






在这里实现一个简单的小需求,对数据库中100个员工根据年龄字段分为六组(0-20,20-30,30-40,40-50,50-60,60+)的操作:
方法一
这是我最开始使用的一个方法:
public List<Map> showGroup() {
//创建员工按年龄分组的集合,key为1-6,value为员工集合
List<Map> page = new ArrayList<>();
//使用map集合来存储各组对应的年龄信息
Map<Integer, List<SunStaffEntity>> map = new HashMap();
for (int i = 1; i <= 6; i++) {
//获取当前组的最小年龄限制和最大年龄限制
Integer minAge = staffGroupDao.queryById(i).getMinAge();
Integer maxAge = staffGroupDao.queryById(i).getMaxAge();
//删选出符合条件的员工
List<SunStaffEntity> staff_list = sunStaffDao.queryByAges(minAge, maxAge);
//将符合条件的员工存入结果集map中
map.put(i, staff_list);
page.add(map);
}
return page;
}
是通过在数据库中建了一张表,通过查询这个表来获取每次分组的条件。
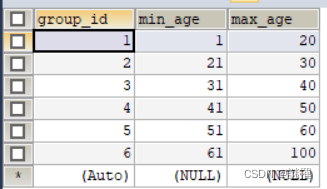
但是很快便意识到这个方法虽然看着简便但是非常不好:首先增加了数据库的压力,每次循环都会查询数据库;其次数据库中存放的应该是信息而不是条件,这张表的并没有很大的意义。
方法二
这是我第二次使用集合和循环实现的方法:(在这里获取员工信息时我还是使用了之前定义的范围查询的方法)
public List<Map> showGroups() {
//获取所有员工的信息
List<SunStaffEntity> staff_list = sunStaffDao.queryByAges(1, 100);
//最终结果的集合对象
List<Map> page = new ArrayList<>();
//使用map集合来存储各组对应的年龄信息
Map<Integer, List<SunStaffEntity>> map = new HashMap();
//获取每组的年龄信息
List<SunStaffEntity> listOfAge1 = new ArrayList<>();
List<SunStaffEntity> listOfAge2 = new ArrayList<>();
List<SunStaffEntity> listOfAge3 = new ArrayList<>();
List<SunStaffEntity> listOfAge4 = new ArrayList<>();
List<SunStaffEntity> listOfAge5 = new ArrayList<>();
List<SunStaffEntity> listOfAge6 = new ArrayList<>();
//遍历年龄的集合,将所有不重复的年龄进行分组
for (SunStaffEntity staff : staff_list) {
if (staff.getAge() > 1 && staff.getAge() <= 20) {
//存入第一组的员工信息
listOfAge1.add(staff);
} else if (staff.getAge() > 20 && staff.getAge() <= 30) {
listOfAge2.add(staff);
} else if (staff.getAge() > 30 && staff.getAge() <= 40) {
listOfAge3.add(staff);
} else if (staff.getAge() > 40 && staff.getAge() <= 50) {
listOfAge4.add(staff);
} else if (staff.getAge() > 50 && staff.getAge() <= 60) {
listOfAge5.add(staff);
} else {
listOfAge6.add(staff);
}
}
map.put(1, listOfAge1);
map.put(2, listOfAge2);
map.put(3, listOfAge3);
map.put(4, listOfAge4);
map.put(5, listOfAge5);
map.put(6, listOfAge6);
page.add(map);
return page;
}
这个方法是可以实现的,只是代码看着并不美观;其次是这样的方法只适用于显示基本的一些信息,当需要显示更多其它附属的信息时就显得比较乏力,所以又有了第三种方法。
方法三
其实这个方法和第二种基本没有区别,代码也不美观,这里就不做优化了,主要实现这个思路,变化的地方是将Map集合换成了一个自定义的类(此处是Result),这样就方便我们对数据进行分层和额外展示我们需要的其他信息:
public List<Result> showGroup3() {
//最终结果的集合对象
List<Result> page = new ArrayList<>();
//获取所有员工的信息
List<SunStaffEntity> staff_list = sunStaffDao.queryByAges(1, 100);
//获取每组的年龄信息
List<SunStaffEntity> listOfStaff1 = new ArrayList<>();
List<SunStaffEntity> listOfStaff2 = new ArrayList<>();
List<SunStaffEntity> listOfStaff3 = new ArrayList<>();
List<SunStaffEntity> listOfStaff4 = new ArrayList<>();
List<SunStaffEntity> listOfStaff5 = new ArrayList<>();
List<SunStaffEntity> listOfStaff6 = new ArrayList<>();
//遍历map的key
for (SunStaffEntity staff : staff_list) {
staff.setGroupId(Math.toIntExact((staff.getStaffId())));
if (staff.getAge() > 1 && staff.getAge() <= 20) {
listOfStaff1.add(staff);
// staff.setGroupId(1);
} else if (staff.getAge() > 20 && staff.getAge() <= 30) {
listOfStaff2.add(staff);
// staff.setGroupId(2);
} else if (staff.getAge() > 30 && staff.getAge() <= 40) {
listOfStaff3.add(staff);
// staff.setGroupId(3);
} else if (staff.getAge() > 40 && staff.getAge() <= 50) {
listOfStaff4.add(staff);
// staff.setGroupId(4);
} else if (staff.getAge() > 50 && staff.getAge() <= 60) {
listOfStaff5.add(staff);
// staff.setGroupId(5);
} else {
listOfStaff6.add(staff);
// staff.setGroupId(6);
}
}
Result result1 = new Result(101, listOfStaff1);
Result result2 = new Result(102, listOfStaff2);
Result result3 = new Result(103, listOfStaff3);
Result result4 = new Result(104, listOfStaff4);
Result result5 = new Result(105, listOfStaff5);
Result result6 = new Result(106, listOfStaff6);
page.add(result1);
page.add(result2);
page.add(result3);
page.add(result4);
page.add(result5);
page.add(result6);
return page;
}
总结
三个方法都很简单,第一个方法是对数据库使用不当所以直接弃用,另外两个方法主要是体现集合的使用和对数据的一个分层。自定义的类可以提高对数据展示的灵活性。















 9357
9357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









