







Python的数据类型
一、数据类型概念
数据类型是编程语言的基本组成元素,是最微观独立的个体,复杂功能的代码离不开数据基本的数据类型。
常用的数据类型
| 类型 | 描述 | 说明 |
|---|---|---|
| string | 字符串类型 | 用引号引起来的数据都是字符串 |
| int | 整型(有符号) | 数字类型,存放整数 如 -1,10, 0 等 |
| float | 浮点型(有符号) | 数字类型,存放小数 如 -3.14, 6.66 |
Python基本数据类型:Number(数字)、String(字符串)、Bool(布尔值)、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典)
使用type()语句查看数据的类型
type()是Python的一个内建的获取变量类型的函数,掌握使用type()语句查看数据的类型。
语法:type(被查看类型的数据)
二、基本数据类型按功能分类
按功能进行分类
- 标准数据类型:None、int、float、bool、str
- 容器数据类型:list、tuple、dict、set
2.1 标准数据类型
2.1.1 空值类型
None表示空值,它是一个特殊的Python对象,表示一个常量,None的类型是NoneType。
None和任意对象比较都是False,除了他自己本身。
使用时要注意以下几点:
- None是一个特殊的常量
- None和False不同
- None不是0
- None不是空字符串
- None和任何其他的数据类型比较永远返回False
- None不支持任何运算也没有任何内建方法
- None与0、空列表、空字符串不一样
- None有自己的数据类型NoneType
- None是没有像len,size等属性,要判断一个变量是否为None,直接使用:变量名==None或变量名!=None
- 可以将None赋值给任何变量,但是不能创建其他NoneType对象(它只有一个值None)
2.1.2 数字类型
int类型:表示整数
float类型:表示浮点数,即小数
complex类型:表示复数,复数的虚部默认是 字母 j 。复数由实部(real)和虚部(imag)构成,在 Python 中,复数的虚部以j或者J作为后缀,具体格式为:a + bj,a 表示实部,b 表示虚部。
#3.复数的使用
# 1、定义两个复数变量
num1 = 8 - 2j
num2 = 6 + 6j
print(num1,type(num1))
print(num2,type(num2))
print('-' * 100)
# 2、复数的四则运算
# 2.1 加法运算
print(num1 + num2)
print('-' * 100)
# 2.2 加减法运算
print(num1 - num2)
print('-' * 100)
# 2.3 乘减法运算
print(num1 * num2)
print('-' * 100)
# 2.3 除减法运算
print(num1 / num2)
print('-' * 100)
2.1.3 布尔类型
布尔(bool)表达现实生活中的逻辑,即真和假,True表示真,False表示假。
True本质上是一个数字记作1,False记作0
注意:
1.python 中布尔值使用常量True 和 False来表示
2.注意大小写是敏感的
3.< > == 等返回的类型就是bool类型,比较运算符等返回的值就是bool类型
4.布尔类型通常用来判断,在条件语句中使用
2.1.4 字符串类型
字符串是一种用来表示文本的数据类型,它是由符号或者数值组成的一个连续序列。
Python支持使用单引号、双引号和三引号定义字符串,其中单引号和双引号通常用于定义单行字符串,三引号通常用于定义多行字符串。
python 中还允许使用三单引号(""" 或者''')或三个双引号创建跨越多行的字符串,这种字符串中可以包含换行符、制表符及其他特殊字符。
2.1.4.1 字符串的三种定义方式
"""
字符串的三种定义方式:
1.单引号定义法
2.双引号定义法
3.三引号定义法
"""
# 单引号定义法,使用单引号进行包围
name = 'Python'
print(name)
# 双引号定义法
name2 = "Python"
print(name2)
# 三引号定义法,写法和多行注释是一样的,在"""直接换行就代表会有一个空行
name3 = """
学习
Python
"""
print(name3)
2.1.4.2 字符串特殊使用
遇到要显示带引号的字符串,比如“学习python"或'python',其中双引号和单引号也要显示出来,可以在遇到单引号时使用双引号,遇到双引号时使用单引号,或者使用转移字符\来解除引号的作用。
2.1.4.3 字符串的拼接
如果有两个字符串(文本)字面量,可以将其拼接成一个字符串,通过+号即可,但是,+号无法和非字符串类型进行拼接,因为类型不一致。
2.1.4.4 表达式进行字符串格式化——占位符
-
为什么要使用字符串格式化
在字符串拼接过程中,会发现如下问题
- 变量过多,拼接起来很麻烦
- 字符串无法和数字或其它类型完成拼接
-
字符串格式化语法
Python中支持非常多的数据类型占位
最常用的是如下三类:
1)字符串: %s:将内容转换成字符串,放入占位位置
2)整数:%d:将内容转换成整数,放入占位位置
3)浮点数: %f:将内容转换成浮点型,放入占位位置
字符串格式化的语法:"%占位符"%变量
常用占位符有3个:
-- 1)字符串: %s
-- 2)整数:%d
-- 3)浮点数: %f
代码实现:
# 传统的输出
name = 'Jerry'
age = 18
score = 91.3
result = True
print('我的姓名是' + name + ',我今年', age, '岁了,我的考试成绩是', score, '分,及格情况为', result, '。')
# 字符串占位符的使用:%s、%d、%f
print('我的姓名是%s,我今年%d,我的考试成绩是%f,及格情况为%s。' % (name, age, score, result))
输出结果:
我的姓名是Jerry,我今年 18 岁了,我的考试成绩是 91.3 分,及格情况为 True 。
我的姓名是Jerry,我今年18,我的考试成绩是91.300000,及格情况为True。
-
补充:数字精度控制格式化
使用辅助符号"m.n"来控制数据的宽度和精度
- m,控制宽度,要求是数字(很少使用),设置的宽度小于数字自身,不生效
- .n,控制小数点精度,要求是数字,会进行小数的四舍五入
理解:
%5d:表示将整数的宽度控制在5位,如数字11,被设置为5d,就会变成:[空格][空格][空格]11,用三个空格补足宽度。
%5.2f:表示将宽度控制为5,将小数点精度设置为2,小数点和小数部分也算入宽度计算。
如,对11.345设置了%7.2f 后,结果是:[空格][空格]11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .35
%.2f:表示不限制宽度,只设置小数点精度为2,如11.345设置%.2f后,结果是11.35
代码实现:
#1.整数的精度控制
num1 = 77
print('整数num1宽度被设置为5,输出结果为%5d' % num1)
输出结果:
整数num1宽度被设置为5,输出结果为 77
#2.小数的精度控制
num2 = 6.23812
print('小数num2宽度被设置为7,小数点后保留两位小数,输出结果为%7.2f' % num2)
输出结果:
小数num2宽度被设置为7,小数点后保留两位小数,输出结果为 6.24
num3 = 88.455
print('小数num3小数点后保留两位小数,输出结果为%.2f' % num3)
输出结果:
小数num3小数点后保留两位小数,输出结果为88.45
#发现问题:88.455保留两位小数进行输出的时候没有进行四舍五入操作,原因是88.455在进行十进制和二进制转换过程中出现精度丢失的情况
#原因:使用python的decima模块查看丢失后的数据,得知原因
import decimal
num3_new= decimal.Decimal(num3)
print(f'转换后实际的数据是{num3_new}')
输出结果:
转换后实际的数据是88.4549999999999982946974341757595539093017578125
2.1.4.6 表达式进行字符串格式化——f{}
name = 'Jerry'
age = 18
score = 91.455
result = True
# 使用f"内容{变量}"的格式来快速格式化输出
print(f'我的姓名是{name},我今年{age}岁了,我的考试成绩是{score}分,及格情况为{result}。')
输出结果:
我的姓名是Jerry,我今年18岁了,本次考试的成绩分数为91.455分,及格情况为 True 。
# 如何对小数点后面的数据进行位数控制呢?
# (1)遇到小数操作的时候使用小数的占位符
print(f'我的姓名是{name},我今年{age}岁了,我的考试成绩是%.1f分,及格情况为{result}。' % score)
# (2)使用f"内容{变量:.1f}"
print(f'我的姓名是{name},我今年{age}岁了,我的考试成绩是{score:.1f}分,及格情况为{result}。')
输出结果:
我的姓名是Jerry,我今年18岁了,本次考试的成绩分数为99.5分,及格情况为True。
我的姓名是Jerry,我今年18岁了,本次考试的成绩分数为99.5分,及格情况为True。
2.2 数据容器类型
数据容器,就是为了批量存储或批量使用多份数据。一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素,每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,可以大致分为5类:列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict),它们各有特点,但都满足可容纳多个元素的特性。
数据容器特点:
(1)是否支持重复元素
(2)是否可以修改
(3)是否有序等
2.2.1 列表(list)
列表的概念
列表可以一次存储多个数据,且在列表中可以存储不同的数据类型的数据,可以修改列表中的元素(增删改)同时也支持列表的嵌套。
列表的特点:
-
可以容纳多个数据 (上限为2**63-1、9223372036854775807个)
-
可以容纳不同类型的数据 (混装)
-
数据是有序存储的 (有下标序号)
-
允许重复数据存在
-
可以修改 、增加或删除元素等
-
支持while和for循环遍历获取列表中的元素
基本语法
列表内的每一个数据,称之为元素。以 []作为标识,列表内每一个元素之间用英文的逗号,隔开。
# 字面量
[元素1,元素2,元素3,元素4,...]
# 定义变量
变量名称 = [元素1,元素2,元素3,元素4,......]
# 定义空列表的两种方式
变量名称 = []
变量名称 = list()
列表中元素的类型有限制吗?
列表中存储的元素的数据类型没有任何限制,甚至列表也可以是列表中的元素,这样就可以定义嵌套列表。
代码实现
# 定义没有元素空列表
# 1)方式1:[]
list01 = []
print(list01, type(list01)) # [] <class 'list'>
# 2)方式2:使用list()
list02 = list()
print(list02, type(list02)) # [] <class 'list'>
# 定义带多个元素的列表
list03 = [100, 88.88, 'hello', True, None, False, 'hello', [1, 2, 3]]
print(list03) # [100, 88.88, 'hello', True, None, False, 'hello', [1, 2, 3]]
print(type(list03)) # <class 'list'>
# 1.3 使用list(可迭代类型的数据)函数定义带多个元素的列表,将可迭代数据进行逐个获取出来存储到列表中
list04 = list('abcd')
print(list04) #['a', 'b', 'c', 'd']
list05 = list(range(5))
print(list05) #[0, 1, 2, 3, 4]
list06 = list([1, 2, 3, 4, 5])
print(list06) #[1, 2, 3, 4, 5]
# 1.4 定义纯嵌套的列表元素
list07 = [[1, 2, 3, 4, 5], ['a', 'b', 'c', 'd'], [True, None, False]]
print(list07) # [[1, 2, 3, 4, 5], ['a', 'b', 'c', 'd'], [True, None, False]]
列表的下标索引
列表的下标索引有两种方式:
- 列表的下标(索引)- 正向,默认从0开始,依次递增(0、1、2、3……)
- 列表的下标(索引)- 反向,默认从-1开始,依次递减(-1、-2、-3…)
mylist01 = [100, 88.88, 'hello', True, None, False, 'hello', [1, 2, 3]]
print(mylist01)
print('-' * 100)
# 2.1 正向获取:默认从0下标开始
print(mylist01[0])
print(mylist01[1])
print(mylist01[2])
print(mylist01[3])
print(mylist01[4])
print(mylist01[5])
print(mylist01[6])
print(mylist01[7])
# print(mylist01[8]) # IndexError: list index out of range
# 2.2 反向获取:默认从-1开始
print(mylist01[-1])
print(mylist01[-2])
print(mylist01[-3])
print(mylist01[-4])
print(mylist01[-5])
print(mylist01[-6])
print(mylist01[-7])
print(mylist01[-8])
# print(mylist01[-9]) # IndexError: list index out of range
二维列表取出单独元素
语法:列表名称[下标][下标]
mylist02 = [[1, 2, 3, 4, 5], ['a', 'b', 'c', 'd'], [True, None, False]]
print(mylist02)
print(mylist02[0],type(mylist02[0])) # [1, 2, 3, 4, 5] <class 'list'>
print(mylist02[0][3]) # 4
print(mylist02[1],type(mylist02[1])) # ['a', 'b', 'c', 'd'] <class 'list'>
print(mylist02[1][1]) # b
print(mylist02[2],type(mylist02[2])) # [True, None, False] <class 'list'>
print(mylist02[2][0]) # True
列表的循环遍历
while循环遍历
# 定义一个列表
mylist01 = [100, 88.88, 'hello', True, None, False, 'hello', [1, 2, 3]]
print(mylist01)
# 定义一个记录下标位置的变量
index1 = 0
# 使用循环获取所有的下标
while index1 < len(mylist01):
print(index1, mylist01[index1])
# 控制循环结束的条件
index1 += 1
for循环遍历
for index2 in range(len(mylist01)):
print(index2, mylist01[index2])
# 使用简单的for循环完成
for x in mylist01:
print(x)
纯嵌套列表的遍历
# 基础变量
mylist02 = [[1, 2, 3, 4, 5], ['a', 'b', 'c', 'd'], [True, None, False]]
print(mylist02)
# for循环遍历获取大列表中的每一个小列表
for little_list in mylist02:
print(little_list)
# for循环遍历获取大列表中的每一个小列表,继续获取每一个小列表中的每一个元素
for little_list2 in mylist02:
if isinstance(little_list2, list):
for c in little_list2:
print(c)
else:
print(little_list2)
如何将大列表中嵌套列表的每一个元素一次性获取出来
# (1)使用for循环完成
for y in mylist01:
# print(y)
# 使用isinstance()函数判断是否一个列表
if isinstance(y, list):
for z in y:
print(z)
else:
print(y)
# (2)使用while循环完成,while循环要通过下标索引去拿
index_w = 0
while index_w < len(mylist01):
# 使用isinstance()函数判断是否一个列表
if isinstance(mylist01[index_w], list):
for b in mylist01[index_w]:
print(b)
else:
print(mylist01[index_w])
# 控制循环结束的条件
index_w += 1
列表的区间取值(切片取值)
在python中,只要有下标索引的类型数据都支持区间取值
-
mylist[start:end:step]:获取从列表下标start开始到end下标结束的元素,包含start,不包含end,step不写,默认步长为1 -
mylist[:end]:从列表下标为0的位置开始获取,一直获取到end下标位置结束,不包含end下标的元素 -
mylist[:end:step]:从列表下标为0的位置开始获取,按照一定的步长一直获取到end下标位置结束,不包含end下标的元素 -
mylist[start:]:从某个下标位置开始获取一直到最后 -
mylist[start::step]:从某个下标位置开始按照一定的步长获取一直到最后 -
mylist[:]:从头获取到尾部,跟直接输出列表名是一样的效果 -
mylist[::step]:从头获取到尾部,按照一定的步长 -
mylist[:-1]:从头获取到尾部,不包含最后一个元素 -
mylist[::-step]:倒序获取列表中的元素,默认步长为-1,也可以自定义步长 -
mylist[start:end:-step]:倒序获取列表中的元素,按照一定的步长 -
获取最后一个元素
代码实现
#索引(正): 0 1 2 3 4 5 6 7
mylist = [100, 88.88, 'hello', True, None, False, 'hello', 'Python']
#索引(反): -8 -7 -6 -5 -4 -3 -2 -1
print(mylist)
mylist[start:end:step]:获取从列表下标start开始到end下标结束的元素,包含start,不包含end,step不写,默认步长就是1
print(mylist[1:6]) # [88.88, 'hello', True, None, False]
print(mylist[1:6:2]) # [88.88, True, False]
mylist[:end]:从列表下标为0的位置开始获取,一直获取到end下标位置结束,不包含end下标的元素
print(mylist[:6]) # 默认步长为1
# [100, 88.88, 'hello', True, None, False]
mylist[:end:step]:从列表下标为0的位置开始获取,按照一定的步长一直获取到end下标位置结束,不包含end下标的元素
print(mylist[:7:3]) # 指定步长为2
#输出结果:[100, True, 'hello']
mylist[start:]:从某个下标位置开始获取一直到最后
print(mylist[1:]) # 默认步长为1
# [88.88, 'hello', True, None, False, 'hello', 'Python']
mylist[start::step]:从某个下标位置开始按照一定的步长获取一直到最后
print(mylist[1::4]) # 指定步长为1
# [88.88, False]
mylist[:]:从头获取到尾部,跟直接输出列表名是一样的效果
print(mylist[:]) #默认步长为1
# [100, 88.88, 'hello', True, None, False, 'hello', 'Python']
mylist[::step]:从头获取到尾部,按照一定的步长
print(mylist[::2])
# [100, 'hello', None, 'hello']
mylist[:-1]:从头获取到尾部,不包含最后一个元素
print(mylist[:-1]) # 默认步长为1
[100, 88.88, 'hello', True, None, False, 'hello']
mylist[::-step]:倒序获取列表中的元素,默认步长为-1,也可以自定义步长
print(mylist[:-1:2]) # 指定步长为2
# [100, 'hello', None, 'hello']
mylist[start:end:-step]:倒序获取列表中的元素,按照一定的步长
print(mylist[::-1]) # 指定步长为-1
['Python', 'hello', False, None, True, 'hello', 88.88, 100]
print(mylist[::-2]) # 指定步长为-2
# ['Python', False, True, 88.88]
- 获取最后一个元素
print(mylist[-1], type(mylist[-1])) # Python <class 'str'>
print(mylist[len(mylist) - 1:len(mylist)]) # mylist[7:8]——》['Python']
print(mylist[-1::]) # ['Python']
print(mylist[-1::1]) # ['Python']
列表常用的内置函数
查询的功能
-
len():查询列表的元素个数语法:
len(列表) -
count():统计列表内某元素的数量语法:
count(元素) -
index():查找指定元素在列表的下标,如果找不到,报错ValueError
语法:列表.index(元素)index就是列表对象(变量)内置的方法(函数)注意:
# 定义一个列表 mylist = [100, 'hello', 'spss', 'hello', True, 'hello', None, 'hello'] print(mylist) print(mylist.index('hello', 2, 6)) # 从指定位置开始找某一个元素第一次出现的位置返回的结果是:1
原因:index支持从某个位置开始查找,但位置是按照元组位置下标进行统计的
修改的功能
-
直接通过下标位置修改列表中的元素
语法:
列表[要修改的元素下标索引]=修改值
添加的功能
-
append():在列表尾部追加一个元素
语法:
列表.append(元素) -
insert():在指定位置添加一个元素,原来位置上的元素往后移语法:
列表.insert(元素) -
extend():在尾部追加一批元素,只能放可迭代类型的对象语法:
列表.extend(可迭代类型的数据)# 定义一个列表 mylist = [100, 'hello', 'spss', 'hello', True, 'hello', None, 'hello'] print(mylist.index('hello')) mylist.extend('bac') # 也可以放[1,2,3] print(mylist) # [100, 'mysql', 88.88, 'hello', True, None, 'hello', 'a', 'b', 'c']
删除的功能
-
del():删除指定下标的元素语法:
del 列表[下标索引]del 列表:将列表从python解析器中删除 -
pop():删除指定下标的元素,会将被删除的那个元素返回出来语法:
列表.pop(下标索引) -
remove():移除列表中第一次出现的那个元素,没有该元素则报错语法:
列表.remove(元素)# 定义一个列表 mylist = [100, 'hello', 'spss', True, 'hello', None] # 跳过第一次出现的元素删除后面那个相同的元素该如何实现 # 使用反转列表函数将列表元素反转:reverse() mylist.reverse() print(mylist) # [None, 'hello', True, 'spss', 'hello', 100] # 反转后在删除 mylist.remove('hello') print(mylist) # [None, True, 'spss', 'hello', 100] # 再将删除后的列表进行反转 mylist.reverse() print(mylist) # [100, 'hello', 'spss', True, None] -
clear():清空列表中的元素语法:
列表.clear()
2.2.2 元组(tuple)
元组的概念
元组同列表一样,都可以封装多个、不同类型的元素。但最大的不同点在于:元组一旦定义完成,就不可修改。
元组的特点
- 可以容纳多个数据
- 可以容纳不同类型的数据(混装)
- 数据是有序存储的(下标索引)
- 允许重复数据存在
- 不可以修改(增加或删除元素等,但可以修改内部list的内部元素)
- 支持while和for循环遍历获取列表中的元素
基本语法
定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
# 定义元组字面量
(元素,元素,......,元素)
# 定义元组变量
变量名称 = (元素,元素,......,元素)
# 省略括号定义元组
变量名称 = 元素,元素,......,元素
# 定义空元组
变量名称 = () # 方式1
变量名称 = tuple() # 方式2
# 元组也支持嵌套,定义一个嵌套元组
t1 = ( (1, 2, 3), (4, 5, 6) )
print(t1[0][0]) # 结果:1
print(t1[1][1]) # 结果:5
代码实现
# 1.定义空元素
# 方式1:()方式
tup01 = ()
# 方式2:使用tuple()
tup02 = tuple()
# 2. 定义带一个元素的元组:(元素,),逗号不能省略
tup03 = (100,)
# 3. 定义带多个数据的元组
# 1)用(元素1,元素2,元素3)定义
tup04 = (100, 88.88, 'hello', True, False, 'hello', None, [1, 2, 3], (4, 5, 6))
# 2)省略()定义:不建议使用
tup05 = 100, 88.88, 'hello', True, False, 'hello', None, [1, 2, 3], (4, 5, 6)
tup06 = 100,
# 3)使用tuple(可迭代类型数据)定义
tup07 = tuple('abcd') # ('a', 'b', 'c', 'd')
tup08 = tuple([1,2,3])
# 4. 定义纯嵌套的元素(二维元组)
tup09 = ((1,2,3),('a','b','c'),(True,False,None))
# ((1, 2, 3), ('a', 'b', 'c'), (True, False, None))
元组常用的内置函数
查询的功能
-
len():查看元组中元素的个数语法:
len(元组) -
count():查个某一个元素在元组中出现的次数,如果没有该元素则返回0语法:
count(元组) -
index():查找指定元素在元组的下标,如果找不到,报错ValueError,支持从指定位置查找
语法:列表.index(元素)index就是列表对象(变量)内置的方法(函数)
修改的功能
元组不支持修改:变向修改,如果元组中的元素是list列表,该列表中的元素是可以修改的
# 定义一个元组
mytup01 = (100, 88.88, 'hello', True, None, 'hello', [1, 2, 'hello'], (2, 3, 6, 8))
print(mytup01[6]) # [1, 2, 'hello']
mytup01[6][0] = 100
print(mytup01) # (100, 88.88, 'hello', True, None, 'hello', [100, 2, 'hello'], (2, 3, 6, 8))
删除的功能
del 列表:将元组从python解析器中删除
# 3、将元组从Python解析器中消失
del mytup01
# print(mytup01) # NameError: name 'mytup01' is not defined
2.2.3 字符串(str)
# 定义一个字符串
my_str01 = 'jerry'
print(my_str01)
字符串常用的内置函数
查询的功能
len(字符串):获取字符串中字符的个数,也是字符串的长度
print(len(my_str01))
字符串.count(字符串数据):查看字符串中某一个字符或字符串出现的个数,没有则返回0
print(my_str01.count('r')) # 2
print(my_str01.count('j')) # 1
print(my_str01.count('z')) # 0
print(my_str01.count('rr')) # 1
字符串.index(字符数据):查看字符串中某一个字符或字符串第一次出现的下标位置,没有则报错
print(my_str01.index('r')) # 2
print(my_str01.index('rr')) # 2
# print(name.index('z')) # ValueError: substring not found
字符串.find(字符数据):查看字符串中某一个字符或字符串第一次出现的下标位置,没有则返回-1
print(my_str01.find('r')) # 2
print(my_str01.find('rr')) # 2
print(my_str01.find('z')) # -1代表没有的意思
思考:如何获取相同字符出现在后面那个字符的下标
name2 = 'jesse'
print(name2.find('e')) # 1或者
跳过第一次出现的这个字符的位置进行指定区间查找
print(name2.find('e', 2)) # 4
print(name2.find('e', 2, 5)) # 4
print(name2.find('e', 2, 4)) # -1 包前不包后
startswith():验证是否以某个字符或字符串为开头,是返回True,不是就是返回False
print(my_str01.startswith('j')) # True
print(my_str01.startswith('je')) # True
print(my_str01.startswith('ja')) # False
print(my_str01.startswith('a')) # False
endswith():验证是否以某个字符或字符串为结尾,是返回True,不是就是返回False
print(my_str01.endswith('ry')) # True
print(my_str01.endswith('y')) # True
print(my_str01.endswith('rz')) # False
print(my_str01.endswith('z')) # False
isdigit():检查字符串中是否包含全数字的字符,是返回True,不是就是返回False
my_str02 = '12345'
my_str02_new = '12345abc'
print(my_str02.isdigit()) # True
print(my_str02_new.isdigit()) # False
isalpha():检查字符串中是否包含全字母的字符,是返回True,不是就是返回False
my_str03 = 'abcd'
my_str03_new = '12345abc'
print(my_str03.isalpha()) # True
print(my_str03_new.isalpha()) # False
isinstance():查看某一个数据是否为指定的类型,是返回True,不是就是返回False
print(isinstance('hello', str)) # True
print(isinstance('hello', int)) # False
print(isinstance(100, int)) # True
print(isinstance(100, float)) # False
print(isinstance(88.88, float)) # True
print(isinstance(True, bool)) # True
print(isinstance(False, bool)) # True
print(isinstance(True, int)) # True
print(isinstance(False, int)) # True
print(isinstance([100,88.88,'hello',True,None], list)) # True
修改的功能
注意:字符串本身是不支持修改的,一旦定义出字符串数据,这个数据就是一个常量值,被修改的字符串会生成一个新的字符串或其他类型的数据
#定义一个字符串
str01 = 'hello'
print(str01)
print('-' * 100)
'''
错误的语法:强制修改字符串串中的数据会直接报错:因为字符串本身是不支持修改
print(str01[0])
str01[1] = 'a' # TypeError: 'str' object does not support item assignment
print(str01)
'''
upper():将全小写的字符串转换成全大写,生成一个新的字符串
str01_new1 = str01.upper()
print(str01_new1) # HELLO
print(str01) # hello,原字符串没有改变
lower():将全大写的字符串转换成全小写,生成一个新的字符串
str01_new2 = str01_new1.lower()
print(str01_new2) # hello
print(str01) # hello,原字符串没有改变
replace():将字符串中旧的数据替换为新的数据,生成一个新的字符串
str02 = 'hello,java'
print(str02)
str02_new1 = str02.replace('java','python')
print(str02_new1) # hello,python
print(str02) # hello,java 原字符串没有改变
split():将字符串按照指定的字符进行分割,生成一个列表容器
str03 = '上海-北京-深圳-广州-南京-杭州-苏州'
print(str03)
str03_list01 = str03.split('-')
print(str03_list01) # ['上海', '北京', '深圳', '广州', '南京', '杭州', '苏州']
print(str03) # 上海-北京-深圳-广州-南京-杭州-苏州
# split('-',4)其中4代表分割次数为4
str03_list02 = str03.split('-',4)
print(str03_list02) # ['上海', '北京', '深圳', '广州', '南京-杭州-苏州']
join(可迭代类型的数据):拼接的一个方法,一个一个拿出来进行拼接,实质商操作的是字符串之间的join,如果容器里有非字符串的类型,会出现报错
print('hello' + 'world') # +实现字符串的拼接
print('-'.join('abcdefg')) #a-b-c-d-e-f-g
print('-'.join(['hello','wolrd'])) # hello-wolrd
# print('-'.join(['hello','wolrd',100,88.88,True])) # TypeError: sequence item 2: expected str instance, int found
-
剔除首尾指定的字符:生成一个新的字符串
-
strip():剔除首尾空格
str04 = ' hello world '
print(str04)
str04_new = str04.strip()
print(str04_new) # hello world
strip(xxx):剔除首尾指定的字符
str05 = '1122hello1122'
print(str05)
str05_new1 = str05.strip('1122')
print(str05_new1) # hello
str05_new2 = str05.strip('122')
print(str05_new2) # hello,找首尾里面出现的1、2,进行剔除
eval():将字符串转换为实际的代码操作,eval()中必须是字符串
print('3.14',type('3.14')) # 3.14 <class 'str'>
print(eval('3.14'),type(eval('3.14'))) # 3.14 <class 'float'>
print(eval('3.14+1')) # 4.140000000000001
print(eval('99+1')) # 100
# 针对字符串本身
print(eval('"abc"'),type(eval('"abc"'))) # abc <class 'str'>
删除的功能
字符串中的删除方法del:没有删除的功能,但是有一个方法可以将字符串直接从Python解析器中消失
my_str04 = 'James'
print(my_str04)
del my_str04 # 将字符串直接从Python解析器中消失
# print(my_str04)
# NameError: name 'my_str04' is not defined. Did you mean: 'my_str01'?
2.2.4 集合(set)
集合的概念
集合最主要的特点就是:不支持元素的重复(自带去重功能)、并且内容无序。
集合的特点
- 可以容纳多个数据
- 可以容纳不同类型的数据(混装)
- 数据是无序存储的(不支持下标索引)
- 不允许重复数据存在
- 可以修改(增加或删除元素等)
- 支持for循环
- 不可以使用while循环,因为不支持下标索引
结果中可见: 去重且无序,因为要对元素做去重处理,所以无法保证顺序和创建的时候一致。
注意点:set集合中包含的是不可变类型的数据,而列表是可变类型数据
基本语法
#定义集合字面量
{元素,元素,......,元素}
# 定义集合变量
变量名称 = {元素,元素,......,元素}
#定义空集合
变量名称 = set()
和列表、元组、字符串等定义基本相同:
- 列表使用:[]
- 元组使用:()
- 字符串使用:""
- 集合使用:{}
代码实现
# 定义集合
# (1) 定义空集合:set()
set01 = set()
print(set01, type(set01)) # set() <class 'set'>
# (2) 定义带多个元素的集合
# 注意点:在集合中存储的都是不可变类型的数据,在集合中不能存储列表
# 错误的演示:在集合中不能存储列表
# set02 = {100, 88.88, 'hello', True, None, [4, 5, 6]}
# print(set02) # TypeError: unhashable type: 'list'
# print(type(set02))
set02 = {100, 88.88, 'hello', True, None, False, 'hello', (1, 2, 3)}
print(set02) # {False, True, 100, 88.88, 'hello', (1, 2, 3), None}
print(type(set02)) # <class 'set'>
# (3) 使用set(可迭代类型对象)创建集合
set03 = set([1,2,3,3]) # 把列表中每一个元素单独取出来,放到set里
print(set03) # {1, 2, 3}
print(type(set03)) # <class 'set'>
集合的循环遍历
set(集合)只支持for循环遍历
# 定义一个集合
myset = {100, 88.88, 'hello', None, 'hello', True, False, (1, 2, 3)}
print(myset)
# 使用for循环遍历获取集合中的元素
# 方式1
for x in myset:
print(x)
# 方式2
for y in myset:
if isinstance(y,tuple):
for z in y:
print(z)
else:
print(y)
集合常用的内置函数
首先,因为集合是无序的,所以集合不支持:下标索引访问,但是集合和列表一样,是允许修改的
| 操作 | 说明 |
|---|---|
集合.add(元素) | 集合内添加一个元素 |
集合.remove(元素) | 移除集合内指定的元素 |
集合.pop() | 从集合中随机取出一个元素 |
集合.clear() | 将集合清空 |
集合1.difference(集合2) | 得到一个新集合,内含2个集合的差集,原有的2个集合内容不变 |
集合1.difference_update(集合2) | 在集合1中,删除集合2中存在的元素,返回的是None,且集合1被修改,集合2不变 |
集合1.union(集合2) | 得到1个新集合,内含2个集合的全部元素,原有的2个集合内容不变 |
len(集合) | 得到一个整数,记录了集合的元素数量 |
# 定义一个集合
myset = {100, 88.88, 'hello', None, 'hello', True, False, (1, 2, 3)}
# 1.len():查看集合中元素的个数
print(len(myset))
# 2.add():向集合中添加元素
myset.add('python')
print(myset)
# 3.删除集合中的元素
# 3.1 remove():移除指定的元素,如果没有该元组则报错
myset.remove('python')
print(myset)
# 3.2 pop()随机移除集合中的一个元素,会将被移除的这个元素返回
x = myset.pop()
print(x)
print(myset)
# 3.3 clear():清空集合中的额元素
myset.clear()
print(myset)
# 3.4 将集合从Python解析器中消失
del myset
# print(myset) # NameError: name 'myset' is not defined
# 4.取两个集合的差集
myset01 = {1, 2, 3, 4, 5, 6}
myset02 = {1, 2, 3, 8}
# 4.1 集合1.difference(集合2)得到一个新集合,内含2个集合的差集(取集合1中有的,集合2中没有的),原有的2个集合内容不变
myset_new1 = myset01.difference(myset02)
print(myset_new1) # {4, 5, 6}
print(myset01) # {1, 2, 3, 4, 5, 6}
print(myset02) # {8, 1, 2, 3}
# 4.2 集合1.difference_update(集合2)在集合1中,删除集合2中存在的元素,集合1被修改,集合2不变
myset_new2 = myset01.difference_update(myset02)
print(myset_new2) # None
print(myset01) # {4, 5, 6}
print(myset02) # {8, 1, 2, 3}
# 5、集合1.union(集合2)得到1个新集合,内含2个集合的全部元素原有的2个集合内容不变
set01 = {1, 2, 3, 4, 5, 9}
set02 = {1, 2, 3, 4, 5, 100, 7, 8}
myset_new3 = set01.union(set02)
print(myset_new3) # {1, 2, 3, 4, 5, 100, 7, 8, 9}
print(set01) # {1, 2, 3, 4, 5, 9}
print(set02) # {1, 2, 3, 4, 5, 100, 7, 8}
2.2.5 字典(dict)
字典的概念
可以使用字典,实现用key取出Value的操作
字典的特点
- 字典可以提供基于Key检索Value的场景实现
- 使用{}存储元素,每一个元素是一个键值对
- 每一个键值对包含Key和Value(用冒号分隔)
- 键值对之间使用逗号分隔
- 键值对的Key和Value可以是任意类型(Key不可为字典),可以有嵌套字典(例如:值是字典)
- 字典内Key不允许重复,重复添加等同于覆盖原有数据
- 可以修改(增加或删除更新元素等)
- 字典不可用下标索引,而是通过Key检索Value
- 支持for循环,不支持while循环
基本语法
# 定义字典字面量
{key:value, key:value,......, key:value}
# 定义字典变量
my_dict = {key:value, key:value,......, key:value}
# 定义空字典
my_dict = {} # 空字典定义方式1
my_dict = dict() # 空字典定义方式2
代码实现
# 1.定义带元素的字典:键不能为字典类型
dict03 = {'jesse': 18, 'jerry': 29, 'james': 22, 'jesse': 35, 'tom': {28: '中国'}}
print(dict03)
print(type(dict03))
## 2.通过dict(可迭代类型的数据)函数创建字典
## 如果使用普通列表进行定义,会出现报错
# list01 = ['jerry','Tom']
# dict04 = dict(list01)
# print(dict04)
## 报错:ValueError: dictionary update sequence element #0 has length 5; 2 is required
# 1)定义一个特殊的列表:嵌套的列表
list01 = [['jerry', 35], ['Tom', 42]]
# 2)将这个特殊的列表放在dict()函数中
dict04 = dict(list01)
print(dict04) # {'jerry': 35, 'Tom': 42}
# 3.定义嵌套的字典:字典中的值又是一个字典类型
dict05 = {
'Tom': {'语文': 90, '数学': 100, '英语': 88.5},
'Jerry': {'语文': 80, '数学': 90, '英语': 87.5},
'James': {'语文': 70, '数学': 80, '英语': 89.5},
'Jack': {'语文': 60, '数学': 50, '英语': 86.5},
}
print(dict05)
# 5、通过键来获取值
print(dict05['Tom']) # {'语文': 90, '数学': 100, '英语': 88.5}
print(dict05['Jerry']) # {'语文': 80, '数学': 90, '英语': 87.5}
print(dict05['James']) # {'语文': 70, '数学': 80, '英语': 89.5}
print(dict05['Jack']) # {'语文': 60, '数学': 50, '英语': 86.5}
字典的循环遍历
字典支持for循环,不支持while循环
for循环默认获取的是键,通过获取的键找到对应的值
# 定义一个字典
mydict01 = {'jesse': 18, 'james': 42, 'jerry': 20, 'tom': {'score': 90}}
# 1.默认获取的是键,然后通过键去找值
for key01 in mydict01:
print(key01, mydict01[key01])
# 2.使用keys()函数先获取所有的键,然后通过键去找值
for key02 in mydict01.keys():
print(key02, mydict01[key02])
# 3.直接获取键和值:items()
for x, y in mydict01.items():
print(x, y)
'''结果:
jesse 18
james 42
jerry 20
tom {'score': 90}
'''
# 4.只需要值:values()
for v in mydict01.values():
print(v)
'''结果:
18
42
20
{'score': 90}
'''
# 5.循环遍历嵌套
for x, y in mydict01.items():
if isinstance(y, dict):
print(x,end=' ')
for a, b in y.items():
print(a, b)
else:
print(x, y)
'''
jesse 18
james 42
jerry 20
tom score 90
'''
字典常用的内置函数
len(字典):查看字典中元素的个数字典.keys():获取字典中所有的键字典.values():获取字典中所有的值字典.items():同时获取键和值字典.pop(Key):获得指定Key的Value,同时字典被修改,指定Key的数据被删除字典.clear():清空字典中的元素del 字典:将字典从Python解析器中删除字典[Key] = Value:字典被修改,新增了元素,字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值字典[Key] = Value:字典被修改,元素被更新
# 定义一个字典
mydict01 = {'jesse': 18, 'james': 42, 'jerry': 20, 'tom': {'score': 90}, 'jesse': 35}
# len():查看字典中元素的个数
print(len(mydict01)) # 4,出现相同键时,会拿后面的值替换前面的
# keys():获取字典中所有的键
print(mydict01.keys())
# values():获取字典中所有的值
print(mydict01.values())
# items():同时获取键和值
print(mydict01.items())
# 修改字典中的元素
# (1) 向字典中添加元素
mydict01['rose'] = 18
print(mydict01)
# {'jesse': 35, 'james': 42, 'jerry': 20, 'tom': {'score': 90}, 'rose': 18}
# (2) 更新字典中的元素
mydict01['james'] = 40
print(mydict01)
# {'jesse': 35, 'james': 40, 'jerry': 20, 'tom': {'score': 90}, 'rose': 18}
# 删除字典
# (1) pop(xxx):通过键删除字典中的元素,会将被删除的那个值返回
v = mydict01.pop('rose')
print(v) # 18
print(mydict01)
# {'jesse': 35, 'james': 40, 'jerry': 20, 'tom': {'score': 90}}
# (2) clear():清空字典中的元素
mydict01.clear()
print(mydict01) # {}
# (3) 将字典从Python解析器中消失
del mydict01
# print(mydict01) # NameError: name 'mydict01' is not defined
-----------------------------Python基础09 48:00
三、数据容器对比总结
3.1 数据容器分类
数据容器可以从以下方面进行分类:
-
是否支持下标索引
1)支持:列表、元组、字符串 - 序列类型
2)不支持:集合、字典 - 非序列类型 -
是否支持重复元素:
1)支持:列表、元组、字符串 - 序列类型
2)不支持:集合、字典 - 非序列类型 -
是否可以修改
1)支持:列表、集合、字典
2)不支持:元组、字符串
3.2 数据容器特点对比
| 数据容器 | 列表 | 元组 | 字符串 | 集合 | 字典 |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | Key:Value Key:除字典外任意类型 Value:任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
3.3 数据容器的应用场景
基于各类数据容器的特点,它们的应用场景如下:
- 列表:可修改、可重复的存储场景
- 元组:不可修改、可重复的存储场景
- 字符串:一串字符串的存储场景
- 集合:去重存储场景
- 字典:可用Key检索Value的存储场景
四、数据容器的通用操作
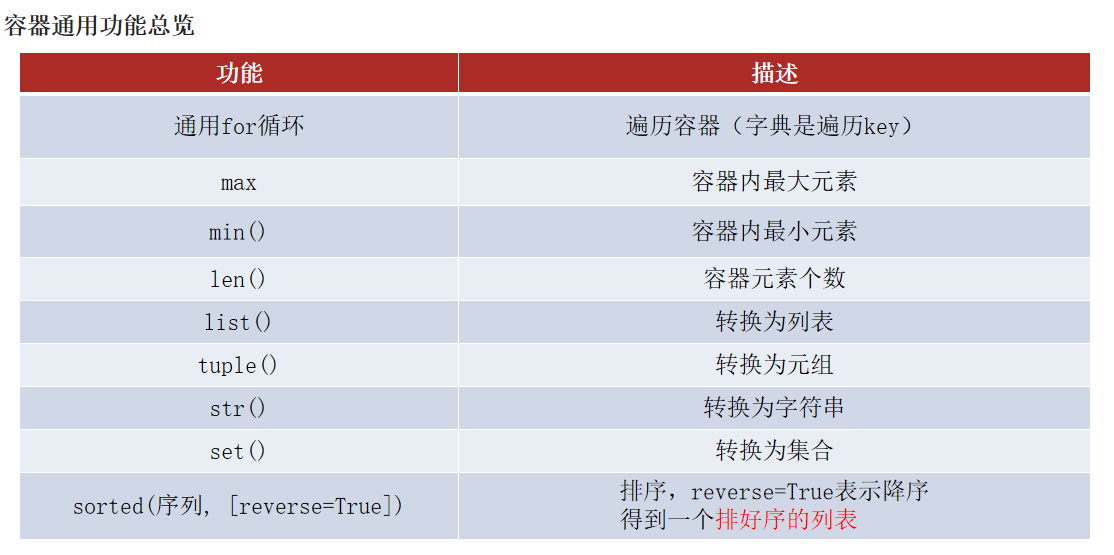
4.1 通用遍历
数据容器尽管各自有各自的特点,但是它们也有通用的一些操作。
首先,在遍历上:5类数据容器都支持for循环遍历,列表、元组、字符串支持while循环,集合、字典不支持(无法下标索引),尽管遍历的形式各有不同,但是,它们都支持遍历操作。
4.2 通用统计功能
除了遍历这个共性外,数据容器可以通用非常多的功能方法。
len(容器):统计容器的元素个数
统计最大最小元素时,在字典中是默认找key的最大最小值
max(容器):统计容器的最大元素
min(容器):统计容器的最小元素
4.3 通用转换功能
除了下标索引这个共性外,还可以通用类型转换
list(容器):将给定容器转换为列表
tuple(容器):将给定容器转换为元组
str(容器):将给定容器转换为字符串
set(容器):将给定容器转换为集合
代码实现过程:
"""
演示数据容器的通用功能
"""
my_list = [1, 2, 3, 4, 5]
my_tuple = (1, 2, 3, 4, 5)
my_str = "abcdefg"
my_set = {1, 2, 3, 4, 5}
my_dict = {"key1": 1, "key2": 2, "key3": 3, "key4": 4, "key5": 5}
# 类型转换: 容器转列表
print(f"列表转列表的结果是:{list(my_list)}")
print(f"元组转列表的结果是:{list(my_tuple)}")
print(f"字符串转列表结果是:{list(my_str)}")
print(f"集合转列表的结果是:{list(my_set)}")
print(f"字典转列表的结果是:{list(my_dict)}")
# 类型转换: 容器转元组
print(f"列表转元组的结果是:{tuple(my_list)}")
print(f"元组转元组的结果是:{tuple(my_tuple)}")
print(f"字符串转元组结果是:{tuple(my_str)}")
print(f"集合转元组的结果是:{tuple(my_set)}")
print(f"字典转元组的结果是:{tuple(my_dict)}")
# 类型转换: 容器转字符串
print(f"列表转字符串的结果是:{str(my_list)}")
print(f"元组转字符串的结果是:{str(my_tuple)}")
print(f"字符串转字符串结果是:{str(my_str)}")
print(f"集合转字符串的结果是:{str(my_set)}")
print(f"字典转字符串的结果是:{str(my_dict)}")
# 类型转换: 容器转集合
print(f"列表转集合的结果是:{set(my_list)}")
print(f"元组转集合的结果是:{set(my_tuple)}")
print(f"字符串转集合结果是:{set(my_str)}")
print(f"集合转集合的结果是:{set(my_set)}")
print(f"字典转集合的结果是:{set(my_dict)}")
执行结果:
列表转列表的结果是:[1, 2, 3, 4, 5]
元组转列表的结果是:[1, 2, 3, 4, 5]
字符串转列表结果是:['a', 'b', 'c', 'd', 'e', 'f', 'g']
集合转列表的结果是:[1, 2, 3, 4, 5]
字典转列表的结果是:['key1', 'key2', 'key3', 'key4', 'key5']
列表转元组的结果是:(1, 2, 3, 4, 5)
元组转元组的结果是:(1, 2, 3, 4, 5)
字符串转元组结果是:('a', 'b', 'c', 'd', 'e', 'f', 'g')
集合转元组的结果是:(1, 2, 3, 4, 5)
字典转元组的结果是:('key1', 'key2', 'key3', 'key4', 'key5')
列表转字符串的结果是:[1, 2, 3, 4, 5]
元组转字符串的结果是:(1, 2, 3, 4, 5)
字符串转字符串结果是:abcdefg
集合转字符串的结果是:{1, 2, 3, 4, 5}
字典转字符串的结果是:{'key1': 1, 'key2': 2, 'key3': 3, 'key4': 4, 'key5': 5}
列表转集合的结果是:{1, 2, 3, 4, 5}
元组转集合的结果是:{1, 2, 3, 4, 5}
字符串转集合结果是:{'g', 'c', 'e', 'f', 'a', 'b', 'd'}
集合转集合的结果是:{1, 2, 3, 4, 5}
字典转集合的结果是:{'key5', 'key4', 'key2', 'key3', 'key1'}
4.4 通用排序功能
通用排序功能
sorted(容器, [reverse=True])
将给定容器进行排序
注意,排序后都会得到列表(list)对象。
代码实现:
# 进行容器的排序
my_list = [3, 1, 2, 5, 4]
my_tuple = (3, 1, 2, 5, 4)
my_str = "bdcefga"
my_set = {3, 1, 2, 5, 4}
my_dict = {"key3": 1, "key1": 2, "key2": 3, "key5": 4, "key4": 5}
print(f"列表对象的排序结果:{sorted(my_list)}")
print(f"元组对象的排序结果:{sorted(my_tuple)}")
print(f"字符串对象的排序结果:{sorted(my_str)}")
print(f"集合对象的排序结果:{sorted(my_set)}")
print(f"字典对象的排序结果:{sorted(my_dict)}")
print(f"列表对象的反向排序结果:{sorted(my_list, reverse=True)}")
print(f"元组对象的反向排序结果:{sorted(my_tuple, reverse=True)}")
print(f"字符串对象反向的排序结果:{sorted(my_str, reverse=True)}")
print(f"集合对象的反向排序结果:{sorted(my_set, reverse=True)}")
print(f"字典对象的反向排序结果:{sorted(my_dict, reverse=True)}")
执行结果:
列表对象的排序结果:[1, 2, 3, 4, 5]
元组对象的排序结果:[1, 2, 3, 4, 5]
字符串对象的排序结果:['a', 'b', 'c', 'd', 'e', 'f', 'g']
集合对象的排序结果:[1, 2, 3, 4, 5]
字典对象的排序结果:['key1', 'key2', 'key3', 'key4', 'key5']
列表对象的反向排序结果:[5, 4, 3, 2, 1]
元组对象的反向排序结果:[5, 4, 3, 2, 1]
字符串对象反向的排序结果:['g', 'f', 'e', 'd', 'c', 'b', 'a']
集合对象的反向排序结果:[5, 4, 3, 2, 1]
字典对象的反向排序结果:['key5', 'key4', 'key3', 'key2', 'key1']
五、Python中推导式的使用
5.1 推导式概念
推导式(comprehensions),又称解析式,是Python中按照固定的条件表达式,自动生成数据的一种语法规则。推导式可以从一个数据序列构建另一个新的数据序列,常用于数据处理场景。
推导式是从一个或者多个迭代器快速创建序列的一种方法。它可以将循环和条件判断结合,从而避免冗长的代码。通过推导式,可以直接优化传统的通过循环结构和选择结构实现的列表操作,简化传统语法生成数据的规则或者过滤数据的规则。
目前,Python存在着三种推导式,分别为:列表推导式、字典推导式和集合推导式。其中,最常用的就是列表推导式。
推导式的特点
-
简化代码:推导式可以替换使用循环和条件语句的代码,使代码更加简洁、易读和易维护
-
提高效率:推导式的执行速度通常比使用循环和条件语句的方式更快,可以加快代码的执行效率
5.2 推导式的基本语法
5.2.1 列表推导式
[表达式 for item in 可迭代对象 ]
for循环里的临时变量,要赋值给一个表达式,这个表达式就是列表中的元素,和临时变量的名称要一致(自己赋值给自己)
# 定义一个列表
# (1) 直接使用[]创建
list01 =[1, 2, 3, 4, 5]
# (2) 使用list(range语句)创建
list02 = list(range(1, 6))
# (3) 通过for循环遍历获取range语句中序列,然后将数据追加到列表中
list03 = []
for x in range(1,6):
print(x)
list03.append(x)
# (4) 使用推导式创建
list04 = [x for x in range(1,6)]
#结果:
[1, 2, 3, 4, 5]
扩展练习:
# 1.使用推导式创建一个1-5之间平方值的列表
list05 = [x ** 2 for x in range(1, 6)] # [1, 4, 9, 16, 25]
# 2.使用推导式,1~10之间的奇数进行平方,存储到列表中
list06 = [x ** 2 for x in range(1, 11) if x % 2 != 0] # [1, 9, 25, 49, 81]
# 3.使用推导式完成,将1~10之间的奇数进行平方,偶数进行立方,然后存储到列表中
# 如果涉及到判断只有一个if的时候,直接放在推导式for循环后实现,如果出现的是if-else语句的话,需要放在推导式for循环之前
list07 = [x ** 2 if x % 2 != 0 else x ** 3 for x in range(1, 11)]
[[1, 8, 9, 64, 25, 216, 49, 512, 81, 1000]]
# 4.使用推导式完成,特征两值获取,将1~10之间的数字,将比5大的值标记为1,比5小的值标记为0(包含5)
list08 = [1 if x > 5 else 0 for x in range(1, 11)]
# 5.使用推导式完成,随机生成10个成绩(分数区间在0~100之间),判断是否及格
# (1) 生成10个随机的分数
list08 = [random.randint(0, 100) for x in range(1, 11)]
# (2) 使用判断表示成绩的及格情况
result01 = ['及格' if score >= 60 else '不及格' for score in list08]
print(result01)
# 或
result02 = [f'{score}-及格' if score >= 60 else f'{score}-不及格' for score in list08]
print(result02)
['35-不及格', '97-及格', '31-不及格', '83-及格', '97-及格', '68-及格', '45-不及格', '96-及格', '79-及格', '67-及格']
# 6.如何获取列表中相同的元素
mylist = [1, 2, 3, 2, 3, 2, 4, 5]
myset = set()
# 第一种方式:传统方式实现:将列表中相同元素个数大于1的先获取到,然后存放在集合中去重
for x in mylist:
if mylist.count(x) > 1:
myset.add(x)
print(list(myset))
# 第二种方式:使用推导式完成
mylist_new = [x for x in set(mylist) if mylist.count(x) > 1]
print(mylist_new)
5.2.2 集合推导式
语法:{表达式 for item in 可迭代对象 }
# 1.生成1~10之间的偶数,然后存储到集合中
myset01 = {x for x in range(1, 11) if x % 2 == 0}
# 2.将列表转换为一个集合
mylist = ['jesse','james','jesse','jerry','jack']
# 方式1:set()
myset02 = set(mylist) # {'jesse', 'james', 'jack', 'jerry'}
print(myset02)
# 方式2:使用集合推导式
myset03 = {x for x in mylist}
print(myset03) # {'jesse', 'james', 'jack', 'jerry'}
print(type(myset03))
5.2.3 字典推导式
语法:{ key_expression : value_expression for 表达式 in 可迭代对象}
# 1.将列表转换为字典
name_list = ['jesse', 'james', 'jerry', 'jesse']
age_list = [18, 40, 20, 35]
# 方式1:
mydict01 = {}
for index in range(len(name_list)):
# print(index)
mydict01[name_list[index]] = age_list[index]
print(mydict01)
# 方式2:使用字典推导式完成
mydict02 = {name_list[index]:age_list[index] for index in range(len(name_list))}
print(mydict02)
# {'jesse': 35, 'james': 40, 'jerry': 20}
5.2.4 元组推导式
# 1.将1~100之间5的倍数的数据通过推导式存储到元组中
# (1) 使用列表推导式完成
mylist = [x for x in range(1,101) if x % 5 == 0]
print(mylist)
# (2) 使用元组推导式完成
mytuple = (x for x in range(1,101) if x % 5 == 0)
print(mytuple)
# 内存地址:<generator object <genexpr> at 0x000001B6E5C665E0>,只适合临时使用一次,如果再次使用,数据容器为空
# 需要使用tuple()函数进行转换
mytuple2 = tuple(mytuple)
print(mytuple2)
# (5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100)
print(type(mytuple2)) # <class 'tuple'>















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









