







模型介绍
Wav2Lip是一种先进的深度学习模型,旨在将音频波形直接转换为面部动画,尤其关注于唇部动作的生成与同步。这一技术的核心在于其能够利用输入的语音信号,生成与之高度匹配的嘴唇动作,从而实现逼真的语音驱动数字人物动画效果。Wav2Lip的开发不仅标志着在语音驱动的面部动画领域的一个重要进展,也为虚拟现实、游戏制作、智能语音助手等多个应用领域提供了新的技术手段。
Wav2Lip模型基于生成对抗网络(GAN)设计,包含生成器和判别器两个主要部分。生成器的任务是根据输入的音频波形生成逼真的面部动画,而判别器的目标是区分生成的动画与真实的面部动画。该模型通过训练一个专家口型同步判别器来判断音频和口型是否同步,实验证明,这个判别器比传统基于像素的人脸重建方法或基于GAN的判别器在口型同步判别任务上更为准确。这种精确度的提升得益于Wav2Lip对SyncNet的改进,包括使用RGB图像作为输入、增加模型深度以及采用余弦相似度二元交叉熵损失等措施。
Wav2Lip的训练过程分为两个主要阶段:专家音频和口型同步判别器的预训练阶段以及GAN网络的训练阶段。在第一阶段,模型通过大量的音频-图像对来学习如何准确地判断口型与音频的同步情况。在第二阶段,GAN的生成器网络学习音频-图像对之间的映射关系,逐渐学会根据音频特征生成逼真的嘴唇动作。为了优化模型性能,Wav2Lip使用的损失函数包括重建损失、对抗损失和风格损失等,这些损失函数有助于提高模型的准确性和稳定性。
在应用场景方面,Wav2Lip因其能够提供高质量的语音到面部动画转换,而在多个领域显示出广泛的应用前景。例如在语音动画方面,可以为VR/AR环境提供更加丰富的视觉反馈;在电影和游戏制作领域,可以创建更加逼真的角色表演效果;智能语音助手中,通过结合语音识别与合成技术,提供更加自然和智能的交互体验。
随着技术的不断进步和应用需求的不断扩大,Wav2Lip及其相关技术的发展将为数字人物动画、人机交互等领域带来更多可能性。特别是在提升用户体验、增强互动真实感方面,这类技术的应用潜力巨大。然而,实现更自然、更逼真的动画效果仍面临诸多挑战,如进一步提高模型对复杂语音变化的适应能力、处理不同语言和口音的同步问题等,这些都是未来研究的重要方向。
总之,Wav2Lip作为一种创新的深度学习模型,在将语音波形转换为面部动画方面取得了显著成果。通过其独特的模型结构和训练方法,Wav2Lip不仅提升了语音驱动动画的同步精度和真实性,也为相关应用领域提供了新的技术支持和解决方案。未来,随着技术的进一步优化和应用的深入,Wav2Lip有望在数字人物动画、智能交互等方面发挥更大作用,为用户提供更加丰富、逼真的交互体验。
个人需求
为目标视频或者图片生成所要音频的对应口型,并生成视频。
下载地址
官方地址:https://github.com/Rudrabha/Wav2Lip
个人仓库:。。。
模型配置
整体分为5步
一、下载权重文件
官方提供加载地址,README.md中查看。

此次任务中,只涉及第一个预训练权重。实现的结果嘴部模糊,需要进一步清晰化。效果一般。
第二个预训练权重,因电脑配置原因,有待使用。
二、准备测试数据
新建文件夹input,准备了一张jpg图片,一段MP4视频,一段录音wav。
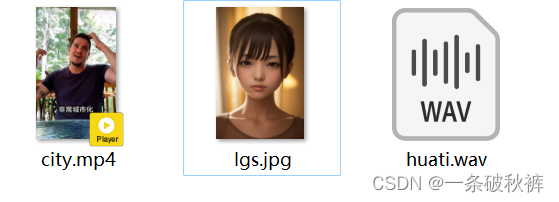
目标1:改变mp4内的男人整个过程的口型,改变的内容为wav。
目标2:使jpg内girl的口型为wav的内容。
建议视频长度与音频长度相同
三、安装相关包
我的环境:
- python 3.8.19
- torch 2.3.1+cu121
- torchaudio 2.3.1+cu121
- torchvision 0.18.1+cu121
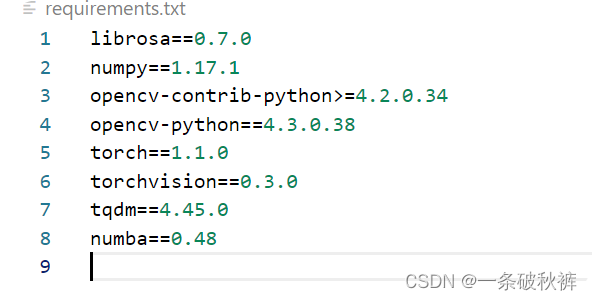
此外还需要ffmpeg,下载地址。
四、编译运行
参照:

个人指令:
python .\inference.py --checkpoint_path checkpoints\wav2lip.pth --face input\lgs.jpg --audio input\huati.wav BUG
Traceback (most recent call last):
File ".\inference.py", line 280, in <module>
main()
File ".\inference.py", line 225, in main
mel = audio.melspectrogram(wav)
File "F:\VSCodeProject\Wav2Lip-master-2\audio.py", line 47, in melspectrogram
S = _amp_to_db(_linear_to_mel(np.abs(D))) - hp.ref_level_db
File "F:\VSCodeProject\Wav2Lip-master-2\audio.py", line 95, in _linear_to_mel
_mel_basis = _build_mel_basis()
File "F:\VSCodeProject\Wav2Lip-master-2\audio.py", line 100, in _build_mel_basis
return librosa.filters.mel(hp.sample_rate, hp.n_fft, n_mels=hp.num_mels,
TypeError: mel() takes 0 positional arguments but 2 positional arguments (and 3 keyword-only arguments) were given解决方法
这个错误是因为在调用librosa.filters.mel()函数时,传入了错误的参数。根据错误信息,mel()函数需要0个位置参数,但传入了2个位置参数和3个关键字参数。
尝试修改_build_mel_basis()函数中的librosa.filters.mel()调用,将位置参数改为关键字参数。
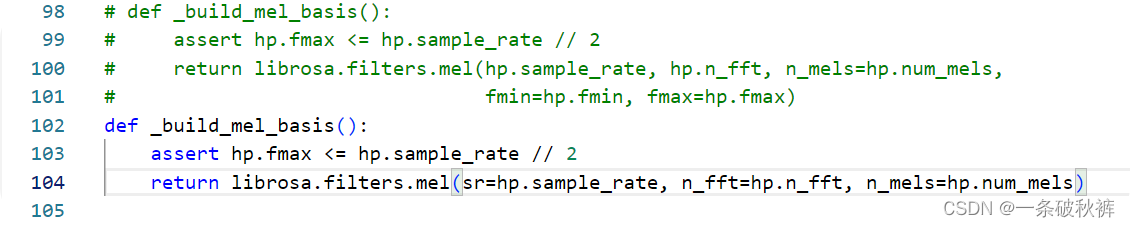
def _build_mel_basis():
return librosa.filters.mel(sr=hp.sample_rate, n_fft=hp.n_fft, n_mels=hp.num_mels)
五、查看结果

mp4

jpg

参考资料
B站UP:

















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









