







大家好,我是带我去滑雪!
本期使用UCI Machine Learning Repository 的小麦种子数据 seeds_dataset.csv 进行判别分析。该数据集中,变量“Class”为响应变量,取值为1,2,3,表示三种不同类型的小麦种子,变量V1-V7 均为数值型特征变量,为根据X光技术得到的麦粒几何性质,比如面积、周长、宽度等。该数据需要提前下载并放置python工作路径,数据可去文末获取。
期望完成如下问题:
(1)载入数据集seeds_dataset.csv,展示其形状与前五个观测值;
(2)计算该数据框的统计特征,以及响应变量的分布;
(3)计算各变量间的相关系数,并实现相关系数矩阵可视化;
(4)使用全样本进行线性判别分析,画出第1线性判元与第2线性判元的散点图,并根据种子类型进行上色;
(5)设定参数”random_state=0“,使用分层抽样,随机选取三分之二的样本作为训练集,进行线性判别分析;
(6)在测试集中预测,展示混淆矩阵,并计算准确率;
(7)使用训练集,进行二次判别分析;
(8)在测试集中,计算二次判别分析的混淆矩阵与准确率。
(1)载入数据集seeds_dataset.csv,展示其形状与前五个观测值;
首先载入并查看数据数据:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as ans
import csv
data=pd.read_csv('seeds_dataset.csv')
data输出结果:
V1 V2 V3 V4 V5 V6 V7 Class 0 15.26 14.84 0.8710 5.763 3.312 2.221 5.220 1 1 14.88 14.57 0.8811 5.554 3.333 1.018 4.956 1 2 14.29 14.09 0.9050 5.291 3.337 2.699 4.825 1 3 13.84 13.94 0.8955 5.324 3.379 2.259 4.805 1 4 16.14 14.99 0.9034 5.658 3.562 1.355 5.175 1 ... ... ... ... ... ... ... ... ... 205 12.19 13.20 0.8783 5.137 2.981 3.631 4.870 3 206 11.23 12.88 0.8511 5.140 2.795 4.325 5.003 3 207 13.20 13.66 0.8883 5.236 3.232 8.315 5.056 3 208 11.84 13.21 0.8521 5.175 2.836 3.598 5.044 3 209 12.30 13.34 0.8684 5.243 2.974 5.637 5.063 3
展示数据集前5个观测值:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as ans
import csv
data=pd.read_csv('seeds_dataset.csv')
data.head()输出结果:
V1 V2 V3 V4 V5 V6 V7 Class 0 15.26 14.84 0.8710 5.763 3.312 2.221 5.220 1 1 14.88 14.57 0.8811 5.554 3.333 1.018 4.956 1 2 14.29 14.09 0.9050 5.291 3.337 2.699 4.825 1 3 13.84 13.94 0.8955 5.324 3.379 2.259 4.805 1 4 16.14 14.99 0.9034 5.658 3.562 1.355 5.175 1
展示数据形状:
其中plt.savefig函数为保存图像设置参数,squares1.png为图像名称,由于python默认的图像像素值仅72,所以图像看起来十分模糊,这里设置dpi=300,将图像像素提高到300。另外有时候画图时,发现图像显示不全,可以设置 bbox_inches ="tight",就可以解决。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as ans
import csv
data=pd.read_csv('seeds_dataset.csv')
data.head()
plt.plot(data)
plt.savefig("squares1.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
(2)计算该数据框的统计特征,以及响应变量的分布;
考察数据框data的统计特征可以使用describe()。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as ans
import csv
data=pd.read_csv('seeds_dataset.csv')
data.describe()输出结果:
V1 V2 V3 V4 V5 V6 V7 count 210.000000 210.000000 210.000000 210.000000 210.000000 210.000000 210.000000 mean 14.847524 14.559286 0.870999 5.628533 3.258605 3.700201 5.408071 std 2.909699 1.305959 0.023629 0.443063 0.377714 1.503557 0.491480 min 10.590000 12.410000 0.808100 4.899000 2.630000 0.765100 4.519000 25% 12.270000 13.450000 0.856900 5.262250 2.944000 2.561500 5.045000 50% 14.355000 14.320000 0.873450 5.523500 3.237000 3.599000 5.223000 75% 17.305000 15.715000 0.887775 5.979750 3.561750 4.768750 5.877000 max 21.180000 17.250000 0.918300 6.675000 4.033000 8.456000 6.550000
考察响应变量分布可以使用value_counts()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as ans
import csv
data=pd.read_csv('seeds_dataset.csv')
data.value_counts('Class')输出结果:
Class 1 70 2 70 3 70 dtype: int64
(3)计算各变量间的相关系数,并实现相关系数矩阵可视化;
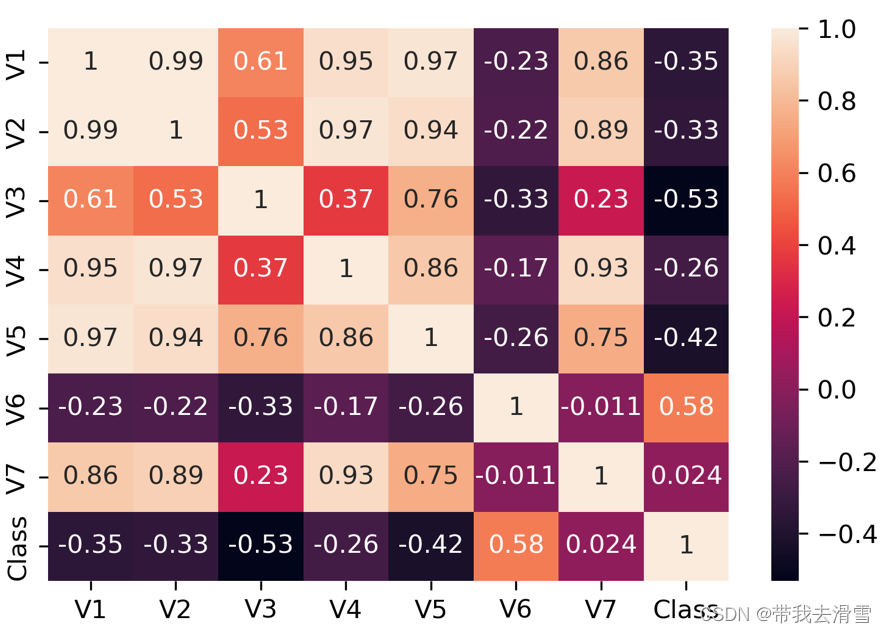
使用corr.()方法计算变量间的相关系数矩阵,如果特征变量增多,直接看相关系数矩阵将会变得异常困难,可以使用seaborn模块的heatmap()函数将相关系数矩阵进行可视化,相关代码与结果如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import csv
data=pd.read_csv('seeds_dataset.csv')
data.corr()输出结果:
V1 V2 V3 V4 V5 V6 V7 Class V1 1.000000 0.994341 0.608288 0.949985 0.970771 -0.229572 0.863693 -0.346058 V2 0.994341 1.000000 0.529244 0.972422 0.944829 -0.217340 0.890784 -0.327900 V3 0.608288 0.529244 1.000000 0.367915 0.761635 -0.331471 0.226825 -0.531007 V4 0.949985 0.972422 0.367915 1.000000 0.860415 -0.171562 0.932806 -0.257269 V5 0.970771 0.944829 0.761635 0.860415 1.000000 -0.258037 0.749131 -0.423463 V6 -0.229572 -0.217340 -0.331471 -0.171562 -0.258037 1.000000 -0.011079 0.577273 V7 0.863693 0.890784 0.226825 0.932806 0.749131 -0.011079 1.000000 0.024301 Class -0.346058 -0.327900 -0.531007 -0.257269 -0.423463 0.577273 0.024301 1.000000 fig=sns.heatmap(data.corr(),annot=True,fmt='.2g')#annot为热力图上显示数据;fmt='.2g'为数据保留两位有效数字
fig
plt.savefig("squares.png",
bbox_inches ="tight",
pad_inches = 1,
transparent = True,
facecolor ="w",
edgecolor ='w',
dpi=300,
orientation ='landscape')输出结果:
(4)使用全样本进行线性判别分析,画出第1线性判元与第2线性判元的散点图,并根据种子类型进行上色;
使用全样本(不分训练集和测试集)进行线性判别分析,可以通过sklearn模块的LinearDiscriminantAnalysis类来实现:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import csv
from sklearn.model_selection import train_test_split
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
from sklearn.metrics import cohen_kappa_score
data=pd.read_csv('seeds_dataset.csv')
y=data.Class#将响应变量记为y
model=LinearDiscriminantAnalysis()#创建一个实例model
model.fit(data,y)#使用fit方法进行估计
model.score(data,y)#计算预测准确率输出结果:
0.9666666666666667model.scalings_#考察线性判别元的系数估计值
输出结果:
array([[ 4.23778614e-01, 4.19531669e+00], [-3.79919995e+00, -8.50579585e+00], [-5.92772810e+00, -8.69823024e+01], [ 5.98819597e+00, -7.83067468e+00], [-3.70482197e-02, 7.14104253e-01], [ 4.50472160e-02, 3.21253808e-01], [-3.11807592e+00, 6.91384931e+00]])
为了更好地展示线性判别系数,将其变为数据框,并加上适当的行名和列名:
lda_loadings=pd.DataFrame(model.scalings_,columns=['LD1','LD2'])
lda_loadings输出结果:
LD1 LD2 V1 0.423779 4.195317 V2 -3.799200 -8.505796 V3 -5.927728 -86.982302 V4 5.988196 -7.830675 V5 -0.037048 0.714104 V6 0.045047 0.321254 V7 -3.118076 6.913849
lda_scores=model.fit(data,y).transform(data)
lda_scores.shape#考察线性判别得分形状
lda_scores[:5,:]#考察线性判别得分前5行观测值输出结果:
array([[ 0.43132208, -3.44768583], [ 0.75286941, -4.1839799 ], [ 1.09393189, -2.95867452], [ 1.7680201 , -3.25241433], [-0.49441123, -3.43848523]])
下面画出两个线性判别元(LD1,LD2)的散点图,以达到数据降维的目的。为此,先将lda_scores变为数据框,并在此数据框上加上响应变量”Class“:
LDA_scores=pd.DataFrame(lda_scores,columns=['LD1','LD2'])#将lda_scores变为数据框lda_scores
LDA_scores['Class']=data.Class
LDA_scores.head()#查看LDA_scores数据框前五行输出结果:
LD1 LD2 Class 0 0.431322 -3.447686 1 1 0.752869 -4.183980 1 2 1.093932 -2.958675 1 3 1.768020 -3.252414 1 4 -0.494411 -3.438485 1 fig=sns.scatterplot(x='LD1',y='LD2',data=LDA_scores,hue='Class',style='Class')#画出两个线性判别元的散点图,其中参数”hue=='Class'“表示根据小麦类别进行上色,style='Class'表示图标按小麦类别进行区分
plt.savefig("squares.png",dpi=300, bbox_inches ="tight")输出结果:
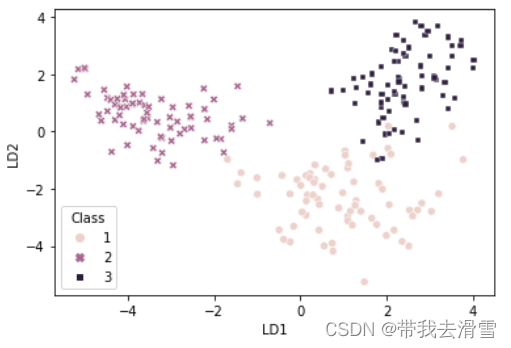
从上图可以发现,在降维之后的线性判别元(LD1,LD2)空间中,从LD1维度来看,第2种小麦能够与其他两种小麦区分开来,而从LD2维度来看,第1种小麦能够很好地与其他两种小麦区分。
(5)设定参数”random_state=0“,使用分层抽样,随机选取三分之二的样本作为训练集,进行线性判别分析;
data_train,data_test,y_train,y_test=train_test_split(data,y,test_size=0.3,stratify=y,random_state=0)
model=LinearDiscriminantAnalysis()#创建一个实例model
model.fit(data_train,y_train)
model.score(data_train,y_train)输出结果:
0.9795918367346939
(6)在测试集中预测,展示混淆矩阵,并计算准确率;
prob=model.predict_proba(data_test)#使用训练的模型预测测试集的分类概率
prob[:5]#z展示前5行预测概率输出结果:
array([[7.29717976e-03, 9.92655417e-01, 4.74033207e-05], [4.49893724e-05, 1.04163559e-06, 9.99953969e-01], [2.34958628e-09, 9.99999998e-01, 8.06413906e-13], [9.51231312e-03, 5.92638876e-08, 9.90487628e-01], [2.97531335e-07, 9.99999702e-01, 4.62306830e-11]])pred=model.predict(data_test)#使用训练的模型预测测试集种每个样例小麦的种类
pred[:5]#z展示前5个预测结果输出结果:
array([2, 3, 2, 3, 2], dtype=int64)model.score(data_test,y_test)#计算测试集准确率
输出结果:
0.9365079365079365confusion_matrix(y_test,pred)#计算混淆矩阵
输出结果:
array([[18, 0, 3], [ 0, 21, 0], [ 1, 0, 20]], dtype=int64)print(classification_report(y_test,pred))#计算基于混淆矩阵的一系列模型预测效果的评价指标
输出结果:
precision recall f1-score support 1 0.95 0.86 0.90 21 2 1.00 1.00 1.00 21 3 0.87 0.95 0.91 21 accuracy 0.94 63 macro avg 0.94 0.94 0.94 63 weighted avg 0.94 0.94 0.94 63cohen_kappa_score(y_test,pred)#计算科恩的kappa指标
输出结果:
0.9047619047619048
结果显示,模型测试集的准确率达到93.65%,约等于94%,利用训练的模型对测试集进行预测时,只有1个观测值被错误分类。科恩kappa值达到90.48%,说明预测值与实际值之间较为一致,线性判别分析对数据集 seeds_dataset.csv中的小麦种类取得较好的分类效果。
(7)使用训练集,进行二次判别分析;
model=QuadraticDiscriminantAnalysis()#创建一个QuadraticDiscriminantAnalysis类的实例
model.fit(data_train,y_train)#使用训练集进行训练
(8)在测试集中,计算二次判别分析的混淆矩阵与准确率。
pred=model.predict(data_test)#使用训练的模型预测测试集种每个样例小麦的种类
pred[:5]#z展示前5个预测结果输出结果:
array([1, 1, 1, 1, 1], dtype=int64)confusion_matrix(y_test,pred)#计算混淆矩阵
输出结果:
array([[21, 0, 0], [21, 0, 0], [21, 0, 0]], dtype=int64)model.score(data_test,y_test)#计算模型准确率
输出结果:
0.3333333333333333
二次判别分析结果显示,模型的准确率为33.33%,从混淆矩阵也可以看出,测试集中有42个观测值被错误分类,说明二次判别分析的分类效果很差,对于数据集seeds_dataset.csv中的小麦种类不能达到较好的分类效果。
需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/1FmXgepDVpv7c-eYdwPHDYg?pwd=2138
提取码:2138
更多优质内容持续发布中,请移步主页查看。
若有问题可邮箱联系:1736732074@qq.com
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!

















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











