







一、论文梳理
1、论文研究背景
此文对卷积核的改进源于其他学者对CNN的大量尝试,其中包括:1)小卷积核:在第一个卷积层用了更小的卷积核与步长(反卷积那篇);2)多尺度:训练和测试使用整张图的不同尺度。VGGNet不仅将上面的两种方法应用到自己的网络设计和训练测试阶段,同时还考虑了深度对网络性能的影响。
2、论文研究成果
1)模型研究成果:
在ILSVRC比赛中获得了分类项目的第二名和定位项目的第一名。其结构简单,提取特征能力强,因此应用场景广泛,应用于风格迁移、目标检测、GAN等。
2)对比实验成果:
此文对六组模型进行对比实验,以研究深度对网络的影响。具体的对比模型如下:

(1)对比单尺度预测实验:
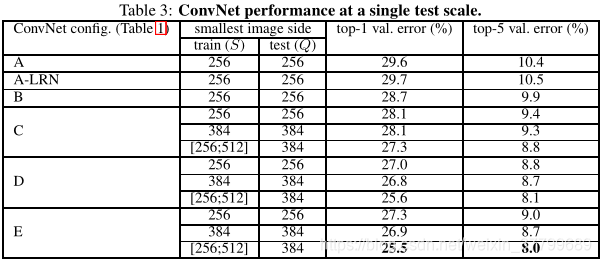
实验结论:第一点:LRN对网络性能提升没有帮助(此后卷积神经网络中很少有人加入LRN);第二点:对于同一网络结构多尺度训练可以提高网络精;第三点:VGG19效果最好,一定程度的加深网络可以提高精度。
关于多尺度操作:多尺度操作并非是改变输入数据的尺度(全连接层要求网络的输入尺寸一致),而是改变原图像大小。【256,512】的意思:对图像进行等比例缩放,其缩放的大小为最小尺度在256与512之间。在输入模型之前,把图像切分成尺寸为224的图像块,并从中随机抽取作为图像。
(2)对比多尺度预测实验:
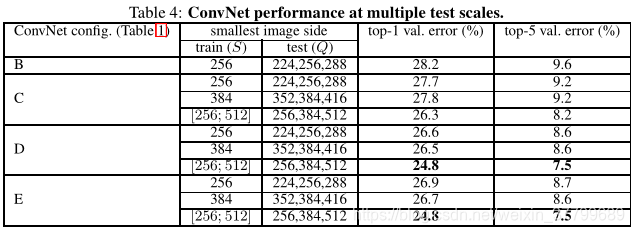
实验结论:第一点:对比单尺度预测和多尺度综合预测,对训练集进行多尺度处理可以提升预测精度;第二点:VGG16为最优网络结构,因为它效果与VGG19相似并且结果更为简单。(以后使用VGG多为VGG16模型)。
3)测试方法对比实验:
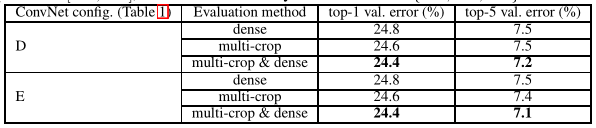
实验结论: 对密集卷积网络评估和多重裁切评估进行了比较。我们同样还评估了两种技术通过计算两者soft-max输出平均值的互补结果。可以看出使用多重裁切比密集评估的效果略好,并且两种方法是完全互补的,因为两者组合的效果比每一种都要好。
两种评价方法: 第一点:dense将原图直接送到网络进行预测,将最后的全连接层改为1x1的卷积(FCN),这样最后可以得出一个预测的w*h*n的score map,再对结果求平均。其中,w和h与输入图片大小有关,而n与所需类别数相同;第二点:multi-crop为使用的卷积层+全连接层策略。通过将测试图片缩放到不同大小Q,Q可以不等于S(训练时图片大小)。在Q*Q图片上裁剪出多个S*S的图像块,将这些图像块进行测试,得到多个1*n维的向量。通过对这些向量每一纬求平均,得到在某一类上的概率。
差别在于convolution boundary condition不同:dense由于不限制图片大小,可以利用像素点及其周围像素的信息(来自于卷积和池化),包含了一些上下文信息,增大了感受野,因此提高分类的准确度;而multi-crop由于从图片上裁剪再输网络,需要对输入的图像进行padding(相当于在剪裁过程中对边界进行舍弃),因此增加了噪声。参考链接
4)模型融合实验(D、E)对比:模型融合后错误率进一步下降

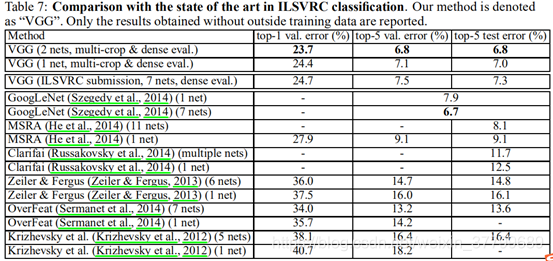
5)与其他模型对比实验:第二名
3、论文结论
1)在一定范围内,通过增加深度可有效提升网络性能。
2)最佳模型:VGG16,只使用3*3卷积和2*2池化,简洁优美。
3)多个小卷积核比单个大卷积核性能更好。
4)LRN层并不会对网络性能带来提升。
5)尺度抖动(scale jittering),即多尺度训练(【256,512】剪裁)和多尺度测试(multi-crop测试),有利于网络性能的提升。
二、基础讲解
1、感受野
概念:与特征图上的一点有关系的点在原图的区域,即卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
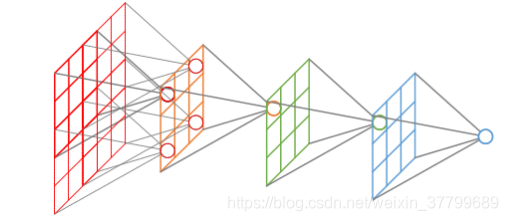
计算:

注:上述为理论上的感受野大小,实际上真正起作用的感受野要远小于理论上的。
举例:

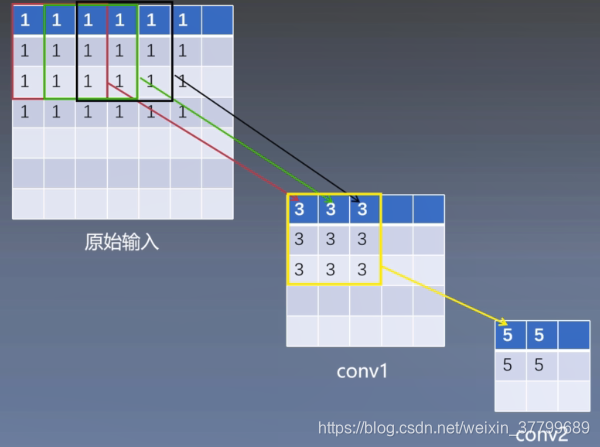
结论:
一个5*5卷积核感受野大小于两个3*3卷积核的感受野相同,以此类推3个3*3卷积核的感受野与一个7*7的卷积核感受野等价。
三、论文重点讲解
1、摘要翻译
本文研究了在大规模图片识别中,卷积神经网络的深度对准确率(accuracy)的影响。我们的主要贡献是通过非常小的3x3卷积核的神经网络架构全面评估了增加深度对网络的影响,结果表明16-19层的网络可以使现有设置的网络性能得到显著提高。这项发现是我们在2014年的ImageNet比赛中提交方案的基础,我们的团队分别在定位和分类中获得了第一和第二的成绩。我们还证明了此模型可以泛化到其他数据集上,并达到当前最佳水平。我们已经公布了两个性能最佳的卷积神经网络模型,以便深度视觉在计算机视觉中的进一步研究。
2、网络结构与权重参数计算:
1)网络结构:
共有5个卷积块,每个卷积块由不同数量的小卷积层堆积;每个卷积块的通道数量依次增加一倍(倒金字塔型);每个卷积块结束后进行最大池化;有三个全连接层。
2)参数计算(VGG16)

3)补充
(1)为什么使用3*3的卷积核?
原因1:深度更深并增加了非线性,即3个3*3的卷积核与一个7*7的卷积核感受野等效,但这三个卷积核之间加入了激活函数,与仅使用一个7*7卷积核相比,深度更深且非线性程度更高。
原因2:参数量少,即假设输入通道大小为C,则三个C通道的卷积核参数量为3*(C*3*3*C)=27*C*C,一个C通道的7*7卷积核参数量为C*7*7*C=49*C*C。
(2)1*1卷积核的作用?
作用1:增加非线性因素。
作用2:调整网络的维度,增加或减少维度(通道数)。
3、训练数据处理
1)方法:各向同性的缩放训练图像最小边
step1:将图像进行等比变化,最小边长度为256
step2 : 对等比变化后的图像随机截取224*224的图像块
step3 :对剪裁图像块进行随机随机水平翻转与RGB颜色转化
2)举例对比


4、多尺度训练数据 (不是测试方法)

注:论文中虽然没提测试集是如何截取的,但应该是中心截取。


5、超参数设置:
batchsize=256、学习率=5*10-4、Adam学习率=0.01、动量=0.9、迭代步数:370KK、epoches=75<100、初始化方式:高斯初始化
6、模型总结(特点):

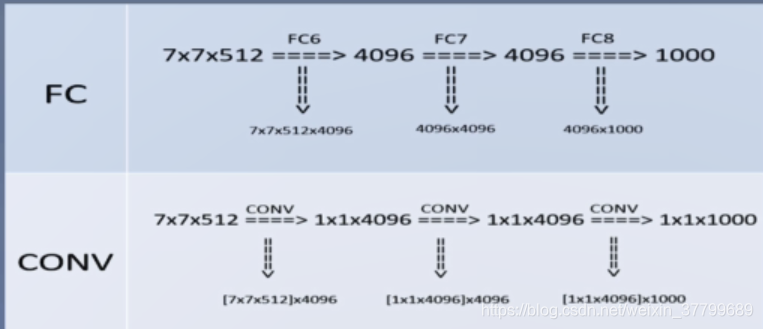
思考:为什么全连接转卷积?为了适应多尺度的输入
1)全连接层缺点:限制输入尺寸
全连接层计算公式:f=wx+b,假设输入全连接层的特征7*7*5、输出的特征为1000
此时,x.shape=(245,1)、b.shpe=(1000,1)、w.shape=(245,1000)
若改变全连接层的输入为14*14*5,输出大小不变。
则x.shape=(980,1),而w.shape=(245,1000)不等于(980,1000)
2)全卷积层
使用1000个7*7*5卷积核代替全连接层,其w.shape不变都为(245,1000)。因此,可以将FC层的参数赋给卷积层。
假设输入特征7*7*5,平均scoremap,其输出尺度为【1,1,1,1000】
假设输入特征14*14*5,平均scoremap,其输出尺度为【1,1,1,1000】
四、代码重点讲解
1、微调是使用预训练的神经网络模型,来训练我们自己的数据集合。
1)什么情况使用微调?
自己设计的网络不好用,精度太低;数据集合相似但数据量小;计算资源不够。
2)为啥微调会有效?
神经网络浅层学习的是通用特征级基础特征,如边缘,轮廓颜色等。深层是针对特定数据的更抽象的特征,全连接成就是对特征进行组合并评分分类。我们可以利用网络前几层学习到通用特征,仅让网络学习数据的抽象特征,节省资源和时间。
3)应用场景

2、数据增强实践
1)求缩放后图片的尺寸
2)缩放图像
3)随机剪裁
4)主函数
if __name__ =='__main__':
data_dir = './flower_photos'
training_filenames, validation_filenames,class_names_to_ids = split_datas(data_dir)
train_data, train_label =get_datas_and_labels('train', training_filenames, class_names_to_ids)
val_data, val_label =get_datas_and_labels('validation', validation_filenames, class_names_to_ids)
train = Load_data(train_data, train_label, 1, 5, shuffle = True, buffer_size=1000)
print(val_data)3、数据加载
def _get_filenames_and_classes(dataset_dir):
'''
生成包含图像绝对路径的列表,以及花卉品种排序后的列表
:param dataset_dir: 数据的位置
:return: 返回一个列表这个列表包含了所有图片的路径,返回花卉种类名称
'''
directories = []
class_names = []
#获取每个flowers_photos文件夹中的文件夹名称
for filename in os.listdir(dataset_dir):
#获取每个文件夹的绝对路径
# directories=['./flower_photos/roses', './flower_photos/daisy', ...]
# class_names=['roses', 'daisy', 'tulips', 'dandelion', 'sunflowers']
path = os.path.join(dataset_dir, filename)
if os.path.isdir(path):
directories.append(path)
class_names.append(filename)
photo_filenames = []
#获取每张图片的绝对路径
#photo_filenames=['./flower_photos/roses/488849503_63a290a8c2_m.jpg',...]
for directory in directories:
for filename in os.listdir(directory):
path = os.path.join(directory, filename)
photo_filenames.append(path)
return photo_filenames, sorted(class_names)

















 33
33

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









