







前言
随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。来源于哔哩哔哩博主“霹雳吧啦Wz”,博主学习作为笔记记录,欢迎大家一起讨论学习交流。
一、YOLOV1

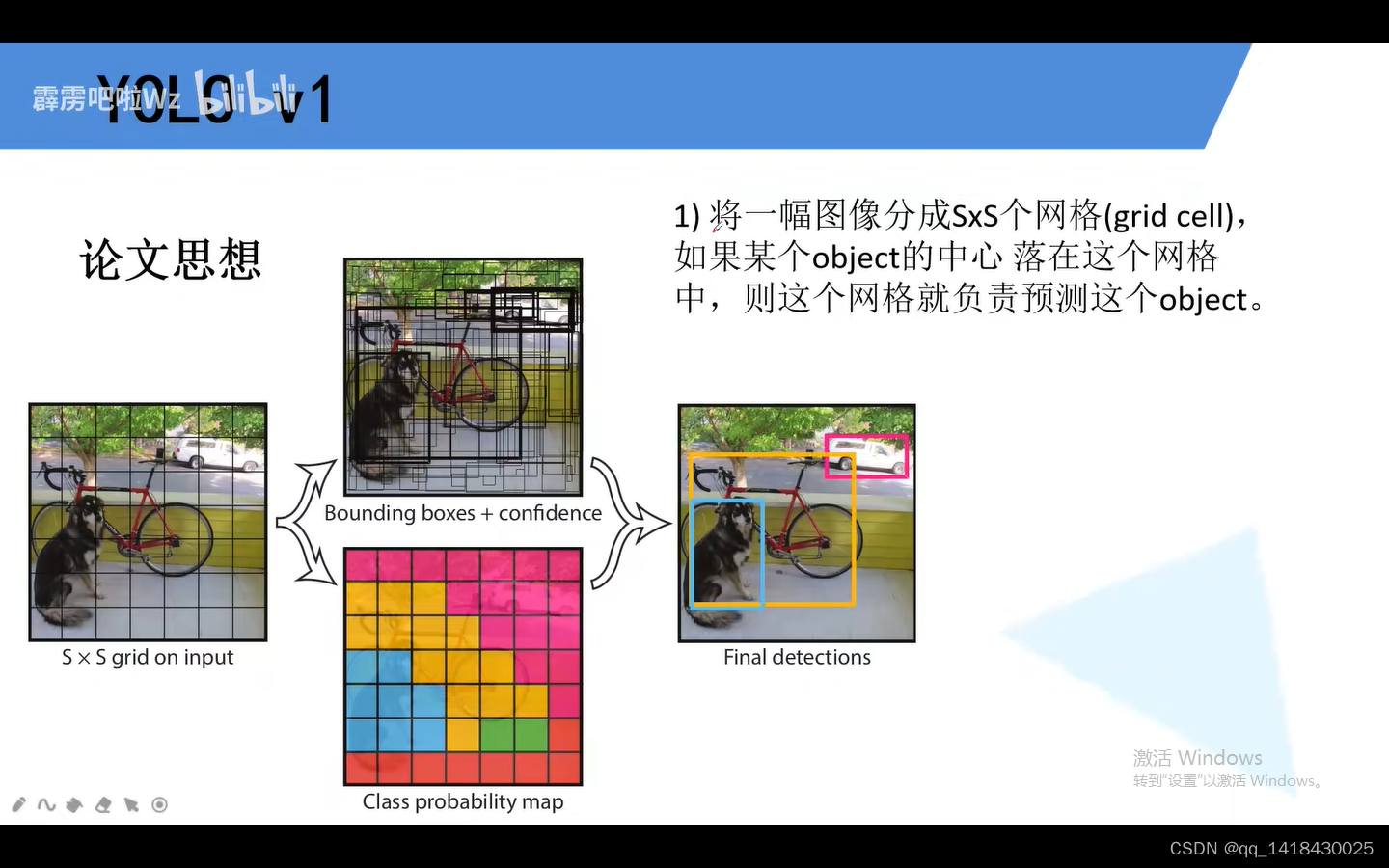

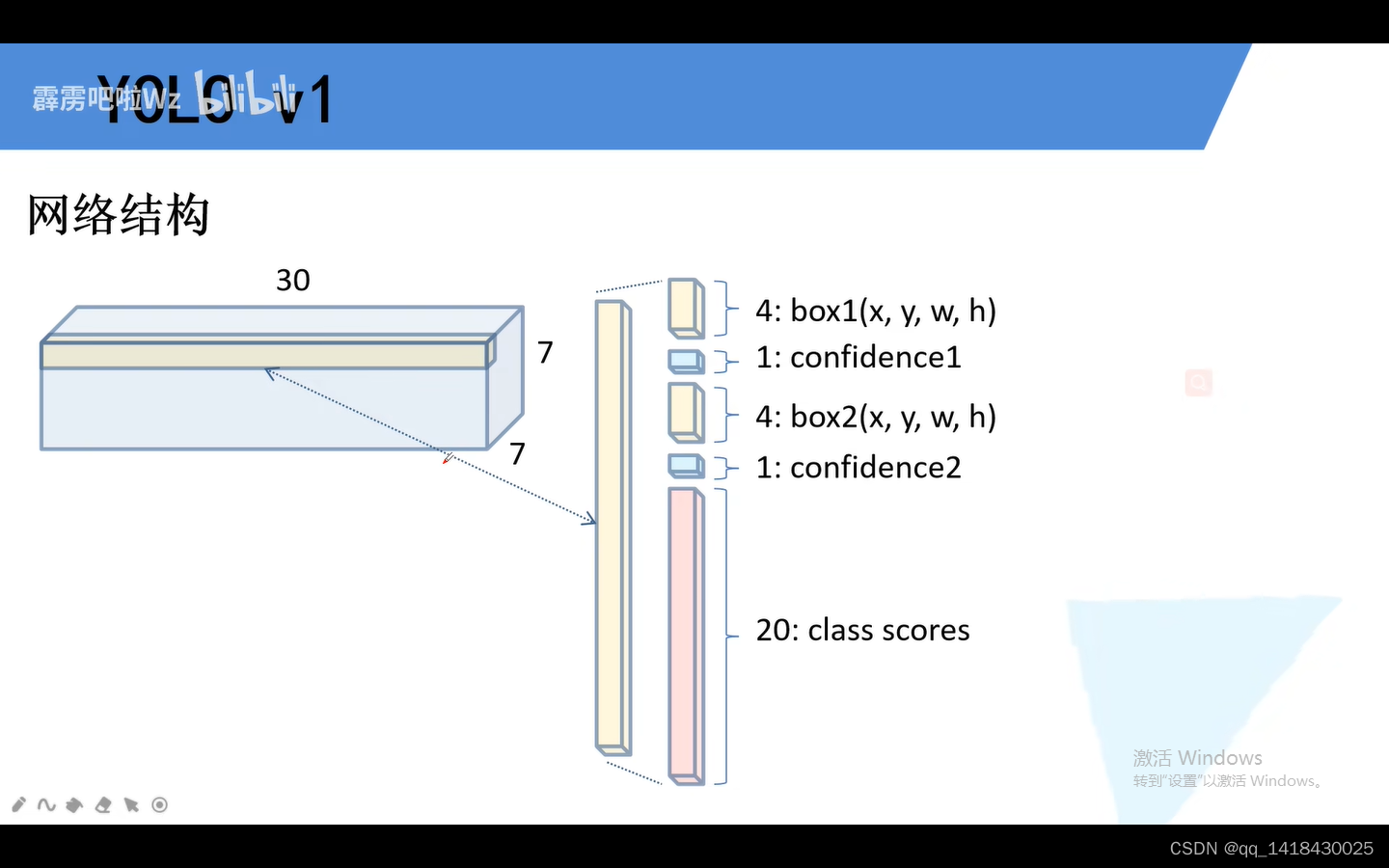
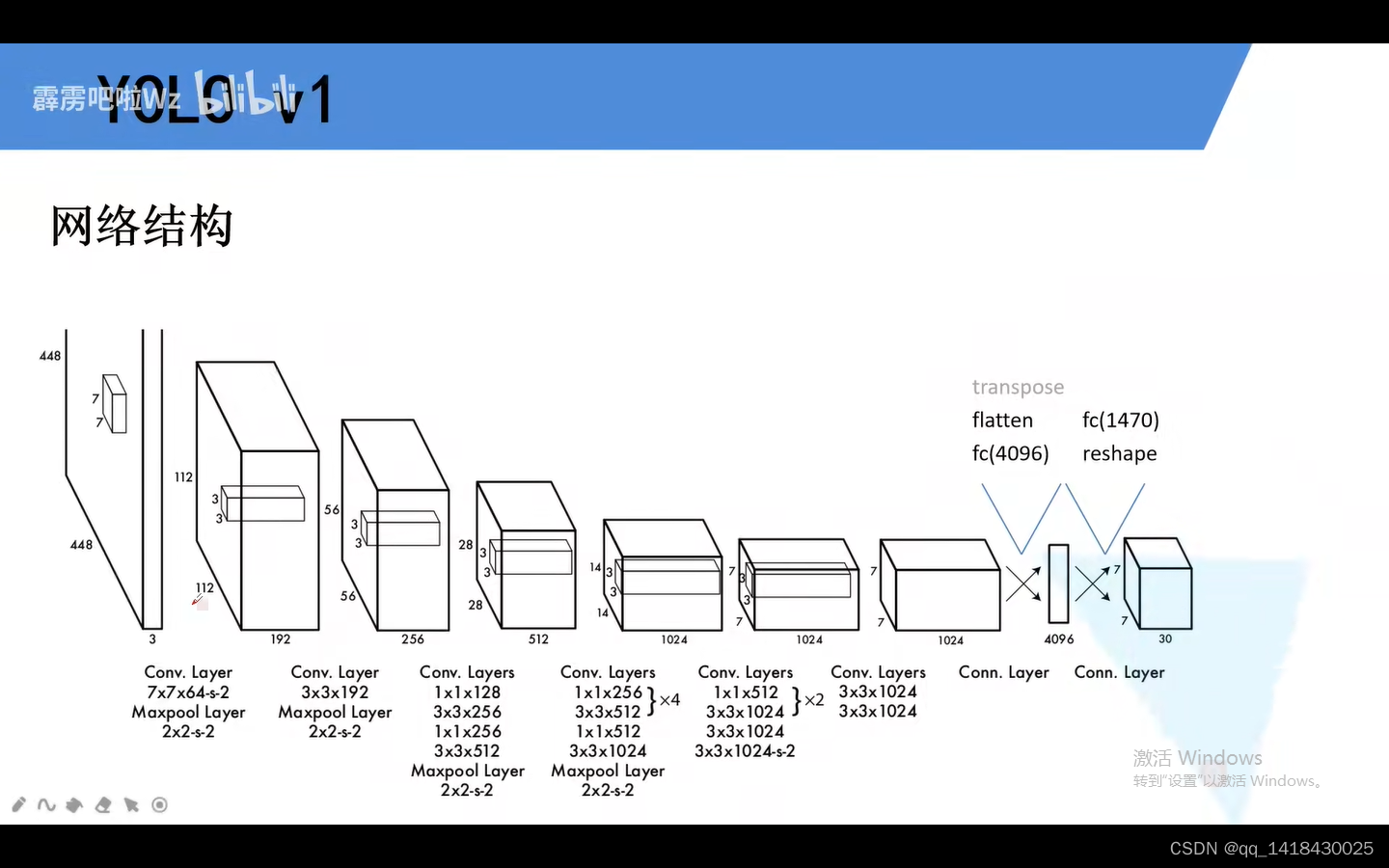


二、YOLOV2












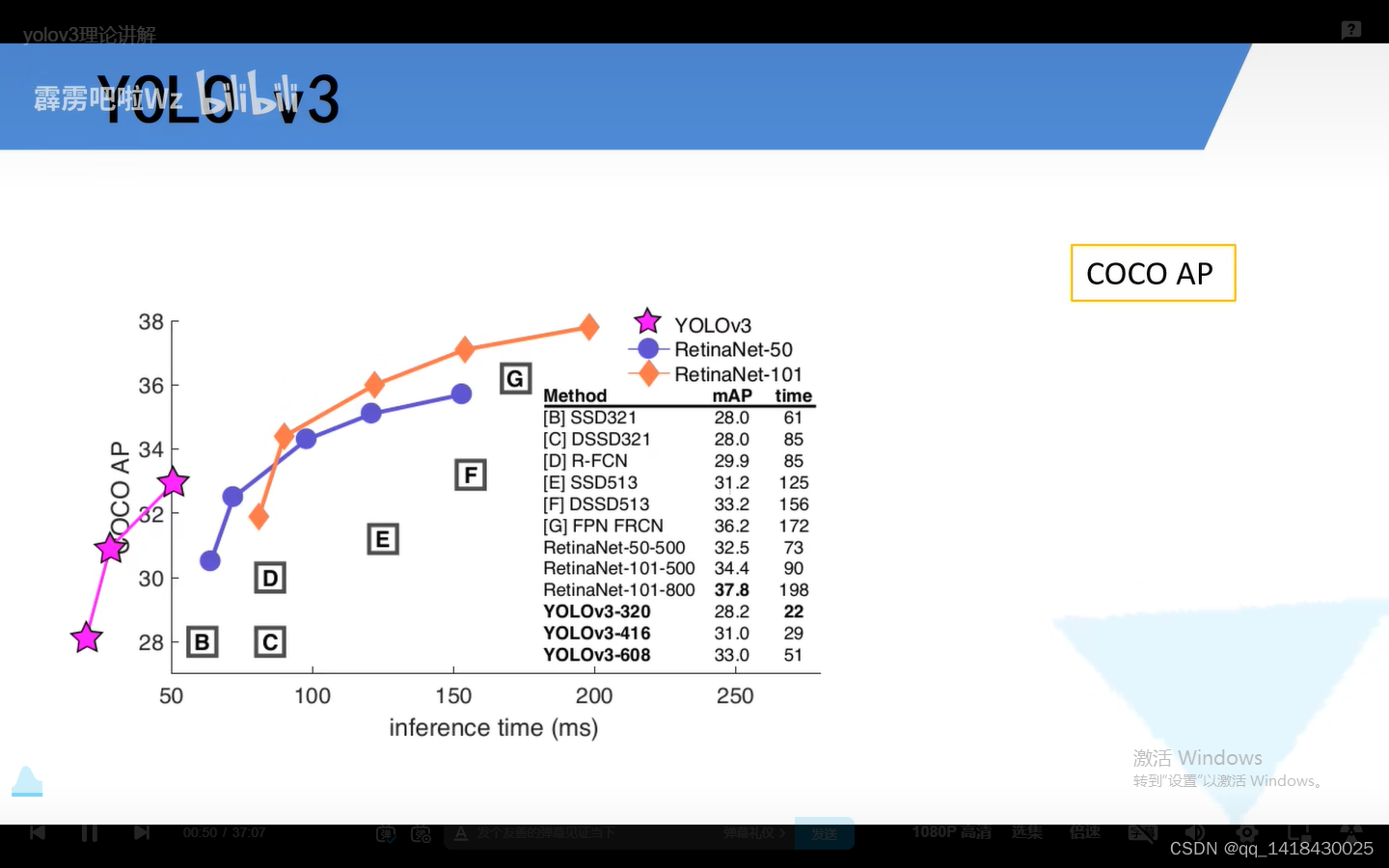
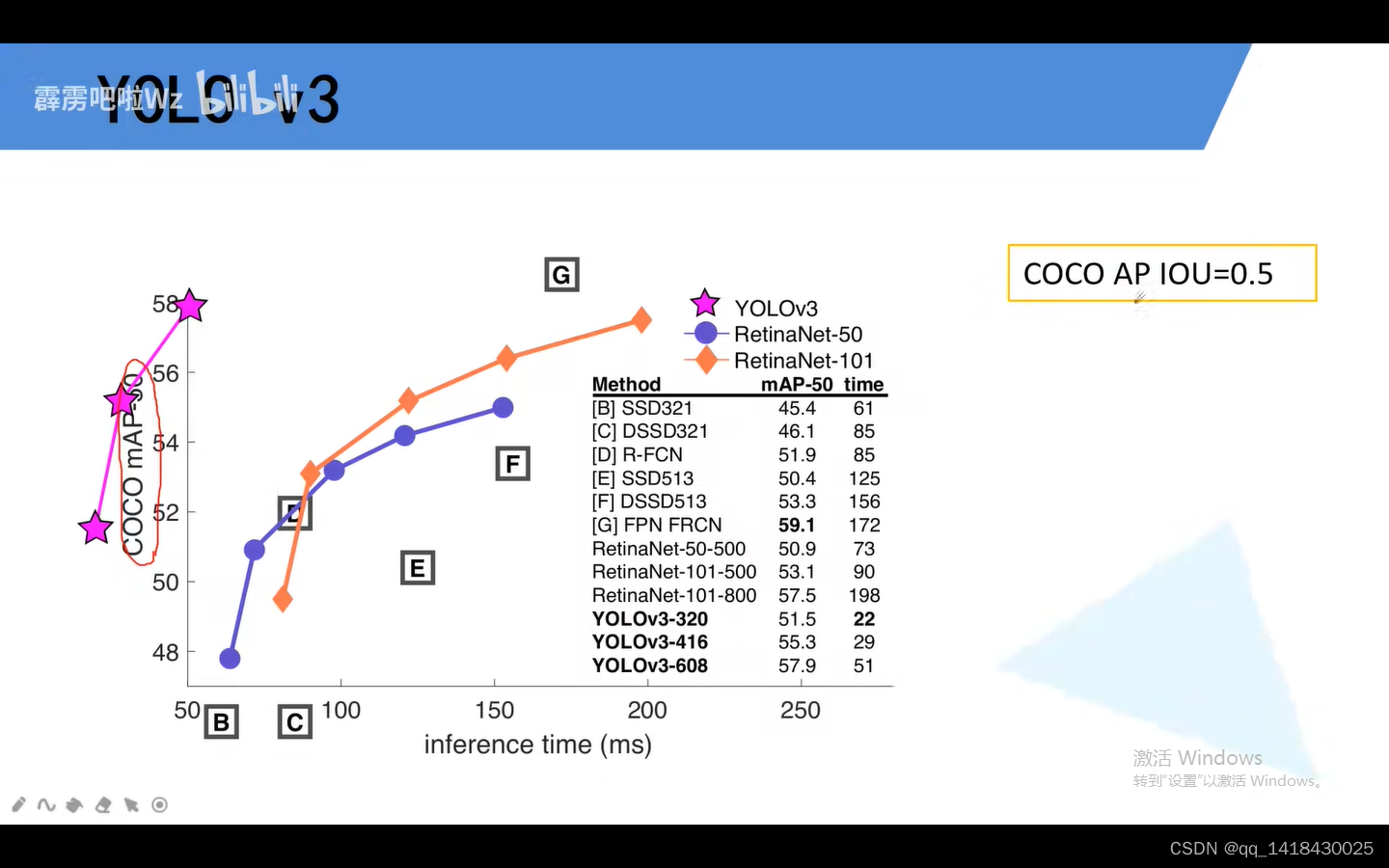
三、YOLOV3


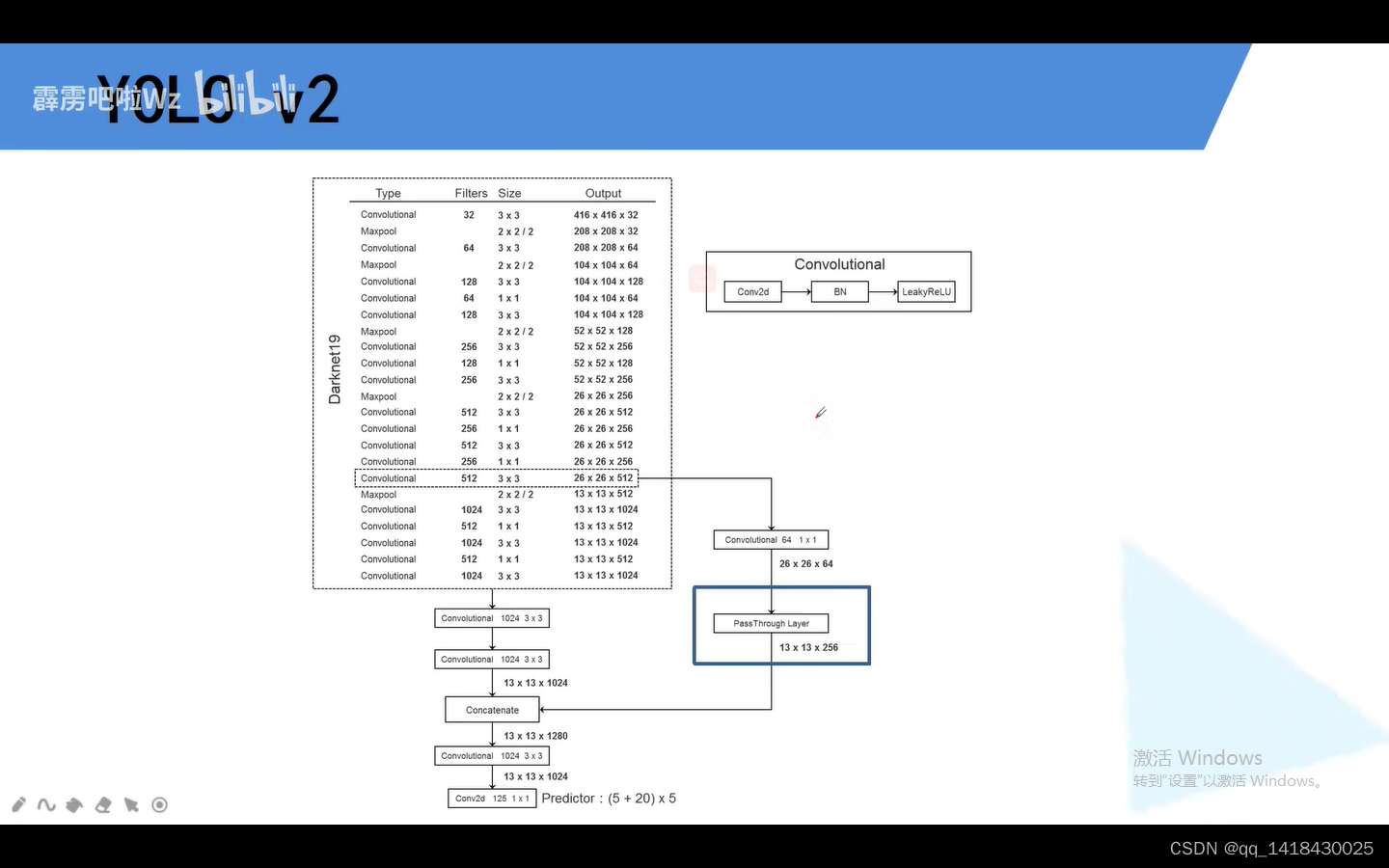
3.1 YOLOV3 采用的Darknet-53网络,YOLOV2采用的是Darknet-19网络。因为有53个卷积层,所以叫做Darknet-53网络。
Darknet-53网络中没有最大下采样maxpooling,所有的最大下采样都是通过卷积进行操作(3x3/2),即卷积替换最大下采样完成尺度的缩小。
与Resnet网络相比,Darknet-53网络卷积核的个数比Resnet少,所以运行速度比Resnet快一点点。关于详细的解释可以参照“霹雳吧啦”写的博文。
3.2 Darknet-53网络中Convolutional结构是Conv+BN+LeakyReLU;
残差结构黑色部分,不是Residual就是一个残差结构,而是Convolutional(1x1)+Convolutional(3x3)部分才是一个残差Residual部分。

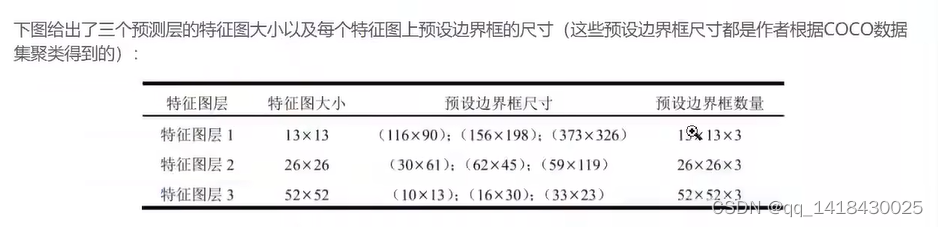
3.3 YOLOV3 会在三个预测层进行预测。每一个预测特征图上有三个不同尺度,通过聚类得到,这样三个预测层一共就有9种不同尺度。
N是特征层的大小,3是三个不同尺度,4是位置参数,1是类别置信度分数,80是类别数目(coco数据集有80个类别)
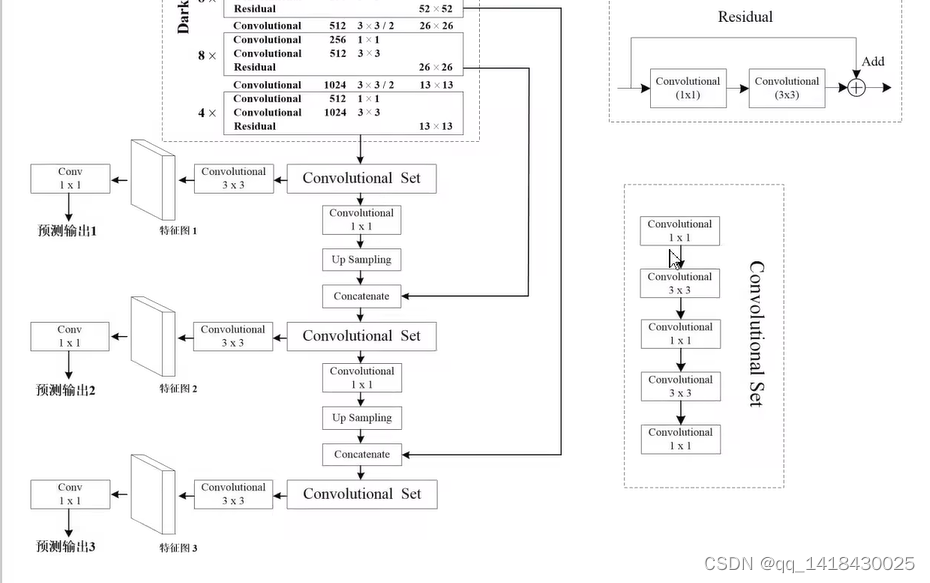
3.4 YOLOV3 会在三个预测层进行预测。
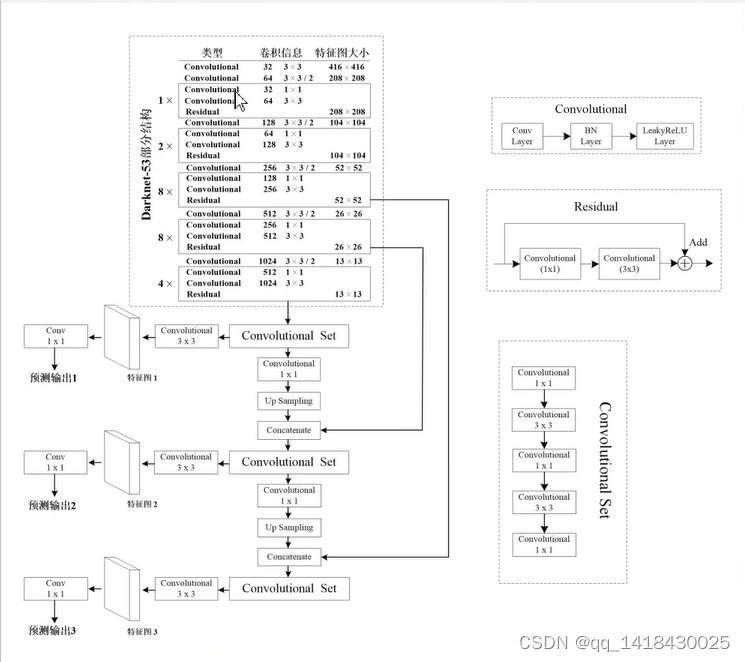
第一个预测特征层是在输入是416x416大小,最后去掉池化和全连接之后得到的13x13进行预测(通过convolutional Set+Convolutional3x3等输出);
第二个预测特征层是通过第一个的convolutional Set+Convolutional1x1+上采样up sampling,然后尺度变成26x26(高和宽扩大为原来的两倍),再将其与Darknet-53网络的倒数第二层进行深度上的拼接,concatenate(尺寸即高和宽一样,都是26x26),最后再进行通过convolutional Set+Convolutional3x3等输出;
这里采用的concatenate,与FPN特征金字塔相比,特征金字塔是在对应的维度上进行相加。(再去看看特征金字塔FPN,再来理解这个,没大理解这个,同学说两个作用差不多)
第三个预测特征层是在第二个的convolutional Set+Convolutional1x1+上采样up sampling,然后尺度变成52x52(高和宽扩大为原来的两倍),再将其与Darknet-53网络的倒数第三层进行深度上的拼接,concatenate(尺寸即高和宽一样,都是52x52),最后再进行通过convolutional Set+Convolutional3x3等输出;
综上所述:第一个预测特征层输出是13x13,第二个预测特征层是26x26,第三个特征层是52x52.分别对应预测大尺度,中尺度,小尺度的目标。

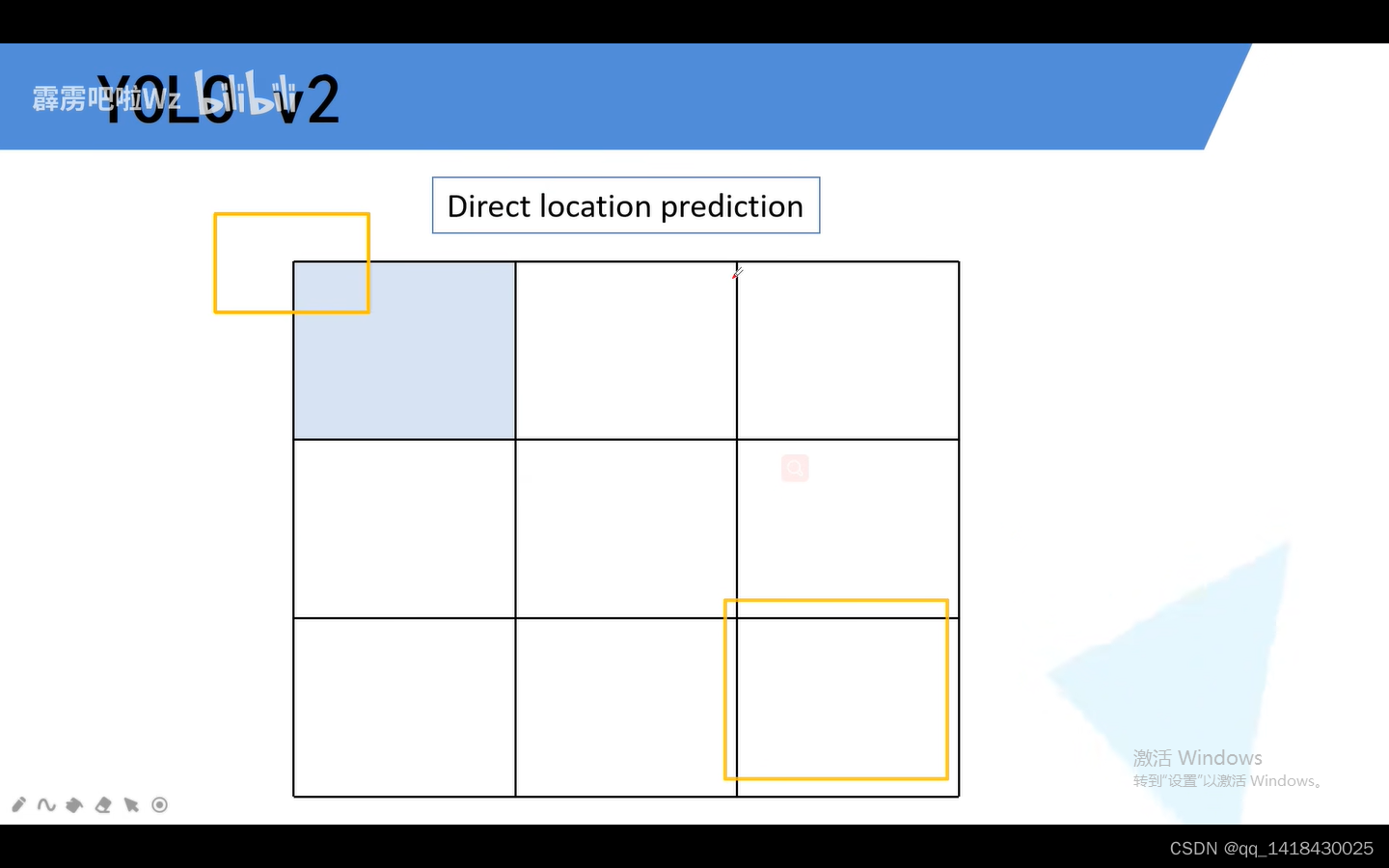
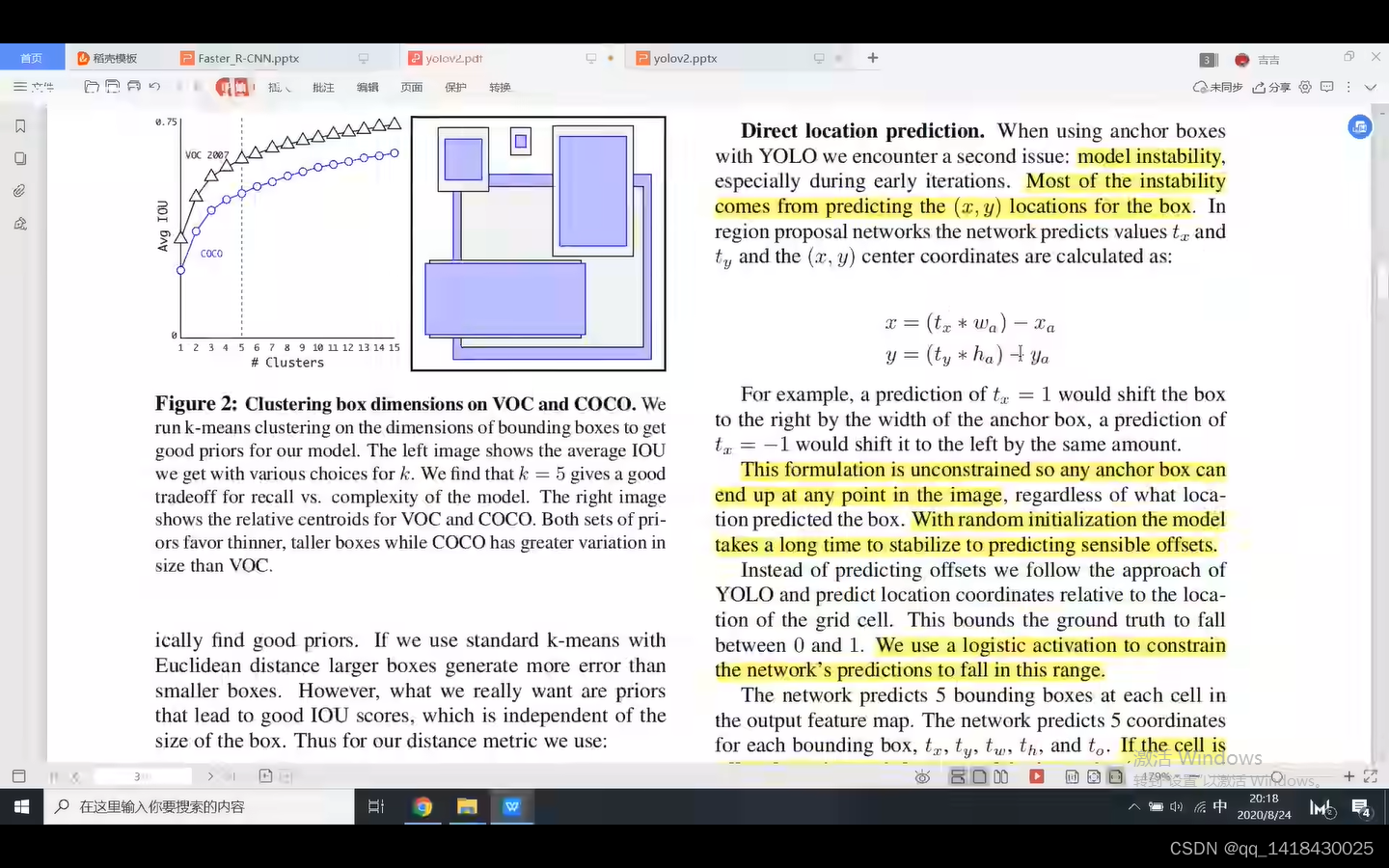
3.5 YOLOV3 采用和YOLOV2预测目标边界框一致,但是和SSD、Fast RCNN之前都不一样,之前是网络预测目标中心点回归参数是相对于Anchor的偏移量,而YOLOV3网络预测目标中心点回归参数不是相对于Anchor的偏移量,而是相对于当前边界框cell的左上角坐标。(将预测边界框的中心限制在当前cell中。)
从前面的网络结构图当中可以看出,最后三个不同尺度的预测特征图都是通过1x1卷积在最终预测特征层上进行预测输出。YOLOV3有三个预测特征层,每一个预测特征层有三个不同的模板。
假设现在是某一个预测特征层,当1x1卷积滑动到当前窗口时候,会对三个不同的模板都进行预测四个位置参数(Tx Ty Tw Th)+一个置信度分数+每一个类别分数(根据数据集采用,coco80类)。
虚线矩形框对应的就是anchor,Pw是anchor的宽度,Ph是anchor的高度。蓝色边界框是网络最终预测目标的一个位置及大小。
Bx=sigmoid(Tx)+Cx,Cx是当前cell的左上角x坐标,Bx是最终预测目标的x坐标,Tx是网络预测的位置参数x.
同理By=sigmoid(Ty)+Cy,Cy是当前cell的左上角y坐标,By是最终预测目标的y坐标,Ty是网络预测的位置参数y.
Bw=Pw*ETw,其中Bw是最终预测目标的宽度,Pw是anchor的宽度.
Bh=Ph*ETh,其中Bh是最终预测目标的高度,Ph是anchor的高度.
综上所述:通过公式即可将网络预测的四个位置回归参数转化为最终目标边界框的位置参数。

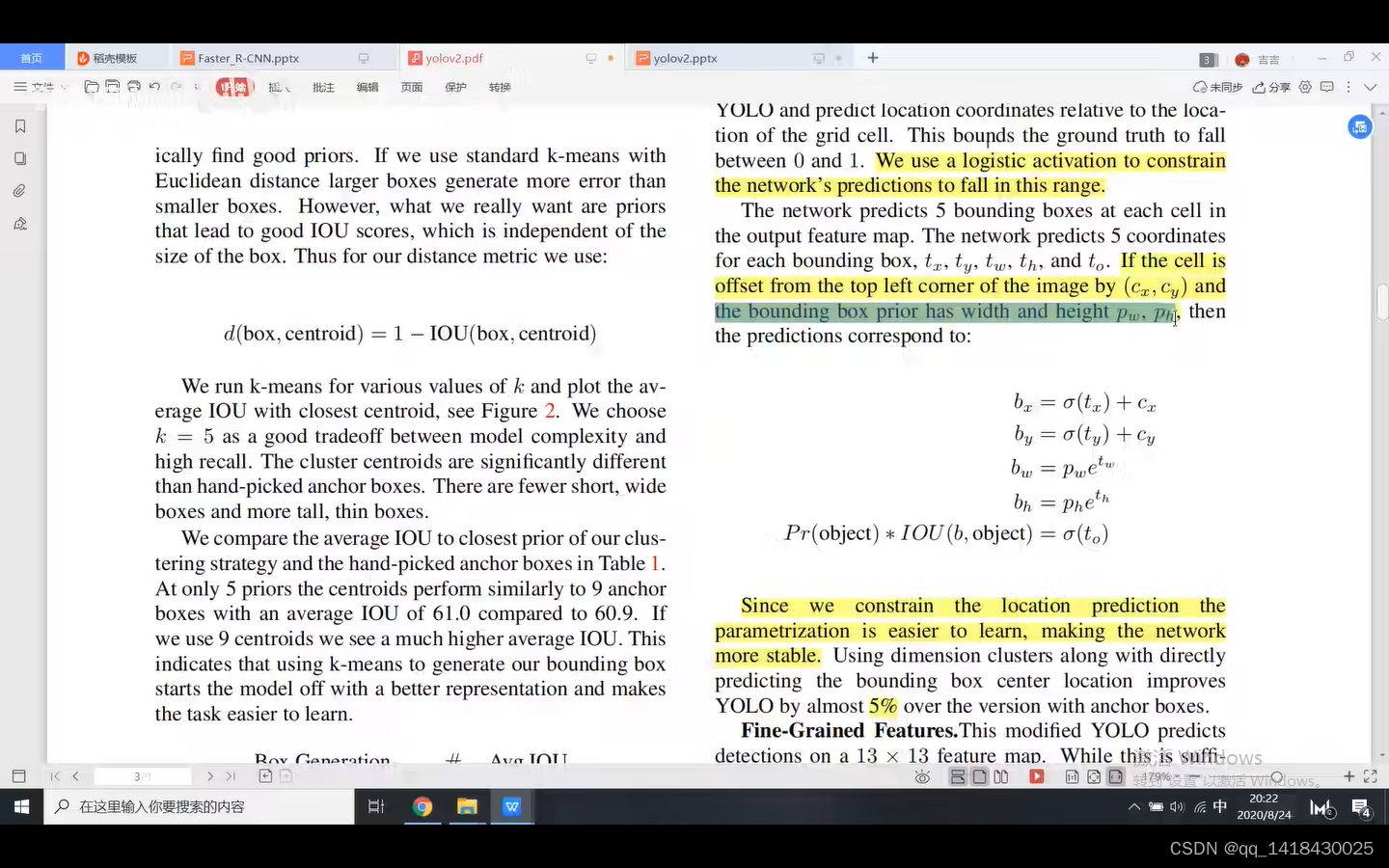
3.6 正负样本匹配:针对一张图片有几个GT,我们就分配几个bounding box(prior),即每一个GT我们仅仅分配一个bounding box(prior)。
原则:1.与GT重合程度最大的bounding box(prior)作为正样本;
2.对于bounding box(prior)与GT也重合但他不是最大,比如超过某个阈值0.5,我们直接丢去这个预测结果。即既不是正样本也不是负样本。
3.如果bounding box prior没有任何GT,那么它没有位置和类别预测,仅仅有confidence score。
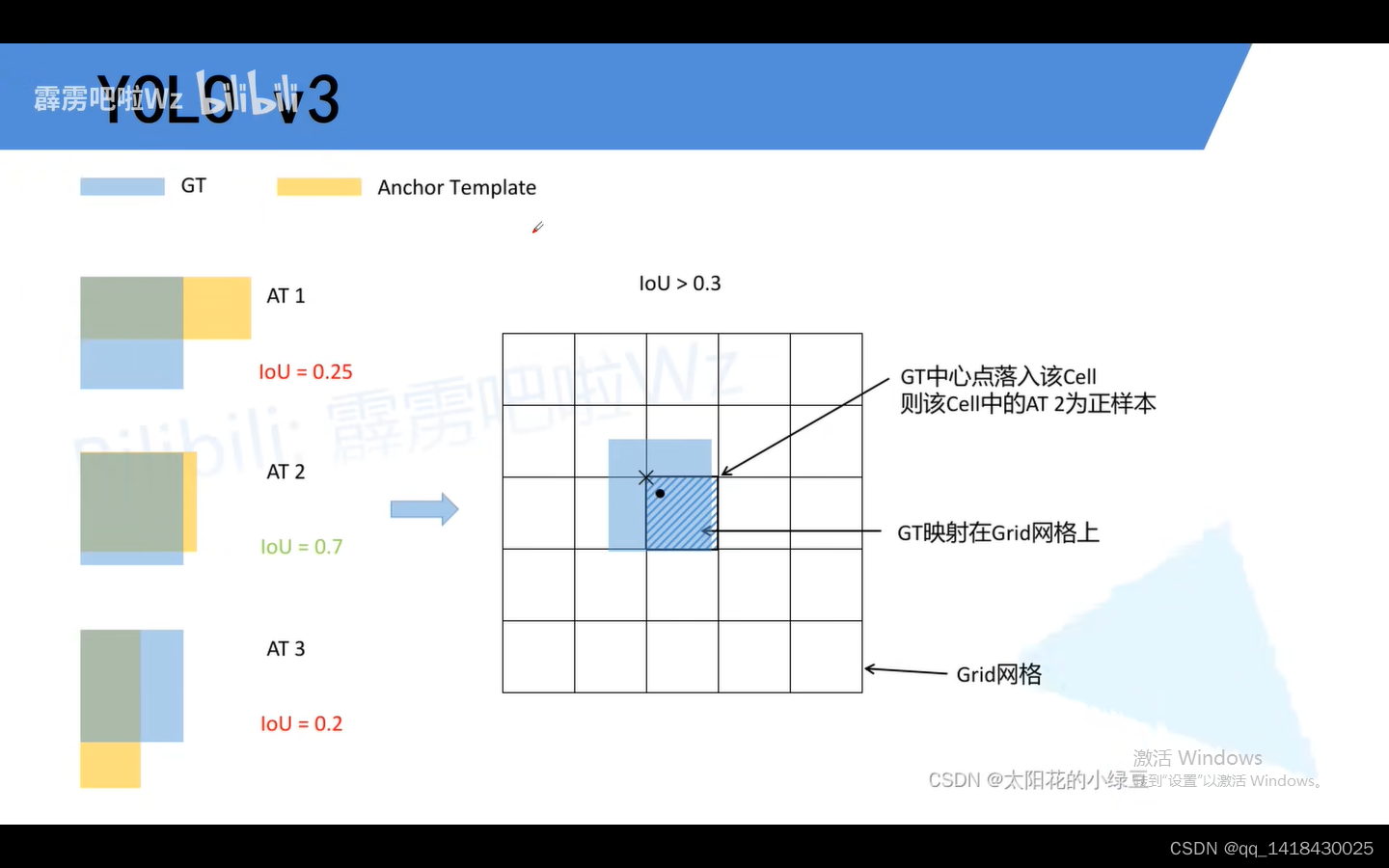
3.7 u版的实现准则(实现部分):蓝色对于GT,黄色对于是Anchor 模板。将每一个GT与anchor 模板左上角进行一个重合再计算IOU,通过设置一个阈值比如0.3,大于0.3阈值的我们都会变成正样本,即第二个模板中满足条件。然后将GT映射到Grid网格(预测特征层上),黑色圆点对应的是GT的中心点。GT中心点落在哪个cell中,就由该cell当中满足阈值的模板作为正样本。通过此方法大大加大原论文中正样本数目,因为原论文中仅仅把只和GT重合度最高的anchor作为正样本数目。

损失包括置信度损失、分类损失和定位损失,原论文中并没有给出损失计算公式。

置信度损失:confidence score使用的是逻辑回归,逻辑回归大部分采用二值交叉熵损失。oi表示预测目标边界框与真实目标边界框的IOU,蓝色代表anchor(bounding box/prior),绿色是GT box,通过预测目标边界框的偏移量应用到anchor上得到黄色的边界框,即预测目标边界框。绿色对应真实目标边界框,即黄色与绿色边界框的IOU交并比是oi.

类别损失:也采用二值交叉熵损失。Oij表示预测目标边界框i中是否存在第j类目标,如果存在即为1,不存在即为0.

预测概率加起来并不等于1,预测概率之和为1的是softmax函数,通过sigmoid函数并不一定为1,每一个预测值之间是互不干扰,相互独立。自定义公式与官方给的公式是一模一样。
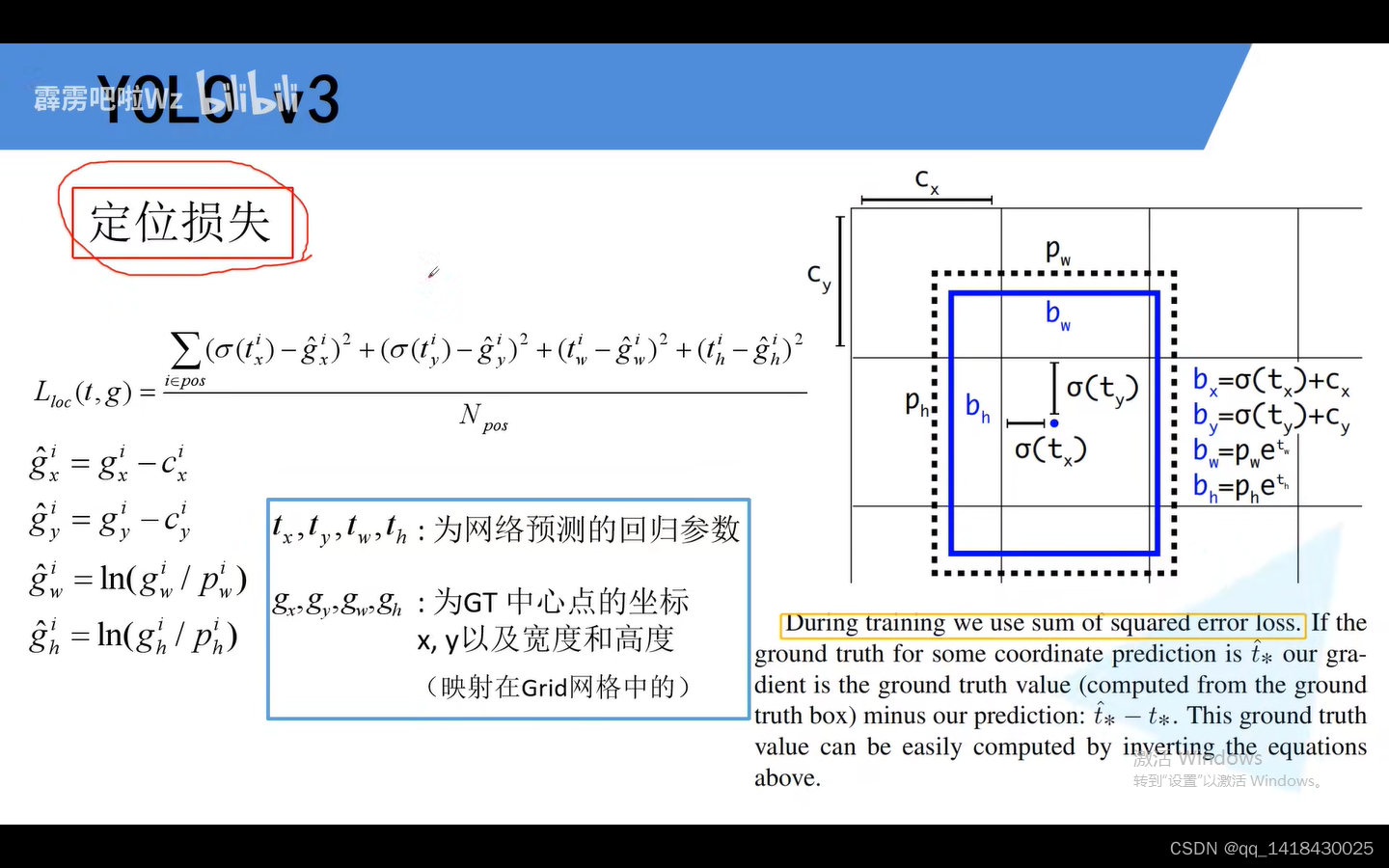
t为网络预测回归参数,g^为对应真实中心点坐标以及宽高回归参数,预测值-真实值,再取平方,最后再求和。g为对应GT中心的坐标以及宽高参数(gt映射到对应的网格当中)。
四、YOLOV3 SPP
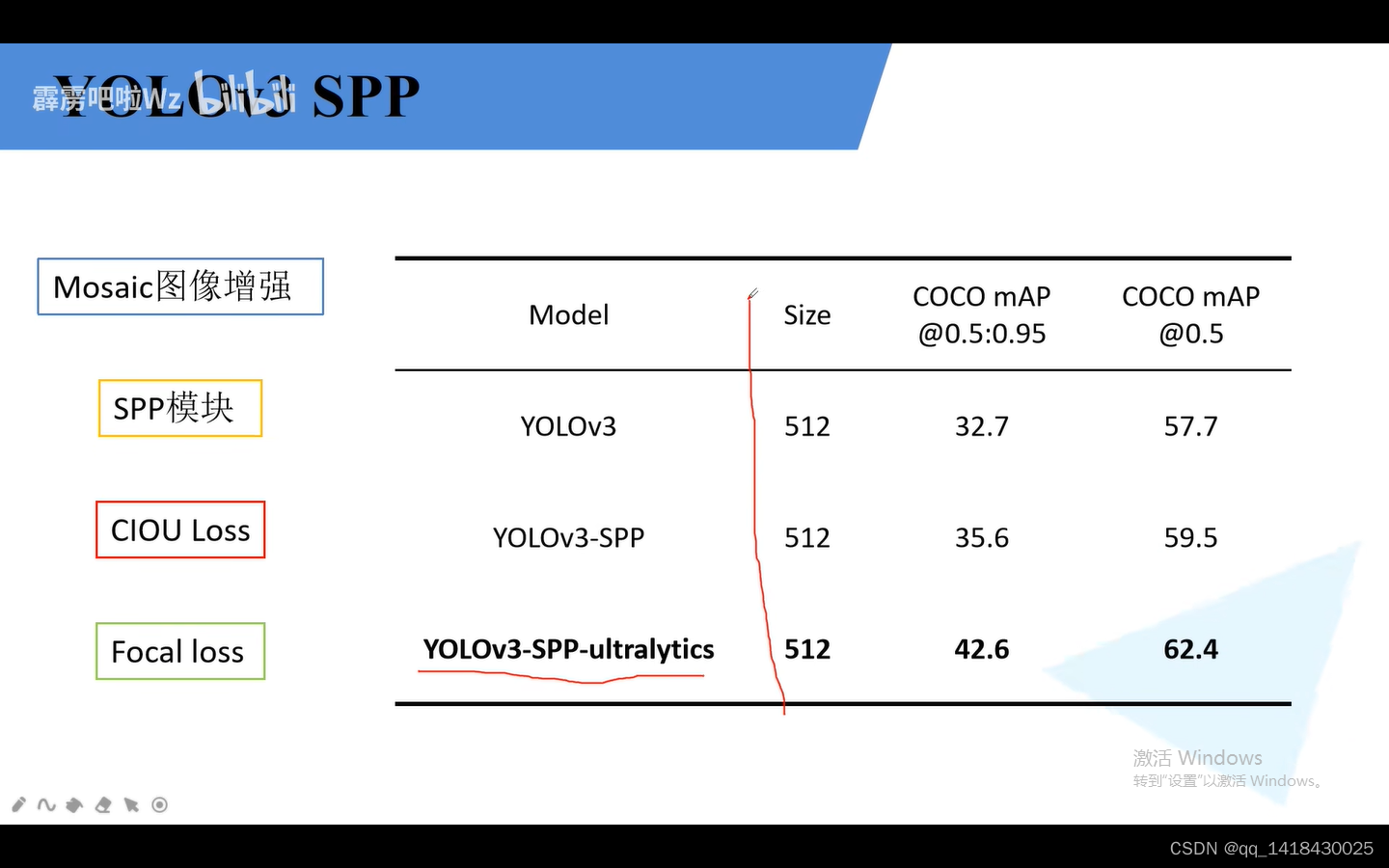
4.1 YOLOv3-spp使用了Mosaic图像增强,SPP模块和CLOU loss.默认不使用Focal loss。

总结:Mosaic图像增强就是将多张图片进行输入进入训练。理论上batsize越高对于BN越好,但是由于设备受限,不一定能达到理想。此时将多张图片输入到网络中等价于将batsize增加。
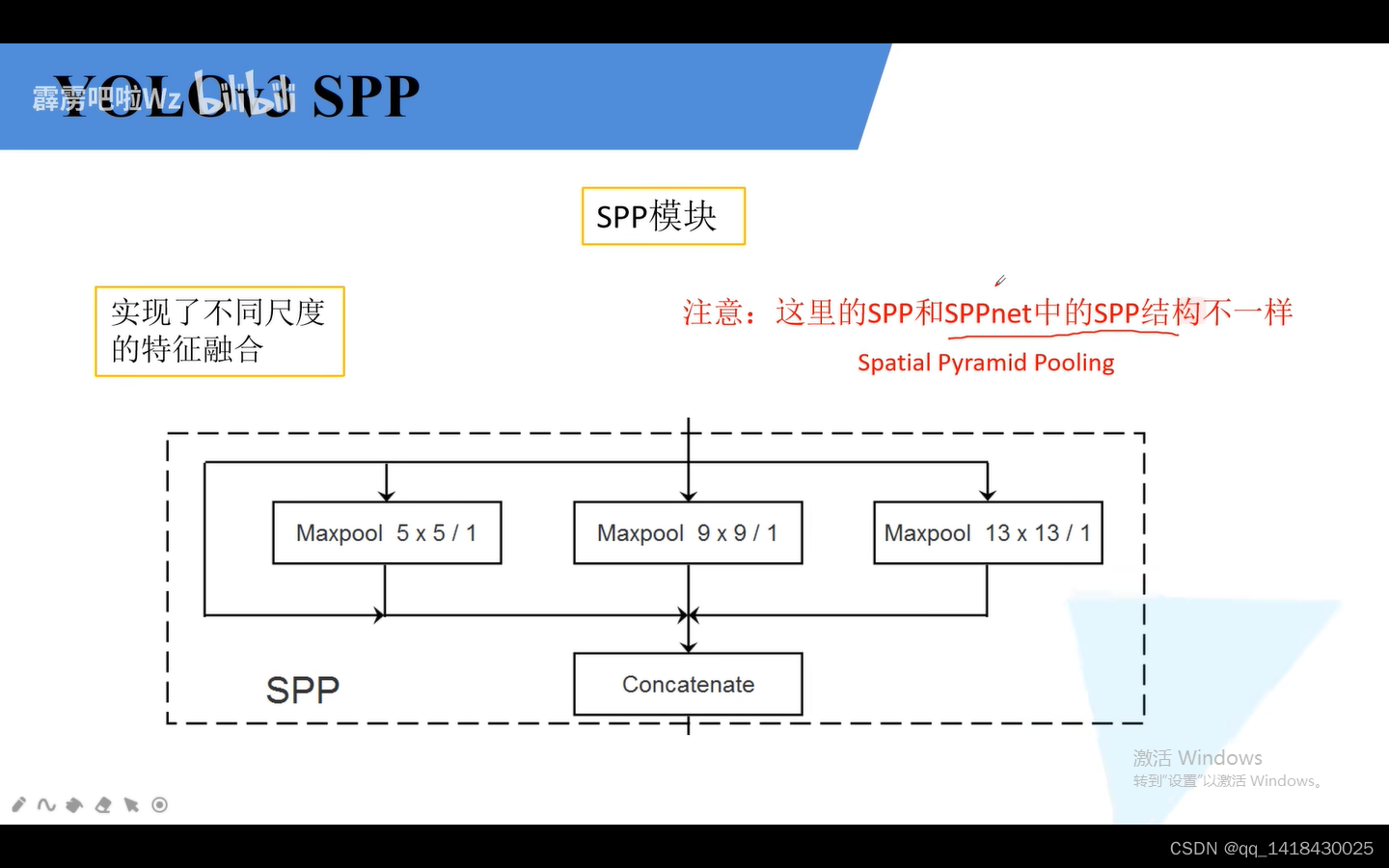
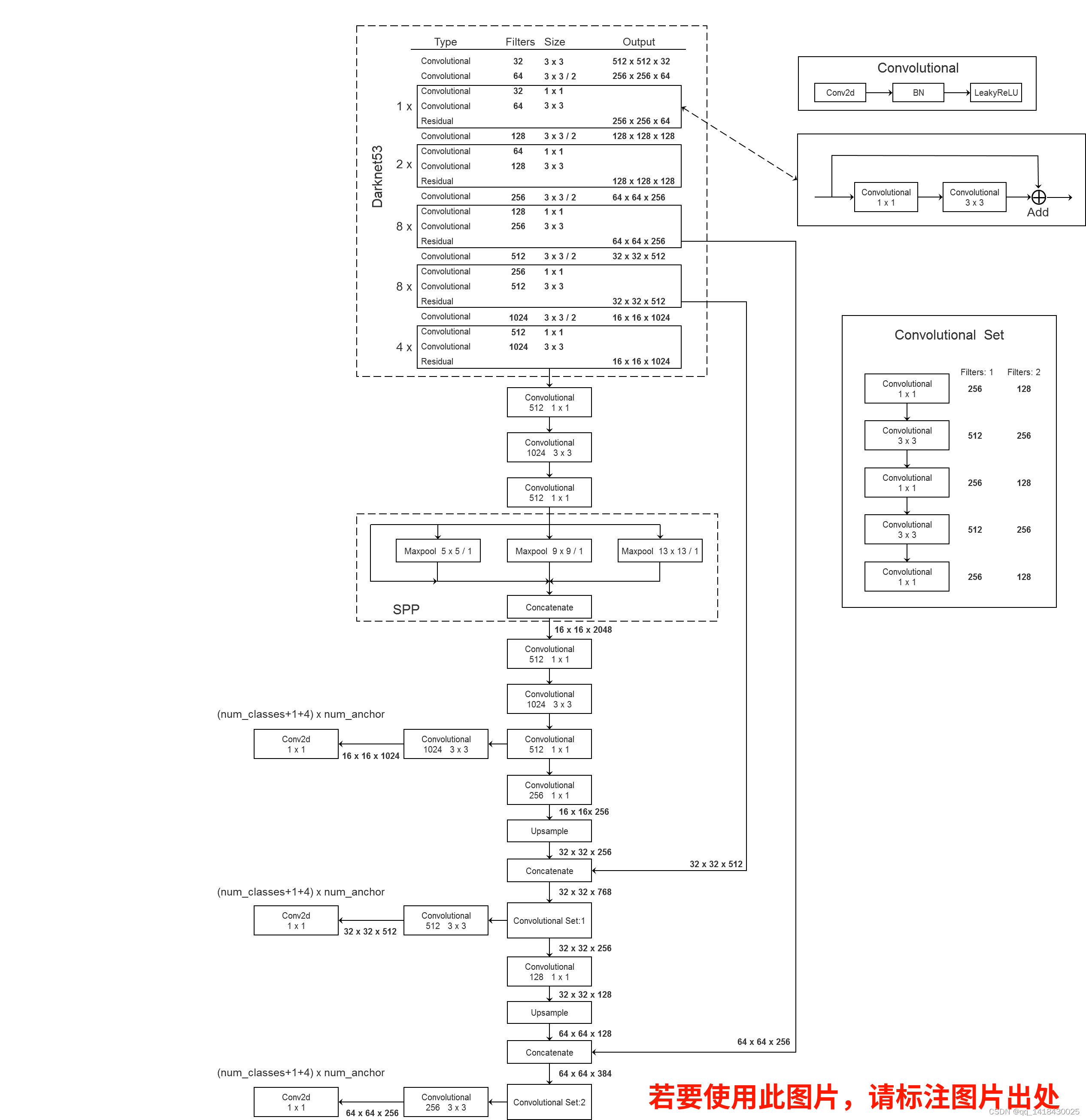
4.2 YOLOv3-spp和YOLOv3相比,在第一个预测特征层上增加了一个SPP结构。
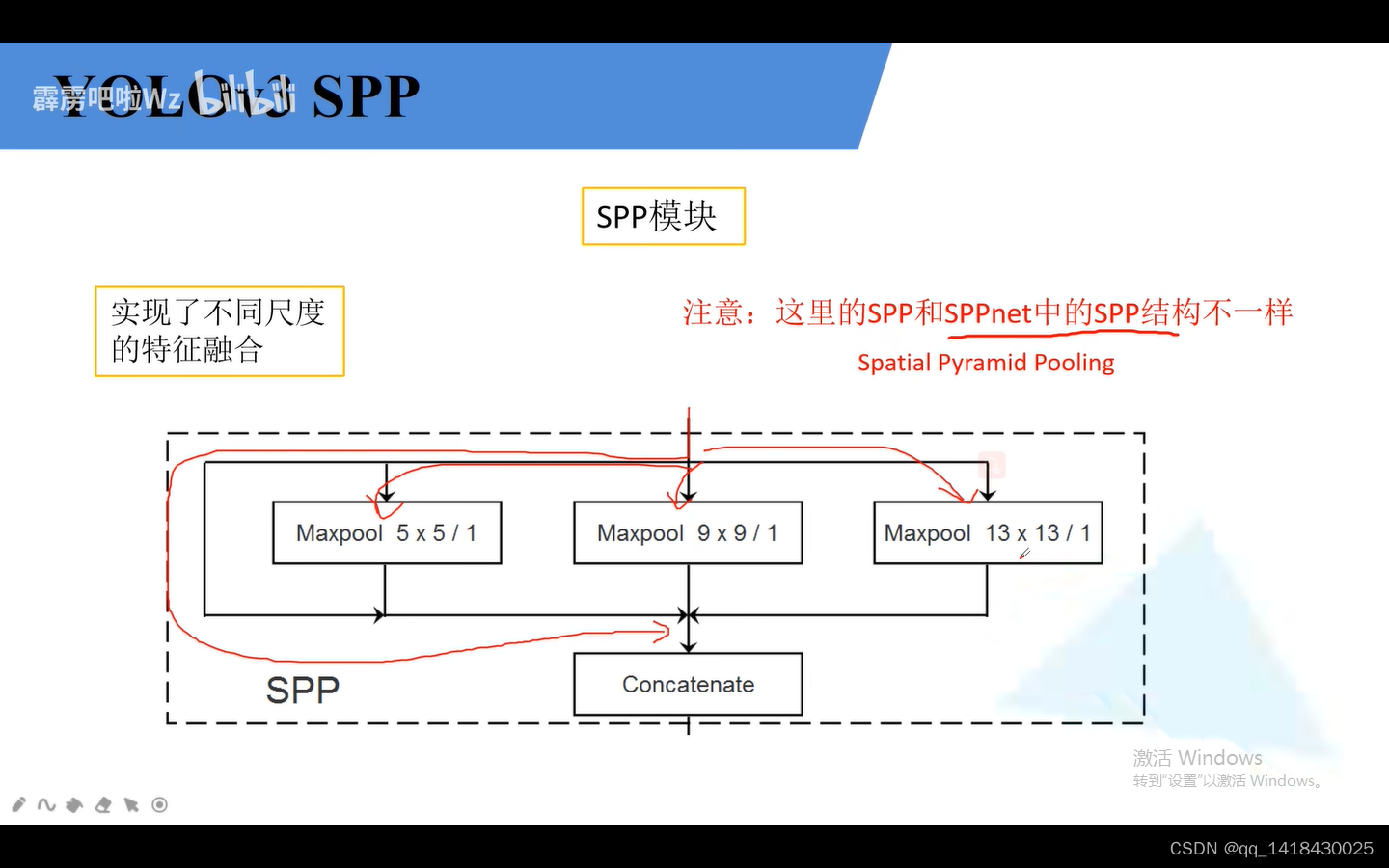
SPP结构:四个分支。分别是直接输出、一个池化5x5、一个池化9x9、一个池化13x13(步距都是1),通过padding填充之后高度和宽度以及深度都没有发生变化。最后再进行concatenate拼接。通过这个SPP就实现了不同尺度的特征融合。
在经过darknet-53主干后,通过三个卷积之后变成16x16x512.然后再经过SPP结构,输出尺寸不变,深度变为原来的四倍。即变成16x16x2048.
SPP结构就是将不同分支的深度进行拼接,尺寸不变,通道数增分支倍数。
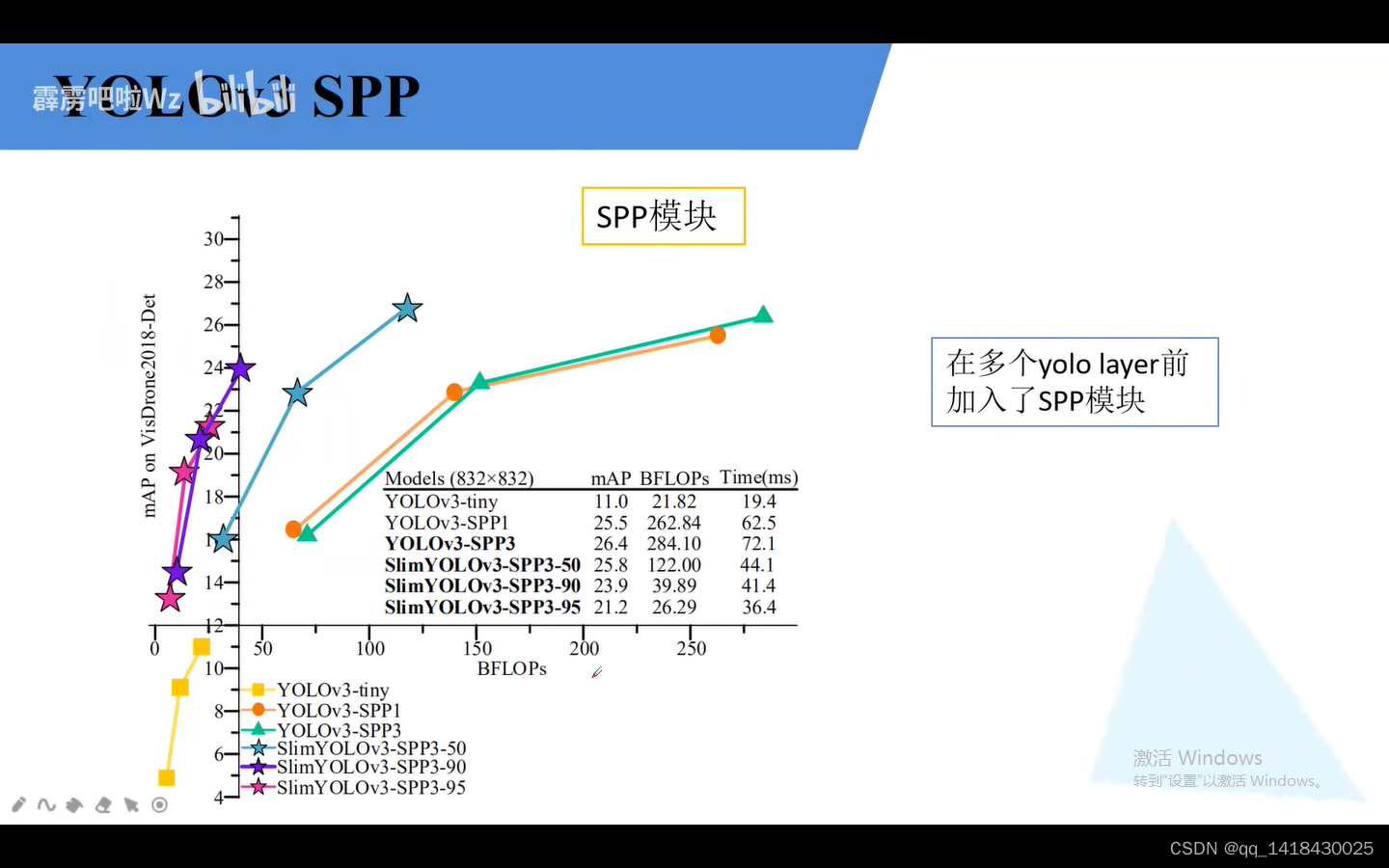
理论上也可以将第二个输出和第三个输出之间再增加SPP结构,但是实验表明增加了多个SPP模块提高性能并不特别高,而且推理时间也增加了。(下图)

4.3 之前的YOLOv3损失采用的是差值平方的计算方法,L2损失。
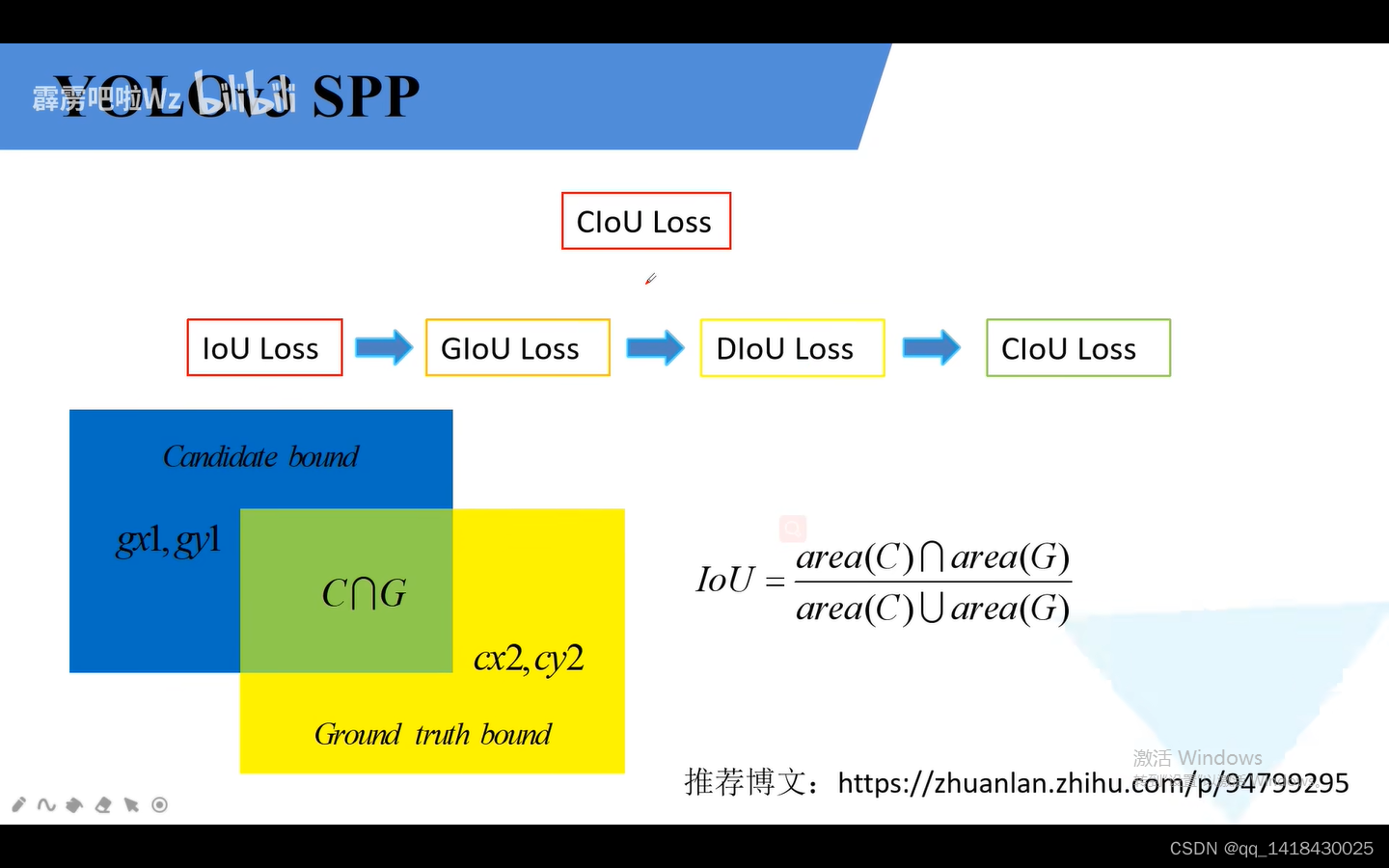
YOLOV3 SPP损失是一系列 iou loss:iou loss、glou loss、SDIOU CLOU.其中SDIOU CLOU损失是在同一篇论文提出的。
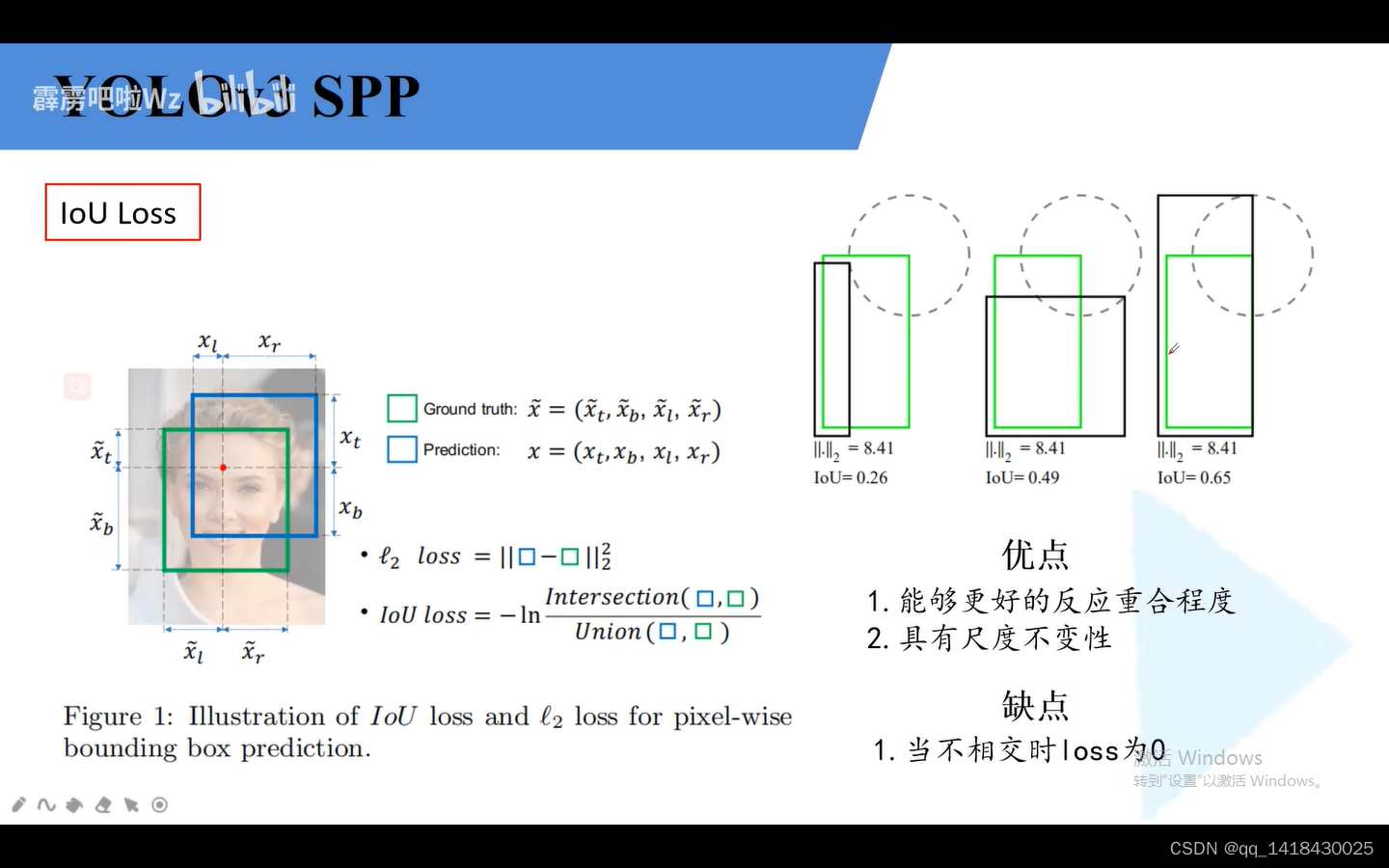
1.IOU loss:绿色代表GT box,黑色代表预测边界框。第三个预测效果较前两个好。他们l2损失都是一样的。IOU LOSS=1-IOU另一个常见计算公式。当两个框没有交集,即 IOU loss为0.
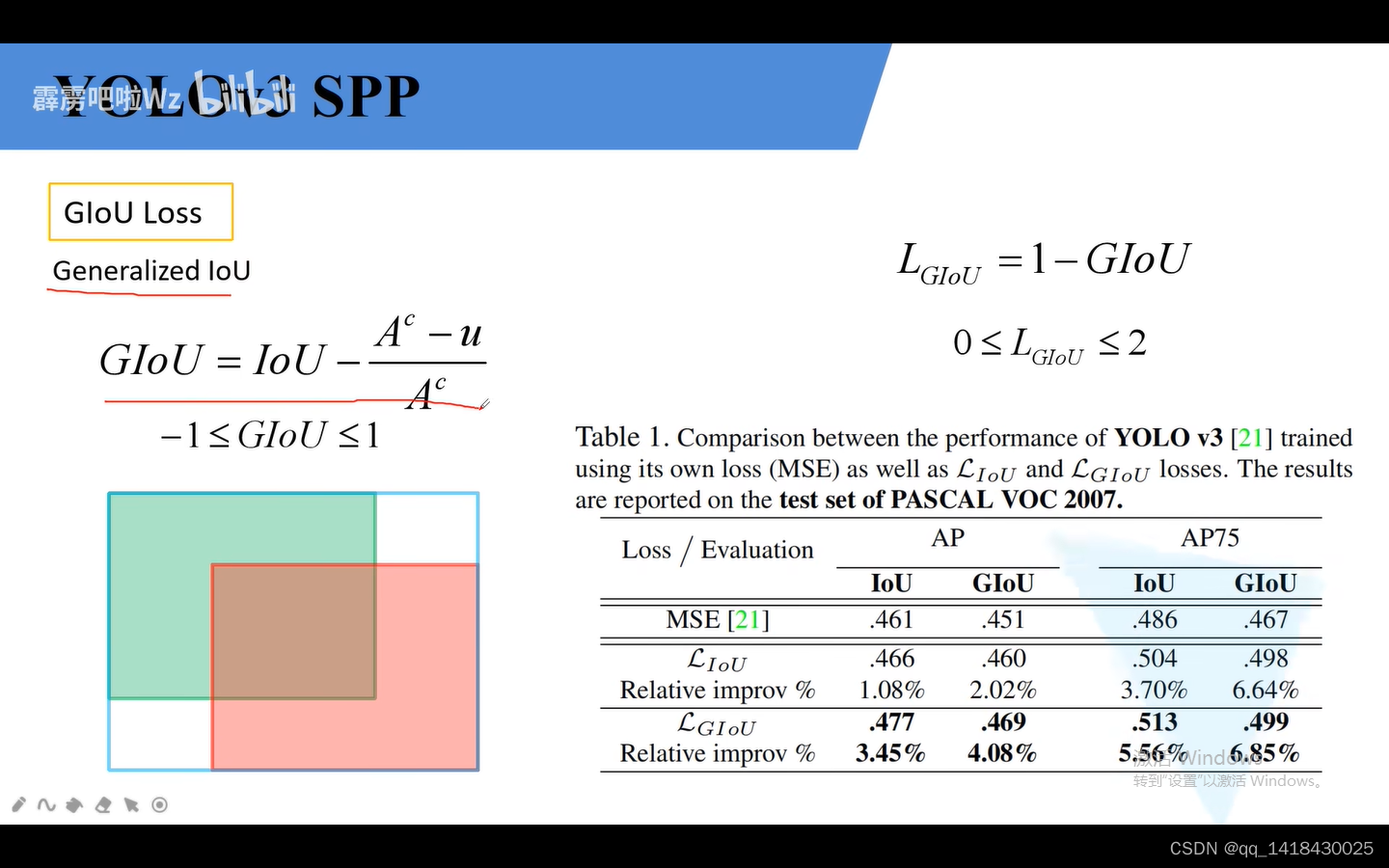
2.GIOU loss:绿色代表GT box(真实边界框),红色代表预测边界框。蓝色边界框代表用最小的矩形边界框框住。蓝色边界框面积即为Ac,两个边界框的并集即为U。
当两个框是完全重合时候,AC最小的矩形边界框=U两个边界框的并集,即GLOU为IOU=1。
当两个框是完全分开时候,AC最小的矩形边界框是无穷,U两个边界框的并集是一个常数,IOU趋近于0,后面趋近于1,所以是-1。
综上:GIOU在-1和1之间。
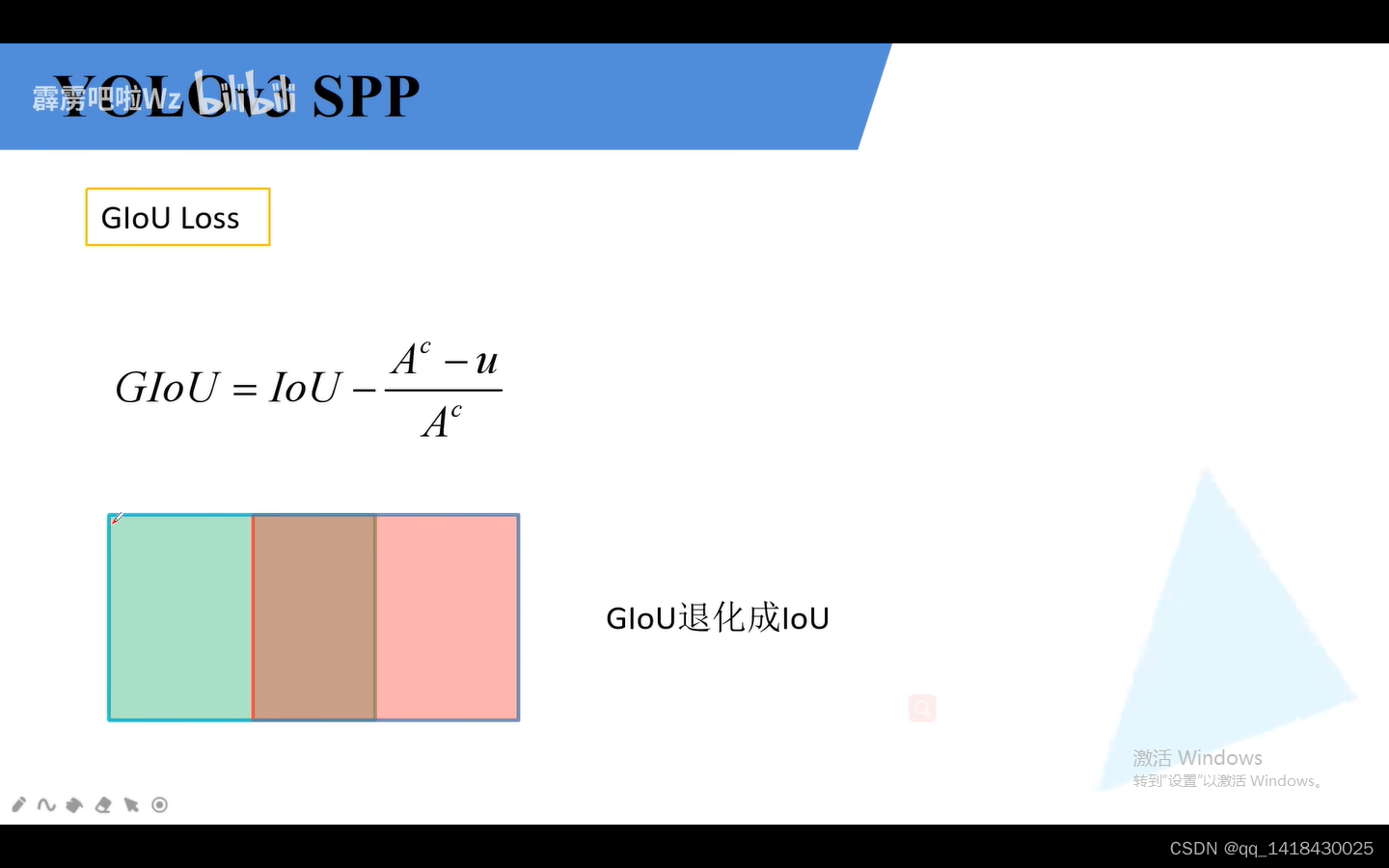
giou LOSS=1-GIOU 在某些情况下GIOU=iou
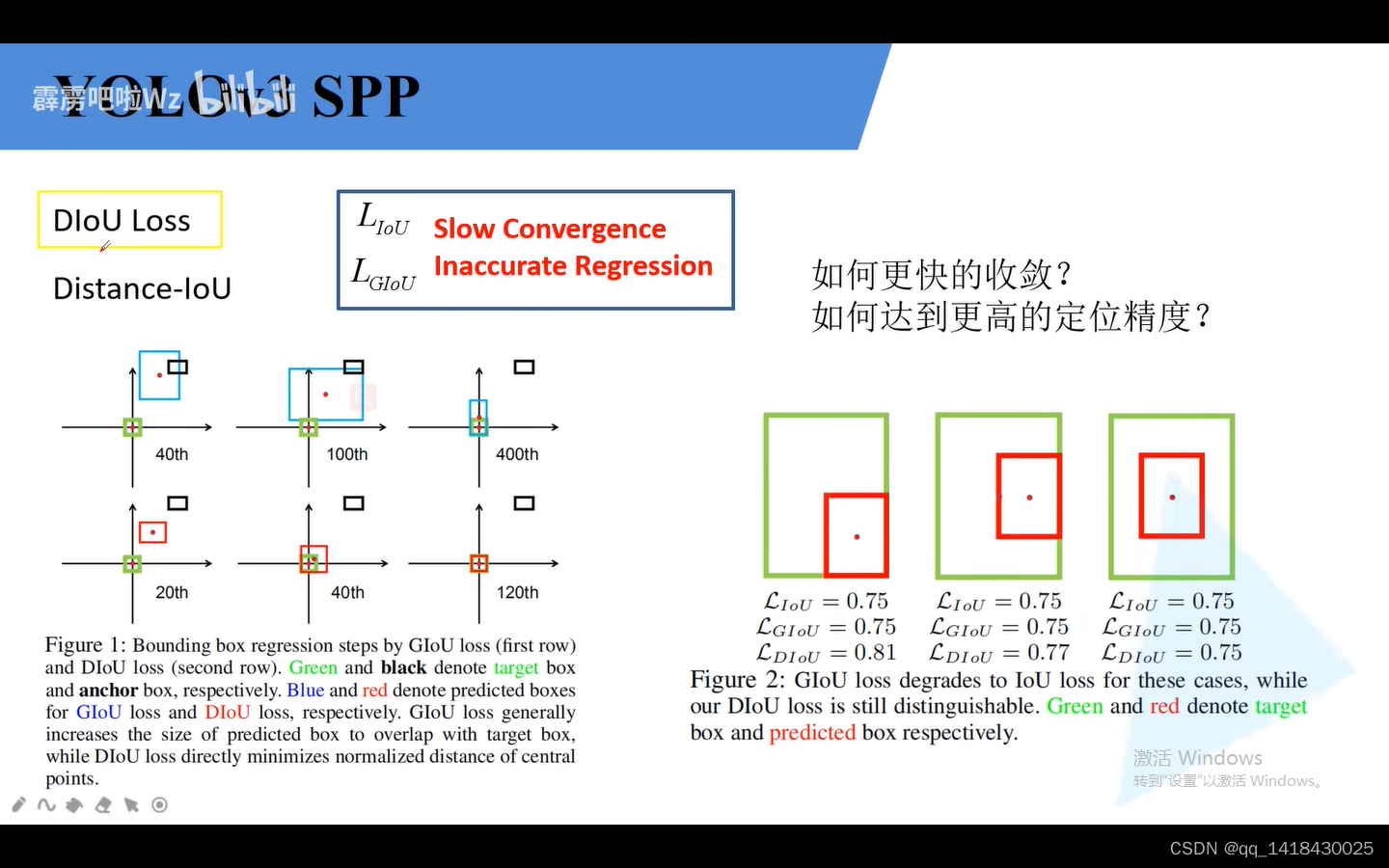
3.dIOU loss:左边上图是GIOU,下图是DIOU.黑色是anchor,绿色是真实边界框,蓝色是预测边界框。左图想说明是DIOU可以迭代相同次数甚至更小的迭代次数达到比GIOU更好的重合预测。
右边图说明了三组图片的GIOU,IOU相同,但是diou不相同。
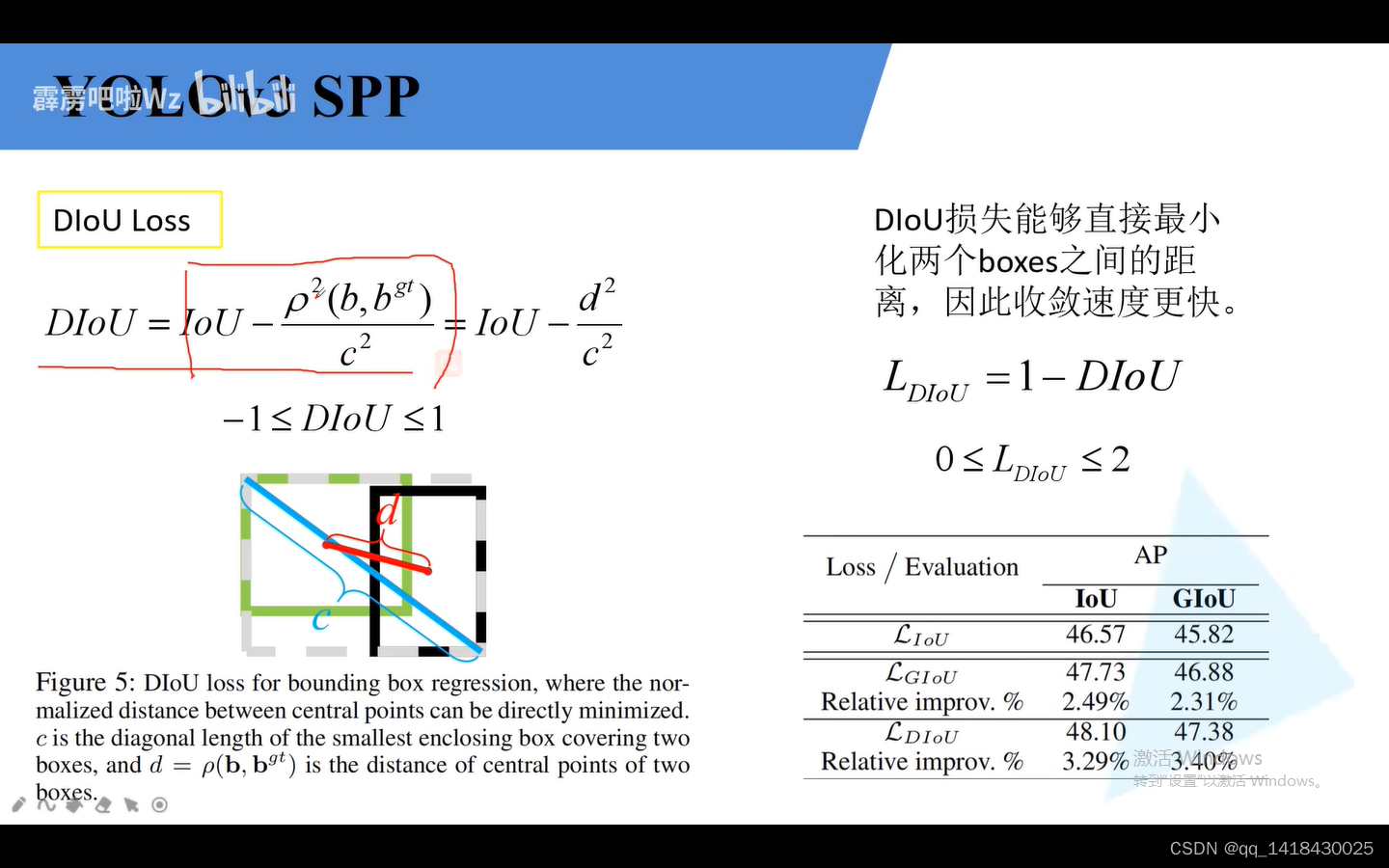
B代表预测边界框的中心坐标(黑色),Bgt代表真实目标边界框的中心坐标(蓝色),c代表最小外接矩形的最小距离。
当两个边界框完美重合时候,d两个边界框的中心距离为0,iou=1
当两个边界框相聚无穷远时候,d和c比值为1.iou=0
综上:diou在[-1,1]
DIOU LOSS=1-DIOU
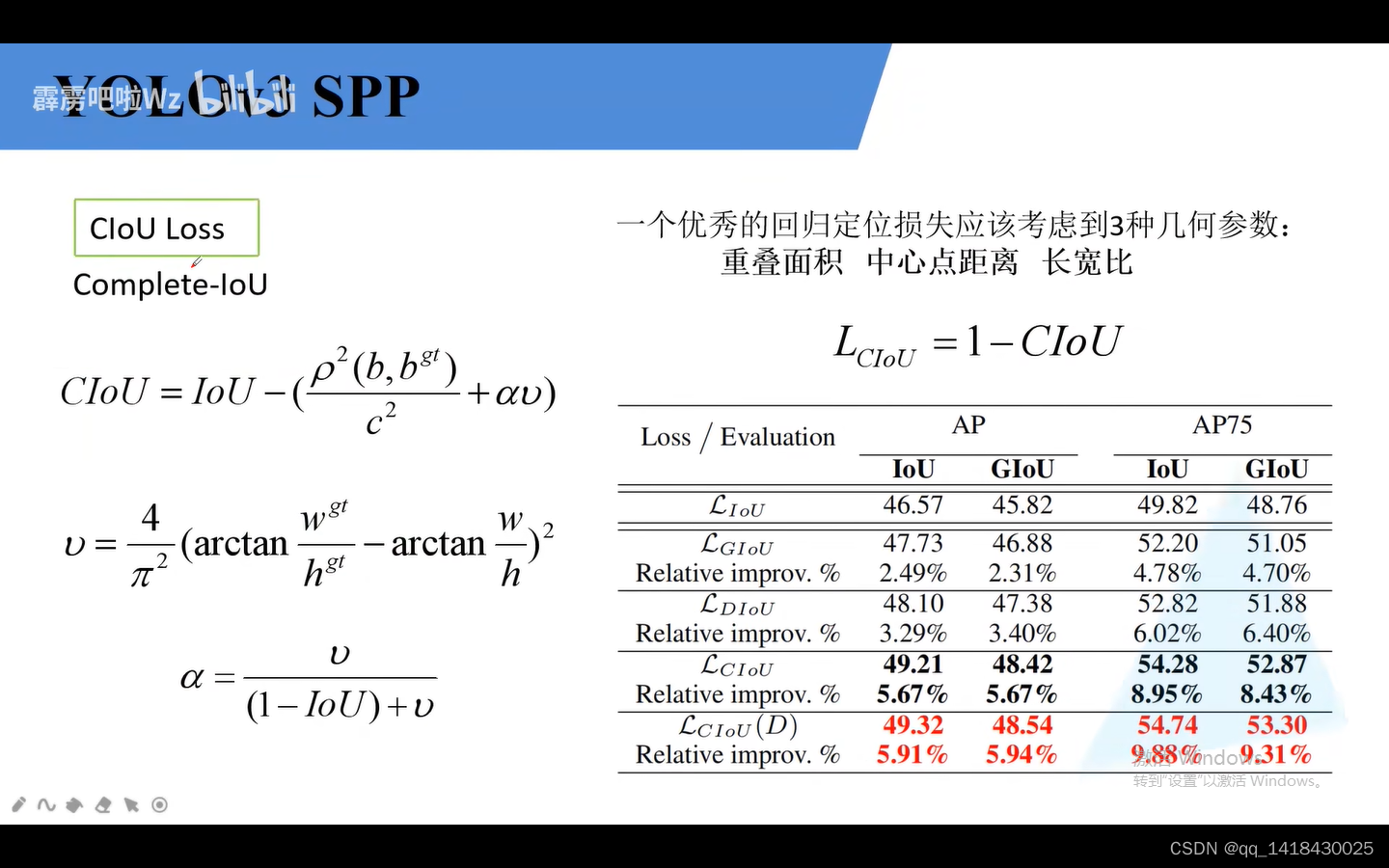
4.CIOU loss:损失最重要的三个参数:重叠面积(IOU) 中心点距离(DLOU) 长宽比(clou)
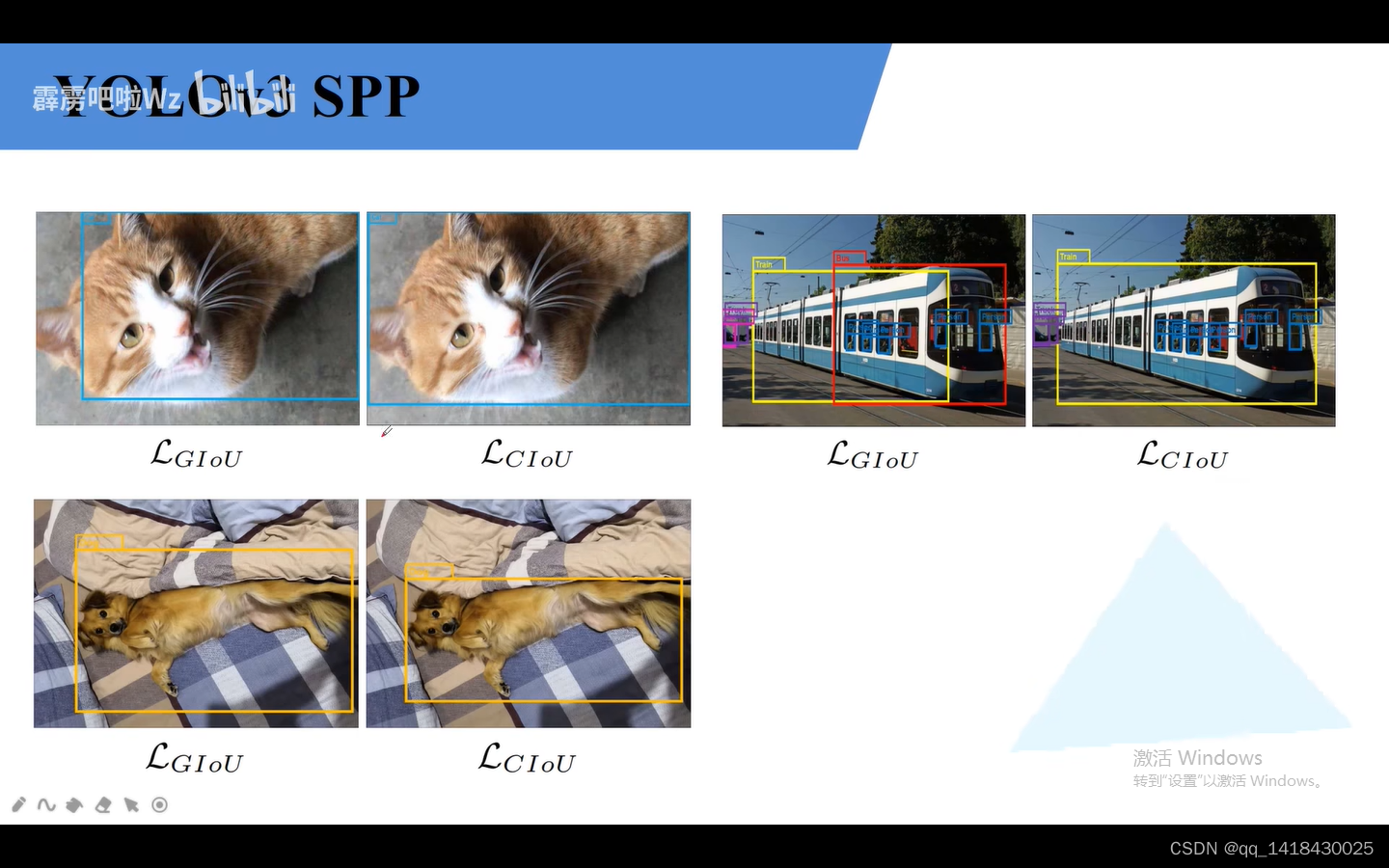
介绍了IOU GIOU DIOU CIOU理论之后,发现使用CLOU的效果比GIOU好很多。有时候和调参也有关系,不一定CLOU就效果非常好。
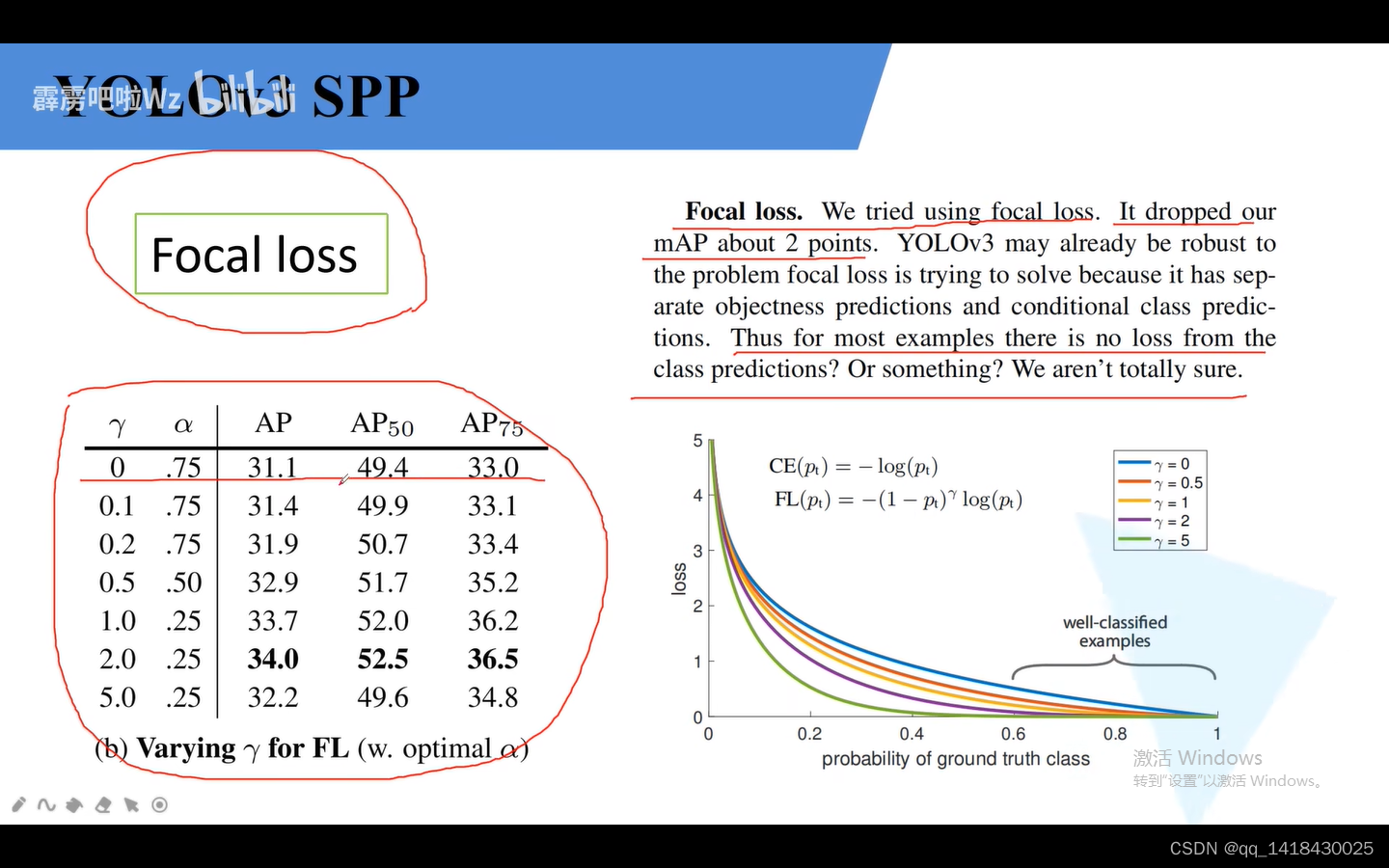
4.4 之前的YOLOv3尝试使用Focal LOSS结果效果并不好,甚至MAP还降低了两个点.但有的使用之后效果还可以,如左图的使用之后效果增加了几个点。

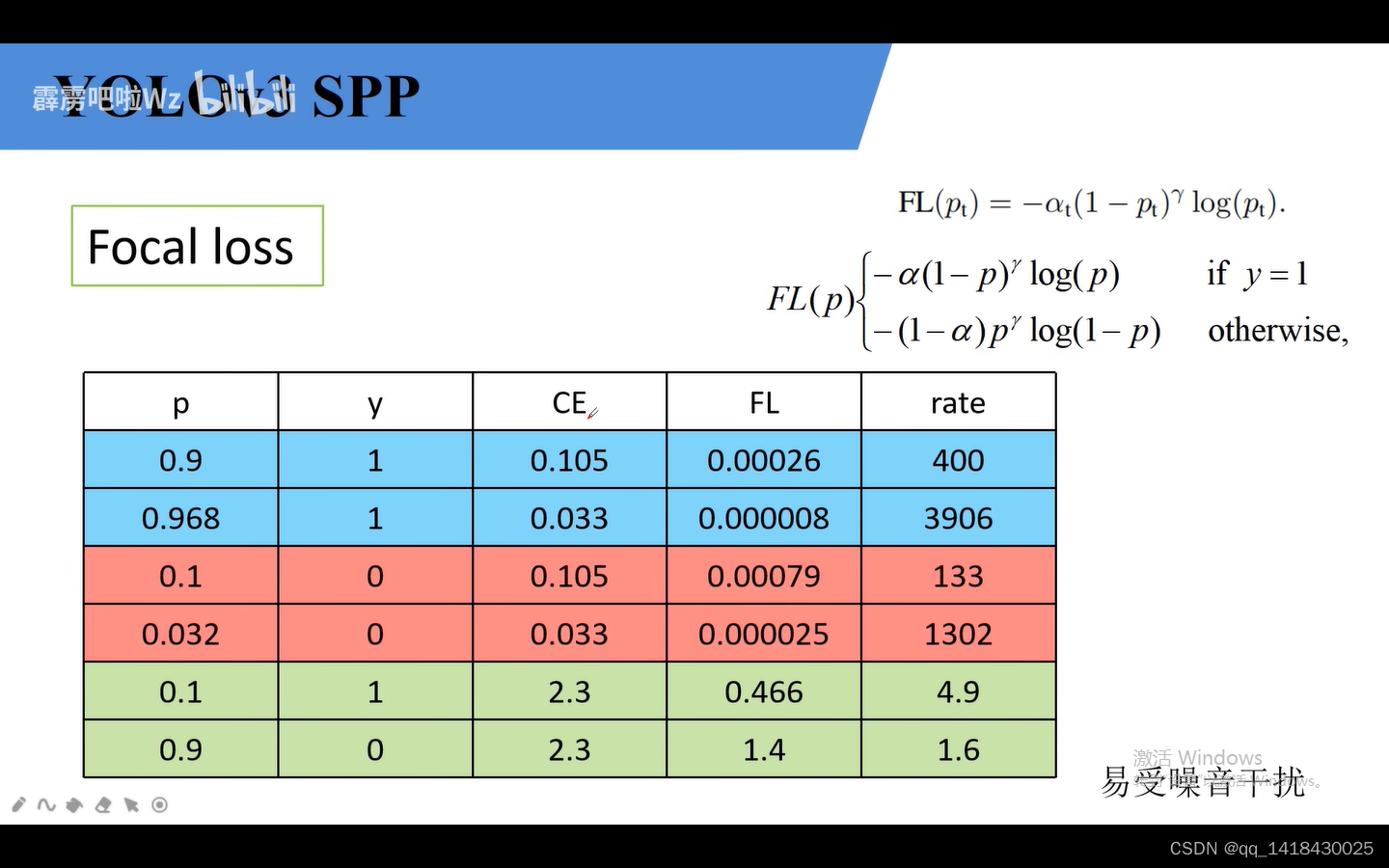
Focal Loss针对单阶段目标检测网络:解决正负样本不平衡的问题。使用Focal Loss之后效果还可以,相比于hard negative mining(选取损失比较大的负样本)
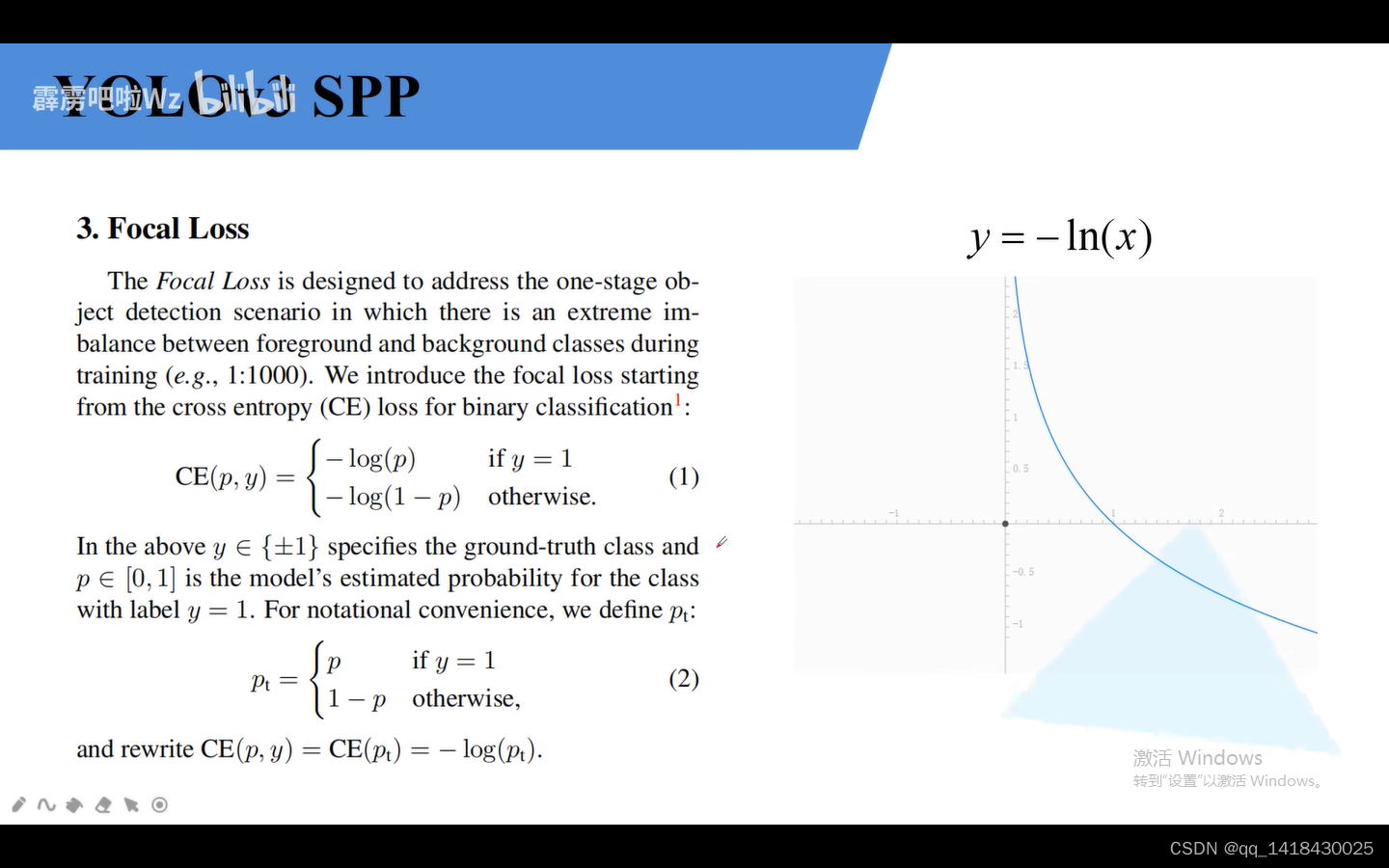
Focal Loss针对单阶段目标检测网络:解决正负样本不平衡的问题。
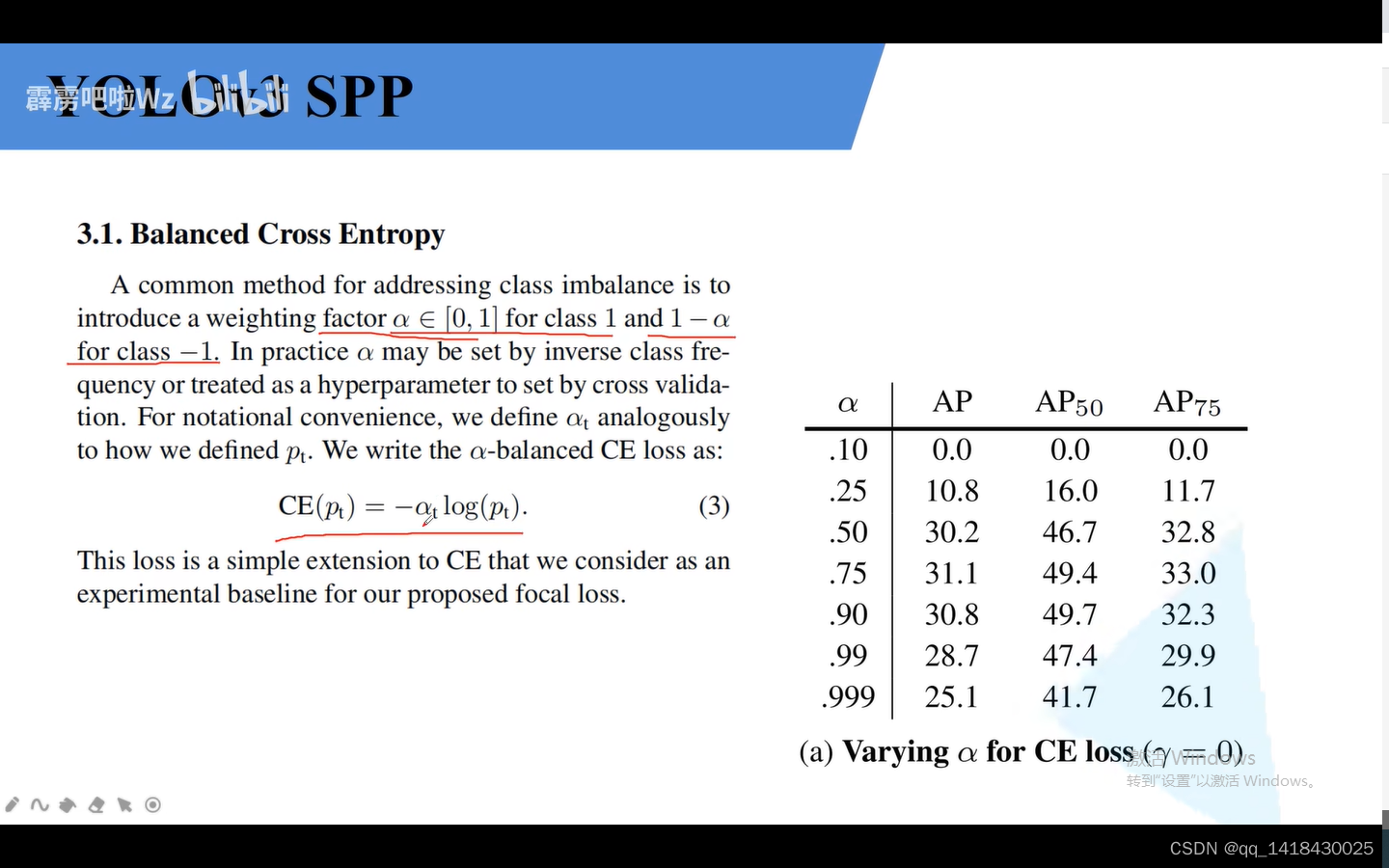
a引入解决正负样本匹配数目不平衡的情况。
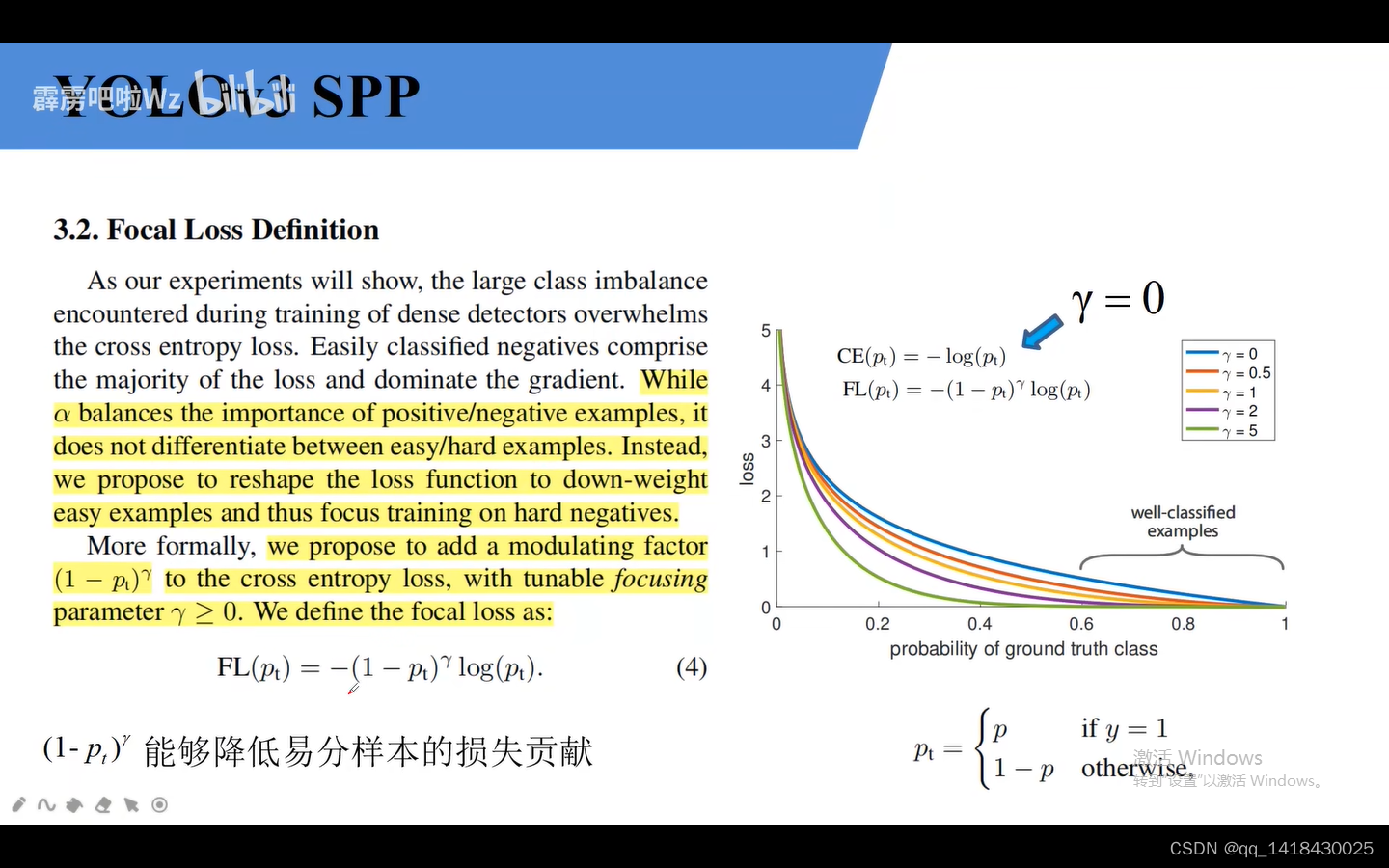
这个参数降低易分样本的损失贡献的情况。
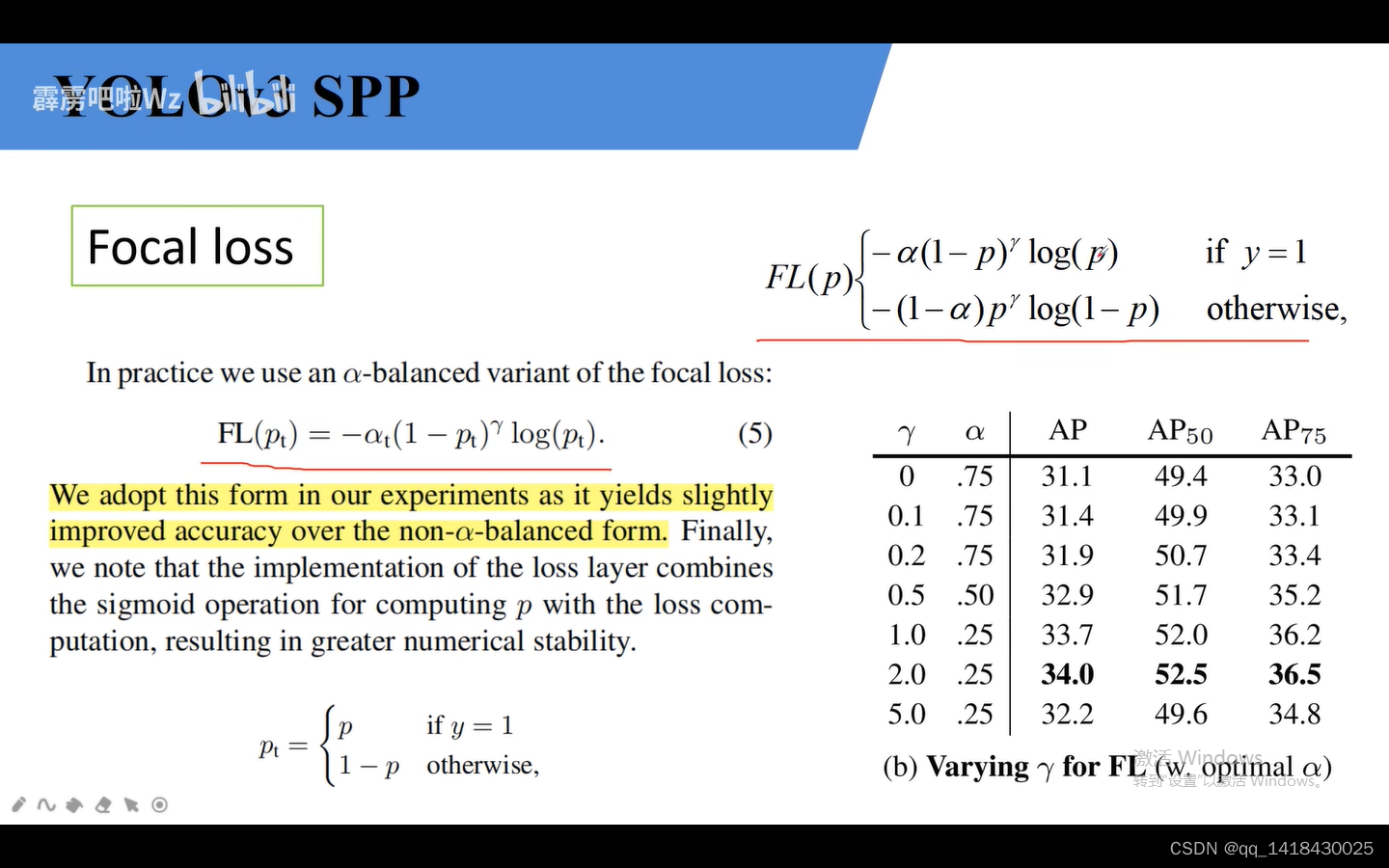
这个综合上面两个参数的情况。

















 7909
7909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











