







论文地址:https://arxiv.org/abs/2305.08192
代码地址:https://github.com/WindVChen/DiffAttack
目录
3.2 Basic Framework of Destruction and Reconstruction
3.3 “Deceive” Strong Diffusion Model
3.4 Preserve Content Structure
Abstract
许多现有的对抗攻击在图像RGB空间上产生Lp范数扰动。尽管在可迁移性和攻击成功率方面取得了一些成就,但精心制作的对抗样本很容易被人眼感知。对于视觉的不可感知性,最近的一些研究探索了不受Lp范数约束的无限制攻击,但缺乏攻击黑盒模型的可迁移性。在这项工作中,我们通过利用扩散模型的生成和判别能力,提出了一种新的难以察觉和可迁移的攻击。具体来说,我们不是在像素空间中直接操作,而是在扩散模型的潜在空间中进行扰动。结合精心设计的内容保存结构,我们可以生成嵌入语义线索的人类不敏感的扰动。为了更好的可迁移性,我们进一步“欺骗”扩散模型,它可以被视为一个额外的识别代理,通过将其注意力从目标区域转移开。据我们所知,我们提出的方法DiffAttack是第一个将扩散模型引入对抗攻击领域的方法。在各种模型结构(包括cnn, Transformers, mLp)和防御方法上的大量实验证明了我们的攻击方法优于其他攻击方法。
Introduction
我们将扩散模型引入对抗攻击领域的动机主要来自它的两个有益特性。1)良好的隐蔽性。扩散模型倾向于对符合人类感知的自然图像进行采样,这自然满足了对抗攻击的不可感知性要求。2)强代理的近似。一方面,扩散模型的去噪过程可以作为一种强大的净化防御。另一方面,在大规模数据集上训练的扩散模型本身具有强大的判别能力,可以近似为基于迁移的攻击的强替代模型。如果攻击可以骗过这个“强模型”,那么我们就可以期望很好的迁移到其他模型和防御。
为了有效地利用扩散模型的上述优点,我们从三个方面进行了工作。首先,我们利用DDIM构建基本框架,将图像逆到噪声中,然后在潜在空间中进行修改。与通过改变引导文本实现内容编辑的方法[48,49]相比,我们侧重于对潜在的直接操作,这有利于攻击的成功。其次,我们提出偏离文本和图像像素之间的交叉注意映射,这样我们可以将扩散模型转换为可以实际欺骗和攻击的替代模型。最后,为了避免扭曲初始语义,我们考虑了具体的措施,包括自注意约束和反转强度。我们将提出的无限制攻击称为DiffAttack。
Diffusion Model
在前向过程中,首先将图像转换为纯高斯噪声,然后训练U-Net结构来预测反转过程中每个时间步中的附加噪声。经过大量数据的训练,扩散模型既可以从随机采样的噪声中生成高质量的图像,也可以根据文本提示的指导生成更具体的图像。
Method
3.1 Problem Formulation
给定一个干净的图像x和它对应的标签y,攻击者的目标是制造扰动,使分类器的决策Fθ (θ表示模型的参数)从正确变为错误:
![]()
其中Attack(·)为攻击方法,x’表示精心制作的对抗样本。由于Fθ的信息在黑盒场景中是不可访问的,因此对抗样本是在替代模型Gφ上制作的。
3.2 Basic Framework of Destruction and Reconstruction
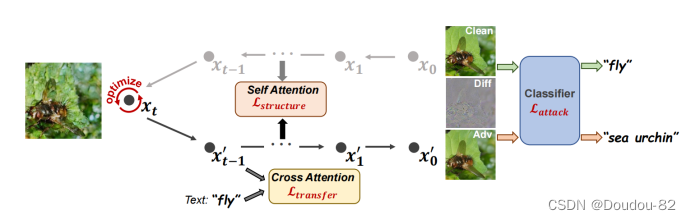
图2:DiffAttack框架。我们采用稳定扩散,利用DDIM反演将干净图像转化为潜在空间。隐式被优化以欺骗分类器。交叉注意图被用来“欺骗”扩散模型,而我们使用自注意图来保留结构。
我们在图2中展示了DiffAttack的整个框架,其中我们采用了开源的Stable Diffusion,对海量文本图像对进行预训练。本文的框架还利用了DDIM反演技术,通过反演确定性采样过程,将干净图像映射回扩散潜空间:
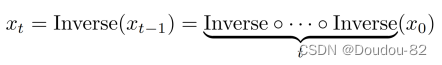
其中Inverse(·)表示DDIM反演操作我们对从x0(初始图像)到xt的几个时间步进行反演。
我们在这里提出直接扰动潜在的xt:
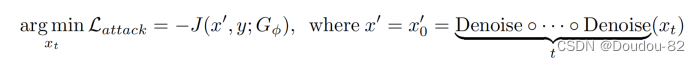
其中J(·)为交叉熵损失,Denoise(·)为扩散去噪过程。
3.3 “Deceive” Strong Diffusion Model
扩散模型的反向过程是一种很强的对抗性净化防御。因此,我们的扰动潜信号在解码为最终图像之前经历了净化,从而确保了精心制作的对抗样本的自然性以及对其他净化降噪的鲁棒性。
除了避开去噪部分外,我们还进一步提高了攻击的可迁移性。给定一张图像及其对应的标题,从图3中我们可以看到,在反演的重建过程中,交叉注意图显示出了引导文本与图像像素之间的强关系,这说明了预训练扩散模型的强大识别能力。

图3:交叉注意和自注意地图的可视化。在交叉注意中,文本和像素之间有很强的关系,而自注意则能很好地显示结构
C表示为干净图像的类别,我们将其设置为groundtruth类别的名称(我们也可以简单地使用预测类别Gφ,因此不依赖于真实标签)。我们在所有去噪步骤中累积图像像素与C之间的交叉注意映射并得到平均值。为了“欺骗”预训练的扩散模型,我们建议最小化以下公式:
![]()
其中Var(·)计算输入的方差,Cross(·)表示去噪过程中所有交叉注意图的累加,SDM为稳定扩散。这种洞察力是为了分散扩散模型对标记对象的注意力。通过将交叉注意力均匀地分布到图像的每个像素上,我们可以破坏原始的强语义关系,确保我们精心制作的对抗样本很好地“欺骗”了强扩散模型。
3.4 Preserve Content Structure
如果变化的程度没有得到控制,那么产生的对抗样本可能会失去初始干净图像的大部分语义,这会失去对抗攻击的意义。因此,我们在这里主要从两个角度来保存内容结构。
Self-Attention Control. 研究发现,基于自相似的描述符可以在忽略图像外观的情况下捕获结构信息。根据这个想法,我们可以从图3中观察到,扩散模型中的自注意也嵌入了这个属性,这与主要关注高级语义的交叉注意形成对比。因此,我们建议利用自注意图进行结构保留。我们设定了逆潜函数的一个副本xt(fix),它是固定的,没有扰动。通过分别计算xt(f)和xt的自注意映射(记为St(f)和St),我们强迫St接近St(f),方法如下:
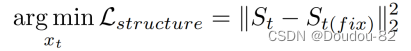
我们在这里将自注意约束应用于所有去噪步骤。由于xt(f)很好地重建了原始的干净图像,我们可以通过这种方式保留结构。
Inversion Strength Trade-off. 随着DDIM反演强度的增加,潜函数xt将更接近于纯高斯分布,对其的扰动会受到更多去噪步骤的影响而造成严重的失真。而有限的反演无法提供足够的攻击空间,因为潜函数先验太强。我们在去噪过程的后面控制反转以保留高级语义,并减少DDIM样本的总步骤以获得更多的编辑空间。
一般情况下,DiffAttack的最终目标函数如下,其中α、β、γ分别表示各损失的权重因子:
![]()

















 7116
7116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









