







目录
前言:安装torch
参考博客python Anaconda以及pytorch下载安装,在jupter notebook中执行代码_水w的博客-CSDN博客
AI地图:


一、前期知识
◼ 数据操作
(1) 访问张量形状
① 可以通过张量的shape属性来访问张量的形状和张量中元素的总数。

(2)改变张量形状
① 要改变一个张量的形状而不改变元素数量和元素值,可以调用reshape函数

(3)创建全0、全1张量
① 使用全0、全1、其他常量或者从特定分布中随即采样的数字。

(4)创建特定值张量
① 通过提供包含数值的Python列表(或嵌套列表)来为所需张量中的每个元素赋予确定值。

(5)张量运算操作
- 常见的标准算术运算符(+、-、*、/、和 **)都可以被升级为按元素运算。

对每个元素应用更多的计算。

- 张量合并操作:可以把多个张量结合在一起。

- 张量逻辑运算:通过逻辑运算符构建二元张量。

- 张量累加运算: 对张量中所有元素进行求和会产生一个只有一个元素的张量

- 张量广播运算:即使形状不同,仍然可以通过调用广播机制(broadcasting mechanism) 来执行按元素操作。

- 张量访问运算:可以用[-1]选择最后一个元素,可以用[1:3]选择第二个和第三个元素

- 张量元素改写
① 除读取外,还可以通过指定索引来将元素写入矩阵。

② 为多个元素赋值相同的值,只需要索引所有元素,然后为它们赋值。
- 张量内存变化
① 运行一些操作可能会导致为新结果分配内容。

② 如果在后续计算中没有重复使用X,即内存不会过多复制,也可以使用X[:] = X + Y 或 X += Y 来减少操作的内存开销。

- 张量转Numpy
① 张量转 NumPy。

② 将大小为1的张量转为 Python 标量。

◼ 数据预处理
(1)创建数据集:创建一个人工数据集,并存储在csv(逗号分隔符)文件。

(2)加载数据集: 从创建的csv文件中加载原始数据集。

(3) 预处理数据集
① 为了处理缺失的数据,典型的方法包括插值和删除,这里,我们考虑插值。

② 对于inputs中的类别值或离散值,将“NaN”视为一个类别。

(4) 数据集转张量
① inputs 和 outputs 中的所有条目都是数值类型,它们可以转换为张量格式。

◼ 线性代数知识









# 标量
(1)标量:由只有一个元素的张量表示。

# 向量
(1)创建向量: 可以将向量视为标量值组成的列表。
(2)访问向量元素:通过张量的索引来访问任一元素。
(3)访问向量长度,向量维度

(4)向量求和: 计算所有元素的和。

(5)向量点积
① 点积是相同位置的按元素成绩的和。

② 可以通过执行按元素乘法,然后进行求和来表示两个向量的点积。

# 矩阵
(1)创建矩阵:通过指定两个分量m和n来创建一个形状为m×n的矩阵。
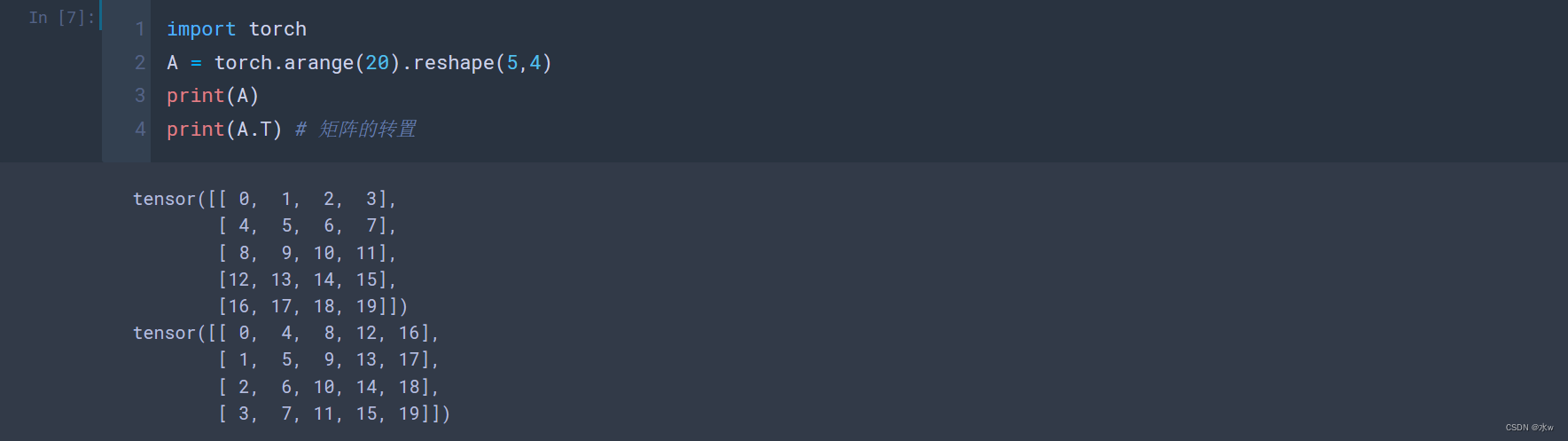
(2)矩阵的转置
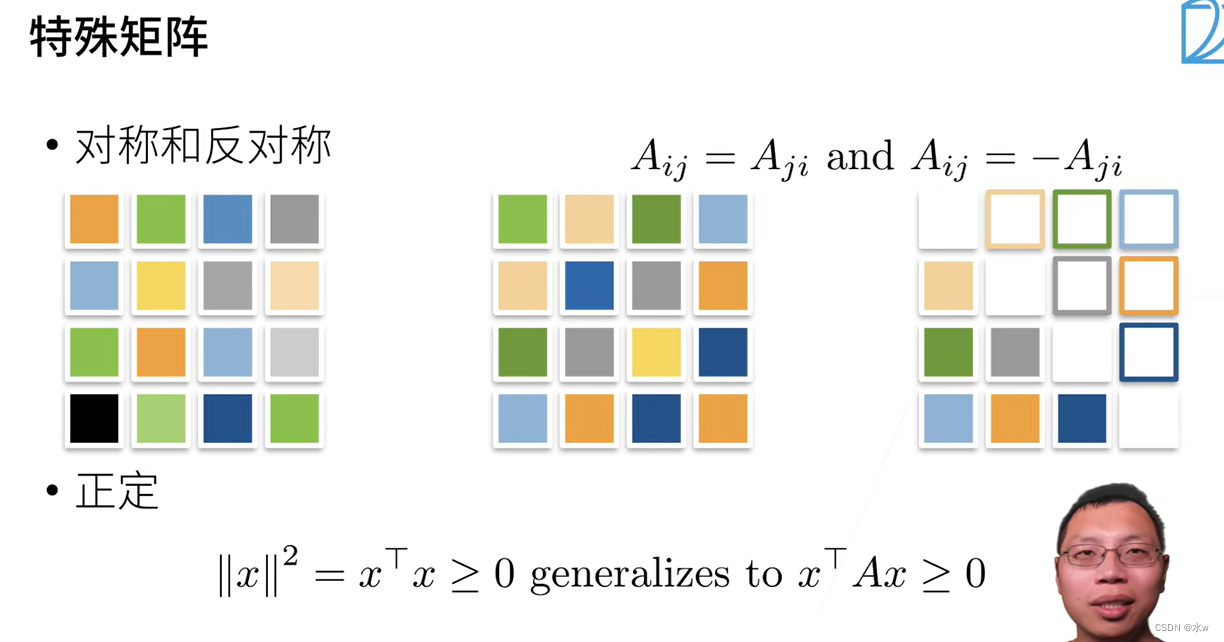
(3)对称矩阵的转置等于它本身 
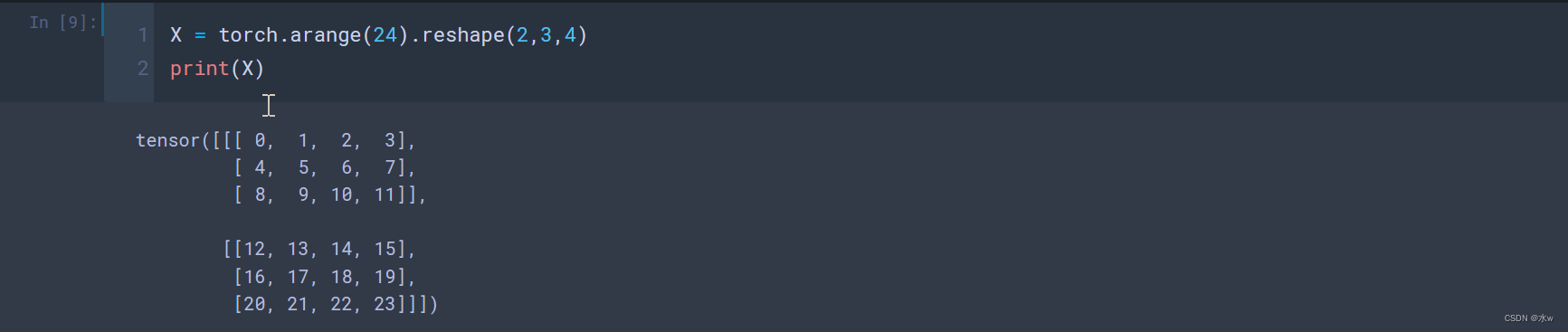
(4)多维矩阵:就像向量是标量的推广,矩阵是向量的推广一样,可以构建更多轴的数据结构。
(5)矩阵克隆: 给定具有相同形状的任何两个张量,任何按元素二元运算的结果都将是相同形状的张量。
(6)矩阵相乘(对应元素相乘):两个句子的按元素乘法称为哈达玛积(Hadamard product)(数学符号⊙)

(7)矩阵加标量

(8)矩阵求和:表示任意形状张量的元素和。
矩阵某轴求和(维度丢失):指定张量沿哪一个轴来通过求和降低维度。

 (9)矩阵平均值: 一个与求和相关的量是平均值(mean或average)。
(9)矩阵平均值: 一个与求和相关的量是平均值(mean或average)。

(10)矩阵广播:通过广播将 A 除以 sum_A。 
(11) 矩阵某轴累加: 某个轴计算A元素的累加总和。

(12)矩阵向量积
A是一个m×n的矩阵,x是一个n×1的矩阵,矩阵向量积是一个长度为m的列向量,其第i个元素是点积。

(13)矩阵相乘(线性代数相乘)
可以将矩阵-矩阵乘法AB看作是简单地执行m次矩阵-向量积,并将结果拼接在一起,形成一个n×m矩阵。

(14)范数
L1范数,它表示为向量元素的绝对值之和;

L2 范数是向量元素平方和的平方根;

矩阵F范数:矩阵的弗罗贝尼乌斯范数(Frobenius norm)是矩阵元素的平方和的平方根;


















 1238
1238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











