






文章目录
摘要
本周主要学习了VGG这一经典的卷积神经网络,通过阅读相关论文和研究工作,我对VGG的结构和创新有了更深刻的理解。VGG由一系列卷积层组成,使用小尺寸的3x3卷积滤波器,接着是最大池化层。这种简单而统一的架构使得它易于理解和实现。与之前的AlexNet等架构相比,VGG网络相对较深。通过堆叠多个卷积层,实现了更抽象和层次化的特征表示。VGG网络中的卷积层都使用相同大小的滤波器,这提高了网络的一致性。VGG网络在设计上注重网络的深度和宽度。通过专注于扩大通道数的卷积核和缩小高和宽的池化操作,VGG在保持模型表达能力的同时,有效地降低了计算复杂度的增速。这种平衡使得VGG可以构建更深更宽的网络结构,从而更好地适应复杂的视觉任务。VGG模型的名称按照其深度进行了编号,例如VGG16和VGG19,分别包含16和19层的权重。这种简单的编号方式使得它们更容易被识别和引用。最后进行了代码实践。
Abstract
This week, I primarily studied the classic convolutional neural network, VGG. Through reading related papers and research, I gained a deeper understanding of the structure and innovations of VGG. VGG is composed of a series of convolutional layers, using small 3x3 convolution filters, followed by max-pooling layers. This simple and uniform architecture makes it easy to comprehend and implement. In comparison to previous architectures like AlexNet, VGG is relatively deeper. By stacking multiple convolutional layers, it achieves more abstract and hierarchical feature representations.The convolutional layers in the VGG network use filters of the same size, enhancing the network’s uniformity. In its design, VGG emphasizes both the depth and width of the network. By focusing on expanding the number of channels in convolutional kernels and reducing height and width through pooling operations, VGG maintains model expressiveness while effectively slowing down the increase in computational complexity. This balance allows VGG to construct deeper and wider network structures, making it better suited for complex visual tasks.VGG models are named based on their depth, such as VGG16 and VGG19, which contain 16 and 19 layers of weights, respectively. This straightforward naming convention makes them easily recognizable and referenced. Finally, practical coding exercises were conducted.
1、研究背景和目的
20世纪80年代和90年代,神经网络曾经兴盛一时,但后来由于计算能力不足和训练技术的限制而逐渐式微。然而,在2000年后,随着计算能力的显著提高和更好的训练方法的出现,深度学习再次成为研究的焦点。在计算机视觉领域,图像分类一直是一个重要的问题。传统的计算机视觉方法通常需要手工设计特征,这在处理复杂数据集时存在限制。VGG是2014年Oxford的Visual Geometry Group提出的,其在在2014年的 ImageNet 大规模视觉识别挑(ILSVRC -2014中获得了亚军,第一名是GoogleNet。该网络是作者参加ILSVRC 2014比赛上的作者所做的相关工作,相比AlexNet,VGG使用了更深的网络结构,证明了增加网络深度能够在一定程度上影响网络性能。作者以比赛为目的——解决ImageNet中的1000类图像分类和 localization。作者对六个网络的实验结果在深度对模型影响方面,进行了感性分析(越深越好),实验结果是16和19层的VGGNet(VGG代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的[Robotics Research Group,该Group研究范围包括了机器学习到移动机器人分类和localization的效果好(作者斩获2014年分类第二,localization第一,分类第一是当年的GoogLeNet.)
2.研究内容
2.1 VGG网络结构简介
网络结构如下:
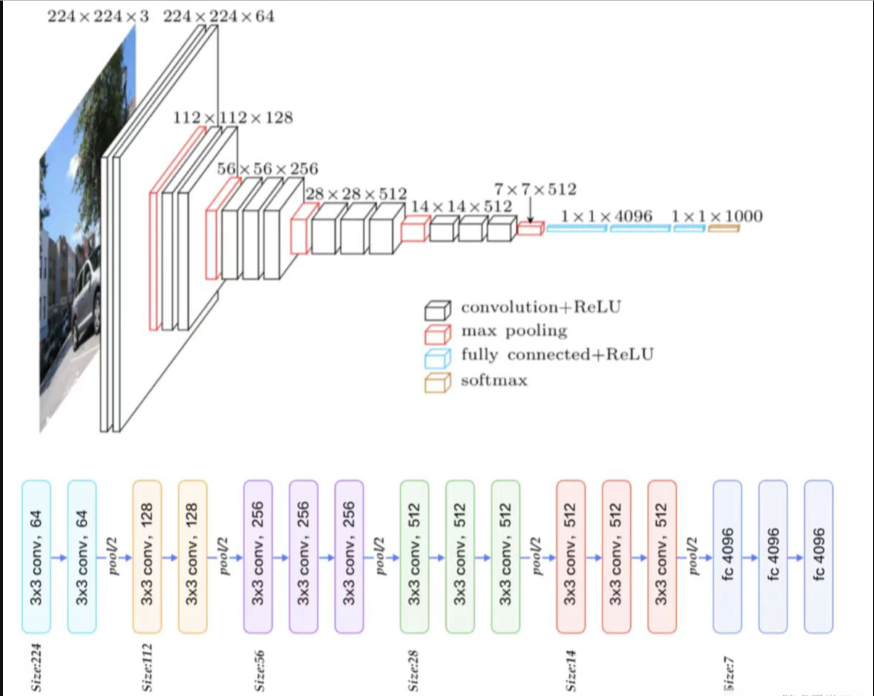
上图上半部分是常见的VGG网络结构,可以看见输入图片是224*224的RGB图像,经过卷积、池化与全连接操作后输出1000个分类结果;下半部分是五段卷积组,每一段卷积组后接一个最大池化层,最后由3层全连接层输出分类结果。
整个模型结构可分为两大部分:提取特征网络结构与分类网络结构
卷积层默认kernel_size=3,padding=1;池化层默认size=2,strider=2。下面进行结构分析:
输入图像尺寸为2242243
经过2层的6433卷积核,即卷积两次,再经过ReLU激活,输出尺寸大小为22422464
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为11211264
经过2层的12833卷积核,即卷积两次,再经过ReLU激活,输出尺寸大小为112112128
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为5656128
经过3层的25633卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为5656256
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为2828256
经过3层的51233卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为2828512
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为1414512
经过3层的51233卷积核,即卷积三次,再经过ReLU激活,输出尺寸大小为1414512
经最大池化层(maxpooling),图像尺寸减半,输出尺寸大小为77512
然后将feature map展平,输出一维尺寸为77512=25088
经过2层的114096全连接层,经过ReLU激活,输出尺寸为114096
经过1层的111000全连接层(1000由最终分类数量决定,当年比赛需要分1000类)输出尺寸为111000,最后通过softmax输出1000个预测结果
3.2 权重参数(不考虑偏置)
输入层为2142243,没有参数为0,存储容量为2242243=150k
第一层卷积,输入层有3个channels,卷积核数量为64,所以参数为64333=1728,存储容量为224224*64=3.2m
第二层卷积,输入有64个channels,卷积核数量为64,所以参数为643364=36864,存储容量为224224*64=3.2m
第一层池化,输入为64个channels,高宽减半,所以参数为0,存储容量为11211264=800k
第三层卷积,输入有64个channels,卷积核数量为128,所以参数为6433128=73728,存储容量为112112*128=1.6m
第四层卷积,输入有128个channels,卷积核数量为128,所以参数为12833128=147456,存储容量为112112*128=1.6m
第二层池化,输入为128个channels,高宽减半,所以参数为0,存储容量为5656128=400k
第五层卷积,输入有128个channels,卷积核数量为256,所以参数为25633128=294912,存储容量为112112*128=800k
第六层卷积,输入有256个channels,卷积核数量为256,所以参数为25633256=589824,存储容量为112112*128=800k
全连接层权重参数为:前一层节点数×本层的节点数
FC1(1×1×4096)参数:7×7×512×4096=102760448,存储容量为4096
FC2(1×1×4096)参数:4096×4096=16777216,存储容量为4096
FC3(1×1×1000)参数:4096×1000=4096000,存储容量为1000

VGG16具有如此之大的参数数目(主要集中在全连接层),可以预期它具有很高的拟合能力;但同时缺点也很明显:即训练时间过长,调参难度大;需要的存储容量大,不利于部署。
2.2 VGG网络结构特点
2.2.1 小卷积核
卷积与网络深度息息相关,虽然AlexNet使用了11x11和5x5的大卷积,但大多数还是3x3卷积,对于stride=4的11x11的大卷积核,理由在于一开始原图的尺寸很大因而冗余,最为原始的纹理细节的特征变化可以用大卷积核尽早捕捉到,后面更深的层数害怕会丢失掉较大局部范围内的特征相关性,后面转而使用更多3x3的小卷积核和一个5x5卷积去捕捉细节变化。
而VGGNet则全部使用3x3卷积。因为卷积不仅涉及到计算量,还影响到感受野。前者关系到是否方便部署到移动端、是否能满足实时处理、是否易于训练等,后者关系到参数更新、特征图的大小、特征是否提取的足够多、模型的复杂度和参数量等。
计算量
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层的非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升网络的深度,在一定程度上提升神经网络的效果。
比如,3个3x3连续卷积相当于1个7x7卷积:3个3*3卷积的参数总量为 3x(3 * 3 * C 2 C^2 C2) =27 C 2 C^2 C2,1个7x7卷积核参数总量为 1 * 7 * 7 * C 2 C^2 C2 =49 C 2 C^2 C2,这里 C 指的是输入和输出的通道数。很明显,27 C 2 C^2 C2<49 C 2 C^2 C2,即最终减少了参数,而且3x3卷积核有利于更好地保持图像性质,多个小卷积核的堆叠也带来了精度的提升。
感受野
简单理解就是输出feature map上的一个对应输入层上的区域大小。
计算公式:(从深层推向浅层)
F(i)为第i层感受野
strider为第i步的步距
ksize为卷积核或池化核尺寸
例如:
feature map:F=1
conv3*3(3):F=(1-1)*1+3=3
conv3*3(2):F=(3-1)*1+3=5
conv3*3(1):F=(5-1)*1+3=7
见下图,输入的8个元素可以视为feature map的宽或者高,当输入为8个神经元经过三层conv3x3的卷积得到2个神经元。三个网络分别对应stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷积核在3层、1层、1层时的结果。因为这三个网络的输入都是8,也可看出2个3x3的卷积堆叠获得的感受野大小,相当1层5x5的卷积;而3层的3x3卷积堆叠获取到的感受野相当于一个7x7的卷积。
input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果。
或者我们也可以说,三层的conv3x3的网络,最后两个输出中的一个神经元,可以看到的感受野相当于上一层是3,上上一层是5,上上上一层(也就是输入)是7。
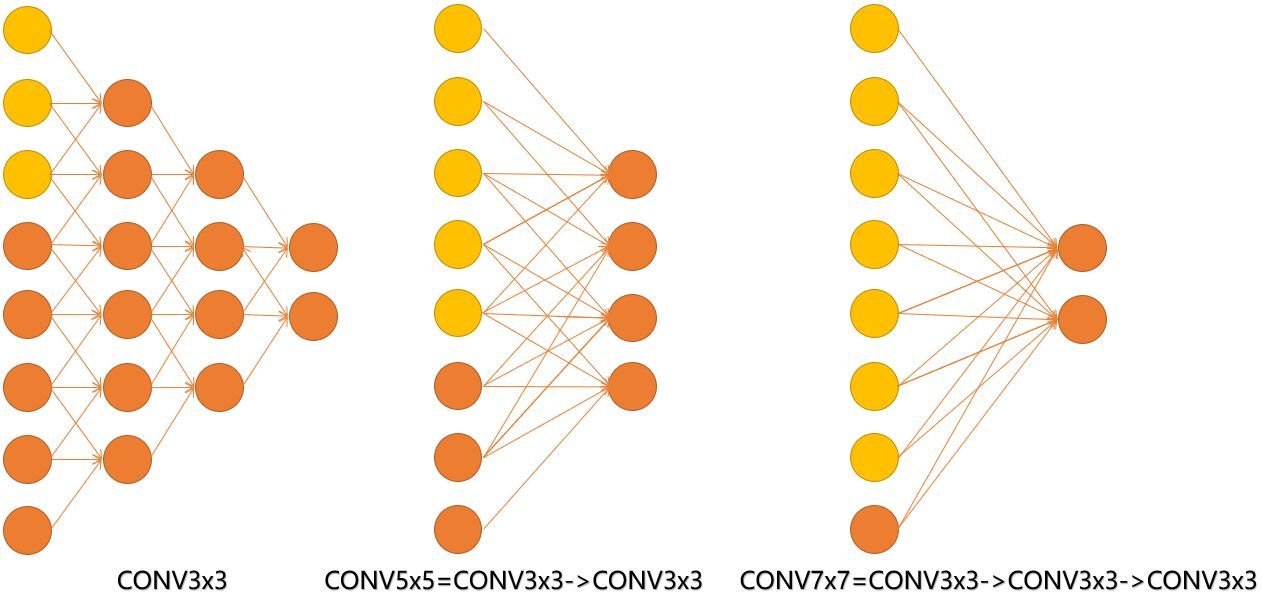
此外,倒着看网络,也就是backprop的过程,每个神经元相对于前一层甚至输入层的感受野大小也就意味着参数更新会影响到的神经元数目。在分割问题中卷积核的大小对结果有一定的影响,在上图三层的conv3x3中,最后一个神经元的计算是基于第一层输入的7个神经元,换句话说,反向传播时,该层会影响到第一层conv3x3的前7个参数。从输出层往回forward同样的层数下,大卷积影响(做参数更新时)到的前面的输入神经元越多。
堆叠小卷积核相比使用大卷积核具有更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,可使决策函数更加具有辨别能力;此外,3x3比7x7就足以捕获细节特征的变化:3x3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化;3个3x3堆叠近似一个7x7,网络深了两层且多出了两个非线性ReLU函数,网络容量更大,对于不同类别的区分能力更强。
2.2.2 小池化核
2012年的AlexNet的pooling的kernel size全是奇数,所有池化采用kernel size=3x3,stride=2的max-pooling,而VGG使用的max-pooling的kernel size=2x2,stride=2。pooling kernel size从奇数变为偶数。小kernel带来的是更细节的信息捕获。
池化做的事情是根据对应的max或者average方式进行特征筛选,max-pooling更容易捕捉图像上的变化,梯度的变化,带来更大的局部信息差异性,更好地描述边缘、纹理等构成语义的细节信息。
2.2.3 全连接层
VGG最后三个全连接层在形式上完全平移了AlexNet的最后三层,VGGNet后面三层(三个全连接层)为:
FC4096-ReLU6-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
FC4096-ReLU7-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
FC1000-SoftMax1000分类,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
超参数上只有最后一层fc有变化:bias的初始值,由AlexNet的0变为0.1,该层初始化高斯分布的标准差,由AlexNet的0.01变为0.005。
3、VGG网络结构的主要贡献
3.1 小卷积核组
VGG网络的一个重要贡献是通过采用小尺寸的卷积核来替代大的卷积核。具体而言,作者大量使用33的卷积核(极少数情况下使用11的卷积核),这样的设计有助于减少模型参数的数量。通过多个小卷积核的组合,网络能够学习更复杂的特征表示。
3.2 小池化核
与AlexNet使用的33的池化核不同,VGG网络中的池化操作全部采用22的卷积核。这样的小池化核有助于在减小空间尺寸的同时保留更多的空间信息,从而更好地捕捉图像的局部特征。
3.3 网络更深特征图更宽
VGG网络在设计上注重网络的深度和宽度。通过专注于扩大通道数的卷积核和缩小高和宽的池化操作,VGG在保持模型表达能力的同时,有效地降低了计算复杂度的增速。这种平衡使得VGG可以构建更深更宽的网络结构,从而更好地适应复杂的视觉任务。
3.4 卷积核替代全连接
VGG网络在测试阶段采用了将全连接层替换为卷积层的策略。通过将三个全连接层替换为三个卷积层,VGG模型能够接收任意高度或宽度的输入图像,增加了网络的灵活性,同时减少了参数数量,降低了过拟合的风险。
3.5 多尺度
为了提升性能,VGG网络采用了多尺度训练的方法。在训练和测试阶段,模型使用整张图片的不同尺度,这有助于提高模型对不同尺度输入的适应性,增强了模型的泛化能力。
3.6 去掉了LRN层
为了简化模型结构,VGG移除了深度网络中的LRN层,即局部响应归一化层。作者的实验发现,在深度较大的情况下,LRN层的作用变得不太显著,因此可以去除以降低计算成本,同时保持网络性能。这一决策也使得VGG更加易于训练和理解。
4.代码实现:
import time
import torch
from torch import nn, optim
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class FlattenLayer(torch.nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)
# 使用vgg_block函数来实现这个基础的VGG块
def vgg_block(num_convs, in_channels, out_channels):
blk = []
for i in range(num_convs):
if i == 0:
blk.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
else:
blk.append(nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1))
blk.append(nn.ReLU())
blk.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*blk)
# 卷积层模块串联数个vgg_block,其超参数由变量conv_arch定义
# 第一块的输入输出通道分别是1(因为下面要使用的Fashion-MNIST数据的通道数为1)和64
conv_arch = ((1, 1, 64), (1, 64, 128), (2, 128, 256), (2, 256, 512), (2, 512, 512))
# 经过5个vgg_block, 宽高会减半5次, 变成 224/32 = 7
fc_features = 512 * 7 * 7
fc_hidden_units = 4096
# VGG
def vgg(conv_arch, fc_features, fc_hidden_units=4096):
net = nn.Sequential()
# 卷积层部分
for i, (num_convs, in_channels, out_channels) in enumerate(conv_arch):
net.add_module('vgg_block_' + str(i+1), vgg_block(num_convs, in_channels, out_channels))
# 全连接层部分
net.add_module('fc', nn.Sequential(
FlattenLayer(),
nn.Linear(fc_features, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, fc_hidden_units),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(fc_hidden_units, 10)
))
return net
5.总结
在本周学习中,我学习了VGG这一经典的卷积神经网络,VGG是基于AlexNet改进的,VGG模型很好的适用于分类和定位任务。VGG网络的核心思想是使用多个连续的3x3卷积核和最大池化层来构建网络层。它通过堆叠多个卷积层和池化层来增加网络的深度,以提取输入图像的特征。VGG网络的深度可以根据需求进行调整,其中VGG16和VGG19是最常用的两个变种,分别有16和19个卷积层。最后进行代码实践,对VGG这一经典的卷积神经网络有了更深的理解。















 749
749











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









