







简介
什么是Whisper?
OpenAI的Whisper是一个自动语音识别(ASR)系统,它经过了大量多语言和多任务的监督数据训练,能够进行多语言语音识别、语音翻译和语言识别等任务。Whisper模型使用了一个编码器-解码器的Transformer架构,通过训练能够将输入的音频转换为对应的文本序列,并能够根据特殊的标记执行不同的任务。Whisper模型的训练数据集非常庞大,包含了68万小时的多语言音频数据,这使得它在语音识别上达到接近人类水平的鲁棒性和准确性。
什么是Whisper.cpp?
whisper.cpp 是一个开源项目,它是对 OpenAI 的 Whisper 模型的 C/C++ 移植实现。Whisper 模型是一个强大的自动语音识别(ASR)系统,而 whisper.cpp 项目使得这个模型能够在不同的平台上以本地方式运行,包括但不限于 Windows、Mac OS、Linux、Android 和 WebAssembly 等。
为什么使用Whisper.cpp?
whisper.cpp 是对 OpenAI 的 Whisper 模型的 C/C++ 移植版本,它相比原始的 Whisper 模型(通常是以 Python 编写,依赖于 TensorFlow 或 PyTorch 等深度学习框架)具有以下优势:
-
无依赖性:
whisper.cpp不需要安装任何第三方的库或框架,只需要一个 C/C++ 编译器就可以编译和运行,这减少了对外部库的依赖。 -
内存占用低:它的内存占用非常低,只需要几兆字节的内存就可以处理音频数据,这使得它适合在资源受限的设备上运行。
-
跨平台性能:
whisper.cpp支持多种技术和平台,包括 Apple Silicon、ARM NEON、Metal、Core ML、AVX、OpenCL、CUDA 等,可以在 Mac OS、iOS、Linux、Windows、Android、WebAssembly 等多种操作系统上运行。 -
高性能:它利用多核和并行计算的优势,实现高效的语音识别,可以在 CPU、GPU 或其他加速器上运行,提供高性能的推理能力。
-
混合精度和整数量化:支持使用不同的精度来运行 Whisper 模型,例如 32 位浮点数、16 位浮点数、8 位整数等。这可以根据不同的设备和需求,平衡模型的大小、速度和准确度。
-
零运行时内存分配:
whisper.cpp在运行时不会进行动态内存分配,有助于提高性能和稳定性。 -
支持 CPU 独占推理:即使在没有 GPU 的设备上也能运行,提供 CPU 独占的推理能力。
-
轻量级实现:整个模型的高级实现都包含在
whisper.h和whisper.cpp中,使得集成到不同平台和应用变得容易。 -
C-style API:提供了 C 风格的 API,便于与其他语言和框架集成。
-
支持量化:支持整数量化的模型,量化模型需要的内存和磁盘空间更少,并且可能在某些硬件上更高效。
-
支持 Docker:提供了 Docker 镜像,简化了部署和使用过程。
-
社区支持:有活跃的社区支持,提供了多种语言的绑定和示例,方便开发者使用和集成。
这些优势使得 whisper.cpp 成为一个轻量级、高性能、易于集成的自动语音识别解决方案,适用于需要实时、离线、通用和轻量级语音识别的场景。
本篇博客将介绍如何使用Whisper.cpp工具来为 Windows 上的视频文件生成字幕。
需要准备的工具
在使用Whisper.cpp之前需要安装好下面四个工具:
-
VC Redistributable
提供运行时支持:当编译C++应用程序时,编译器会生成二进制代码,但可能不会包含所有必要的库。VC Redistributable包含这些库,确保应用程序在运行时可以访问所需的函数和资源。提高兼容性:不同的应用程序可能使用不同的库版本,VC Redistributable提供了一个统一的库集合,减少应用程序之间的兼容性问题。
在下载地址中选择适合自己电脑的版本下载,下载地址。
-
Whisper.cpp v1.6.0
下载地址 -
Model
下载地址 -
FFMPEG
FFMPEG是一个开源的计算机程序,主要用于处理音频和视频文件。它支持多种格式转换、录制、编辑和流化等功能。下载地址

开始
1. 文件格式转换
由于 whisper.cpp 目前只支持 16 khz 的 wav 文件格式的文件,需要先使用 ffmpeg 将mp4文件转成所需的格式。
在cmd命令窗口将路径切换到"ffmpeg/bin"的安装目录,执行以下指令:
ffmpeg.exe -i "xxx.mp4" -ar 16000 -acodec pcm_s16le xxx.wav
"xxx.mp4"为需要转换的mp4文件,"xxx.wav"是转换后的wav文件。这两处需要自行修改
2. Whisper模型下载
即上面需要【准备的工具中的3.model】。关于模型的详细信息可以在Whisper.cpp github官网关于模型介绍部分查阅
3. 使用Whisper实现自动语音识别
在cmd命令窗口将路径切换到"whisper"的安装目录,执行以下指令:
main.exe -m "model_path" "xxx.wav" -osrt
"model_path"是下载的模型存放的绝对路径,"xxx.wav"是在【1.文件格式转换】后的wav文件,-osrt是参数,下面会详细说明。
例如,我使用了ggml-large-v3.bin对new.wav文件做自动语音识别,执行以下指令:
main.exe -m "C:\Users\50533\Desktop\whisper\ggml-large-v3.bin" "new.wav" -osrt -l Chinese
执行结果如下(展示部分内容):

关于自动语音识别的具体参数(包括文件存储、gpu使用、语言设置等等)可以执行main.exe查看
main.exe

4. 备注
在上面的演示中我们在每次重新打开cmd窗口时都需要将路径切换到”ffmpeg“/"whisper"的安装目录才能使用,这样有些麻烦。
如果将Whisper和ffmpeg添加至系统路径(就是将Whisper和\ffmpeg-7.0.1-essentials_build\bin在高级系统设置中-环境变量-系统-Path加入),这样我们能在任何目录运行它!
可能遇到的问题
1. windows系统无法输出中文字符,出现乱码问题
问题如下图所示:

原因
cmd命令行窗口字符编码不匹配导致。
解决方法
- win+R输入redit进入注册表
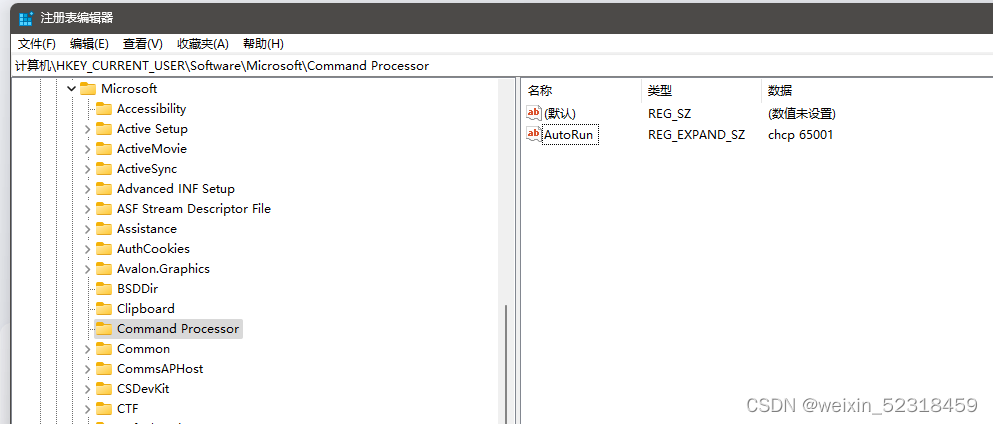
- 找到
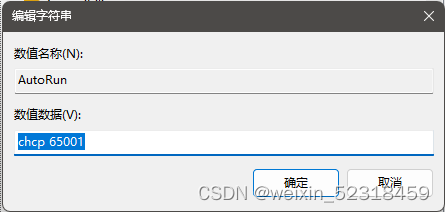
计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Command Processor,双击AutoRun项,将其数值数据改为chcp 65001,点击确定。
- 重启cmd后生效

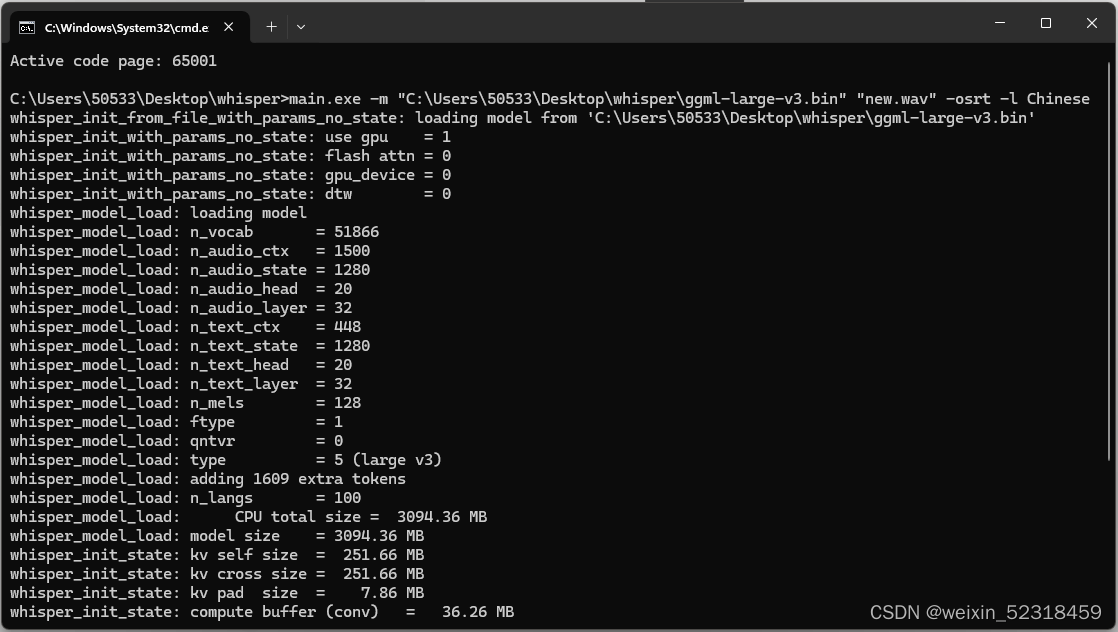
- 执行Whisper语音自动识别命令,可以看到成功输出中文

问题解决方案参考:
【Github】chinese characters not showing up on windows
【CSDN】CMD中文乱码
【CSDN】cmd窗口汉字显示乱码
【CSDN】Win10系统下CMD显示乱码的解决方法
2. ‘chcp’ 不是内部或外部命令,也不是可运行的程序或批处理文件
原因
出现 'chcp' 不是内部或外部命令,也不是可运行的程序或批处理文件。 这个错误通常意味着你的系统无法识别 chcp 命令。chcp 是一个命令行工具,用于更改Windows系统的代码页,以支持不同的字符集。
这个错误可能由以下几个原因造成:
- 命令提示符(cmd)被损坏:这可能是因为系统文件损坏或缺失。
- 环境变量问题:chcp 命令所在的路径可能没有添加到系统的环境变量 PATH 中。
- 操作系统版本:某些版本的Windows可能不支持或不包含chcp命令。
解决方法
- 检查环境变量:确保 chcp 命令的路径(通常是
%SystemRoot%\System32)已经被添加到环境变量 PATH 中。 - 使用管理员权限运行命令提示符:右键点击命令提示符图标,选择“以管理员身份运行”,然后再次尝试使用 chcp 命令。
- 修复或重新安装命令提示符:如果命令提示符被损坏,可能需要修复或重新安装它。
- 使用其他命令:如果 chcp 命令不可用,你可以尝试使用其他命令来达到相同的目的,例如使用 mode 命令查看和设置代码页。


















 4127
4127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









