






本地环境:cuda 11.7 torch2.1.0
项目文件结构:
1. 项目文件结构:
如果利用Llama Factory 进行微调主要会用到 LLama-Factory/src 中的文件
2. src 下的目录结构
本地推理的demo
通过api.py 进行 LLaMa-Factory 项目文件下运行,会有一个 web的demo
(可能需要修改 gradio 下面一个包的权限,创建一个公共的端口就可以)
CUDA_VISIBLE_DEVICES=1 python src/api.py --model_name_or_path LLama/Llama3-8B-Chinese-Chat --template llama3 我运行之后打不开 网址 所以 根据之前的 为了简单起见 还是用 cli_demo.py 放在 src 路径下
from llamafactory.chat import ChatModel
from llamafactory.extras.misc import torch_gc
try:
import platform
if platform.system() != "Windows":
import readline # noqa: F401
except ImportError:
print("Install `readline` for a better experience.")
def main():
chat_model = ChatModel()
messages = []
print("Welcome to the CLI application, use `clear` to remove the history, use `exit` to exit the application.")
while True:
try:
query = input("\nUser: ")
except UnicodeDecodeError:
print("Detected decoding error at the inputs, please set the terminal encoding to utf-8.")
continue
except Exception:
raise
if query.strip() == "exit":
break
if query.strip() == "clear":
messages = []
torch_gc()
print("History has been removed.")
continue
messages.append({"role": "user", "content": query})
print("Assistant: ", end="", flush=True)
response = ""
for new_text in chat_model.stream_chat(messages):
print(new_text, end="", flush=True)
response += new_text
print()
messages.append({"role": "assistant", "content": response})
if __name__ == "__main__":
main()CUDA_VISIBLE_DEVICES=0 python src/cli_demo.py --model_name_or_path 自己模型地址 --template 和模型有关(看github 的 readme)遇到的问题:如果torch的版本低会有一个 BFloat16 的问题(开始是 2.0.1 报错了)
升级成 2.1.0 就好了
pytorch 官网 2.1.0 应该最低是cuda11.8 的 直接升级成这个就行 conda install 速度会快一些
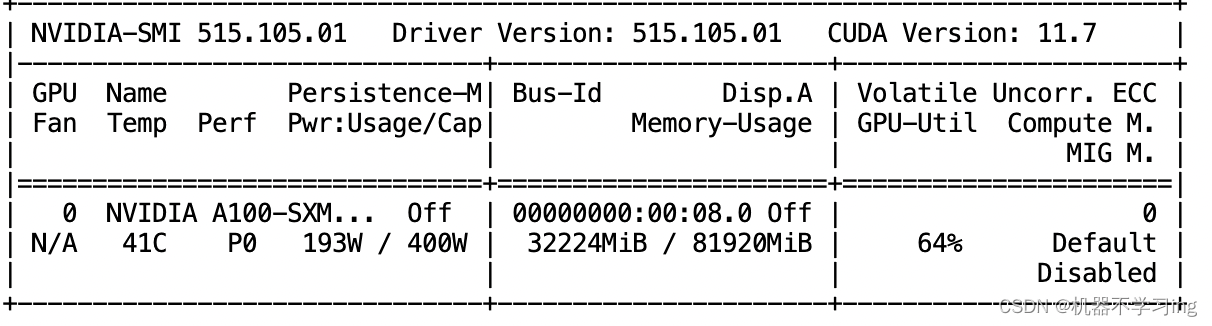

可以在命令行进行展示:效果如下:

============= 以上是 2024.05.29 的 最新 LLaMa Factory 版本 =====================
本地微调:
再进行微调的时,主要就是 运行train.py 这个文件,但是需要指定一些参数 比如模型路径 数据集 微调方式等
train.py 内容
from llamafactory.train.tuner import run_exp
def main():
run_exp()
def _mp_fn(index):
# For xla_spawn (TPUs)
run_exp()
if __name__ == "__main__":
main()
可以看到 train.py 就是用到了 llamafactory.train.tuner ,所以进一步看一下 llamafactory 文件的目录结构
llamafactory/train 的 结构:
tuner.py 内容如下:python 相对导入:python 相对导入-CSDN博客
from typing import TYPE_CHECKING, Any, Dict, List, Optional
import torch
from transformers import PreTrainedModel
from ..data import get_template_and_fix_tokenizer
from ..extras.callbacks import LogCallback
from ..extras.logging import get_logger
from ..hparams import get_infer_args, get_train_args
from ..model import load_model, load_tokenizer
from .dpo import run_dpo
from .kto import run_kto
from .ppo import run_ppo
from .pt import run_pt
from .rm import run_rm
from .sft import run_sft
if TYPE_CHECKING:
from transformers import TrainerCallback
logger = get_logger(__name__)
def run_exp(args: Optional[Dict[str, Any]] = None, callbacks: List["TrainerCallback"] = []) -> None:
model_args, data_args, training_args, finetuning_args, generating_args = get_train_args(args)
callbacks.append(LogCallback(training_args.output_dir))
if finetuning_args.stage == "pt":
run_pt(model_args, data_args, training_args, finetuning_args, callbacks)
elif finetuning_args.stage == "sft":
run_sft(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
elif finetuning_args.stage == "rm":
run_rm(model_args, data_args, training_args, finetuning_args, callbacks)
elif finetuning_args.stage == "ppo":
run_ppo(model_args, data_args, training_args, finetuning_args, generating_args, callbacks)
elif finetuning_args.stage == "dpo":
run_dpo(model_args, data_args, training_args, finetuning_args, callbacks)
elif finetuning_args.stage == "kto":
run_kto(model_args, data_args, training_args, finetuning_args, callbacks)
else:
raise ValueError("Unknown task.")
def export_model(args: Optional[Dict[str, Any]] = None) -> None:
model_args, data_args, finetuning_args, _ = get_infer_args(args)
if model_args.export_dir is None:
raise ValueError("Please specify `export_dir` to save model.")
if model_args.adapter_name_or_path is not None and model_args.export_quantization_bit is not None:
raise ValueError("Please merge adapters before quantizing the model.")
tokenizer_module = load_tokenizer(model_args)
tokenizer = tokenizer_module["tokenizer"]
processor = tokenizer_module["processor"]
get_template_and_fix_tokenizer(tokenizer, data_args.template)
model = load_model(tokenizer, model_args, finetuning_args) # must after fixing tokenizer to resize vocab
if getattr(model, "quantization_method", None) and model_args.adapter_name_or_path is not None:
raise ValueError("Cannot merge adapters to a quantized model.")
if not isinstance(model, PreTrainedModel):
raise ValueError("The model is not a `PreTrainedModel`, export aborted.")
if getattr(model, "quantization_method", None) is None: # cannot convert dtype of a quantized model
output_dtype = getattr(model.config, "torch_dtype", torch.float16)
setattr(model.config, "torch_dtype", output_dtype)
model = model.to(output_dtype)
else:
setattr(model.config, "torch_dtype", torch.float16)
model.save_pretrained(
save_directory=model_args.export_dir,
max_shard_size="{}GB".format(model_args.export_size),
safe_serialization=(not model_args.export_legacy_format),
)
if model_args.export_hub_model_id is not None:
model.push_to_hub(
model_args.export_hub_model_id,
token=model_args.hf_hub_token,
max_shard_size="{}GB".format(model_args.export_size),
safe_serialization=(not model_args.export_legacy_format),
)
try:
tokenizer.padding_side = "left" # restore padding side
tokenizer.init_kwargs["padding_side"] = "left"
tokenizer.save_pretrained(model_args.export_dir)
if model_args.export_hub_model_id is not None:
tokenizer.push_to_hub(model_args.export_hub_model_id, token=model_args.hf_hub_token)
if model_args.visual_inputs and processor is not None:
getattr(processor, "image_processor").save_pretrained(model_args.export_dir)
if model_args.export_hub_model_id is not None:
getattr(processor, "image_processor").push_to_hub(
model_args.export_hub_model_id, token=model_args.hf_hub_token
)
except Exception:
logger.warning("Cannot save tokenizer, please copy the files manually.")
可以看到 包含两个函数:
1. run_exp() 根据传入参数的不同选择不同的方式
2. export_model: 将原来的模型和微调之后的checkpoint 进行合并
到这里就基本上完成了 流程上的梳理 具体的微调方法需要到每个函数内部自行查看
======================= 以上 2024/05/27 ========================
怎么finetuning起来?
写一个脚本 train.sh ,放在 llama-factory 根目录下:终端运行 bash train.sh 即可
CUDA_VISIBLE_DEVICES=0 python src/train.py \
--stage sft \
--do_train True \
--model_name_or_path 自己模型的路径\
--finetuning_type lora \
--template default \
--flash_attn auto \
--dataset_dir data \
--dataset 自己的数据集\
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 1.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--report_to none \
--output_dir 模型微调完成之后adapter的输出位置 \
--fp16 True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target q_proj,v_proj \
--plot_loss True具体的参数 batch_size ,lora_rank 需自行确定
推理:
CUDA_VISIBLE_DEVICES=0 python src/cli_demo.py
--model_name_or_path 模型地址
--adapter_name_or_path 训练出来的适配器的位置
--template 提示词模版和模型相关即可成功 !
注:暂时没用 vllm 框架,用的话可能问题较多















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









