







概述
一、爬虫定义
网络爬虫就是一种可以自动提取特定的静态或者动态网页中自己所需要的数据的方法,一段自动抓取互联网信息的程序称为爬虫,python是最为广泛使用的编程语言,因为python有着强大的第三方库且语言简洁。
爬虫指的是: 向网站发起请求, 获取资源后分析并提取有用数据的程序, 从技术层面来说就是通过程序模拟浏览器请求站点的行为, 把站点返回的HTML 代码、 JSON 数据、 图片、 视频等爬到本地, 进而提取自己需要的数据, 存放起来使用。
二、主要技术
request库、beautifulsoup库、re正则表达式、scrapy框架等是使用最为广泛的几种网络爬虫技术。request库、beautifulsoup、re正则表达式、scrapy框架等是使用最为广泛的几种网络爬虫技术。
常用的分析算法:拓扑分析算法,网页内容分析算法等
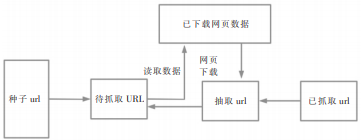
三、爬虫架构

四、爬虫流程















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









