









Python复习笔记
文章目录
一、前言
这是哪托针对老师的课件整理的复习笔记,基础入门,希望能对广大基础小白受用。内容如有错误的地方,劳请留言指正。
笔记所有代码使用Microsoft VS Code的 Python、Jupyter 插件编译。
二、语言基础
2.1标识符
1.2.1标识符
标识符可以包括英文、数字以及下划线,并且:
开头必须是字母或下划线;
不能以数字开头开头;
区分大小写的;
不能出现分隔符、标点符号或者运算符;
不能使用关键字:def if for while class等
最好不要使用内置模块名、类型名、函数名、已经导入的模块 及其成员名
合法的标识符:A、ABC、aBc、a1b2、ab_123、__(连续两个下画线)、_123 等
非法的标识符:6a2b、abc-123、hello world(中间用了空格)、for(关键字)等
1.2.2关键字
关键字None
- None是一个特殊的Python对象,不是False,不是0,也不是空字符串、空列表等。
- None有自己的数据类型NoneType,None和任何其他数据类型进行是否相等比较永远返回False。
- 可以将None赋值给任何变量,但是不能创建其他NoneType对象。
2.1.3变量
变量: 与 C与Java语言相比
相同点:
- 用于储存计算结果或能表示值
- 可以通过
变量名访问,变量值通常是可变的。 - 变量具有
名字,不同变量是通过名字相互区分的。
不同点:
- 变量的数据类型:不需要声明
- 变量的数据类型:可以变化(Python是
动态类型语言)。 - 变量使用之前:必须赋值。
常量:Python没有常量,即没有语法规则限制改变一个常量的值。
怎么办呢?
使用人为约定。通常用全大写字母表示常量,编程时不要修改它的值。
# 常量示例
TAX_RATE = 0.17
PI = 3.14
CUMTXHC = "你喜欢我吗"
2.2数据类型
1.整型int
整数:没有小数部分的数值,分为正整数、0和负整数。
100、0、 -100
100 #十进制
ob101 #二进制
0o11 #八进制
0x2F #十六进制
2.浮点数float
浮点数:包含小数点的数。
15.0、0.37、-11.2、2.3e2、3.14e-2
15.0
2.3e2 #科学计数法
3.14e-2
3.复数complex
复数由两部分组成:实部和虚部。复数的形式为:实部+虚部j。
2+3j、0.5-0.9j都是复数。
2+3j
z=0.5-0.9j
z.real #复数的实部
z.imag #复数的虚部
两个注意点:
- Python支持
任意大的数字,仅受内存大小的限制(所以在使用时,不用考虑int、float的范围) - 为了提高可读性,在数值中可以使用
下画线
4.布尔bool
布尔类型是用来表示逻辑“是”、“非”的一种类型,它只有两个值,True和False (首字母T和F是大写的)
Python将布尔值True实现为1(int类型),False实现为0,所以可以参与整型运算,但不建议这么做
5.字符串str
Python语言中的字符串是一种序列。字符串用单引号、双引号、三引号作为定界符。
“Python”、’ Hello,World ‘、“123”、’’'abcd8 ^ ‘’'等。
6.列表 list
列表也是一种序列类型。列表用方括号“[”和“]”将列表中的元素括起来。元素之间以逗号进行分隔。
[1,2,3,True]、[“one”,“two”,“three”,“four”]和[3,4.5, “abc”]
7.元组 tuple
元组也是一种序列。元组用“(”和“)”作为边界将元素括起来。元素之间以逗号分隔。
(1,2,3,True)、(“one”,“two”,“three”,“four”)和(3,4.5, “abc”)。
8.字典 dict
字典是唯一内建的映射类型,可用来实现通过数据查找关联数据的功能。字典是键值对的无序集合。字典中的每一个元素都包含两部分:键和值。字典用大括号“{”和“}”来表示,每个元素的键和值用冒号分隔,元素之间用逗号分隔。
{‘1801’:‘张三’, ‘1802’:‘徐虎’, ‘1803’:‘张林’}
9.集合 set
集合是由各种不可变类型的元素组成,但元素之间无序,并且元素都不重复。
{‘car’, ‘ship’, ‘train’, ‘bus’}。
2.3赋值语句、运算符
2.3.1赋值语句的格式
<变量>=<表达式>
#常规:同java
#特殊:多变量赋值
x,y=1,2
a = b = 3
#两变量的交换
x,y=1,2
x,y=y,x
2.3.2运算符
1.算数运算符
在Python中,算术运算符有:+(加)、-(减)、*(乘)、/(真除法)、//(求整商)、%(取模)、**(幂)。
需要说明的几点:
(1) + 运算符不支持不同类型的对象之间的连接
3+"ab" #错误:不同类型
str(3)+"ab" #正确:通过类型转换函数str()将数字3转换成字符串'3'
(2) * 运算符可以用于列表、元组或字符串与整数的相乘,用于将这些序列重复整数所指定的次数。它不适用于字典和集合与整数的相乘。
[1,3,5] * 2 # 列表list
#[1, 3, 5, 1, 3, 5]
('a','b','c') * 2 # 元组tuple
#('a', 'b', 'c', 'a', 'b', 'c')
'Hello' * 2 # 字符串str
#'HelloHello'
{1801:'Lily'} * 2 # 字典dict:不可以。因为字典的键key不能重复。
(3)** 运算符:幂运算,与内置函数pow()相同
(4)/ 真除法 与 //整数除法
5/3 # 真除 1.6666666666666667
5//3 # 取商的整数部分 1
7.4//3 # 操作数为实数时,则取实数形式的整数(即*.0) 2.0
2.关系运算符
六个:<(小于)、<=(小于等于)、>(大于)、>=(大于等于)、==(等于)、!=(不等于)。
结果:布尔值True或False
所有的字符串都是Unicode字符串;
- 单个字符:可以通过
ord()函数获取该字符的Unicode码, - 通过
chr()函数把编码转换为对应的字符。
ord('a') #97
chr(97) #得到对应的字符 a
ord('我') #25105
chr(25105) #我
注意:字符串和数字属于不可比较大小的
列表比较大小:也是从左到右逐个元素的依次比较,类似 字符串之间的比较
列表中:字符串与数值也是不能比较的
[1,2,3]>['a','b'] # 出错
['ab','c',6]>['ab',3,'a'] # 出错
(5)关系运算符可以连用,等价于某几个用and连接起来的表达式。注意:C语言和Java语言均不可这么用。
3<5>2 #与 下式 含义相同 True
3<5 and 5>3 #True
3<5==5 #与 下式 含义相同 True
3<5 and 5==5 #True
(6)因为精度问题可能导致实数运算有一定的误差
- 要尽可能地避免在实数之间进行相等性判断
0.4-0.3 # 有误差了
#0.10000000000000003
0.1==0.4-0.3 # 误差 导致 不相等
#Flase
#解决方法:使用实数之间的差值的绝对值是否小于某一个很小的数来作为实数之间是否相等的判断。
abs(0.1-(0.4-0.3))<0.00000000001 # True,表示 0.1 和 0.4-0.3是相等的
#True
3.测试运算符
四个:in、not in、is、is not。
结果:返回布尔值True或False
2 in [2,3,4] # 列表 True
a = 3
a in [2,3,4] #True
b="abcedfg" # 测试 字符串str
"ab" in b #True
a = (1,2,3)
b = (1,2,3)
a is b # False: 虽然a、b内容一样,但不是同一个对象。
a is not b # True
(7)同一性测试运算符is和is not测试是否为同一个对象或内存地址是否相同,返回布尔值True和False。
x=[1,3,5]
y=[1,3,5]
x is y #测试x、y是否为同一个对象:x,y相等,但不是同一个对象 Flase
x is not y #True
x==y #测试x、y是否相等 True
注意:
- 是否相等
==:只是测试值是否相同, - 是否为同一个对象
is:指的是是否指向同一个对象(如果指向同一个对象,则内存地址应该相同,当然也相等)
内置函数id()返回对象的标识(内存地址)
id(x) # 每个人运行得到的内存地址可能会不一样 3055563066432
z=x # 赋值语句z=x,则z和x不仅值相等而且指向同一个对象,z、x的内存地址相同。
z is x #True
4.逻辑运算符
在Python中,逻辑运算符有:and(与)、or(或)、not(非)。通过逻辑运算符可以将任意表达式连接在一起。
哪些是False:False、None、数值类型中的0、空字符串’’、空元组()、空列表[]、空字典{}、空集合{}等
not False #True
not True #Flase
not 3 # 非零值为True Flase
not 0 # 零值为false True
(10)逻辑操作符and和or也称作短路操作符,具有惰性求值的特点:
- 短路运算:表达式从左向右解析,一旦结果可以确定就停止。
- 注意:逻辑运算符and、or不一定会返回布尔值True和False。
and(与运算):结果不一定为True或False
当计算表达式exp1 and exp2时,
①先计算exp1的值,当exp1的值为True或非空值(非0、非None、值非空的其他数据类型),才计算并输出exp2的值;
②当exp1的值为False或空值(0、None、值为空的其他数据类型),直接输出exp1的值,不再计算exp2。
True and 3 # 第一个为True,则输出第二个的值(结果与第二个值有关):下同 3
4 and False #Flase
3<4 and 4>5 # 3<4的值为True,则计算并输出4>5的值False
False and 4 # 第一个为False,则不再计算第二个的值,直接输出第一个的值:下同
0 and 'c' # 直接输出0
() and 'c' # 直接输出()
or或运算:结果不一定为True或False
当计算表达式exp1 or exp2时:
①先计算exp1的值,当exp1的值为True或非空值(非0、非None、值非空的其他数据类型),直接输出exp1的值,不再计算exp2;
②当exp1的值为False或空值(0、None、值为空的其他数据类型),才计算并输出exp2的值。
True or 3 #第一个为True,则不再计算第二个的值,直接输出第一个的值:下同
3<4 or 4>5 #3<4的值为True,则直接输出True
False or 4 #第一个为False,则继续计算第二个的值,输出第二个的值:下同
0 or 'c'
(11)赋值运算符(=)、复合赋值运算符(+=、-=、*=、/=、//=、%=、**=)、位运算符(&、|、^等)等。
此处基本同C语言。
(12)特别注意: Python没有自加++与自减--
(13)优先级小括号()最高
2.4从控制台输入和输出
1. input()函数
用于输入数据,无论用户输入什么内容,该函数都返回字符串类型。
其格式如下:
input(prompt=None) # prompt=None,表示提示语默认为空
x = input("请输入x值:") # 请输入x值:100
type(x) # 查看x的类型,为<class 'str'> #str
2.类型转换函数
1)int()函数
格式1:int([x])
功能:截取数字的整数部分或将字符串转换成一个整数;如果不给定参数则返回0。
int() #1、没有参数时:0
int(23.74) #2、浮点数:直接截取整数部分(不进行四舍五入)
int(-3.52)
int('4') #3、整数字符串
int('45.6') #4、浮点数字符串:错误 。
注意:int()函数不接受带小数的数字字符串
格式2 :int(x, base=10)
功能:把base进制的字符串x转换为十进制,base为基数(进制),默认为十进制
base的有效值范围为0和2-36
int('1001001',2) #1、二进制的数1001001转换为十进制数 73
int('2ef',16) #2、十六进制的数2ef转换为十进制数 751
int('27',8) #3、八进制的数27转换为十进制数 23
int('101.001',2) #4、不允许二进制的小数(不接受带小数的数字)
int('0b110', base=0) #5、二进制的数110转换为十进制数 6
2)float()函数
格式:float(x=0, /)
功能:将一个数字或字符串转换成浮点数
float() # 默认参数x为0
float('inf') #无穷大,inf不区分大小写
int("3+5") # 错误
float("3.5*2") # 错误
#int()、float()不能转换表达式字符串,所以引入eval()函数
3) eval()函数
- 格式 :eval(source, globals=None, locals=None, /)
- 功能:将 source 字符串 当做一个python 表达式 进行解析和计算,返回计算结果。
- 参数说明:
source是一个字符串,这个字符串能表示成Python表达式,或者是能够通过编译的代码;
globals是可选的参数,默认为None,如果设置属性不为None的话,就必须是dictionary对象;
locals也是可选的参数,默认为None,如果设置属性不为None的话,可以是任何map对象。
- 字符串中是
表达式:返回表达式的值; - 字符串中是
列表、元组或字典:得到真正的列表、元组或字典; - 字符串中是能够通过编译的
代码:执行代码。
x=3
eval('x+1') # 表达式:x+1
eval('3+5') #8
eval('[1,2,3]') # 返回列表[1,2,3]
eval('{1:23,2:32}') # 返回字典{1:23,2:32}
eval('print(3**2)') # 执行print(3**2)语句 9
eval("__import__('os').getcwd()") # 执行语句:获取当前目录
#####组合使用: int()、float()、eval()函数和input()
x=eval(input("请输入x值:")) #输入列表格式:[1,2,3]
x #获得列表
x=eval(input("请输入x值:")) #输入字典格式:{'a':1,'b':2}
x #获得字典
3.数据的输出
print()函数
格式如下:
print(value, …, sep=’ ‘, end=’\n’, file=sys.stdout, flush=False)
各参数的解释如下:
value:需要输出的对象,一次可以输出一个或者多个对象(其中…表示任意多个对象),对象之间要用逗号(,)分隔
sep:对象之间的间隔符,默认用一个空格分隔;
end:以何字符结尾,默认值是换行符;
file:表示输出位置,可将输出到文件,file指定的对象要有“写”的方法,默认值是sys.stdout(标准输出,即控制台屏幕);
flush:将缓存里面的内容是否强制刷新输出,默认值是False(一般不需要)。
print('1.hello','world','!') #一次输出三个对象,中间默认用空格隔开
print('2.hello','world','!',sep='*') #一次输出三个对象,中间用*隔开
print('3.hello','world','!',sep='') #一次输出三个对象,中间无分隔,因为sep参数值被设置为空字符串了
print('4.hello','world','!',end='!') #一次输出三个对象,以!结尾(不换行)
print('5.hello','world','!',sep=',', end='!') #一次输出三个对象,以,分隔,以!结尾
可以看出:print函数默认输出是换行的。如果要实现不换行,需要在变量末尾设置 end参数
2.5内置函数
| 函数 | 功能 |
|---|---|
| abs(x) | 返回数字x的绝对值,如果给出复数,返回值就是该复数的模 |
| bin(x) | 把整数x转换为二进制 |
| divmod(x,y) | 函数返回整商和余数的元组 |
| eval(s[,globals[,locals]]) | 计算字符串中表达式的值并返回 |
| help(obj) | 返回对象obj的帮助信息 |
| id(obj) | 返回对象obj的标识(内存地址) |
| input(prompt=None, /) | 接受键盘输入,显示提示信息,返回字符串 |
| len(obj) | 返回对象obj(列表、元组、字典、字符串、集合、range对象)的元素个数 |
| map(func, *iterables) | 包含若干函数值的map对象,其中func表示函数,iterables表示迭代对象,将函数作用于迭代对象 |
| max(x[,y,z…])、min(x[,y,z…]) | 返回给定参数的最大值、最小值,参数可以为可迭代对象 |
| pow(x,y[,z]) | pow()函数返回以x为底,y为指数的幂。如果给出z值,该函数就计算x的y次幂值被z取模的值 |
| print(value, …, sep=’ ‘, end=’\n’, file=sys.stdout, flush=False) | 输出对象,默认输出到屏幕,相邻数据之间使用空格分隔,结尾以换行符结束 |
| range([start,]end[,step]) | 返回range对象,该对象包含按参数([start,end)范围内,step为步长)生成的整数 |
| round(x[,n]) | 返回浮点数x的四舍五入值,若不给出n值,则返回整数;给出n值,则代表舍入到小数点后的位数 |
| sorted(iterable, /, *, key=None, reverse=False) | 返回排序后的列表,其中iterable表示要排序的序列或迭代对象,key表示排序规则,reverse表示升序或降序,默认升序 |
| sum(iterable, start=0, /) | 返回序列iterable中所有元素之和,如果指定起始值start,则返回start+sum(iterable);如果iterable为空,则返回start |
| chr(i) | 返回Unicode编码为i所对应的字符,0 <= i <= 0x10ffff |
| complex(real[,imag]) | 把字符串或数字转换为复数,如果第1个参数是字符串,不能使用第2个参数 |
| float(x=0, /) | 把一个数字或字符串转换成浮点数 |
| hex(x) | 把整数转换成十六进制串 |
| int(x[,base]) | 把数字和字符串转换成一个整数,或把base进制的字符串x转换为十进制,base为可选的基数,默认为十进制 |
| list([x])、tuple([x])、dict([x])、set([x]) | 将对象x转换成列表、元组、字典、集合,或生成空列表、空元组、空字典、空集合 |
| oct(x) | 把给出的整数x转换成八进制串 |
| ord(x) | 返回一个字符的Unicode编码 |
三、流程控制
3.1分支结构
-
单分支if语句 -
双分支if/else语句 -
多分支if/elif/else语句 -
选择结构的‘嵌套’
-
选择结构的三元运算
【注意】:Python
没有switch语句
语法类似于java此处省略

3.2循环结构
定义:
- 给定的判断条件为真(包括非零、非空)时,重复执行某些操作;
- 判断条件为假(包括零、空)时,结束循环。
循环分类:
- while语句
- for语句
循环中断:
- break
- continue
带else的循环语句(Python特有)
与java类似相关内容请参考java
3.2.1for循环语句
for语句通过遍历一个序列(字符串、列表、元组)或迭代器等可迭代对象中的每个元素来建立循环。
for语句的语法形式如下所示:
for 变量 in 序列或迭代器等可迭代对象:
循环体
补充
range()函数:返回可迭代对象。
语法格式如下:
range(start, stop[, step])
功能:
产生一个从start开始(包括start,默认为0),到stop结束(不包括stop),两个整数对象之间间隔step(默认为1)的可迭代对象。
可以用for循环直接遍历range函数产生的可迭代对象
for i in range(0,10): # 默认step:1
print(i,end=' ')
for i in range(3,15):
print(i,end=' ')
range对象可以被转换成列表或元组,例如:
y=list(x) # range对象转换为list列表对象
z=tuple(x) # range对象转换为tuple元组对象
3.2.2 break语句和continue语句
详细解释:
- break语句:可以用在while和for循环中。在循环进行过程中,如果某个条件被满足(一般通过if语句判断是否满足执行break语句的条件),则可以通过break语句立即终止本层循环。如果break语句在具有两层循环嵌套的内层循环中,则只终止内层循环,进入到外层循环的下一条语句继续执行。
- continue语句:可以用在while和for循环中。在循环体执行过程中,如果遇到continue语句,程序会跳过本次循环的循环体剩余语句,回到循环开始的地方重新判断是否进入下一次循环。
精简:
- break语句终止整个当前循环;
- continue语句的执行不会终止整个当前循环,只是提前结束本次循环,跳过循环体中本次循环的剩余语句,提前进入到下一次循环。
再精简:
- 同
C语言。
3.2.3 带else的循环语句(与C语言不同,不建议用)
Python中的while和for语句后面还可以带有else语句块。
语句语法如下:
while 条件表达式:
循环体
else:
else语句块
三种执行流程:
1)正常循环:当条件表达式为真(True、非空、非零)时,反复执行循环体。
2)执行一次else:当条件表达式为假(False、零、空)而导致循环终止(或无法进入循环),else语句块执行一次,然后结束该循环结构。
3)不执行else:如果该循环是因为执行了循环体中的break语句而导致循环终止,else语句块不会执行,直接结束该循环结构。
例:从键盘输入一个正整数n,用while循环找出小于等于该整数n且能被23整除的最大正整数。如果找到了,输出该整数;如果没有找到,则输出“未找到”
n=int(input('请输入一个正整数:'))
i=n
while i>0:
if i % 23 == 0:
print("小于等于",n,"且能被23整除的最大正整数是:",i)
break
i = i-1
else:
print("未找到。")
带else的for语句语法如下:
for 变量 in 序列或迭代器等可迭代对象:
循环体
else:
else语句块

3.2.4循环嵌套

四、常用数据结构
4.1 序列
4.1.1列表 list
列表是Python中最基本的数据结构,是最常用的数据类型。
列表的特点:
1.列表将由若干数据作为元素的序列放置在一对方括号中,元素之间以逗号分隔。
2.列表中的元素允许重复。
3.列表是可以修改的:增删改查。(以上类似数组)
4.列表元素可以由任意类型的数据构成。同一列表中各元素的类型可以各不相同。(不同于数组)
列表的操作汇总:
-
创建列表: [,]、list()
-
访问元素: list1[n]
-
更改元素值
-
切片: [::]形式
-
列表计算: 列表+列表,列表 * 整数
-
列表
方法-查:.index()、.count()、
-增:.extend()、.insert()、.append()、
-删:.pop()、.remove()、.clear()
-序:.sort()、.reverse()) -
序列
函数(不仅仅用于列表):len()、max()、min()、sorted()、reversed() -
命令:del 列表
1.列表的创建
# 创建 一维列表
list1 = [3.14, 1.61, 0, -9, 6,3.14] # 1.[,...,]方式: 普通列表
list2 = ['train', 'bus', 'car', 'ship']
list3 = ['a',200,'b',150, 'c',100.5]
list4 = [] # 2.[]方式:创建空列表
list5=list() # 3.list()函数
# 创建 二维列表
list_sample=[['IBM','Apple','Lenovo'],['America','America','China']]
2.列表的元素访问
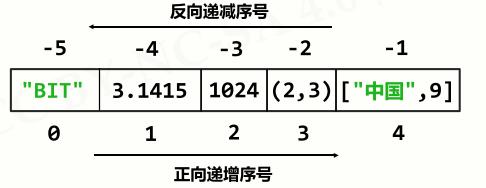
- 索引:列表中的每个元素被关联一个序号,即元素的位置。
- 索引值是从0开始,第二个则是 1,以此类推,从左向右逐渐变大;
- 列表也可以从后往前,索引值从-1开始,从右向左逐渐变小。
- 适用于所有序列类型的对象:列表、元组、字符串
3.修改元素
- 通过重新赋值来更改某个元素的值
- 注意合法索引范围,超过范围则会出错。
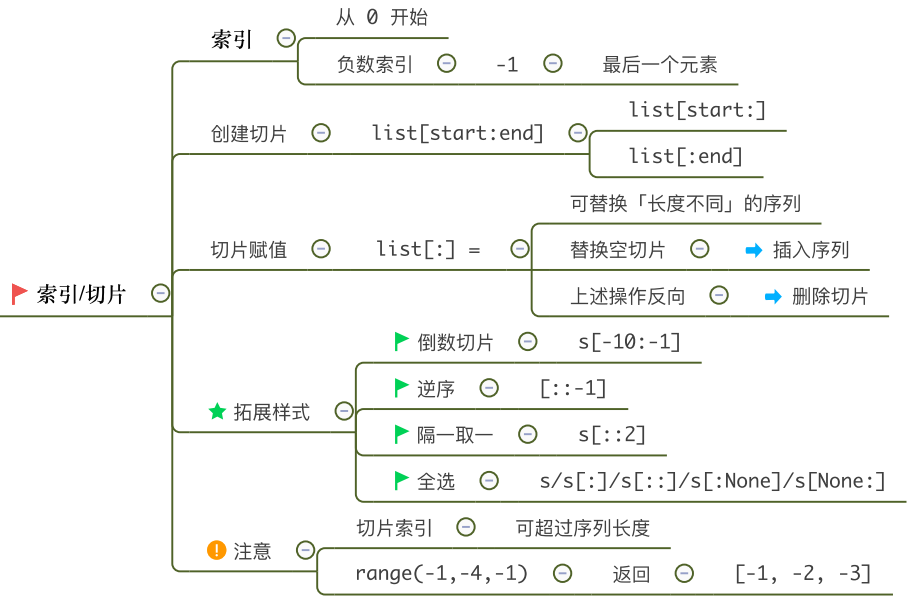
4.列表切片
-
在列表中,可以使用切片操作来选取指定位置上的元素组成新的列表。
-
简单的切片方式为(步长默认为1):原列表名[start : end]
- [start:end):左封闭(能取到),右开放(取不到)
- 左索引start为0时可缺省,右索引end为列表长度时可缺省。
vehicle = ['train', 'bus', 'car', 'ship']
vehicle[0:3]
vehicle[0:1] # 取第0号元素
vehicle[:3] # start缺省:为 0
vehicle[3:] # end缺省:为列表长度4(长度从1开始计算)
vehicle[:] # start、end都缺省:全列表
vehicle[3:3] # start等于end时:空列表
也可以使用负数作索引
vehicle = ['train','bus','car','ship']
vehicle[-3:-1] # 索引为-3和-2位置上的元素:依然是从左往右取 ['bus', 'car']
vehicle[-2:] # 索引从-2至列表末尾位置上的元素 ['car', 'ship']
切片步长:非零整数(即可正可负,但不能为0)(跳着切片)
原列表名[start : end : step]
- 步长为1时:参数可以省略。
- 步长不为1时:该参数不可省略。
n=list(range(10)) # range()函数为0-9的可迭代对象,用list()函数转换为从0到9的列表n
n[0:10:2] # 步长为2,索引值从0开始,每次增长2,但索引值必须小于10。 [0, 2, 4, 6, 8]
n[::3] # [0,3,6,9]
n[7:2:-1] # 步长为负数时,start不能小于end值。 [7, 6, 5, 4, 3]
n[11::-2] # 11超过范围,实际索引从最后一个元素开始。不出错。 [9, 7, 5, 3, 1]
n[::-2] # 这里步长为负数,表示在整个列表内,从后往前取值。 [9, 7, 5, 3, 1]
n[::-1] # 作用:逆序 [9, 8, 7, 6, 5, 4, 3, 2, 1, 0]
利用切片还可以更改元素值。有点类似多变量赋值的感觉。
n[2:4]=[110,1] # 分别更改索引号为2和3的位置上元素值。
n[-5::2]=[-1,-2,-3] # 分别更改索引号为-5、-3、-1三个位置上的元素值。
n[2:5]=[10,11] # 少给1个数呢?少的那个数,被删掉了
5. del命令
注意是命令,不是函数或方法。
从列表中删除元素,也可以删除整个列表
vehicle = ['train', 'bus', 'car', 'ship']
del vehicle[3]
vehicle # 删除了'ship'
del vehicle # 删除列表vehicle
vehicle # 列表vehicle不存在了:再次使用出错
补充:方法、函数、命令的概念上的区别
- 命令:内置命令,没有括号
- 函数:是指内置函数(或用import导入的某模块的函数),直接可以使用,比如pow(2,3)
- 方法:是指某个对象的方法,格式为对象名.方法名(),比如list.sort(),是指列表list对象的sort()方法
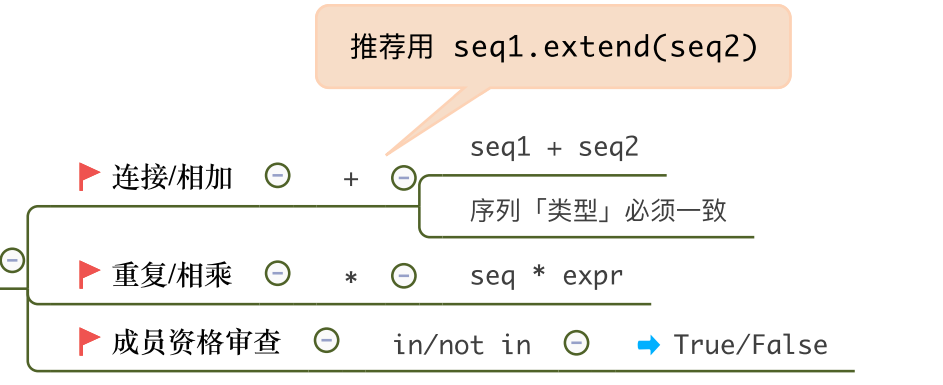
6.列表运算
1)列表相加
- 通过列表相加的方法生成新列表
- 支持 复合赋值 +=
vehicle1 = ['train', 'bus', 'car', 'ship']
vehicle2 = ['subway', 'bicycle']
vehicle2 + vehicle1 # 结果为新列表,原列表不变
vehicle+=['bike'] # 复合赋值语句
vehicle1-vehicle2 # 不支持 减 运算:出错
2)列表乘法
- 列表 * 整数n:生成一个新列表。
- 新列表:原来列表的元素重复n次。
vehicle1 = ['train', 'bus']
vehicle1 * 3 #['train', 'bus', 'train', 'bus', 'train', 'bus']
vehicle = vehicle1 * 2 # 相乘语句
vehicle *= 2 # 复合赋值语句,相当于重新定义了vehicle列表
7.列表方法:类型本身的方法
1) index(value[,start=0[,stop]])
- 返回
第一个value值元素索引位置。 - start没指定:则从索引为0的位置开始查找,否则从索引为strat的位置开始查找。
- stop没指定:可以查找到列表最后元素,否则在位于[start, stop)内的索引区间查找。
- 如果找不到匹配项,就会引发异常。
vehicle = ['train', 'bus', 'car', 'subway', 'ship', 'bicycle', 'car']
vehicle.index('car') # 整个列表范围内'car'第1次出现的索引位置是2
vehicle.index('car', 3) # 在从索引为3开始,'car'第1次出现的索引位置是
2) count()
- 统计某个元素在列表中出现的
次数。
3) append()
- 追加单个元素到列表的尾部,只接受**
一个**元素 - 元素可以是任何数据类型,被追加的元素在列表中保持着原结构类型。
4) extend()
- 在列表的末尾一次性追加另一个
列表中的多个值(只能有一个参数) - 应用:用新列表扩展原有的列表
- insert()
- 将一个元素插入到指定位置。
- 两个参数:第一个参数是索引点,即插入的位置,第二个参数是插入的元素。
vehicle = ['train', 'bus', 'car', 'ship']
vehicle.insert(3,'plane') # 插入后,在3位置
vehicle.insert(-2,'bike') # 注意插入后的位置,在-2位置的前面
6) remove()
- 用于移除列表中与某值匹配的
第一个元素 - 如果找不到匹配项,就会引发异常
7) pop()
- 移除列表中的一个元素(默认为
最后一个元素),并且返回该元素的值(出栈) - 可以指定索引位置
- 当不在索引范围内或者是空列表中,均会触发异常
8) clear()
- 删除列表中所有元素,但
保留列表对象。
请注意与del命令的区别:del命令删除整个列表时,列表对象不再保留
9) reverse()方法
- 用于将列表中的元素位置反向存放。
- 列表中可以有不同类型的元素,reverse()方法只是将位置反转
10) sort()
元素排序:默认按***升序***排列。
两个参数:
- reverse参数:默认为False(升序),若等于True表示降序排序(如果包含的是字符串,按字符串排序规则)。
- key参数:指定排序方式。
numbers=[12,34,3.14,99,-10]
numbers.sort() # 按数值大小升序
numbers.sort(reverse=True) # 降序
numbers.sort(key=str) # 按转换为字符串后的大小升序排列,ASCII码
nv=[12,'bus',99,'train'] # 排序的元素必须是可比较大小(字符串和数值不能比较)
nv.sort()
8.列表函数:不单单用于列表的函数,也可用于其他数据结构
9.列表遍历
- 通过for语句或者while语句循环遍历所有元素
vehicle=['train', 'bus', 'car', 'subway', 'ship', 'bicycle']
for i in vehicle: #1.直接遍历每一个元素
print(i,end=' ')
i=0
while i<len(vehicle): #3.while循环:通过索引遍历每一个元素
print(vehicle[i],end=' ')
i+=1
4.1.2元组
元组和列表十分相似,元组是用一对圆括号()括起、用逗号分隔的多个元素的组合。
- 属于序列:有顺序,可以重复;
- 元组是不可更改的,是不可变对象:元组创建之后就不能修改、添加、删除成员。
元组的上述特点使得其在处理数据时效率较高,而且可以防止出现误修改操作。
1.元组的创建
tuple1 = ('a',200,'b',150, 'c',100) # 1.创建多个元素的元组
tuple3 = (3,) #创建单一元素的元组,后面的逗号不能省略(省略后,就变成字符串类型了
tuple4=() # 2.创建空元组
tuple5 = tuple() # 3.使用tuple函数,创建空元组
2.元组的访问
和列表一样,可以通过索引(访问单个)、切片(访问多个)来访问元组的成员
vehicle=('train', 'bus', 'car', 'ship', 'subway', 'bicycle')
vehicle[-3] # 索引方式
vehicle[0:3:2] # 切片方式
vehicle[1]='bike' #元组:不能更改元素值。不能赋值。 报错
3.元组的运算
1)元组相加
通过元组相加的方法生成新元组
vehicle1 = ('train', 'bus', 'car', 'ship')
vehicle2 = ('subway', 'bicycle')
vehicle1 = vehicle1 + vehicle2 # 正确:重新定义了vehicle1
2)元组相乘
- 用数字n乘以一个元组,会生成一个新元组。
- 在新元组中原来的元组元素将依次被重复n次。
vehicle1 = ('train', 'bus', 'car', 'ship')
vehicle1*2
3).元组的遍历
通过for语句或者while语句(同列表方法)
4.1.3 列表与元组的转换
1.列表–>元组
- tuple()函数:接受一个列表,并返回一个包含同样元素的元组。
- 从结果上看,tuple()函数冻结了列表
vehicle = ['train', 'bus', 'car', 'ship', 'subway', 'bicycle'] #list
tuple(vehicle) #元组
t = tuple(vehicle)
2.元组–>列表
- list()函数:接受一个元组,并返回一个包含同样元素的列表。
- 从结果上看, list()函数融化了元组
vehicle=('train','bus','car','ship','subway','bicycle')
list1 = list(vehicle)
4.2 字典
字典是Python中唯一内建的映射类型
用一对花括号“{”和“}”作为边界,元素之间以逗号分隔:{123:“zhangsan”,456:“lisi”}
- 每个元素是一对键(key)和值(value),键和值之间用英文冒号分隔。
映射:可通过数据key查找关联数据value。无序:字典的元素没有顺序,因此不能像序列那样通过位置索引来查找成员数据。但是每一个值都有一个对应的键。不重复:字典的键是不重复的。
用法:通过键key来访问相应的值value(值value是可以重复的)。
4.2.1 创建字典
abbreviation ={'WAN':'Wide Area Network', 'CU':'Control Unit', 'LAN':'Local Area Network', 'GUI':'Graphical User Interface'} #1.{'':'','':''}创建
a=dict(WAN='Wide Area Network',CU='Control Unit',LAN='Local Area Network') #2.dict()创建,需注意:键外面不能加引号
keys=['WAN','CU','LAN'] #列表list
values=('Wide Area Network','Control Unit','Local Area Network') #元组
b=dict(zip(keys,values)) #3.由序列构建zip对象,由zip对象创建字典
c=dict.fromkeys(['WAN','CU','LAN']) #4.以给定序列(元组或者列表)为键,创建值为空的字典
d={} #5-1.创建空字典
e=dict() #5-2.无参的dict函数
- 键key必须是
不可修改类型的数据,如数值、字符串和元组等(列表是可变的,不能作为字典的键) - 键对应的值value可以是任何类型的数据。
- 字典是无序集合,字典的显示次序由字典在内部的存储结构决定。
4.2.2 字典操作
1.字典中“键-值”对的数量
len():返回字典中项(键-值对)的数量
abbreviation ={'WAN':'Wide Area Network', 'CU':'Control Unit', 'LAN':'Local Area Network', 'GUI':'Graphical User Interface'}
len(abbreviation)
2.查找与特定键相关联的值:键—>值
abbreviation ={'WAN':'Wide Area Network', 'CU':'Control Unit', 1:'Local Area Network', 'GUI':'Graphical User Interface'}
abbreviation[1]
3.修改字典中的数据
在字典中,某个键相关联的值可以通过赋值语句来修改.
如果指定的键不存在,则相当于向字典中添加新的键值对
abbreviation ={'WAN':'Wide Area Network', 'CU':'Control Unit', 'LAN':'Local Area Network', 'GUI':'Graphical User Interface'}
abbreviation['CU']='control unit' #有则修改
abbreviation['FTP']='File Transfer Protocol' #无则添加
4.删除字典条目
del 命令:用来删除字典条目或者整个字典
del abbreviation['CU'] #键存在
del abbreviation #删除整个
in命令:查找某键值是否在字典中。如果存在返回“True”,否则返回“False”
4.2.3 字典方法
1.keys()、values()
keys()方法将字典中的键以可迭代的dict_keys对象返回。values()方法将字典中的值以可迭代的dict_values对象形式返回
abbreviation ={'WAN':'Wide Area Network', 'CU':'Control Unit', 'LAN':'Local Area Network', 'GUI':'Graphical User Interface'}
abbreviation.keys()
#dict_keys(['WAN', 'CU', 'LAN', 'GUI'])
list(abbreviation.values()) #转换成 列表
tuple(abbreviation.values()) #转换成 元组
2.items()
将字典中的所有键和值以可迭代的dict_items对象返回,每对键值对组成元组作为一个元素
abbreviation ={'WAN':'Wide Area Network', 'CU':'Control Unit', 'LAN':'Local Area Network', 'GUI':'Graphical User Interface'}
abbreviation.items()
#dict_items([('WAN', 'Wide Area Network'), ('CU', 'Control Unit'), ('LAN', 'Local Area Network'), ('GUI', 'Graphical User Interface')])
list(abbreviation.items()) #转换成 列表
tuple(abbreviation.items()) #转换成 元组
3.setdefault()
使用dict.setdefault(key, default=None)时,
- 如果字典中包含参数key对应的键,则返回该键对应的值;
- 否则以参数key的值为键,以参数default的值为该键对应的值,在字典中插入键-值对元素,并返回该元素的值部
abbreviation ={'WAN':'Wide Area Network', 'CU':'Control Unit', 'LAN':'Local Area Network', 'GUI':'Graphical User Interface'}
abbreviation.setdefault('CU') #1.存在这个键:返回对应的值value
abbreviation.setdefault('CU',"控制单元") #2.存在这个键,默认值和原有的值不一样:返回对应的原值value
abbreviation['CU']='control unit' #有则修改
abbreviation.setdefault('FTP','File Transfer Protocol') #3.不存在这个键:插入新的键值对
abbreviation['FTP']='File Transfer Protocol' #和之前比较:无则添加
abbreviation.setdefault('cu') #4.不存在这个键,也未指定新值 'cu': None
4.update()
将另一个字典中的所有键值对一次性地添加到当前字典中
如果两个字典中存在有相同的键,则以另一个字典中的值更新当前字典
5.clear()
clear()方法将字典中的所有条目删除,变成空字典
6.pop()
pop()方法能够弹出并删除字典中的键值对
abbreviation.pop('CU') #返回键为'CU'的值,并在字典中删除该键值对
7.popitem()
popitem()方法能够弹出字典的一个元素,如果字典为空则触发异常
8.get()
返回指定键所对应的值,如果键不存在则返回默认值。默认值为None,也可以自己指定。
4.2.4遍历字典
1.遍历字典的key
for i in abbreviation: #默认遍历字典的键
print(i)
print(i,abbreviation[i])
for i in abbreviation.keys(): #和上面相同
print(i,abbreviation[i])
2.遍历字典的值Value
for i in abbreviation.values():
print(i)
3.遍历字典的键值对
for i in abbreviation.items(): #keys() values() items()
print(i)
4.2.5列表、元组、字典的转换
1.列表与字典之间的转化:字典–>列表
Python中的list()函数可以将字典转换列表,但列表不能转换为字典
list(abbreviation) #默认将键转化为列表
list(abbreviation.keys()) #键
list(abbreviation.values()) #值
list(abbreviation.items()) #键值对
2.元组与字典之间的转化:字典–>元组
Python中的tuple()函数可以将字典转换元组,但元组不能转换为字典
tuple(abbreviation) #默认将键转化为元组
tuple(abbreviation.keys()) #键
tuple(abbreviation.values()) #值
tuple(abbreviation.items()) #键值对
4.3 集合 Set
集合是一组用{ }括起来的无序,不重复元素,元素之间用逗号分隔。
元素可以是各种类型的不可变对象。
集合,想象成 只有key 没有value值的字典dict
4.3.1 集合的创建
集合类型的值有两种创建方式:
- 用一对花括号将多个元素括起来,元素之间用逗号分隔:{1,3,‘a’}
- 函数set():将字符串、列表、元组等类型的数据转换为集合类型。
vehicle={'train','bus','car','ship'} # 1、直接赋值
vehicle=set(['train','bus','car','ship']) # 2、Set()函数,list() tuple() dict()
#注意:空集合只能用set()来创建,而不能用空的花括号{}表示,因为Python已将空{}用于表示空字典
a=set() # 无参的set函数,空集合
集合中没有相同的元素,因此创建集合时会自动删除掉重复的元素(利用这一点,可以快速去重)。
4.3.2 集合的运算
1.len() 、max()、min()、sum()
返回集合中元素的个数
nums = {4,3,8,9,0,-5,7}
max(nums)
sum(nums)
sorted(nums) # 生成排序后的列表:集合本身无序
reversed(nums) # 不能反序:集合本身无序
2.in
判断某元素是否存在于集合之中,判断结果用布尔值True或False表示
3.并集、交集
并集:创建一个新的集合,该集合包含两个集合中的所有元素。
交集:创建一个新的集合,该集合为两个集合中的公共部分
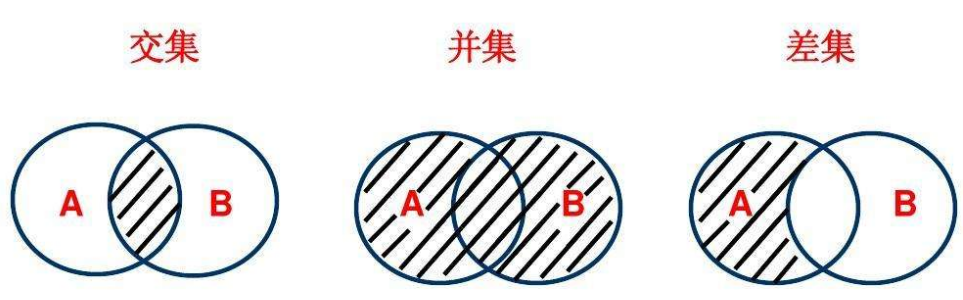
vehicle1={'train','bus','car','ship'}
vehicle2={'subway','bicycle','bus'}
vehicle1|vehicle2 #并集
vehicle1&vehicle2 #交集
4.差集
A-B表示集合A与B的差集,返回由出现在集合A中但不出现在集合B中的元素所构成的集合。
vehicle1-vehicle2
5.对称差
返回由两个集合中那些不重叠的元素所构成的集合
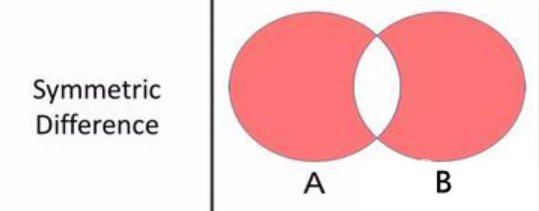
vehicle1^vehicle2
6.子集和超集
- 子集:如果集合A的每个元素都是集合B中的元素,则集合A是集合B的子集。
超集:超集是仅当集合A是集合B的一个子集,集合B才是集合A的一个超集。
- A<=B,检测A是否是B的子集;
- A<B,检测A是否是B的真子集;
- A>=B,检测A是否是B的超集;
- A>B,检测A是否是B的真超集;
- 以上结果只返回True或False
- A |= B将B的元素并入A中。
4.3.3 集合的方法
同样以面向对象方式实现集合类型的运算
1.union()、intersection()
- union()方法相当于并集运算。
- intersection()方法相当于交集运算
vehicle1={'train','bus','car','ship'}
vehicle2={'subway','bicycle','bus'}
vehicle1.union(vehicle2) #并集,新的集合
vehicle1 # vehicle1未发生改变
vehicle2 # vehicle2未发生改变
vehicle1.intersection(vehicle2) #交集,产生新集合
2.update()
update()方法相当于集合元素合并运算,注意与union()方法的区别
vehicle1.update(vehicle2)
vehicle1 # vehicle1发生了改变
3.difference()
相当于差集运算
vehicle1.difference(vehicle2) #新集合
vehicle1 #原集合没有变化
4.symmetric_difference()
相当于对称差运算
vehicle1.symmetric_difference(vehicle2) #结果相同
vehicle2.symmetric_difference(vehicle1)
5.issubset()和issuperset()
- issubset()方法:判断是否子集。<=
- issuperset()方法:判断是否超集>=
vehicle2.issubset(vehicle1)
vehicle1.issuperset(vehicle2)
6.add()
是向集合中添加元素
vehicle1.add('ship') #重复元素,只保留一个
7.remove()
是从集合中删除元素,如果集合中没有该元素,则出错
8.discard()
作用是从集合中删除元素,如果集合中没有该元素,也不提示出错
9.pop()
pop()方法的作用是从集合中删除任一元素,并返回该元素;
如果集合为空,则抛出KeyError异常。
10.clear()
从集合中删除所有元素,变成一个空集合
4.4 可迭代对象Iterable 与 迭代器Iterator
简单解释:
可迭代对象 是 存放元素的容器,可以被遍历其中的元素。(类比:链表)
迭代器 由可迭代对象(容器)提供的(因为只有该容器知道怎么遍历它的每一个元素),用于遍历容器元素的一个工具。(类比:链表的遍历指针p)
4.4.1 可迭代(Iterable)对象
列表、元组、字符串、字典可以用 for…in…进行遍历。
表面:只要可以用 for…in…进行遍历的对象就是可迭代对象,那么列表、元组、字符串、字典都是可迭代对象。
本质:如果一个对象实现了__iter__()方法,那么这个对象就是可迭代(Iterable)对象
help(list) #方法1:查看list对象的方法,是否有__iter__方法(类似于java中查看某一个类可实现的方法)
方法2:可以通过调用内置函数isinstance()来判断一个对象是否属于可迭代(Iterable)对象
from collections.abc import Iterable
isinstance(['abc',1,8.5],Iterable) #1.列表list是可迭代对象吗?
isinstance(123,Iterable) #7.数值int float 是可迭代对象吗?不是
迭代器(Iterator):实现了__iter__方法和__next__方法,并且可以通过__next__方法不断返回下一个值的对象
迭代器(Iterator)还可以通过内置函数next()访问下一个元素。
可以通过调用Python内置函数isinstance()来判断一个对象是否属于迭代器(Iterator)
from collections.abc import Iterator
isinstance([],Iterator) #列表list 是迭代器吗?
isinstance([],Iterator) #列表list 是迭代器吗?
isinstance({1:'one',2:'two'},Iterator) #字典dict 是迭代器吗?
isinstance({'one','two'},Iterator) #集合set 是迭代器吗?
isinstance('abcdefg',Iterator) #字符串str 是迭代器吗?
isinstance(range(10),Iterator) #range函数生成的数列 是迭代器吗?
isinstance(123,Iterator) #数值 是迭代器吗?
#以上对象均不能成为迭代器(注意迭代器和可迭代对象不同)
可迭代对象(容器)—> 迭代器(迭代工具)
- 虽然列表、元组、字符串、字典、集合都是可迭代(Iterable)对象而不是迭代器(Iterator),但可以通过iter()函数获得一个迭代器(Iterator)
from collections.abc import Iterator
vehicle=['train','bus','car','ship'] #列表 list
v=iter(vehicle) #取list的迭代器
v.__next__() #1、自带方法__next__():返回下一个值
next(v) #2、也可以用内置函数next()函数
v.__next__() #没有下一个元素了,触发StopIteration异常
next(v) #内置函数:next()访问下一个值(同样异常)
4.4.2 相关内置函数
- enumerate()枚举
- zip() 组合
- map() 映射(逐个计算)
- filter()过滤(挑选)
共同点:这四个函数都会返回一个 特定对象,它们都既是迭代器、也是可迭代对象。
1.enumerate() 枚举
- 格式:enumerate(iterable, start=0)
- 功能:返回下标和值的enumerate对象。
- 参数:第1个参数表示可迭代(Iterable)对象,第2个参数表示下标的开始值,默认从0开始。
通俗:将容器的每个元素取出来,搭配一个下标
enumerate对象:既是Iterable对象(容器),也是Iterator对象(容器的遍历工具)
vehicle=['train','bus','car','ship'] #列表list(用其他容器也可以)
vv1=enumerate(vehicle) #取得list的枚举器
for i in vv1: #迭代器 可以使用for in语句
print(i," ")
#(0, 'train')
#(1, 'bus')
#(2, 'car')
#(3, 'ship')
next(vv1) #也可以使用next()函数
vv1.__next__() #也可以使用 __next__()方法
list(vv1) # 将剩余的enumerate对象vv1元素转换为列表
tuple(vv2) #enumerate对象vv2转换为元组
vv2=enumerate(vehicle,1) #下标从1开始
vv2.__next__() #返回下一个值
for i in enumerate(vehicle): #遍历enumerate对象中的元素
print(i,end=' ') #(0, 'train') (1, 'bus') (2, 'car') (3, 'ship')
for i,x in enumerate(vehicle):
print(i,x,end=' ') #遍历enumerate对象元素的下标和值 0 train 1 bus 2 car 3 ship
vv1=enumerate(vehicle)
dict(vv1) #enumerate对象vv1转换为字典:枚举号转为key,枚举值转为value
#{0: 'train', 1: 'bus', 2: 'car', 3: 'ship'}
vv1=enumerate(vehicle)
set(vv1) #enumerate对象vv1转换为集合
2.zip()
- 格式:zip(iter1 [,iter2 […]])
- 功能:将多个迭代器(Iterator)对象(或者可迭代(Iterable)对象)中的元素压缩到一起,返回一个zip对象。
通俗:将多个容器的逐个对应元素拼合在一起
同样,zip对象既是一个可迭代(Iterable)对象,也是一个迭代器(Iterator)对象。
vv1=zip('abcd') #1、只有一个参数:字符串(容器),每个元素是元组
list(vv1) #[('b',), ('c',), ('d',)]
vv3 = zip('abcd',vehicle) #2、有两个参数:有两个容器作为参数
list(vv3) #[('c', 'car'), ('d', 'ship')]
('b', 'bus') in zip('abcd',vehicle) #zip对象是可迭代对象(容器),可以使用in运算
vv2=zip('abcd',enumerate(vehicle)) #第二个参数是 枚举(也是容器)
next(vv2) #('a', (0, 'train'))
vv3=zip(range(2),vehicle) #不同长短时:匹配短的
list(vv3)
vv4=zip('abcd',range(4),vehicle) #3、更多参数:更多容器
next(vv4) #('a', 0, 'train')
3.map()
- 格式:map(func, *iterables)
- 功能:把一个函数func依次映射到可迭代(Iterable)对象的每个元素上,返回一个map对象。
通俗:将每个元素 传入 func函数,把结果放入map里
map对象:既是一个可迭代(Iterable)对象,也是一个迭代器(Iterator)对象
aa=['1','5.6','7.8','9']
bb1=map(float,aa) #将每个元素变为float类型
next(bb1) #1.0
list(map(str,range(5))) #将0-4改为字符串
#['0', '1', '2', '3', '4']
def fun(x): # 2、定义一个 函数
return x**2
list(map(fun,[1,2,3,4])) #list中的每个元素,都执行一次fun函数,结果放入map
#[1, 4, 9, 16]
4.filter()
- 格式:filter(函数名 or None, 可迭代对象)
- 功能:把一个带有一个参数的函数function作用到一个可迭代(Iterable)对象上,返回一个filter对象。
- filter对象中的元素由可迭代(Iterable)对象中使得函数function返回值为True的那些元素组成。
- 如果指定函数为None,则返回可迭代(Iterable)对象中等价于True的元素。
通俗:将容器中的元素用函数过滤(挑选)一下
filter对象:既是一个可迭代(Iterable)对象,也是一个迭代器(Iterator)对象。
只保留满足条件的元素
aa=[5,6,-9,-56,-309,206] #用法1:函数
def func(x): #定义函数func,x为奇数返回True,否则返回False
return x%2!=0
bb=filter(func,aa) #将aa中的每个元素,作为参数,带入func(x)。将返回值为True的元素保留下来。
type(bb) #bb是一个filter对象
next(bb) #5
cc=filter(lambda x:x%2!=0,aa) #用法2:lambda函数(匿名函数,不用单独定义函数了)
dd=[6,True,1,0,False]
ee=filter(None,dd) #用法4:指定函数为None(函数就不起作用了。就看元素本身,是否为True)
4.5 推导式
- 利用列表推导式、字典推导式、集合推导式可以从一个数据对象构建另一个新的数据对象。
- 利用生成器推导式可以构建生成器对象。
- 语法糖
4.5.1 列表推导式
列表推导式(list comprehension)是Python开发时用得最多的技术之一,表示对可迭代(Iterable)对象的元素进行遍历、过滤或再次计算,生成满足条件的新列表。
它的结构是在一个方括号里包含一个函数或表达式(再次计算),接着是一个for语句(遍历),然后是0个或多个for(遍历)或者if语句(过滤),在逻辑上等价于循环语句,但是形式上更简洁。
语法形式:
[函数 / 表达式
for 值1 in 可迭代对象1 if 条件1
for 值2 in 可迭代对象2 if 条件2
……
for 值n in 可迭代对象n if 条件n ]
1.列表推导式和循环语句for
如果要将一个列表中的元素均扩大2倍组成新列表:
n=[10,-33,21,5,-7,-9,3,28,-16,37] #列表推导式:
number=[i*2 for i in n]
number
两点:
- 利用列表推导式更加简洁。
- 由于Python内部对列表推导式做了大量优化,还能保证较快的运行速度
for循环可以嵌套。列表推导式中也可以有多个for语句。
如果要将一个一层嵌套数字列表中的元素展开后扩大2倍组成新列表:
n=[[10,-33,21],[5,-7,-9,3,28,-16,37]] #一层嵌套列表
number=[] #常规写法:
for i in n: #每一行
for j in i: #行中的每一列
number.append(j*2)
number
n=[[10,-33,21],[5,-7,-9,3,28,-16,37]] #列表推导式:
number=[j*2 for i in n for j in i]
number
2.列表推导式和条件语句if
在列表推导式中,条件语句if对可迭代(Iterable)对象中的元素进行筛选,起到过滤的作用。
#接着上面的例子,如果是将一个数字列表中的是正数的元素扩大2倍组成新列表:
n=[10,-33,21,5,-7,-9,3,28,-16,37]
number=[i*2 for i in n if i>0]
number
另外,在列表推导式中还可以使用if else语句。
#将一个数字列表中的正偶数扩大2倍、正奇数扩大3倍组成新列表
n=[10,-33,21,5,-7,-9,3,28,-16,37]
number=[i*2 if i%2==0 else i*3 for i in n if i>0]
number
3.列表推导式和函数function
在列表推导式中可以使用函数function。
#利用列表推导式快速生成包含15个30~80(包含30、80)之间的随机整数列表rlist。
import random
rlist=[random.randint(30,80) for i in range(15)] #使用randint()函数
rlist
# 对rlist中的元素,如果被3整除则该数除以3,如果被7整除则该数扩大2倍,其他的数扩大5倍,这些数组成新列表number
def ff(x):
if x%3==0:
x/=3
elif x%7==0:
x*=2
else:
x*=5
return x
number=[ff(i) for i in rlist] #使用自定义的ff()函数
number
4.同时遍历多个列表或可迭代对象
#有两个成绩列表score1和score2,将score1中分数90及以上和score2中分数85及以下的元素两两分别组成元组,将这些元组组成列表nn中的元素
score1=[86,78,98,90,47,80,90]
score2=[87,78,89,92,90,47,85]
nn=[(i,j) for i in score1 if i>=90 for j in score2 if j<=85]
nn
4.5.2 字典推导式
字典推导式和列表推导式的使用方法类似
- 将方括号变成花括号
- 需要两个表达式,一个生成键,一个生成值,两个表达式之间使用冒号分隔
- 最后生成的是字典
语法形式:
{函数 / 表达式
for 值1 in 可迭代对象1 if 条件1
for 值2 in 可迭代对象2 if 条件2
……
for 值n in 可迭代对象n if 条件n }
# 列表name存储若干人的名字(唯一),列表score在对应的位置上存储这些人的成绩,利用字典推导式,以名字为键、成绩为值组成新字典dd。
name= ['Bob','Tom','Alice','Jerry','Wendy','Smith']
score=[86,78,98,90,47,80]
dd={i:j for i,j in zip(name,score)}
# 以名字为键、成绩为值组成新字典exdd,新字典中的键值对只包含成绩80及以上的
exdd={i:j for i,j in zip(name,score) if j>=80} #增加一个if
# 以名字为键、名字的长度为值组成新字典nd
nd={i:len(i) for i in name}
4.5.3 集合推导式
集合也有自己的推导式,跟列表推导式类似
- 只不过将方括号变成花括号
- 最后生成的是集合
语法形式:
{函数 / 表达式
for 值1 in 可迭代对象1 if 条件1
for 值2 in 可迭代对象2 if 条件2
……
for 值n in 可迭代对象n if 条件n }
alist=[i*2 for i in (1,2,3,3,2,1,4)]
bset={i*2 for i in (1,2,3,3,2,1,4)}
不难发现,构建alist和bset的时候,除了方括号和花括号不同以外其他语法均相同,alist生成一个列表,里面的元素是元组(1,2,3,3,2,1,4)中每个元素的2倍,而且元素位置一一对应;blist生成一个集合,里面的元素是元组(1,2,3,3,2,1,4)中每个元素的2倍去掉重复元素后的结果,并且并非与元组的元素位置一一对应。
需要说明的是:元组没有推导式
4.5.4 生成器推导式
生成器推导式用法与列表推导式类似,把列表推导式的方括号改成圆括号。它与列表推导式最大的区别是:生成器推导式的结果是一个生成器对象,是一种迭代器(Iterator);而列表推导式的结果是一个列表。
生成器对象可以通过for循环或者next()方法、next()函数进行遍历,也可以转换为列表或元组,但是不支持使用下标访问元素,已经访问过的元素也不支持再次访问。当所有元素访问结束之后,如果想再次访问就必须重新创建该生成器对象。
gen=(int(i/3) for i in range(1,10) if i%3==0)
gen #<generator object <genexpr> at 0x00000110CC45C970>
list(gen) #生成器对象转换为列表
gen.__next__() #不能再次访问
next(gen) #访问下一个元素
gen=(int(i/3) for i in range(1,10) if i%3==0)
for i in gen: #for循环遍历
print(i,end=' ')
五、字符串
5.1 字符串的编码
-
ASCII码
标准ASCII码为7位编码,包括英文字母、数字、标点符号等128个字符。用1个字节存储,最高位为0.
扩展ASCII码:1个字节存储,最高位为1。 -
Unicode编码
.把所有语言统一到一套编码里
.采用2个字节或4个字节(生僻字符)的编码
.缺点:全部是英文的话,比ASCII码多用一倍存储空间 -
UTF-8编码
可变长编码,英文字符用1个字节(兼容ASCII码),中文字符用3个字节,其他语言也有用2或4个字节
-
GB2312、GBK等中文编码
一般用2个字节
Python3支持两种类型字符串:str类型(支持Unicode编码)和bytes类型,而且str类型和bytes类型可以相互转换。
- str.encode()可以转换为bytes类型
- bytes.decode()转换为str类型
- 除此之外,其他方法都一样
s='我' #str类型
#编码(str-->bytes)
s1=s.encode('gbk') #编码成bytes类型,gbk编码格式
s1 #b'\xce\xd2',16进制,2个字节(1位16进制数,用4位2进制数表示)
s2=s.encode('utf-8') #编码成bytes类型,utf-8编码格式
s2 #b'\xe6\x88\x91',16进制,3个字节
#解码(bytes-->str)
s3=s1.decode('gbk') #s1目前是gbk编码的bytes字符串,使用gbk进行解码
s4=s2.decode('utf-8') #s2目前是utf-8编码的bytes字符串,使用utf-8进行解码
s5=s.encode('ascii') #s('我')是str类型字符串,中文字符串不能以ascii编码
'ABC'.encode('ascii') #英文字符串可以以ascii编码
也可以使用bytes(string, encoding) 和str(bytes_or_buffer[, encoding])完成两种类型的相互转换
s='阳光'
b=bytes(s,encoding='gbk') #str-->bytes,用gbk编码转换
u=bytes(s,encoding='utf-8') #用utf-8编码转换,3个字节
bs=str(b,encoding='gbk') #bytes-->str,用gbk编码转换
us=str(u,encoding='utf-8')#str类型
ub = str(u,encoding='gbk') #u是用utf-8转换来的,'阳光',3个字节
ub #结果有误
Python3.x完全支持中文字符,解析器默认采用UTF-8解析源程序,
无论是数字字符、英文字母、汉字都按 一个 字符来对待和处理
5.2 字符串的构建
在Python中字符串的构建,主要通过两种方法来实现,一是使用str函数,二是用单引号、双引号或三引号
1.单引号或双引号构造字符串 :要求引号成对出现
- 合法:如:‘Python World!’、‘ABC’、“what is your name?”
- 不合法:'string"
2.字符串本身有 单引号或双引号时:
字符串包含了 单引号,且不用转义字符:整个字符串就要用 双引号 来构造。
字符串包含了 双引号,且不用转义字符:整个字符串要用 单引号 来构造。
print("Let's go!") #字符串本身有单引号
'"Hello world!",he said.' #字符串本身有双引号
print('"Hello world!",he said.') #print函数输出时,是没有外层的引号的
3.对引号转义
'Let\'s go!'
print('Let\'s go!')
"\"Hello world!\"he said"
print("\"Hello world!\"he said")
4.对其他字符转义
转义字符以“\”开头,后接某些特定的字符或数字
| 转义字符 | 含义 | 转义字符 | 含义 | 转义字符 | 含义 |
|---|---|---|---|---|---|
| \(行尾) | 续行符 | \n | 换行符 | \f | 换页符 |
| \ | 一个反斜杠 | \r | 回车 | \ooo | 3位8进制数ooo对应的字符,如\123 |
| ’ | 单引号’ | \t | 横向(水平)制表符 | \xhh | 2位16进制数hh对应的字符,如\x6a |
| " | 双引号" | \v | 纵向(垂直)制表符 | \uhhhh | 4位16进制数hhhh表示的Unicode字符 |
print("你好\n再见!") #\n表示换行,相当于敲了一个回车键
print('\123\x6a') #8进制数123对应的字符是“S”,16进制数6a对应的字符“j sj
5.原始字符串
假设在C:\test文件夹中有一个文件夹net,如何输出完整路径呢?可能你想到的是
print("c:\test\net") #错误
第1种方法:使用“\”表示反斜杠,则t和n不再形成\t和\n
print("c:\\test\\net")
第2种方法:在原始字符串前加 r 前缀
在字符串前面加上字母 r 或 R 表示原始字符串,所有的字符都是原始的本义而不会进行任何转义。
print(r"c:\test\net")
6.三重引号字符串
三重引号将保留所有字符串的格式信息。
- 如字符串跨越多行,行与行之间的回车符、引号、制表符或者其他任何信息,都将保存下来。
- 在三重引号中可以自由的使用单引号和双引号。
'''"What's your name?"
"My name is Jone"'''
#'"What\'s your name?"\n "My name is Jone"'
print('''"What's your name?"
"My name is Jone"''')
"What's your name?"
"My name is Jone"
5.3 字符串格式化
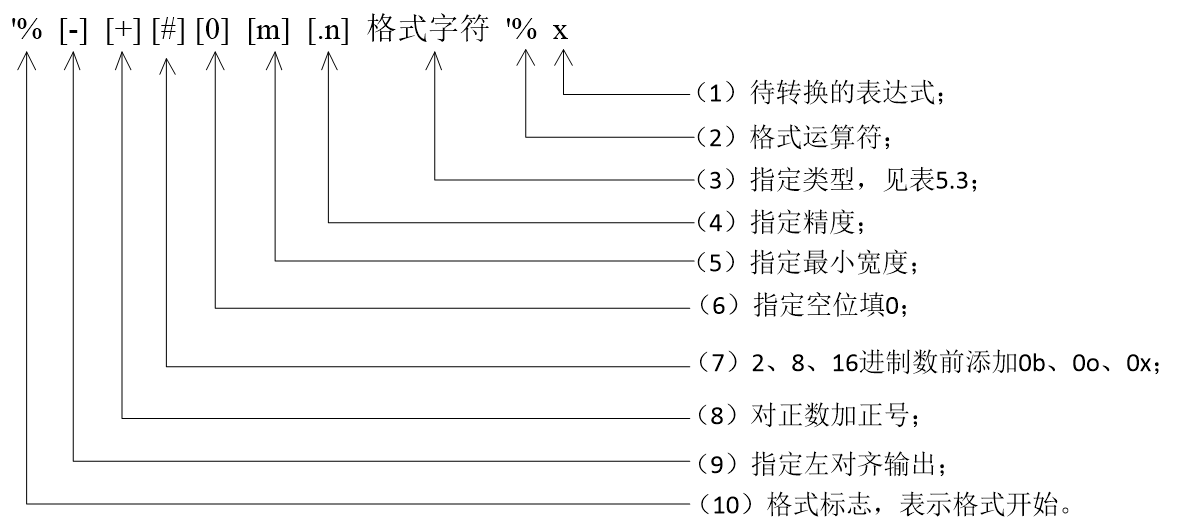
5.3.1 用 % 符号格式化字符串
格式以%开头格式化运算符用%表示用对象代替格式串中的格式,最终得到1个字符串- 基本同
C语言
1.字符串格式的书写
- [ ]中的内容可以省略;
- 简单的格式是:% 加格式字符,如%f、%d、%c等;
- 当最小宽度及精度都出现时,它们之间不能有空格,格式字符和其他选项之间也不能有空格,如%8.2f。
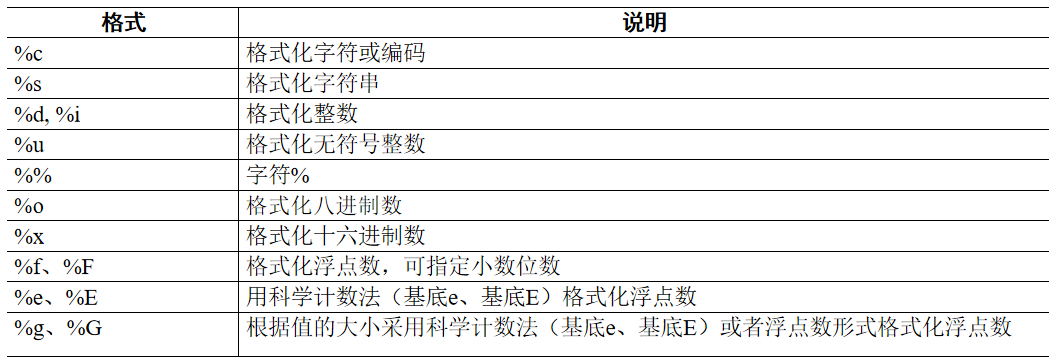
2.常用格式字符的含义(基本同C语言)
3.最小宽度和精度
最小宽度:转换后的值所保留的最小字符个数。
精度(对于数字来说):结果中应该包含的小数位数。
#浮点数
a=3.1416
'a=%6.2f'%a #总宽度为6,保留2位小数,四舍五入 'a= 3.14'
'%f'%3.1416 #单独的%f,默认保留6位小数 '3.141600'
'%.2f'%3.1416 #保留2位小数,第2位四舍五入,3.14
'%.2f'%3.1476 #四舍五入为3.15
'%7.2f'%3.1416 #宽度7位,保留2位小数,空位填空格 ' 3.14'
'%07.2f'%3.1416 #宽度7位,保留2位小数,空位填0 '0003.14'
'%7.2f'%1234567.8901 #实际宽度,允许超出最小宽度 '1234567.89'
'%+07.2f'%3.1416 #宽度7位,保留2位小数,正数加正号,空位填0 '+003.14'
'%-7.2f'%-3.1416 #宽度7位,保留2位小数,空位填空格,左对齐输出 '-3.14 '
"%-2d"%156 #左对齐
"%-2d"%5 #左对齐,右补空格
'%d'%'5' #字符串'5'用格式化整数%d输出,引发异常(类型必须一致)
'%s'%5 #与str()等价
#多对象:%后用元组
'%.2f,%4d,%s'%(3.456727,89,'Lily') #常量-->元组
'3.46, 89,Lily'
name='Lily'
age=18
'我叫%s,今年%d岁'%(name,age) #变量-->元组 '我叫Lily,今年18岁'
4.进位制和科学计数法
a=123456
y='%o'%a #转换为八进制串
z='%x'%a #转换为十六进制串
za='%0x'%a #16进制数前添加0x
se='%e'%a #转换为科学计数法串,基底e
se #小数点前有一位非零数字,小数点后是6位小数
'%e'%12345.678 #科学计数法,基底e '1.234568e+04'
'%E'%12345.678 #科学计数法,基底E '1.234568E+04'
'%g'%12345.678 #采用浮点数形式,根据值的大小采用%e或%f
'%G'%12345.678 #采用浮点数形式
'%.4G'%12345.678 #采用科学计数法形式,基底E
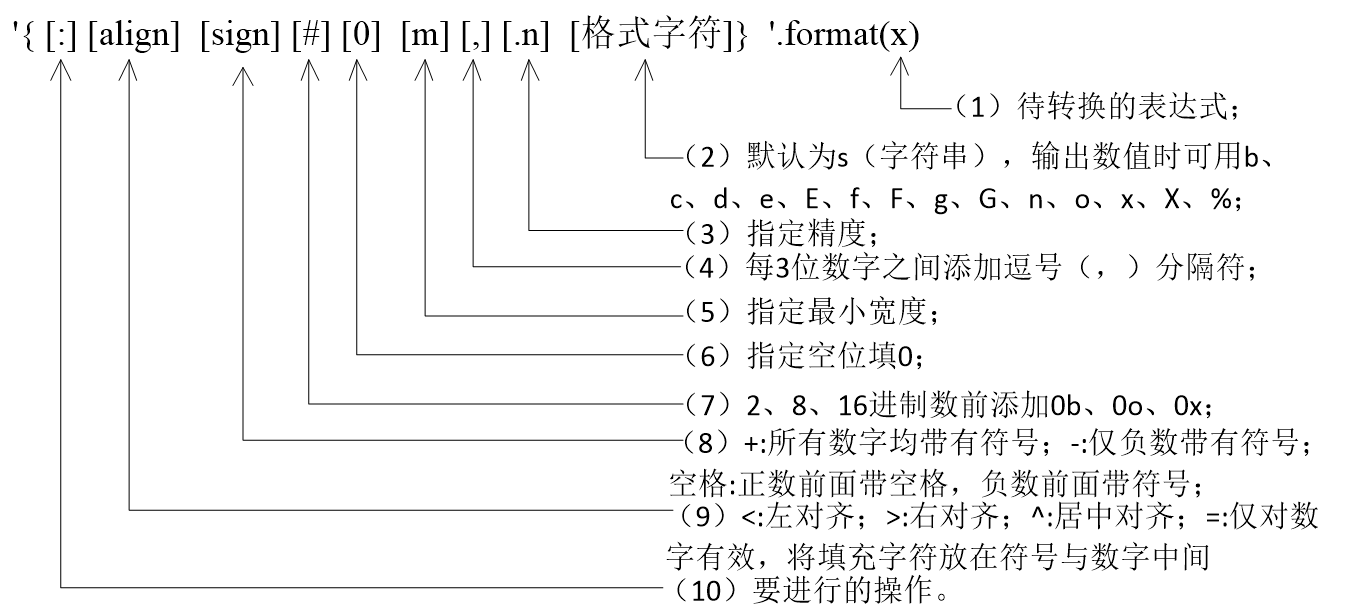
5.3.2 format()方法格式化字符串
format()方法是通过{}和:来代替传统%方式
首先看{}和参数的对应关系
'我叫{},今年{}岁'.format('张清',18) #以下输出均为'我叫张清,今年18岁'
'我叫{0},今年{1}岁'.format('张清',18)
'我叫{1},今年{0}岁'.format(18,'张清')
my=['张清',18]
'我叫{},今年{}岁'.format(*my) #列表前加*,自动解包
'我叫{0[0]},今年{0[1]}岁'.format(my) #列表不加*,则需要用列表的索引元素
#{后的0表示第一个参数(若有第2个参数,则为1),[]中的数字表示列表元素的索引
'我叫{name},今年{age}岁'.format(name='张清',age=18) #直接写变量名
'我叫{name},今年{age}岁'.format(age=18,name='张清') #有了名字之后,就可以任意顺序
my={'name':'张清','age':18}
'我叫{name},今年{age}岁'.format(**my) #字典前加**,自动解包
'{0:.2f}'.format(2/3) #十进制的0.67
'{0:b}'.format(8) #二进制
'{0:o}'.format(8) #八进制
'{0:x}'.format(18) #十六进制
'{:,}'.format(1234567890) #千分位格式化,1,234,567,890
'{0:*>10}'.format(18) #右对齐 '********18'
'{0:*<10}'.format(18) #左对齐 '18********'
'{0:*^9}'.format(18) #居中对齐 '***18****'
'{0:0=10}'.format(-18) #0放在-和18中间 '-000000018'
'{0:_},{0:#x}'.format(9999) #_作为分隔符(起到千分位的作用) '9_999,0x270f'
5.3.3 带f前缀的格式化字符串
name='张清'
age=18
f'我叫{name},今年{age}岁'
5.4 字符串截取
字符串 属于 序列 类型,同样,可以使用索引或者切片。
单个字符
- 索引str[index]取出单个字符
切片字符
- str[start : end : step]取出一片字符。同序列的切片。
s="student"
s[1:3] #取出位置为1到位置为2的字符,不包括位置3的字符 'tu'
s[:3] #取出从头至位置为2的字符 'stu'
s[-2:] #取出从倒数第2个位置开始的所有字符,从左往右取(步长默认是1) 'nt'
s[:] #正序全部字符
s[::-1] #逆序全部字符
s[::2] #步长为2
字符串属于不可变序列类型,不支持字符串修改
5.5 字符串常用内置函数
s='Merry days will come,believe.'
len(s) #字符串长度
max(s) #最大字符
min(s) #最小字符:本处为空格
ord('M') #获取该字符的Unicode码 77
chr(77) #把编码转换为对应的字符 'M'
ord('好') #汉字的编码
chr(22909)
5.6字符串常用方法
由于字符串属于不可变序列,下述方法中涉及到返回字符串的都是新字符串,原有字符串对象不变。
1.center()、ljust()、rjust()
格式:
- center(width, fillchar=’ ') 居中对齐
- ljust(width, fillchar=’ ') 左对齐
- rjust(width, fillchar=’ ') 右对齐
说明:
- width:指定宽度;
- fillchar:填充的字符,默认为空格。
功能:
- 返回一个宽度为width的新字符串,原字符串居中(左对齐或右对齐)出现在新字符串中,如果width大于字符串长度,则使用fillchar进行填充。
'你好'.center(10) #居中对齐,以空格填充 ' 你好 '
'你好'.center(11,"*") #居中对齐,以*填充 '*****你好****'
'你好'.ljust(10,"!") #右对齐,以!填充 '你好!!!!!!!!'
'你好'.rjust(10,"-") #左对齐,以-填充 '--------你好'
2.lower()、upper()
- lower()方法将大写字母转换为小写字母,其他字符不变,并返回新字符串(全部为小写字母)。
- upper()方法将小写字母转换为大写字母,其他字符不变,并返回新字符串(全部为大写字母)。
用处:解决有关不区分大小写问题
3.capitalize()、title()、swapcase()
- capitalize():将
整个字符串首字母转换为大写形式,其他字母转换为小写形式。 - title(): 将每个
单词的首字母转换为大写形式,其他部分的字母转换为小写形式。 - swapcase():将
大小写互换。
提醒:均返回新字符串,原字符串对象不做任何修改。
4.islower()、isupper()、isdigit()
功能:测试字符串是否为全小写、大写、数字。如果是,则返回True;否则返回False。
其他的方法,请通过“help(str)”自行查看帮助信息。
5.find()、rfind()
格式:
- S.find(sub[, start[, end]])
- S.rfind(sub[, start[, end]])
说明:
- sub:字符串(子串);
- start:开始位置;
- end:结束位置。查找范围start开始,end结束,不包括end。
功能:
- 在字符串S中,在[start,end)范围内查找并返回子串sub首次出现的位置索引
- 如果
没有找到则返回-1。 默认范围是整个字符串。- 其中find()方法
从左往右查找,rfind()方法从右往左查找。
6.index()、rindex()
格式:
- S.index(sub[, start[, end]])
- S.rindex(sub[, start[, end]])
功能:
- 在字符串S中,查找并返回在[start,end)范围内,子串sub首次出现的位置索引
- 如果
不存在则抛出异常。(和find()、rfind()的不同点) 默认范围是整个字符串。- 其中index()方法
从左往右查找,rindex()方法从右往左查找。
7.count()
格式:
- S.count(sub[, start[, end]])
功能:
- 在字符串S中,查找并返回[start,end)范围内子串sub出现的
次数 - 如果
不存在,则返回0。 - 默认范围是
整个字符串。
8.split()
功能:
- 以指定字符为
分隔符,从左往右将字符串分割开来,并将分割后的结果组成列表返回。 - 如果字符串中的某种字符出现0次或多次,可以利用split()方法,根据该字符把字符串分离成多个子串组成的列表。
对于split(),如果不指定分隔符,实际上表示以任何空白字符(包括连续出现的)作为分隔符。
空白字符包括空格、换行符、制表符等。
除了split(),还有rsplit(),表示从右往左将字符串分割开来,这两种方法还能指定最大分隔次数
9.join()
join()方法可用来连接序列中的元素,并在两个元素之间插入指定字符,返回一个字符串
join()方法是split()方法的逆方法
s='Heart is living in tomorrow'
slie=s.split() #用空格分割
ss=' '.join(slie) #用空格接上
10.replace()
格式:
- replace(old,new,count=-1)
功能:
- 查找字符串中old子串并用new子串来替换。
- 参数count默认值为-1,表示替换
所有匹配项,否则(count为其他值时)最多替换count次。 - 返回替换后的新字符串(原字符串不变)。
s1='中国北京,北京地铁,地铁沿线,北京沿线城市'
s4=s1.replace('北京','Beijing',2) #指定最大替换次数
11.maketrans()、translate()
- maketrans():生成字符映射表
- translate():根据字符映射表替换字符。
- 这两种方法联合起来使用可以一次替换多个字符。
t=''.maketrans('iort','mn24') #两个序列中的元素按照次序一一对应,用于替换
#{105: 109, 111: 110, 114: 50, 116: 52}
s='Heart is living in tomorrow'
s.translate(t)
#'Hea24 ms lmvmng mn 4nmn22nw'
#'Heart is living in tomorrow'
12.strip()
strip():去除字符串两侧的空白字符(空格、回车、制表符等)或指定字符,并返回新字符串。
s1='HHwHeart is liwving iHn tomorrowHww'
s1.strip('Hw') #从两端逐一去除“H”或“w”字符,直到不是这两个字符为止(中间的字符Hw不能去除)
5.7 字符串string模块
字符串string模块定义了Formatter类、Template类、capwords函数和常量,熟悉string模块可以简化某些字符串的操作。
import string
s=input('请输入英文单词,用空格分隔:')
ss=string.capwords(s) #用到了string.capwords()函数
print('单词首字母大写:',ss)
说明:这种方法直接用到string模块中的常量ascii_lowercase和random模块中choice()方法。choice()方法的功能是在一个非空的序列中随机选择一个元素。
import random
x='012345abcde'
random.choice(x)
5.8正则表达式
5.8.1正则表达式的元字符
正则表达式(模式串)中的字符,根据作用不同,分为两类:
普通字符:大多数字母和字符一般都会和自身匹配。元字符:有些字符比较特殊,它们和自身并不匹配,而是表明应和一些特殊的东西匹配,或者会影响重复次数。
因为在模式串中常常有特殊字符,为了书写方便,在字符串前加r前缀,不对其进行转义。
第一种情况:
模式串中全部是 普通字符
import re #导入re模块
w='abc' #模式串中 全部是普通字符
re.findall(w,'aabaab') #无匹配
re.findall(w,'aabcaabc') #两处匹配(查找到两个)
第二种情况:
模式串中含有 元字符
常用的元字符:
1.“.”:表示任意单个字符 (除换行符以外)
import re
s='hi,i am a student.my name is Hilton.'
re.findall(r'i',s) #在s中,匹配所有的i
s='''hi,
i student.
Hilton.''' #三引号字符串中可以有换行符
re.findall(r'.',s) #本结果中:没有匹配两个换行符
s='hi,i am a student.my name is Hilton.'
re.findall(r'i.',s) #匹配i后面跟除换行符以外的任意字符的形式
#必须是两个字符:第一个是i,第2个是换行符以外的任意字符,可以是空白符
2.“[]”:指定字符集
- 用来指定一个字符集合,例如:[abc]、[a-z]、[0-9];
- 从字符集合中
必须选一个,也只能选一个字符(即单个字符) - 有些元字符在方括号中不起作用(作为普通字符),例如:[akm$]和[m.]中元字符都不起作用;
- 方括号内的“”表示补集,匹配不在区间范围内的字符,例如:[3]表示除3以外的字符。
import re
s='mat mit mee mwt meqwt'
re.findall(r'm[iw]t',s) #匹配m后跟i或者w再跟t形式:mit mwt
#查找3个字符:第1字符必须是m,第3字符必须是t,中间字符只能是iw中的一个
3.“^”:匹配行首,匹配每 行 中以^后面的字符开头的字符串(必须放在模式串的开头)
英文称为caret (英语发音:/ˈkærət/)
记忆法:^数学上读作hat,帽子(戴头上),可以形象的想象成 首部
匹配模式:
- 默认只匹配多行字符串的
首行; - 多行匹配需要单独设置re.M参数。
4.“ ” : 匹 配 ‘ 行 尾 ‘ , 匹 配 每 行 中 以 ”:匹配`行尾`,匹配每行中以 ”:匹配‘行尾‘,匹配每行中以之前的字符结束的字符串
英语读作dollar,音标:['dɒlə®]
记忆法:$,可以形象的想象成 弯曲的尾巴,“行尾”
匹配模式:
- 默认只匹配多行字符串的
末行; - 多行匹配需要单独设置re.M参数。
5.“\”:反斜杠后面可以加不同的字符以表示不同的特殊意义(四对)
-
\b匹配单词头或单词尾(\b放前面,会匹配单词头;\b放后面,会匹配单词尾);相当于^或$(但这两个只能用于整个字符串,不能切分单词) -
\B与\b相反,匹配非单词头或单词尾(不查找单词头或单词尾,只查其他部分);
-
\d匹配任何数字字符;相当于[0-9]; -
\D与\d相反,匹配任何非数字字符,相当于[^0-9];
-
\s匹配任何空白字符,相当于[\t\n\r\f\v]; -
\S与\s相反,匹配任何非空白字符,相当于[^\t\n\r\f\v];\t是制表符,\f是换页符,\v是垂直制表符
-
\w匹配任何字母、数字或下画线字符,相当于[a-zA-Z0-9_]; -
\W与\w相反,匹配任何非字母、数字和下画线字符,相当于[^a-zA-Z0-9_];
-
也可以用于取消所有的元字符:\、[。
-
这些特殊字符都可以包含在[]中。如:[\s,.]将匹配任何空白字符、",“或”."。
第一对:\b和\B
字符串中切分单词的分隔符,包括空格、换行、制表符、各种标点符号。
\b:单词头/单词尾:注意不是整个字符串,而是分隔后的每个单词
\B:和\b相反(不查开头/结尾的,只查其他部分的)
第二对:\d与\D
\d:数字字符,等同于[0-9]
\D:和\d相反,等同于[^0-9](非数字字符)
第三对:\s与\S
\s:匹配(查找)任何空白字符,相当于[\t\n\r\f\v]:横向制表符、换行、回车、换页符、纵向制表符
\S:和\s相反,不匹配(查找)任何空白字符,相当于[^\t\n\r\f\v]
\S与“.”区别
- “.”, 表示任意单个字符(换行符除外)
- “\S”,表示任意单个字符(空白符除外)。注意是大写的S。
第四对:\w与\W
\w:匹配任何字母、数字或下画线字符,相当于[a-zA-Z0-9_]
\W:和\w相反,不匹配任何字母、数字或下画线字符,相当于[^a-zA-Z0-9_]
第五点:用\取消元字符
s='hi,i am a student.my name is Hilton.'
re.findall(r't.',s) #此时的.就是元字符:匹配(查找)t+任意字符
re.findall(r't\.',s) #此时的.就是普通的字符:匹配(查找)t.
第六点:\d、\D、\s、\S、\w、\W也可以用在[]内
以上5类元字符都是表示单个字符。
.:任意单个字符(换行符除外)
[]:集合中的任意单个字符
^:行首
$:行尾
\:\b\d\s\w
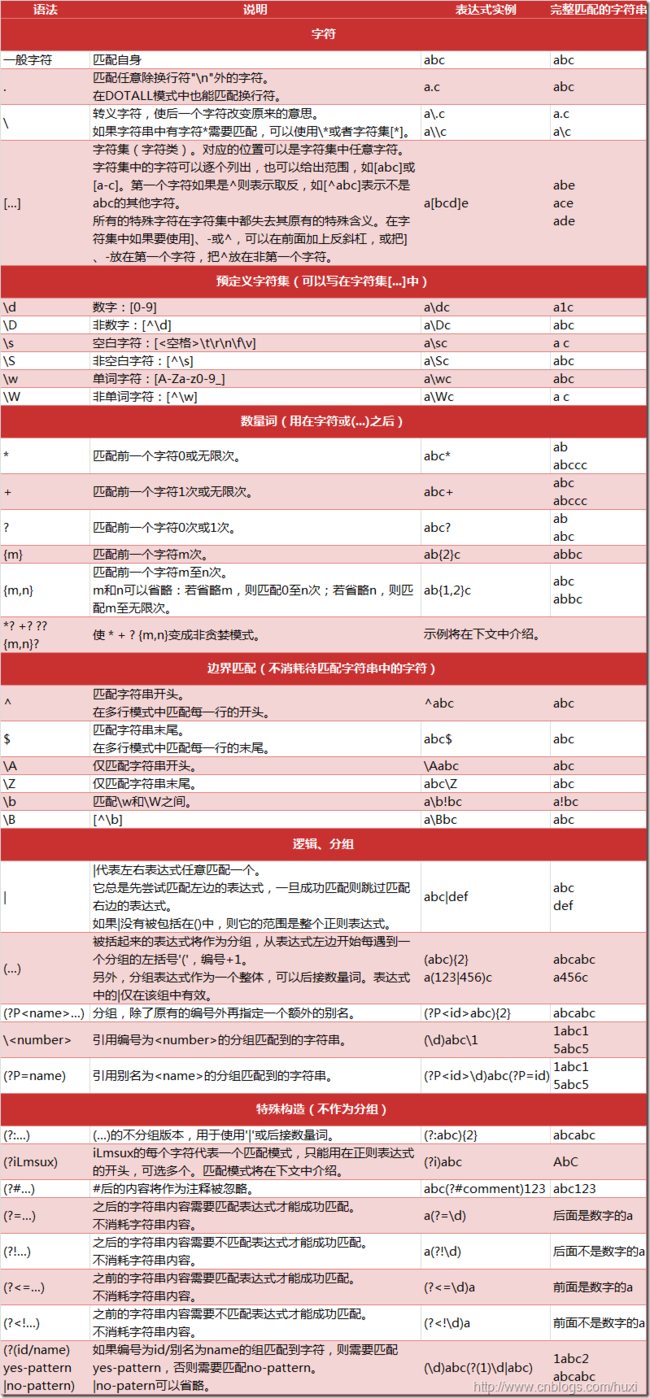
量词
正则表达式能指定正则表达式的一部分的重复次数,用到的元字符有“*”、“+”、“?”、“{}”。
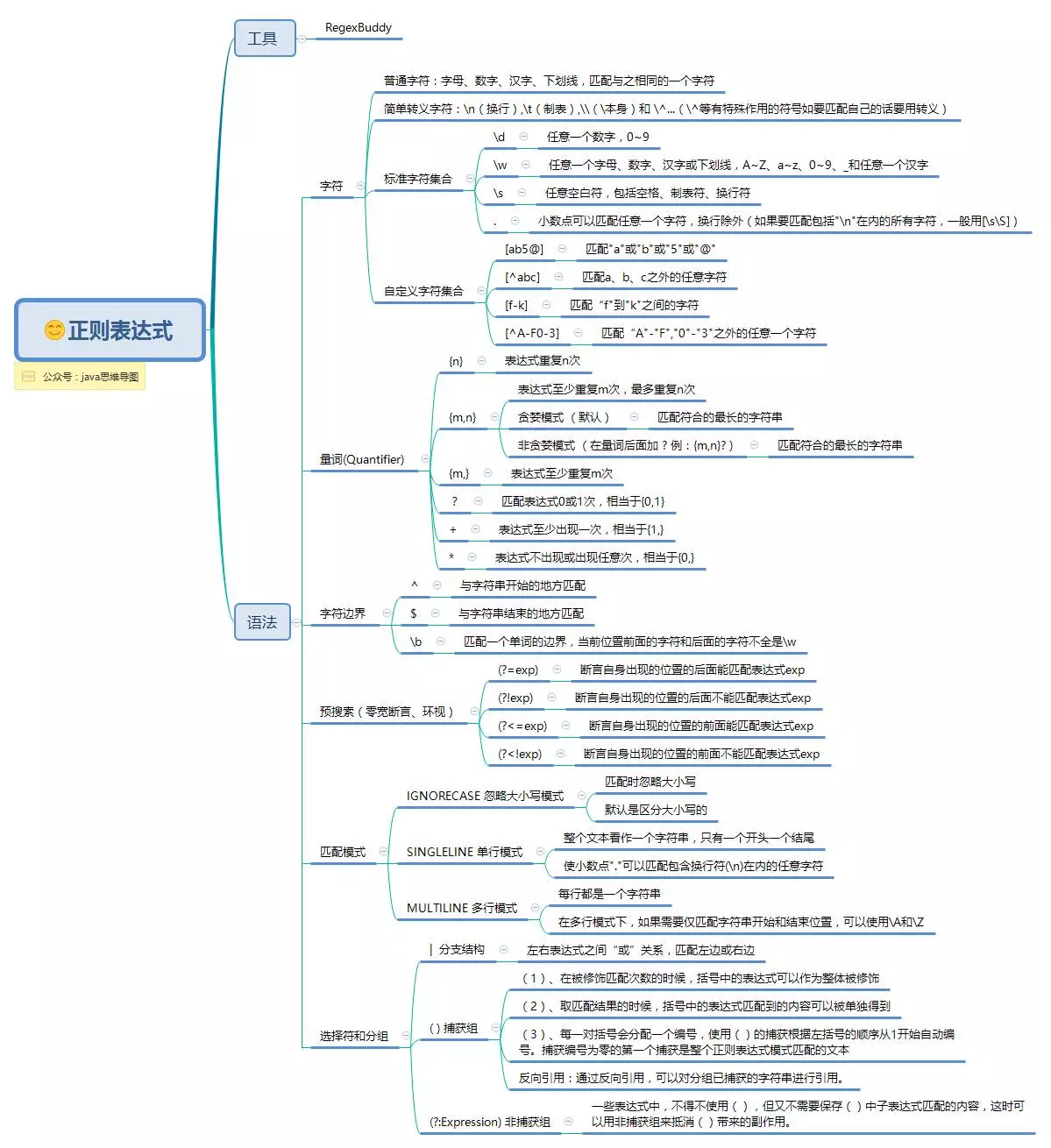
六、函数
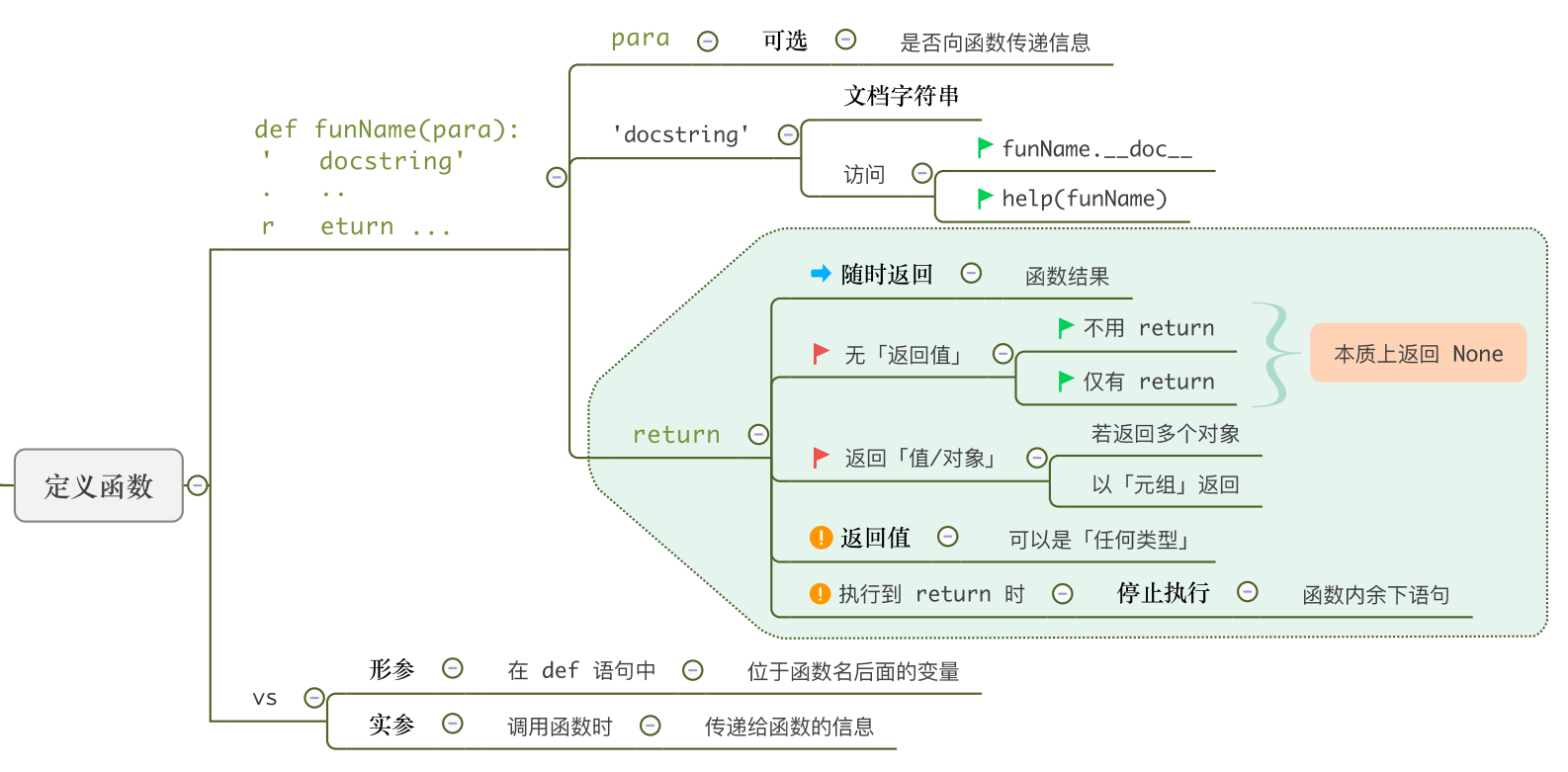
6.1 函数的定义
函数定义格式如下:
def 函数名(形式参数):
函数体
函数名必须符合Python标识符的规定;形式参数,简称为形参,写在一对圆括号里面,多个形参之间用逗号隔开;- 该行以
冒号结束; - 没有
返回值类型(因为Python是动态类型); - 函数体是语句序列,左端必须
缩进空格。
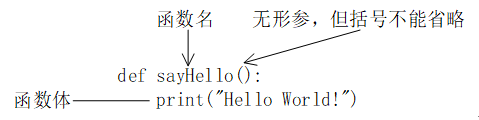
如何改进此函数使之能打印出其他字符串呢?
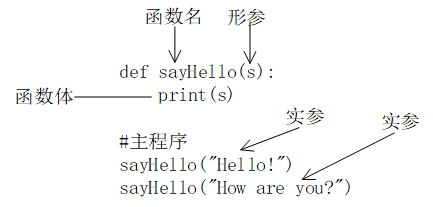
如何返回结果?
- 函数使用关键字
return来返回函数的结果值。 - 执行return语句, 同时意味着函数的
终止。
6.2 函数的调用
当调用一个函数时,程序控制权就会转移到被调用的函数上,真正执行该函数;
执行完函数后,被调用的函数就会将程序控制权交还给调用者
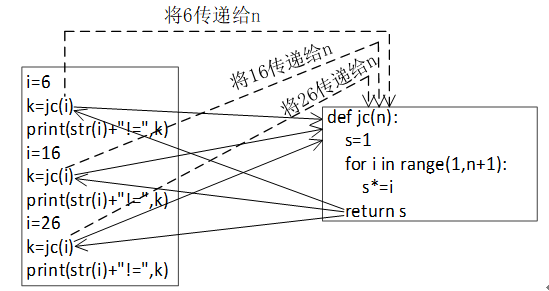
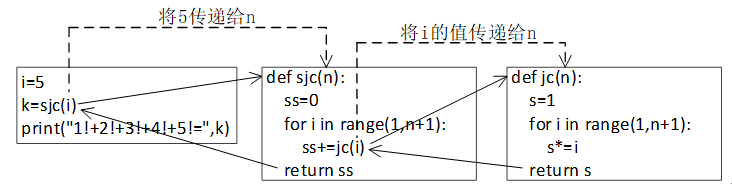
函数可以多次嵌套调用。
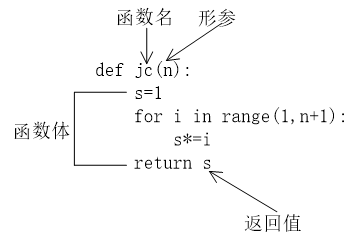
#求正整数阶乘的函数
def jc(n): #函数定义:计算n!
s=1
for i in range(1,n+1):
s*=i
return s
#-------------------函数:sjc(n) ----------------------
#求阶乘和的函数
def sjc(n): #函数定义:计算1!+2!+3!+...+n!
ss=0
for i in range(1,n+1):
ss+=jc(i)
return ss
#------------------- 主程序 ----------------------
i=5 #函数调用:计算1!+2!+3!+4!+5!
k=sjc(i)
print("1!+2!+3!+4!+5!=",k)
6.3 形参与实参
同C语言:
- 在函数定义中,括号中列出的参数称为形式参数,简称
形参。 - 如果形参的个数超过1个,各参数之间用
逗号隔开。 - 在定义函数时,函数的形参不代表任何具体的值,只有在函数调用时,才会有具体的值赋给形参。
- 调用函数时传入的参数称为实际参数,简称
实参。
6.4 函数的返回
return语句用于从函数返回值,给调用者。格式如下:
def 函数名(形式参数):
……
return <表达式1>,…,<表达式n>
如果一个函数的定义中没有return语句,运行时,系统将自动在函数体的末尾插入return None语句
6.5 变量的作用域
变量的**作用域**是指一个变量能够作用的范围,也就是在多大范围内能够被解释器识别。
根据变量的作用域,变量可分为全局变量和局部变量。
-
局部变量:声明在函数内部的变量,该变量只能在该函数内部使用,超出范围就不能使用。 -
全局变量:
- 声明在函数外部的变量,作用范围是:所在程序文件内从定义开始至文件结束,包括变量定义后所调用的函数内部。
- 也可以通过global关键词将函数内部的变量申明为全局变量,该变量可以在主程序中 调用该函数后 的 剩余 语句中使用。
若函数中定义的局部变量(或形参)与全局变量重名,则局部变量(形参)优先。但是,尽量不要出现这种情况。
但是,为了提高程序的正确性和模块化程度,
- 要尽量
避免使用global在函数体内定义全局变量; - 也要尽量
避免在函数内直接使用主程序中定义的全局变量; - 全局变量一般作为
常量使用; - 尽量以
参数传递方式来使用相关数据。
思考:调用者将实参传递给函数形参后,函数体内部对该形参进行修改;则,函数调用结束后,函数调用者相应的实参变量是否发生了变化?
【简言之:形参的修改,是否会影响实参?】
这要分两种情况来讨论:
- 传递的 实参变量 是一个
不可变对象的变量(如int、float、str、bool、tuple、set),函数内部对该形参变量的任何修改都不会对调用者的实参产生影响。 - 传递的 实参变量 是一个
可变对象的变量(如list、dict),函数内部对该形参变量的修改都会反馈到实参变量,函数调用结束后,实参也能看到相同的修改效果。
所以,Python的参数传递本质是传递 对象引用 ,即 传地址,而不是传递对象的值。
但是,因为 不可变对象 本身的值没法修改,所以,形参的修改影响不到它。
6.6位置参数
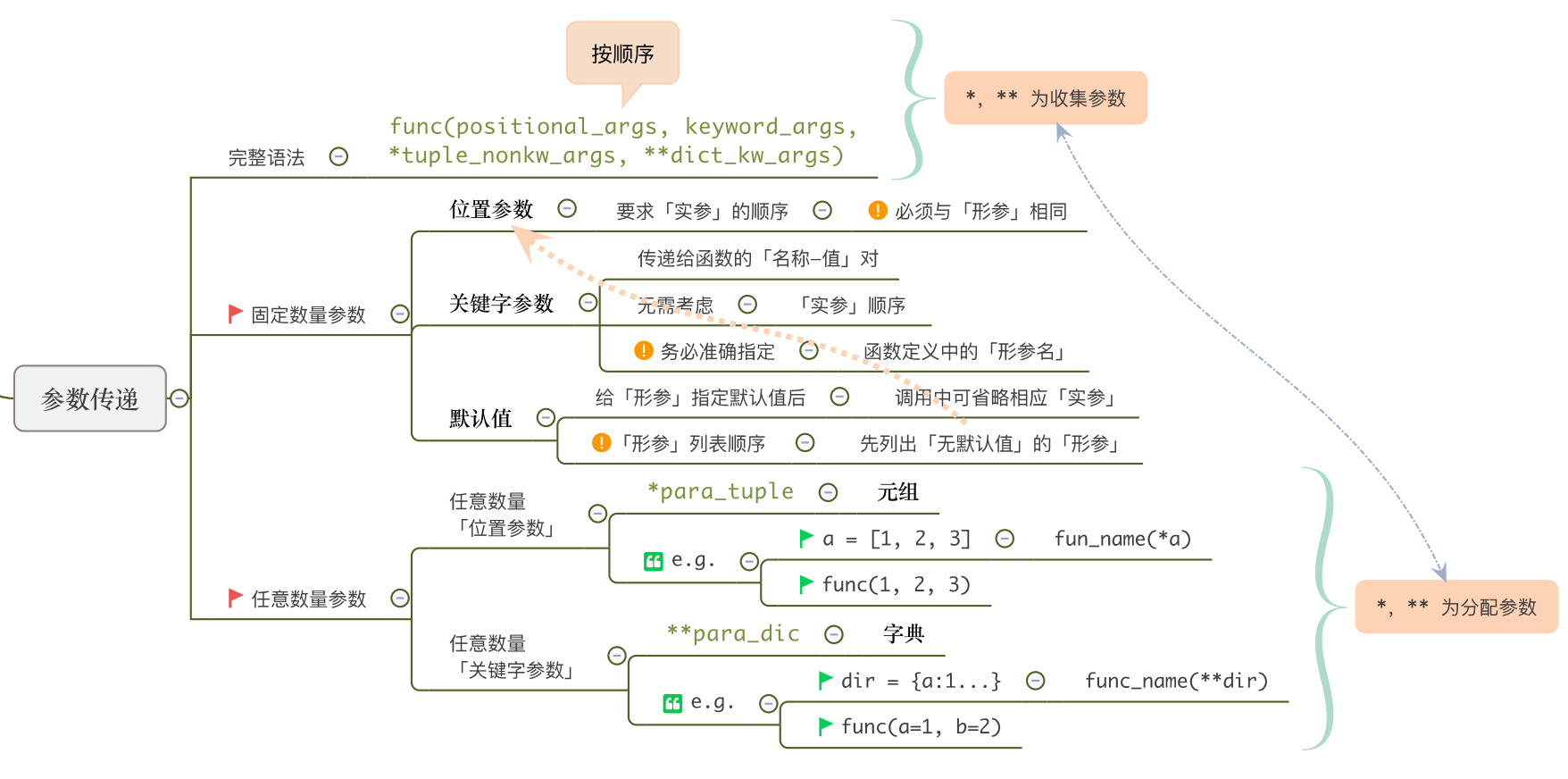
参数传递时有两种方式:位置参数和关键字参数。
- 位置参数:按照参数的位置来传递
- 关键字参数:按照参数赋值的形式来传递(下一小节讲)
位置参数:实参和形参在顺序、个数和类型上必须一一匹配(和C语言相同)。
前面示例中,调用带参数的函数时均使用位置参数的方式。
6.7默认参数与关键字参数
- 形参 中有“名=值”形式:
默认参数 - 实参 中有“名=值”形式:
关键字参数
函数的形参可以设置默认值。这种形参通常称为默认参数(也称为,可选参数)。
- 若 调用时
没有为这些参数提供值:这些参数就使用默认值; - 若 调用时
有实参:则将实参的值传递给形参,形参定义的默认值将被忽略。
函数 形参 定义格式如下:
def 函数名(非默认参数, 形参名=默认值, ……):
函数体
def sayHello(s="Hello!",n=2,m=1): #3个都是默认参数
for i in range(1,n+1):
print(s*m)
#---------------------- 主程序 ----------------------
sayHello() #均未赋新值:均取默认值
print()
sayHello("Ha!",3,4) #全部赋新值:按照顺序,依次赋值给形参
print()
sayHello("Ha!") #部分赋新值:按照顺序,形参中s赋予新值“Ha!”,n和m没有赋新值,取默认值
函数定义时,非默认参数与默认参数可以并存,但非默认参数之前不能有默认参数。
即:非默认参数在前,默认参数在后。
- def sayHello(s,n=2)是有效的,
- def sayHello(s=“Hello!”,n)是无效的。
关键字参数
在函数调用(实参)中,通过“变量名=值”的“键-值”形式将实参传递给形参(也称为命名参数)。
三个优点:
- 参数按名称意义明确;
- 传递的参数与顺序无关;
- 如果有多个可选参数,则可以选择指定某个参数值。
def sayHello(s,n=2,m=1):
for i in range(1,n+1):
print(s*m)
#---------------------- 主程序 ---------------------
sayHello("Ha!")
print()
sayHello("Ha!",3) #此时的3是位置参数,对应形参的n:不直观
print()
sayHello("Ha!",m=3) #原第2个形参取默认值
print()
sayHello(m=3,s="Ha!") #可以不按顺序
6.8可变长度参数
形参中有带或的参数
带有一个\的形参:
函数可以接收不定个数的参数:通过在形参前面使用标识符“*”来实现。
在调用函数时,对应带星参数后所有的参数被收集为一个元组。
#------------- all_1() ---------------
def all_1(*args):
print(args) #收集为一个元组
#------------- 主程序 ----------------
all_1("a") #1个参数
all_1("a",2) #2个参数
all_1("a",2,3.15) #3个参数
all_1("a",2,3.15,True,[1,2,'3']) #5个参数
在Python中,很多内置函数也使用了可变参数函数,如max和min都可以接收任意个数的参数。
max(3,5,7,11)
min(5,6,4,8,3)
用标识符*实现的可变长度的参数也可以和其他普通参数联合使用
这时一般将可变长度参数放在形参列表的最后。
#-------------- all_3() -----------------
def all_3(s,*args):
print(s)
print(args)
#--------------- 主程序 ------------------
all_3("abc","a",2,3,"b")
Python还提供了一种形参名前面加标识符“**”的方式,用来引用一个字典。
- 函数调用者实参 :
必须以关键字参数的形式为其赋值:强制命名参数;如实参形式 m=3,n=‘a’ - 形参得到一个以关键字参数中变量名为key,右边表达式值为value的字典;形参获得形式:{‘m’:3,‘n’:‘a’}
#----------- all_4()函数-----------
def all_4(**args): #形参:**双星花
print(args) #收集为一个字典dict
#------------ 主程序 -----------
all_4(x="a",y="b",z=2) #实参:关键字参数
all_4(m=3,n=4)
以“**”为前缀的可变长度参数(字典)、以“*”为前缀的可变长度参数(元组)、普通参数在函数定义中可以混合使用。
这时,最前是普通参数,其次是以“*”为前缀的可变长度参数,最后是以“**”为前缀的可变长度参数。
fun(普通参数,…,*可变长度参数,**可变长度参数)
#------------ 函数定义 -------------
def all_6(a,b,*aa,**bb):
print(a)
print(b)
print(aa)
print(bb)
#------------ 主程序 ----------------
all_6(1,2,3,4,5,xx="a",yy="b",zz=2)
6.9序列和字典作为参数
如果实参是字典:
- 函数定义中的
形参也是字典;
如果使用序列作为实参,则要满足下列两个条件之一:
- 函数中
形参也是序列; - 如果函数中形参是n个单变量,则在实参的序列变量名前加“*”,要求实参序列中的元素个数与单变量形参个数相同;
简言之,字典 对 字典,序列 对 序列(或,序列解包后 对 多变量)。
如果实参中普通变量与序列变量混用,则以“*”为前缀的序列变量放置在实参的最后。
#---------------- sum1() ---------------
def sum1(args): #形参:序列
print(args)
s=0
for i in args:
s+=i
return s
#---------------- sum2() ---------------
def sum2(args): #形参:字典
print(args)
s=0
for i in args.keys():
s+=args[i]
return s
#---------------- 主程序 ---------------
print("sum1:")
aa=[1,2,3] #列表(序列)作实参
print(sum1(aa)) #[1,2,3] 6
print(sum1([4,5])) #列表(序列)作实参 [4, 5] 9
bb=(6,2,3,1) #元组(序列)作实参
print(sum1(bb)) #(6, 2, 3, 1) 12
print()
print("sum2:")
cc={'x': 1, 'y': 2, 'c': 3} #字典变量 作实参
print(sum2(cc))
print(sum2({'aa': 1, 'bb': 2 ,'cc': 4, 'dd': 5, 'ee': 6})) #字典常量
#----------- 函数定义,形参为单变量参数 -------
def sum3(x,y,z): #形参:多个单变量
return x+y+z
#--------------主程序 --------------------
a,b,c=1,2,3
print(sum3(a,b,c)) #单变量参数 6
aa=[1,2,3] #列表
print(sum3(*aa)) #实参为列表变量,加前缀"*",自动解包,和形参个数相同 6
bb=(1,2,3) #元组
print(sum3(*bb)) #实参为元组变量,加前缀"*",自动解包,和形参个数相同 6
cc=[8,9]
print(sum3(7,*cc)) #实参为单变量+序列,序列部分自动解包,总数和形参个数相同 24
总结*出现在不同位置:
形参样式(如aa,**bb):可变长度参数(打包为元组,字典)
实参样式(如aa):序列解包为单变量
6.10 生成器(yield)函数
生成器其实是一种特殊的迭代器。
这种迭代器更加优雅,不需要写iter()和next()方法,只需要在函数中使用一个yield关键字以惰性方式逐一返回元素。
惰性:是指并不会提前生成元素放入容器(勤快),而是何时需要何时再计算生成(懒惰)。
生成器一定是迭代器(反之不成立)
Python 中使用了yield的函数返回生成器对象,此函数称为生成器函数,只能用于迭代操作。
调用该函数的过程:
- 每次遇到yield语句时,函数会暂停执行,并保存当前所有的运行状态信息,返回yield后面的值(相当于return),并在下一次执行next()方法时从当前位置继续运行。
生成器函数返回的是一个生成器对象
#------------------ fib() -----------------------
def fib(n):
i, a, b = 0, 1, 1
#常规写法:L=[]不需要了,因为每次只生成(返回)一个值
while i < n:
yield a #表示:返回a的值,然后暂停在这儿,等着下一次next(继续从这一行运行)。
#常规写法:L.append(a)。
a, b = b, a + b #注意:等号后面的b,a是赋值语句执行之前的值
i += 1
#没有return L语句了,因为已经用yield返回值了
#------------------- 主程序 ---------------------
n=int(input('请输入个数:'))
L=fib(n) #此时L是个生成器对象
for x in L:
print(x) #1 1 2..
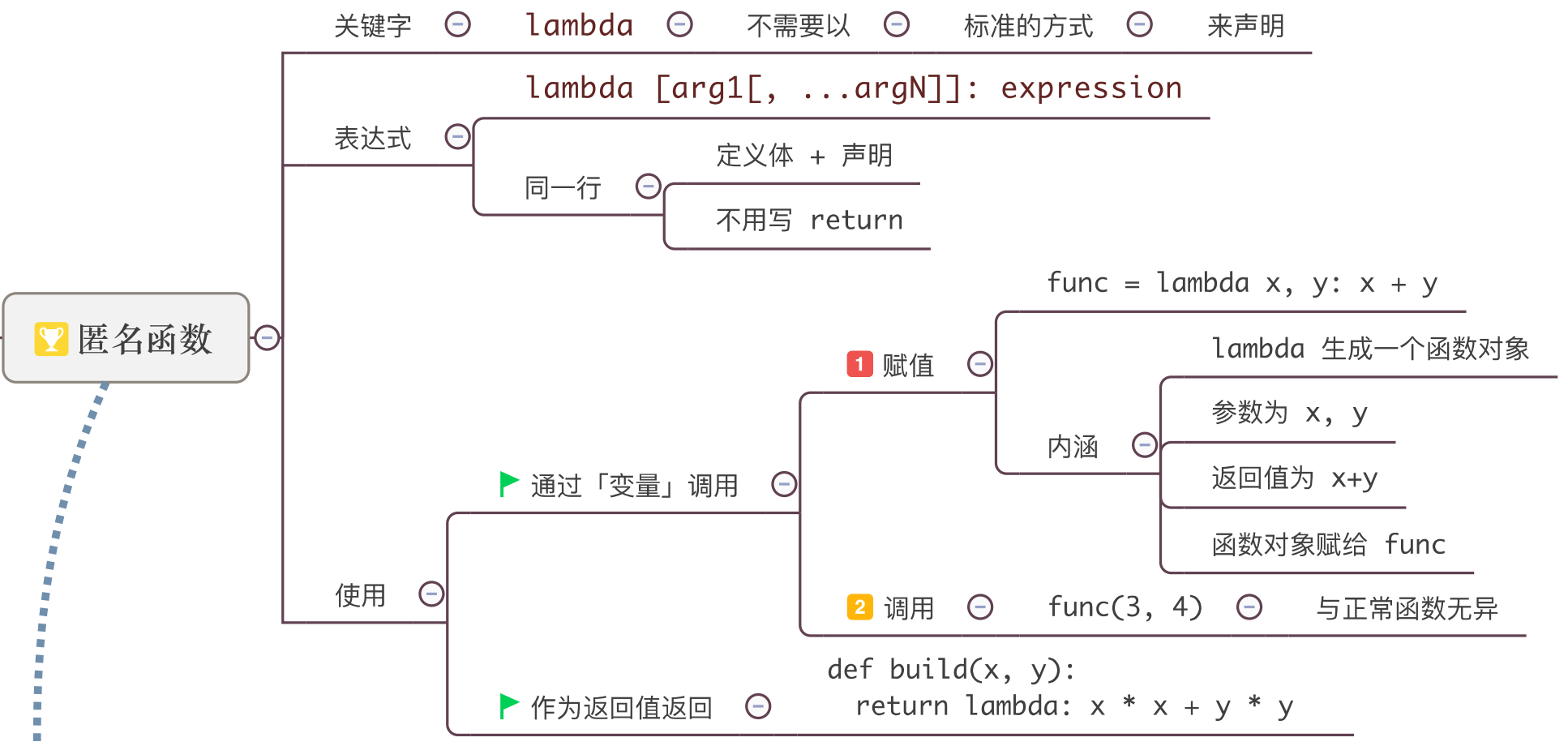
6.11 lambda函数
何时适合lamda函数?
函数的形式比较简单,且只需要作为参数传递给其他函数(只用一次就完事)。
- lambda函数是一个
匿名函数,有时也被称为lambda表达式,比def格式的函数定义简单很多; - Lambda函数可以接收
任意多个参数,但只返回一个表达式的值; - lambda中
不能包含多个表达式;
定义格式为(在同一行):
lambda 形式参数 : 表达式
- 形式参数可以有多个,它们之间用逗号隔开
- 表达式只有一个
- 返回表达式的计算结果。
速记:功能简单,单行,匿名,返回单个值
本质:就是一个普通函数的精简版
f=lambda x,y : x+y #f是lamda函数的名字
f(5,10)
y=list(filter(lambda i : i%2==0, x))
y
6.12 递归
递归:如果一个函数在内部直接或间接地调用它本身。
递归并没有特别语法,只是递归思想。
#------------------ fac()函数定义 --------------
def fac(n):
if n==1:
return 1
else:
return n*fac(n-1)
#------------------- 主程序 --------------------
a=eval(input("please enter n:"))
print(str(a)+"!=",fac(a))
编写递归函数必须满足以下两点:
- 有明确的递归终止条件及终止时的值;
- 能用递归形式表示,并且向终止条件的方向发展。
七、文件操作
7.1 文件的基础知识
从存储简单字符的文本到具有复杂格式的word文档,从静态图像到多媒体视频,从桌面数据库access到复杂网络数据库oracle等,这些信息最终都以文件的形式存储到磁盘上。
无论何种类型的文件,在内存或磁盘上最终都是以二进制编码存储的。
但,根据逻辑上编码的不同,可以区分为文本文件和二进制文件:
- 文本文件基于
字符编码,如ASCII码、Unicode编码等。文本文件存储的是普通字符串,能够用记事本等文本编辑器直接显示字符、进行编辑。 - 二进制文件是基于值编码的,以
字节串的形式存储,其编码长度根据值的大小长度可变。二进制文件不能用文本编辑器显示或编辑,如声音、图像等文件。
Python标准库中包括下列文件处理的相关模块
-
io模块:文件流的输入/输出操作模块
-
bz2模块:读取和写入bzip2压缩算法的压缩文件
-
gzip模块:读取和写入gzip压缩算法的压缩文件
-
zipfile模块:读取和写入zip压缩算法的压缩文件
-
zlib模块:读取和写入zlib压缩算法的压缩文件
-
tarfile模块:读取和写入TAR压缩算法的卷文件
-
csv模块:读取和写入CSV格式的文件
-
pickle和cPickle:序列化Python对象
-
xml包:XML文件的处理
-
os模块:基本操作系统功能,包括文件操作
-
json模块:JSON格式数据操作
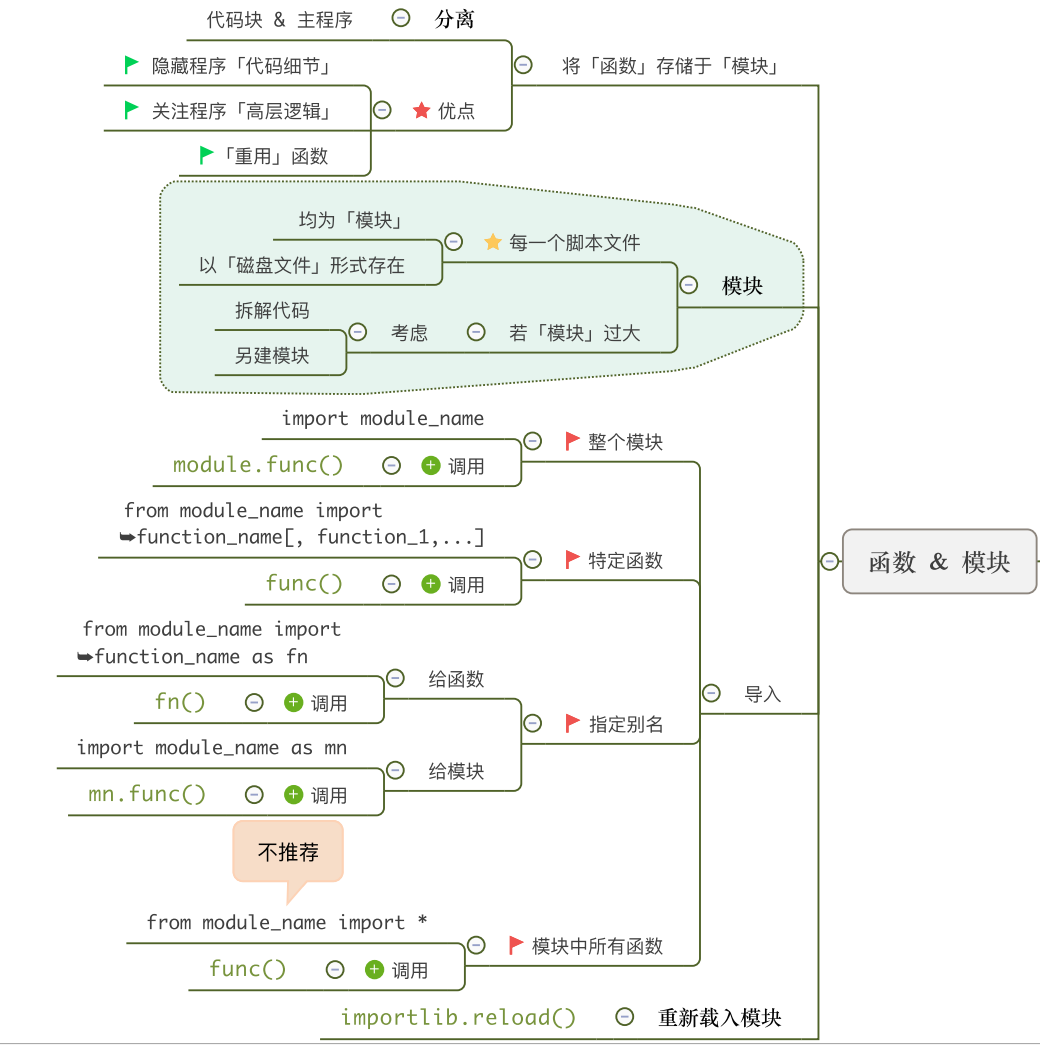
7.2 文件的打开与关闭
打开一个文件:
格式:open(name[, mode [, buffering]])
说明:
- name是唯一必须提供的参数,即为文件的路径。
- mode是可选参数,指定读写模式,我们将在后面小节对其详细说明。
- buffering是可选模式,缓存大小
- 返回值:调用open函数之后,将得到一个文件对象。
#假如在d盘根目录下存在一个名为'test.txt'的文件,可以通过以下语句打开它:
f = open(r'd:\test.txt')
#若存在这个文件,则获得一个文件对象f
#如果d盘中不存在这个文件,则会提示以下错误:
在windows操作系统下,文件名所包含的路径名有如下三种写法:
f = open(r'd:\test.txt') #r前缀
f = open('d:\\test.txt') #反斜杠转义
f = open('d:/test.txt') #正斜杠
Python中的文本对象有三种常用属性:
- closed属性:用于判断文件是否关闭,若文件处于打开状态,则返回False;
- mode属性:返回文件的打开模式;
- name属性:返回文件的名称。
文件关闭
文件读写完毕之后,要注意使用f.close()方法关闭文件。
作用:把缓存区的数据写入磁盘,释放内存资源供其他程序使用。
f.close()
f.closed #三个属性依然可以查询
f.mode
f.name
f.read() #但,不能再读写了
在打开文件open时,可以时用with语句,系统会自动关闭打开的流。
with open(r'd:\test.txt') as f:
f.read()
#-- 上面的with已经执行完毕,系统自动关闭文件
#f.close() 就不需要了
f.read() #再读写,出错
7.3 读写文件
首先使用open函数,以某种模式打开文件,获得一个文件对象。
open(name, mode)
- 如果只提供一个参数’name’,那么将返回一个只读的文件对象。
- 可以通过mode参数提供文件打开模式。该参数有多种选择,参见下表。
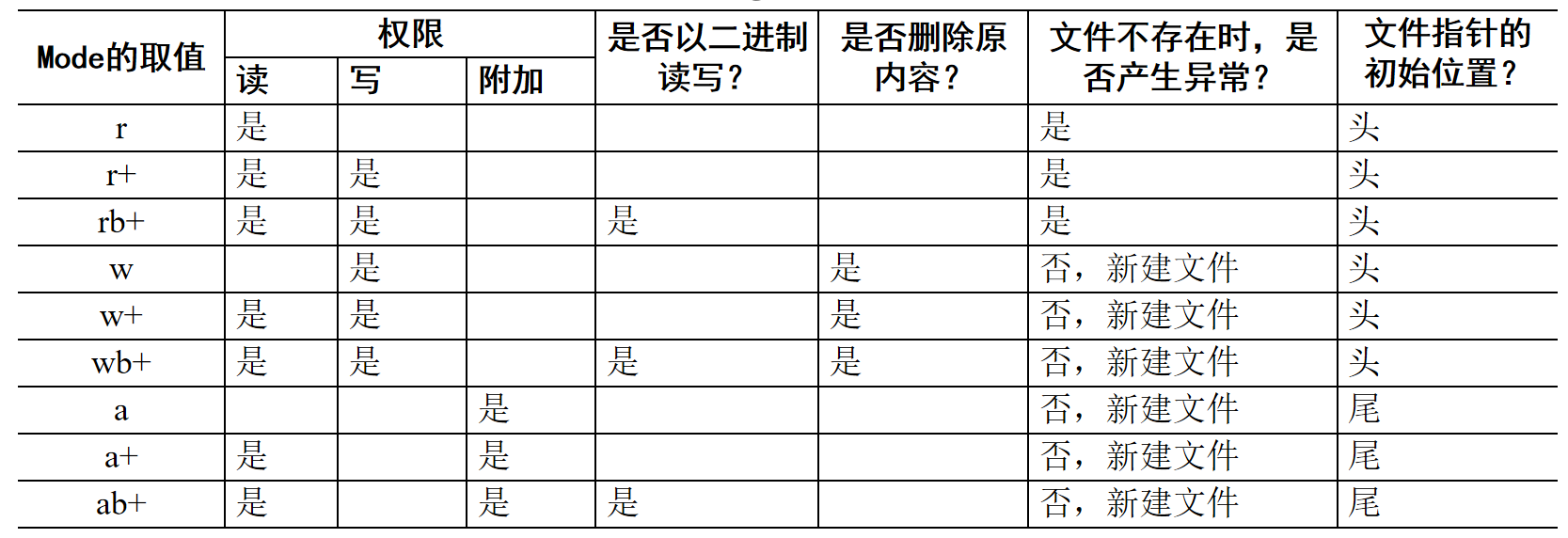
速记:
- r为读,w为写,a为附加。
- +增加了相反功能(读增加了写,写增加了读)。
- b支持二进制文件。
7.3.1 文本文件的写入
open()函数在’r+’,‘w’,'w+'和’a+'等模式下打开文件后,可返回一个文本文件对象,此时,可以往文本文件写入数据。
文件对象内置读写数据的方法write()、writelines()。

文本文件的write()方法
f=open('d:\\test.txt','w') #w:会新建文件或删除原有数据,以覆盖的方式写入(不能读取)
f.write('123计18-12班\n') #返回的是 成功写入的字符数
f.write('abc')
#f.read() #会出错
f.close()
打开d盘的test.txt文件可以发现其中有两行文本:123和abc。
另外,需注意的是,一旦在’w’模式下打开某个已经存在的文件,则该文件里的原有数据会被清空。
writelines()可实现逐行写入给定列表中的所有字符串元素。
f = open('d:\\test.txt','a') #a:以附加模式写入
a_list = ['\nhubei','\n78901234']
f.writelines(a_list)
f.close()
#打开test.txt文件可以发现有4行文本:567,def,123和abc。

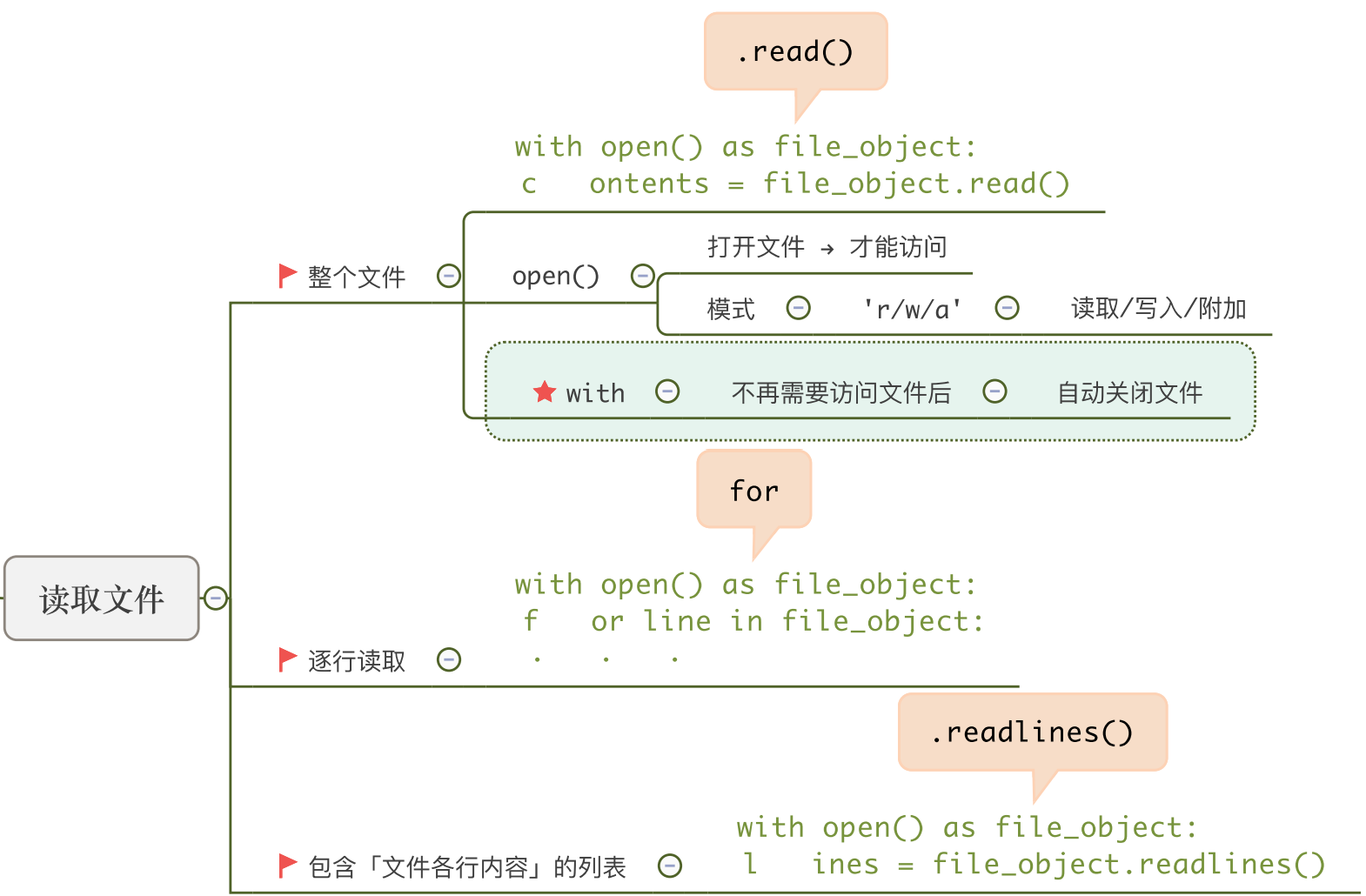
7.3.2 文本文件的读取
open()函数在‘r’,‘r+’,‘w+’和‘a+’等模式打开文件后,可返回一个文本文件对象,在此基础上实现对文本文件的读取。
内置读取数据的方法有read()、readline()、readlines(),如下表所示。

利用read()方法可读取文件中指定长度的字符:
- 若括号中无数字,则直接读取文件中
所有的字符; - 若提供数字,则一次读取
指定数量字节的字符。
读取示例:
1.在d盘根目录下新建一个名为’test.txt’的文件,并在其中输入两行英文’hello Python!‘和’how are you!’,然后保存并关闭文件。
2.在’r’模式下构建文件对象f之后,可以用其内置函数read(),readline()和readlines()等方法读取出f中的数据。
f = open('d:\\test.txt')
f.read(3) #读取3个字节,读取指针会后移
f.read(2) #读取2个字节
f.read() #读取剩余全部字节
内置方法f.readline()可实现逐行读取字符。
- 若括号中
无数字,则默认读取一行; - 若括号中有数字,则读取这一行中对应数量的字符(如果该数字大于这一行的字符数,则读取这一行所有字符)。
f = open('d:\\test.txt')
f.readline() #读取第一行(包括换行符\n) hello python\n
f.readline(2) #读取第二行的2个字符 ho
f.readline() #读取本行剩余的所有字符 w are you
内置方法f.readlines()可实现读取一个文件中的所有行,并将其作为一个列表返回。
每一行的信息作为列表中的一个字符串元素。
f = open('d:\\test.txt')
#f=open('d:\\test1.py')
f.readlines()
值得注意的是,调用readlines()方法将返回一个以文件每一行内容作为元素的列表存储在内存之中。
- 当文件存储的信息量
较小时,对于计算性能的影响较小; - 但当文件
很大时,则需要占用较大的内存,影响到计算机的正常运行。
此时,有三种方法可以替代readlines()以减少内存的占用:
- (1)组合使用循环结构与readline()方法,
逐行读取文本内容; - (2)利用iter(文件对象)返回一个
迭代器,从而降低了对计算机内存的占用(随用随取); - (3)直接利用
文件对象本身迭代功能,逐行读取信息。
这三种方法是等效的(每次只读取/处理 一行)。
#方法1
f = open('d:\\test.txt')
line = f.readline()
while line: #1、用常规的循环
print(line,end='')
line = f.readline()
f.close()
#方法2
f = open('d:\\test.txt')
for line in iter(f): #2、从f中获取迭代器,逐个迭代(f看作是容器,其中的每行看作一个元素)
print(line,end='')
f.close()
#方法3
f = open('d:\\test.txt')
for line in f: #3、直接迭代文件对象f(f看作是容器,可以支持直接迭代)
print(line,end='')
f.close()
最后,如果需要将迭代器转化为列表,则可考虑以下方法:
f = open('d:\\test.txt')
li = list(f) # f本身就是一个容器,list函数直接做转换。
print(li)
7.3.3 二进制文件的写入
二进制文件的写入有两种常用的方法。
-
一种是通过struct.Struct对象的pack方法(将数据转换为二进制的字节串),然后用write方法写入文件。
两步完成:先pack()转换,再write()写入
-
另一种是用pickle模块的dump方法(将数据转换为二进制的字节串),并直接写入文件。
一步完成:dump(),转换加写入
方法一:
用struct.Struct对象的pack方法将数据转换为二进制的字节串,然后通过write方法写入文件对象。
基本步骤如下:
导入struct包;- 创建struct.
Struct对象; - 利用struct.Struct对象的pack方法将数据
转换为二进制的字节串; - 将二进制的字节串
写入准备好的文件对象。
其中struct.Struct对象的创建格式为:Struct(fmt)。其中fmt是由格式字符组成的字符串。格式字符如上表所示。
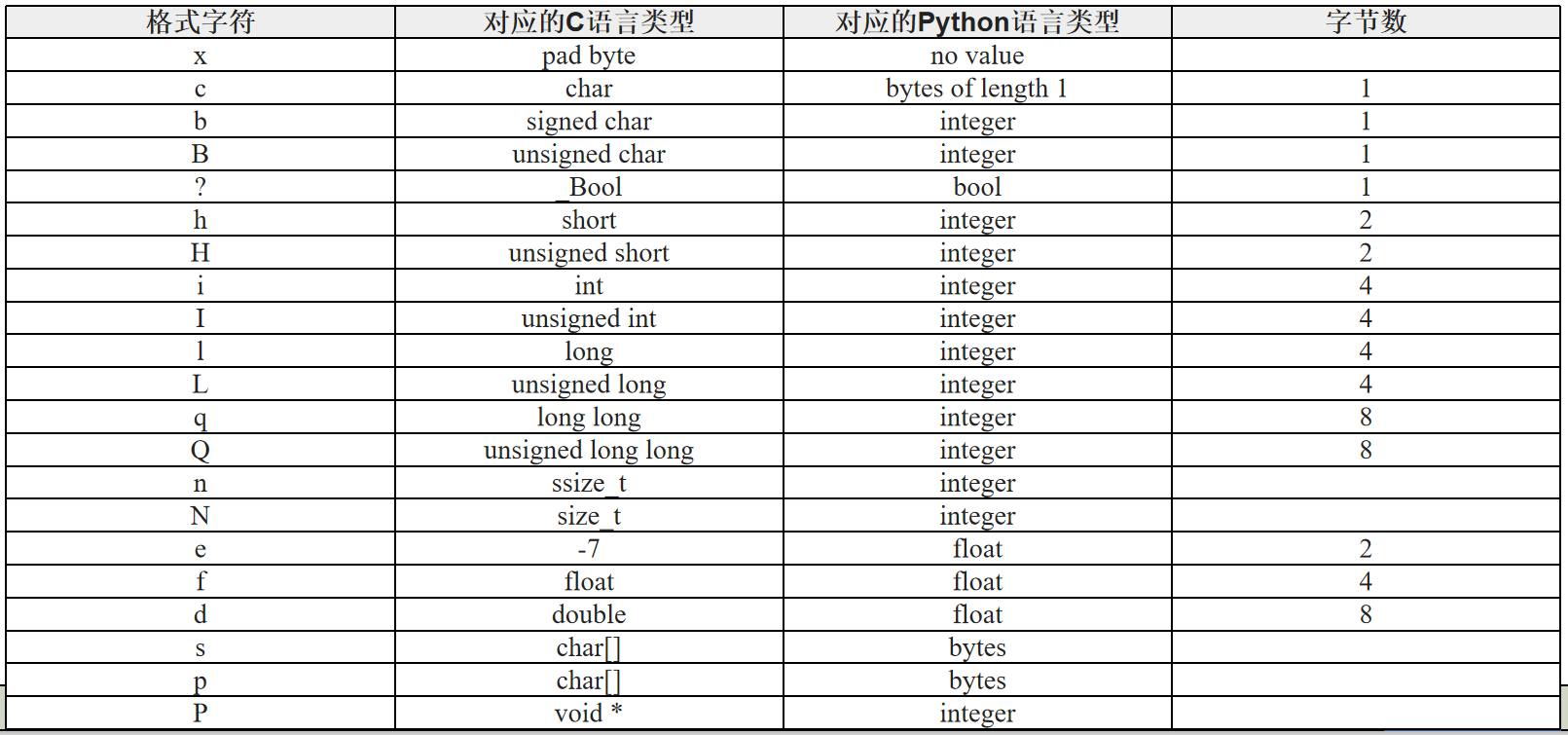
利用struct.Struct对象的pack方法将一个整数、一个字符串、一个浮点数和一个布尔值转换为二进制的字节串,并新建文件对象用write方法写入该文件中。
import struct #1、导入struct包
values=(8,b'abc',9.9,True) #待存储的数据(各种数据类型),b前缀表示以ASCII编码
#values=(8,bytes('abc', encoding = "utf-8"),9.9,True) #字符串的另一种写法
s=struct.Struct('I3sf?') #2、格式字符串,创建struct对象:1个int,3个字符,1个float,1个bool
packed_data=s.pack(*values) #3、利用Struct对象中的pack方法将数据转换为二进制字节串(*表示解包)
f=open('example7_1.dat','wb') #没有写磁盘和全路径:和本文件在一个文件夹里面的example7_1.dat
f.write(packed_data) #4、在文件对象中写入二进制字节串packed_data
f.close() #用VSCode打开这个文件,但是很难理解
方法二:
用pickle模块的dump方法将数据转换为二进制的字节串,并直接写入文件(转换、写入,一次完成)。
dump方法最基本的调用格式为:
dump(数据对象,文件对象)。
其功能是:将数据对象转换为二进制的字节串并写入文件对象中
利用pickle模块的dump方法分别将一个字符串、一个列表、一个字典、一个整数和一个浮点数写入文件中。
import pickle #1、导入pickle模块
s='好好学习' #字符串,默认是unicode编码,与带有u前缀的u'好好学习'是等同的
li=[1,2,'天天向上',9.9] #列表list
d={1:10,2:20} #字典dict
x=8 #int
y=8.8 #float
f=open('example7_2.dat', 'wb') #2、打开文件,模式为二进制写入wb
pickle.dump(s, f) #3、转换每一个变量s,并写入f
pickle.dump(li, f)
pickle.dump(d, f)
pickle.dump(x, f)
pickle.dump(y, f)
f.close( )
7.3.4 二进制文件的读取
上述两个程序生成的数据文件,用记事本文件(或者直接用VSCode)打开后,内容是无法理解的。
需要用对应的相反的转换方式读入。
与写入时的方法相对应,二进制文件的读取也有两种常用的方法。
1.Struct对象写入的文件:
- 首先打开文件,读取文件内容,
- 然后利用struct.unpack将字节串转换为原对象。
2.pickle模块的dump()方法写入的文件:
- 利用pickle.load()方法每次读取一个对象的内容,并自动转换为相应的对象。
读取上例生成的example7_1.dat文件中的信息,并在屏幕上打印输出
import struct
f=open('example7_1.dat', 'rb') #rb:二进制 读取
s=f.read() #二进制的字节串的形式
print(s) #打印出 十六进制格式,看一下
#struct.unpack中的格式字符串
#须与struct.Struct中的格式字符串相同
t=struct.unpack('I3sf?', s) #和写入的时候相同:i表示读取int,3s表示3个字符,f表示float数据,?表示bool
print(t) #元组:(8,b'abc',9.8999999,True)
for x in t: #遍历元组中的每一个
print(x)
f.close()
import pickle
f=open('example7_2.dat', 'rb')
try: #异常处理(和Java的try是一样的)
while True:
x = pickle.load(f) #读取每一个数据x:load()会自动作数据转换
#pickle.load()从文件中无内容可读时,
#抛出EOFError异常
print(x)
except EOFError: #异常处理:和Java的catch作用一样的。EOF:End Of File 文件结束
print('读取完毕')
f.close()
7.4 文件指针
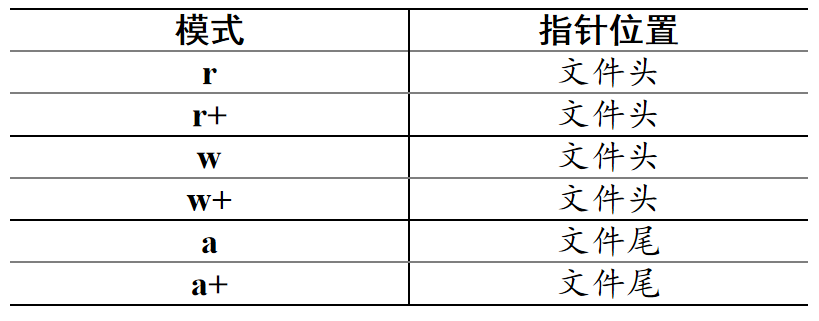
建立文件对象f之后,可调用其内置方法f.seek(offset[,where])移动指针的位置。
-
where定义了指针位置的参照点:
- 若where缺省,其默认值为0,即文件
头位置。 - 若where取值为1,则参照点为
当前指针位置。 - 若where取值为2,则参照点为文件
尾。
- 若where缺省,其默认值为0,即文件
-
offset参数定义了指针相对于参照点where的偏移量,取整数值:
- 如果offset取
正值,则往文件尾方向移动。 - 如果offset取
负值,则往文件头方向移动。
- 如果offset取
在文本文件中,如果没有使用“b”模式选项打开文件,从文件尾开始计算相对位置时就会引发异常。
因此,如果需要从文本文件的文件尾这个相对位置来计算指针的偏移量,需要使用“b”模式打开文本文件。
注意:
- 对指针位置重新定位时,指针可以往后移至任意位置,但不可移至文件头之前。
- 指针位置的计算都是以字节为单位。
- 在不同模式下打开的文件对象,文件指针的起始位置各不相同,详细情况请参见下表。
f = open('d:\\test.txt','rb')
f.seek(3) #从头前移3个字节:返回值是目前的指针的位置3
f.read(3) #读取3个字节,读取指针会后移
f.read(2) #读取2个字节
f.seek(-3,1) #从当前位置后退3个字节:返回移动后指针所在的位置5
f.read() #读取剩余全部字节
7.5 文件的压缩和解压缩
gzip和bz2模块实现了用于gzip和bz2格式压缩文件的open()函数,支持打开对应格式的压缩文件,从而实现压缩文件的读取和写入处理。
打开压缩文件的语法如下:
- f = gzip.open() #其语法格式与内置函数open()类似
- f = bz2.open() #其语法格式与内置函数open()类似
以gzip为例
gzip.open(filename, mode=‘rb’, compresslevel=9, encoding=None, errors=None, newline=None)
功能:打开一个gzip已经压缩好的gzip格式的文件,并返回一个文件对象。
参数:
- filename:文件名
- mode
二进制使用:‘r’,‘rb’,‘a’,‘ab’,‘wb’
文本文件使用:'rt,‘at’,‘wt’
默认是:‘rb’ - compresslevel:压缩级别,0-9的数值
#使用gzip模块压缩和解压缩文件的示例
import gzip # 1.导入gzip模块,gzip压缩格式
with gzip.open(r'd:\test.txt.gz', 'wt') as f: #压缩后的文件(准备生成的压缩文件),压缩文件对象f
for s in open(r'd:\test.txt', 'r'): #源文件(已经存在的文件)
f.write(s) #f:压缩文件对象,在write()时,会先压缩,再写入
# gzip 解压缩
for s in gzip.open(r'd:\test.txt.gz', 'r'): #直接迭代open方法返回的压缩文件对象,获取解压缩后的字符串
print(s)
在D盘可以看到压缩后生成的gz压缩文件,也可以用常规的压缩软件(360压缩等)打开。
7.6 CSV文件格式的读写
CSV文件
-
纯文本文件,可以用记事本打开; -
由任意数目的
记录(行)组成,记录间以某种换行符分隔; -
每条记录由
字段组成,字段间的分隔符最常见的是逗号或制表符; -
最广泛的
应用是在程序之间转移表格数据。
本节使用的scores.csv文件,其内容为
学号,姓名,性别,班级,语文,数学,英语
101511,宋颐园,男,一班,72,85,82
101513,王二丫,女,一班,75,82,51
101531,董再永,男,三班,55,74,79
101521,陈香燕,女,二班,80,86,68
101535,周一萍,女,三班,72,76,72
可以直接将上述内容,复制到记事本中,保存为scores.csv文件即可。
该文件可以直接用Excel或wps打开,也可以拖入VSCode打开(注意将右下角的字符编码改成GB18030)
1)csv.reader对象和csv文件的读取
csv.reader对象用于从CSV文件读取数据(格式为列表对象)。
其构造函数为:
csv.reader(csvfile,dialect=‘excel’,**fmtparams)
- csvfile是文件对象或list对象
- dialect用于指定CSV的格式模式
- fmtparams用于指定特定格式,以覆盖dialect中的格式
创建之后的reader对象包含以下属性:
- csvreader.dialect:返回其dialect
- csvreader.line_num:返回读入的行数
csv.reader对象是可迭代对象(可以直接用next()函数或for迭代每一行记录)
import csv
#-------------- readcsv1()函数 -------------------
def readcsv1(csvfilepath):
with open(csvfilepath, newline='') as f: #1.打开文件,自动关闭
f_csv = csv.reader(f) #2.创建csv.reader对象
headers = next(f_csv) #3.next对f_csv直接取首行(标题)
print(headers) #打印标题(列表)
for row in f_csv: #4.迭代后续的每一行:循环打印各行(每行是列表)
print(row) #也可以再对row列表迭代每个列值(for col in row:)
#--------------- 主程序 ----------------
readcsv1(r'scores.csv') #未指明磁盘等全路径时,指的是本ipynb文件所在的当前文件夹
2)csv.writer对象和csv文件的写入
csv.writer对象用于将列表对象写入到CSV文件。
其构造函数为:
csv.writer(csvfile,dialect=‘excel’,**fmtparams)
- csvfile是任何支持write()方法的对象,通常是文件对象
- dialect和fmtparams,与reader对象的构造函数中参数的意义相同
csv.writer对象支持下列方法:
- csvwriter.writerow(row):写入一行数据
- csvwriter.writerows(rows):写入多行数据
#【例】使用writer对象写入csv文件
import csv
#-------------- writecsv1()函数 -------------------
def writecsv1(csvfilepath):
headers = ['学号', '姓名', '性别', '班级', '语文', '数学', '英语']
rows = [('101511', '宋颐园', '男', '一班', '72', '85', '82'),
('101513', '王二丫', '女', '一班', '75', '82', '51')]
with open(csvfilepath,'w', newline='') as f: #1.打开文件,自动关闭
f_csv = csv.writer(f) #2.创建csv.writer对象
f_csv.writerow(headers) #3.写入1行(标题),list列表
f_csv.writerows(rows) #写入多行(数据),list列表还有元组(每一行)
#--------------- 主程序 ----------------
writecsv1(r'scores1.csv')
3)csv.DictReader对象和csv文件的读取
如果希望通过CSV文件的首行标题字段名访问,则可以使用csv.DictReader对象的构造函数,以返回字典dict(map映射):
csv.DictReader(csvfile,fieldnames=None,restkey=None,restval=None,dialect=‘excel’,*args,**kwds)
- csvfile:是文件对象或list对象
- fieldnames:用于指定字段名,如果没有指定,则第一行为字段名
- 可选的restkey和restval:用于指定字段名和数据个数不一致时,所对应的字段名或数据值;
- 其他参数同csv.reader对象
#【例】使用DictReader对象读取csv文件
import csv
#-------------- readcsv2()函数 -------------------
def readcsv2(csvfilepath):
with open(csvfilepath, newline='') as f: #1.打开文件
f_csv = csv.DictReader(f) #2.创建csv.DictReader对象
headers = next(f_csv) #3.next迭代f_csv,取到 首行(标题)
print(headers) #打印标题(字典)
for row in f_csv: #4.循环打印各行(字典)
print(row)
#--------------- 主程序 ----------------
readcsv2(r'scores.csv')
4)csv.DictWriter对象和CSV文件的写入
如果需要写入带有字段名称的数据(“键值对”的映射数据)到CSV,可以使用csv.DictWriter对象的构造函数:
csv.DictWriter(csvfile,fieldnames=None,restval=’’,extrasaction=‘raise’,dialect=‘excel’,*args,**kwds)
- csvfile:是文件对象或list对象
- fieldnames:用于指定字段名,如果没有指定,则第一行为字段名
- 可选的restval:用于指定默认数据
- 可选的extrasaction:用于指定多余字段时的操作
- 其他参数同csv.writer对象
#【例】使用DictWriter对象写入csv文件(csv_writer2.py)
import csv
#-------------- writecsv2()函数 -------------------
def writecsv2(csvfilepath):
headers = ['学号', '姓名', '语文', '数学', '英语']
rows = [{'学号': '101511', '姓名': '宋颐园', '数学': '85', '语文': '72','英语': '82'},
#故意语文和数学调换次序:依然写入正确,说明写入时是按照字段名,而不是顺序
{'学号': '101513', '姓名': '王二丫', '语文': '75', '数学': '82', '英语': '51'}]
with open(csvfilepath,'w', newline='') as f: #1.打开文件,准备写入w,自动关闭
f_csv = csv.DictWriter(f, headers) #2.创建csv.DictWriter对象
f_csv.writeheader() #3.写入标题
f_csv.writerows(rows) #4.写入多行(数据)
#--------------- 主程序 ----------------
writecsv2(r'scores2.csv')
5)csv文件格式化参数和Dialect对象
在创建reader/writer对象时可以指定CSV文件格式化参数,CSV文件格式化参数包括如下选项:
- delimiter:分隔符,默认为’.’
- quoting:用于指定使用双引号的规则,可以为csv模块中的常量QUOTE_ALL(全部)、QUOTE_MINIMAL(仅特殊字符字段)、QUOTE_NONNUMERIC(非数字字段)、QUOTE_NONE(全部不)
- doublequote、escapechar、lineterminator、quotechar、skipinitialspace、strict等自行查看文档
#格式化例子
import csv
#-------------- writecsv3()函数 -------------------
def writecsv3(csvfilepath):
headers = ['学号', '姓名', '性别', '班级', '语文', '数学', '英语']
rows = [('101511', '宋颐园', '男', '一班', '72', '85', '82'),
('101513', '王二丫', '女', '一班', '75', '82', '51')]
with open(csvfilepath,'w', newline='') as f:
f_csv = csv.writer(f, delimiter=':', quoting=csv.QUOTE_ALL) #指定格式化参数
#冒号分隔,数据加引号
f_csv.writerow(headers) #写入一行(标题)
f_csv.writerows(rows) #写入多行(数据)
#--------------- 主程序 ----------------
writecsv3(r'scores3.csv')
运行后,可以使用VSCode打开生成的scores3.csv文件(修改VSCode右下角的中文编码为GB18030),可以发现是符合格式的。
Dialect对象
若干格式化参数可以组成一个Dialect对象(方便多次使用),然后传递给reader或writer的构造函数
- csv.register_dialect(name[,dialect],**fmtparams):使用命名参数,**注册一个名称
- csv.unregister_dialect(name):取消注册的名称
- csv.get_dialect(name):获取注册名称的Dialect对象,无注册时将导致csv.Error
- csv.list_dialects():所有注册对象Dialect的列表
#【例】Dialect对象示例
import csv
#-------------- writecsv4()函数 -------------------
def writecsv4(csvfilepath):
csv.register_dialect('mydialect', delimiter=':', quoting=csv.QUOTE_NONE)
#1.冒号分隔,无引号,作为一种组合,起名为mydialect
headers = ['学号', '姓名', '性别', '班级', '语文', '数学', '英语']
rows = [('101511', '宋颐园', '男', '一班', '72', '85', '82'),
('101513', '王二丫', '女', '一班', '75', '82', '51')]
with open(csvfilepath,'w', newline='') as f: #2.打开文件
f_csv = csv.writer(f, 'mydialect') #3.创建writer对象:指明已经在csv中注册的一个 mydialect
f_csv.writerow(headers) #4.写入首行(标题)
f_csv.writerows(rows) #5.写入多行(数据)
#--------------- 主程序 ----------------
writecsv4(r'scores4.csv')
import csv
csv.list_dialects() #列出所有已注册的Dialect对象:['excel','excel-tab','unix','mydialect
7.7 json模块和JSON格式数据
JSON(JavaScript Object Notation,JavaScript对象标记)定义了一种标准格式,用字符串来描述典型的内置对象(如字典、列表、数字和字符串)。JSON是网络数据交换的流行格式之一。
JSON表示对象:
{“firstName”: “Brett”, “lastName”: “McLaughlin”}JSON表示数组: {
“name”: “中国”,
“province”: [{
“name”: “黑龙江”,
“cities”: {
“city”: [“哈尔滨”, “大庆”]
}
}, {
“name”: “广东”,
“cities”: {
“city”: [“广州”, “深圳”, “珠海”]
}
}, {
“name”: “台湾”,
“cities”: {
“city”: [“台北”, “高雄”]
}
}, {
“name”: “新疆”,
“cities”: {
“city”: [“乌鲁木齐”]
}
}]
}
你可以发现,JSON和Python的各种组合数据结构的格式,是一样的。
所以,Python读写JSON格式非常方便。
Python标准库中的json模块可以读写JSON格式的文件:
-
dumps(obj):把obj对象序列化为JSON字符串
-
dump(obj, fp):把obj对象序列化为JSON字符串,再写入到文件fp
-
loads(s):把JSON字符串s反序列化后的对象
-
load(fp):从文件fp中读取JSON字符串反序列化后的对象
#【例】对象JSON格式系列化示例
import json
data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] #列表
str_json = json.dumps(data)
str_json #输出:'[{"a": "A", "c": 3.0, "b": [2, 4]}]'
data1 = json.loads(str_json)
data1 #输出:[{'a': 'A', 'c': 3.0, 'b': [2, 4]}]
八、类与对象
8.1认识类与对象
在Python中,所有的数据(包括数字和字符串)实际上都是对象,每个对象都属于某个类型。
万物皆对象,对象都有类
类
在Python中,使用类来定义同一种类型的对象。
类(class)是广义的数据类型,能够定义复杂数据的特性,包括静态特性和动态特性。
- 属性:静态特性(数据抽象),使用变量存储数据域;
- 方法:动态特性(行为抽象),对数据执行操作。
对象
对象是类的一个实例,一个类可以创建多个对象。
创建类的一个实例的过程被称为实例化。
在术语中,对象和实例经常是可以互换的。对象就是实例,实例就是对象。
类和对象的关系
相当于普通数据类型和它的变量之间的关系。比如
- 可以定义一个鸟类(Bird),那么一只具体的宠物鹦鹉parrot就是这个鸟类的一个对象,动物园里的一只会表演的八哥也是这个鸟类的一个对象;
- 可以定义一个股票类(Stock),那么某一支具体的股票就是这个股票类的一个对象。
总结,类和对象的关系:
1.类是对象的抽象,而对象是类的具体实例;
2.类是抽象的,而对象是具体的;
3.每一个对象都是某一个类的实例;
4.每一个类在某一时刻都有零或更多的实例;
5.类是静态的,它们的存在、语义和关系在程序执行前就已经定义好了;对象是动态的,它们在程序执行时可以被创建和删除;
6.类是生成对象的模板。
8.2类的定义
在Python 2及以前的版本中,类分为经典类和新式类。
-
经典类:- 类可以有父类(若定义时,指定父类)
- 也可以没有父类(若定义时,未指定父类)
-
新式类:
- object类是祖先类(最顶层的类,唯一没有父类的类)
- 其他所有的类都有父类,并且都直接或间接地继承自object
在Python3中,所有的类都是按新式类来处理
Python中使用class保留字来定义类,类名的首字母一般要大写。
类的主要成员包括两种类型,即描述状态的数据成员(属性)和描述操作的函数成员(方法)。
定义格式:
class <类名>:
类属性1
……
类属性n
<方法定义1>
……
<方法定义n>
创建类的对象
类是抽象的,如果要使用类定义的功能,就必须实例化类,即创建类的对象。
在创建实例对象后,就可以使用"."运算符来调用其成员。
注意:创建类的对象、创建类的实例、实例化类等说法是等价的,都是以类为模板生成了一个对象。
实例对象的创建和调用格式如下:
- 对象名 = 类名(参数列表)
- 对象名.对象函数() 或 对象名.对象属性
# -------- Person类 ----------
class Person: #定义类 Person
pass #类体为 空(演示而已)
# --------- 主程序 -----------
p1 = Person() #创建Person类的对象p1
print(Person,type(Person),id(Person)) #类对象的类型、地址
print(p1,type(p1),id(p1)) #实例对象的类型、地址
p2 = Person()
print(p2,type(p2),id(p2))
上面的演示类Person,是空类。
一般来说,类中应该有属性、方法。
8.3类的属性
属性:类的数据成员,是在类中定义的成员变量,用来存储描述类的特征的值。
- 属性可以被该类中定义的方法访问
- 也可以通过类或实例对象进行访问
注意和“局部变量”的区别
局部变量:在函数体或代码块中定义的变量,只能在其定义的范围内访问。
8.3.1 类属性和实例属性
类中的属性有两种:类属性和实例属性(对象属性)。
-
类属性:
- 类属性属于整个类,不是特定实例的一部分,而是所有实例之间共享一个副本
- 比如,某学校中的Teacher的schoolName是类属性,因为所有该Teacher类的对象都共享这一个属性
- 是在类中方法之外定义的
-
实例属性:
- 类的每个实例都包含了该类的实例对象变量的一个单独副本,实例对象变量属于特定的实例。
- 各个实例拥有的实例属性都互相独立,互不影响。
- 比如,Teacher类的name是实例属性,因为每个Teacher的对象都有不同的名字。
- 是在初始化方法__init__()之中定义的,定义时以self为前缀
- 只能通过对象名访问
先看, 类属性的用法
首先,类属性一般在类体中(方法以外)通过如下形式初始化:
类属性变量名 = 初始值
然后,在其类定义的方法中或外部代码中通过类名访问:
类名.类属性名 = 值 #写入
类名.类属性名 #读取
定义鸟类,其共同属性是有羽毛,有各种鸣叫方式,再定义一个类的方法移动(move())。假设养了一只鹦鹉,名叫parrot。它就是鸟类的一个对象,根据鸟类的定义来创建这个对象,并输出相关属性
#----------- 类:Bird -------------
class Bird:
have_feather=True #两个 类属性:在方法以外,又必须在类体内
way_of_song="叽叽喳喳"
def move(self): #普通方法
print('飞飞飞飞')
#print(Bird.have_feather) #如果要在本类的方法中访问类属性,也要加上 类名Bird
# ---------------- 主程序 ---------------------
print(Bird.have_feather) #1.类名.类属性
print(Bird.way_of_song)
print()
bird1=Bird() #创建Bird类的一个对象,名为parrot
bird1.move() #让对象parrot执行move()方法
print('有羽毛' if bird1.have_feather else '没羽毛') #单行的if else。可以用对象名,但不建议
print("parrot"+bird1.way_of_song) #2.对象名.类属性 (不建议:容易误解为实例属性)
类属性的修改和增加都是直接通过“类名.属性名”访问。
在下例中修改了鸟类Bird的way_of_song类属性,并且增加了legs类属性。
Bird.way_of_song="叽叽叽叽" #修改 类属性
Bird.legs=2 #增加 类属性
print(Bird.way_of_song)
print(Bird.legs)
再看, 实例属性的用法
首先,实例属性在__init__()方法中通过如下形式初始化:
self.实例变量名 = 初始值
然后,在本类的其他实例方法中:通过self访问:
self.实例变量名 = 值 #写入
self.实例变量名 #读取
或者,在本类之外,创建对象实例后:通过对象实例访问:
obj1 = 类名() #创建对象实例
obj1.实例变量名 = 值 #写入
obj1.实例变量名 #读取
定义Rectangle类表示矩形。该类有两个实例属性width和height,均在构造方法中定义,有两个方法getArea和getPerimeter分别计算矩形的面积和周长。
class Rectangle:
def __init__(self,w,h):
self.width=w #定义两个实例属性:width和height
self.height=h
def getArea(self):
return self.width * self.height #1.在本类的其他实例方法中,是可以访问实例属性的
def getPerimeter(self):
return (self.width + self.height) * 2
#主程序
t1=Rectangle(15,6) #创建Rectangle的一个对象t1,宽为15,高为6
print("矩形t1的宽:",t1.width,",高:",t1.height) #2.用创建的对象t1,访问其实例属性
print("矩形t1的面积:",t1.getArea())
print("矩形t1的周长:",t1.getPerimeter())
t1.width=8 #修改对象的实例属性
print("矩形t1新的宽:",t1.width)
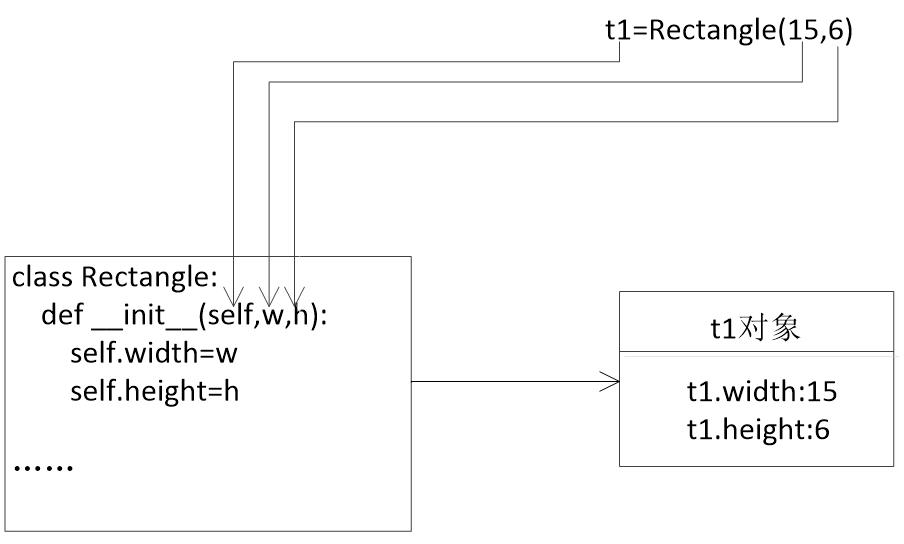
当使用t1=Rectangle(15,6)创建t1对象时,Python自动调用__init__()方法,传递给该方法的实参是t1、15、6,相当于函数调用__init__(t1,15,6),这样就为对象t1进行了初始化操作,变量width赋值15,变量height赋值6,width和height均属于实例属性。也就是说创建了一个Rectangle类的宽为15,高为6的矩形对象t1。
8.3.2 属性的访问权限
类中的属性根据外部对其访问的权限,分为公有属性、保护属性和私有属性。
-
没有以任何下画线开头的属性是
公有(public)属性:
- 在任何地方均可以访问该属性。
-
“单下画线” 开始的属性是
保护(protected)属性:
- 只有其本身和子类能访问到这些属性。【留待下一章 继承,讲解】
-
“双下画线” 开始的属性是
私有(private)属性:
- 只有该类的对象能访问,即使子类对象也不能访问到这个属性。
-
但是,Python的
私有
属性,并不是真正意义的私有,而是一种
伪私有
。
- 私有属性可以通过“对象名._类名__私有属性名”的方式直接访问;
- 这种访问方式破坏了类的封装性。
- 所以,在日常开发中,不要使用这种方式访问私有属性。
class Person:
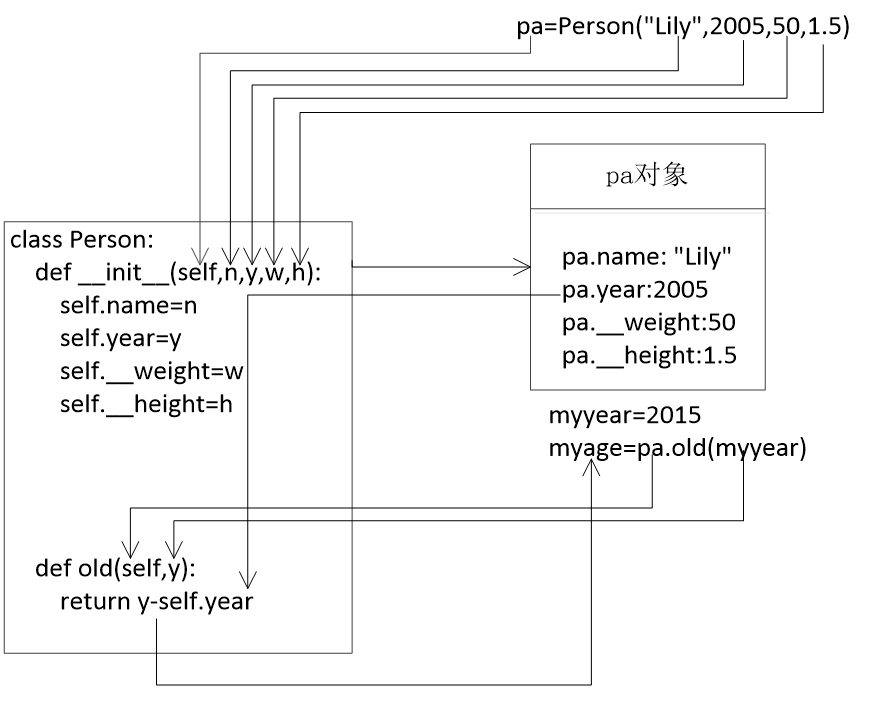
def __init__(self,n,y,w,h): #构造方法
self.name=n #定义公有属性:姓名name和出生年份year
self.year=y
self.__weight=w #定义私有属性:以千克为单位的体重weight、以米为单位的身高height
self.__height=h
def old(self,y): #普通方法:计算年龄=参数年份y-对象属性year
#print("体重为",self.__weight) #在本类的其他方法中,可以访问self.__私有属性名
return y-self.year #访问本类的公有属性
#主程序
pa=Person("Lily",2005,50,1.5) #创建Person类的对象pa
print("姓名为",pa.name,",体重为",pa._Person__weight,"千克") #访问对象的公有,私有属性(不建议)
pa._Person__weight=48 #访问私有成员(不建议):Person是类名,前单后双的下划线
print("现在的体重为",pa._Person__weight,"千克") #访问私有成员(不建议)
#print(pa.__weight) #错误,不能直接访问私有成员
myyear=2020
myage=pa.old(myyear) #调用普通方法,计算年龄差
if myage>0:
print("到"+str(myyear)+"年"+str(myage)+"岁")
elif myage<0:
print(str(myyear)+"年还没出生呢,出生于"+str(pa.year)+"年")
else:
print(str(myyear)+"年刚出生")
类中定义的实例方法都必须以self作为第一个参数,这个参数表示当前是哪一个实例对象要执行类的方法,这个实参由Python隐含地传递给self。图8.4表示例8-4中创建Person类对象以及对象的old()方法调用的过程
8.4类中的方法
8.4.1实例方法
类中的每个方法其实都是一个函数定义,但,与函数略有差别:
-
1.每个实例方法的第一个参数都是self,self代表将来要创建的对象实例本身。
-
2.实例方法的调用:
- 可以被本类的其他方法调用:self.方法名()
- 也可以在本类之外,创建本类的对象,然后通过**对象名.方法名()**来调用(即向对象发消息请求对象执行某个方法)
实例方法的声明格式如下:
def 方法名(self [,形参列表]):
函数体
注意:
- 虽然方法的第一个参数为self,但调用时,用户并不需要,也不能给该参数传值
- Python会自动把实例对象传递给该参数
实例方法的调用格式如下:
对象名.方法名([实参列表])
#------------- 定义类Person -----------------
class Person:
def say_hi(self, name): #定义方法say_hi()
self.name = name #把参数name赋值给self.name,即成员变量name(域)
#注意两个name的区别(形参name和实例属性self.name)
print('您好, 我叫', self.name)
#-------------- 主程序 -----------------
p = Person() #创建对象实例
p.say_hi('Alice') #调用实例方法
p.name #读取实例属性
8.4.2 实例方法的访问权限
实例方法根据外部对其访问的权限,可分为3种:公有方法、保护方法和私有方法。
-
开头既没有单下画线,也没有双下画线的方法是
公有(public)方法:
- 允许任何对象进行访问
- 公有方法可以通过对象名调用。其调用形式为:“对象名.公有方法(<实参>)”
-
以单下画线开头的方法是
保护(protected)类型的:【留待 下一章 继承 讲解】
- 只允许其本身与子类进行访问
- 也不能用于 from module import *
-
双下画线开头的是
私有(private)方法:
- 只允许这个类本身进行访问
-
但是,Python的私有方法,同样,也不是真正意义的私有,也是一种
伪私有
。
- 私有方法可以通过“对象名._类名__私有方法名”的方式直接访问;
- 这种访问方式破坏了类的封装性。
- 所以,在日常开发中,也不要使用这种方式访问私有方法
# ------------------------ 类:Book -------------------------------
class Book: #定义类Book
def __init__( self,name, author, price):
self.name = name #把参数name赋值给self.name,即实例属性name
self.author = author #把参数author赋值给self.author,即实例属性author
self.price = price #把参数price赋值给self.price,即实例属性price
def __check_name(self): #定义私有方法(双下划线),判断name是否存在
if self.name == '' : return False
else: return True
def get_name(self): #定义类Book的方法get_name
if self.__check_name():print(self.name,self.author) #本类中,调用私有方法
else:print('No value')
# -------------------------- 主程序 --------------------------
b = Book('Python程序设计教程','江红',59.0) #创建对象
b.get_name() #调用对象的方法
#b.__check_name() #直接调用私有方法,非法,出错
b._Book__check_name() #通过对象名._类名__方法名()是可以调用的。但,不建议这么做。
8.4.3 实例的构造与初始化
特殊方法
一个类中有两个特殊的方法:new()和__init__()。
这两个方法合起来类似于Java和C++等程序设计语言中的构造方法:用于创建并初始化一个对象。
-
1.new()方法用于创建对象:
- 当实例化(创建)一个类对象时,最先被调用的是__new__()方法
- 必须有返回值:创建的对象
-
2.init()方法用于执行类的实例的初始化工作:
- new()方法创建完对象后,将该对象传递给__init__()方法中的self参数,开始初始化对象的状态
- 无返回值。(Java的构造方法也没有返回值)
-
3.这两个方法都是在实例化对象时被
自动调用的,不需要程序显式调用。 -
4.如果用户未设计__init__()方法,Python将提供一个
默认的__init__()方法。 -
5.
子类如果想调用父类(基类)的__init__()方法,必须显式调用,否则子类的__init__()方法不会自动调用父类的__init__()方法。
new()方法说明
- 当实例化一个类对象时,最先被调用的是__new__()方法;
- new()方法用于创建对象: new()方法创建完对象后,将该对象传递给__init__()方法中的self参数,init()方法紧接着进行对象的初始化;
- new()方法是一个静态方法,在object类(根类)中已经定义,因此不用每次定义类的时候都声明这个方法;
- 如果类定义中没有重写该方法,将使用从父类继承而来的__new__()方法。
# ------------- 类:Person ------------------
class Person(object): # 1.此处,括号中object类是Person的父类
def __new__(cls, name, age): #2.第一个参数cls表示需要实例化的类,由Python解释器自动提供
print('执行__new__方法。') # 增加一句输出
return super(Person, cls).__new__(cls) #3.然后,再调用父类的new方法。super表示父类
#4.必须返回创建的对象:要么自己创建,要么父类创建的对象
def __init__(self, name, age): #5.self参数就是 __new__()返回的对象
print('执行__init__方法。')
self.name = name
self.age = age #6.完成对象的初始化工作,不需要返回值
def getName(self):
return self.name
def getAge(self):
return self.age
#主程序
if __name__ == '__main__': #8.第一次出现这种句式,解释见下
p = Person('Tom', 24) #7.从输出结果可见:先执行__new__()方法,再执行__init__()方法
print('姓名:', p.getName())
print('年龄:', p.getAge())
绝大多数情况下,都不需要提供__new__()方法。
何时需要呢?
new()方法的作用
- Python官方文档:new()方法是当你继承一些不可变的class时(比如int, str, tuple), 提供给你一个自定义这些类的实例化过程的途径。
- 很少用,不再提供例子了。
补充:
new()方法的一个应用:实现单例模式(singleton)。
单例模式:
- 整个程序有且仅有类的一个实例。
- 该类负责创建自己的对象,同时确保只有一个对象被创建。
因为类每一次实例的过程都是通过new来控制的,所以通过重载new方法,我们可以很简单的实现单例模式。
#---------- 类: --------------
class Single():
def __new__(cls): #重定义了 __new__()
# 关键:每一次实例化的时候,都只会返回同一个instance对象
if not hasattr(cls, 'instance'): # hasattr()函数用于判断对象是否包含对应的属性
# 如果没有某个约定的属性(说明还没有对象),则
cls.instance = super(Single, cls).__new__(cls)
#新创建一个对象,并设置给这个约定的属性
return cls.instance # 如果有/已创建,则返回这个属性(实例本身)
#---------- 主程序 --------------
obj1 = Single() #表面看,创建了两个对象。但其实,这两行运行时,只创建一个对象
obj2 = Single() #而本行运行时,会发现已经存在一个对象了,就会直接返回已有的对象
print(id(obj1),id(obj2)) # 输出两个对象的id,会发现是相同的。其实,obj1和obj2都指向同一个对象,
obj1.attr1 = 'value1' # 给obj1的属性赋值,会导致obj2也有这个属性
print(obj1.attr1, obj2.attr1) # 并且,两个对象的属性值,也是相同的
print(obj1 is obj2) # is :判断两个对象是不是同一个对象。结果为 真。
8.4.4 析构方法:del()
del()析构方法用于销毁类的实例,如释放对象占用的资源(例如打开的文件,网络连接等)。
在默认情况下,当对象不再被使用时,Python解释器会自动进行垃圾回收,这时会执行__del__()方法。但是,Python解释器的垃圾回收时间是不确定的,所以无法保证这个方法究竟在什么时候运行。
通过
del命令语句可以强制销毁一个对象实例:该语句会立即触发python调用该对象的__del__()方法如果类没有提供__del__()方法,Python会提供默认的__del__()方法。
# --------------- 类:Pizza --------------------
class Pizza:
def __init__(self,d):
self.diameter=d #披萨的大小尺寸
print("调用__init__方法")
def __del__(self):
print("调用__del__方法")
# ---------------主程序 --------------------
pz1=Pizza(8) #创建第1个对象,pz1是指向该对象的引用:该对象的引用计数为1
pz2=Pizza(10) #创建第2个对象,pz2是指向该对象的引用:该对象的引用计数为1
pz3=pz2 #第3个对象引用pz3(没有创建新对象)和pz2 指向同一个对象:该对象的引用计数增为2
print('准备删除pz1')
del pz1 #因为该对象的引用计数为1,可以__del__方法删除
print('准备删除pz2')
del pz2 #该对象的引用计数为2(还有一个pz3的引用),暂时不能调用__del__()方法(只将引用计数-1)
print('准备删除pz3')
del pz3 #此时,该对象的引用计数为1,就可以调用__del__()方法了
8.4.5 静态方法与类方法
静态方法:(概念同 Java的静态方法)
- 静态方法的定义之前需要添加“
@staticmethod”。 - 静态方法定义时,
不需要表示访问对象的self参数,形式上与普通函数的定义类似。 - 静态方法只能访问属于
类的成员(类属性、类方法),不能访问属于对象的成员(实例属性、实例方法)。 - 一个类的所有实例对象
共享静态方法。 - 使用静态方法时,既可以通过“
类名.静态方法名()”来访问,也可以通过“对象名.静态方法名()”来访问(不建议,容易被误解为实例方法)。
静态方法通过装饰器@staticmethod来定义
@staticmethod
def 静态方法名([形参列表])
函数体
静态方法一般通过类名来访问,也可以通过对象实例来调用(不建议)。
类名.静态方法名([实参列表])
或者
对象名.静态方法名([实参列表])
# --------------- 类:Person --------------------
class Person:
number=0 #类属性(各对象共享):Person对象的总计数
def __init__(self,name):
self.name = name
Person.number+=1 #每次创建对象的时候,+1
def getName(self):
print('My name is ',self.name)
@staticmethod #声明静态方法,去掉则编译报错
def getNumber(): #静态方法没有self
print("总人数为:",Person.number)
# --------------- 主程序 ---------------
p1 = Person("Tom")
p1.getName()
p1.getNumber() #对象名.静态方法()(不建议,容易误解为普通方法):返回1
Person.getNumber() #类名.静态方法():返回1
p2=Person('Alice') #类属性number = 2
p2.getName()
p2.getNumber() #对象名.静态方法()(不建议,容易误解为普通方法):返回2
Person.getNumber() #类名.静态方法():返回2
p1.getNumber() #会返回2:因为getNumber()是类的静态方法,number是类属性(p1和p2共享)
类方法
- 允许声明属于类本身的方法,即
类方法 - 类方法中,一般对
类本身进行操作。 - 类方法
不能对特定实例进行操作,在类方法中访问对象实例属性会导致错误 - 使用类方法时,既可以通过“
类名.类方法名()”来访问,也可以通过“对象名.类方法名()”来访问(不建议,容易被误解为实例方法)。
类方法通过装饰器@classmethod来定义,第一个形式参数必须为类对象本身,通常为cls
@classmethod
def 静态方法名(cls,[形参列表])
函数体
注意:
- 虽然类方法的第一个参数为cls,但调用时,用户*不需要* 也*不能* 给该参数传值
- Python会*自动* 把实例对象传递给该参数
类方法一般通过类名来调用,也可通过对象实例来调用(不建议)
类名.类方法名([实参列表])
或者
对象名.类方法名([实参列表])
class Foo:
classname = "Foo" #类属性
def __init__(self, name): #初始化方法
self.name = name
print("init:",self.name)
def f1(self): #实例方法
print("f1():",self.name)
@staticmethod
def f2(): #静态方法
print("static")
@classmethod
def f3(cls): #类方法:cls实际是Foo类名
print("classmethod",cls.classname) #访问的是类属性classname。不能访问实例属性。
#self.name
# --------------- 主程序 --------------------
f = Foo("李四") #会调用 初始化方法__init__()
f.f1() #用 对象名.实例方法()
Foo.f2() #用 类名.静态方法()
Foo.f3() #用 类名.类方法()
# --------------- 父类:Person --------------------
class Person(object):
__number = 0 #私有的类属性(只有一份,所有类的对象共享)
def __init__(self):
Person.__number += 1
@classmethod
def getNumber(cls): #类方法
return cls.__number
# --------------- 子类:Student -------------------
class Student(Person):
def __init__(self, name):
self.name = name
super().__init__() #必须显式调用父类的__init__()方法,否则,不会调用
#若注释掉本行,就不再调用父类的init(),Person的number就不再加1,输出结果就不同了
# ------------- 主程序 --------------
s1 = Person() #父类Person的对象
print(s1.getNumber()) #对象名.类方法():输出1;不建议
print(Person.getNumber()) #直接用 类名.类方法():输出1
s2 = Student("Alice") #子类Student的对象
print(s2.getNumber()) #子类Student继承了父类Person的类方法getNumber(),可以使用:输出2
print(Person.getNumber()) #直接用 类名 来调用类方法:输出2
print(s1.getNumber()) #number是类属性,s1、s2共享:也输出2:
实例方法、静态方法与类方法的区别:
修饰符不同:
- 实例方法:不需要修饰符
- 静态方法:依赖于“@staticmethod”修饰符
- 类方法:依赖于“@classmethod”修饰符
参数不同:
- 实例方法:第一个参数使用self表示调用对象
- 类方法:第一个参数使用cls表示调用的类
- 静态方法:不需要这些附加参数
调用方式不同:
- 实例方法:只能通过实例对象调用
- 类方法 和 静态方法 可以通过类对象或者实例对象调用,如果是使用实例对象调用的类方法或静态方法,最终都会转而通过类对象调用
作用不同:
- 实例方法:用于处理实例属性,完成对象的动态行为。
- 静态方法:主要是用来存放逻辑性的代码,逻辑上属于类,但是和类本身没有关系,也就是说在静态方法中,不会涉及到类中的属性和方法的操作。可以理解为,静态方法是个独立的、单纯的函数,它仅仅托管于某个类的名称空间中,便于使用和维护。此时的类,更像是命名空间或者包。
- 类方法:是将类本身作为对象进行操作的方法,直接处理类对象。假设有个方法,且这个方法在逻辑上采用类本身作为对象来调用更合理,那么这个方法就可以定义为类方法。
8.5 可变对象与不可变对象
首先,要分清 对象本身 与 对象引用的区别
- Python中所有数据都是对象,对象是存储在内存的区域内(前面的图中的对象);
- 对象名是指向对象的引用。
其次,可变对象的值是可以改变的;不可变对象的值不能改变。
最后,在Python的内建标准类型中,哪些是可变对象,哪些是不可变对象?
- 列表、字典和集合为可变类型。用户自定义类的对象是可变对象。
- int,float,bool,str,元组 为不可变类型。
函数调用中的可变与不可变对象
Python的函数调用,参数传递都是 传地址 的。 但是,实参类型不同,会导致结果不同。
- 当一个 可变对象 传给函数时:函数内可以改变这个对象的内容,会影响到实参。
- 当一个 不可变对象 传给函数时:修改对应的形参的值,会生成新的对象;实参对象不会被改变。
自定义的类也是可变对象,作为参数。# ---------------- 函数 increment() -------------------
def increment(n,i):
print('第3行:函数体内,执行加法之前,形参变量n的地址为:',id(n))#和实参地址相同
n+=i
print("第4行:函数体内,加完i之后, n :",n) #n指向新的值,不再和实参相同了
print('第5行:函数体内,执行加法之后,形参变量n的地址为:',id(n))#n指向新的地址
#主程序
#-- 第1次调用:不可变对象作实参 --
x=1 #int,不可变对象
print("第1行:调用function函数前,变量x所指向的地址:",id(x)) #第1行
print("第2行:执行increment函数之前, x :",x) #第2行:x = 1
increment(x,2) #输出第3、4、5行
print("第6行:执行increment函数之后, x :",x) #第6行:x不变,依然为1
print("第7行:调用function函数后,变量x所指向的地址:",id(x)) #第7行:x依然指向原地址
自定义的类也是可变对象,作为参数。
# ------------------ 类:Point -----------------------
class Point:
def __init__(self,x,y):
self.x=x
self.y=y
#------------------- 全局函数:increment -------------
def increment(c,times):
while times>0:
c.x += 5
c.y += 5
times -= 1
print("inside c.x,c.y:,times:",c.x,c.y,times)
# -------------------- 主程序 -----------------------
myc=Point(10,20)
times=5
print("begin:myc.x:",myc.x,",myc.y:",myc.y) #第1行:x:10 y:20
print("begin:times:",times) # 第2行:times:5
increment(myc,times) #参数myc:可变对象(自定义) ,参数times:int,不可变对象
print("after increment,myc.x:",myc.x,",myc.y:",myc.y)
#myc随着函数形参c修改而变化:myc.x:35 myc.y:45
print("after increment,times is",times) #不可变对象作实参:不变,依然是5
在上述程序代码中定义了Point类,属性x、y表示一个点的坐标,increment函数表示共经过times次,每次x、y的值均加5。
在主程序中,创建了一个Point对象myc,x、y坐标分别为10、20,定义了一个int对象times,初始值为5;在increment函数中,Point对象c的x、y属性均增加5,c.x+=5,c.y+=5分别创建新的int对象,并将它赋值给c.x和c.y,myc与c均指向同一个对象;当increment函数完成后,myc.x和myc.y为35、45,跟调用函数之前的值相比发生了改变,而times-1创建一个新的int对象,它被赋值给times,在函数increment之外,times的值还是5。
将一个对象传递给函数,就是将这个对象的引用传递给函数,传递不可变对象和传递可变对象是不同的。像数字、字符串这样的不可变对象,函数外的对象的原始值并没有被改变。而像point类、列表这样的可变参数,如果对象的内容在函数内部被改变,则对象的原始值也被改变。
8.6 get和set方法
通过给对象的实例属性赋值,可以改变该对象的实例属性值。
如在例对于对象t1,可以通过t1.width=8这样的赋值语句改变实例属性width的值,
但是这样直接访问数据域可能会带来一些问题。
- 可能直接设置成不合法的值:就像上面提到的t1.width=8如果写成t1.width=-8,那么这个宽度width就是不合法的,
- 也会导致类难以维护并且易于出错。
为了避免客户端直接修改属性的问题,可以提供get方法返回值,set方法设置新值。
通常get方法被称为获取器或访问器,set方法被称为设置器或修改器。
Rectangle类的定义,用get和set方法来获取值和设置值。
# ------------------ 类:Rectangle -----------------------
class Rectangle:
def __init__(self,w,h):
self.__width=w #实例属性 私有:
self.__height=h
def getArea(self):
return self.__width*self.__height
def getPerimeter(self):
return (self.__width+self.__height)*2
def getWidth(self): #两对 get和set公有方法:访问 两个私有实例变量
return self.__width
def getHeight(self):
return self.__height
def setWidth(self,w):
if w>0:
self.__width=w
else:
print("宽度width有误")
def setHeight(self,h):
if h>0:
self.__height=h
else:
print("高度height有误")
# ------------------ 主程序 -----------------------
r=Rectangle(25,16)
print("矩形t2的宽:",r.getWidth(),",高:",r.getHeight()) #get方法
print("矩形t2的面积:",r.getArea())
print("矩形t2的周长:",r.getPerimeter())
r.setWidth(8) # set方法
print("矩形t2新的宽:",r.getWidth())
r.setWidth(-8) #set方法
print("矩形t2新的宽:",r.getWidth())
程序解释:
在上面代码Rectangle类中,通过getWidth和getHeight方法获取对象的私有width和height属性值,通过setWidth和setHeight方法设置对象的私有width和height属性值,如果设置的值不符合要求,则打印有误信息。
在主程序中,创建了一个width为25,height为16的Rectangle类对象t2,然后通过调用getWidth和getHeight方法获得width和height的值,调用getArea 和getPerimeter方法计算出面积和周长,随后通过setWidth方法将width设置成8,并将新的width打印出来,最后还是通过setWidth方法将width设置成-8,由于数据不符合要求,打印出错误信息,width还是原来的8没有改变。
由于类中两个对象属性是私有的,无法在主程序中通过对象名直接访问私有属性。
九、类的重用
9.1 类的重用方法
类的重用技术:是指复用已有的代码,而不必从头开始编写。
比如,可以使用系统标准类库、开源项目中的类库、自定义类等已经调试好的类,从而降低工作量并减少错误的可能性。
类主要有两种重用方法:继承与组合。
- 继承:是指在现有类的基础上创建新类,以扩展原有类的属性(数据成员)和方法(成员函数)。
- 组合:是指在新创建的类中,将已有类的对象作为其属性。
9.2 类的继承
继承:是在父类(或称为基类)的基础上 扩展 新的属性和方法。
子类
- 自动具备 所有祖先类(不仅仅父类)中的非私有属性和非私有方法;
- 子类也可以增加新的属性和方法;
- 子类也可以通过重定义来覆盖从父类继承而来的方法。
object类
- 在Python语言中,object类是所有类的最终父类,所有类最顶层的根类都是object类。
如何从object继承?
- class ClassName():若没有明确指定父类,则默认从Python的根类object继承。
- class ClassName(object):指明父类为object也可以
多重继承
- Python支持多重继承,即,一个类可以有多个父类,同时从多个父类中继承所有特性。
- Java和C#都不支持多重继承。
何时用继承?
- 是否使用继承的基准:子类和父类是一种“is-a”(子类是父类的一种)的关系
- 比如:Cat
是一种Animal ;SmartMobilePhone是一种MobilePhone。
9.2.1 继承的语法
类的继承定义的语法:
class ChildClassName(父类名1[, 父类名2[,父类名3, …]]):
类体或pass语句
说明:
- 小括号()内为父类,可以有多个父类;
- 如果圆括号中没有父类,则表示从object类派生;
- 如果只是给出一个定义,尚没有定义类体时,可以使用pass语句(空语句)代替类体。
根据类图与下面的描述,来定义父类与子类:
1.产品Product的属性包括:
产品编号(ID)、名称(name)、颜色(color)、价格(price)、重量(weight)。
2.计算机Computer除具有产品Product所具有的基本属性外,还有如下属性:
内存(memory)、硬盘(disk)、中央处理器(CPU)。
3.手机MobilePhone类除具有产品Product类所具有的基本属性外,还具有如下属性:
第几代手机(generation)、网络制式(networkstandard)。
4.智能手机SmartMobilePhone类既具有手机MobilePhone类的特征,也具有计算机Computer类的特征,另外还具有如下特征:前置摄像头像素(frontCamera)、后置摄像头像素(rearCamera)、是否支持wifi热点(wifiHotSupport)。【本类暂不实现,留在后面的多重继承部分实现】
class Product(object): # 继承自object根类
id = 0 # 1个类属性
def __init__(self,name,color,price,weight):
Product.id=Product.id+1
self.name=name # 4个实例属性:公开
self.color=color
self.price=price
self.weight=weight
print('创建了一个Product对象. ID是'+str(Product.id))
def setPrice(self,price):
self.price=price
def getPrice(self):
return self.price
#--------------------- 子类:Computer -----------------------
class Computer(Product):
def __init__(self,name,color,price,weight,memory,disk,processor):
super(Computer,self).__init__(name,color,price,weight)
self.memory=memory
self.disk=disk
self.processor=processor
print('创建了一个Computer对象. 名字name是 ', name)
#--------------------- 子类:MobilePhone -----------------------
class MobilePhone(Product):
def __init__(self,name,color,price,weight,generation,networkstandard):
super(MobilePhone,self).__init__(name,color,price,weight)
self.generation=generation
self.networkstandard=networkstandard
print('创建了一个MobilePhone对象. 名字name是 ', name)
#------------------------- 主程序 -------------------------
def main():
c=Computer("联想笔记本电脑",'Black',5800,'2kg','4096K','128G','Intel')
m=MobilePhone("Nokia",'Black',600,'0.3kg','4G','TD-SCDMA')
print("产品名称:"+c.name+",产品价格:"+str(c.getPrice()))
print("产品名称:"+m.name+",产品价格:"+str(m.getPrice()))
if __name__ == "__main__":
main()
9.2.2子类继承父类的属性
父类的哪些属性可以继承?
-
非私有属性(公有、保护):
- 可以继承;
- 可以访问。
-
私有属性:
- 不能
继承; - 也无法在子类中
访问父类的私有属性; - 子类只能通过父类中的
公有方法访问父类中的私有属性
- 不能
#--------------- 父类:Product --------------------
class Product(object):
id = 0 #类属性:1个
def __init__(self,name,color,price):
Product.id=Product.id+1
self.name=name #公有实例属性
self.color=color #公有实例属性
self.__price=price #私有实例属性
def setPrice(self,price): #公有set和get方法
self.__price=price
def getPrice(self):
return self.__price
#--------------- 子类:MobilePhone --------------------
class MobilePhone(Product):
def __init__(self,name,color,price,networkstandard):
super(MobilePhone,self).__init__(name,color,price) #调用父类的init方法,3个属性初始化
self.networkstandard=networkstandard #特有的属性 初始化
#继承了父类中的公共属性,可以直接访问
print('创建了一个MobilePhone对象.名字name是', self.name)
print('产品编号: '+str(self.__class__.id)) #继承父类中的类属性,可以直接访问
#print('The price is ' + str(self.__price)) #无法继承父类中的私有属性,不能在子类中直接访问
print('价格price是' + str(self.getPrice())) #可以通过父类中的公有方法访问其私有属性
#--------------- main() --------------------
def main():
m=MobilePhone("Nokia",'Black',600,'TD-SCDMA')
print("产品名称:"+m.name+",产品价格:" + str(m.getPrice()))
print("id是",MobilePhone.id) #调用从父类中继承的类属性
print("id是",m.id) #对象名.类属性(不建议)
#--------------- 主程序 -------------------
if __name__ == "__main__":
main()
属性覆盖
子类如果定义了和父类中名称相同的属性,父类中的属性在子类中将被覆盖。
#--------------- 父类:Product --------------------
class Product(object):
id = 0 #类属性
def __init__(self,name,price):
Product.id=Product.id+1
self.name=name #公有实例属性
self.color='父类中定义的Color.'
self.__price=price #私有实例属性
def setPrice(self,price):
self.__price=price
def getPrice(self):
return self.__price
#--------------- 子类:MobilePhone --------------------
class MobilePhone(Product):
def __init__(self,name,price,networkstandard):
super(MobilePhone,self).__init__(name,price)#用父类的init方法初始化2个属性
self.networkstandard=networkstandard
self.color='子类中定义的color. '#子类中的属性color覆盖父类中的同名的属性
#继承了父类中的公共属性,可以直接访问
print('创建了一个MobilePhone对象. 名字name是', self.name)
print('产品编号: '+str(self.__class__.id)) #继承父类中的类属性,可以直接访问
print('The price is ' + str(self.getPrice())) #可以通过父类中的公有方法访问私有属性
#------------------ 主程序 ----------------------
def main():
m=MobilePhone("Nokia",600,'TD-SCDMA')
print("产品名称:"+m.name+",产品价格:"+str(m.getPrice()))
print(m.color) #调用子类中的属性
print(MobilePhone.id) #调用从父类中继承的类属性
if __name__ == "__main__":
main()
9.2.3子类继承父类的方法
哪些方法可以继承?
- 非私有方法(公有、保护方法):继承
- 私有方法:不能继承
#--------------- 父类:Product --------------------
class Product(object):
id = 0
def __init__(self,name,price):
Product.id=Product.id+1
self.name=name
self.color='The color defined in the parent class.'
self.__price=price
def setPrice(self,price): #公有方法
self.__price=price
def __getPrice(self): #公有方法
return self.__price
@staticmethod #声明静态,去掉则编译报错; 静态方法不能访问类属性和实例属性
def testStaticMethod(): #静态方法:不需要参数self
print("The static method is called.")
@classmethod #类方法
def testClassMethod(cls):
print("The class method is called.")
#--------------- 子类:MobilePhone --------------------
class MobilePhone(Product):
def __init__(self,name,price,networkstandard):
super(MobilePhone,self).__init__(name,price)
self.networkstandard=networkstandard
self.color='子类定义的color.' #子类中的属性color覆盖父类中的同名的属性
#继承了父类中的公共属性,可以直接访问
print('A MobilePhone has been created. the name is', self.name)
#print('The price is ' + str(self.__price)) #无法继承父类中的私有属性,不能在子类中直接访问
print('The price is ' + str(self.__getPrice())) #可以通过父类中的公有方法访问私有属性
self.testStaticMethod() #访问继承自父类的静态方法
self.testClassMethod() #访问继承自父类的类方法
#----------------------- 主程序 ---------------------------
def main():
m=MobilePhone("Nokia",600,'TD-SCDMA')
print("产品名称:"+m.name+",产品价格:"+str(m.__getPrice())) #公开方法 可以继承
print(m.color) #调用子类中的属性
MobilePhone.testStaticMethod() #静态方法 可以继承
m.testStaticMethod() #对象名.静态方法名()(不建议)
MobilePhone.testClassMethod() #类方法 可以继承
m.testClassMethod()
if __name__ == "__main__":
main()
方法覆盖
当子类中定义了与父类中同名的方法时,子类中的方法将覆盖父类中的同名方法,也就是重写了父类中的同名方法。
#--------------- 父类:Product --------------------
class Product(object):
id = 0
def __init__(self,name,price):
Product.id=Product.id+1
self.name=name
self.color='父类中定义的color'
self.__price=price
def setPrice(self,price):
self.__price=price
def getPrice(self):
return self.__price
def totalPrice(self,number):
print('父类中的totalPrice方法被调用.')
#--------------- 子类:MobilePhone --------------------
class MobilePhone(Product):
def __init__(self,name,price,networkstandard):
super(MobilePhone,self).__init__(name,price)
self.networkstandard=networkstandard
# 子类中的属性color覆盖父类中的同名的属性
self.color='The color defined in the sub class.'
def totalPrice(self,number): # 新增:定义与父类中同名的方法
print('调用了子类中的totalPrice方法。')
super(MobilePhone,self).totalPrice(number)
#---------------------- 主程序 ----------------------
def main():
m=MobilePhone("Huawei",600,'TD-SCDMA')
print("产品名称:"+m.name+",产品价格:"+str(m.getPrice()))
print(m.color) # 调用子类中的属性
# 调用子类中的方法,因为子类覆盖了父类中同名的方法
m.totalPrice(2)
if __name__ == "__main__":
main()
从运行结果的最后一行看,调用子类对象的同名方法时,执行的是子类中的方法,而不是父类中的同名方法。
如果需要在子类中调用父类中同名的方法,可以采用如下格式:
super(子类类名, self).方法名称(参数)
如例9-5中子类MobilePhone的方法中需要调用父类Product中的totalPrice方法,需要采用如下格式:
super(MobilePhone,self).totalPrice(2)
9.2.4 继承关系下的__init__()初始化方法
情况1:
继承时,如果子类的初始化方法没有覆盖父类的初始化方法__init__():即子类没提供init方法。
- 则在创建子类的对象时,默认执行
父类的初始化方法。
#----------------------- 父类:Product ----------------------
class Product(object):
id = 0
def __init__(self):
Product.id=Product.id+1
print('执行父类Product的初始化方法')
#---------------------- 子类:MobilePhone ----------------------
class MobilePhone(Product):
def test(self):
print('执行MobilePhone类中的普通方法')
#---------------------- 主程序 ----------------------
def main():
m=MobilePhone()
m.test()
if __name__ == "__main__":
main()
运行解释:
父类Product有一个初始化方法__init__(self),子类MobilePhone继承父类Product且没有重写初始化方法,因此在创建Product对象时,调用父类的默认初始化方法__init__(self)。
情况2:
当子类中的初始化方法__init__()覆盖了父类中的初始化方法时:子类提供了一个__init__方法。
- 创建子类对象时,执行
子类中的初始化方法,不会自动调用父类中的初始化方法。
#---------------- 父类:Product ----------------
class Product(object):
id = 0
def __init__(self):
Product.id=Product.id+1
print('执行父类Product的初始化方法')
#---------------- 子类:MobilePhone ----------------
class MobilePhone(Product):
def __init__(self):
print('执行子类MobilePhone类的初始化方法')
def test(self):
print('执行MobilePhone类中的普通方法')
#----------------- 主程序 ----------------
def main():
m1=MobilePhone()
m1.test()
if __name__ == "__main__":
main()
运行解释:
创建MobilePhone的对象时,执行子类MobilePhone中的初始化方法__init__(self),而父类Product中的初始化方法不会得到执行。
情况3:
子类的初始化方法能否调用父类的初始化方法?
- 在Python语言中,编译器
不会自动插入对父类初始化方法的调用。 - 所以,如果需要调用父类的初始化方法,必须在子类的初始化方法中
明确写出调用语句。
有两种方法调用父类的初始化方法:
父类名.init(self, 其他参数)
super(本子类名, self).init(其他参数)
注意,这里的其他参数是指初始化方法定义时列出的除self外的参数
#---------------- 父类:Product ----------------
class Product(object):
id = 0
def __init__(self):
Product.id=Product.id+1
print('执行父类Product类的初始化方法')
#-------------- 子类:MobilePhone ----------------
class MobilePhone(Product):
def __init__(self):
#Product.__init__(self) #调用父类初始化方法1
super(MobilePhone,self).__init__() #调用父类初始化方法2
print('执行子类MobilePhone类的初始化方法')
def test(self):
print('执行子类MobilePhone类中的普通方法')
#----------------- 主程序 ----------------
def main():
m=MobilePhone()
m.test()
if __name__ == "__main__":
main()
9.2.5多重继承
多重继承
- 子类有多个父类,同时继承多个父类的非私有属性和非私有方法。
- Python没有提供 接口,可以用 多重继承 机制来模拟 接口。
但是,多重继承使用不当,会出现隐患。所以,建议尽量少使用。
9.3 类的组合
组合是类的另一种重用方式。
组合关系可以用“has-a”关系来表达,即,一个类中包含其他类的对象。
比如,计算机Computer,包含了Display显示器、Disk磁盘、Processor处理器等。
比如,动物园Zoo,包括Panda大熊猫、Zebra斑马、Bear熊、Tiger老虎等。
继承与组合的区别:
-
继承
:
- 父类的内部细节对于子类来说在一定程度上是 可见 的。
- 所以通过继承的代码复用可以说是一种“白盒”代码复用。
-
组合
:
- 对象之间各自的内部细节是 不可见 的。
- 所以通过组合的代码复用可以说是一种“黑盒”代码复用。
9.3.1 组合的语法
在Python中,一个类可以包含其他类的对象作为属性,这就是类的 组合 。
所以,组合,并没有增加新的语法形式。
#------------- 被组合类:Display、Memory、Disk、Processor -----------------
class Display(object):
pass
class Memory(object):
pass
class Disk(object):
pass
class Processor(object):
pass
#------------- 组合类:Computer类 -----------------
class Computer(object):
def __init__(self):
self.display = Display() #创建了一个Display类的对象,作为本类的属性
self.memory = Memory() #.........Memory...............
self.disk = Disk() #.........Disk................
self.processor = Processor() #.........Processor...........
class MobilePhone(object):
def __int__(self):
self.display = Display()
self.memory = Memory()
#-------------- 主程序 -------------
def main():
c = Computer()
m = MobilePhone()
m.display.
if __name__ == "__main__":
main()
在组合关系下有两种方法可以初始化对象的属性。
- 第一种方法是(初始化方法传递参数):通过组合类初始化方法传递被组合对象所属类的初始化方法中的参数;紧密耦合
- 第二种方法是:在主程序中创建被组合类的对象,然后将这些对象传递给组合类。松耦合
第一种方法:实现对象属性初始化。
#------------- Display、Memory类 -----------------
class Display(object):
def __init__(self,size):
self.size = size
class Memory(object):
def __init__(self,size):
self.size = size
#------------- Computer类 -----------
class Computer(object):
def __init__(self,displaySize,memorySize):
self.display = Display(displaySize) #传递参数给Display()的初始化方法
self.memory = Memory(memorySize) #.........Memory()............
#-------------------- 主程序 ----------------------
def main():
c = Computer(23,2048)
if __name__ == "__main__":
main()
在第一种方法中,在Computer类的初始化方法中分别传递显示器尺寸displaySize和内存大小memorySize给两个组合对象所属类的初始化方法,在组合类Computer中创建被组合的对象
#(第二种方法)
#------------- Display、Memory类 -----------------
class Display(object):
def __init__(self,size):
self.size = size
class Memory(object):
def __init__(self,size):
self.size = size
#--------------- Computer类 -----------------
class Computer(object):
def __init__(self,display,memory):
self.display = display
self.memory = memory
#------------- 主程序 -----------------
def main():
display = Display(23) #创建被组合对象Display,此时传递参数
memory = Memory(2048)
c = Computer(display,memory)
if __name__ == "__main__":
main()
在第二种方法中,组合类的初始化方法参数由两个被组合类的对象组成。
因此,在主程序中需要预先创建被组合对象,然后将这些对象作为参数传递给组合类的初始化方法,最终赋值给组合类的对象属性。
9.3.2 继承与组合的结合
在实际项目开发过程中,仅使用继承或组合当中的一种技术难以满足实际需求,通常会将两种技术结合使用。
内存、显示器和计算机均属于一种产品,其中计算机需要显示器和内存。请用Python语言简要实现这些类及它们之间的关系。
# ------------ 父类 Product -------------
class Product(object):
pass
# ------------ 子类 Display,Memory,Computer -------------
class Display(Product): #使用了 继承
def __init__(self,size):
self.size = size
class Memory(Product):
def __init__(self,size):
self.size = size
class Computer(Product):
def __init__(self,display,memory):
self.display = display #使用了 组合
self.memory = memory
#------------------- 主程序 ------------------------
def main():
display = Display(23)
memory = Memory(2048)
c = Computer(display,memory)
if __name__ == "__main__":
main()
十、异常处理
10.1 异常
异常 是在程序执行过程中发生的影响程序正常执行的一个事件。
比如:磁盘满、打印机没开、被零除、输入格式不正确
遇到 异常,怎么办?
- 有些异常,不用处理,也无法处理:栈溢出、内存不足等
- 有些异常,可以处理或者抛给调用方来处理:被零除、输入格式不正确等
Python提供了 异常处理机制,将处理模式、处理流程 统一化,标准化。
异常处理使程序能够处理完异常后继续它的正常执行,不至于使程序因异常导致退出或崩溃。
异常处理机制:
- 1.将 出现的错误信息 封装为 对应的异常对象;
- 2.将该异常对象 抛出去(目的:正常流程代码和异常处理代码分离开,不干扰正常处理流程);
- 3.匹配(捕获)抛出的异常对象,由能处理该异常的代码来处理;
- 4.若本方法不能处理,则继续抛给调用方,直到能够处理,或者,到最后,抛到操作系统(停止该程序)。
即:异常是Python对象,当Python无法正常处理程序时就会抛出一个异常。一旦Python脚本发生异常,程序需要捕获并处理它,否则程序会终止执行。
#coding=gbk
try:
price=float(input("请输入价格:")) # 第1次:故意输入'x'(非数值),第2次:输入数值(正确)
print('价格为:%5.2f' % price)
except ValueError:
print('您输入的不是数字。')
print("接下来的代码...")
运行解释:
- 当在提示符下输入 非数字时,float()函数将产生一个ValueError异常。
- try块中检测到ValueError异常后,终止try中后续代码的执行,将ValueError异常抛给except部分。
- except部分中能处理ValueError的代码来处理:即执行except ValueError语句后面的代码。
- 处理完异常后,继续执行下面的语句(不再回去try块中执行price=float(…)下面的剩余语句了)。
10.2 Python中的异常类
Python程序出现异常时,会新建一个异常类的对象并抛出。 以下是Python的标准异常类。
异常类的继承架构(从左往右,是继承关系)
-
BaseException类:Python中所有异常类的根类。
-
Exception类:大部分常规异常类的基类。
- NameError、ZeroDivisionError、IOError等
-
SystemExit异常类:不管程序是否正常退出,都将引发SystemExit异常。
例如,在代码中的某个位置调用了sys.exit()函数时,将触发SystemExit异常。利用这个异常,可以阻止程序退出或让用户确认是否真的需要退出程序。
-
KeyboardInterrupt异常:是因用户按下Ctrl+C组合键来终止命令行程序而触发
10.3 Python的异常处理语法
try:
<可能出现异常的语句块> # 自动抛出标准异常类的对象
raise 自定义的异常类名字() # 或者 主动创建并抛出 自定义异常类的对象
except <异常类名字name1>:
<异常处理语句块1> #如果在try部份引发了'name1'异常,执行这部分语句块
except <异常类名字name2> as e1: #将抛出的异常对象传给e1(处理语句需要其中的信息)
<异常处理语句块2> #如果在try部份引发了'name2'异常,执行这部分语句块
except < (异常类名字name3, 异常类名字name4, …)> as e2: #本块可以处理多种异常类对象
<异常处理语句块3> #如果引发了'name3'、'name4'、…中任何一个异常,执行该语句块
…
except:
<异常处理语句块n> #如果引发了异常,但与上述异常都不匹配,执行此语句块
else: #如果没有上述所列的异常发生,执行else语句块
<else语句块>
finally: #无论有无异常,都需要执行的语句块
<任何情况下都要执行的语句块>
1.try中的语句块先执行。
2-1.如果try语句块中的某一语句执行时 发生异常,Python会创建对应的异常对象就抛到except部分,从上到下 依次 判断抛出的异常对象是否与except后面的异常类相匹配,
找到并执行第一个匹配该异常的except后面的语句块,异常处理完毕。
没有找到匹配的异常类别,则执行不带任何匹配类型的except语句后面的语句块,异常处理完毕。
没有匹配的except子句,也没有不带匹配类型的except部分,则异常将往上被递交到调用方的try/except语句进行异常处理,或者直到将异常传递给程序的最上层(操作系统),从而结束程序。
多个except子句,要注意父类和子类的顺序:必须子类在父类的except子句前。(如果父类在子类前,那么子类的except子句就永远没有机会匹配成功了。)
2-2.如果try语句块中的任何语句在执行时没有 发生异常,Python将执行else语句后的语句块。
3.无论有无异常发生(执行完except后的异常处理语句或else后面的语句块后),程序一定会执行finally后面的语句块。这里的语句块主要用来进行收尾操作(关闭文件、释放连接等操作)。
所以,一个异常处理模块至少有一个try和一个except语句块,else和finally语句块是可选的。
10.4 自定义异常类
异常处理流程一般包括 三个步骤:
- 将可能产生异常的代码段放在try代码块中;
- 出现特定情况时抛出(raise)异常;
- 在except部分捕获并处理异常。
前面例子都是 标准异常类,是由系统自动抛出,隐藏了异常抛出的步骤。
仅仅使用 标准异常类 通常不能满足系统开发的需要,有时候需要 自定义 异常类。
- 可以继承BaseException类或其子类来创建自定义异常类;
- 类名一般以Error或Exception为后缀。
- 系统无法识别自定义的异常类,只能在程序中显式地使用raise抛出异常
class InvalidNumberError(ArithmeticError):
def __init__(self,num):
super(InvalidNumberError,self).__init__()
self.num = num
def getNum(self):
return self.num
from except_example import InvalidNumberError #本文件使用Jupyter,不必导入模块
try:
x=float(input('请输入设备成本:'))#第1、2、3次输入:150
y=int(input('请输入分摊年数:')) #第1次输入:8 第2次输入:0 第3次输入:x
z=x/y #第1次:z=18.75 第2次:被0除错误(标准异常,自动创建并抛出)
if z > 10 :
raise InvalidNumberError(z) #先创建一个InvalidNumberError对象,参数为z,然后抛出
print('每年分摊金额为%.2f'% z)
except ArithmeticError: #该异常类为InvalidNumberError的父类,必须在其后
print("数学异常。")
except InvalidNumberError as ex: #第1次:InvalidNumberError异常被捕获,该异常对象传给ex
print('每年分摊的金额为%.2f大于10了,请重新分配.' % ex.getNum())
except ZeroDivisionError: #第2次:若输入0,则被0除异常被捕获
print("发生异常,分摊年数不能为0.")
except: #第3次:x非数值
print('输入有误')
因为InvalidNumberError是一个自定义类,因此需要使用raise来显式地抛出异常。自定义异常的其他使用方法与标准模块中的异常类使用方法相同。
10.5 with语句
with语句可以自动关闭文件。
with open(r'd:\test.txt') as f:
f.read()
with语句是其中一个隐藏低层次抽象的方法。
同样,with可以用在 异常处理上,目的是简化类似于try-except-finally这样的代码。
- 因为try-except-finally通常用于保证资源的唯一分配,并在任务结束时释放资源,如线程资源、文件、数据库连接等。
with语句的语法如下:
with context-expression [as var]:
with语句块
#常规异常处理写法
try:
f=open('testwith.txt','r')
for line in f:
print(line,end='')
finally:
f.close()
#简化后的代码
with open('testwith.txt','r') as f: # 不需要写f.close()语句了
for line in f:
print(line,end='')
但是,并 不是所有的对象 都支持with语句这一新的特性。
只有支持上下文管理协议的对象才能使用with语句。
第一批支持该协议的对象有:file、decimal.Context、thread.LockType、threading.Lock、threading.RLock、threading.Condition、threading.Semaphore、threading.BoundedSemaphore。
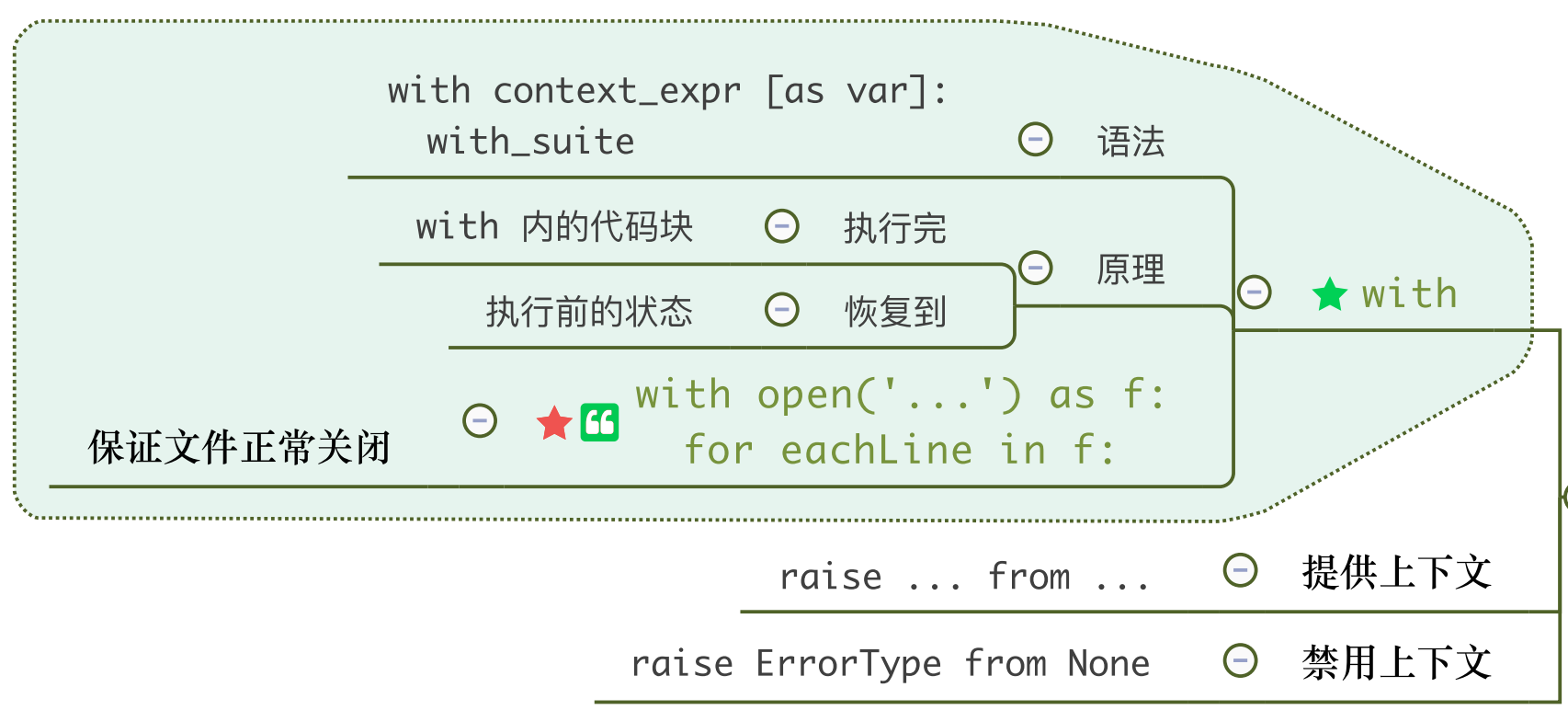
10.6 断言
断言从Python1.5版本开始引入,是申明表达式为真的判定。如果表达式为假则抛出异常。
断言语句可以理解为raise-if-not语句,用来测试表达式.
- 如果表达式为 假,则触发AssertionError异常;
- 如果表达式为 真,也就是断言成功,则程序不采取任何措施。
断言的语法格式如下:
assert expression [, arguments]
其中expression是断言表达式;arguments是断言失败时(断言表达式为假时)传递给AssertionError对象的字符串(失败信息)。
assert 2==1+1 # 表达式正确,--> 断言成功 --> 不采取任何措施
assert 2==1*1 # 表达式错误, -->断言失败 --> 抛出异常信息
a = int(input("请输入整数a:"))
b = int(input("请输入整数b:"))
assert b!=0,'除数不能为0'
c = a / b
print(a,'/',b,'=',c)
和其他异常一样,AssertionError也可以通过try-except来捕获。
如果没有捕获,该异常将终止程序的运行。
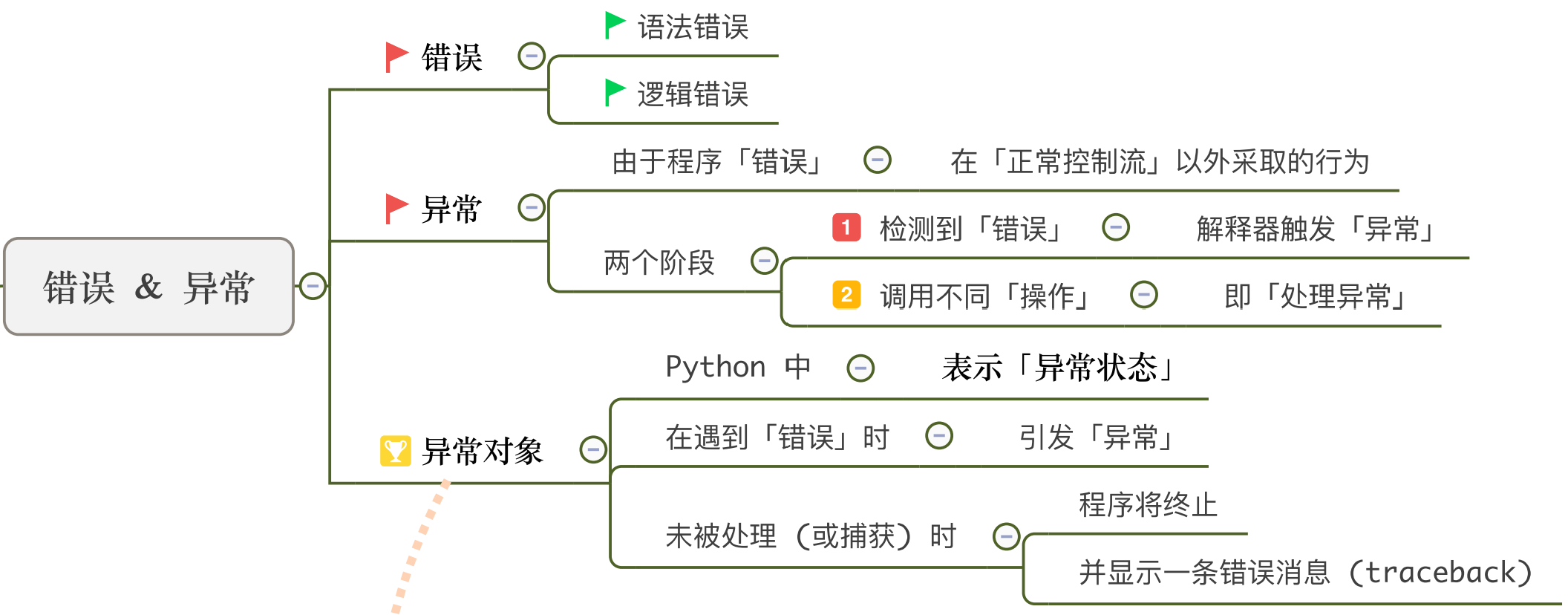


















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











