






1. 论文简介
论文名:YOLOv3: An Incremental Improvement
论文地址 :YOLOv3
论文作者:Joseph Redmon, Ali Farhadi
论文时间:2018年
YOLOv3论文篇幅比较短,基本上可以说是4页,很多思想和YOLOv1以及YOLOv2是一样的,可以参考以下两篇博文哈哈~
2. 分类网络Darknet-53
作者设计了一个新的特征提取网络叫做Darknet-53,主要由一系列1x1和3x3的卷积层组成(conv2D层+BN层+LeakyReLU层)。因为一共有53个卷积层,所以称为Darknet-53。论文中给出了Darknet-53的具体结构,如下图所示。
其中,Size列没有写“/2”的表示stride为1,padding为same;而写了“/2”的表示stride为2,此时padding为valid,特征图大小会变为原来的一半(下采样通过卷积实现而不是pooling实现)。Convolutional表示Conv2D+BN+LeakyReLU,最后的connected其实就是一个conv2D。
另外注意:最后三层(Avgpool,Connected和Softmax层)只在ImageNet数据集上训练分类网络时才会使用,而作为YOLOv3的backbone时是不使用的。

作者提到,Darknet-53比Darknet-19精度高不只一点,和ResNet-101相比,精度略高但速度快1.5倍,和ResNet-152相比,精度略差但速度快2倍。具体如下表所示。

3. YOLOv3网络结构(检测网络)
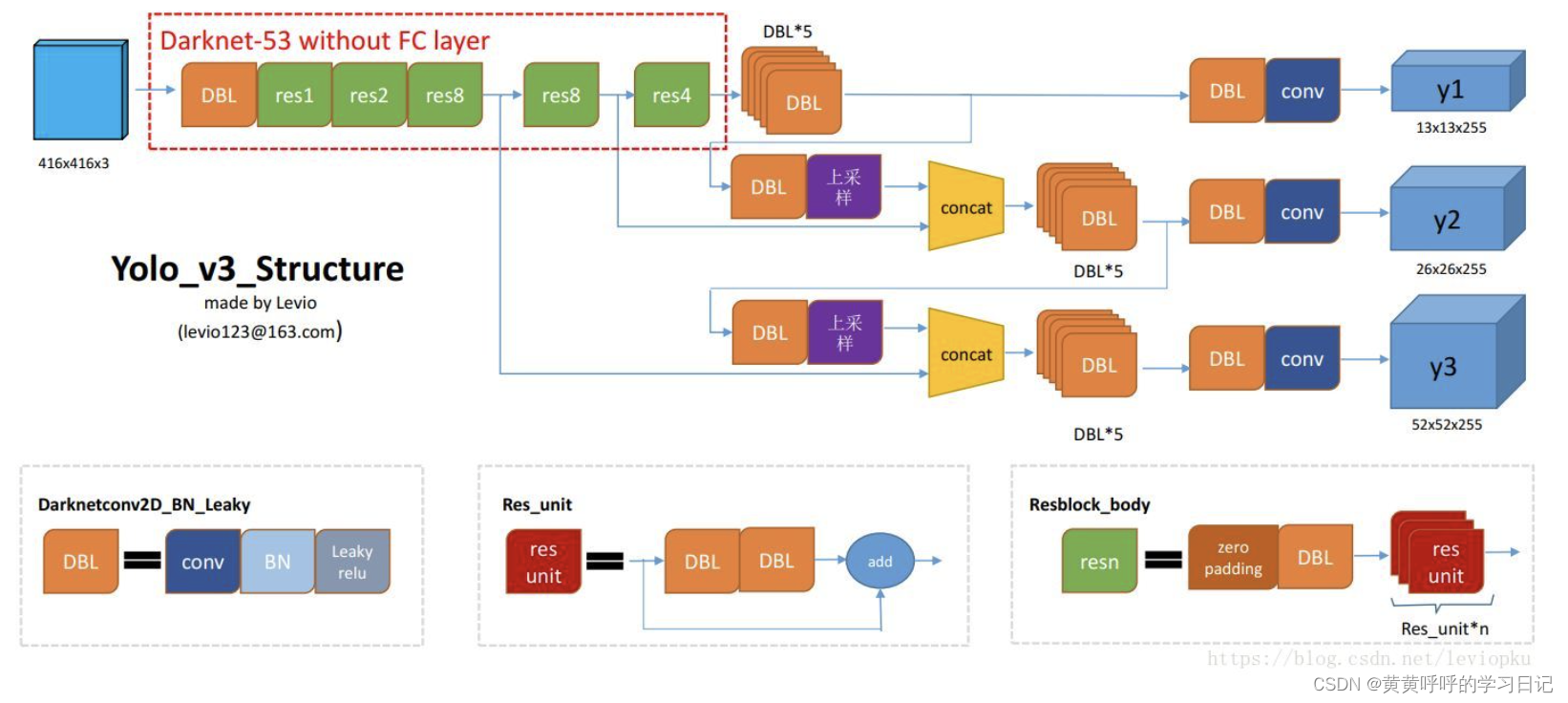
注:此图来自图片右下角所指链接博文。
3.1 网络结构说明
YOLOv3训练时同样采用了多尺度训练的策略,此图以416x416的输入为例。
左上角红色虚线框内为去掉最后三层(Avgpool,Connected和Softmax层)的Darknet-53网络,我们称之为backbone。
橘色DBL:Conv2D+BN+LeakyReLU,也就是Darknet-53中的1个Convolutional。不过这里没有区分卷积核大小是1x1还是3x3。
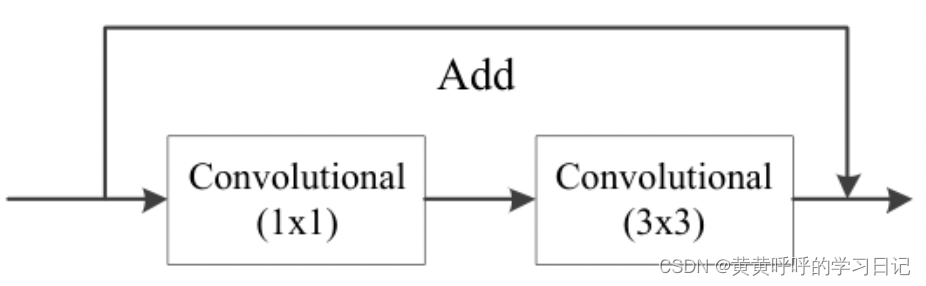
红色res unit:残差结构,包含1个卷积核大小为1x1的DBL+1个卷积核大小为3x3的DBL以及short-cut分支。也就是Darknet-53中Residual模块,如下面第一张图所示,第二张图为绘制出来的效果。

绿色resn:1个卷积核大小为1x1的DBL+n个res unit。例如,res4在Darknet-53中体现为下图所示。

backbone网络在经过res1之后的输出特征图大小为208x208,在经过res2之后的输出特征图大小为104x104,在经过第一个res8之后的输出特征图大小为52x52,在经过第二个res8之后的输出特征图大小为26x26,在经过res4之后的输出特征图大小为13x13(416x416的输入在经过32倍下采样之后得到13x13的输出)。
紫色:2倍上采样操作。上采样后可以和backbone中的特定层输出在维度方向上进行拼接。这种方式可以获取更多语义信息,使得细粒度的特征得以融合。
深蓝色conv:仅仅为一个卷积核大小为1x1的卷积层(无BN也无激活函数)。
3.2 预测特征层
YOLOv3中有三个预测特征层,大小分别是13x13,26x26,52x52,从网络结构图中我们也能看到它们分别是如何得到的。13x13的预测特征层用于检测大目标,26x26的预测特征层用于检测中等大小的目标,52x52的预测特征层用于检测小目标。
每个预测特征层的每个grid cell的输出为255个值,其中,255 = 3x(4+1+80),3表示每个grid cell有3个预设的bounding box prior(anchor box),4表示目标边界框的位置预测信息(相对于grid cell的坐标偏移量、宽和高缩放系数),1表示置信度,80表示类别数(COOC数据集)。所以3个预测特征层的最终输出为13x13x255,26x25x255和52x52x255。
YOLOv3中,作者同样采用K-means算法对COCO数据集进行聚类,选择了9个不同尺寸的bounding box prior(anchor box)。这9个box分布在3个预测特征层上,也就是每个预测特征层会预设3种尺寸的bounding box prior。
具体的,可以参考下图。

4. bounding box的预测
其实和YOLOv2一样,每个预测特征层最后通过255个1x1的卷积层进行预测(可以想象成1x1的卷积核在特征图上滑动,每个grid cell针对每个anchor box会预测255个值),而在YOLOv3中有3个预测特征层。
255 = 3 x ( 4 + 1 + 80 ),其中4表示目标边界框位置相关预测,1表示目标边界框的置信度预测,80表示类别。位置和置信度的预测值分别是,通过如下公式计算。

关于边界框位置的调整下图所示,具体可以参考YOLOv2。

5. 损失函数
YOLOv3的损失函数分为三个部分:目标定位损失、置信度损失和分类损失。
5.1 正负样本的匹配
论文中提到,针对每一个GT只会分配一个bounding box prior作为正样本,而只有当某个bounding box prior和GT有最大IOU时才被认为是正样本。IOU的值不是最大但又大于某个阈值(论文中threshold设为0.5)时,这些bounding box prior直接倍丢弃,剩余的则是负样本。负样本不参与定位损失和分类损失的计算,只计算置信度损失。
(实际发现,如果采用上面方式,正样本会非常少。现在一些版本的代码中,正样本匹配准则可能会和原论文不一样)
5.2 定位损失
目标定位损失采用的是sum of squared error loss,注意只有正样本才有目标定位损失。

其中,g代表GT box,可以由上面4个公式反向推导得到,也就是将4个公式中的b由GT的值替代。
5.3 置信度损失
置信度损失采用二值交叉墒损失。

其中,,表示预测的目标边界框i中是否存在目标,0意味着不存在,1意味着存在。
5.4 分类损失
分类损失采用二值交叉墒损失。很多时候在多分类任务中,输出层会使用softmax激活函数,而YOLOv3中,作者提到,在很多复杂数据集中,同一目标可同时归为多个类别,例如目标既是人这一类也是女人这一类,而softmax只会把目标归到一类中,所以多标签的方式有时候也能使模型具有更好的性能。

其中,,表示预测的目标边界框i中是否真的存在第j类目标,0意味着不存在,1意味着真实存在。
表示预测的目标边界框i中存在第j类目标的概率(sigmoid之后的值)。
6. 代码后续补充
看到大家比较推荐qqwweee的keras版本:github地址:https://github.com/qqwweee/keras-yolo3
另外也会有MindSpore版本的讲解。














 730
730











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









