







1. llama factory shell 脚本的参数有哪些?
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
### method
stage: pt
do_train: true
finetuning_type: lora
lora_target: q_proj,v_proj
### dataset
dataset: c4_demo
cutoff_len: 1024
max_samples: 1000
overwrite_cache: true
preprocessing_num_workers: 16
### output
output_dir: saves/llama3-8b/lora/sft
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
### train
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 0.0001
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_steps: 0.1
fp16: true
### eval
val_size: 0.1
per_device_eval_batch_size: 1
evaluation_strategy: steps
eval_steps: 500有一个问题:就是为什么这里的finetuning_type: lora还是取值为lora,
pretrain 和 sft 的区别是:
sft是基于指令的 {"input":content, "instruction":content, "output": content}这样的数据格式
pt: 是自回归的任务{"text":content} 这样的文本即可 需要自己的数据进行领域知识的注入, 继续预训练和从零开始预训练在本质上是没有区别的,只不过一个是随机初始化参数 一个不是随机初始化参数
2. 代码阅读
主要分为三个部分pt的代码 sft的代码 和 ppo部分的代码
通用部分: 无论是 pt. sft. ppo 或者其他的 都需要进行这一步参数的获取
i). 参数获取
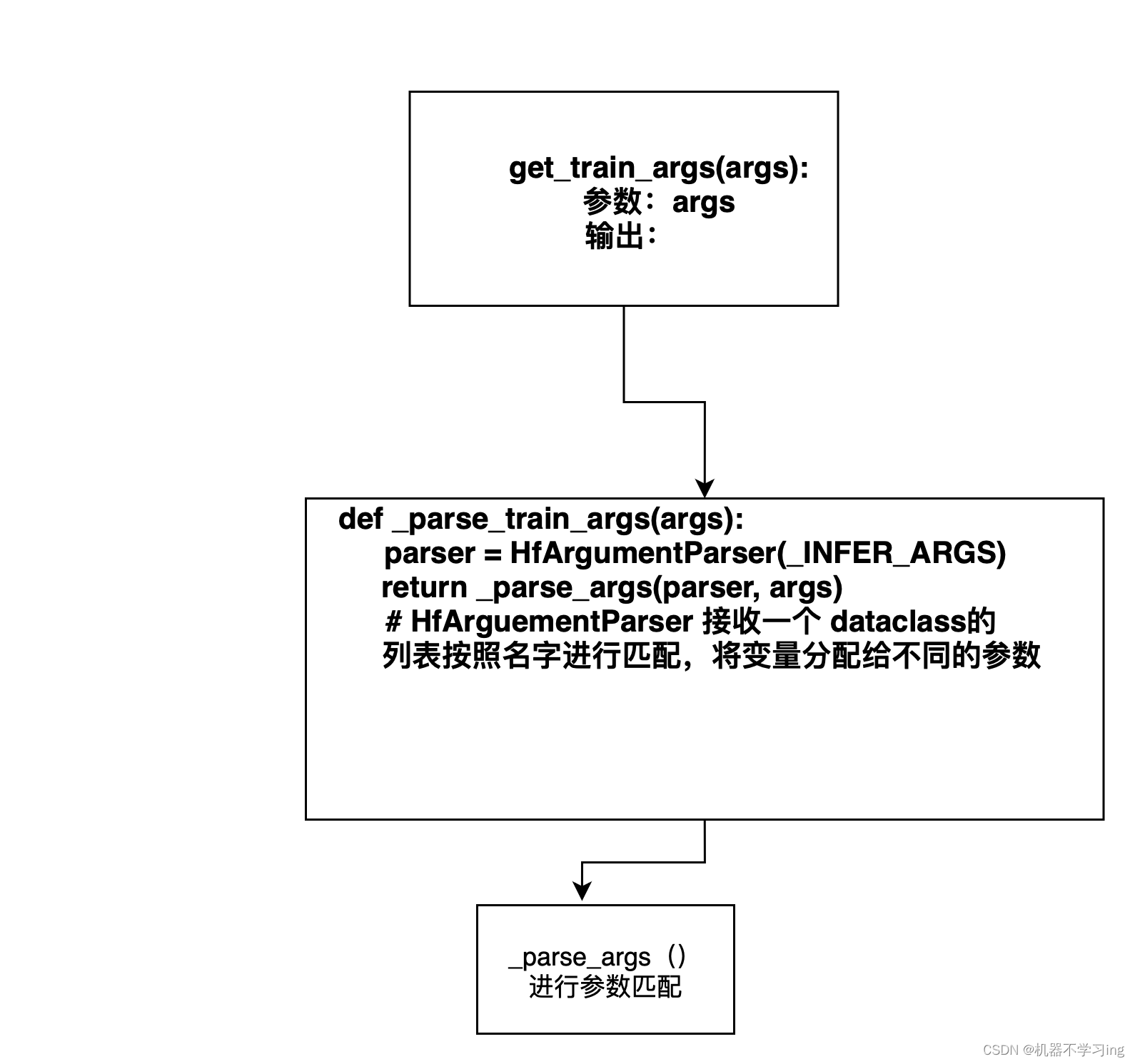
参数获取到的主要流程:
get_train_args(args):
# 接收 args(来自命令行,或者yaml,json 这样的配置文件) 通过 调用_parse_train_args 进行参数的分配
# 因为返回值是一个元组所以需要多个值进行接收
model_args, data_args, training_args, finetuning_args, generating_args = _parse_train_args(args)
# _parse_train_args(args) 中主要如下:parser = HfArgumentParser(_TRAIN_ARGS)
def _parse_train_args(args: Optional[Dict[str, Any]] = None) -> _TRAIN_CLS:
parser = HfArgumentParser(_TRAIN_ARGS) # _TRAIN_ARGS 是一个超参数 在整个文件中都是可见的
# # _TRAIN_ARGS_ 是一些 arguement的类 组成的list 会根据名字把参数分配到不同的 dataclass 中 所以是parser是一个不同的dataclass子类的实例化对象
return _parse_args(parser, args) # _parse_args 会返回参数,和parser对应 和前面的 mdoel_args, data_args 等对应最后 get_train_args() 会返回一些和训练相关的参数:四部分如下:
model_args, data_args, training_args, finetuning_args, generating_args
根据不同的参数决定是哪一个微调或者继续预训练
def run_exp(args: Optional[Dict[str, Any]] = None, callbacks: List["TrainerCallback"] = []) -> None:
model_args, data_args, training_args, finetuning_args, generating_args = get_train_args(args)
# get_train_args(args) 得到和训练相关的一些 参数
callbacks.append(LogCallback(training_args.output_dir))
# 这个 是一个 list 内部元素是 TrainerCallback 默认值是空的
# TrainerCallback:
# 定制训练过程:允许用户在训练的不同阶段执行自定义的操作,例如记录日志、动态调整学习率、保存模型等。
# 与 Trainer 类交互:可以访问和修改与训练相关的状态信息,如当前的训练步骤、metrics 的更新等。
# 在进行下面的阶段的时候需要有上面的参数
if finetuning_args.stage == "pt":
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1209
1209

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









