







本文是接着上一篇深度学习之 11 残差网络的实现_水w的博客-CSDN博客
目录
延时神经网络(Time Delay Neural Network,TDNN)
1 网络记忆能力
• 全连接神经网络 和 卷积神经网络➢ 只能单独的处理一个个的输入,前一个输入和后一个输入 是完全没有关系的 。• 比如输入一整张图片。• 某些任务需要能够更好的处理序列 的信息,➢ 前面的输入和后面的 输入是有关系的 。• 比如,当理解一句话意思时,孤立的理解这句话的每个词是不够的,需要处理这些词连接起来的整个 序列 ;• 当处理视频的时候,不能只单独的去分析每一帧,而要分析这些帧连接起来的整个 序列 。
实例1:语言模型
给定一句话前面的部分,预测接下来最有可能的一个词是什么
我昨天上学迟到了,老师批评了____。分词结果:
我|昨天|上学|迟到|了 ,老师|批评|了 ____。
•
2-Gram模型 :在语料库中,搜索『了』后面最可能的一个词;
•
3-Gram模型 :搜索『批评了』后面最可能的词;
•
4-Gram, 5-Gram, …, N-Gram :
模型的大小和N的关系是指数级的,会占用海量的存储空间;
而循环神经网络RNN理论上可以往前(后)看任意多个词
实例2: 槽填充(Slot Filling)问题
例如在一个自动订票系统中,用户输入“我想八月二号
到达
台北”,需要填充槽(slot),
目 的 地:台北
到达时间:2020.08.02如何使用前馈神经网络(Feedforward network)解决此问题?
首先使用1-of-N encoding方法将每一个单词表示成一个向量。

目标:
训练前馈神经网络,使得输入“台北”时,目的地的概率最大。
示例应用:通过前馈网络解决槽填充问题?
输入
:一个单词(每个单词都表示一个向量)
输出
:
表示输入词属于槽的概率分布
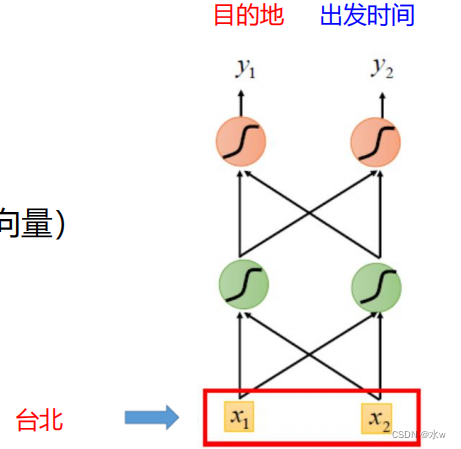
若另一个用户输入“我想在八月二号
离开
台北”,需要填充槽(slot),
出 发 地:台北
出发时间:2020.08.02对于前馈神经网络,使得输入“台北”时,出发地的概率最大。
Problem:
对于同一个输入,输出的概率分布应该也是一样的,不可能出现既是目的地的概率最高又是出发地的概率最高。
解决思路
:我们希望神经网络拥有“记忆”(memory)的能力,能够根据之前的 信息(如到达
或
)得到不同的输出。
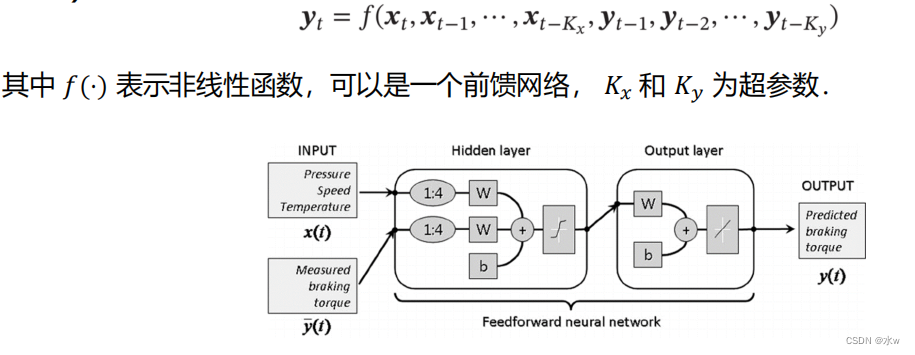
如何给网络增加记忆能力(除RNN外)?延时神经网络(Time Delay Neural Network,TDNN)
建立一个额外的延时单元,用来存储网络的历史信息(可以包括输入、输出、隐状态等)这样,前馈网络就具有了短期记忆的能力。
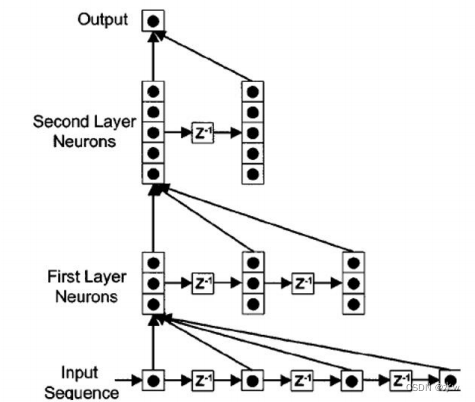
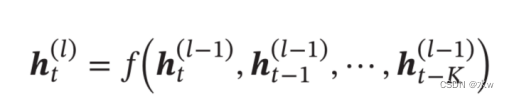
•
自回归模型(Autoregressive Model,AR)
:一类时间序列模型,用变量
𝑦
𝑡
的历史信息来预测自己 ;
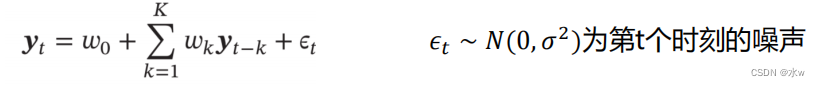
• 有外部输入的非线性自回归模
型(Nonlinear Autoregressive with Exogenous Inputs Model,
NARX)
2 循环神经网络(RNN)
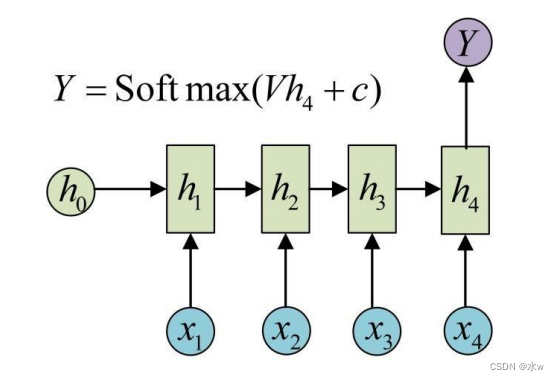
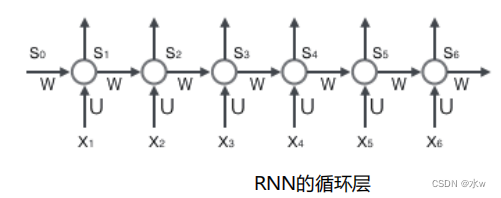
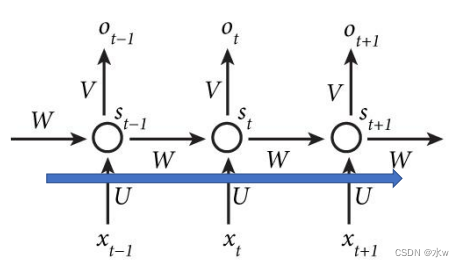
一个简单的循环神经网络由 输入层 、一个 隐藏层 和一个 输出层 组成。• 去掉有W的带箭头的圈,它就变成普通的 全连接神经网络• x 是一个向量,它表示 输入层 的值• s 是一个向量,它表示 隐藏层 的值, s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层 的值• o 也是一个向量,它表示 输出层 的值• U 是输入层到隐藏层的 权重矩阵• V 是隐藏层到输出层的 权重矩阵• W 是 隐藏层 上一次的值作为这一次的输入的 权重矩阵
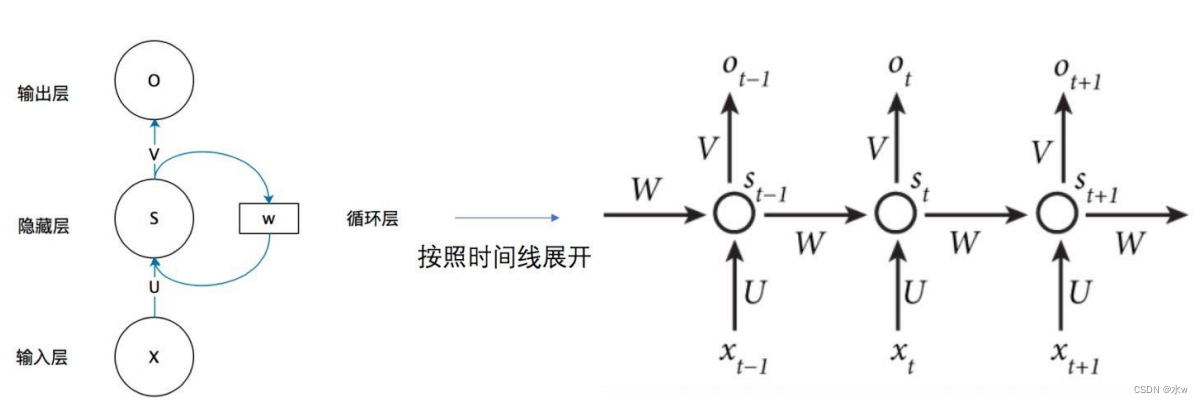
网络在t时刻接收到输入
x
𝑡
之后,隐藏层的值是
s
𝑡
,输出值是
o
𝑡
。 s𝑡
的值不仅仅取决于
x
𝑡
,还取决于
s
𝑡−1
。
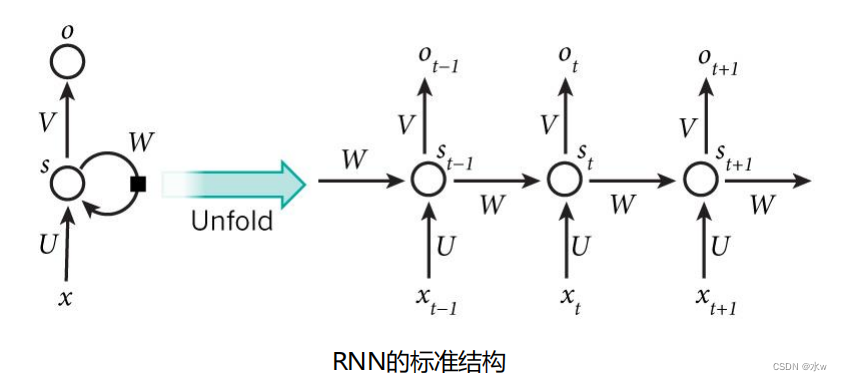
循环神经网络
可以往前看任意多个
输入值
的原因:
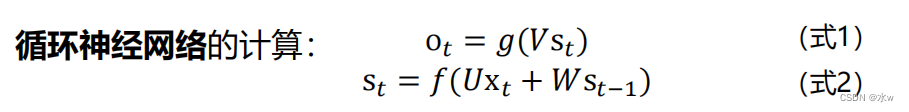
如果反复将(式2)带入(式1),我们将得到,即输出值o𝑡 ,受前面历次输入值x𝑡,x𝑡−1、x𝑡−2、x𝑡−3…的影响。
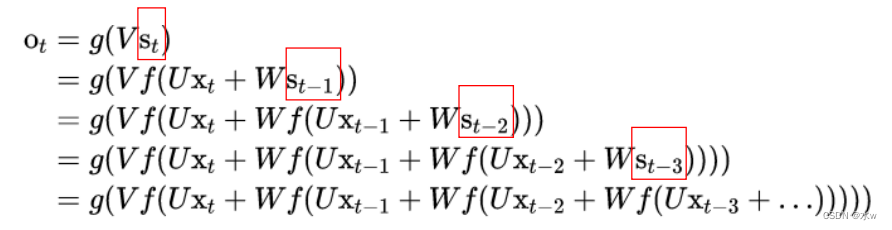
RNN的输入输出
RNN是一个序列模型• 如何将可变长度序列作为 输入 ?• 如何预测可变长度序列作为 输出 ?• 神经网络模型通过训练“学”到的东西蕴含在“ 权值 ”中。• 基础的神经网络只在 层与层 之间建立权连接,• 而RNN最大的不同之处在于隐藏 层内 的神经元也建立了权连接。
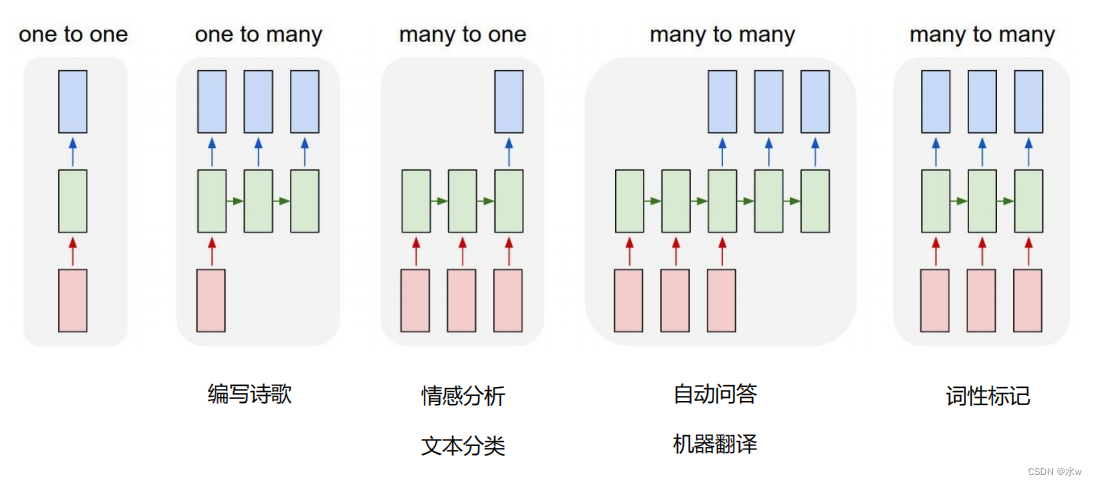
◼ Many-to-One模型:
在文本分类中,输入数据为单词的序列,输出为该文本的类别。
◼ One-to-Many模型
输入为一张图片,输出为图片的文字描述。
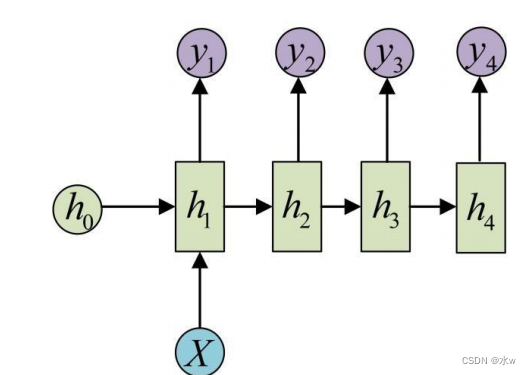
◼ Many-to-Many模型(同步)
输入和输出的序列个数相同,如输入为视频序列,输出为每一帧对应的标签。
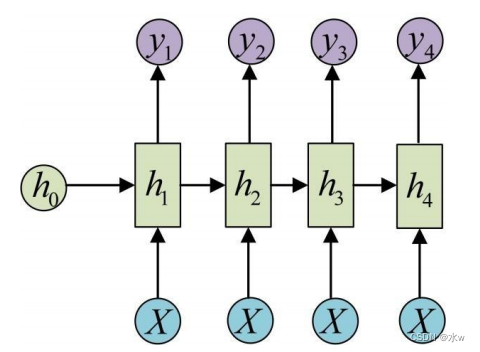
◼ Many-to-Many模型(异步)
输入和输出的序列个数不同,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
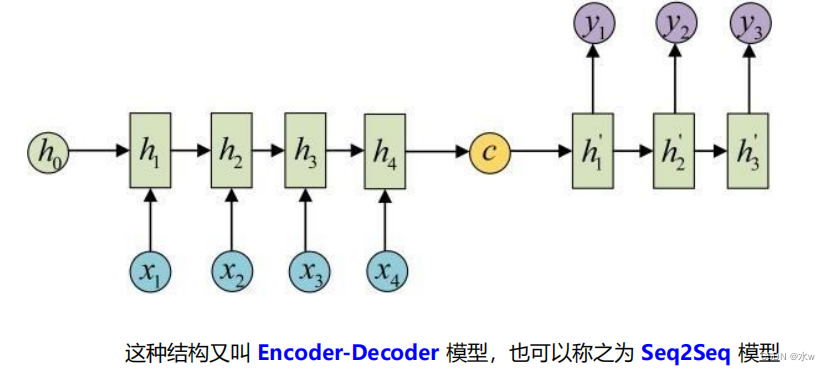
◼ RNN模型应用举例
- RNN写诗

3 随时间反向传播(BPTT)
• BPTT(Back-Propagation Through Time)算法是常用的训练RNN的方法,因为RNN处理时间序列数据,所以要基于时间反向传播,故称作 随时间反向传播 。• BPTT的中心思想是沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛(和BP算法相同)。• BPTT算法本质上还是BP算法,BP算法本质是梯度下降法,那么求各个参数的梯度便成了此算法的核心。
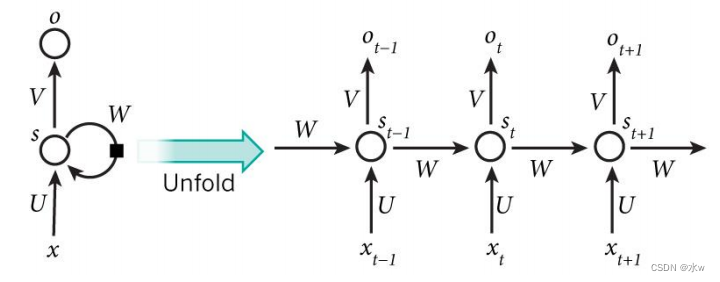
需要寻优的参数有三个,分别是 U、V、W 。与BP算法不同的是, 权重矩阵W和U的寻优过程需要追溯之前的历史数据 (BPTT算法的重点)。
BPTT算法基本原理
BPTT算法是针对 循环层 的训练算法,它的基本原理和BP算法是一样的, 也包含同样的三个步骤:A. 前向计算每个神经元的输出值;B. 反向计算每个神经元的 误差项 𝑗 值( 它是误差函数 E 对神经元 𝑗 的 加权输入 𝑛𝑒𝑡𝑗 的偏导数 );C. 计算每个权重的梯度。 最后再用随机梯度下降 算法更新权重。
A. 前向计算
使用前面的
式2
对循环层进行前向计算:
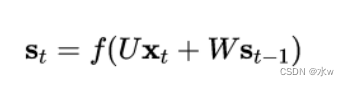
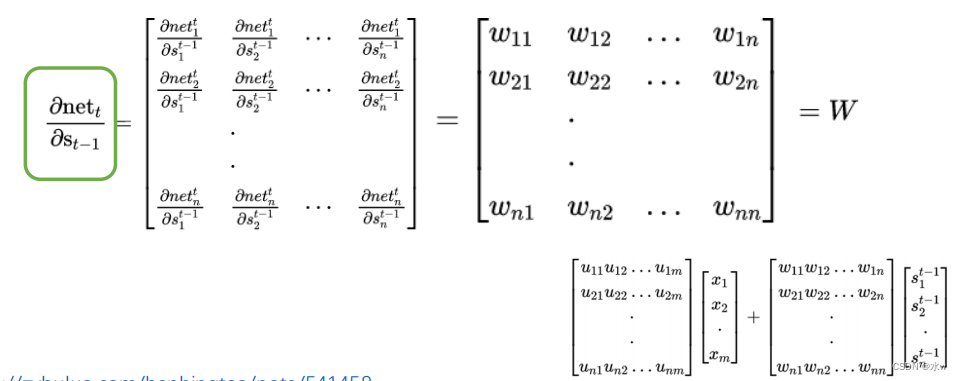
注意: 上面的 𝒔 𝑡 、 𝒙 𝑡 、 𝒔 𝑡−1 都是向量,用 黑体字母 表示; 而U、V 是矩阵 ,用大写字母表示。 向量的下标 表示 时刻 , 例如, 𝒔 𝑡 表示在 t 时刻向量 s 的值,偏置 b 此处不体现。
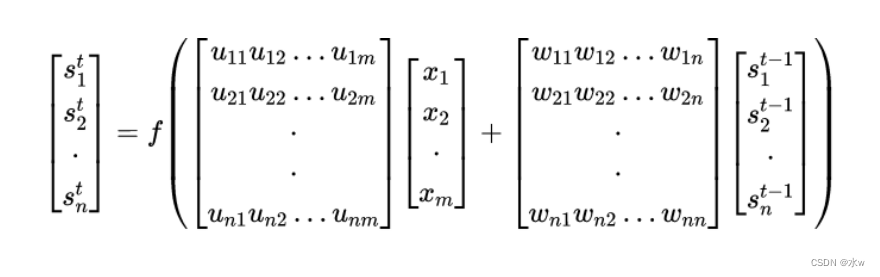
假设输入向量
x
的维度是m,输出向量
s
的维度是n,则矩阵U的维度是n×m,矩阵
W的维度是n×n,下面是上式展开成矩阵的样子:
B. 误差项的计算
BPTT算法将第 l 层 t 时刻的 误差项 𝛿 tl 值沿两个方向传播:一个方向是其传递到上一层网络,得到 𝛿 tl−1 ,这部分只和 权重矩阵 U 有关;另一个方向是将其沿时间线传递到初始 t 1 时刻,得到 𝛿 1l,这部分只和 权重矩阵 W 有关。
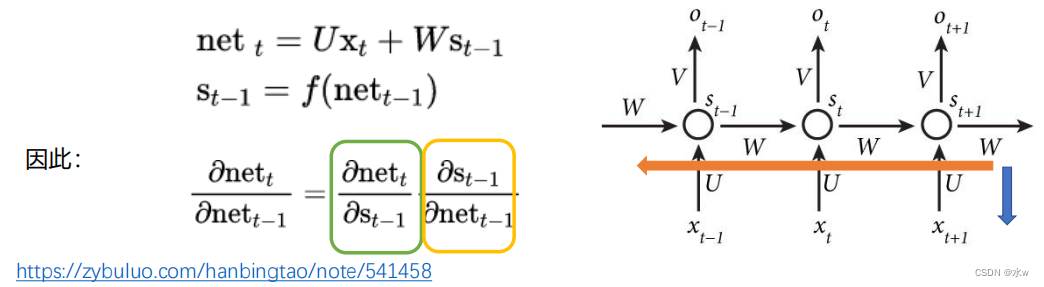
用向量
net
𝑡
表示神经元在t时刻的
加权输入(净输入)
,因为:
用a表示列向量,用
a
𝑇
表示行向量,上式的第一项是向量函数对向量求导,其结果为Jacobian矩阵:
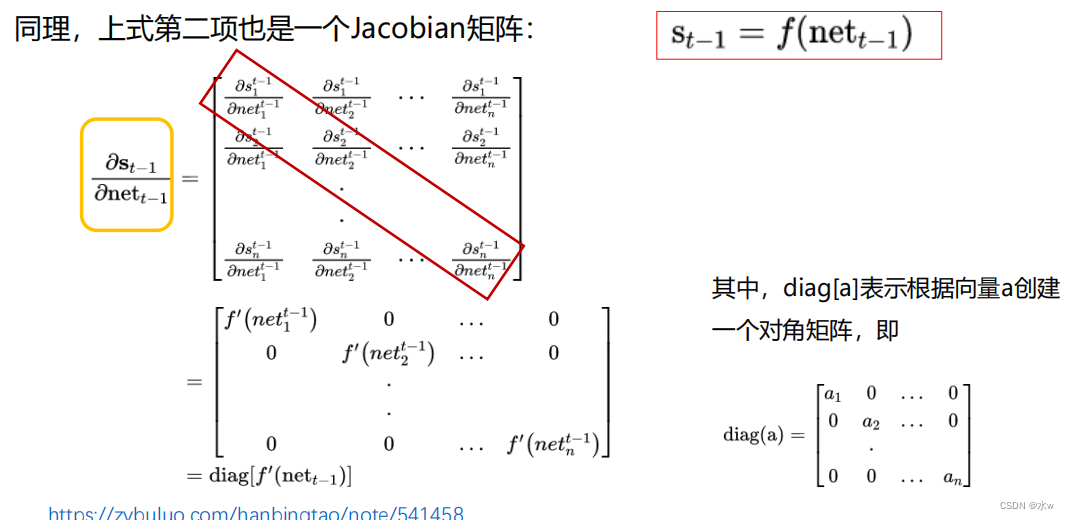
最后,将两项合在一起,可得:
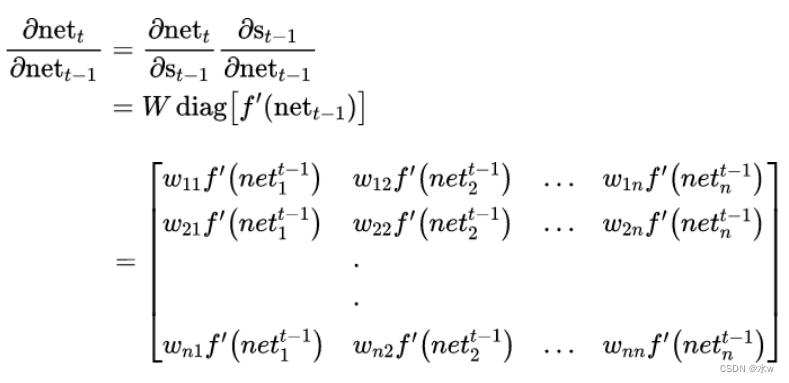

循环层将误差项反向传递到上一层网络,与普通的全连接层完全一样


C. 权重梯度的计算
BPTT算法的最后一步:计算每个权重的梯度。 首先,计算误差函数E对权重矩阵W的梯度 𝜕𝐸/𝜕w
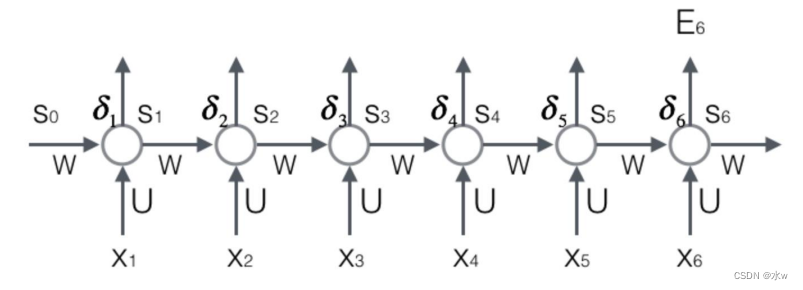
前两步中已经计算得到的量包括每个时刻t
循环层
的输出值
𝑠
𝑡
,以及误差项
𝛿
𝑡
。
求得任意一个时刻的
误差项
𝛿
𝑡
,以及上一个时刻循环层的输出值
𝑠
𝑡−1
,就可以按照下面的公式求出权重矩阵在t时刻的梯度
𝛻
𝑊
𝑡
𝐸
:
最终的梯度 𝜵 𝑾 𝑬 是各个时刻的梯度之和

4 双向循环神经网络
对于语言模型来说,很多时候光看前面的词是不够的,比如下面这句话:
我的手机坏了,我打算____一部新手机。
如果我们只看横线前面的词,手机坏了,那么我是打算修一修?换一部新的?还是大哭一场?这些都是无法确定的。
但如果我们也看到了横线后面的词是『一部新手机』,那么,横线上的词 填『买』的概率就大得多了。
在此任务中,可以增加一个按照时间的逆序来传递信息的网络层,增强网络的能力。
基本循环神经网络无法对此进行建模,因此,需要 双向循环神经网络 .双向循环神经网络由两层循环神经网络组成,它们的输入相同,只是信息传递的方向不同。
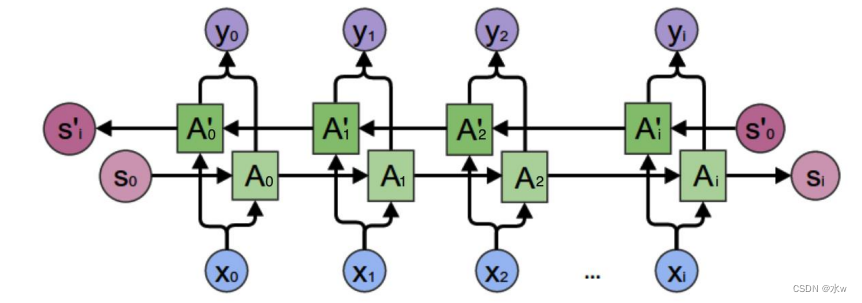
◼ 双向循环神经网络的隐藏层
双向循环神经网络
的隐藏层要保存两个值,一个值
𝐴
参与正向计算, 另一个值𝐴’
参与反向计算。最终的输出值取决于
𝐴
和
𝐴’。其计算方法为(以y2为例):
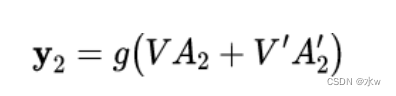
𝐴2和𝐴′2 则分别计算:
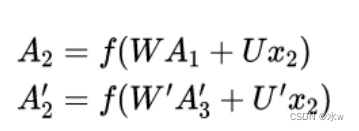
正向计算时,隐藏层的值 𝑠 𝑡 与 𝑠 𝑡−1 有关;反向计算时,隐藏层的值 𝑠 𝑡′与 𝑠 𝑡+1 ′ 有关;最终的输出取决于正向和反向计算的 加和 。
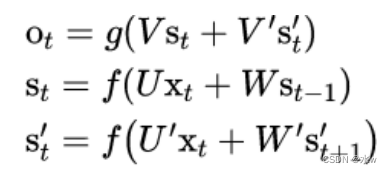
从上面三个公式得到,正向计算和反向计算
不共享权重
, 也就是说𝑈
和
𝑈′
、
𝑊
和
𝑊′
、
𝑉
和
𝑉′
都是不同的
权重矩阵
。
主要参考文献:

















 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











