






介绍
whisper.cpp是一个开源项目,它是对OpenAI的Whisper模型的C/C++移植实现。
OpenAI的Whisper是一个自动语音识别(ASR)系统,经过大量多语言和多任务的监督数据训练,能够进行多语言语音识别、语音翻译和语言识别等任务。而whisper.cpp项目使得这个模型能够在不同的平台上以本地方式运行,包括但不限于Windows、Mac OS、Linux、Android和WebAssembly等。
whisper.cpp的优势主要体现在以下几个方面:
无依赖性: whisper.cpp不需要安装任何第三方的库或框架,只需要一个C/C++编译器就可以编译和运行,这减少了对外部库的依赖。
轻量级: whisper.cpp库非常小巧,只有一个源文件,便于集成到任何项目中,无论是大型还是小型,都不会增加过多的负担。
高性能: 通过使用模板元编程和C++17特性,whisper.cpp在运行时几乎无额外开销。它使用了类型安全的方式,保证了事件处理的效率。
简单易用: 设计简洁明了,API友好,开发者可以快速上手并开始编写事件驱动的代码。
此外,whisper.cpp还提供了音频转文字的功能,但需要注意的是,它目前只支持16khz的wav文件格式的音频文件。在使用前,可能需要使用如ffmpeg这样的工具将音频文件转换成所需的格式。
总的来说,whisper.cpp是一个功能强大且灵活的语音识别工具,为开发者提供了在多种平台上进行本地语音识别的新选择。然而,由于技术领域的快速发展,建议在使用前查阅最新的文档和资料,以确保获取最准确和最新的信息。
关于Whisper.cpp是个什么东西我就不过多解释了,这里主要是说搭建环境的,对于Whisper.cpp的说明网上有一大堆,也有点懒得写了。
参考文档:
https://blog.csdn.net/weixin_52318459/article/details/139546485
下载
whisper.cpp 的地址
whisper.cpp地址
whisper.cpp github官网关于Models介绍部分
或使用Git命令将项目克隆到本地:
git clone https://github.com/ggerganov/whisper.cpp
没有装Git的,可以参考以下链接:
Git安装链接
Model的地址
Model的地址
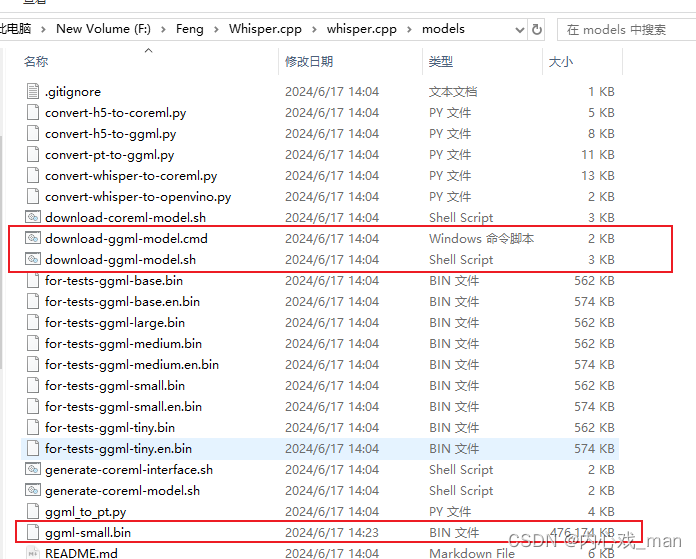
下完whisper.cpp项目之后还要下载Model,我用的是small Model,关于Model的详细描述请找其他文章,写这个Blog的时候我对whisper.cpp也不是很了解,只是刚刚搭建好环境而已,记录一下。
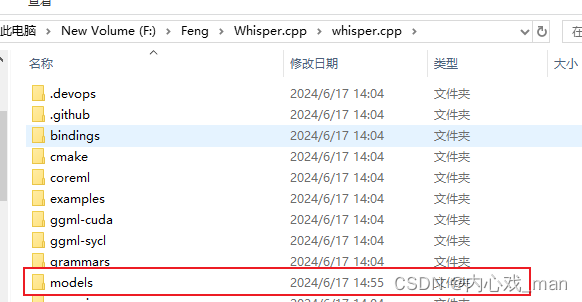
在whisper.cpp 项目的根目录中有个models文件夹,进去使用命令下载small Model,
下面的是CMD命令,在cmd中执行:
download-ggml-model.cmd small
还有一个shell命令:
download-ggml-model.sh medium
随便挑一个,参考下图。
注意:如果两个命令都不成功,那就看一下能不能访问Model的地址(上面的链接),如果访问不了,那就需要使用迅雷下载了,往下看。
迅雷下载Model
迅雷Model下载链接
可根据不同的Model填写不同的链接路径:
https://huggingface.co/ggerganov/whisper.cpp/resolve/main/ggml-small.bin
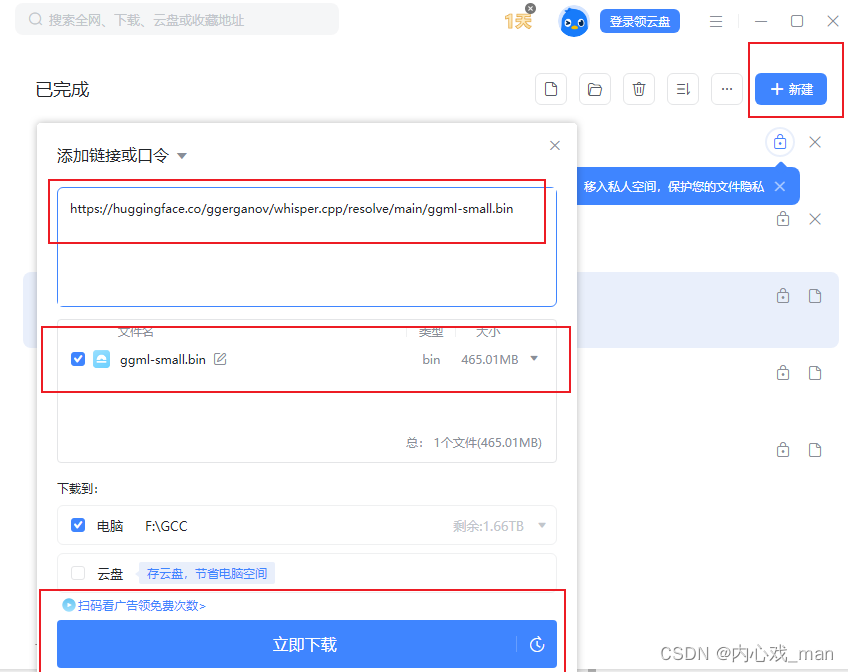
注意Model需要放在Whisper.cpp项目中的Models文件夹中。
make命令生成Main.exe
上面两步成功之后就在Whisper.cpp项目的根路径下使用Git命令生成main.exe
make
如果显示make命令不存在就参考以下链接安装make命令:
make命令参考链接
安装好make命令后就继续执行,如果执行失败显示GCC不存在的话就参考以下链接:
GCC安装参考链接
继续执行make命令,如果make命令成功执行没有报错的话,往下看.
在Whisper.cpp项目的根路径下使用Git命令进行音频文件识别,识别成功后的文件在samples文件夹中的jfk.wav.srt文件中。
./main -osrt -m ./models/ggml-small.bin -f samples/jfk.wav
ffmpeg
whisper.cpp目前只支持16khz的wav文件格式的音频文件,所以其他文件可以使用ffmpeg来转换为.wav文件。
如果还没有安装ffmpeg可以参考以下链接:
ffmpeg安装链接
ffmpeg -i ./repeat.mp3 -ar 16000 -ac 1 -c:a pcm_s16le ./repeat.wav
./main -osrt -m ./models/ggml-medium.bin -f samples/repeat.wav -l zh
使用 whispe.cpp 的 demo
whisper 中的几个函数:
whisper_lang_id() :语言支持检测——这里要使用小写,如 chinese 而不能用 Chinese.
whisper_context_default_params() :设置默认的上下文参数
whisper_init_from_file_with_params() :初始化上下文
whisper_is_multilingual() :检查上下文是否支持多国语言
whisper_full(): 语音识别过程的函数
whisper_full_n_segments(): 获取一共产生了多少段文字
whisper_full_get_segments_text(): 获取识别到的一段文字
whisper_full_n_token() :一段识别中有多少个 tokern
whisper_full_get_token_id() :获取对应 id 的 token
代码部分
代码写在main.cpp中,然后重新回到根目录whisper.cpp中执行make命令生成新的main.exe,然后执行main.exe测试新写入的代码功能即可
#include "common.h"
#include "whisper.h"
#include "grammar-parser.h"
#include <cmath>
#include <fstream>
#include <cstdio>
#include <regex>
#include <string>
#include <thread>
#include <vector>
#include <cstring>
bool wav_read(std::string fname, std::vector<float>& pcmf32)
{
std::vector<std::vector<float>> pcmf32s;
if (!::read_wav(fname, pcmf32, pcmf32s, false)) {
fprintf(stderr, "error: failed to read WAV file '%s'\n", fname.c_str());
return false;
}
return true;
}
int whisper_init(struct whisper_context * *ctx, whisper_full_params& wparams)
{
if (whisper_lang_id("chinese") == -1) {
fprintf(stderr, "error: unknown language '%s'\n", "Chinese");
exit(0);
}
struct whisper_context_params cparams = whisper_context_default_params();
cparams.use_gpu = false;
*ctx = whisper_init_from_file_with_params("models/ggml-small.bin", cparams);
if (*ctx == nullptr) {
fprintf(stderr, "error: failed to initialize whisper context\n");
return 3;
}
wparams = whisper_full_default_params(WHISPER_SAMPLING_GREEDY);
wparams.language = "chinese";
return 0;
}
int whisper_exit(struct whisper_context ** ctx)
{
whisper_free(*ctx);
return 0;
}
int whisper_identify(struct whisper_context **ctx, whisper_full_params& wparams, std::vector<float> pcmf32, std::string& result)
{
if(whisper_full(*ctx, wparams, pcmf32.data(), pcmf32.size()) != 0){
return -1;
}
const int n_segments = whisper_full_n_segments(*ctx);
for (int i = 0; i < n_segments; ++i) {
const char * text = whisper_full_get_segment_text(*ctx, i);
result += text;
}
return 0;
}
int main(int argc, char ** argv) {
std::vector<float> pcmf32;
struct whisper_context *ctx = nullptr;
whisper_full_params wparams;
std::string text;
if(!wav_read("output.wav", pcmf32)){
fprintf(stderr, "wave read failed !\n");
return -1;
}
if(whisper_init(&ctx, wparams)){
fprintf(stderr, "whisper init error !\n");
return -1;
}
if(whisper_identify(&ctx, wparams, pcmf32, text)){
fprintf(stderr, "identify error !\n");
return 0;
}
whisper_exit(&ctx);
fprintf(stdout, "text is : %s\n", text.c_str());
return 0;
}
好了,暂时到这了。















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









