







链接:https://arxiv.org/abs/2203.06616
代码:https://github.com/jiaxiaojunQAQ
本文发表于2022年的CVPR,它是由中科院信工所、香港中文大学(深圳)和腾讯 AILab 共同提出的一种可学习的对抗训练框架 LAS-AT 通过引入“可学习的攻击策略”,LAS-AT 可以学习自动产生攻击策略来提高模型的鲁棒性。
Backward
对抗训练(AT)被认为是最有效的防御方法之一,这个式子就是进行对抗训练的过程:
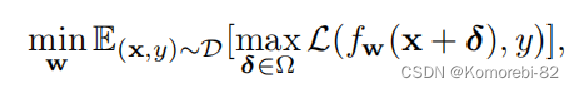
首先最大化损失找到合适的扰动,形成对抗样本,再使用对抗样本最小化损失调整模型参数,完成训练。 而对抗样本的生成是进行对抗训练的关键 ,以前的研究工作大多是根据攻击方法“手动指定攻击参数”来生成对抗样本的, 这些攻击参数的组合可被视为攻击策略 。
Motivation
目前的方法主要存在以下两个问题:
1)大多数现有的方法仅仅使用固定的攻击策略(手动指定)来生成 AE,限制了模型的鲁棒性; 2)大多数方法只使用一种攻击策略,而目前已有研究指出在对抗训练的不同阶段中使用固定的攻击策略会使得模型的鲁棒性受限

在本文中,通过引入“可学习的攻击策略”,即 LAS-AT,提出了一个新颖的对抗训练框架,它可以学习自动产生攻击策略以提高模型的鲁棒性。
Method
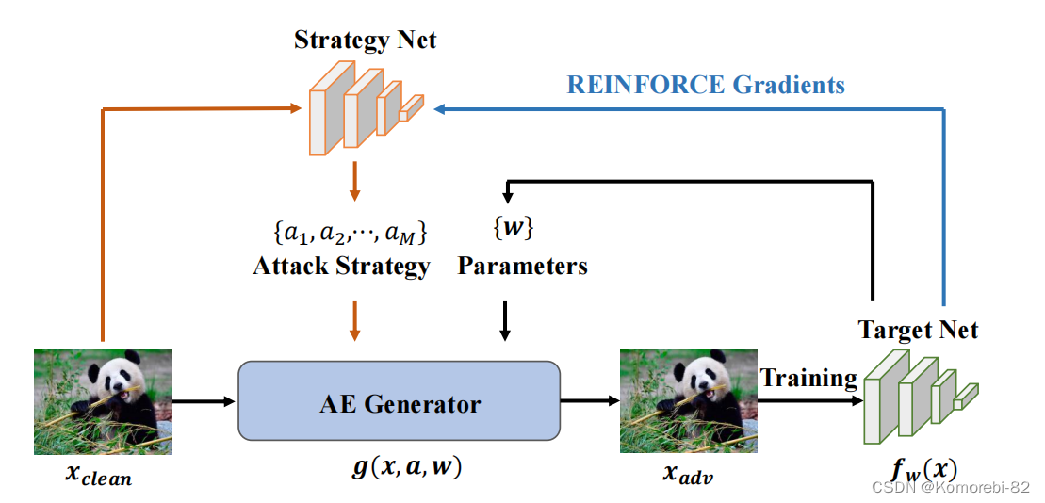
LAS-AT 框架图:它由一个策略网络和一个目标网络组成。这两个网络是具有竞争关系的。 对于策略网络,在给定一个干净的图像时,策略网络会生成一个对应的针对该样本的攻击策略;这些攻击参数的可选值的一个组合可以看作是一个策略 对于目标网络,AE 生成器会根据攻击策略和目标网络来生成一个 AE,用于训练目标网络。同时,目标网络也会分别给予 AE 生成器和策略网络一个监督信号。
给定一个干净的样本x,对抗样本的生成过程可以被定义为:
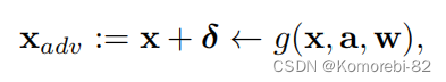
Xadv 表示的是其对应的对抗样本,a 是一个攻击策略,w 表示的是目标网络的参数,g(·) 表示的是我们使用的攻击方法(PGD)。
对抗训练公式:
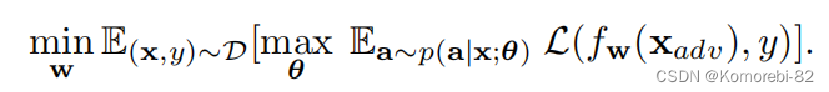
与标准的对抗训练相比,最与众不同的地方在于对抗样本的生成方式。 标准对抗训练采用的是人为设定的策略去求解内部优化问题。然而本文中我们是使用策略网络根据条件概率分布去产生一个样本依赖策略。
Loss Function
![]()
L1:衡量对抗样本的预测标签与真实标签之间的距离的损失
Loss of Evaluating Robustness.L2评估鲁棒性损失:
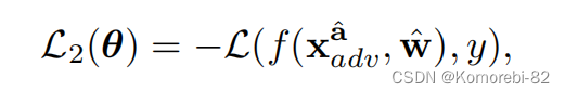
为了引导策略网络的学习,我们提出了一种新的度量方式去评估对抗攻击,主要使用的是目标网络单步更新的鲁棒性。 具体地,一个攻击策略 a 首先被用作去创造一个对抗样本 Xadv,并且该对抗样本通过一阶梯度下降法去单步调整目标网络的参数 w。 如果更新后的目标网络 w^能够正确预测由另一种攻击策略 a^生成的对抗样本Xadv^ 的标签,则此时可以说该攻击策略是有效的。
Loss of Predicting Clean Samples.L3 预测干净样本损失:
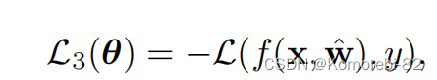
一个好的攻击策略应该不仅可以提高目标模型的鲁棒性也能够保持预测干净样本的准确率。在本论文中也考虑了目标模型在预测干净样本时的性能
总损失L:
![]()
L1 是目标网络和策略网络参数的函数,L2 和 L3 涉及策略网络参数。α和β是两个损失项的权衡超参数。
Optimization
论文提出了一种算法来交替优化两个网络的参数。
给定θ,优化目标网络的子问题可以定义为

给定一个干净的图像,策略网络生成一个策略分布p(a|x;θ),我们从条件分布中随机抽样一个策略。采样策略用于生成AEs。收集了一批样本的AEs后,我们可以通过梯度下降来更新目标模型的参数,即:
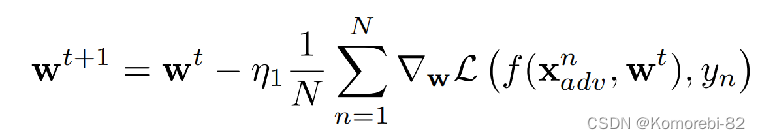
其中N为小批量样品的数量,η1为学习率
给定w,优化策略网络参数的子问题可以写成:
![]()
![]()
计算目标函数J(θ)对参数θ的导数为:
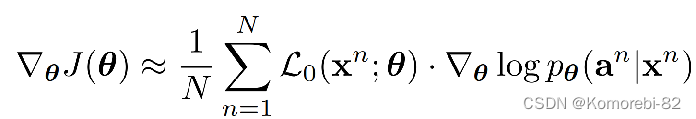
其中L0 = L1 + αL2 + βL3。 与优化目标网络类似,生成ae后,我们可以通过梯度上升来更新目标模型的参数:
![]()
其中η2为学习速率。θ和w是迭代更新的。我们每k次更新θ就更新w一次。
Experiments
与其他 AT 模型比较
下表分别为不同对抗训练的方法在 CIFAR10、CIFAR100 数据集上鲁棒性的实验结果。 我们选择PGD、TRADES和AWP这三种作为基础模型 ,然后把我们的方法和这些模型的组合 在攻击方面选择了几种对抗性攻击方法对训练好的模型进行攻击,包括 PGD、C&W 和 AA,以干净正确率和稳健正确率作为评价指标。

可以发现,在大多数攻击场景下,论文中提出的三种方法对抗训练出的模型的性能都优于原理的基础模型模型,并且最优数据都出现在与论文中的方法结合的模型中。 而且在很多情况下,论文中的方法不仅提高了基础模型的鲁棒性,而且提高了干净样本分类的精度。
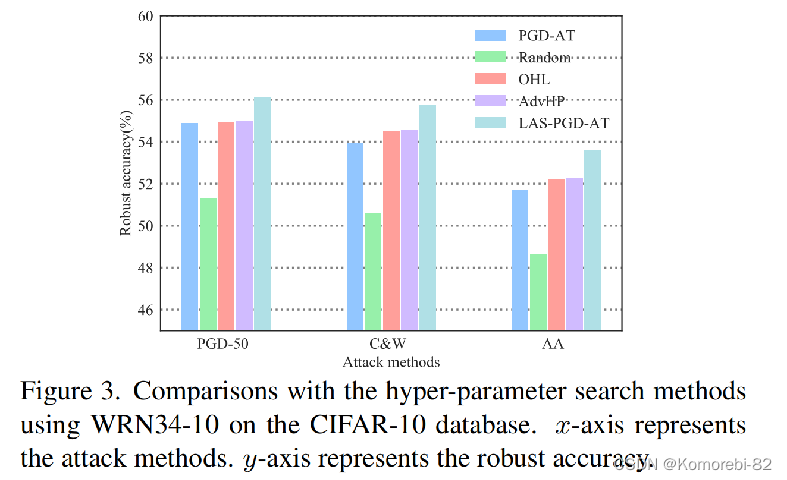
论文中方法与其他几种超参数搜索方法进行了比较。从图中可以看出,论文中的方法(绿蓝色)在所有攻击场景下对抗训练出的模型都达到了最佳的鲁棒性性能。
策略网络在不同训练阶段的攻击策略分布。
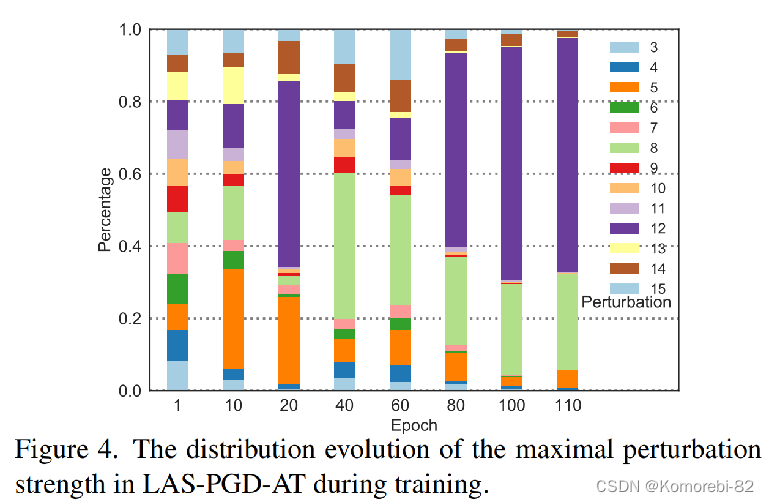
在对抗训练开始时,分布覆盖了最大扰动强度的所有可选值。每个值都有选择的机会,这确保了对抗样本的多样性。 随着对抗训练的进行,小扰动强度的百分比降低。在后期,最大扰动强度的分布被几个大值占据。 这一现象表明,策略网络逐渐增加大扰动强度的百分比,以生成更强的对抗扰动,进而目标网络的鲁棒性通过使用强对抗样本进行训练而逐渐增强
鲁棒性实验
本文也在这两种目标网络(WRN)上测试了方法的有效性。与两种不同的训练方法对比,实验表明本文的方法 LAS-AWP 可以提高模型的鲁棒性,实现更高的鲁棒性精度 并且它在自动攻击(AA)下的结果也是更好的
















 1700
1700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









