







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
主要讲述yolov8代码的内容,以及修改代码。
文章目录
前言
最近在使用YOLOv8过程中遭遇到了许多bug,现在留下一些记录。方便自己回来查看问题,同时也可以为大家提供帮助。
提示:以下是本篇文章正文内容
一、YOLOv8训练脚本?
代码如下:
下面展示一些 内联代码片。
from ultralytics import YOLO
# Load a model
model = YOLO(model= r'D:\code _vs\yolov8\ultralytics-main\ultralytics\cfg\models\v8\ghost_conv_v8n.yaml') # build a new model from YAML
# Train the model
model.train(data=r'D:\code _vs\yolov8\ultralytics-main\ultralytics\cfg\datasets\ameng_strength.yaml',
epochs=300, imgsz=640,workers=0,device = 'cuda:0',batch = 3,cache = True,pretrained = False,profile = True)
常见的训练方式也是这样,我这里修改了YOLO的配置文件。也正是像大家在改进代码常做的那样,在这种情况下,会出现几个bug。第一个是已经加载过训练的模型,为什么会又在加载一遍。第二个是如何进行迁移学习。第三个是在修改了YOLOv8的默认配置文件的时候,yolov8无法显示模型的Gflops大小。第四个是如何让模型可以选择大小比如 n,s,l,x
二、问题
1.模型多次加载问题
代码如下(示例):
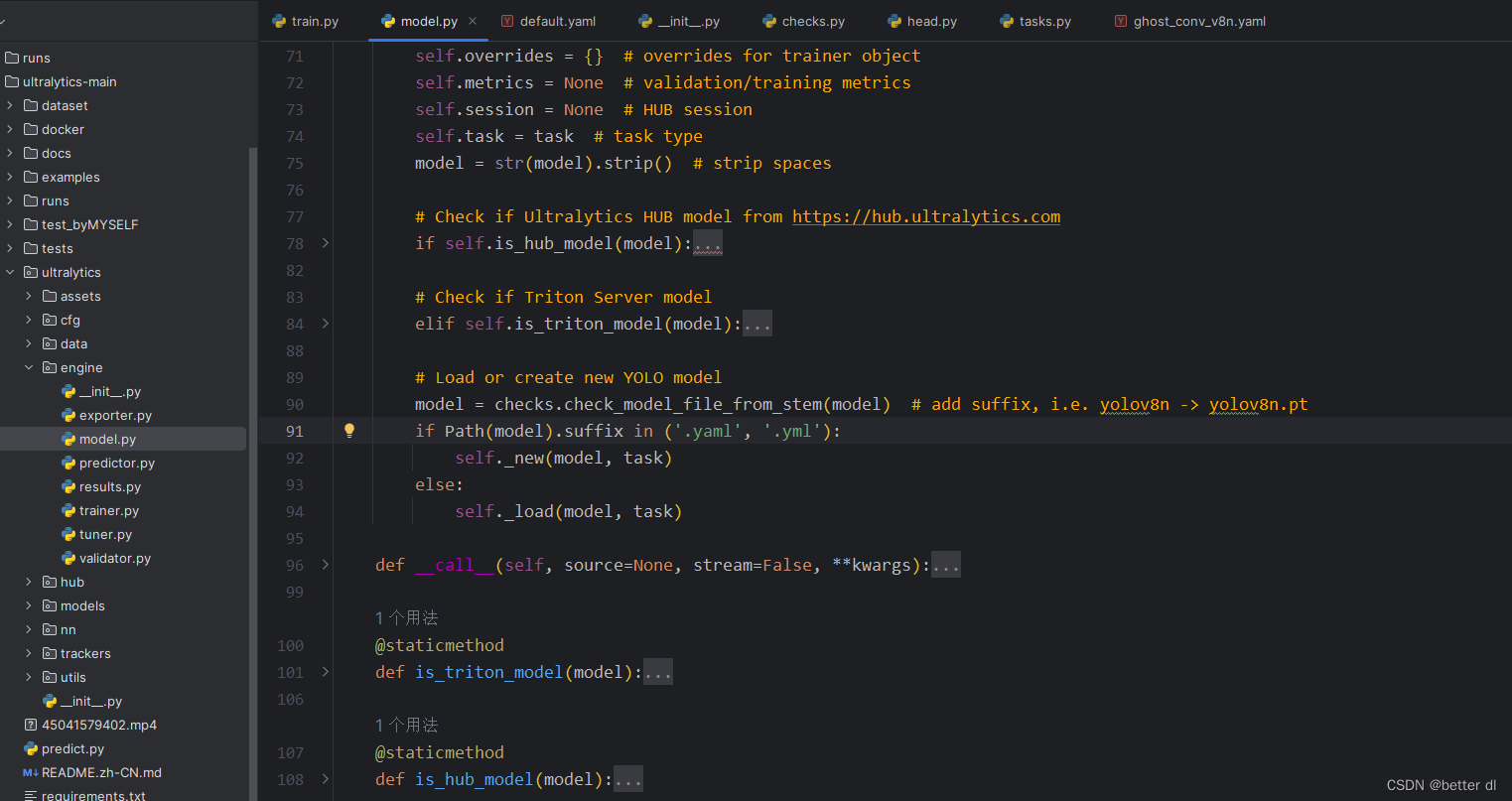
可以看到yolov8在进行调用Model类的时候就已经在初始化的地方对配置文件进行了调用。创造了模型这里的self._new()函数就是对该模型已经完成了建立。顺带提一嘴,yolov8在新建模型的时候是靠yaml文件类型,调用new函数。在重构之前模型时候调用.pt文件。用的是load函数。

这里的new和load就是对模型构建的入口函数。
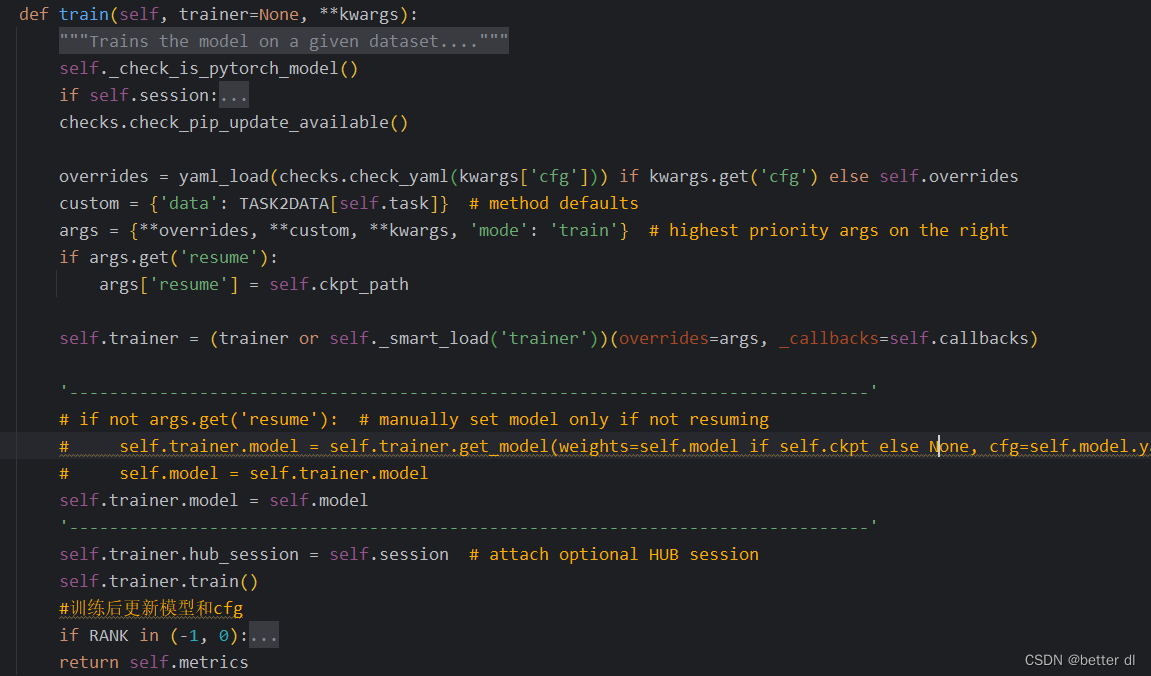
在train函数中又再次调用了这个加载模型的函数,所以我们选择注释他,并且将model传给trainner.model。这样就可以正常运行了。不会出现重复调用的问题。并且也正是因为这个原因导致csdn上的一些博主给的冻结代码是错误的,因为他们只冻结了yolo构建的模型,但是在train的时候又再一次调用new函数,从新构建了一个新的模型。让冻结不起效果,是虚假的冻结。
2.迁移学习
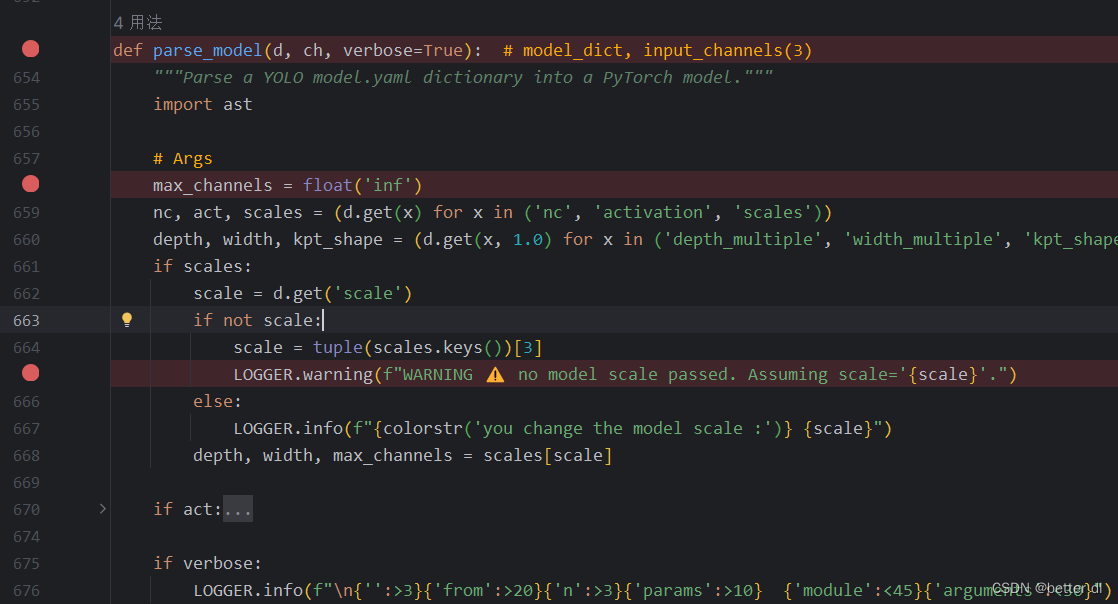
在11月份发布的yolov8中已经具备了对模型层数的冻结功能,可以发现YOLOv8在调用生成模型的时候会重复冻结一些层,比如 d2l中的conv层。在这里我已经删除了 always_freeze_names = [] 这里会永远冻结带有这些这些名称网络层。

同时,我们也经常再冻结一些网络层的时候发现会爆出warning字样,就是elif 这个函数把冻结层置为参数非冻结。
另外大家可以在default.yaml文件里面的freeze层里面去冻结层数。
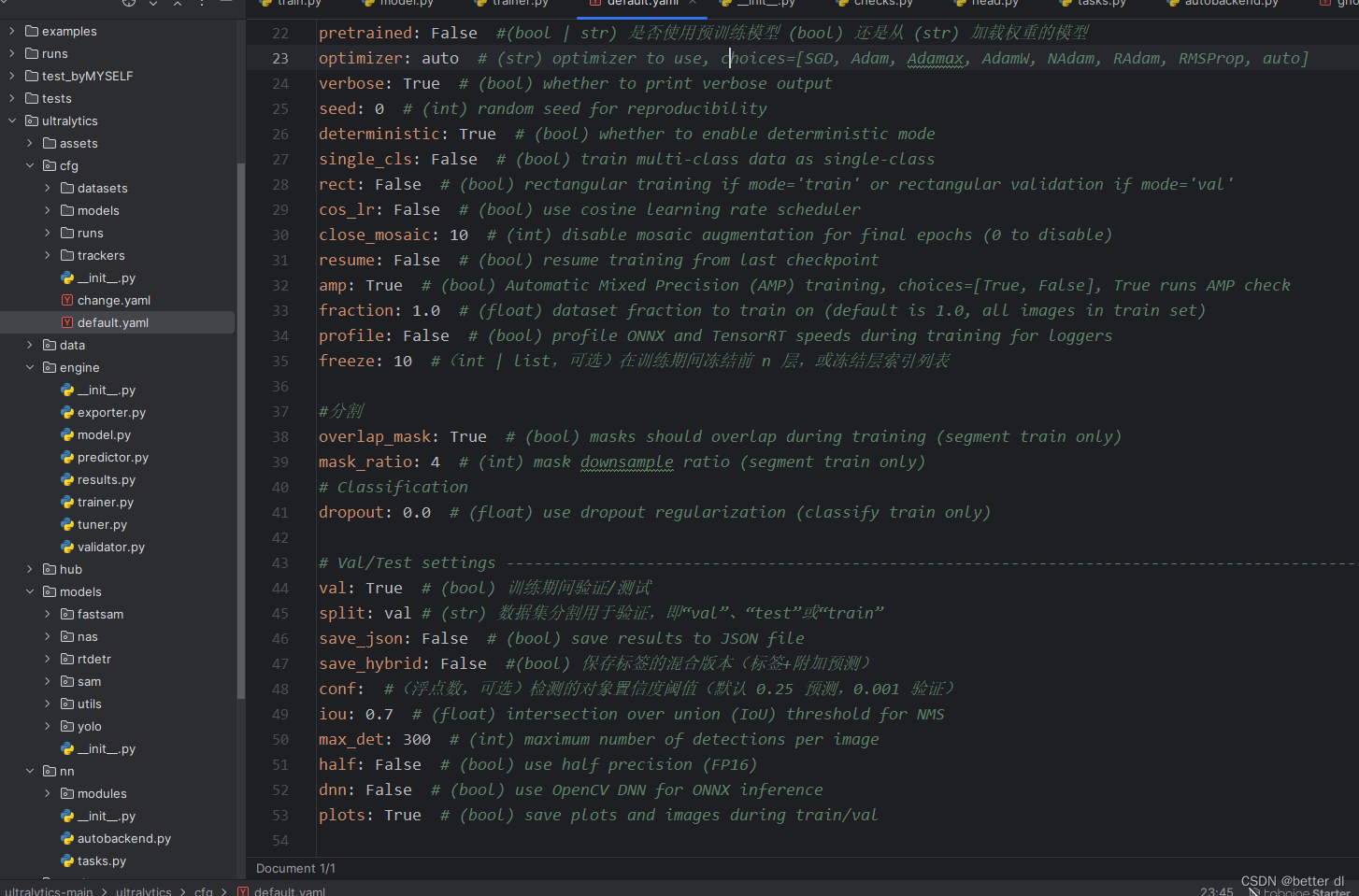
那么我这里是冻结前十层。
3.GFlops问题
这大部分是因为你没有安装一个软件包,
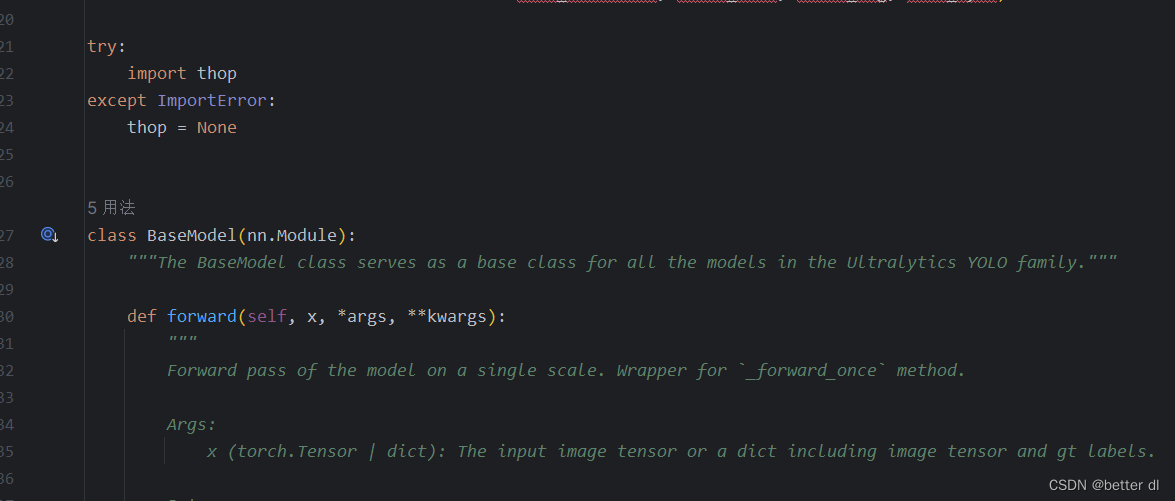
安装了thop就可以解决这个问题。
4、让模型可以选择大小比如 n,s,l,x
我们再替换网络之后发现总是会选择模型最小的作为我们当前模型,这是因为代码会对你传入的模型的文件名做检测。对最后一字母进行检测,如果没有检测到就会默认是最小的。这里大家可以见截图,修改一下就ok了。
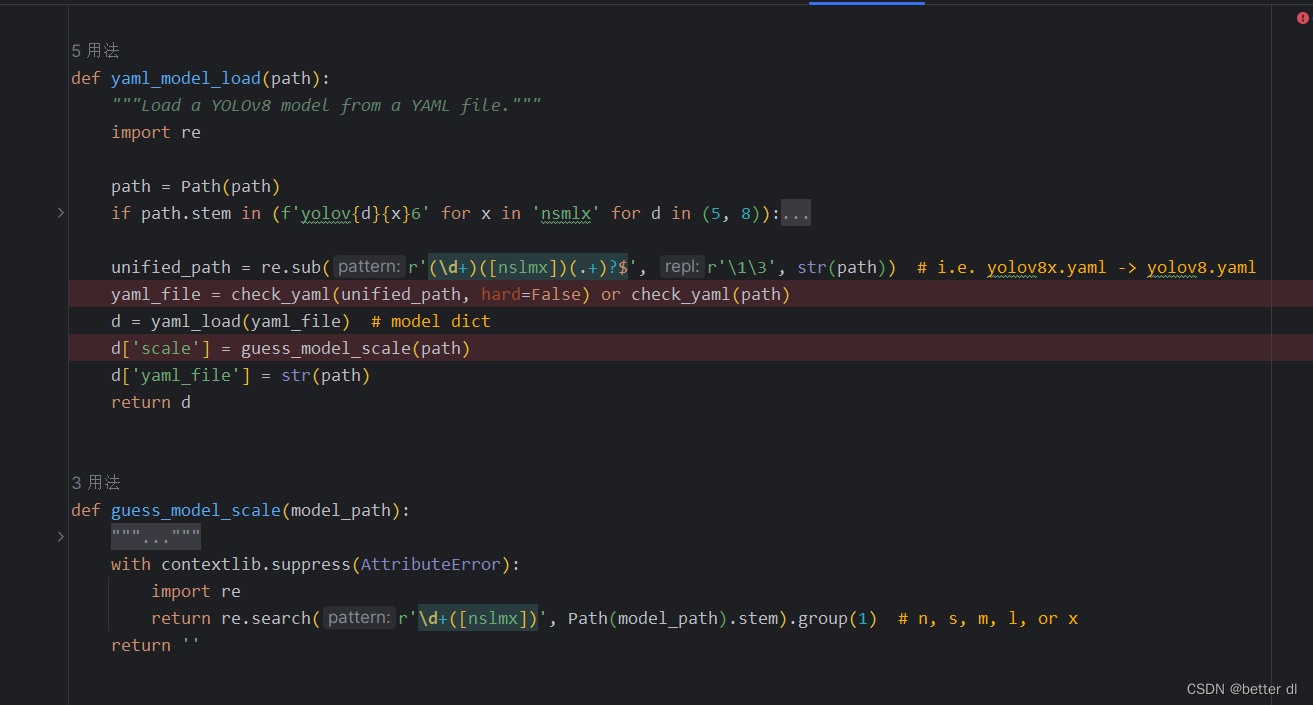
这里的guess_model_scale就是再对模型进行大小的估计,会切分出最后一个字符,大家可以根据自己想要的格式进行正则表达式修改,我这里是寻找数字后第一个的字符作为大小,大家可以模仿我的,也能省去很多麻烦。
或者如果你经常使用一个固定模型,可以scale = tuple(scales.keys())[3],数字代表顺序。
总结
解决了4个比较常见的yolov8模型问题,希望留存给后来者带来方便。
最后给大家看一下,我修改了yolov8中的conv模块为ghostconv。模型确实轻量不少,但是精度也是一言难尽。

确实模型很轻量。只有7.8GFLOPS.模型训练起来很快,200张图片只需要8s左右就一个epcoch。

这是冻结层,提示出来的信息。大家可以注释掉,如果觉得乱的话。

最后,我也存在一个问题,就算为什么我跑模型时候会一直下载pt,我猜想可能是因为混合精度的问题。所以一直下载,也确实挺烦人的。pycharm的路径也会经常标红,确实让人看得很不舒服。















 5528
5528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









