






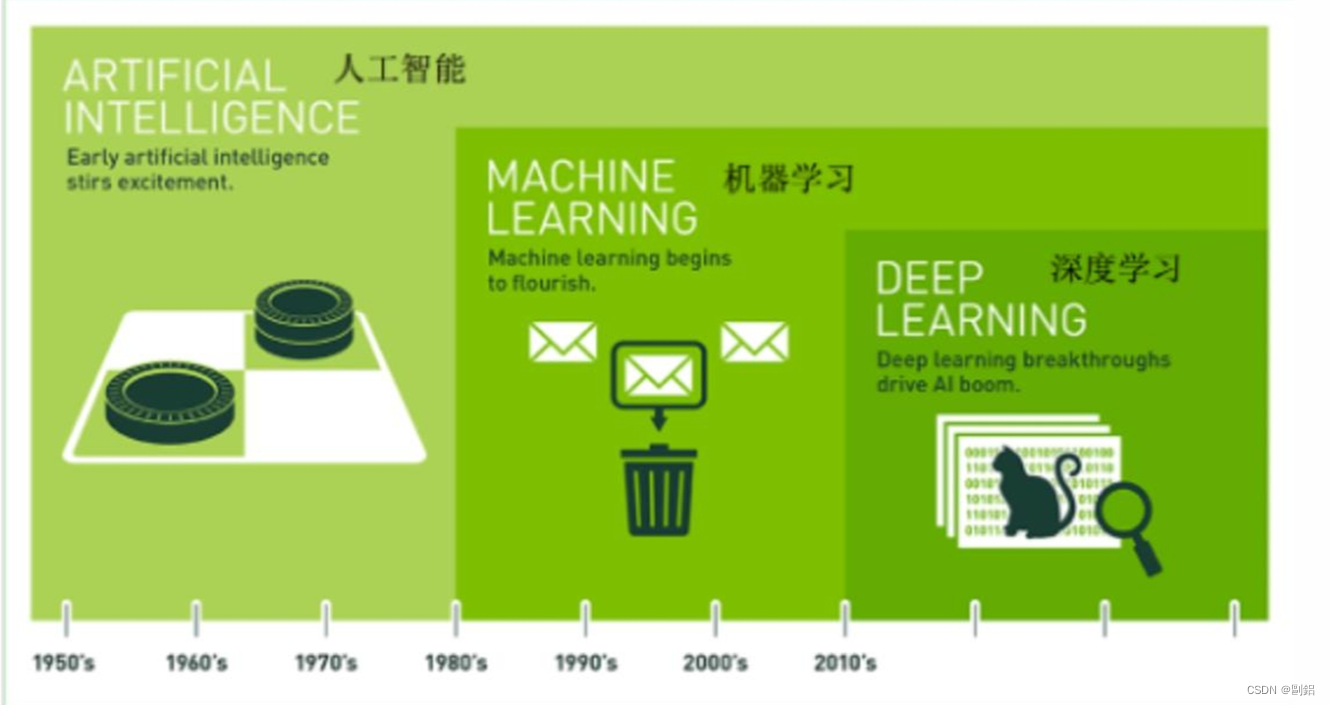
人工智能三大概念及其关系
人工智能(AI):使用计算机来模拟或者代替人类
机器学习(ML):机器自动学习,并不只由人定义规则编程
深度学习(DL):大脑仿生,模拟人大脑神经网络,设计一层层神经元模拟事物
机器学习是实现人工智能的一种途径,深度学习是机器学习的一种更加深入的方法。
机器学习学习方法
基于规则的学习:程序员根据自己经验定义规则
基于模型的学习:由于某些事物,问题无法可以定义明确的规则,如:图片,语音等。这时就要由机器从数据中自动学习出规律
机器学习的应用领域
自然语言处理(NLP):是人工智能和语言学领域的交叉学科,研究能实现人与机器之间用自然语言进行有效通信的各种理论和方法。
计算机视觉(CV):计算机视觉是一门研究如何使机器“看”的科学,它涉及用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉任务,并进一步进行图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像
数据挖掘和数据分析:数据挖掘(Data Mining)是从大量的数据中提取隐藏在其中的、事先不知道的、但潜在有用的信息的过程;数据分析则是指用适当的统计分析方法对收集来的大量数据进行分析,通过汇总、理解和消化数据,以最大化地开发数据的功能并发挥数据的作用。数据分析的目的是提取有用信息并形成结论。
人工智能发展历史
人工智能的发展历史可以追溯到上世纪中叶,经历了多个阶段和重要的里程碑。以下是对人工智能发展历史的简要概述:
- 起源与早期发展(1940s-1950s):
- 1943年,心理学家Warren McCulloch和数学家Walter Pitts提出了第一个神经元模型,为神经网络的发展奠定了基础。
- 1950年,“计算机之父”Alan Turing提出了“图灵测试”,这一测试成为评判一个机器是否具备人类智慧的标准。同年,计算机科学家John McCarthy提出了“人工智能”这个词汇,并组织了首个人工智能会议。
- 推理与专家系统的发展(1950s-1970s):
- 在这一阶段,人工智能主要围绕推理和专家系统展开。专家系统是一种基于规则的人工智能系统,能够利用专家的知识解决特定领域的问题。
- 代表性的专家系统包括DENDRAL系统(用于化学分析)和MYCIN系统(用于诊断感染病)。
- 第一次发展高潮与“AI寒冬”(1960s-1970s):
- 上世纪60年代是人工智能的第一个发展黄金阶段,主要研究领域包括语言翻译和证明等。
- 然而,到了70年代,由于技术和计算机性能的限制,以及人们对人工智能的期望过高,导致了许多项目的失败,人工智能进入了所谓的“AI寒冬”。
- 第二次发展高潮与商业应用(1980s-1990s):
- 经过一段时间的低谷后,人工智能在80年代开始迎来第二次发展高潮。
- 人工智能技术在商业领域取得了巨大的成果,包括语音识别、自然语言处理等技术的应用。
- 平稳发展与新技术融合(1990s至今):
- 90年代以来,随着互联网技术的普及,人工智能逐步发展成为分布式主体,并与其他技术如机器学习、深度学习等融合。
- 进入21世纪,人工智能取得了显著进展,尤其在深度学习、自然语言处理、计算机视觉等领域。
- 当代发展与前沿趋势:
- 人工智能在多个领域都取得了重要突破,包括自动驾驶、医疗诊断、金融分析等。
- 同时,人工智能也面临着一些挑战,如数据隐私、伦理问题和可解释性。
- 最新动态与趋势:
- 最近的报告(如李飞飞团队发布的《2024年人工智能指数报告》)揭示了人工智能行业的最新趋势和进展。
例如,人工智能在某些任务上已超越人类,但并非在所有任务上都如此;产业界在人工智能前沿研究中占据主导地位;模型的训练成本显著增加等。
AI发展三要素
算法:算法是一种解决问题的步骤和规则,是描述在特定输入下如何执行特定任务的有限步骤的有序集合。
算力:算力是指计算设备完成计算任务的能力,可以理解为计算机的计算能力或者数据处理能力。•CPU:主要适合I\O密集型的任务 •GPU:主要适合计算密集型任务 •TPU:专门针对大型网络训练而设计 的一款处理器
数据:数据是收集和记录的事实、观察结果或描述性信息的原始材料,可以是数字、文字、图像、音频等形式。
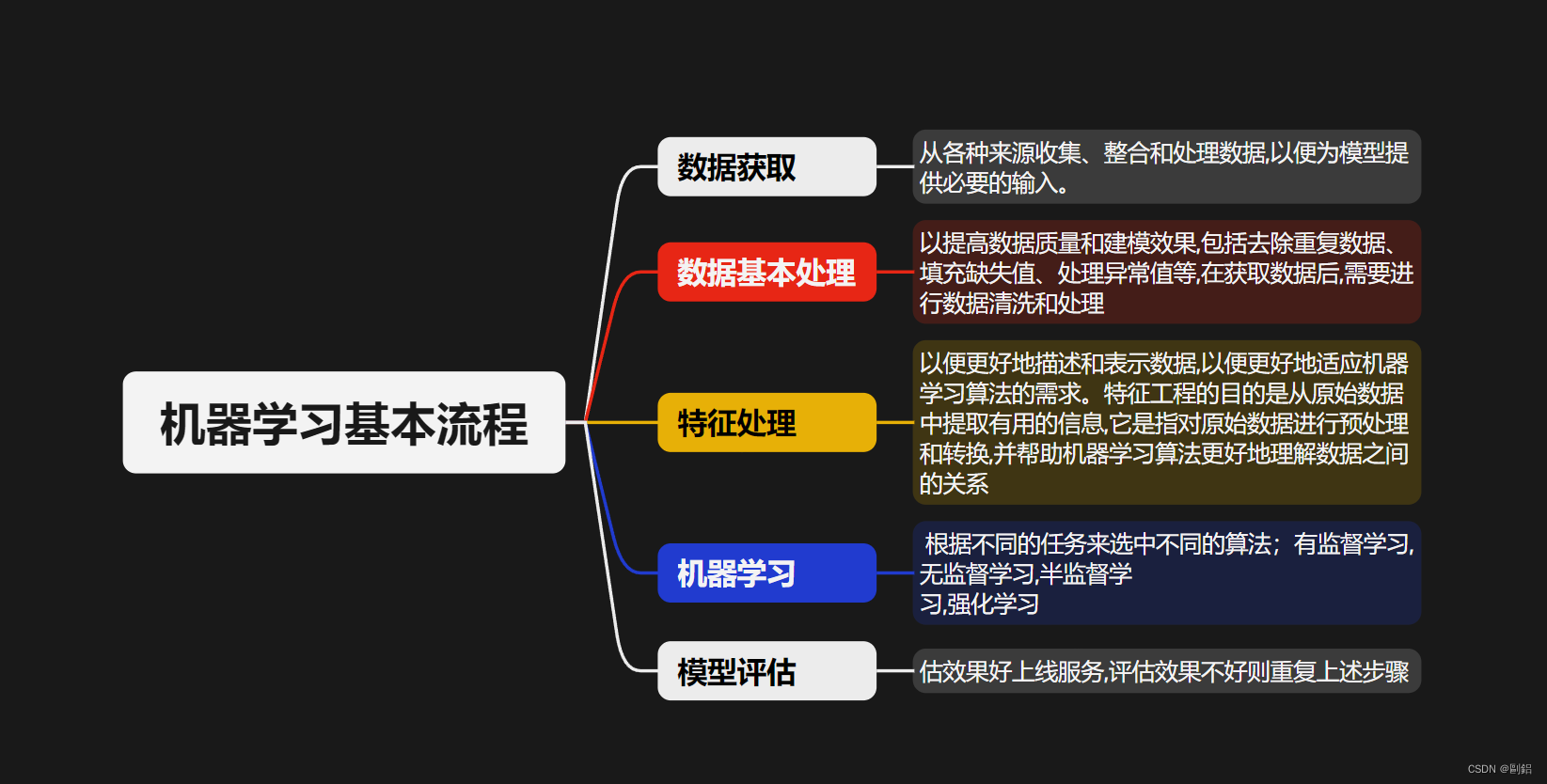
机器学习常用术语
样本
样本是机器学习中的一个基本单位,通常代表一条记录或一个数据点。
特征
特征是用来描述样本的属性或特性的变量。在机器学习中,特征通常被表示为数值或类别值,用于模型学习过程中的输入。
标签
标签是与样本相关联的目标值或输出值。
训练集
训练集是用于训练机器学习模型的数据集。它包含一组带有标签的样本,用于模型学习过程中的参数调整和模型优化。通过训练集,模型能够学习到从特征到标签的映射关系,从而具备预测新样本的能力。
测试集
测试集是用于评估机器学习模型性能的数据集。它同样包含一组带有标签的样本,但与训练集不同,测试集中的样本在模型训练过程中是不可见的。通过将模型应用于测试集,我们可以评估模型在新数据上的表现,从而了解模型的泛化能力和预测准确性
例如:在一个表格中,一行数据就是一个样本;多个样本组成数据集;有时一条样本被叫成一条记录;一列数据一个特征,有时也被称为属性;标签是模型要预测的那一列数据。
机器学习算法分类
有监督学习
在监督学习中,算法通过带有标签的样本进行学习,以预测新数据的输出值或类别。
无监督学习
非监督学习算法处理没有标签的数据,旨在发现数据中的内在结构和模式。常见的非监督学习算法包括聚类算法
半监督
这种学习方式结合了监督学习和非监督学习的特点,处理部分带有标签和部分没有标签的数据。
强化学习
强化学习算法通过与环境的交互来学习,根据反馈信号(奖励或惩罚)来优化决策策略。
主要包含四个元素:Agent(智能体),环境(Environment),行动(Action), 奖励(reward)。















 1063
1063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









