






一、引用
Sendong Zhao, Chang Su, Zhiyong Lu, Fei Wang, Recent advances in biomedical literature mining, Briefings in Bioinformatics, Volume 22, Issue 3, May 2021, bbaa057, Recent advances in biomedical literature mining | Briefings in Bioinformatics | Oxford Academic
二、研究关键词
Biomedical Literature Mining; Deep Learning; Natural Language Processing
生物医学文献挖掘;深度学习;自然语言处理
三、文献类型
Briefings in Bioinformatics
四、研究背景与目的
近年来,生物医学领域的科学论文数量迅速增加。这些文献大多以电子格式提供并易于获取。其中隐藏的领域知识对生物医学研究和应用至关重要,这对生物医学文献挖掘(BLM)技术提出了很高的要求。生物医学信息学(BMI)和计算机科学(CS)社区都在这个主题上做了大量的努力。BMI社区更关注具体的应用问题,因此更喜欢可解释和描述性的方法,而CS社区更追求优越的性能和泛化能力,因此开发出更复杂和通用的模型。本文的目的是回顾两界在土地管理方面的最新进展,并启发新的研究方向。
五、研究内容
(一) 生物医学文献挖掘(Biomedical literature mining, BLM)
是指利用文本挖掘和自然语言处理(NLP)技术,从生物医学文献中自动提取和挖掘知识的领域。长短期记忆(LSTM)、卷积神经网络(CNN)和变压器双向编码器表示(BERT)等深度学习模型已经被确立为命名实体识别(named entity recognition,NER)和关系提取(relation extraction,RE)等NLP任务中的最先进(SOTA)方法。
(二) 分为五个部分
生物医学命名实体识别和规范化(biomedical NER and normalization),生物医学文本分类(biomedical text classification),关系提取(RE),途径提取和假设生成(pathway extraction and hypothesis generation)。
生物医学命名实体识别和规范化是从生物医学文章中提取有意义和有趣实体的最基本任务,它们之间的关系可以通过关系提取来识别。生物医学文本分类对于生物医学文章的分类和索引等任务至关重要。路径提取可以将连接的关系合并,并通过对它们的整合生成路径。通过对生物医学文献进行假设生成,可以发现潜在的生物医学新发现。
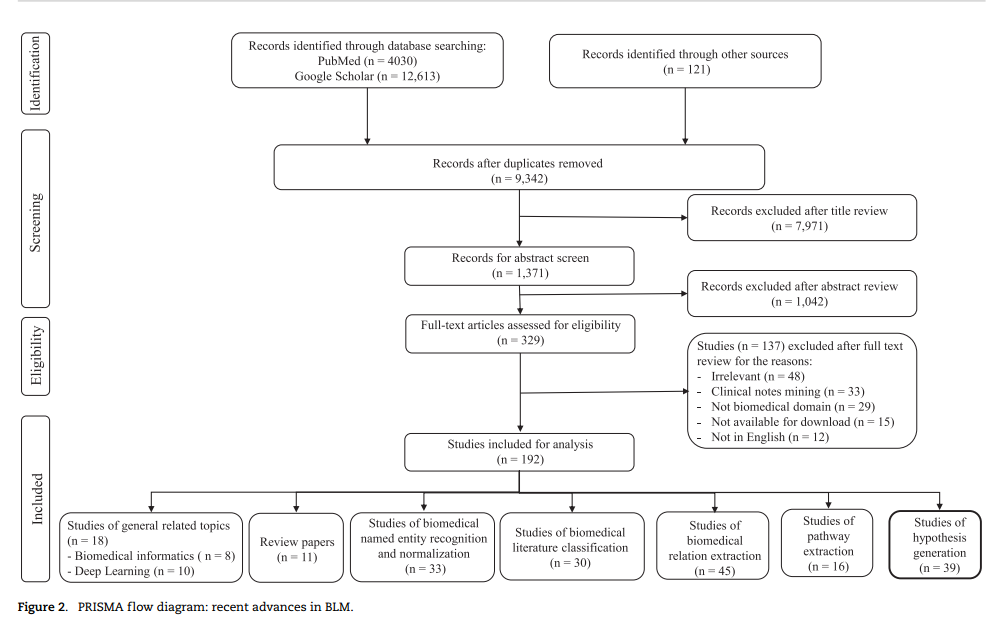
在这些任务中,生物医学NER和规范化以及文本分类是其他任务的基础。它们是实现包括关系提取在内的其他下游任务的必要步骤。路径提取和假设生成通常在关系提取之上进行。

1. 生物医学NEN(named entity normalization)
是将获得的生物医学命名实体映射到受控词汇表中。NER和NEN都可以看作是序列标记问题。传统的生物医学NER方法大致可分为三类:基于字典的方法、语义方法和统计方法。深度学习技术应用于NER,因为它们可以以端到端方式进行训练,而无需额外的特征工程。使用BERT,可以通过将每个标记的输出向量馈送到预测NER标签的分类层来训练NER模型。
2. 生物医学文献分类文本分类
任务主要有两种:相关主题识别和生物医学文献标引。相关主题识别确定生物医学出版物是否与给定主题相关,传统的主题识别研究利用经典的机器学习模型,如监督机器学习模型、排序模型和本体匹配模型来实现目标。生物医学文献标引是另一个重要的生物医学文献分类问题。它为每篇特定的生物医学文章分配一组术语(例如mesh(医学主题标题)术语),以表示文章中讨论的概念。将MeSH术语分配给生物医学文章的问题本质上是一个多标签分类问题,它将每个MeSH术语视为一个二元分类任务,其中许多模型已经应用于此,如k近邻(KNN)、朴素贝叶斯、支持向量机、学习排序方法等。
利用深度学习方法提出了许多MeSH索引模型。这些研究通常包括两个模块:(1)一个神经网络,为每个MeSH术语产生可能性评分;(2)一个分类器,确定术语是否相关或不相关。不同的神经网络架构,包括多层前馈神经网络,卷积神经网络(CNN), rnn,预训练深度神经语言模型,如BERT和ELMo,以及基于注意力的模型。
3. 关系提取(RE)
是指对主要文本中不同生物医学概念之间的关系提及进行检测和分类。RE的目标是检测实体对之间预先指定的关系类型的出现情况。根据关系提取的具体类型,我们将生物医学关系提取研究分为4类:蛋白质-蛋白质相互作用(Protein–protein interactions ,PPIs)、基因型-表型关系(genotype–phenotype relations,GPA)、化学-蛋白质相互作用(chemical–protein interactions,CPI)和药物-药物相互作用(drug–drug interactions,DDI)。
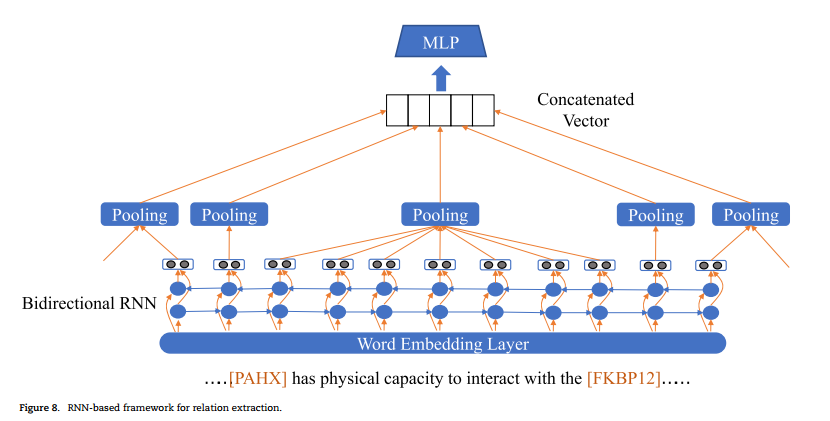
蛋白质-蛋白质相互作用(PPIs)对于理解复杂的疾病机制和设计适当的治疗方法是必不可少的。机器学习方法已被用于自动提取PPI。通过从带注释的文本中学习语言规则,机器学习技术在降低误报率和增加覆盖率方面都比基于规则的方法表现得更好。基因型-表型关联(GPA)从生物医学文献中鉴定GPA在精准医学中起着核心作用。(精准医学(Precision Medicine)是一种新兴的医疗模式,它基于个体的基因、环境和生活方式等差异,为每个患者提供个性化的治疗方案。)化学-蛋白质相互作用(CPI)是指化合物与蛋白质在人体中的相互作用,是药物发现和开发的一项基本任务。药物-药物相互作用(DDI)鉴定是上市后药品安全监测或药物警戒的一项重要任务。以前的DDI提取方法包括基于共现的、基于规则的和机器学习的方法,还有深度学习(CNN,RNN)。
CNN:嵌入层通过查找表将每个单词转换为嵌入向量。具有整流线性单元(ReLU)激活的卷积层通过在单词标记上滑动过滤器将嵌入转换为特征映射。池化层通过选择最高、最低或平均特征值来降低特征映射向量的维数。多层感知器(MLP)层输出每个关系的概率。
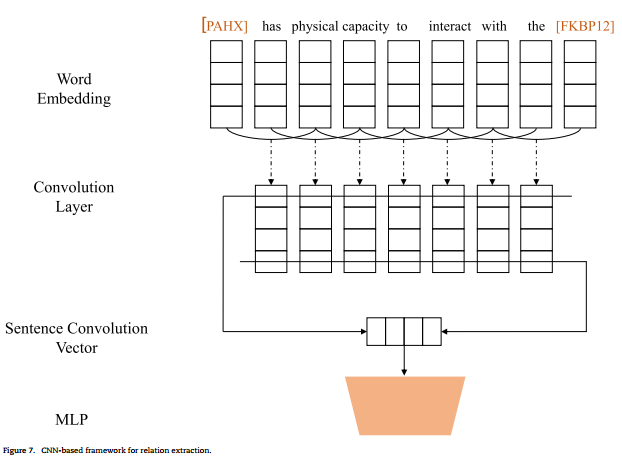
RNN:通过探索词序列中的长期和短期依赖关系来建模文本。它可以提取词汇和句子级别的特征,而不需要任何复杂的NLP预处理过程。
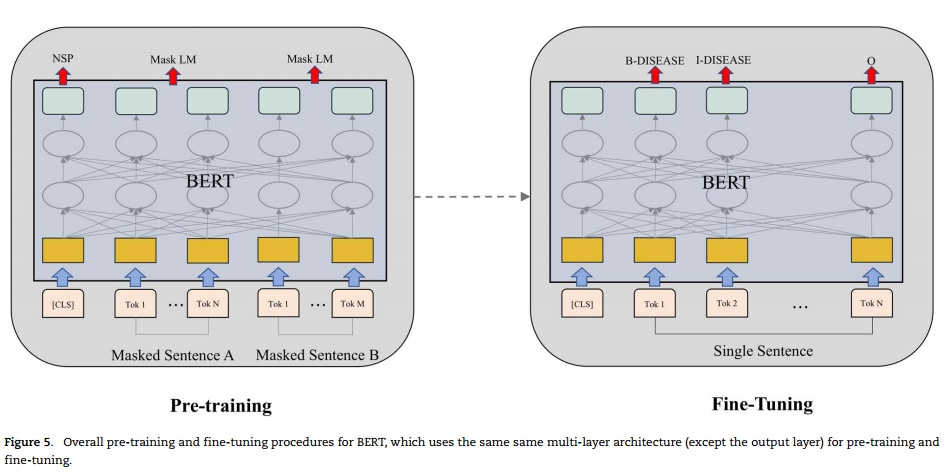
在通用领域语料库上使用预训练的BERT对BioBERT进行初始化。然后,BioBERT在生物医学文本(例如PubMed文章)上进行预训练。BioBERT进一步在几个生物医学语料库上进行了BLM任务的微调。BioBERT只需要有限数量的特定任务参数,但在生物医学关系提取方面优于SOTA模型3.49 F1分。
4. 生物途径提取
生物学途径包括基因、基因产物等异质实体和代谢物等小分子之间的相互作用,相互作用的例子包括转录调控(分子如转录因子与DNA结合,从而调控基因的表达)和翻译后调控(蛋白质合成后对其功能的调节)。现有的研究大多侧重于信号转导和基因调控等静态途径,而不是代谢网络和动力学。路径提取研究有基于规则的系统,基于规则和机器学习方法的混合方法。蛋白质相互作用网络、基因-疾病-药物相互作用网络等其他结构也是生物医学研究人员最感兴趣的领域。
5. 生物医学假设生成
假设生成,也被称为基于文献的发现(literature-based discovery ,LBD),试图通过计算方法从文献中获得新的生物医学发现。它在药物开发、药物再利用和药物警戒等制药行业的一些应用中尤其有前景。大多数LBD系统基于或衍生自Swanson的ABC共现模型。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









