







文章目录
一、什么是集成学习?
集成学习其实就相当于投票,比如分类算法中,我们选择三种算法对同一个问题来进行分类,若有两种以上的算法确定它是第一类,那么最终的结果就是第一类。
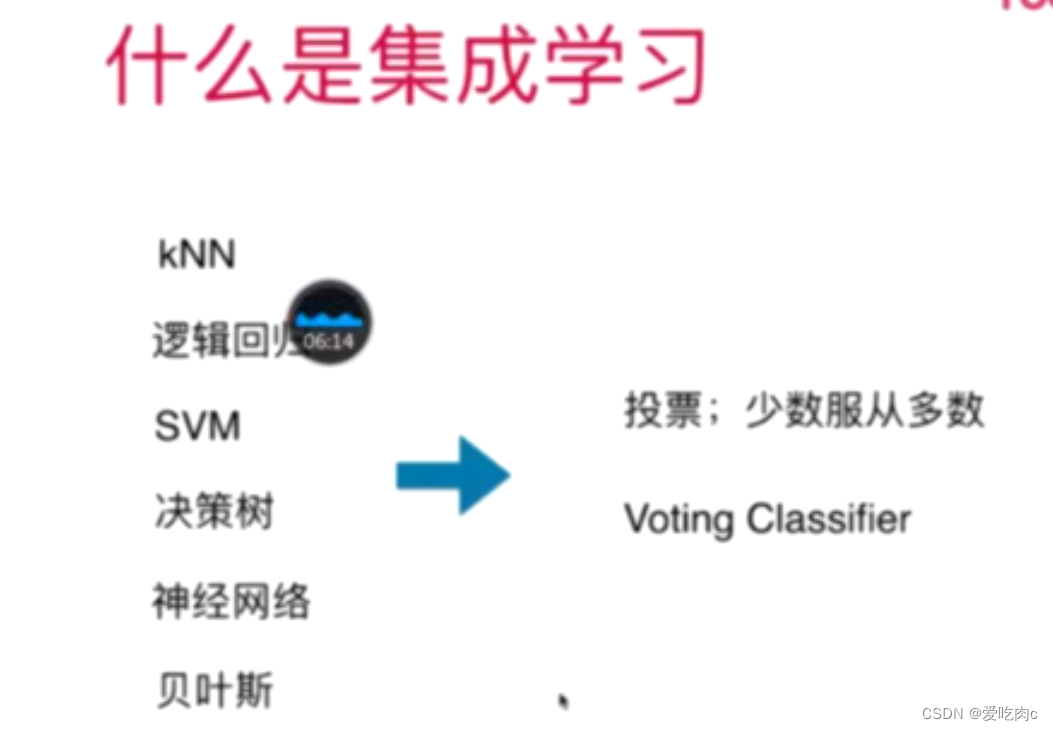
sklearn也为我们封装了
分为Hard Voting 和Soft Voting
1、hard Voting
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x,y=datasets.make_moons(n_samples=500,noise=0.3,random_state=666)
plt.scatter(x[y==0,0],x[y==0,1])
plt.scatter(x[y==1,0],x[y==1,1])
plt.show()
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
svc=SVC()
log_reg=LogisticRegression()
dt_clf=DecisionTreeClassifier()
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=666)
svc.fit(x_train,y_train)
y1_predict=svc.predict(x_test)
svc.score(x_test,y_test)
log_reg.fit(x_train,y_train)
y2_predict=log_reg.predict(x_test)
log_reg.score(x_test,y_test)
dt_clf.fit(x_train,y_train)
y3_predict=dt_clf.predict(x_test)
dt_clf.score(x_test,y_test)
模拟hard voting
y_predict=np.array(y1_predict+y2_pretdict+y3_pretdict>=2,dtype='int')
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_predict)
0.888
sklearn中的hard voting
from sklearn.ensemble import VotingClassifier
vot=VotingClassifier(estimators=[
('log_reg',LogisticRegression()),
('svc',SVC()),
('dt_clf',DecisionTreeClassifier())
],voting='hard')
vot.fit(x_train,y_train)
vot.score(x_test,y_test)
0.888
2、soft Voting
对于投票,我们一般情况下还要分权重。若所有算法结果权重一致,那就是Hard

上述这个图,如果按照hard voting 那最终结果就是B类。
但是我们可以看到,模型1和模型4把其评判为A类的概率极大,但是235模型把其评判为B类的概率
却不是很大,所以我们如果只考虑大于百分之五十就评判为当前一类的话,
效果并不好。

我们可以把模型得到的概率求一个平均值,根据平均值来确定类别
那么这就需要每个算法都可以在判定类别时也要求取一下当时的概率。
对于KNN算法求概率
很容易,不在叙述
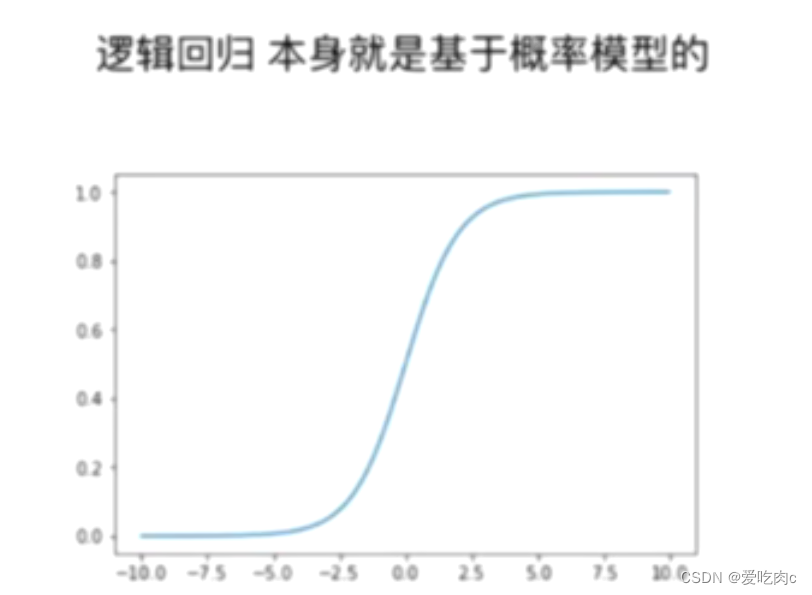
对于逻辑回归
逻辑回归中就是基于概率来分辨类别的
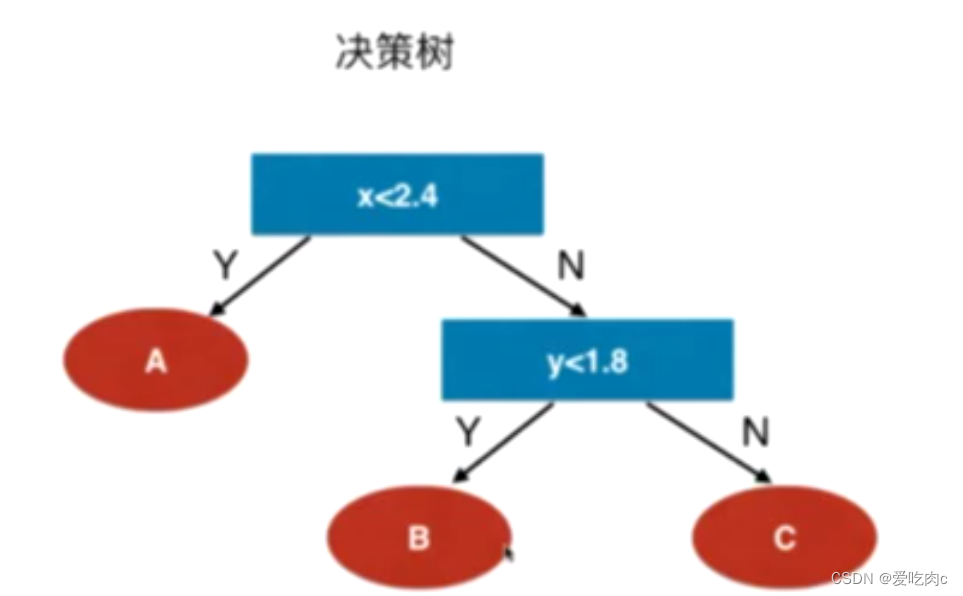
决策树
决策树同knn一样,都是非参数学习,他们求概率的思想也大同小异
svc
svc默认是不求取概率的,因为这比较耗时间,但是我们通过修改一个参数值,让其计算概率值。

probablity默认为False,我们把其修改为TRUE即可
至此,我们学过的算法都可以计算概率,那么就可以使用sofe voting
from sklearn.ensemble import VotingClassifier
vot=VotingClassifier(estimators=[
('log_reg',LogisticRegression()),
('svc',SVC(probability=True)),
('dt_clf',DecisionTreeClassifier(random_state=666))
],voting='soft')
vot.fit(x_train,y_train)
vot.score(x_test,y_test)
0.896
soft Voting 更具有准确性
二、Bagging 和Pasting
1.引入Bagging和Pasting
从投票的角度来说,我们的算法是不够的,因此就需要创造很多不一样的子模型
我们可以根据同一个算法,制造出不同的子模型。

如何创造子模型呢?
我们可以让不同的子模型中的数据不同,这样就具有了差异性。

但是又有一个问题,就是看的样本数据少了,准确率一定会下降的,但是这并不影响,因为我们的子模型很多,累积起来概率就不会很小了。


当然这里只是假设,因为每一个子模型的概率都是不固定的,也不相同。
但是通过这里我们也应该知道,即使每个子模型的准确率不是很高,但是集成学习之后却可以得到很好的准确率。
如何取一部分数据呢?有两种方法

Bagging更常用,是因为如果是Pasting,相当于平均划分了,那么如何划分又是一个问题。
在sklearn中没有单独的PastingClassifier这样一个类,只有BaggingClassifier这个类,
我们可以根据调节bootstrap这个属性来确定是用哪一种采样方式
bootstarp默认为TRUE 代表放回取样
2、代码举例
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bag_clf=BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,max_samples=100,bootstrap=True)
bag_clf.fit(x_train,y_train)
bag_clf.score(x_test,y_test)
0.88
参数:第一个表示我们用的是哪个算法
n_estimators表示子模型的个数
max_samples表示每个子模型取多少个数据
一般我们都会采用决策树,因为决策树对应的参数 即剪枝操作类型多,我们可以获得更多不一样的墨模型
三、oob和关于Bagging的更多讨论
1、oob
对于放回取样:会导致一部分数据没有取到,我们可以利用这没有取到的样本来进行测试/验证。
而不需要单独的测试数据集。使用oob_score这个属性即可

from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
oob_bag_clf=BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,max_samples=100,bootstrap=True,oob_score=True)
oob_bag_clf.fit(x,y)
oob_bag_clf.oob_score_ #下划线即这不是用户传进来的参数,而是根据我们的类计算出的一个结果。
0.906
2、关于Bagging的更多讨论
n_jobs
使用多少个核来计算

%%time
oob_bag_clf=BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,max_samples=100,bootstrap=True,oob_score=True,n_jobs=-1)
oob_bag_clf.fit(x,y)

random_subspaces 随机样本空间采样
如果一个数据样本有多个维度,即有多个样本特征的话,我们可以对其样本特征进行随机样本空间采样,比如一个图像像素。
random_Patches 随机补丁 即针对样本,又针对样本空间采样。

max_feature即采用多少个样本特征
bootstrap_features 即是否采用样本特征采样
oob_bag_clf=BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,max_samples=500,bootstrap=True,oob_score=True,max_features=1,bootstrap_features=True)
oob_bag_clf.fit(x,y)
oob_bag_clf.oob_score_
#max_samples即不对样本采样
oob_bag_clf=BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,max_samples=100,bootstrap=True,oob_score=True,max_features=1,bootstrap_features=True)
oob_bag_clf.fit(x,y)
oob_bag_clf.oob_score_
四、什么是随机森林?
对于我们之前创建的子模型,其基础分类器都是决策树
那这成百上千个决策树放在一起就可以称为一个随机森林。
决策树的节点划分:是在随机的特征子集上寻找最优的划分方式。
这样我们的决策树也就各不相同。
sklearn为我们提供了随机森林的类。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x,y=datasets.make_moons(n_samples=500,noise=0.3,random_state=666)
plt.scatter(x[y==0,0],x[y==0,1])
plt.scatter(x[y==1,0],x[y==1,1])
plt.show()
from sklearn.ensemble import RandomForestClassifier
rf_clg=RandomForestClassifier(n_estimators=500,random_state=666,oob_score=True)
rf_clg.fit(x,y)
rf_clg.oob_score_
五、Extra Trees

减少了方差, 但增大了偏差。
这个是极其随机的,他其实也是随机森林,但是决策树在结点划分上不同
Extra Trees 在节点划分上,是使用随机的特征和随机的阈值,更具有随机性。
from sklearn.ensemble import ExtraTreesClassifier
et_clf=ExtraTreesClassifier(n_estimators=500,bootstrap=True,random_state=666,oob_score=True)
et_clf.fit(x,y)
et_clf.oob_score_
六、Boosting
与Bagging不同,Boosting中的每个模型不是独立的,而是相互依赖的

1、AdaBoosting
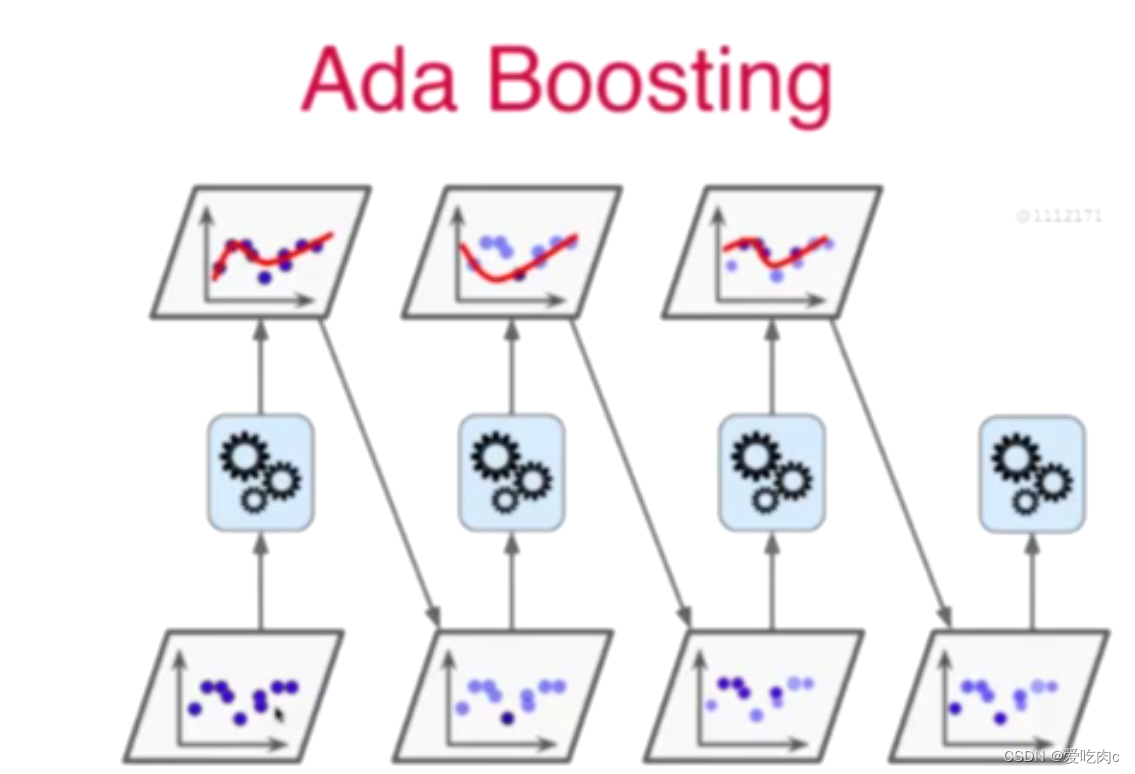
最后根据所有模型来预估。
这里模型的数据都是相同的,只是每一次的权重都不同。深色代表的权重大。

2、Grandient Boosting

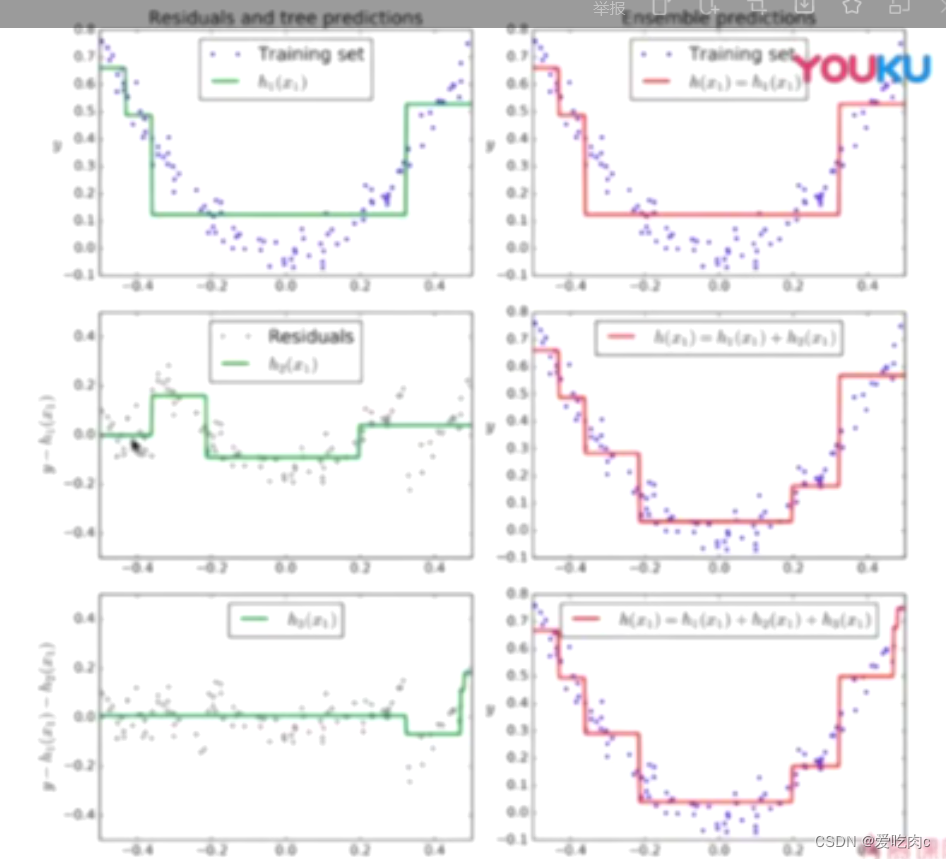
不用指定分类器,它的分类器固定为决策树

3、Stacking
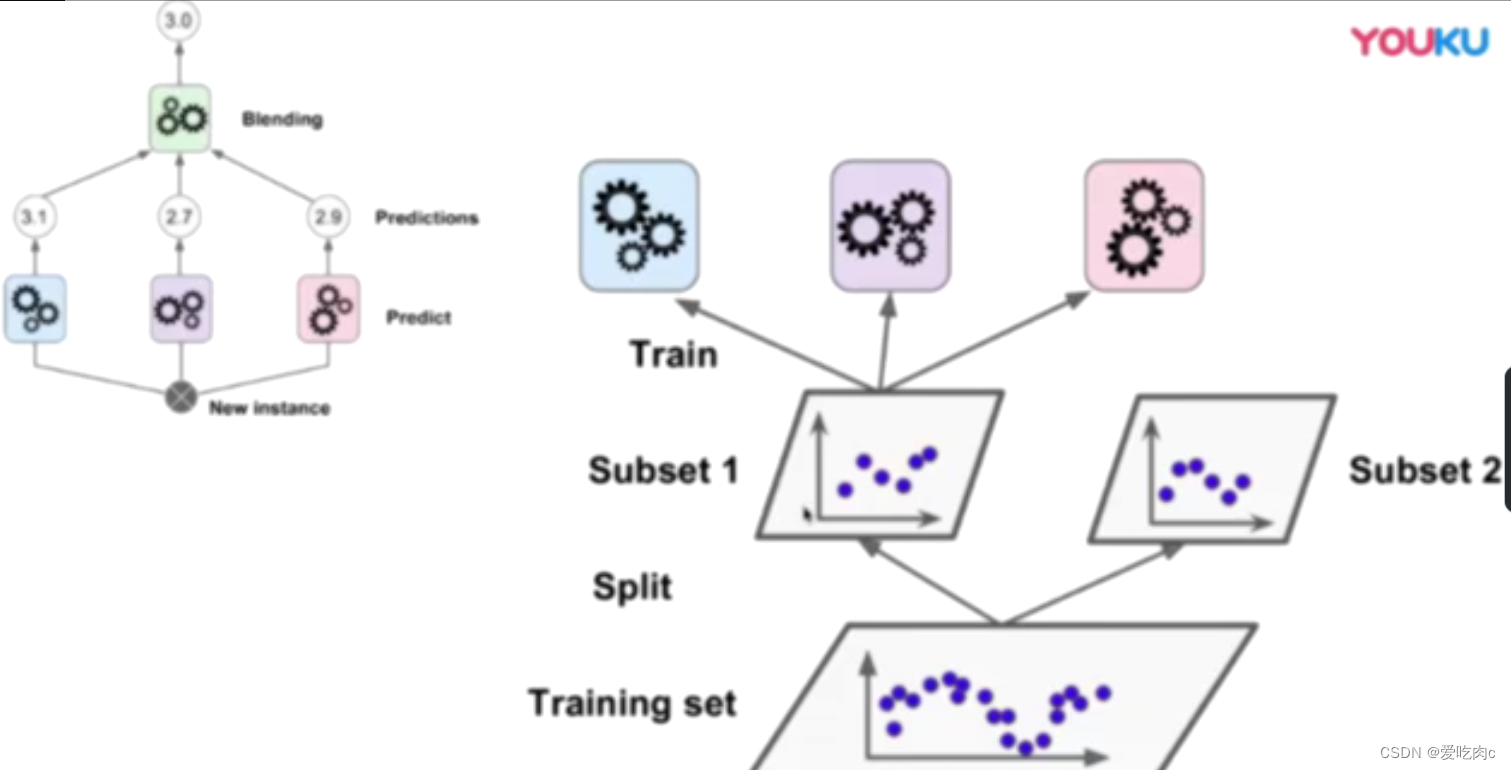
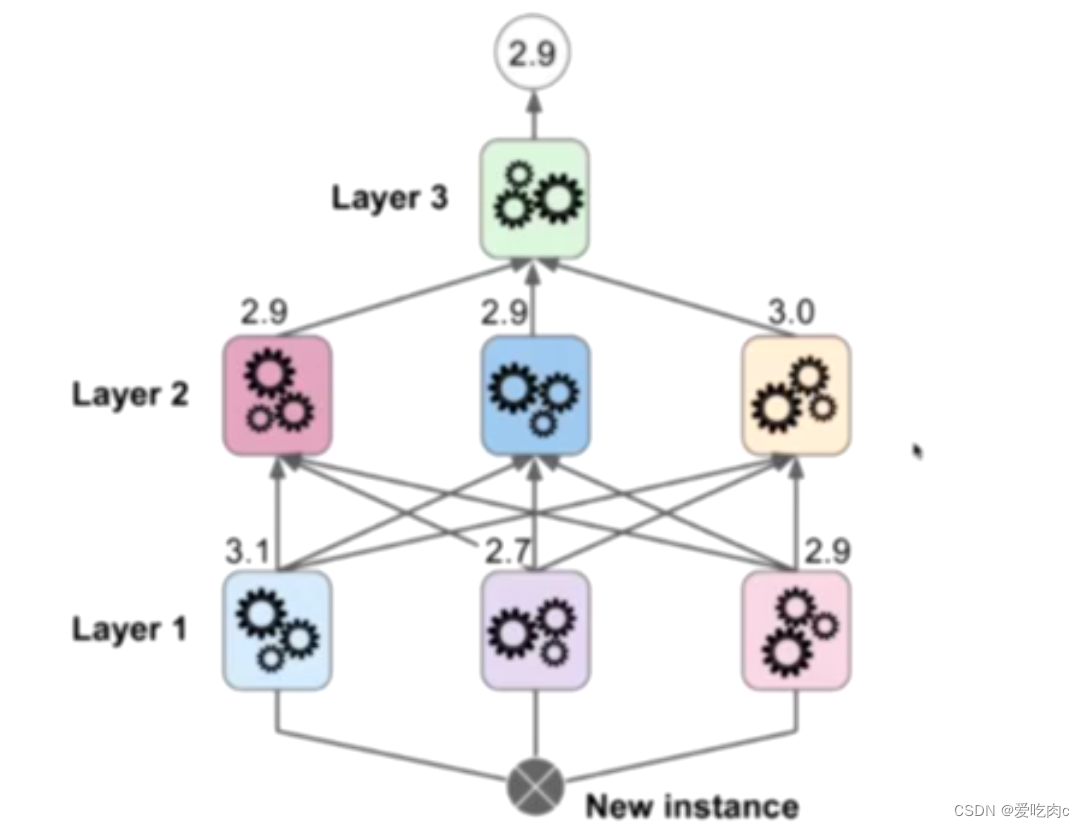
由此可见 有几层也是一个超参数,我们需要将原始数据集划分成几份。
第一份用来训练第一层,第二份用来训练第二层,以此类推…、
会出现过拟合现象。
这里关于Boosting不详细论述。
















 834
834











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









