf{1}(\mathcal{F}_{n}(z_{i}))-Q(n)R_{n}\right|>Q(n)\left(\epsilon-|R_{n}-p|\right)\:\bigg|\:|R_{n}-p|\leq\delta\right)\\&\leq\mathbf{Pr}\left(\left|\sum_{i=1}^{Q(n)}\mathbf{1}(\mathcal{F}_{n}(z_{i}))-Q(n)R_{n}\right|>\frac{Q(n)\epsilon}{2}\:\bigg|\:|R_{n}-p|\leq\delta\right)\\&\leq2\mathrm{e}^{-Q(n)t^{2}/2},\end{aligned} Pr(Xn>ϵ∣∣Rn−p∣≤δ)=Pr i=1∑Q(n)1(Fn(zi))−Q(n)p >Q(n)ϵ ∣Rn−p∣≤δ ≤Pr i=1∑Q(n)1(Fn(zi))−Q(n)Rn >Q(n)(ϵ−∣Rn−p∣) ∣Rn−p∣≤δ ≤Pr i=1∑Q(n)1(Fn(zi))−Q(n)Rn >2Q(n)ϵ ∣Rn−p∣≤δ ≤2e−Q(n)t2/2,
where the first two steps are obvious, the third step follows from the fact that P r ( F n ∣ R n ) = R n \mathbf{Pr}(\mathcal{F}_{n}\mid R_{n})=R_{n} Pr(Fn∣Rn)=Rn and the fourth step is an application of Hoeffding’s Inequality (using the fact that, given R n R_{n} Rn { 1 ( F n ( z ) ) : z ∈ Z } \{1(\mathcal{F}_{n}(z)):z\in Z\} {1(Fn(z)):z∈Z} are independent and identically distributed Bernoulli trials with commor success probability R n R_{n} Rn ).
Now, since P r ( Y ≤ ϵ ) = 1 \mathbf{Pr}(Y\leq\epsilon)=1 Pr(Y≤ϵ)=1
P r ( X n ≤ ϵ ∣ ∣ R n − p ∣ ≤ δ ) − P r ( Y ≤ ϵ ) ∣ = P r ( X n > ϵ ∣ ∣ R n − p ∣ ≤ δ ) ≤ 2 e − Q ( n ) ϵ 2 / 2 . \mathbf{Pr}(X_{n}\leq\epsilon\mid|R_{n}-p|\leq\delta)-\mathbf{Pr}(Y\leq\epsilon)|=\mathbf{Pr}(X_{n}>\epsilon\mid|R_{n}-p|\leq\delta)\leq2\mathrm{e}^{-Q(n)\epsilon^{2}/2}. Pr(Xn≤ϵ∣∣Rn−p∣≤δ)−Pr(Y≤ϵ)∣=Pr(Xn>ϵ∣∣Rn−p∣≤δ)≤2e−Q(n)ϵ2/2.
An application of Lemma 7.1 now gives the third item. For the fourth item, we write
Q(n) >
1
(
F
n
(
z
i
)
)
−
p
Q
(
n
)
p
(
1
−
p
)
=
R
n
(
1
−
R
n
)
p
(
1
−
p
)
(
∑
i
=
1
Q
(
n
)
1
(
F
n
(
z
i
)
)
−
R
n
Q
(
n
)
R
n
(
1
−
R
n
)
+
(
R
n
−
p
)
Q
(
n
)
R
n
(
1
−
R
n
)
)
\frac{\mathbf{1}(\mathcal{F}_n(z_i))-p}{\sqrt{Q(n)p(1-p)}}=\sqrt{\frac{R_n(1-R_n)}{p(1-p)}}\left(\sum_{i=1}^{Q(n)}\frac{\mathbf{1}(\mathcal{F}_n(z_i))-R_n}{\sqrt{Q(n)R_n(1-R_n)}}+(R_n-p)\sqrt{\frac{Q(n)}{R_n(1-R_n)}}\right)
Q(n)p(1−p)1(Fn(zi))−p=p(1−p)Rn(1−Rn)
i=1∑Q(n)Q(n)Rn(1−Rn)1(Fn(zi))−Rn+(Rn−p)Rn(1−Rn)Q(n)
By the central limit theorem,
∑ i = 1 Q ( n ) 1 ( F n ( z i ) ) − R n Q ( n ) R n ( 1 − R n ) → N ( 0 , 1 ) in distribution as n → ∞ , \displaystyle\sum_{i=1}^{Q(n)}\frac{\mathbf{1}(\mathcal{F}_n(z_i))-R_n}{\sqrt{Q(n)R_n(1-R_n)}}\to\mathrm{N}(0,1)\quad\text{in distribution as}n\to\infty, i=1∑Q(n)Q(n)Rn(1−Rn)1(Fn(zi))−Rn→N(0,1)in distribution asn→∞,
since, given R n R_{n} Rn , { 1 ( F n ( z ) ) : z ∈ Z } \{\mathbf{1}(\mathcal{F}_{n}(z)):z\in Z\} {1(Fn(z)):z∈Z} are independent and identically distributed Bernoulli trials with common success probability R n R_{n} Rn . Furthermore, R n R_{n} Rn converges to F F F in probability as T l → x Tl\rightarrow\mathbf{x} Tl→x by Theorem 7.1,so it suffices to show that ( R n − p ) Q ( n ) (R_{n}-p)\sqrt{Q(n)} (Rn−p)Q(n) converges to 0 in probability as η b → x \eta_{b}\rightarrow\mathbf{x} ηb→x .But Q ( n ) = o ( min ( 1 / ∣ P r ( F ) − p ∣ , n ) ) \sqrt{Q(n)}=o(\operatorname*{min}(1/|\mathbf{Pr}(\mathcal{F})-p|,\sqrt{n})) Q(n)=o(min(1/∣Pr(F)−p∣,n)) , so another application of Theorem 7.1 gives the result. L
8. Experiments
In this section,we evaluate the theoretical results of the previous sections empirically for small values of 7 l 7l 7l .We are interested in the following specific schemes: the standard Bloom filter scheme, the partition scheme, the double hashing scheme, and the extended double hashing schemes where f ( i ) = i 2 f(i)=i^{2} f(i)=i2 and f ( i ) = i 3 f(i)=i^{3} f(i)=i3 For c ∈ { 4 , 8 , 12 , 16 } c\in\{4,8,12,16\} c∈{4,8,12,16} ,we do the following. First, compute the value of k ∈ { ⌊ c ln 2 ⌋ , ⌈ c ln 2 ⌉ } k\in\{\lfloor c\ln2\rfloor,\lceil c\ln2\rceil\} k∈{⌊cln2⌋,⌈cln2⌉}
that minimizes p = ( 1 − exp [ − k / c ] ) k p=(1-\exp[-k/c])^{k} p=(1−exp[−k/c])k .Next, for each of the schemes under consideration, repeat the following procedure 10,000 times:instantiate the filter with the specified values of 7 l 7l 7l , C C C
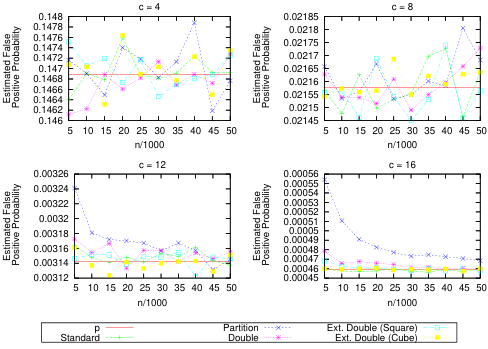
Figure 1: Estimates of the false positive probability for various schemes and parameters.
and k k k ,populate the filter with a set S S S of 7 L 7L 7L items, and then query ⌈ 10 / p ⌉ \lceil10/p\rceil ⌈10/p⌉ elements not in S S S recording the number Q Q Q of those queries for which the filter returns a false positive.We then approximate the false positive probability of the scheme by averaging the results over all 10,000 trials. Furthermore, we bin the results of the trials by their values for C Q CQ CQ in order to examine the other characteristics of Q Q Q 's distribution.
The results are shown in Figures 1 and 2. In Figure 1, we see that for small values of C C C the different schemes are essentially indistinguishable from each other, and simultaneously have a false positive probability/rate close to P P P .This result is particularly significant since the filters that we are experimenting with are fairly small, supporting our claim that these schemes are useful even in settings with very limited space. However, we also see that for the slightly larger values of c ∈ { 12 , 16 } c\in\{12,16\} c∈{12,16} , the partition scheme is no longer particularly useful for small values of 7 L 7L 7L ,while the other schemes are.This result is not particularly surprising, since we know from Section 6 that all of these schemes are unsuitable for small values of T l . Tl. Tl. and large values of C \boldsymbol{C} C . Furthermore, we expect that the partition scheme is the least suited to these conditions, given the observation in Section 2 that the partitioned version of a standard Bloom filter never performs better than the original version. Nevertheless, the partition scheme might still be useful in certain settings, since it gives a substantial reduction in the range of the hash functions. In Figure 2, we give histograms of the results from our experiments with n = 5000 n=5000 n=5000 and c = 8 c=8 c=8
for the partition and extended double hashing schemes. Note that for this value of C C C , optimizing for k k k yields k = 6 k=6 k=6 ,so we have p ≈ 0.021577 p\approx0.021577 p≈0.021577 and ⌈ 10 / p ⌉ = 464 \lceil10/p\rceil=464 ⌈10/p⌉=464 .In each plot, we compare the results to f = d e f 10 , 000 ϕ 464 p , 464 p ( 1 − p ) f\stackrel{\mathrm{def}}{=}10,000\phi_{464p,464p(1-p)} f=def10,000ϕ464p,464p(1−p) ,where
ϕ μ , σ 2 ( x ) = d e f e − ( x − μ ) 2 / 2 σ 2 σ 2 π \phi_{\mu,\sigma^2}(x)\stackrel{\mathrm{def}}{=}\frac{\mathrm{e}^{-(x-\mu)^2/2\sigma^2}}{\sigma\sqrt{2\pi}} ϕμ,σ2(x)=defσ2πe−(x−μ)2/2σ2
denotes the density function of N ( μ , σ 2 ) {\mathrm{N}}(\mu,\sigma^{2}) N(μ,σ2) .As one would expect, given central limit theorem in the fourth part of Theorem 7.2, f f f provides a reasonable approximation to each of the histograms
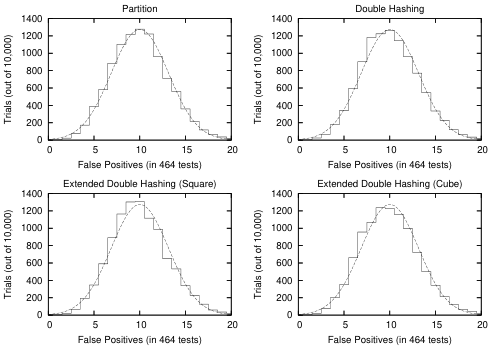
Figure 2: Estimate of distribution of C Q CQ CQ (for n = 5000 n=5000 n=5000 and c = 8 c=8 c=8 ),compared with f f f
9. A Modified Count-Min Sketch
We now present a modification to the Count-Min sketch introduced in [4] that uses fewer hash functions in a manner similar to our improvement for Bloom filters, at the cost of a small space increase.We begin by reviewing the original data structure.
9.1 Count-Min Sketch Review
The following is an abbreviated review of the description given in [4].A Count-Min sketch takes as input a stream of updates ( i t , c t ) (i_t,c_t) (it,ct) ,starting from t = 1 t=1 t=1 ,where each item i t i_{t} it is a member of a universe U = { 1 , … , n } U=\{1,\ldots,n\} U={1,…,n} ,and each count C t Ct Ct is a positive number.(Extensions to negative counts are possible;we do not consider them here for convenience.)The state of the system at time T T T is given by a vector a ⃗ ( T ) = ( a 1 ( T ) , … , a n ( T ) ) \vec{a}(T)=(a_{1}(T),\ldots,a_{n}(T)) a(T)=(a1(T),…,an(T)) ,where a j ( T ) a_{j}(T) aj(T) is the sum of all C t Ct Ct for which t ≤ T t\leq T t≤T and i t = j i_{t}=j it=j .We generally drop the I I I when the meaning is clear. The Count-Min sketch consists of an array Count of width w = d e f ⌈ e / ϵ ⌉ w\stackrel{\mathrm{def}}{=}\left\lceil\mathrm{e}/\epsilon\right\rceil w=def⌈e/ϵ⌉ and depth d = d e f ⌈ ln 1 / δ ⌉ d\stackrel{\mathrm{def}}{=}\left\lceil\ln1/\delta\right\rceil d=def⌈ln1/δ⌉
Count [ 1 , 1 ] , … [1,1],\ldots [1,1],…,Count [ d , w ] [d,w] [d,w] .Every entry of the array is initialized to U U U .In addition,the CountMin sketch uses d d d hash functions chosen independently from a pairwise independent family H H H : { 1 , … , n } → { 1 , … , w } \{1,\ldots,n\}\to\{1,\ldots,w\} {1,…,n}→{1,…,w} The mechanics of the Count-Min sketch are extremely simple.Whenever an update ( i , c ) (i,c) (i,c)
arrives, we increment
C
o
u
n
t
[
j
,
h
j
(
i
)
]
\mathop{\mathrm{Count}}[j,h_{j}(i)]
Count[j,hj(i)] by
t
t
t for
j
=
1
,
…
,
d
j=1,\ldots,d
j=1,…,d .Whenever we want an estimate of
u
i
u_{i}
ui (called a point query),we compute
a
^
i
=
d
e
f
min
j
=
1
d
C
o
u
n
t
[
j
,
h
j
(
i
)
]
.
\hat{a}_i\stackrel{\mathrm{def}}{=}\min_{j=1}^d\mathrm{Count}[j,h_j(i)].
a^i=defj=1mindCount[j,hj(i)].
The fundamentalresult of Count-Min sketches is that for every
τ
˙
\dot{\tau}
τ˙
a
^
i
≥
a
a
n
d
P
r
(
a
^
i
≤
a
i
+
ϵ
∥
a
⃗
∥
)
≥
1
−
δ
,
\hat{a}_{i}\geq a\quad\mathrm{and}\quad\mathbf{Pr}(\hat{a}_{i}\leq a_{i}+\epsilon\|\vec{a}\|)\geq1-\delta,
a^i≥aandPr(a^i≤ai+ϵ∥a∥)≥1−δ,
where the norm is the L 1 L_{1} L1 norm. Surprisingly,this very simple bound allows for a number of sophisticated estimation procedures to be efficiently and effectively implemented on Count-Min sketches. The reader is once again referred to [4] for details.
9.2Using Fewer Hash Functions
We now show how the improvements to Bloom filters discussed previously in this paper can be usefully applied to Count-Min sketches. Our modification maintains all of the essential features of Count-Min sketches, but reduces the required number of pairwise independent hash functions to 2 ⌈ ( ln 1 / δ ) / ( ln 1 / ϵ ) ⌉ 2\lceil(\ln1/\delta)/(\ln1/\epsilon)\rceil 2⌈(ln1/δ)/(ln1/ϵ)⌉ .We expect that, in many settings, E E E and δ \delta δ will be related, so that only a constant number of hash functions will be required; in fact, in many such situations only two hash functions are required. We describe a variation of the Count-Min sketch that uses just two pairwise independent hash
functions and guarantees that
a ^ i ≥ a a n d P r ( a ^ i ≤ a i + ϵ ∥ a ⃗ ∥ ) ≥ 1 − ϵ . \hat{a}_{i}\geq a\quad\mathrm{and}\quad\mathbf{Pr}(\hat{a}_{i}\leq a_{i}+\epsilon\|\vec{a}\|)\geq1-\epsilon. a^i≥aandPr(a^i≤ai+ϵ∥a∥)≥1−ϵ.
Given such a result, it is straightforward to obtain a variation that uses 2 ⌈ ( ln 1 / δ ) / ( ln 1 / ϵ ) ⌉ 2\lceil(\ln1/\delta)/(\ln1/\epsilon)\rceil 2⌈(ln1/δ)/(ln1/ϵ)⌉ pairwise independent hash functions and achieves the desired failure probability δ \delta δ : simply build 2 ⌈ ( ln 1 / δ ) / ( ln 1 / ϵ ) ⌉ 2\lceil(\ln1/\delta)/(\ln1/\epsilon)\rceil 2⌈(ln1/δ)/(ln1/ϵ)⌉ independent copies of this data structure, and always answer a point query with the minimum estimate given by one of those copies. Our variation will use d d d tables numbered { 0 , 1 , … , d − 1 } \{0,1,\ldots,d-1\} {0,1,…,d−1} ,each with exactly u b ub ub counters
numbered { 0 , 1 , … , w − 1 } \{0,1,\ldots,w-1\} {0,1,…,w−1} ,where d d d and U D UD UD will be specified later.We insist that u b ub ub be prime. Just as in the original Count-Min sketch, we let Count [ j , k ] \operatorname{Count}[j,k] Count[j,k] denote the value of the k k k th counter in the j j j th table. We choose hash functions h 1 h_{1} h1 and h 2 h_{2} h2 independently from a pairwise independent. family H : { 0 , … , n − 1 } {\mathcal{H} }: \{ 0, \ldots , n- 1\} H:{0,…,n−1} → \to → { 0 , 1 , … , w − 1 } \{ 0, 1, \ldots , w- 1\} {0,1,…,w−1} ,and define g j ( x ) g_{j}( x) gj(x) = h 1 ( x ) h_{1}( x) h1(x) + j h 2 ( x ) jh_{2}( x) jh2(x) mod U U U for j = 0 , … , d − 1 j=0,\ldots,d-1 j=0,…,d−1 The mechanics of our data structure are the same as for the original Count-Min sketch.
Whenever an update ( i , c ) (i,c) (i,c) occurs in the stream, we increment C o u n t [ j , g j ( i ) ] \mathop{\mathrm{Count}}[j,g_{j}(i)] Count[j,gj(i)] by t t t ,for j = j= j= 0 , … , d − 1 0,\ldots,d-1 0,…,d−1 .Whenever we want an estimate of u i u_{i} ui ,we compute
a ^ i = d e f min j = 0 d − 1 C o u n t [ j , g j ( i ) ] . \hat{a}_i\stackrel{\mathrm{def}}{=}\min\limits_{j=0}^{d-1}\mathrm{Count}[j,g_j(i)]. a^i=defj=0mind−1Count[j,gj(i)].
We prove the following result:
Theorem 9.1. For the Count-Min sketch variation described above.
a ^ i ≥ a a n d P r ( a ^ i > a i + ϵ ∥ a ⃗ ∥ ) ≤ 2 ϵ w 2 + ( 2 ϵ w ) d . \hat{a}_{i}\ge a\quad and\quad\mathbf{Pr}(\hat{a}_{i}>a_{i}+\epsilon\|\vec{a}\|)\le\frac{2}{\epsilon w^{2}}+\left(\frac{2}{\epsilon w}\right)^{d}. a^i≥aandPr(a^i>ai+ϵ∥a∥)≤ϵw22+(ϵw2)d.
In particular, for w ≥ 2 w\geq2 w≥2e / ϵ /\epsilon /ϵ and δ ≥ ln 1 / ϵ ( 1 − 1 / 2 e 2 ) \delta\geq\ln1/\epsilon(1-1/2\mathrm{e}^{2}) δ≥ln1/ϵ(1−1/2e2)
a ^ i ≥ a a n d P r ( a ^ i > a i + ϵ ∥ a ⃗ ∥ ) ≤ ϵ . \hat{a}_{i}\geq a\quad and\quad\mathbf{Pr}(\hat{a}_{i}>a_{i}+\epsilon\|\vec{a}\|)\leq\epsilon. a^i≥aandPr(a^i>ai+ϵ∥a∥)≤ϵ.
Proof. Fix some item i i i .Let A i A_{i} Ai be the total count for all items Z (besides i ˙ \dot{i} i˙ )with h 1 ( z ) = h 1 ( i ) h_{1}(z)=h_{1}(i) h1(z)=h1(i) and h 2 ( z ) = h 2 ( i ) h_{2}(z)=h_{2}(i) h2(z)=h2(i) .Let B j , i B_{j,i} Bj,i be the total count for all items Z with g j ( i ) = g j ( z ) g_{j}(i)=g_{j}(z) gj(i)=gj(z) ,excluding i i i and items 2 counted in A i A_{i} Ai .It follows that
a ^ i = min j = 0 d − 1 Count [ j , g j ( i ) ] = a i + A i + min j = 0 d − 1 B j , i . \hat{a}_i=\min\limits_{j=0}^{d-1}\text{Count}[j,g_j(i)]=a_i+A_i+\min\limits_{j=0}^{d-1}B_{j,i}. a^i=j=0mind−1Count[j,gj(i)]=ai+Ai+j=0mind−1Bj,i.
Thelower bound now follows immediately from the fact thatallitems have nonnegative counts. since all updates are positive. Thus, we concentrate on the upper bound, which we approach by noticing that
P
r
(
a
^
i
≥
a
i
+
ϵ
∥
a
⃗
∥
)
≤
P
r
(
A
i
≥
ϵ
∥
a
⃗
∥
/
2
)
+
P
r
(
min
j
=
0
d
−
1
B
j
,
i
≥
ϵ
∥
a
⃗
∥
/
2
)
.
\mathbf{Pr}(\hat a_i\ge a_i+\epsilon\|\vec a\|)\le\mathbf{Pr}(A_i\ge\epsilon\|\vec a\|/2)+\mathbf{Pr}\left(\min\limits_{j=0}^{d-1}B_{j,i}\ge\epsilon\|\vec a\|/2\right).
Pr(a^i≥ai+ϵ∥a∥)≤Pr(Ai≥ϵ∥a∥/2)+Pr(j=0mind−1Bj,i≥ϵ∥a∥/2).
We first bound
A
i
A_{i}
Ai . Letting
1
(
⋅
)
1(\cdot)
1(⋅) denote the indicator function,we have
E
[
A
i
]
=
∑
z
≠
i
a
z
E
[
1
(
h
1
(
z
)
=
h
1
(
i
)
∧
h
2
(
z
)
=
h
2
(
i
)
)
]
≤
∑
z
≠
i
a
z
/
w
2
≤
∥
a
⃗
∥
/
w
2
,
\mathbf{E}[A_i]=\sum\limits_{z\ne i}a_z\:\mathbf{E}[\mathbf{1}(h_1(z)=h_1(i)\wedge h_2(z)=h_2(i))]\le\sum\limits_{z\ne i}a_z/w^2\le\|\vec{a}\|/w^2,
E[Ai]=z=i∑azE[1(h1(z)=h1(i)∧h2(z)=h2(i))]≤z=i∑az/w2≤∥a∥/w2,
where the first step follows from linearity of expectation and the second step follows from the definition of the hash functions.Markov’s inequality now implies that
Pr
(
A
i
≥
ϵ
∥
a
⃗
∥
/
2
)
≤
2
/
ϵ
w
2
.
\Pr(A_{i}\geq\epsilon\|\vec{a}\|/2)\leq2/\epsilon w^{2}.
Pr(Ai≥ϵ∥a∥/2)≤2/ϵw2.
To bound
min
j
=
0
d
−
1
B
j
,
i
\operatorname*{min}_{j=0}^{d-1}B_{j,i}
minj=0d−1Bj,i ,we note that for any
j
∈
{
0
,
…
,
d
−
1
}
j\in\{0,\ldots,d-1\}
j∈{0,…,d−1} and
z
≠
i
z\neq i
z=i
P
r
(
(
h
1
(
z
)
≠
h
1
(
i
)
∨
h
2
(
z
)
≠
h
2
(
i
)
)
∧
g
j
(
z
)
=
g
j
(
i
)
)
≤
P
r
(
g
j
(
z
)
=
g
j
(
i
)
)
=
P
r
(
h
1
(
z
)
=
h
1
(
i
)
+
j
(
h
2
(
i
)
−
h
2
(
z
)
)
=
1
/
w
,
\begin{aligned}\mathbf{Pr}((h_{1}(z)\neq h_{1}(i)\vee h_{2}(z)\neq h_{2}(i))\wedge g_{j}(z)=g_{j}(i))&\leq\mathbf{Pr}(g_{j}(z)=g_{j}(i))\\&=\mathbf{Pr}(h_{1}(z)=h_{1}(i)+j(h_{2}(i)-h_{2}(z))\\&=1/w,\end{aligned}
Pr((h1(z)=h1(i)∨h2(z)=h2(i))∧gj(z)=gj(i))≤Pr(gj(z)=gj(i))=Pr(h1(z)=h1(i)+j(h2(i)−h2(z))=1/w,
SO
E
[
B
j
,
i
]
=
∑
z
≠
i
a
z
E
[
1
(
(
h
1
(
z
)
≠
h
1
(
i
)
∨
h
2
(
z
)
≠
h
2
(
i
)
)
∧
g
j
(
z
)
=
g
j
(
i
)
)
]
≤
∥
a
⃗
∥
/
w
,
\mathbf{E}[B_{j,i}]=\sum_{z\ne i}a_z\:\mathbf{E}[\mathbf{1}((h_1(z)\ne h_1(i)\vee h_2(z)\ne h_2(i))\wedge g_j(z)=g_j(i))]\le\|\vec{a}\|/w,
E[Bj,i]=z=i∑azE[1((h1(z)=h1(i)∨h2(z)=h2(i))∧gj(z)=gj(i))]≤∥a∥/w,
and so Markov’s inequality implies that
P
r
(
B
j
,
i
≥
ϵ
∥
a
⃗
∥
/
2
)
≤
2
/
ϵ
w
\mathbf{Pr}(B_{j,i}\geq\epsilon\|\vec{a}\|/2)\leq2/\epsilon w
Pr(Bj,i≥ϵ∥a∥/2)≤2/ϵw
For arbitrary
u
b
ub
ub , this result is not strong enough to bound
min
j
=
0
d
−
1
B
j
,
i
.
\operatorname*{min}_{j=0}^{d-1}B_{j,i}.
minj=0d−1Bj,i. However, since
u
b
ub
ub is prime, each item
Z
Z
Z can only contribute to one
B
k
,
i
B_{k,i}
Bk,i (since if
g
j
(
z
)
=
g
j
(
i
)
g_{j}(z)=g_{j}(i)
gj(z)=gj(i) for two values of
j
j
j ,we must have
h
1
(
z
)
=
h
1
(
i
)
h_{1}(z)=h_{1}(i)
h1(z)=h1(i) and
h
2
(
z
)
=
h
2
(
i
)
h_{2}(z)=h_{2}(i)
h2(z)=h2(i) , and in this case 2 's count is not included in any
B
j
,
i
B_{j,i}
Bj,i ). In this sense, the
B
j
,
i
B_{j,i}
Bj,i 's are negatively dependent [7]. It follows that for any value
U
U
U
P
r
(
min
j
=
0
d
−
1
B
j
,
i
≥
v
)
≤
∏
j
=
0
d
−
1
P
r
(
B
j
,
i
≥
v
)
.
\mathbf{Pr}\left(\min\limits_{j=0}^{d-1}B_{j,i}\geq v\right)\leq\prod\limits_{j=0}^{d-1}\mathbf{Pr}(B_{j,i}\geq v).
Pr(j=0mind−1Bj,i≥v)≤j=0∏d−1Pr(Bj,i≥v).
In particular,we have that
P
r
(
min
j
=
0
d
−
1
B
j
,
i
≥
ϵ
∥
a
⃗
∥
/
2
)
≤
(
2
/
ϵ
w
)
d
,
\mathbf{Pr}\left(\min\limits_{j=0}^{d-1}B_{j,i}\geq\epsilon\|\vec{a}\|/2\right)\leq(2/\epsilon w)^d,
Pr(j=0mind−1Bj,i≥ϵ∥a∥/2)≤(2/ϵw)d,
SO
P
r
(
a
^
i
≥
a
i
+
ϵ
∥
a
⃗
∥
)
≤
P
r
(
A
i
≥
ϵ
∥
a
⃗
∥
/
2
)
+
P
r
(
min
j
=
0
B
j
,
i
≥
ϵ
∥
a
⃗
∥
/
2
)
≤
2
ϵ
w
2
+
(
2
ϵ
w
)
d
.
\begin{aligned}\mathbf{Pr}(\hat{a}_{i}\geq a_{i}+\epsilon\|\vec{a}\|)&\leq\mathbf{Pr}(A_{i}\geq\epsilon\|\vec{a}\|/2)+\mathbf{Pr}\left(\operatorname*{min}_{j=0}B_{j},i\geq\epsilon\|\vec{a}\|/2\right)\\&\leq\frac{2}{\epsilon w^{2}}+\left(\frac{2}{\epsilon w}\right)^{d}.\end{aligned}
Pr(a^i≥ai+ϵ∥a∥)≤Pr(Ai≥ϵ∥a∥/2)+Pr(j=0minBj,i≥ϵ∥a∥/2)≤ϵw22+(ϵw2)d.
And for
w
≥
2
w\geq2
w≥2e
/
ϵ
/\epsilon
/ϵ and
δ
≥
ln
1
/
ϵ
(
1
−
1
/
2
e
2
)
\delta\geq\ln1/\epsilon(1-1/2\mathrm{e}^{2})
δ≥ln1/ϵ(1−1/2e2) ,we have
2
ϵ
w
2
+
(
2
ϵ
w
)
d
≤
ϵ
/
2
e
2
+
ϵ
(
1
−
1
/
2
e
2
)
=
ϵ
,
\begin{aligned}\frac{2}{\epsilon w^2}+\left(\frac{2}{\epsilon w}\right)^d\leq\epsilon/2e^2+\epsilon(1-1/2\text{e}^2)=\epsilon,\end{aligned}
ϵw22+(ϵw2)d≤ϵ/2e2+ϵ(1−1/2e2)=ϵ,
completing the proof
10. Conclusion
Bloom filters are simple randomized data structures that are extremely useful in practice.In fact, they are so useful that any significant reduction in the time required to perform a Bloom filter operation immediately translates to a substantial speedup for many practical applications Unfortunately, Bloom filters are so simple that they do not leave much room for optimization. This paper focuses on modifying Bloom filters to use less of the only resource that they tradi-
tionally use liberally: (pseudo)randomness. Since the only nontrivial computations performed by. a Bloom filter are the constructions and evaluations of pseudorandom hash functions, any reduction in the required number of pseudorandom hash functions yields a nearly equivalent reduction in the time required to perform a Bloom filter operation (assuming, of course, that the Bloom filter is stored entirely in memory, so that random accesses can be performed very quickly) We have shown that a Bloom filter can be implemented with only two pseudorandom hash
functions without any increase in the asymptotic false positive probability, and, for Bloom filters of fixed size with reasonable parameters,without any substantial increase in the false positive probability.We have also shown that the asymptotic false positive probability acts,for all practical purposes and reasonable settings of a Bloom filter’s parameters, like a false positive rate. This result has enormous practical significance, since the analogous result for standard Bloom filters is essentially the theoretical justification for their extensive use… More generally, we have given a general framework for analyzing modified Bloom filters, which
we expect will be used in the future to refine the specific schemes that we analyzed in this paper. We also expect that the techniques used in this paper will be usefully applied to other data structures, as demonstrated by our modification to the Count-Min sketch.
Acknowledgements
We are very grateful to Peter Dillinger and Panagiotis Manolios for introducing us to this problem, providing us with advance copies of their work, and also for many useful discussions.
References
[1] P. Billingsley. Probability and Measure, Third Edition. John Wiley & Sons, 1995.
[2] P. Bose, H. Guo, E. Kranakis, A. Maheshwari, P. Morin, J. Morrison, M. Smid, and Y Tang. On the false-positive rate of Bloom filters. Submitted. Temporary version available at http://cg.scs.carleton.ca/~morin/publications/ds/bloom-submitted.pdf [3]A. Broder and M. Mitzenmacher. Network Applications of Bloom Filters: A Survey. Internet Mathematics, to appear. Temporary version available at http: //www.eecs.harvard. edu/. ~michaelm/postscripts/tempim3.pdf [4] G. Cormode and S. Muthukrishnan. Improved Data Stream Summaries: The Count-Min Sketch and its Applications. DIMACS Technical Report 2003-20, 2003 [5]P. C. Dillinger and P. Manolios. Bloom Filters in Probabilistic Verification. FMCAD 2004, Formal Methods in Computer-Aided Design, 2004. [6]P. C. Dillinger and P. Manolios. Fast and Accurate Bitstate Verification for SPIN. SPIN 2004, 11th International SPIN Workshop on Model Checking of Software, 2004.
[7]D. P. Dubhashi and D. Ranjan. Balls and Bins: A Case Study in Negative Dependence. Random Structures and Algorithms, 13(2):99-124, 1998 [8]L.Fan, P. Cao, J. Almeida,and A. Z. Broder. Summary cache: a scalable wide-area Web cache sharing protocol. IEEE/ACM Transactions on Networking, 8(3):281-293, 2000 [9] K. Ireland and M. Rosen. A Classical Introduction to Modern Number Theory, Second Edition. Springer-Verlag, New York, 1990 [10]D. Knuth. The Art of Computer Programming, Volume 3: Sorting and Searching. AddisonWesley, Reading Massachusetts, 1973. [11] M. Mitzenmacher. Compressed Bloom Filters. IEEE/ACM Transactions on Networking. 105:613-620, 2002 [12] M. Mitzenmacher and E. Upfal. Probability and Computing: Randomized Algorithms and Probabilistic Analysis. Cambridge University Press, 2005. [13] M. V. Ramakrishna. Practical performance of Bloom filters and parallel free-text searching Communications of the ACM, 32(10):1237-1239, 1989.















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









