






机器学习是从数据中自动分析获得模型,并利用模型对未知数据进行预测
一、概述
1. 数据集构成
结构:特征值 + 目标值
注:
- 对于每一行数据我们可以称为样本。
- 有些数据集可以没有目标值
行:样本,列:特征值
2. 机器学习算法分类
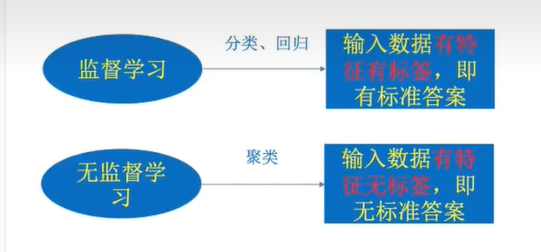
监督学习(预测) 有目标值
-
定义:输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称为回归),或是输出是有限个离散值(称作分类)
-
分类:k-近邻算法、贝叶斯分类、决策树与随机森林、逻辑回归
-
回归:线性回归、岭回归
-
分类问题
特征值:猫狗的图片;目标值:猫/狗 ——类别
-
回归问题
特征值:房屋的各个属性信息(楼层、朝向、位置区域……);目标值:房屋价格——连续型数据
-
无监督学习 无目标值
-
定义:输入数据是由输入特征值所组成
-
聚类 k-means
特征值:人物的各个属性信息;目标值:无
3. 机器学习开发流程
- 获取数据
- 数据处理
- 特征工程
- 机器学习算法训练 - 模型
- 模型评估
- 应用
二、sklearn数据集

1. scikit-learn数据集API介绍
- sklearn.datasets
- 加载获取流行数据集
- datasets.load_*()
- 获取小规模数据集,数据包含在datasets里
- datasets.fetch_*(data_home=None)
- 取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是~/scikit_learn_data/
2. sklearn小数据集
- sklearn.datasets.load_iri()
加载并返回鸢尾花数据集
| 名称 | 数量 |
|---|---|
| 类别 | 3 |
| 特征 | 4 |
| 样本数量 | 150 |
| 每个类别数量 | 50 |
- sklearn.datasets.load_boston()
加载并返回波士顿房价数据集
| 名称 | 数量 |
|---|---|
| 目标类别 | 5-50 |
| 特征 | 13 |
| 样本数量 | 506 |
3. sklearn大数据集
- sklearn.datasets.fetch_20newsgroups(data_home=None, subset=‘train’)
- subset: ‘train’ 或者 ‘test’, ‘all’ ,可选,选择要加载的数据集
- 训练集的“训练”,测试集的“测试,两都的”全部“
4. sklearn数据集的使用
-
以鸢尾花数据集为例:
-
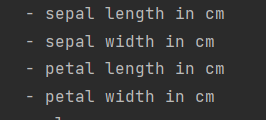
特征值—4个 :花瓣、花萼的长度、宽度
-
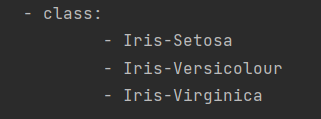
目标值—3个:setosa,vericolor,virginica
-
-
load 和 fetch 返回的数据类型 datasets.base.Bunch(继承自字典)
- data: 特征值,特征数据数组,是 [n_samples * n_features] 的二维 numpy.ndarray 数组
- target: 目标值,标签数组,是 n_samples 的一维 numpy.ndarray 数组
- DESCR: 数据描述
- feature_names: 特征名,新闻数据,手写数字,回归数据集没有
- target_names: 标签名
5. 数据集的划分
拿到的数据不能全部用来训练一个模型。因此会划分数据集。
机器学习一般的数据集会划分为两个部分:
- 训练数据(train):用于训练,构建模型
- 测试数据(test):在模型检验时使用,用于评估模型是否有效
划分比例:
- 训练集:70%—80%
- 测试集:20%—30%
数据集划分api
- sklearn.model_selection.train_test_split(arrays, *options)
- x 数据集的特征值
- y 数据集的标签值/目标值
- test_size 测试集的大小,一般为 float
- random_state 随机数种子,不同的种子会造成不同的随机采样结果。相同的种子采样结果相同
- return 训练集特征值,测试集特征值,训练集目标集,测试集目标集
三、特征工程介绍
吴恩达:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”
特征工程是使用专业背景知识和技巧处理数据,使得特征能在机器学习算法上发挥更好的作用的过程。
- 意义:会直接影响机器学习的效果
pandas:一个数据读取非常方便以及基本的处理格式的工具,用于数据清洗、数据处理
sklearn:对于特征的处理提供了强大的接口
特征工程内容包含:
- 特征抽取/特征提取
- 特征预处理
- 特征降维
四、特征抽取/特征提取
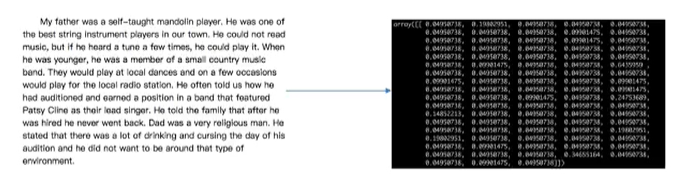
机器学习算法——统计方法——数学公式
文本类型/其他类型 转换为 数值

1. 特征提取
将任意数据(如文本或图像)转换为可用于机器学习的数字特征
注:特征值化是为了计算机更好的去理解数据
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习将介绍)
2. 特征提取api
sklearn.feature_extraction
3. 字典特征提取
作用:对字典数据进行特征值化
sklearn.feature_extraction.DictVectorizer(sparse=True,…)
# 默认sparse为True,即显示为稀疏矩阵。
# sparse=False 显示为二维矩阵 DictVectorizer(sparse=False)
vector:数学中是向量,物理中是矢量。在计算机中以一维数组存储。
matrix:矩阵。矩阵是向量组,所以每行每列都是向量。在计算机中以二维数组存储
类别 -> one-hot 编码

父类:转换器
-
DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器返回 sparse 矩阵
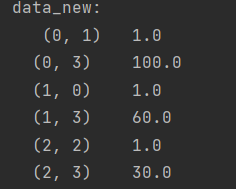
- 稀疏矩阵 - 将非零值按位置表示出来(以元组形式),可以节省内存,提高加载效率
sparse:稀疏
data = [ {'city': '北京', 'temperature': 100}, # 100 {'city': '上海', 'temperature': 60}, # 010 {'city': '深圳', 'temperature': 30}, # 001 ]
-
DictVectorizer.inverse_transform(X) X:array 数组或者 sparse 矩阵 返回值:转换之前数据格式
-
DictVectorizer.get_feature_names() 返回类别名称
总结:对于特征当中存在类别信息的我们都会做 one-hot 编码处理
应用场景
- 数据集当中类别特征比较多
- 将数据集特征转换为字典类型
- DictVectorizer转换
- 本身拿到的数据就是字典类型
4. 文本特征提取
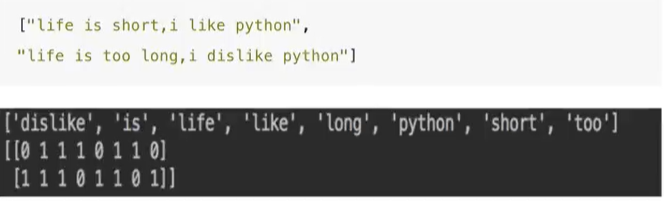
统计每个特征词出现的次数
句子、短语、单词、字母。选择单词作为特征。
特征:特征词(即,单词)
作用:对文本数据进行特征值化
- **sklearn.feature_extraction.text.CountVectorizer(stop_words=[]) **
- 返回词频矩阵,stop_words 停用词列表,表示没什么用,就不做特征词了,可以到网上找停用词表
- CountVectorizer.fit_transform(X) X: 文本或者包含文本字符串的可迭代对象 返回值:返回 sparse 矩阵
- CountVectorizer.inverse_transform(X) X: array 数组或者 sparse 矩阵 返回值:转换之前数据格
- CountVectorizer.get_feature_names() 返回值:单词列表
- sklearn.feature_extraction.text.TfidfVectorizer
将字母以及标点符号不作为最终的特征词列表
不支持使用sparse=False调整为稀疏矩阵。可使用toarray()方法调整。
中文需要以空格将文字隔开。使用jieba库,jieba.cut(字符串)
5. Tf-idf文本特征提取
TF_IDF 表示重要程度
关键词:在某一个类别的文章中,出现的次数很多,但是在其他类别的文章当中出现很少
- TF-IDF 的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或短语具有很好的类别区分能力,适合用来分类
- TF-IDF 作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度
公式
-
词频(term frequency, tf)指的是某一个给定的词语在该文件中出现的频率
-
逆向文档频率(inverse document frequency, idf)是一个词语普通重要性的度量。某一特定词语的 idf, 可以由总文件数目除以包含词语之文件的数目,再将得到的商取以 10 为底的对数得到
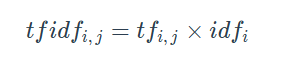
例子
- 有两个词“经济”、“非常” ,有 1000 篇文章的 语料库,其中 100 篇文章有“非常”,10 篇文章有“经济”
- 有两篇文章,文章 A(100 词):10 次“经济”
- tf: 10 / 100 = 0.1
- idf: lg 1000/10 = 2
- TF-IDF: 0.1 * 2 = 0.2
- 文章 B(100 词):10 次“非常”
- tf: 10 / 100 = 0.1
- idf: log 10 1000/100 = 1
- TF-IDF: 0.1 * 1 = 0.1
API
- sklearn.feature_extraction.text.TfidfVectorizer(stop_words=None,…)
重要性:分类机器学习算法进行文章分类中前期数据处理方式
五、特征预处理
- 目标
- 了解数值型数据、类别型数据特点
- 应用MinMaxScaler实现对特征数据进行归一化
- 应用StandardScaler实现对特征数据进行标准化
定义:通过一些转换函数将特征数据转换成更加适合算法模型的特征数据过程
1. 包含内容
- 数值型数据的无量纲化:
- 归一化
- 标准化
2.特征预处理API
sklearn.preprocessing
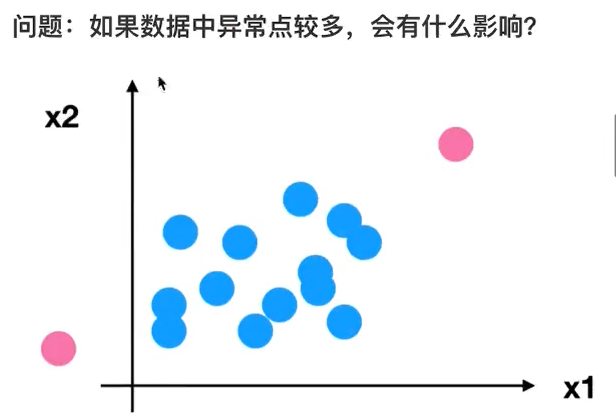
为什么我们要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征。(无量纲化,使不同规格的数据转换到同一规格)
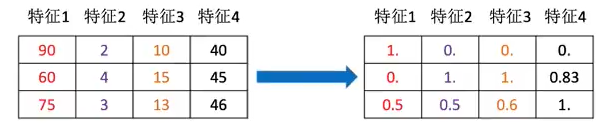
3.归一化
- 定义:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
- 公式:

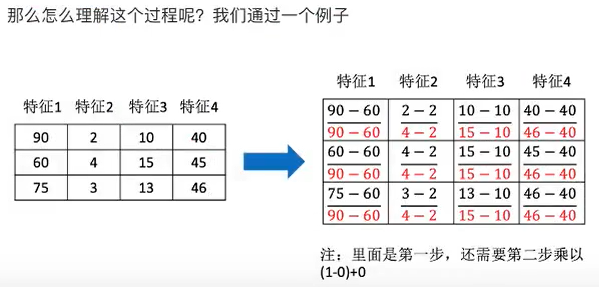
- API
- sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)…)
- feature_range设置区间范围,默认0—1
- MinMaxScalar.fit_transform(X)
- X:numpy_array 格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的 array
- sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)…)
总结:注意最大值最小值是变化的,另外,最大值与最小值非常容易受异常点影响,所以这种方法鲁棒性(健壮性/稳定性)较差,只适合传统精确小数据场景。
4. 标准化
- 定义:通过对原始数据进行变换把数据变换到均值为 0,标准差为 1 范围内
标准差:衡量离散程度或集中程度的
- 公式:
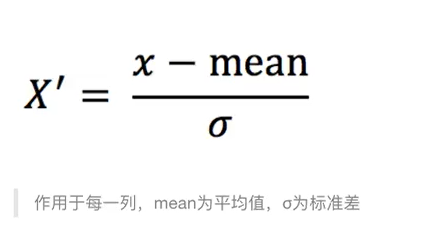
-
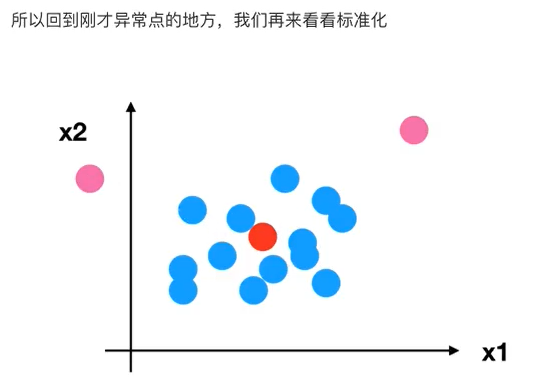
对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
-
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小
-
API
-
sklearn.preprocessing.StandardScaler()
-
处理之后,对每列来说,所有数据都聚集在均值为 0 附近,标准差为 1
-
StandardScaler.fit_transform(X)
- X:numpy array 格式的数据[n_samples,n_features]
-
返回值:转换后的形状相同的 array
-
总结:在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景
六、特征降维
ndarray 维度:嵌套的层数。0维:标量。1维:向量。2维:矩阵。3维……n维
1.降维——降低维度
处理对象:二维数组
定义:降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程
- 降低随机变量的个数
此处的降维,降低的是列数,即降低特征的个数。
效果:特征与特征之间不相关
- 相关特征(correlatedfeature)
- 相对湿度与降雨量之间的相关
- 等等
正是因为在进行训练的时候,我们都是使用特征进行学习。如果特征本身存在问题或者特征之间相关性较强,对于算法学习预测会影响较大
2. 降维的两种方法
- 特征选择
- 主成分分析(可以理解一种特征提取的方式)
3. 特征选择
数据中包含冗余或相关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征

4. 方法
- Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
- 方差选择法:低方差特征过滤
- 相关系数:特征与特征之间的相关程度
- Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)
- 决策树:信息熵、信息增益
- 正则化:L1、L2
- 深度学习:卷积等
5. 模块
sklearn.feature_selection
6. 低方差特征过滤
删除低方差的一些特征。再结合方差的大小来考虑这个方式的角度
- 特征方差小:某个特征很多样本的值比较相近(需要删掉)
- 特征方差大:某个特征很多样本的值都有差别(需要保留)
API
- sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
- 删除所有低方差特征(低于临界值threshold的,全部删掉)
- Variance.fit_transform(X)
- X:numpy array 格式的数据[n_samples,n_features]
- 返回值:训练集差异低于 threshold 的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
7. 相关系数
-
取值:-1 <= r <= +1
-
皮尔逊相关系数(Pearson Correlation Coefficient)
- 反映变量之间相关关系密切程序的统计指标
-
公式:
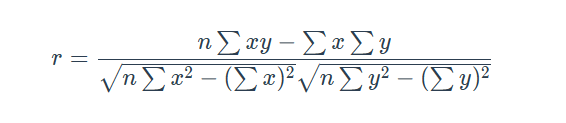
-
特点:相关系数的值介于-1 与+1 之间,即-1 <= r <= +1。其性质如下:
-
当 r>0 时,表示两变量正相关,r<0 时,两变量为负相关
-
正相关:一个变量在增长,另一个变量也在增长。
负相关:一个变量在增长,另一个变量在沿着相反的方向减少
-
当|r|=1 时,表示两变量为完全相关,当 r=0 时,表示两变量间无相关关系
-
当 0<|r|<1 时,表示两变量存在一定程序的相关。且|r|越接近 1,两变量间线性关系越密切;|r|越接近于 0,表示两变量的线性相关越弱
-
一般可按三级划分:|r|<0.4 为低度相关;0.4<=r<0.7 为显著性相关;0.7<=|r|<1 为高度线性相关
-
-
API
- from scipy.stats import pearsonr
- x: (N,) array_like y: (N,) array_like
- Returns: (Pearson’s correlation coefficient, p-value)
- from scipy.stats import pearsonr
特征与特征之间相关性很高:
- 选取其中一个
- 加权求和
- 主成分分析
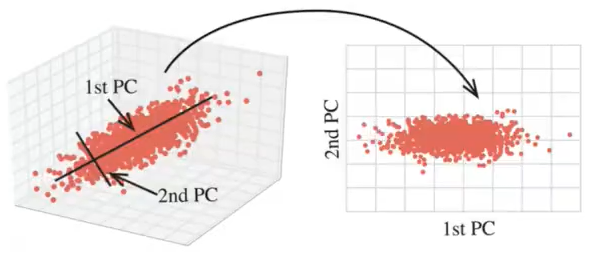
8. 主成分分析PCA
- 定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
- 作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
- 应用:回归分析或者聚类分析
- API
- sklearn.decomposition.PCA(n_components=None)
- 将数据分解为较低维数空间
- n_components:
- 小数:表示保留百分之多少的信息
- 整数:减少到多少特征
- PCA.fit_transform(X) X:numpy array 格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的 array
- sklearn.decomposition.PCA(n_components=None)















 1077
1077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









