






 本文介绍了拓扑优化在结构设计中的应用,通过赵州桥的例子展示了其简化结构和节省材料的优势。首先,详细阐述了进行静力分析的步骤,包括导入模型、设置网格、施加力和约束。接着,进入拓扑优化阶段,说明了如何利用静力学分析结果进行优化,并调整保留材料的百分比。最后,提醒注意实际应用中的对称性考虑,以确保优化效果符合工程需求。
本文介绍了拓扑优化在结构设计中的应用,通过赵州桥的例子展示了其简化结构和节省材料的优势。首先,详细阐述了进行静力分析的步骤,包括导入模型、设置网格、施加力和约束。接着,进入拓扑优化阶段,说明了如何利用静力学分析结果进行优化,并调整保留材料的百分比。最后,提醒注意实际应用中的对称性考虑,以确保优化效果符合工程需求。
很基础。
前言
进行拓扑优化的好处在于可以简化结构,满足力学性能的同时简化结构。
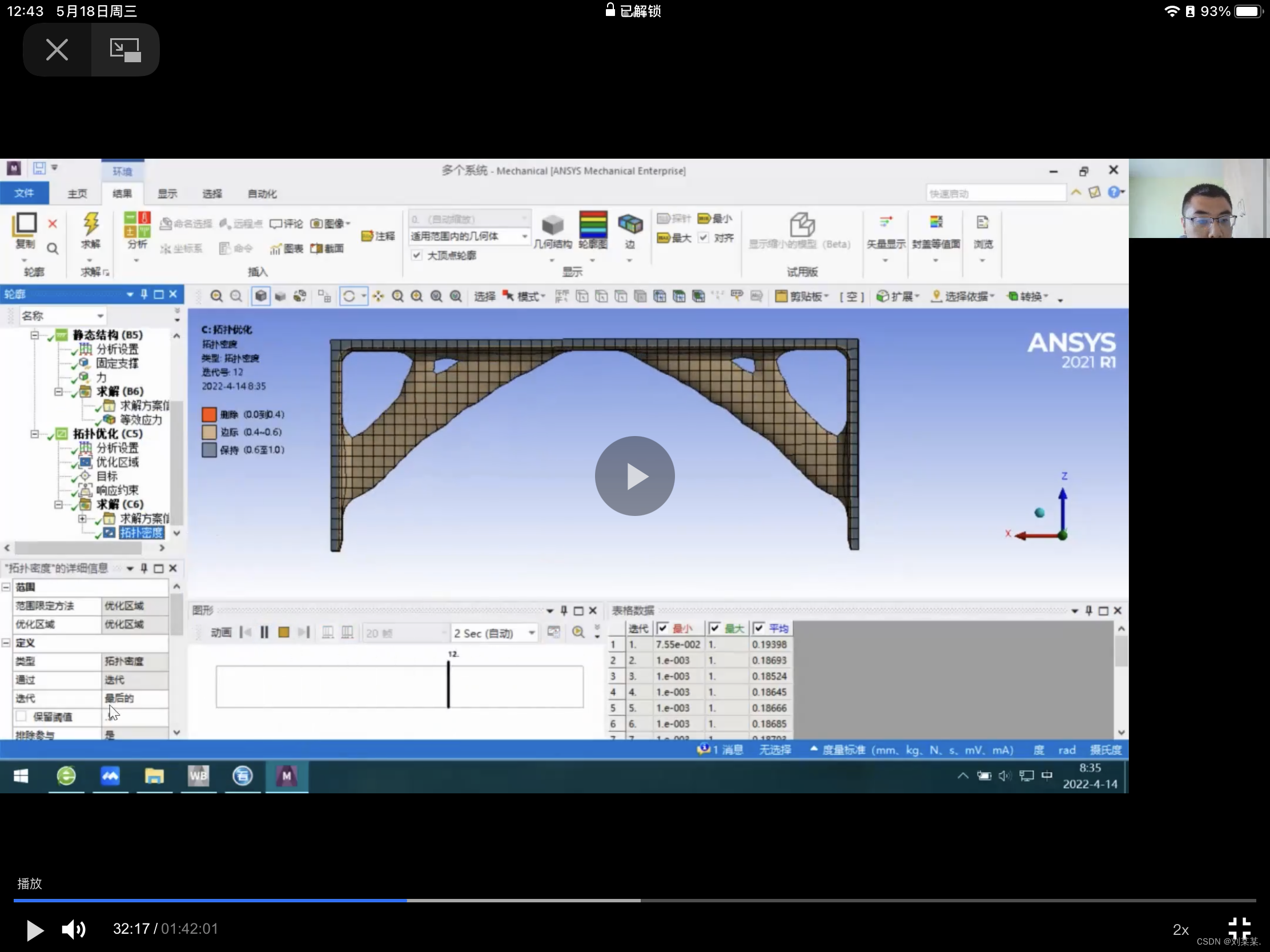
如赵州桥的一大一小的拱,就可以用拓扑优化优化出来,可见一千四百多年以前古人的智慧是多么丰富。

步骤
大体的步骤是需要
1.先导入模型(需要时.x_t格式,这个可以在导出时另存为)
2. 进行静力分析(静态结构),求出结果
3. 进行拓扑优化拓扑。优化的过程就是满足力学性能的要求的同时,简化结构节省材料
-
选中静态结构,拖动到右边的方框中

-
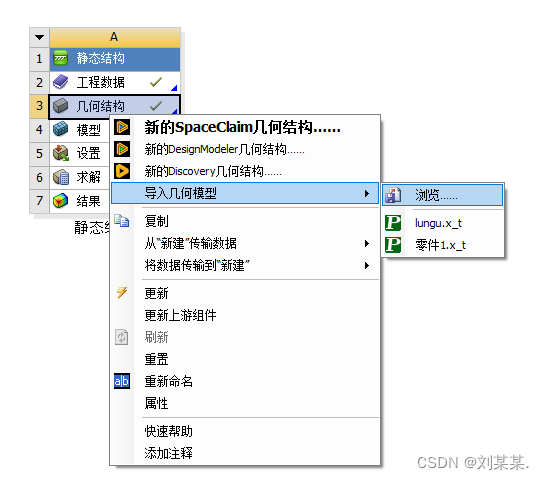
右击几何结构,导入模型.x_t
-
双击模型,进入模型界面
-
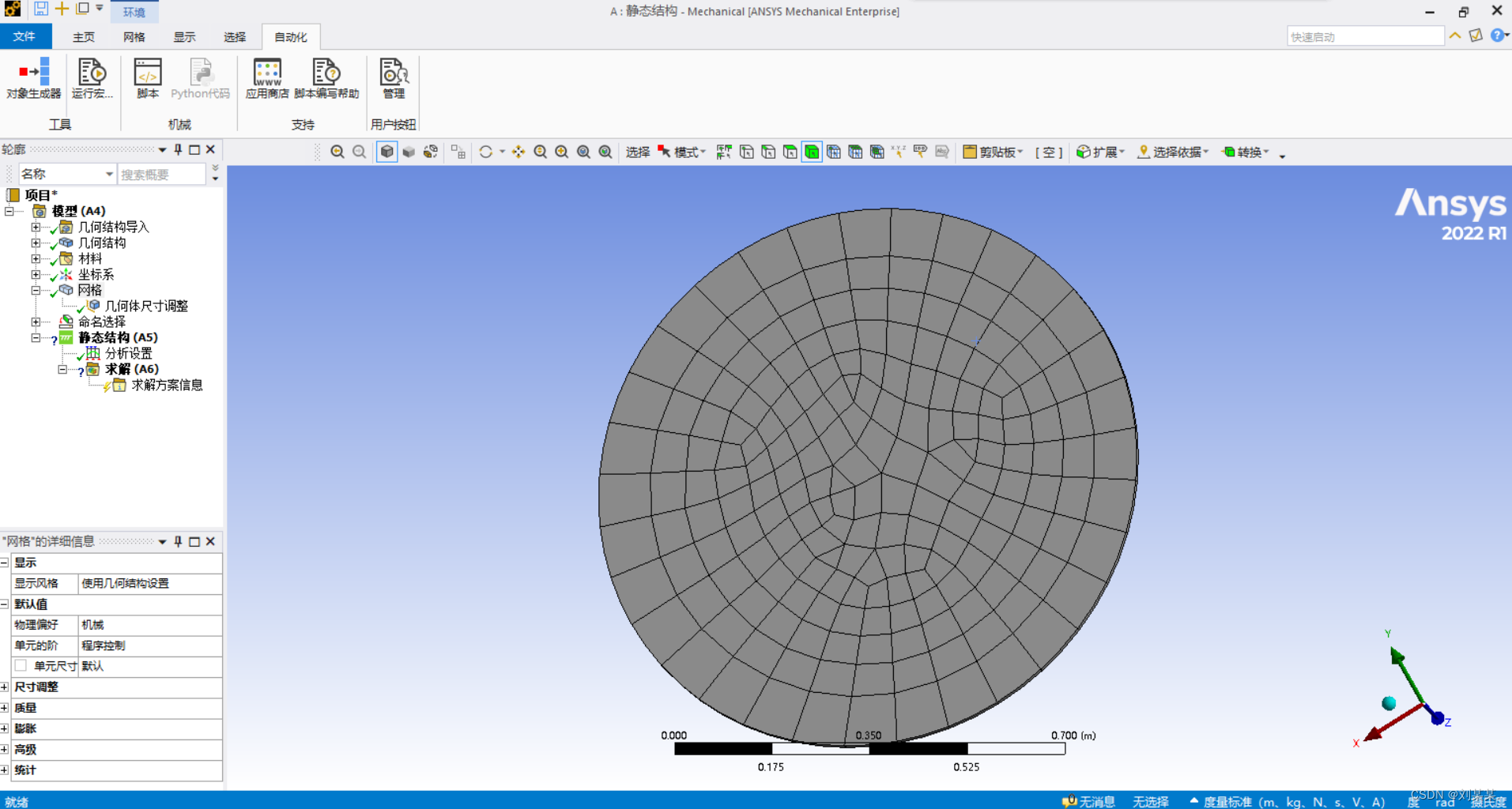
建立网格
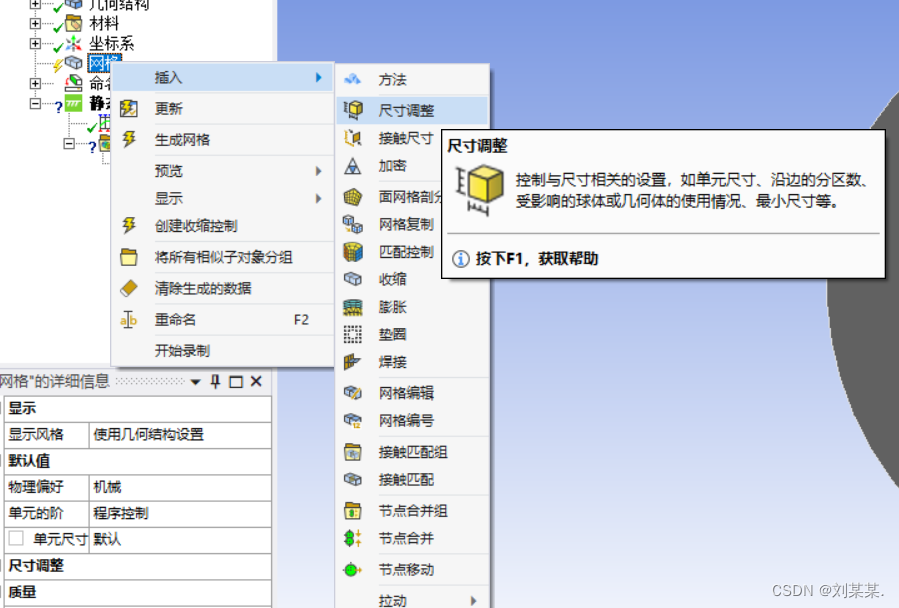
黄色的是需要填写的
几何结构是需要选择整个模型体。红线内可以选择点 线 面 体。选择体。
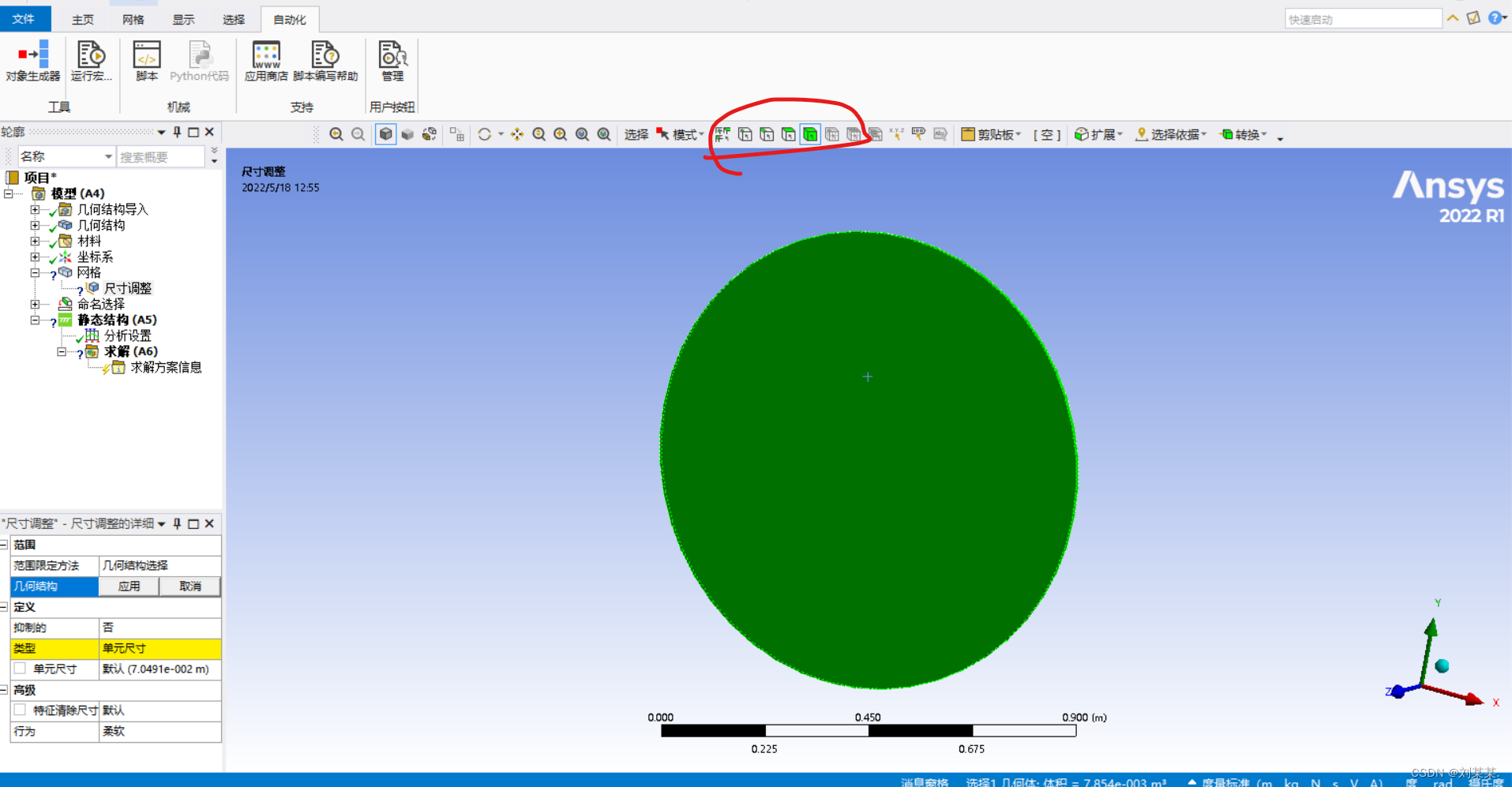
单元尺寸是一个网格的大小
==选好之后,可能没有网格,需要右击网格,点击更新。
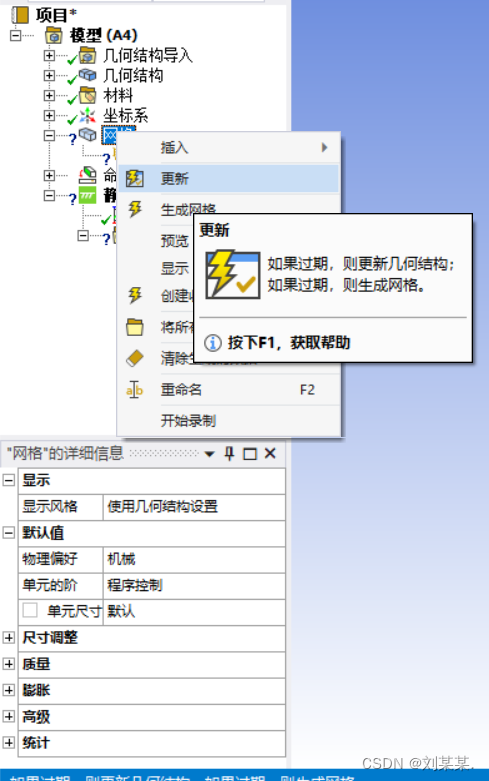
更新后
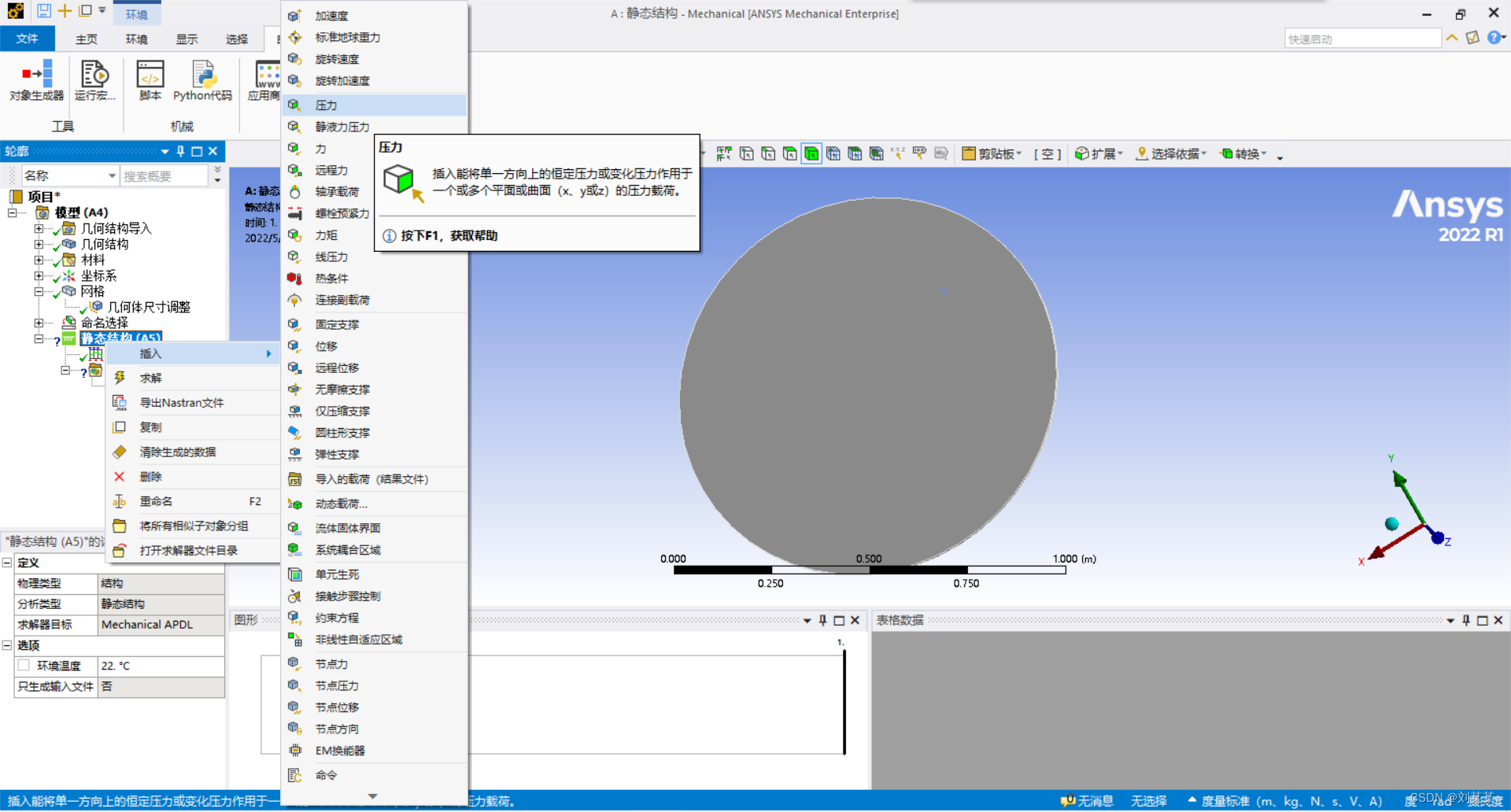
插入力。选择面,插入力
插入固定支撑,不差插入只插入力求解不了。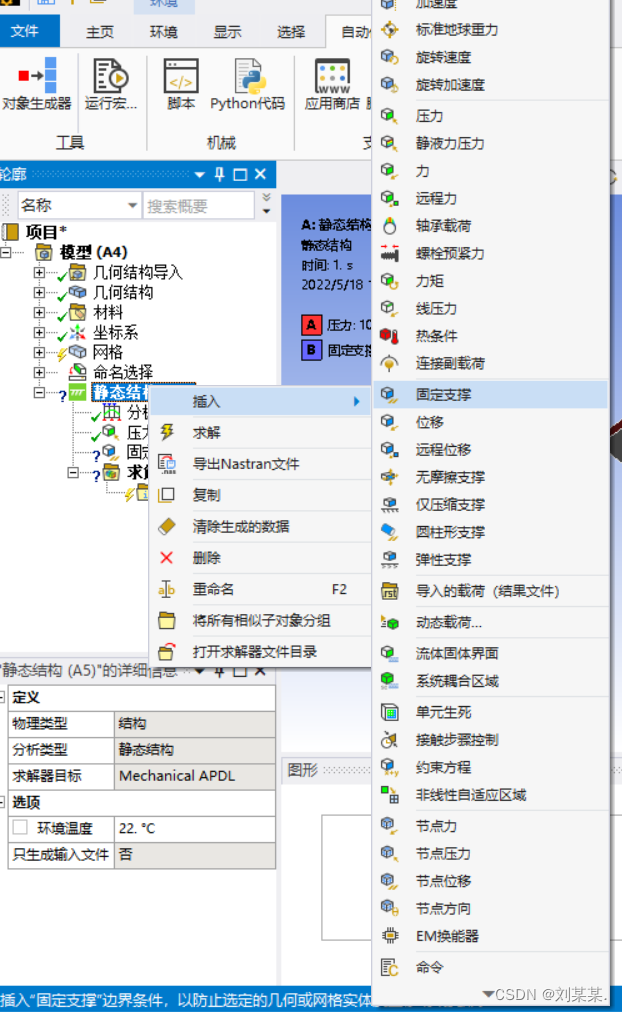
右击求解。求解里插入总变形和等效应变。
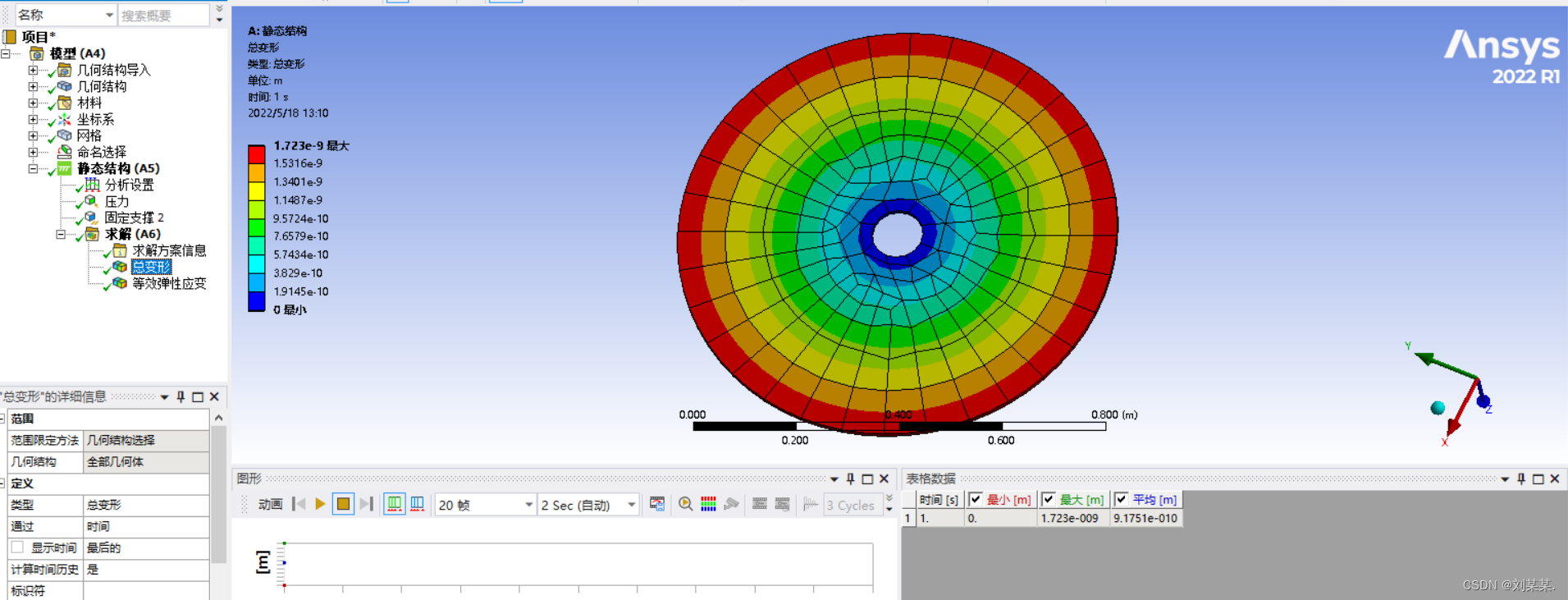
至此,静力学分析结束。
拓扑优化
拓扑优化是在静力学分析的基础上进行的。
回到初始界面
点击结构优化(2022是,其他版本是拓扑优化)拖到A的求解结果里面,代表用他的计算的数据,这样后面就省事儿。
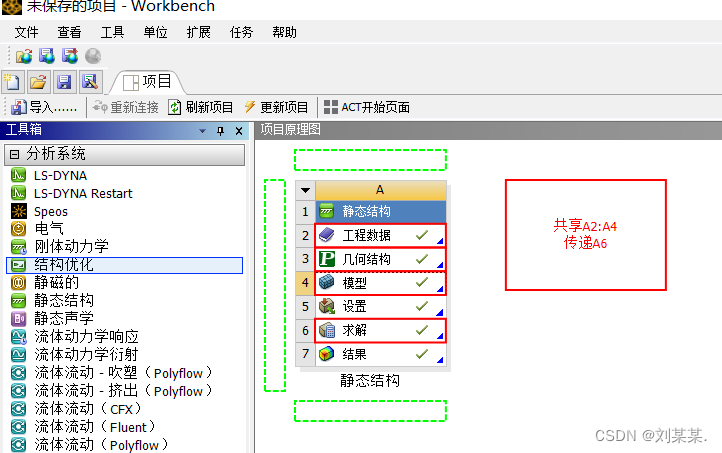
双击下图里的设置*有个小闪电,意思 是需要更改。

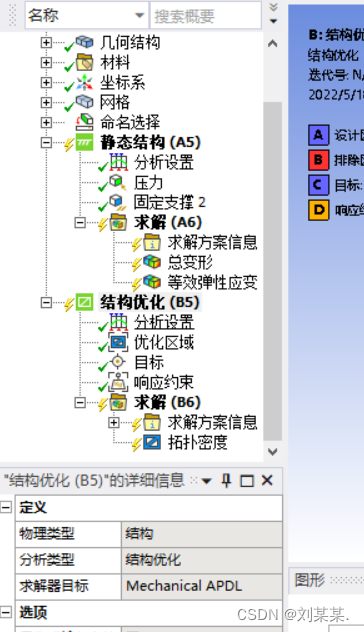
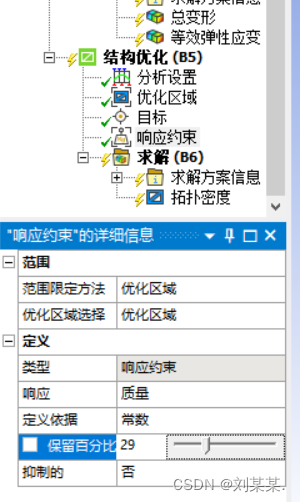
点击响应约束,保留百分比 是留多少材料。一般为百分之三十。
得到之。后,右击求解里的求解
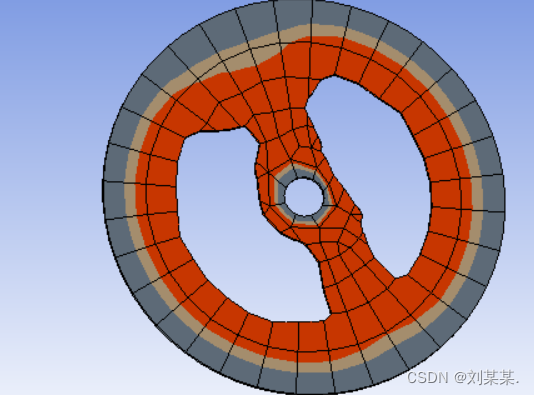
这样做出来是有问题的,因为轮胎的受力不是360度的,应该像如图然后弄三个或者几个对称的就对了。
能力游侠


















 1744
1744

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









