






文章目录
1、概述
本篇博客用来记录 Python 的学习笔记和过程。
参考链接:Python学习教程-廖雪峰
2、学习笔记
2.1、简介
Python是一种计算机程序设计语言。
Python就为我们提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。
Python 的缺点
- 运行速度慢
- 代码无法加密:由于是解释性语言,发布程序就是发布源码
2.2、第一个 python 程序
前提:在安装 python 后,
打开 cmd 窗口(命令行模式),然后输入 python,进入 python 交互模式。
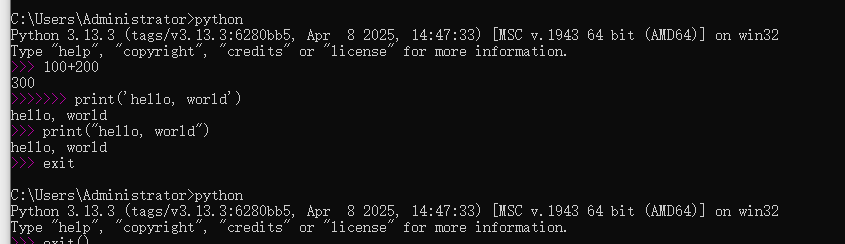
在命令行模式下,可以执行
python进入Python交互式环境,也可以执行python hello.py运行一个.py文件。
Python交互模式的代码是输入一行,执行一行,而命令行模式下直接运行.py文件是一次性执行该文件内的所有代码。
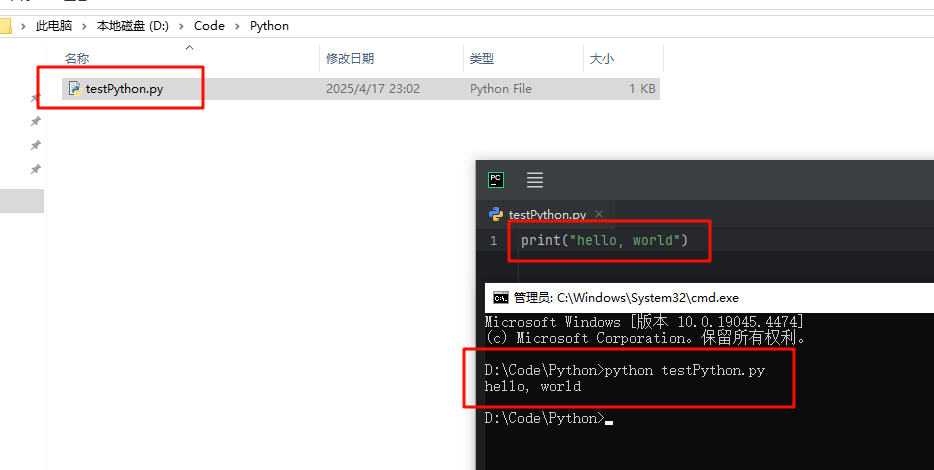
输入与输出
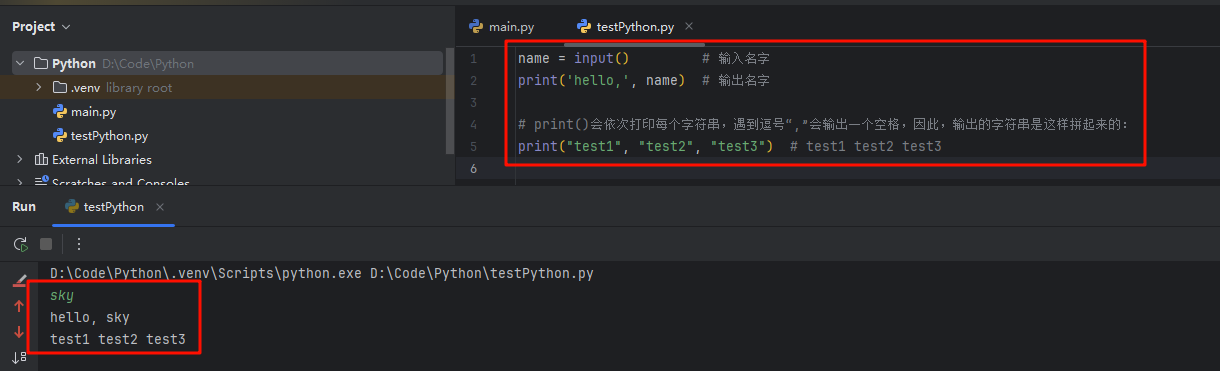
2.3、基础知识
2.3.1、数据类型与变量
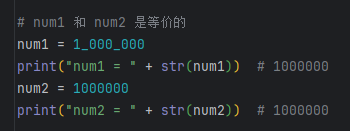
整数
Python允许在数字中间以_分隔
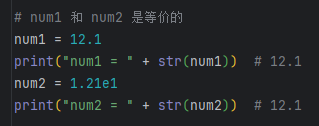
浮点数
浮点数也就是小数,且可以使用科学计数法,例如 1.21e2
字符串
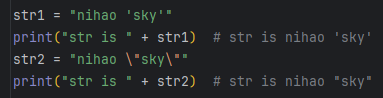
字符串是以单引号'或双引号"括起来的任意文本,比如'abc',"xyz"等等。
且可以使用转义字符\
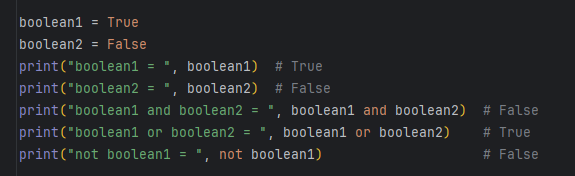
布尔值
一个布尔值只有True、False两种值
布尔值可以用and、or和not运算。
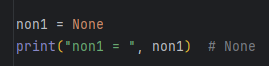
空值
空值是Python里一个特殊的值,用None表示。
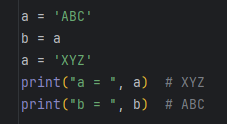
变量
变量的概念基本上和初中代数的方程变量是一致的,只是在计算机程序中,变量不仅可以是数字,还可以是任意数据类型。
变量名必须是大小写英文、数字和_的组合,且不能用数字开头
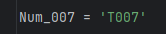
变量
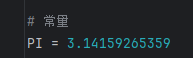
所谓常量就是不能变的变量,在Python中,通常用全部大写的变量名表示常量
2.3.2、字符串和编码
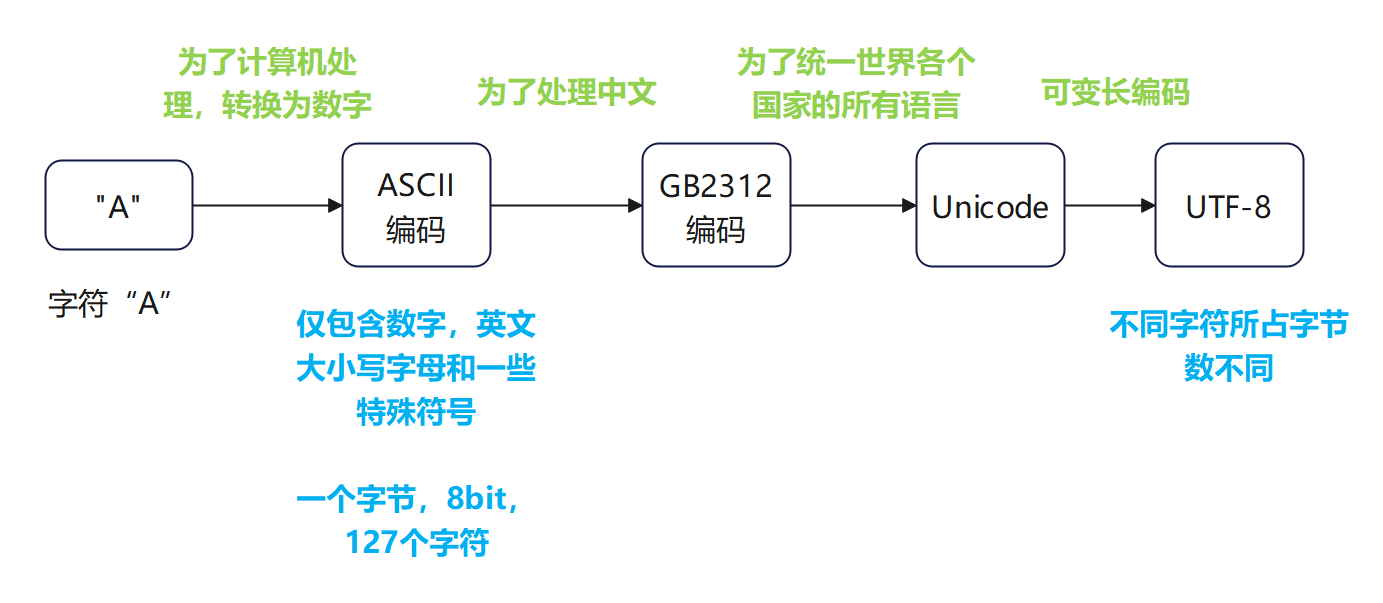

在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言
print("这个是中文") # 包含中文的 str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
print(ord('中')) # 20013
print(chr(20013)) # 中
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
以Unicode表示的str通过encode()方法可以编码为指定的bytes
print('ABC'.encode('ascii')) # b'ABC'
print('ABC'.encode('utf-8')) # b'ABC'
print('中'.encode('utf-8')) # b'\xe4\xb8\xad'
print('中'.encode('ascii')) # 报错
注意,中文是无法使用 ascii 进行编码的
可以使用 decode() 方法进行解码
print(b'ABC'.decode('ascii')) # ABC
print(b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')) # 中文
方法 len() 可以计算字符数,如果先转换为 bytes,再使用 len() 方法,则可以计算字节数
print(len('中文')) # 字符数为 2
print(len('中文'.encode('utf-8'))) # 字节数为 6
1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
格式化
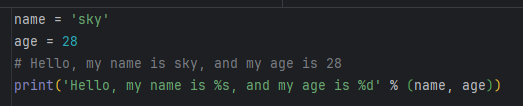
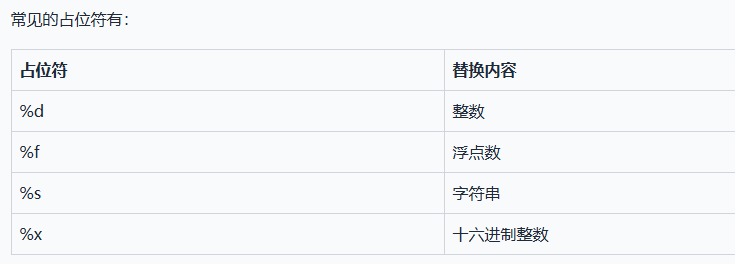
2.3.3、list 和 tuple
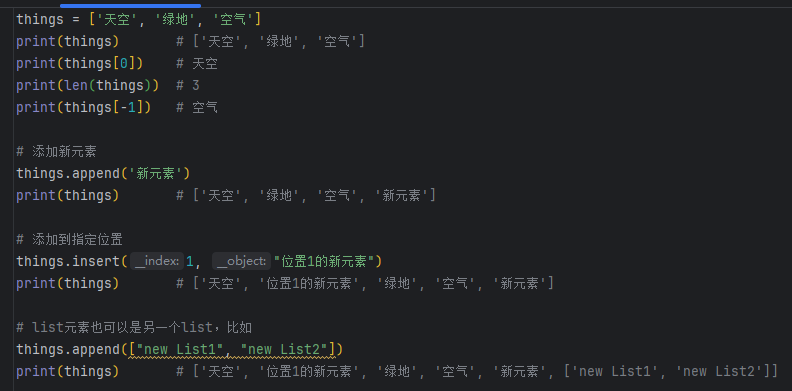
列表(list)
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
元组(tuple)
tuple和list非常类似,但是tuple一旦初始化就不能修改
意义:因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
元组额外添加一个,来表示只有一个元素的元组,用来跟数字1进行区分

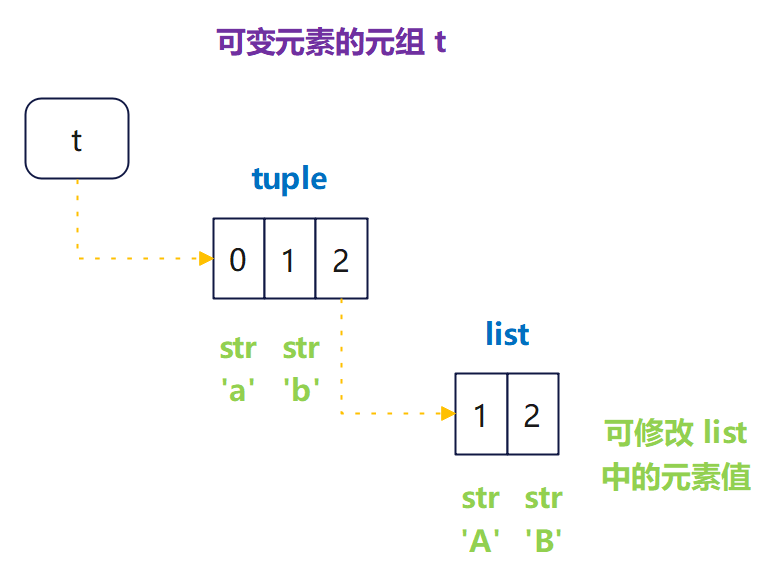
一种特殊的元组是可以修改元素值的,那就是包含 list 的元组
其实元组依然不变,元组依然指向一个固定的
list,但该list中的元素修改了
2.3.4、条件判断
通过if进行条件判断,注意需要加上:,可以使用else和elif
age = 28
if age == 18:
print("age is equal 18")
elif age < 18:
print("age is less than 18")
else :
print("age is greater than 18")
注意通过 input() 方法输入的为字符串,如果要进行比较,需要使用 int() 方法转换为数字
# 输入的数据类型为字符串
ageStr = input("Enter age: ")
# 需要使用 int() 方法将字符串转换为数字
age = int(ageStr)
if age == 18:
print("age is equal 18")
elif age < 18:
print("age is less than 18")
else :
print("age is greater than 18")
2.3.5、模式匹配
可以使用 match 关键字进行模式匹配,来代替复杂的 if elif,例如
score = 'B'
match score:
case 'A':
print('score is A.')
case 'B':
print('score is B.')
case 'C':
print('score is C.')
case _: # _表示匹配到其他任何情况
print('score is ???.')
使用
match语句时,我们依次用case xxx匹配,并且可以在最后(且仅能在最后)加一个case _表示“任意值”,代码较if ... elif ... else ...更易读。
同时还可以进行较为复杂的匹配
age = 15
match age:
case x if x < 10:
print(f'< 10 years old: {x}')
case 10:
print('10 years old.')
case 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18:
print('11~18 years old.')
case 19:
print('19 years old.')
case _:
print('not sure.')
同时match还可以匹配复杂列表
args = ['gcc', 'hello.c', 'world.c']
# args = ['clean']
# args = ['gcc']
match args:
# 如果仅出现gcc,报错:
case ['gcc']:
print('gcc: missing source file(s).')
# 出现gcc,且至少指定了一个文件:
case ['gcc', file1, *files]:
print('gcc compile: ' + file1 + ', ' + ', '.join(files))
# 仅出现clean:
case ['clean']:
print('clean')
case _:
print('invalid command.')
2.3.6、循环
Python的循环有两种,一种是for...in循环,依次把list或tuple中的每个元素迭代出来
sum = 0
for x in [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]:
sum = sum + x
print(sum) # 55
Python提供一个range()函数,可以生成一个整数序列
print(list(range(5))) # [0, 1, 2, 3, 4]
Python的第二种循环是while循环
可以使用break停止循环
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('END')
可以使用continue继续循环
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)
2.3.7、使用dict和set
dict
dict是Python内置的字典,类似其他语言的map
dict的key必须是不可变对象
key不能重复,新的value值会替代旧的value值
因为dict根据key来计算value的存储位置,要保证hash的正确性,作为key的对象就不能变。在Python中,字符串、整数等都是不可变的,因此,可以放心地作为key。而list是可变的,就不能作为key
key = '12'
s2 = {'1':11, '2':22}
s2[key] = 88
print(s2) # {'1': 11, '2': 22, '12': 88}
key = '99'
print(s2) # {'1': 11, '2': 22, '12': 88}
和list比较,dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
set
set和dict类似,也是一组key的集合,但不存储value。同样key也不能重复(重复数据自动被过滤)
add(xx)可以添加元素,remove(xx)可以删除元素
s = {1, 2, 3}
print(s) # {1, 2, 3}
s.add(4)
s.remove(1)
print(s) # {2, 3, 4}
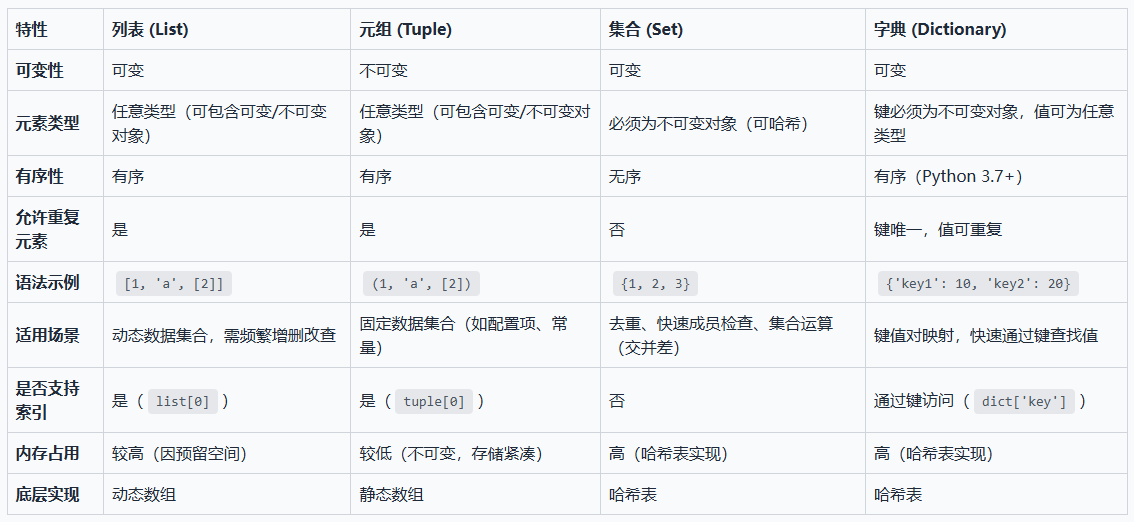
2.3.8、小结
2.4、函数
2.4.1、调用函数
官方函数文档:Python官方函数文档
如果有报错,会给出报错信息
2.4.2、定义函数
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
例如:
def my_abs(x):
if x >= 0:
return x
else:
return -x
print(my_abs(-99))
空函数
如果想定义一个什么事也不做的空函数,可以用pass语句:
def nop():
pass
pass 的作用
pass语句什么都不做,那有什么用?实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
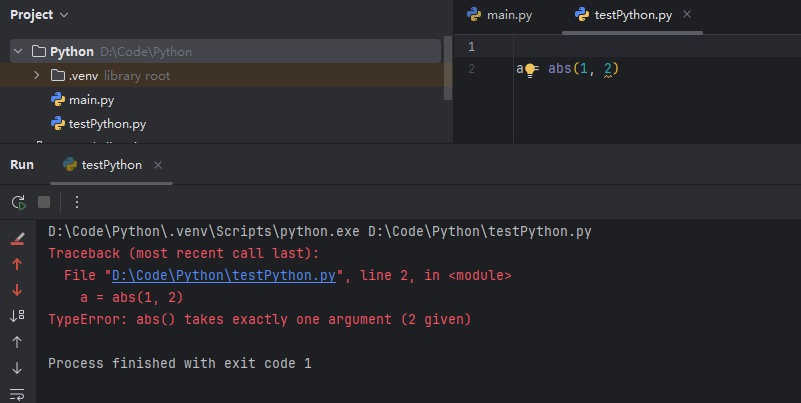
参数检查
调用函数时,如果参数个数不对,Python解释器会自动检查出来,并抛出TypeError:
返回多个值
python 可以返回多个值,即组成了一个元组 turple
比如在游戏中经常需要从一个点移动到另一个点,给出坐标、位移和角度,就可以计算出新的坐标:
import math
def move(x, y, step, angle=0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
在语法上,返回一个
tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值
2.4.3、函数的参数
python 中的函数包含多种不同类型的参数
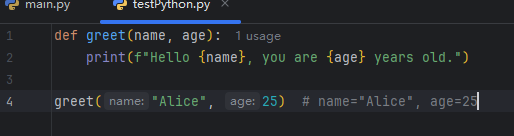
位置参数
定义:按顺序传递的参数,调用时必须按定义顺序传入。
例如:
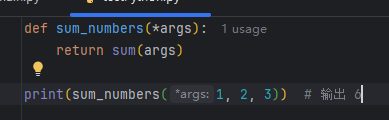
可变参数
作用:接收任意数量的位置参数,内部存储为元组。
语法:在参数前加 *。
示例:
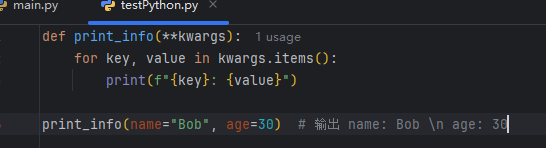
关键字参数 (**kwargs)
作用:接收任意数量的关键字参数,内部存储为字典。
语法:在参数前加 **。
示例:
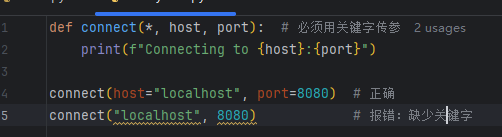
命名关键字参数 (Keyword-only Arguments)
作用:强制要求某些参数必须通过关键字传递(提高代码可读性)。
语法:出现在 * 或 *args 之后的参数。
示例:
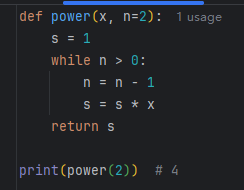
默认参数
定义:包含默认值的位置参数
语法:参数名=xxx
示例:
这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:
必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
2.4.4、递归函数
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
例如:
def fact(n):
if n==1:
return 1
return n * fact(n - 1)
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过**栈(stack)**这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
解决递归调用栈溢出的方法是通过尾递归优化,事实上尾递归和循环的效果是一样的,所以,把循环看成是一种特殊的尾递归函数也是可以的。
尾递归是指,在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
例如:
def fact(n):
return fact_iter(n, 1)
def fact_iter(num, product):
if num == 1:
return product
return fact_iter(num - 1, num * product)
遗憾的是,大多数编程语言没有针对尾递归做优化,Python解释器也没有做优化,所以,即使把上面的fact(n)函数改成尾递归方式,也会导致栈溢出。
2.5、高级特性
2.5.1、切片
Python中的切片操作允许你从序列类型(如列表、字符串、元组等)中高效地提取子序列。
L = ["1", "2", "3", "4"]
# L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。
print(L[0:3]) # ['1', '2', '3']
# 如果第一个索引是0,还可以省略:
print(L[:3]) # ['1', '2', '3']
2.5.2、迭代
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。
例如
L = ["1", "2", "3", "4"]
for x in L:
print(x)
list这种数据类型虽然有下标,但很多其他数据类型是没有下标的,但是,只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代:
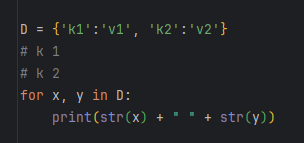
注意
因为dict的存储不是按照list的方式顺序排列,所以,迭代出的结果顺序很可能不一样。
如果要对list实现类似Java那样的下标循环怎么办?
Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
# 0 A
# 1 B
# 2 C
for i, value in enumerate(['A', 'B', 'C']):
print(i, value)
2.5.3、列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
举个例子,要生成list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]可以用list(range(1, 11)):
print(list(range(1, 11))) # [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
还可以生成复杂的表达式
L2 = [x * 2 + 1 for x in range(1, 11)]
print(L2) # [3, 5, 7, 9, 11, 13, 15, 17, 19, 21]
在一个列表生成式中,for前面的if ... else是表达式,而for后面的if是过滤条件,不能带else。
L = [x if x % 2 == 0 else -x for x in range(1, 11)]
print(L) # [-1, 2, -3, 4, -5, 6, -7, 8, -9, 10]
2.5.4、生成器
Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
可以通过next()函数获得generator的下一个返回值:
L = (x * x for x in range(11))
# print(L) 会报错 <generator object <genexpr> at 0x000001DB661BAB50>
print(next(L)) # 0
# 因为生成器也是可遍历的对象,因此可以使用 for xx in xx 来进行便利
for x in L:
print(x)
生成生成器的第二种方法,是使用关键字 yield
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator函数,调用一个generator函数将返回一个generator:
- 普通函数是顺序执行,遇到
return语句或者最后一行函数语句就返回。 generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
def odd():
print('step 1')
yield 1
print('step 2')
yield(3)
print('step 3')
yield(5)
L = odd()
print(next(L))
print(next(L))
print(next(L))
# step 1
# 1
# step 2
# 3
# step 3
# 5
2.5.5、迭代器
可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
生成器都是
Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
from collections.abc import Iterable
from collections.abc import Iterator
print(isinstance([], Iterable)) # true
print(isinstance({}, Iterable)) # true
print(isinstance((x for x in range(10)), Iterable)) # true
print(isinstance(100, Iterable)) # false
print(isinstance([], Iterator)) # false
print(isinstance({}, Iterator)) # false
print(isinstance((x for x in range(10)), Iterator)) # true
print(isinstance(100, Iterator)) # false
3、常见快捷键
| 快捷键 | 作用 |
|---|---|
| Ctrl + Alt + L | 代码格式化 |
| Ctrl + ? | 代码行注释 |
| Ctrl + D | 复制当前行 |
| Ctrl + Y | 删除当前行 |
| Shift + F6 | 变量重命名 |
| Ctrl + Shift + F | 全局查找 |
| Ctrl + Shift + F10 | 运行代码 |

















 2126
2126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









