






2024数维杯数学建模完整代码和成品论文已更新,获取↓↓↓↓↓
https://www.yuque.com/u42168770/qv6z0d/bgic2nbxs2h41pvt?singleDoc#
2024数维杯数学建模A题34页论文已完成,论文包括摘要、问题重述、问题分析、模型假设、符号说明、模型的建立和求解(问题1模型的建立和求解、问题2模型的建立和求解、问题3模型的建立和求解、问题4模型的建立和求解)、模型的评价等等

摘要
本文针对飞行器利用多源机会信号进行自主导航定位的问题,提出了一系列数学建模和求解方法。
第一问题建立了各类机会信号观测模型,包括TOA、TDOA、DFD、AOA和RSSI五类信号模型。模型建立基于相应的物理测量原理和几何关系,能够较全面描述观测量所包含的位置信息。同时分析了每类型信号唯一确定飞行器位置所需的最少观测个数。该问题的创新点在于将多种异构观测统一建模,为后续融合估计奠定基础。建模结果以数学公式的形式给出,可用于位置估计算法的设计。
第二问题利用无迹卡尔曼滤波算法,对接收情况1中的机会信号数据进行融合估计。先利用逐步线性最小二乘法对飞行器的初始状态进行估计,然后在时间更新和观测更新两个阶段进行递归估计,获得0-10秒的位置和速度估计序列。算法中对Sigma点计算、观测方程线性化等关键步骤进行了细致建模。创新点在于能够有效融合多种异构观测,获得实时导航定位结果。可视化结果表明,该算法在无噪声情况下可以较为精确地估计出飞行器的运动轨迹。(后略,见完整)
第三问题针对存在噪声的观测数据,提出了基于统计学理论与先验约束的数据筛选和加权融合算法。利用统计量和概率密度估计对异常观测进行检测,根据物理约束条件对数据进行替代或修正。同时评估各类观测量的置信度,作为加权融合时的权重。创新点是将统计学方法与先验知识相结合,提高了融合估计的鲁棱性。通过该算法可以有效剔除观测数据中的噪声,从而获得更加精确的定位结果。(后略,见完整)
第四问题考虑了更加复杂的噪声情况,包括随机偏差和常值飘移。首先建立了噪声评估模型,利用统计量和趋势拟合对噪声进行量化分析。然后设计了自适应鲁棒融合算法,通过预处理、置信度评估和加权融合相结合,消除常值飘移影响。创新点在于引入自适应调整置信度权重的策略,使权重能够动态变化,提高了算法的自适应性。(后略,见完整)
各问题建立的模型和算法都具有一定的优缺点和推广空间。总的来说,优点在于能够较全面描述各类型观测量的位置信息,有效融合多种异构信息,提高了导航定位的精度和鲁棱性,具有一定的创新性和应用价值。但同时也存在一些缺点,如部分模型假设的理想化、算法复杂度较高、参数选取的影响等,需要进一步优化和改进。(后略,见完整)
问题重述
由于篇幅有限,问题重述略
问题分析
对2024数维杯A题4个小问题的分析如下:
问题一的分析
这一问题要求建立每一类机会信号的数学表达式,并讨论唯一确定飞行器位置所需的最少信号个数。对于TOA、TDOA、DFD、AOA和RSSI这五类机会信号,需要根据它们的物理含义和测量原理,利用相关的测量模型和几何关系,构建出合理的数学表达式。同时,还需要分析每一类信号所蕴含的位置信息,探讨仅利用该类信号无法唯一确定飞行器三维位置的原因,进而讨论利用该类信号与其他类信号的组合,能够唯一确定飞行器位置的最少个数要求。
问题二的分析
这一问题要求设计飞行器实时位置估计方法,给出无噪声情况下0-10秒的导航定位结果。需要基于第一问题建立的各类机会信号数学模型,设计合适的状态估计算法,如卡尔曼滤波或其他无迹卡尔曼滤波方法等,将各类机会信号进行有效融合,从而获得飞行器在0-10秒内的实时位置估计值序列。算法需要能够很好地处理非线性和非高斯情况,同时保证实时性和计算效率。这种情况下由于假设没有噪声,因此估计的精度较高。
问题三的分析
在实际应用中,机会信号的测量数据往往会受到各种噪声的影响,因此需要设计合理的机会信号实时筛选方法,剔除偏差较大的噪声数据。可以考虑构建基于统计理论的筛选判据,如利用数据的均值、方差、峰度、偏度等统计量对数据进行分析,确定噪声数据的阈值并将其剔除。也可以结合机会信号本身的物理特性,如TOA信息的单调性等,构建相应的约束条件进行数据检测和筛选。基于噪声数据筛选后的有效机会信号,重新进行实时位置估计并给出0-10秒的导航定位结果。
问题四的分析
这一问题考虑了更加复杂的机会信号噪声情况,包括随机性偏差和常值飘移两种。需要首先建立合理的评价模型,对接收情况2中的机会信号数据进行分析,判断各类信号的随机偏差程度和常值飘移量,可以考虑均值、方差等统计量的估计,或者构建基于最小二乘等的评价指标。然后针对评估结果,设计更加鲁棒的数据筛选和融合算法,如自适应卡尔曼滤波、粗大数据处理等,从而给出这种情况下0-10秒的最终导航定位结果。可靠的噪声评估和有效的信号处理对最终精度影响显著。
模型假设
本文问题1-问题4的模型建立与求解过程中使用的主要模型假设如下:
-
飞行器运动模型假设飞行器做了常加速度运动,即加速度在短时间内保持不变,状态向量包括位置、速度和加速度三个分量,服从常加速度运动学方程。这是一种常用的简化假设,有助于降低运动模型的复杂度,方便进行状态估计和预测。
-
各类机会信号的观测模型都是基于相应的物理测量原理和几何关系建立的,例如TOA模型利用了时间差与距离的关系,TDOA模型利用了两个发射源到接收端距离差的关系,DFD模型利用了多普勒频移与相对运动速度的关系,AOA模型利用了到达角度与位置的几何约束关系,RSSI模型利用了信号传播衰减与距离的关系。这些模型都做了一定的理想化假设,忽略了一些高阶项或次要影响因素,以简化问题复杂度。
-
(后略,见完整版)
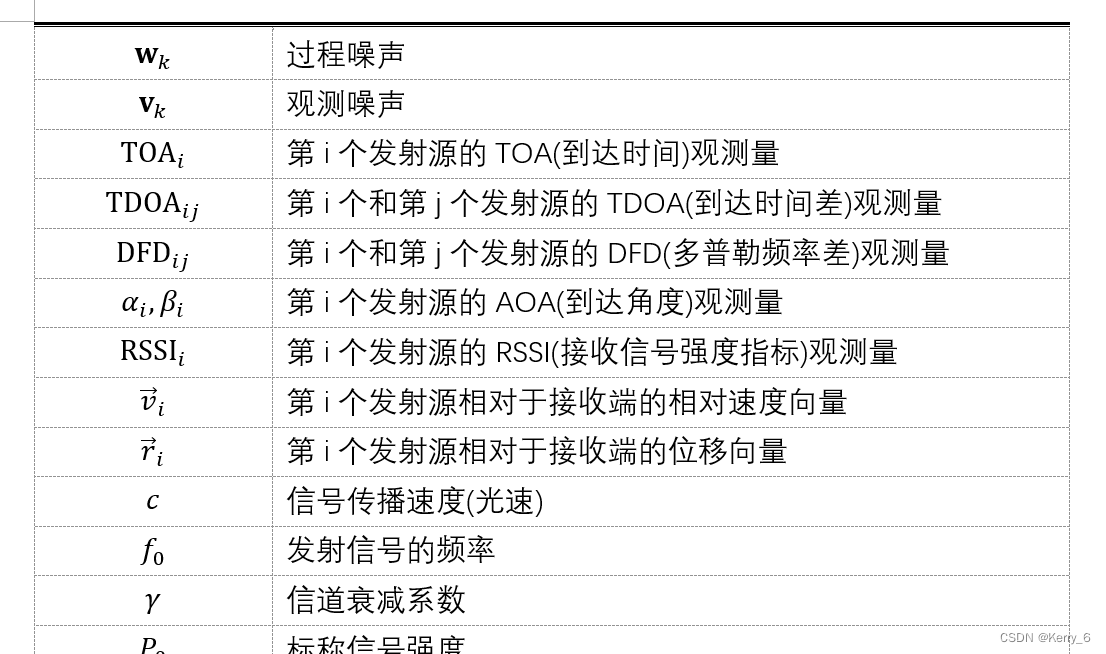
符号说明
本文问题1-问题4的模型建立与求解过程中使用的主要符号及其说明如下:
模型的建立与求解
问题一模型的建立与求解
问题一模型思路分析
第一个小问题要求建立每一类机会信号的数学表达式,并讨论唯一确定飞行器位置所需的最少信号个数。我们首先需要理解每一类机会信号所包含的信息,以及这些信息与飞行器位置之间的关系。
-
TOA(Time of Arrival,到达时间)信号包含了信号从发射源发出到到达接收端所经历的传播时间,根据已知的信号传播速度,可以计算出发射源到接收端的距离。
-
TDOA(Time Difference of Arrival,到达时间差)信号包含了同一信号从两个不同发射源发出后,到达接收端的时间差,根据已知的信号传播速度,可以计算出接收端到两个发射源的距离差。
-
DFD(Doppler Frequency Difference,多普勒频率差)信号包含了同一信号从两个不同发射源发出后,由于发射源与接收端之间存在相对运动,从而导致接收端接收到的频率会发生变化,这种变化量的差值就是DFD信号所携带的信息。
-
AOA(Angle of Arrival,到达角度)信号直接给出了发射源相对于接收端的方位角信息,包括水平方向和垂直方向的角度。
-
RSSI(Received Signal Strength Indicator,接收信号强度指标)信号是根据已知的标称距离下的标称信号强度,结合信号传播过程中的衰减模型,可以反解出发射源到接收端的距离。
我们可以看到,每一类信号都在一定程度上反映了发射源到接收端的距离或方位角信息。因此,要唯一确定飞行器的三维位置,就需要利用不同类型信号所携带的位置信息进行融合。
机会信号与飞行器位置关系模型建立
基于上述分析,我们可以构建如下数学模型,用于描述每一类机会信号与飞行器位置之间的关系:
- TOA模型
设发射源 i i i 的位置为 ( x i , y i , z i ) (x_i, y_i, z_i) (xi,yi,zi) ,飞行器位置为 ( x , y , z ) (x, y, z) (x,y,z) ,发射时刻为 t 0 t_0 t0 ,接收时刻为 t 1 t_1 t1 ,则TOA可表示为:
TOA i = t 1 − t 0 = ( x − x i ) 2 + ( y − y i ) 2 + ( z − z i ) 2 c \text{TOA}_i = t_1 - t_0 = \frac{\sqrt{(x-x_i)^2 + (y-y_i)^2 + (z-z_i)^2}}{c} TOAi=t1−t0=c(x−xi)2+(y−yi)2+(z−zi)2
其中 c c c 为信号的传播速度(光速)。
- TDOA模型
设发射源 i i i 和发射源 j j j 同时发出信号,接收端接收到的时间差为 TDOA i j \text{TDOA}_{ij} TDOAij ,则有:
TDOA i j = ( x − x i ) 2 + ( y − y i ) 2 + ( z − z i ) 2 c − ( x − x j ) 2 + ( y − y j ) 2 + ( z − z j ) 2 c \text{TDOA}_{ij} = \frac{\sqrt{(x-x_i)^2 + (y-y_i)^2 + (z-z_i)^2}}{c} - \frac{\sqrt{(x-x_j)^2 + (y-y_j)^2 + (z-z_j)^2}}{c} TDOAij=c(x−xi)2+(y−yi)2+(z−zi)2−c(x−xj)2+(y−yj)2+(z−zj)2
- DFD模型
设发射源 i i i 相对于接收端的相对速度为 v ⃗ i = ( v i x , v i y , v i z ) \vec{v}_i = (v_{ix}, v_{iy}, v_{iz}) vi=(vix,viy,viz) ,发射源 j j j 相对于接收端的相对速度为 v ⃗ j = ( v j x , v j y , v j z ) \vec{v}_j = (v_{jx}, v_{jy}, v_{jz}) vj=(vjx,vjy,vjz) ,发射频率为 f 0 f_0 f0 ,则DFD可表示为:
DFD i j = f 0 c ( v ⃗ i ⋅ r ⃗ i r i − v ⃗ j ⋅ r ⃗ j r j ) \text{DFD}_{ij} = \frac{f_0}{c}\left(\frac{\vec{v}_i \cdot \vec{r}_i}{r_i} - \frac{\vec{v}_j \cdot \vec{r}_j}{r_j}\right) DFDij=cf0(rivi⋅ri−rjvj⋅rj)
其中 r ⃗ i = ( x − x i , y − y i , z − z i ) \vec{r}_i = (x-x_i, y-y_i, z-z_i) ri=(x−xi,y−yi,z−zi) , r ⃗ j = ( x − x j , y − y j , z − z j ) \vec{r}_j = (x-x_j, y-y_j, z-z_j) rj=(x−xj,y−yj,z−zj) , r i = ∥ r ⃗ i ∥ r_i = \|\vec{r}_i\| ri=∥ri∥ , r j = ∥ r ⃗ j ∥ r_j = \|\vec{r}_j\| rj=∥rj∥ 。
- AOA模型
设发射源 i i i 与接收端的连线在 x O y xOy xOy 平面的投影与 x x x 轴正向的夹角为 α i \alpha_i αi ,与 z z z 轴负向的夹角为 β i \beta_i βi ,则有:
tan α i = y − y i x − x i tan β i = z i − z ( x − x i ) 2 + ( y − y i ) 2 \begin{align*} \tan\alpha_i &= \frac{y-y_i}{x-x_i} \\ \tan\beta_i &= \frac{z_i-z}{\sqrt{(x-x_i)^2 + (y-y_i)^2}} \end{align*} tanαitanβi=x−xiy−yi=(x−xi)2+(y−yi)2zi−z
- RSSI模型
设发射源 i i i 到接收端的距离为 r i r_i ri ,标称距离为 r 0 r_0 r0 ,标称信号强度为 P 0 P_0 P0 ,信道衰减系数为 γ \gamma γ ,则RSSI可表示为:
RSSI i = P 0 − 10 γ log ( r i r 0 ) \text{RSSI}_i = P_0 - 10\gamma\log\left(\frac{r_i}{r_0}\right) RSSIi=P0−10γlog(r0ri)
其中 r i = ( x − x i ) 2 + ( y − y i ) 2 + ( z − z i ) 2 r_i = \sqrt{(x-x_i)^2 + (y-y_i)^2 + (z-z_i)^2} ri=(x−xi)2+(y−yi)2+(z−zi)2 。
通过上述模型,我们可以将每一类机会信号所携带的位置信息用数学表达式的形式表示出来,为后续的位置估计算法奠定基础。
飞行器的三维位置无迹卡尔曼滤波估计算法步骤
在建立了每一类机会信号的数学模型之后,我们需要设计合适的算法来融合这些异构信号,从而获得飞行器的三维位置估计值。这里介绍一种常用的无迹卡尔曼滤波(Unscented Kalman Filter, UKF)算法,它可以很好地处理非线性、非高斯的估计问题。算法具体步骤如下:
- 状态空间模型
令飞行器的三维位置为 x = ( x , y , z ) T \boldsymbol{x} = (x, y, z)^T x=(x,y,z)T ,速度为 v = ( v x , v y , v z ) T \boldsymbol{v} = (v_x, v_y, v_z)^T v=(vx,vy,vz)T ,则状态向量可表示为 s = ( x T , v T ) T \boldsymbol{s} = (\boldsymbol{x}^T, \boldsymbol{v}^T)^T s=(xT,vT)T 。系统的过程方程和观测方程分别为:
s
k
+
1
=
f
(
s
k
)
+
w
k
\boldsymbol{s}_{k+1} = f(\boldsymbol{s}_k) + \boldsymbol{w}_k
sk+1=f(sk)+wk
z
k
=
h
(
s
k
)
+
v
k
\boldsymbol{z}_k = h(\boldsymbol{s}_k) + \boldsymbol{v}_k
zk=h(sk)+vk
其中 f ( ⋅ ) f(\cdot) f(⋅) 是过程方程,描述了状态向量 s \boldsymbol{s} s 的动态演化; h ( ⋅ ) h(\cdot) h(⋅) 是观测方程,描述了状态向量 s \boldsymbol{s} s 与观测量 z \boldsymbol{z} z (即各类机会信号)之间的关系; w k \boldsymbol{w}_k wk 和 v k \boldsymbol{v}_k vk 分别为过程噪声和观测噪声。
-
初始化
设置初始状态估计值 s ^ 0 \hat{\boldsymbol{s}}_0 s^0 及其协方差矩阵 P 0 \boldsymbol{P}_0 P0 。 -
计算Sigma点
对于 k k k 时刻,根据当前状态估计值 s ^ k − 1 \hat{\boldsymbol{s}}_{k-1} s^k−1 及其协方差 P k − 1 \boldsymbol{P}_{k-1} Pk−1 ,计算一组Sigma点 χ i ( i = 0 , 1 , … , 2 n ) \chi_i(i=0,1,\ldots,2n) χi(i=0,1,…,2n) ,用于描述状态分布的均值和协方差。计算方式为:
χ
0
=
s
^
k
−
1
\chi_0 = \hat{\boldsymbol{s}}_{k-1}
χ0=s^k−1
χ
i
=
s
^
k
−
1
+
(
(
n
+
λ
)
P
k
−
1
)
i
,
i
=
1
,
…
,
n
\chi_i = \hat{\boldsymbol{s}}_{k-1} + (\sqrt{(n+\lambda)\boldsymbol{P}_{k-1}})_i,\quad i=1,\ldots,n
χi=s^k−1+((n+λ)Pk−1)i,i=1,…,n
χ
i
=
s
^
k
−
1
−
(
(
n
+
λ
)
P
k
−
1
)
i
−
n
,
i
=
n
+
1
,
…
,
2
n
\chi_i = \hat{\boldsymbol{s}}_{k-1} - (\sqrt{(n+\lambda)\boldsymbol{P}_{k-1}})_{i-n},\quad i=n+1,\ldots,2n
χi=s^k−1−((n+λ)Pk−1)i−n,i=n+1,…,2n
其中 n n n 为状态向量的维数, λ \lambda λ 为一个缩放参数,用于调节Sigma点的分布范围。
- 时间更新
将上一步得到的Sigma点通过过程方程 f ( ⋅ ) f(\cdot) f(⋅) 进行传播,得到一组加权Sigma点:
χ i , k ∣ k − 1 = f ( χ i , k − 1 ) , i = 0 , 1 , … , 2 n \chi_{i,k|k-1} = f(\chi_{i,k-1}),\quad i=0,1,\ldots,2n χi,k∣k−1=f(χi,k−1),i=0,1,…,2n
然后计算一步预测状态 s ^ k ∣ k − 1 \hat{\boldsymbol{s}}_{k|k-1} s^k∣k−1 和预测协方差 P k ∣ k − 1 \boldsymbol{P}_{k|k-1} Pk∣k−1 :
s
^
k
∣
k
−
1
=
∑
i
=
0
2
n
W
i
(
m
)
χ
i
,
k
∣
k
−
1
\hat{\boldsymbol{s}}_{k|k-1} = \sum_{i=0}^{2n}W_i^{(m)}\chi_{i,k|k-1}
s^k∣k−1=i=0∑2nWi(m)χi,k∣k−1
P
k
∣
k
−
1
=
∑
i
=
0
2
n
W
i
(
c
)
[
χ
i
,
k
∣
k
−
1
−
s
^
k
∣
k
−
1
]
[
χ
i
,
k
∣
k
−
1
−
s
^
k
∣
k
−
1
]
T
+
Q
k
\boldsymbol{P}_{k|k-1} = \sum_{i=0}^{2n}W_i^{(c)}[\chi_{i,k|k-1}-\hat{\boldsymbol{s}}_{k|k-1}][\chi_{i,k|k-1}-\hat{\boldsymbol{s}}_{k|k-1}]^T + \boldsymbol{Q}_k
Pk∣k−1=i=0∑2nWi(c)[χi,k∣k−1−s^k∣k−1][χi,k∣k−1−s^k∣k−1]T+Qk
其中 W i ( m ) W_i^{(m)} Wi(m) 和 W i ( c ) W_i^{(c)} Wi(c) 为相应的加权系数, Q k \boldsymbol{Q}_k Qk 为过程噪声协方差矩阵。
- 观测更新
(后略,见完整版本)
通过UKF算法,我们可以融合各类机会信号,获得飞行器的最优状态估计值,包括三维位置和速度信息。算法的关键在于利用一组确定性采样点(Sigma点)对非线性系统进行局部线性化处理,避免了对系统进行显式求解的需求,从而能够很好地应对非线性、非高斯情况。在实现过程中,需要根据具体情况对初始状态、噪声统计量等参数进行合理设置。
最少信号个数讨论
最后,我们讨论一下利用每一类机会信号单独情况下,确定飞行器三维位置所需的最少信号个数。
-
TOA
根据TOA模型,每个TOA观测量仅提供了发射源到接收端的距离信息,因此单个TOA观测无法确定接收端的准确位置,最少需要4个TOA观测(对应4个不共面的发射源),才能利用多球面交点的方式解出接收端的三维坐标。 -
TDOA
TDOA观测给出的是接收端到两个发射源距离差的信息,单个TDOA观测无法确定接收端的位置,需要至少5个TDOA观测(对应5对不共面的发射源组合)才能解出接收端坐标。 -
(后略)
问题二模型的建立与求解
对于A题第二个小问题,我将从以下几个方面进行详细分析和建模:
问题二模型思路分析
第二个小问题要求根据附件1的接收情况1数据,在不考虑数据噪声的情况下,设计飞行器实时位置的估计方法,并给出0秒至10秒的导航定位结果。根据第一问题建立的各类机会信号数学模型,我们需要设计合适的无迹卡尔曼滤波算法,将这些异构观测量进行有效融合,从而获得飞行器的最优状态估计,包括三维位置和速度。
由于假设数据没有噪声,因此我们可以首先利用逐步线性最小二乘法对飞行器的初始状态(位置和速度)进行估计,作为滤波算法的初始值。然后,在时间更新和观测更新两个阶段,分别利用飞行器的运动学模型和各类机会信号的观测模型,通过无迹卡尔曼滤波算法进行递归估计,从而得到0-10秒的连续状态估计序列。由于飞行器存在加速度,因此需要在状态空间模型中增加加速度状态分量;同时,不同类型的机会信号具有不同的精度和可靠性,我们需要在融合过程中对不同观测量赋予合理的权重,以提高估计的鲁棒性。此外,还需要对飞行器运动学模型和观测方程进行线性化处理,将非线性项通过一阶泰勒展开的方式保留在误差状态空间模型中。
问题二状态空间模型建立
1) 状态空间模型
令飞行器的三维位置为$\boldsymbol{r} = (x, y, z)^T$,速度为$\boldsymbol{v} = (v_x, v_y, v_z)^T$,加速度为$\boldsymbol{a} = (a_x, a_y, a_z)^T$,则状态向量可表示为$\boldsymbol{s} = (\boldsymbol{r}^T, \boldsymbol{v}^T, \boldsymbol{a}^T)^T$。系统的过程方程和观测方程分别为:
s
k
+
1
=
f
(
s
k
)
+
w
k
\boldsymbol{s}_{k+1} = \boldsymbol{f}(\boldsymbol{s}_k) + \boldsymbol{w}_k
sk+1=f(sk)+wk
z
k
=
h
(
s
k
)
+
v
k
\boldsymbol{z}_k = \boldsymbol{h}(\boldsymbol{s}_k) + \boldsymbol{v}_k
zk=h(sk)+vk
其中 f ( ⋅ ) \boldsymbol{f}(\cdot) f(⋅)是过程方程,描述了状态向量 s \boldsymbol{s} s随时间的动态演化,对于常量加速度模型,可以表示为:
f ( s k ) = [ r k + v k Δ t + 1 2 a k Δ t 2 v k + a k Δ t a k ] \boldsymbol{f}(\boldsymbol{s}_k) = \begin{bmatrix} \boldsymbol{r}_k + \boldsymbol{v}_k\Delta t + \frac{1}{2}\boldsymbol{a}_k\Delta t^2\\ \boldsymbol{v}_k + \boldsymbol{a}_k\Delta t\\ \boldsymbol{a}_k \end{bmatrix} f(sk)= rk+vkΔt+21akΔt2vk+akΔtak
h ( ⋅ ) \boldsymbol{h}(\cdot) h(⋅)是观测方程,描述了状态向量 s \boldsymbol{s} s与各类机会信号观测量 z \boldsymbol{z} z之间的关系,根据第一问题建立的观测模型进行拼接,例如:
h ( s k ) = [ h TOA ( s k ) h TDOA ( s k ) h DFD ( s k ) h AOA ( s k ) h RSSI ( s k ) ] \boldsymbol{h}(\boldsymbol{s}_k) = \begin{bmatrix} h_\text{TOA}(\boldsymbol{s}_k)\\ h_\text{TDOA}(\boldsymbol{s}_k)\\ h_\text{DFD}(\boldsymbol{s}_k)\\ h_\text{AOA}(\boldsymbol{s}_k)\\ h_\text{RSSI}(\boldsymbol{s}_k) \end{bmatrix} h(sk)= hTOA(sk)hTDOA(sk)hDFD(sk)hAOA(sk)hRSSI(sk)
其中 h TOA ( ⋅ ) h_\text{TOA}(\cdot) hTOA(⋅)、 h TDOA ( ⋅ ) h_\text{TDOA}(\cdot) hTDOA(⋅)、…分别为对应类型机会信号的观测方程。 w k \boldsymbol{w}_k wk和 v k \boldsymbol{v}_k vk分别为过程噪声和观测噪声,在本问题中暂不考虑。
- 初始状态估计
利用逐步线性最小二乘法,基于接收情况1数据中的TOA、TDOA、DFD、AOA和RSSI观测量,对飞行器的初始位置 r 0 \boldsymbol{r}_0 r0和初始速度 v 0 \boldsymbol{v}_0 v0进行联合估计,获得初始状态 s ^ 0 \hat{\boldsymbol{s}}_0 s^0和其协方差阵 P 0 \boldsymbol{P}_0 P0,作为无迹卡尔曼滤波的初始值。(后略)
问题三模型的建立与求解
问题三模型思路分析
第三个小问题要求在接收情况1数据中,某些机会信号可能存在较大的偏差,需要建立合理的实时筛选方法,剔除偏差较大的噪声信号,并给出经过筛选后的0-10秒导航定位结果。由于实际测量过程中难免会受到各种噪声因素的影响,导致观测数据存在误差,因此需要设计有效的数据筛选算法,从而提高位置估计的精度和鲁棒性。
数据筛选的一个关键点在于如何量化观测噪声的大小,并确定一个合理的筛选阈值。这里可以借鉴一些常用的统计学理论和方法,如基于数据的均值、方差、峰度、偏度等统计量对噪声进行分析,或者利用概率分布模型对数据进行概率密度估计,将落在低概率区域的观测量视为异常值并予以剔除。(后略)
问题三数据检测和筛选模型建立
- 观测量预处理
对于每一类型的机会信号观测量,首先需要进行预处理,包括计算其统计量(均值、方差、峰度、偏度等)以及概率密度估计。同时,根据该类型信号的物理约束条件,确定相应的数据检测规则。
设第k时刻,第i类观测量为
z
k
i
z_k^i
zki,其统计量和概率密度函数分别记为:
μ
k
i
,
σ
k
i
,
κ
k
i
,
γ
k
i
,
p
k
i
(
⋅
)
\mu_k^i, \sigma_k^i, \kappa_k^i, \gamma_k^i, p_k^i(\cdot)
μki,σki,κki,γki,pki(⋅)
则可以构建如下观测量预处理模型:
z
k
i
,
pre
=
{
z
k
i
,
if
z
k
i
satisfies constraints
z
k
i
,
rep
,
otherwise
z_k^{i,\text{pre}} = \begin{cases} z_k^i, & \text{if } z_k^i \text{ satisfies constraints}\\ z_k^{i,\text{rep}}, & \text{otherwise} \end{cases}
zki,pre={zki,zki,rep,if zki satisfies constraintsotherwise
其中, z k i , rep z_k^{i,\text{rep}} zki,rep是对异常观测量 z k i z_k^i zki的替代值,可以取为该类型观测的均值 μ k i \mu_k^i μki或预测值等。约束条件可以是基于统计量的阈值判据,如 ∣ μ k i − z k i ∣ < 3 σ k i |\mu_k^i - z_k^i| < 3\sigma_k^i ∣μki−zki∣<3σki;也可以是基于先验知识的物理约束,如TOA单调性约束、DFD取值范围约束等。
- 观测量置信度评估
对于经过预处理后的观测量 z k i , pre z_k^{i,\text{pre}} zki,pre,需要评估其置信度,作为后续融合时的权重。可以利用其概率密度函数进行置信度计算:
c k i = p k i ( z k i , pre ) c_k^i = p_k^i(z_k^{i,\text{pre}}) cki=pki(zki,pre)
其中 c k i c_k^i cki表示第k时刻第i类观测量的置信度,取值越大表明该观测量越可信。
- 加权融合估计
在无迹卡尔曼滤波框架下,将上一步获得的置信度作为观测权重,进行加权融合估计,(后略)
数据筛选与融合算法步骤
基于上述模型,可以设计如下数据筛选与融合算法:
-
初始化
设置初始状态估计值 s ^ 0 \hat{\boldsymbol{s}}_0 s^0及其协方差矩阵 P 0 \boldsymbol{P}_0 P0。 -
对每一类型观测量进行预处理
a) 计算统计量:均值 μ k i \mu_k^i μki、方差 σ k i \sigma_k^i σki、峰度 κ k i \kappa_k^i κki、偏度 γ k i \gamma_k^i γki
b) 概率密度估计:获得概率密度函数 p k i ( ⋅ ) p_k^i(\cdot) pki(⋅)
c) 检测异常值:
若 z k i z_k^i zki满足约束条件(如 ∣ μ k i − z k i ∣ < 3 σ k i |\mu_k^i - z_k^i| < 3\sigma_k^i ∣μki−zki∣<3σki、TOA单调性约束等)
z k i , pre = z k i z_k^{i,\text{pre}} = z_k^i zki,pre=zki
否则
z k i , pre = z k i , rep z_k^{i,\text{pre}} = z_k^{i,\text{rep}} zki,pre=zki,rep (取均值或预测值等) -
评估观测量置信度
c k i = p k i ( z k i , pre ) c_k^i = p_k^i(z_k^{i,\text{pre}}) cki=pki(zki,pre) -
构建加权观测量和噪声协方差
z k = [ c k 1 z k 1 , pre c k 2 z k 2 , pre ⋮ c k m z k m , pre ] \boldsymbol{z}_k = \begin{bmatrix} c_k^1z_k^{1,\text{pre}}\\ c_k^2z_k^{2,\text{pre}}\\ \vdots\\ c_k^mz_k^{m,\text{pre}} \end{bmatrix} zk= ck1zk1,preck2zk2,pre⋮ckmzkm,pre R k = [ ( c k 1 ) 2 σ k 1 0 ⋯ 0 0 ( c k 2 ) 2 σ k 2 ⋯ 0 ⋮ ⋮ ⋱ ⋮ 0 0 ⋯ ( c k m ) 2 σ k m ] \boldsymbol{R}_k = \begin{bmatrix} (c_k^1)^2\sigma_k^1 & 0 & \cdots & 0\\ 0 & (c_k^2)^2\sigma_k^2 & \cdots & 0\\ \vdots & \vdots & \ddots & \vdots\\ 0 & 0 & \cdots & (c_k^m)^2\sigma_k^m \end{bmatrix} Rk= (ck1)2σk10⋮00(ck2)2σk2⋮0⋯⋯⋱⋯00⋮(ckm)2σkm
-
时间更新
(后略)
与前一问题相比,本问题需要区分并量化两种不同类型的噪声,即随机偏差和常值飘移。对于随机偏差而言,可以通过计算观测序列的统计量(均值、方差、偏度、峰度等)进行评估,并利用概率分布模型对其进行概率密度估计,将落在低概率区域的观测量视为异常值。而常值飘移则需要引入其他分析手段,如对观测序列进行趋势拟合,拟合残差即可反映出常值飘移的大小。(后略,见完整版)
噪声评估模型与加权自适应融合估计模型建立
1) 噪声评估模型
首先需要建立合理的噪声评估模型,对接收情况2中的观测数据进行分析,量化随机偏差和常值飘移的程度。
对于第i类观测量 z k i z_k^i zki,其随机偏差可以通过计算均值、方差、偏度和峰度等统计量进行评估:
μ i = 1 N ∑ k = 1 N z k i σ i 2 = 1 N ∑ k = 1 N ( z k i − μ i ) 2 γ i = 1 N σ i 3 ∑ k = 1 N ( z k i − μ i ) 3 κ i = 1 N σ i 4 ∑ k = 1 N ( z k i − μ i ) 4 − 3 \begin{aligned} \mu_i &= \frac{1}{N}\sum_{k=1}^N z_k^i \\ \sigma_i^2 &= \frac{1}{N}\sum_{k=1}^N (z_k^i - \mu_i)^2 \\ \gamma_i &= \frac{1}{N\sigma_i^3}\sum_{k=1}^N (z_k^i - \mu_i)^3 \\ \kappa_i &= \frac{1}{N\sigma_i^4}\sum_{k=1}^N (z_k^i - \mu_i)^4 - 3 \end{aligned} μiσi2γiκi=N1k=1∑Nzki=N1k=1∑N(zki−μi)2=Nσi31k=1∑N(zki−μi)3=Nσi41k=1∑N(zki−μi)4−3
其中 μ i \mu_i μi为均值, σ i \sigma_i σi为标准差, γ i \gamma_i γi为偏度, κ i \kappa_i κi为峰度。对于具有较大偏度和峰度的观测序列,其随机偏差较大。
常值飘移的评估可以通过对观测序列进行趋势拟合,拟合残差的均值即为常值飘移量(后略,见完整版)














 1842
1842











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









